mysql考点
参考:
1、B树和B+树的区别?
1、b+ 树 在 叶子结点之间有指针,而b 树 没有,mysql 是双向指针。这是b+ 树 范围查找 强于 哈希、b树 的关键!
2、b+树 数据都在 叶子结点,b树 每个结点都有数据,b+树每个结点内都是 索引,可以放很多,因此分叉就多,b+树的高度就能被控制在小的范围内。
3、b+树 索引 会重复,b树的 索引 是不会重复出现的。
2、B+ 树 是怎么产生的?
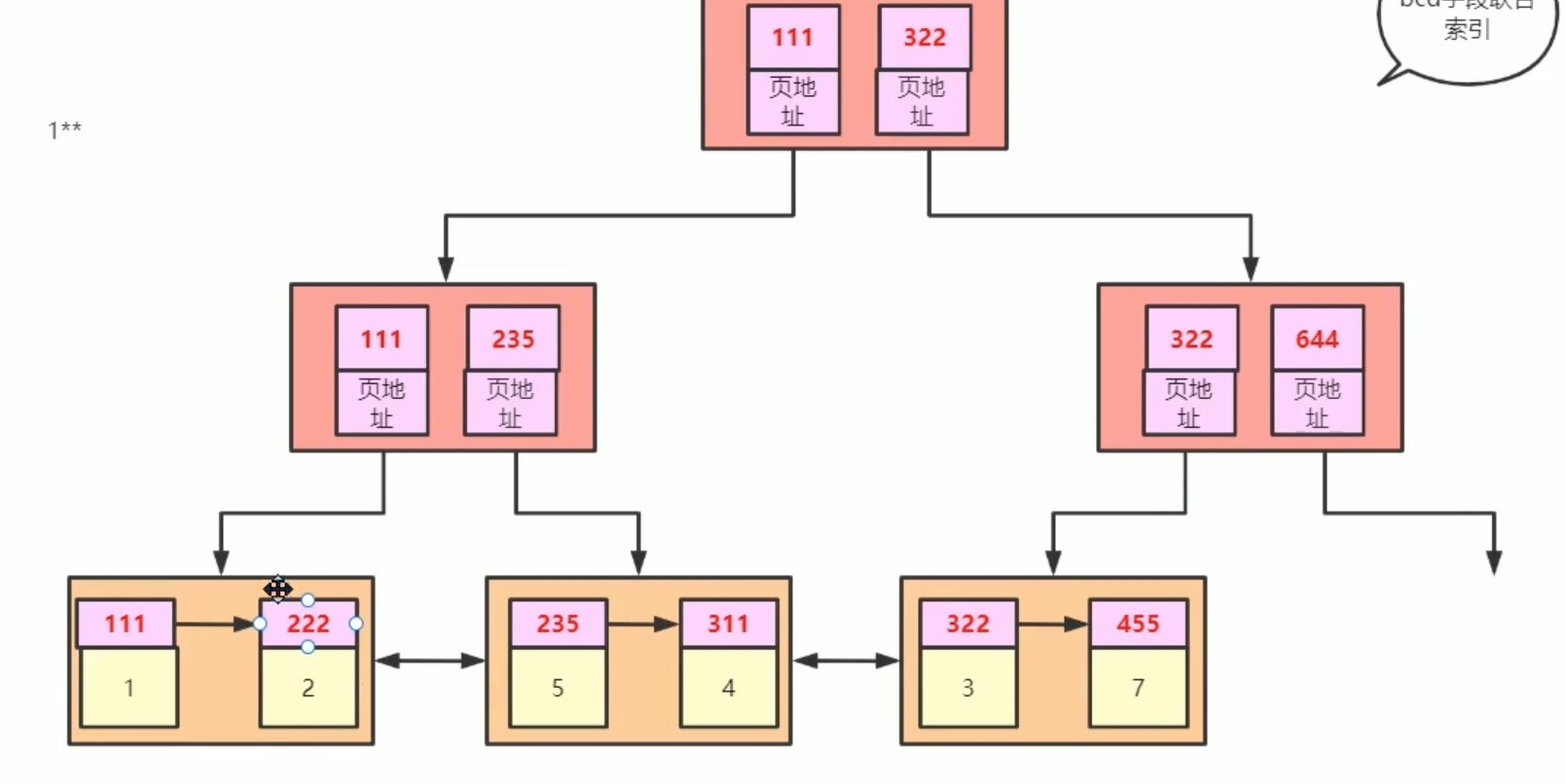
首先,每一个页(叶子结点)按照如下方式设计;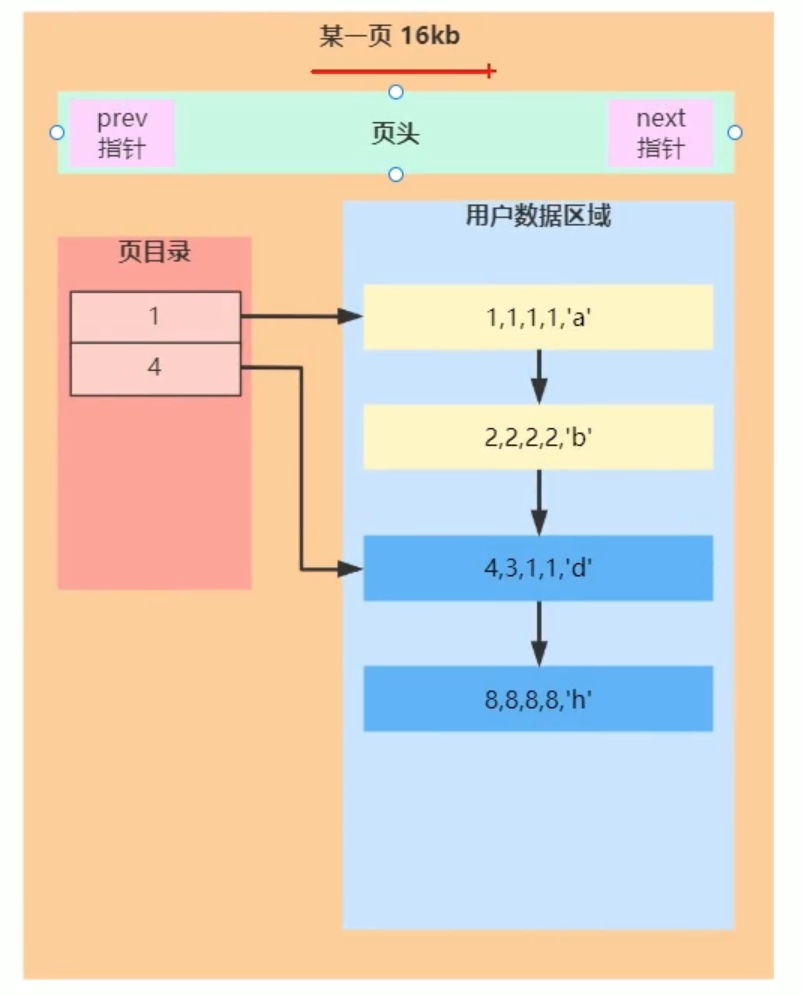
以上 用户数据 按照 顺序递增 加入链表,(所以最好用自增顺序加入数据,不然链表的中间插入操作 复杂度高。);用页目录来降低搜索具体数据的复杂度; 页头中有两个指针 ,来连接 首尾叶子结点。
然后,如同 用页目录 简化 数据链 搜索复杂度的 思路,在不同叶子结点上面用 一个新的结点,只存放每个 叶子结点的 首 数据,来简化 搜索 叶子结点链表 的复杂度,如下:
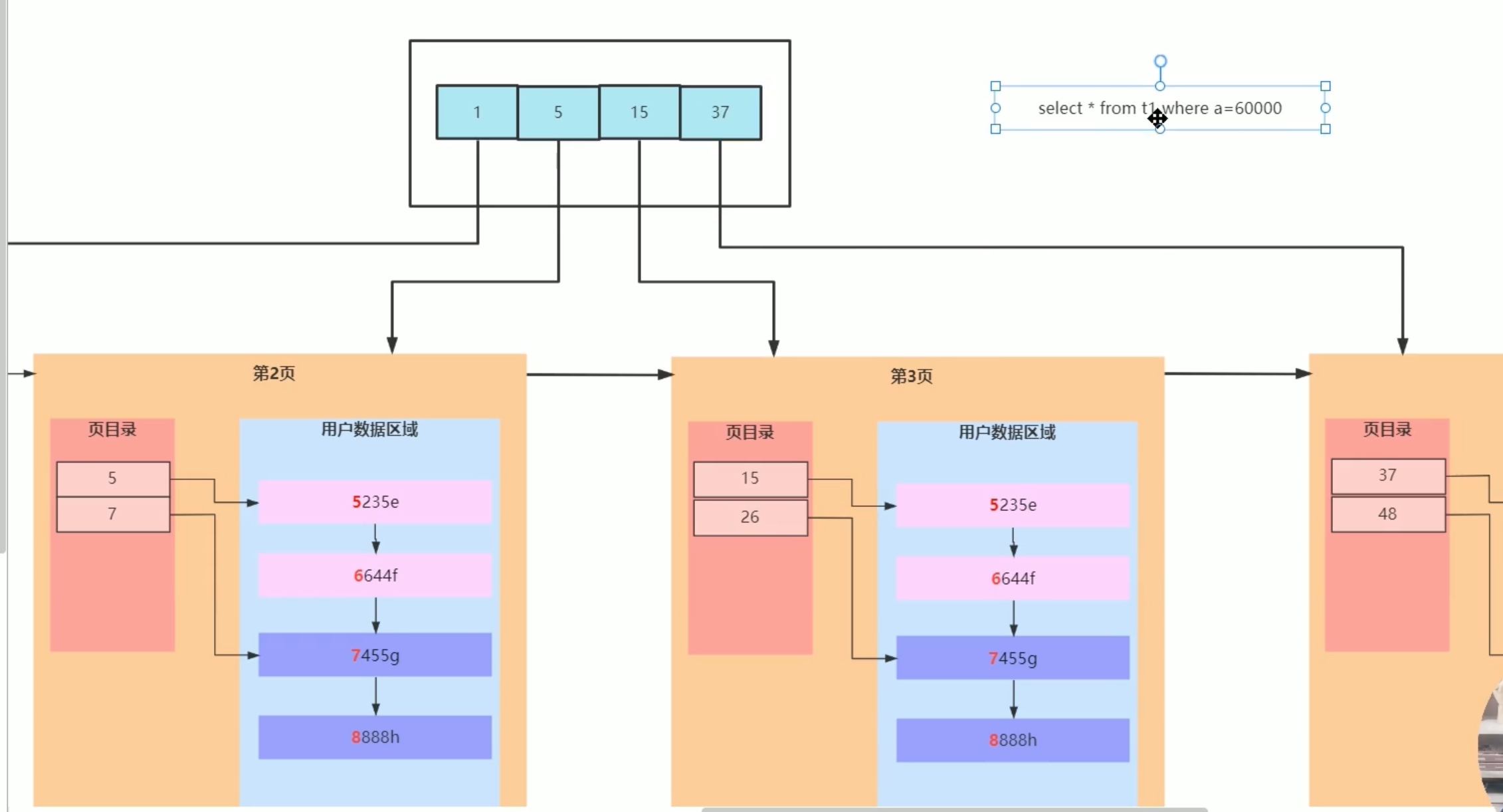
依次类推,一层一层往上,搭建起一个 b+ 树。
假如一个 索引 由一个 int类型的数据结构和一个指针组成,int 是 4b(4字节)innodb指针 是 6b,一个索引就是10b;
一个结点 是 16kb,一个结点纯放索引可以达到 16kb /10b =1638个索引。
假如 一个记录 是1kb,那么叶子结点 能存 16kb / 1kb=16条记录,一个索引 就能查到 16条记录,两层情况的 b+ 树 理论可以存放 1638 * 16 = 26208 条记录。
以此类推,三层的b+ 树 可以存 1638 * 1638 * 16 = 42928704(4千万)记录。
3、Innodb是如何支持范围查找能走索引的?
1、走索引;
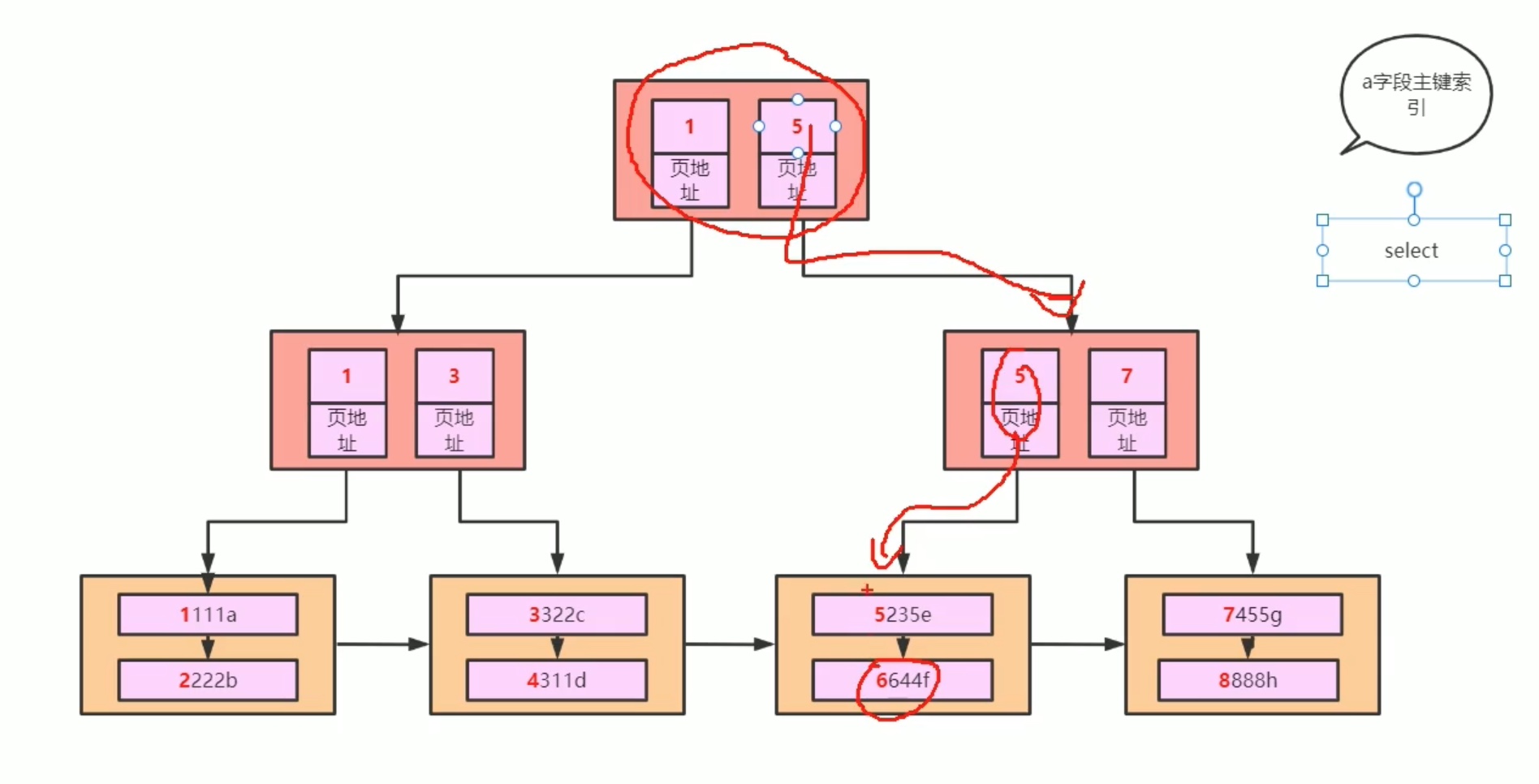
2、走全表查询;
3、先走索引,再 走叶子结点查找,是范围查找的主流做法。
4、为什么要遵守最左前缀原则才能利用到索引?
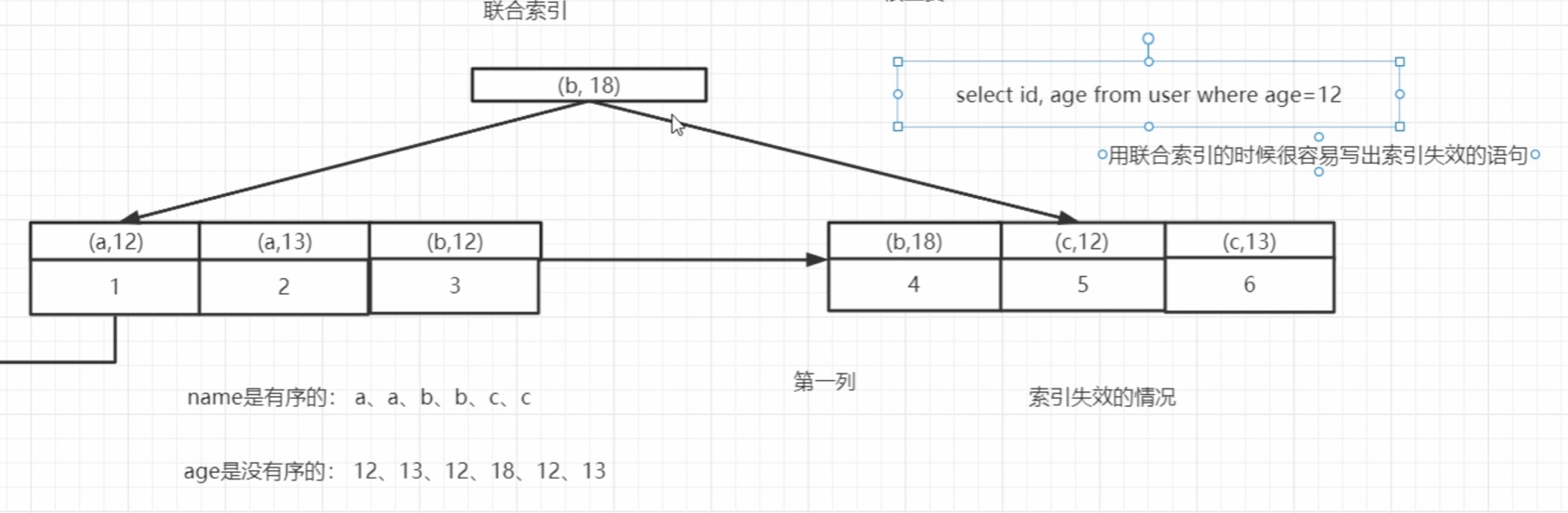
因为 在覆盖索引(联合索引) 中,结构类似于多级目录,一定在要保证 一级目录有序的前提下,二级目录才能有序,以此类推;
如果直接 没有 左边的索引,直接用右边索引 ,因为无序会找不到索引。
只要 where 后面有 索引,顺序不是 和联合索引一样没关系,mysql 会自动调优成 索引顺序。 where c and a and b; 是复合最佳左前缀的。
另外,(1号位置、3号位置)也是可以走索引的,先利用 1号位置找到 叶子结点,再 用3号位置 索引条件下沉 直接 在 b+树中 判断好 ,再 一次性去聚集索引(主键索引)中回表查询。
5、范围查找导致索引失效原理分析
“走 索引、再走回表查询 所造成的 io消耗 +cpu 消耗” > “走 全表查询 的io 消耗 + cpu消耗”。
此时,mysql 会自动选择最优的 方法。就可能 范围查找 索引失效了,cpu 开销单位0.2,io 开销单位1.0。
(一)走全表查询 开销:
通过 show table status like '表名' 可以 查看到 Data_length,通过 show table status like '表名' 可以 查看到 Rows, data_length/1024/16 = 结点数量, 结点数量 * 1 = io 开销;
rows * 0.2 = cpu 开销;
(二)走索引开销:
先用1.0也就是常数级开销找到起始索引位置,再把范围内 x 个叶子结点对应的主键加载进内存,然后去回表查询。
x * 1.0 + 1.0 = io 开销
cpu 二级索引中 读取这 x 个数据一遍,回表查询再 读一遍。
x * 0.2 + x * 0.2 = cpu 开销
比较(一)(二)总的谁小,mysql 会自动选小的,可以就导致了范围索引失效了。
6、覆盖索引的底层原理
select 要找的 字段 直接就是 索引 中的一员,或者就是 二级索引中叶子结点中存放的 数据,不用去 回表查询了。也就是select 要找的 直接被 索引覆盖住了。
extra 会是 using index。
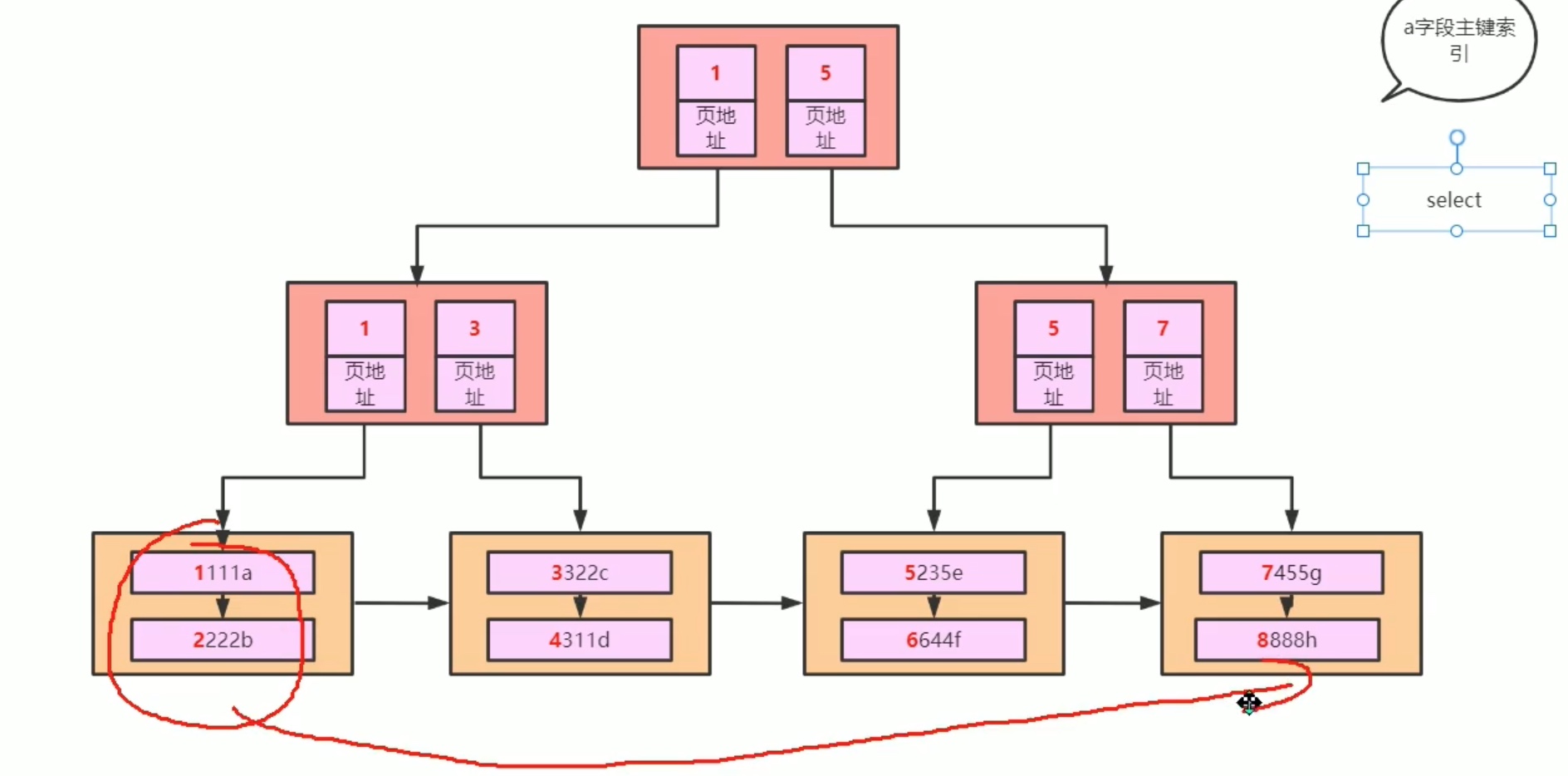
7、索引扫描底层原理
b 是二级索引的一员
select b from t;
连 where 都没有,只可能走叶子结点从左至右遍历,也可能走索引。
mysql 会考虑两种 遍历,一种是 走主键索引的叶子结点遍历,遍历的是全数据;另一种 是走 b 所在的二级索引的叶子结点遍历,遍历的是一批索引 而已,不是全数据,因此可能快很多。
8、order by为什么会导致索引失效?
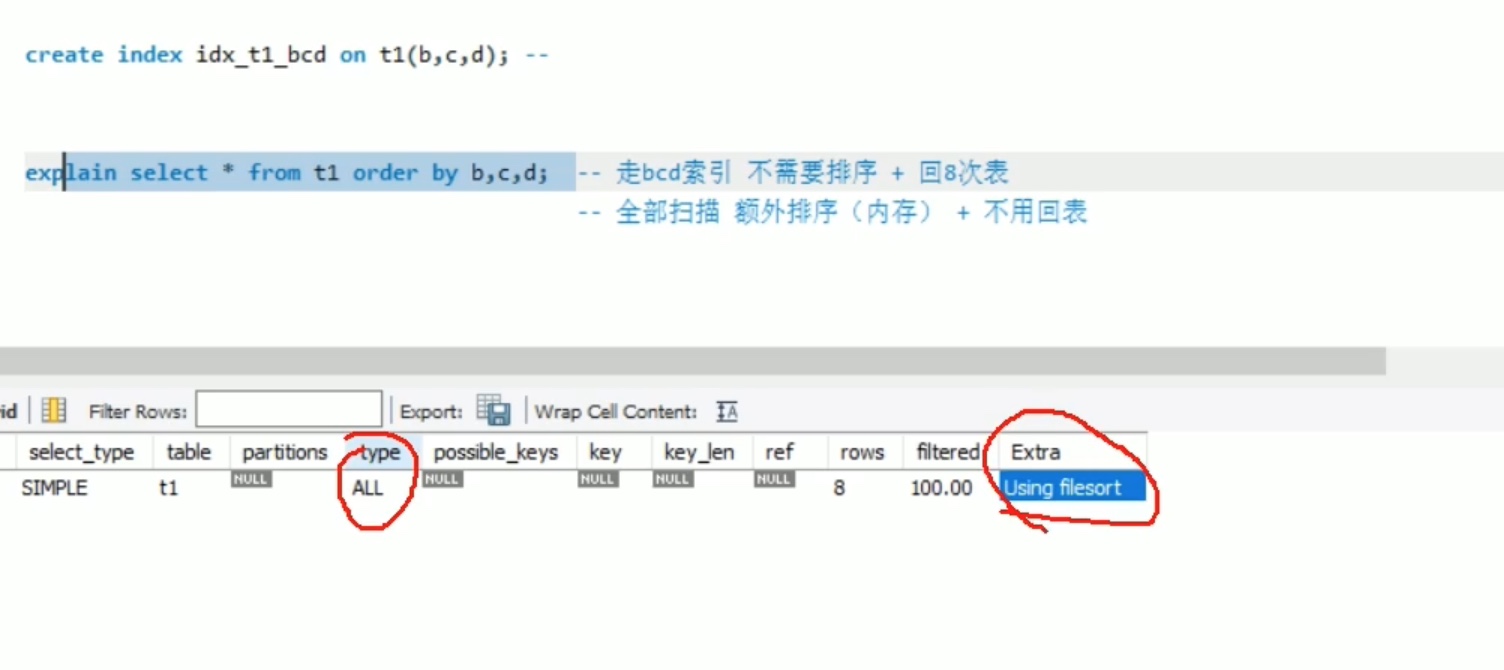
都是走 遍历叶子结点 的方向,走二级索引还不用排序,但是 回表8次,全表扫描的话,对全部数据 加载进 内存,然后内存排序(数量不多的话可能很快),不用回表,数量不多的话,mysql 会选择一个 最优的,可能是全表扫描。
9、mysql中的数据类型转换有哪些要注意的?

以上 a字段是 int类型,e字段是 str类型;
mysql 中 只要 类型对不上都会强制类型转换,但是不是转ascii码,而是无论=左边还是右边,统一 str 转成 数字 0,但是 ‘123’、‘23’ 、‘9’ 这样的数字字符串 会被转成 123、23、9 这样对应的数字。
以上的 最后一个 式子中,e = 1,等式左边e 是 str 类型,右边是 int 的1, e字段中所有的索引都被自动转成了 0,e 要把b+ 树结构都改了,开销会非常大,mysql权衡利弊,最后根本没有用到索引,直接用全表扫描。
10、对字段进行操作导致索引失效原理
e 是索引
where e = 1,等式左边e 是 str 类型,右边是 int 的1, e字段中所有的索引都被自动转成了 0,e 要把b+ 树结构都改了,开销会非常大,mysql权衡利弊,最后根本没有用到索引,直接用全表扫描。
11、Mysql中有哪些存储引擎?
这些存储引擎 是针对 表的,叫 表存储引擎。
innodb、myisam、memory、csv。
12、MyISAM和InnoDB的区别是什么?

13、数据表设计时,字段你会如何选择?



14、Mysql中VARCHAR(M)最多能存储多少数据?

15、请说下事务的基本特性?

16、事务并发可能引发什么问题?
脏读(别人提交前,被你读了)、不可重复读(读第一次,别人update了,你读第二次)、幻读(读第一次,别人insert了,你读第二次)。
17、简单描述下Mysql各种索引?
主键索引、唯一索引(多个null不会冲突)、普通索引、前缀索引(取很长的str的前几个字符作索引)。
18、什么是三星索引?

19、InnoDB一颗B+树可以存放多少行数据?
约 2千万。

前面在 b+ 树是怎么产生的疑问中,我们已经推过了,但是实际上innodb 中不是int类型,而是bigint类型,长度是8 ,因此是 2千万左右。
20、如何提高insert的性能?
1、合并 多条 insert 为一条,减少日志量;
insert into t values(a,b,c),(d,e,f)…
2、bulk_insert_buffle_size 调大批量插入缓存;
3、innodb_flush_log_at_trx_commit = 0;
4、手动提交事务,减少io。
21、什么是全局锁、共享锁、排它锁?
共享锁(读锁):本会话只能对其读不能写,对其他表不能任何操作;其他会话可以来读,不能来写。
排它锁(写锁):本会话能 对其 增删改查,不能对其他表或者行 任何操作,其他会话不能对锁上的对象有任何操作。
全局锁: 库逻辑备份时,整个库都处于 只读状态。
22、谈一下Mysql中的死锁
两个或者两个以上的进程,争夺资源而相互等待的现象。
show engine innodb status 查看最近一次死锁;
innodb lock monitor 锁监控;
死锁怎么办? 应该超时等待时间 innodbblockwait_timeout
发现死锁后,把一个事务回滚,让其他事务继续执行。
23、Mysq如何实现读写分离
将mysql 的数据拷贝成多份 写到其他mysql 服务器上,原来mysql 的数据库负责写,称为 “主库”,其他的数据库 负责读,称为 “从库”。
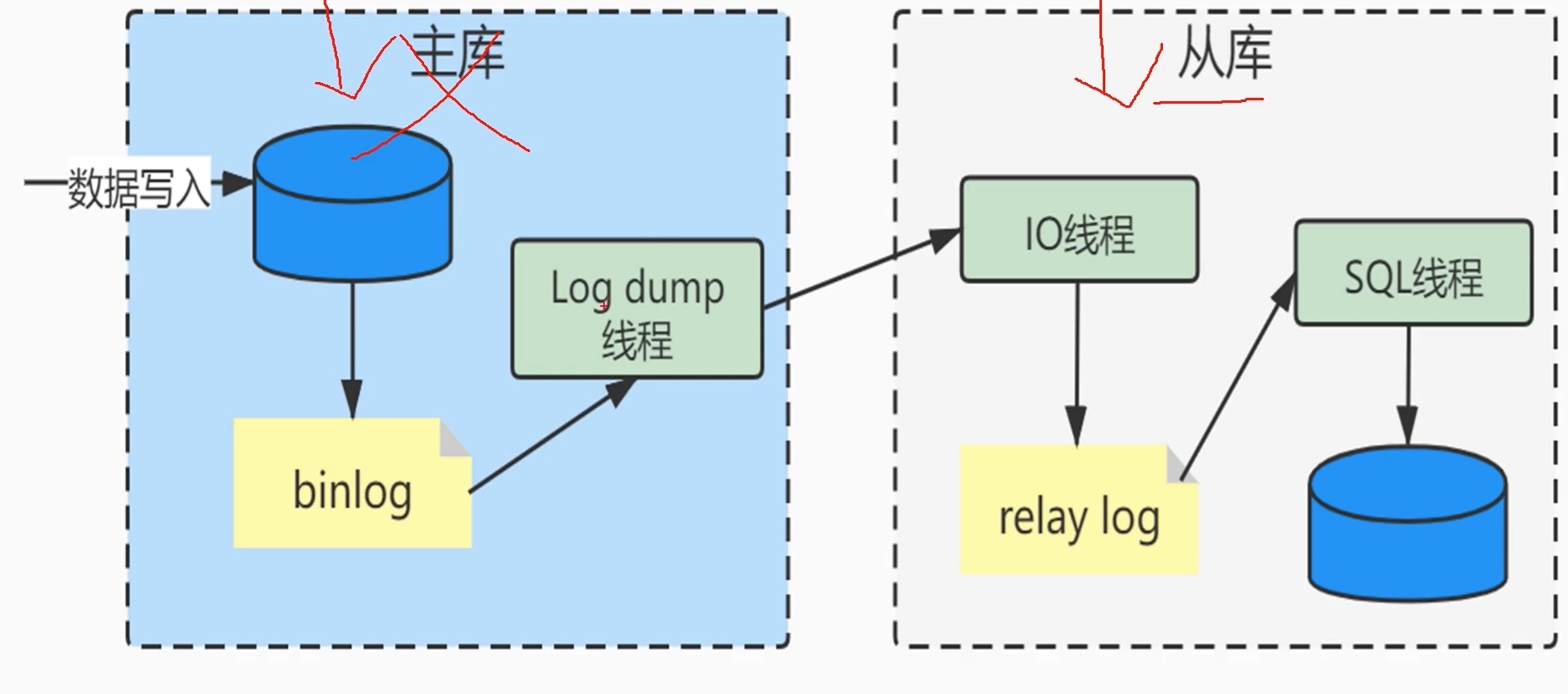
用了 binlog 日志文件,开了一个log dump 线程在主库,从库中用一个io线程接收,搞了一个依赖日志 relay log,把主库的修改同步来过。
优点:1、部分宕机,也不会全部完蛋;
2、分开读写,性能更优;
缺点:mysql 的读写分离是 异步 的,异步就是 不管结没结到 反馈,这边只管发送 ,容易导致 数据的丢失,和 kafka 的异步 丢数据类似。
24、Mysq如何实现分库分表
根据 业务 “垂直拆分”:例如 将不同的表根据“业务”分别放进 用户库、内容库…
“水平拆分”: 将单一的数据表,按照某一种规则,放进多个数据库或者多张数据表当中,例如 用 hash 取模 的规则 将 用户表 放进多个 用户库中1、2、3….; 例如 按时间 每个月的数据 放到每个月的库中。
有时候分库分表也会带来一些问题,比如说 以后查询 某个数据,需要跨多个库和多个表,我们引入 mycat 、等工具解决。
25、索引的基本原理
类似于 新华字典 的目录的作用,具体说一下 hash 、b+ 树就好了。
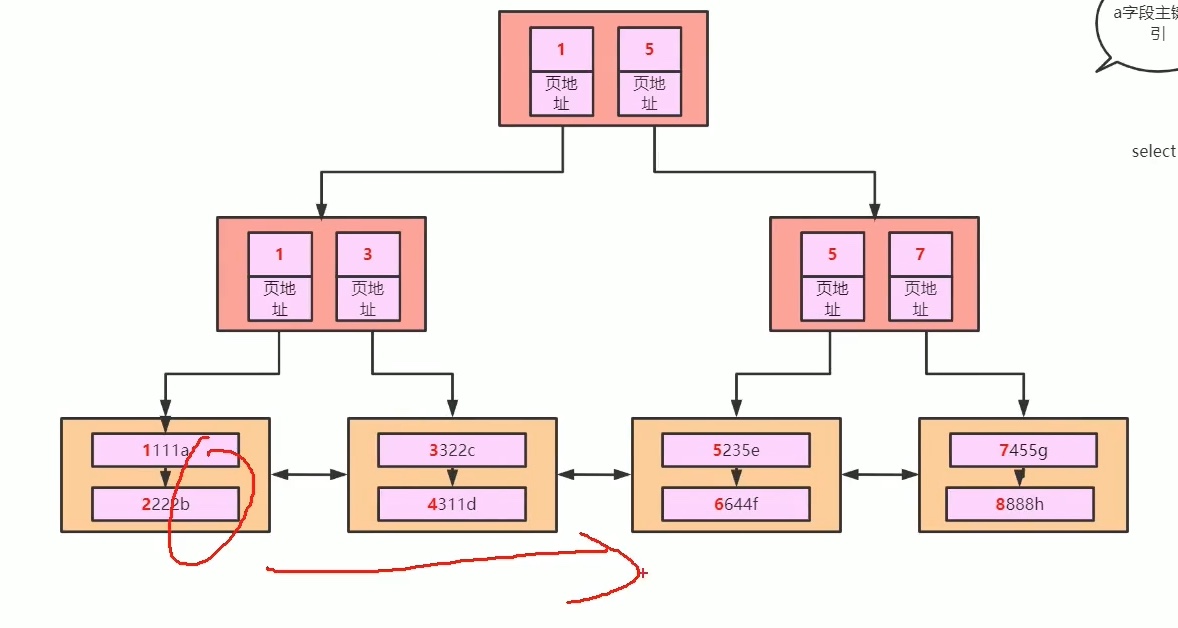
26、mysql聚簇和非聚簇索引的区别
聚族索引:索引找下去能找到 存在叶子结点的 真实数据;而且一定是顺序存储的。
非聚族索引: 索引 找下去 ,叶子结点 存的 也是 索引,找真实数据要回表查。
innodb 主 是聚族索引, myisam 是 非聚族索引存的都是 索引信息,所以 innodb 在范围查找占优,而大范围的排序或者全表扫 myisam 优;
总体innodb 强于myisam。
27、mysql索引结构,各自的优劣
主流的就是 b+ 树、其次 如果仅仅是单条查询,还可以用 hash。hash 面对大量重复值 ,存在大量的冲突,效率低,而且不支持范围操作,而b+ 树牛逼多了。
28、索引的设计原则

29、mysql锁的类型有哪些
共享锁、排它锁、
表锁、行锁、全局锁
意向共享锁、意向排它锁(这两个都是表锁无法手动创建,目的是通过预告降低尝试的操作次数。)、
行锁下又包括: 记录锁、间隙锁、临键锁(左开右闭)。
30、mysql执行计划怎么看
就是说说 explain select… 出现的各个指标的意义。
id)
explain结果里 id有相同也有不同,id大的优先,然后在id值相同的从上往下顺序执行。
(select_type)
里、外、中,join 等。
type)索引类型、类型。
const : 仅仅能够查到一条数据,用于primary key 或者 unique索引。eq_ref: 唯一性索引,对于每一个索引键的查询,返回匹配唯一行数据。ref: 非唯一性索引,对于每个“索引键”的查询,返回匹配的所有行 (0或者多个)。 range:检索指定范围的行,where后面是一个范围查询(between、<、>、in有时候会失效转为无索引情况。)index:把所有索引都查一遍。all:把所有字段都查一遍。
(possible_keys)可能用到的索引
key)实际用到的索引
(key_len)索引的长度,用于判断复合索引是否被完全使用。
(ref)表明当前表所参照的字段。
(rows)实际通过索引扫描的 数据个数(注意是取交并集之前就扫描了)。
(Extra)
using filesort:性能消耗大,需要“额外”一次排序(或者 查找),常见于order by 出现时。using temporary:性能损耗大,用到了临时表。常见于 group by 出现时。using index 性能提升。索引覆盖。using where 需要回表查询。impossible where 不可能出现的情况。
31、事务的基本特性和隔离级别
原子性(都成功都失败)、
一致性(事务的约束条件不能打破,90块钱不能买100块东西)、
隔离性(提交前对别人不可见)、
持久性(一旦提交永久保存);
隔离级别:
read uncommit 容易脏读
read commit 别人一改它就读了,可能前后不一致的 不可重复读
repeatable read (默认)总读第一次读到的,不管别人改没改,可能 幻读,因为别人insert 了
serializable 最死板,每个读都加锁不让别人操作,效率低。
32、怎么处理慢查询
看看原因:临时开 set global slow_query_log=1;查看mysql / data / 慢日志文件。
1、没命中索引? explain
2、查了不需要的字段?
3、数据量太大? 横向、纵向业务分表。
33、ACID靠什么保证的
innodb 表引擎用如下方法保证:
原子性 用 undolog 日志保证;
一致性 业务上保证;
隔离性 mvcc 保证;
持久性 内存+ redolog 日志 保证,宕机后从redolog 日志取数据恢复;
redolog 写盘 – 事务进入prepare状态 – binlog 写盘 – 持久化到 binlog – 如果成功 事务进入 commit 状态 – redolog 写入一个 commit;
34、什么是MVCC

在 read commit 和 repeatable read 两种隔离级别才有 mvcc,读未提交的话根本不存在版本号,串行化全是锁 用不上;


找到字段最新版本号trx_id ,如果在readview 或者它的左边就可以直接用,如果在readview 右边也就是版本号比 readview 大,则不可用, 如果不可用就回到 字段的 roll_point 链上去找上一个版本,重复这样的判断。
read commited 隔离级别下,readview 不断的生成,可能导致前后读的内容 发生了变化,而 repeatable read 隔离级别下,事务内都用第一个readview作后面出现的此字段的readview 来保证可重复读;
35、mysql主从同步原理


这个和kafka 有点像。
36、简述Myisam和Innodb的区别


37、简述mysql中索引类型及对数据库的性能的影响

38、什么是倒排索引?

39、Mysql数据库中,什么情况下设置了索引但无法使用
1、没有符合 “最左前缀”原则;
2、字段类型进行了 隐式转换,如 str 转 int 全部要变成 0,mysql就没走索引;
3、全表扫描 开销 小于 走索引加回表查询 的 开销;
40、B树和B+树的区别,为什么Mysql使用B+树

结合前面讲的 ,画个图。
41、乐观锁、悲观锁
行锁、表锁、等等都是悲观锁,真的锁住了;
乐观锁 不会真的是 锁住 行和表,而是通过版本控制mvcc的方式。