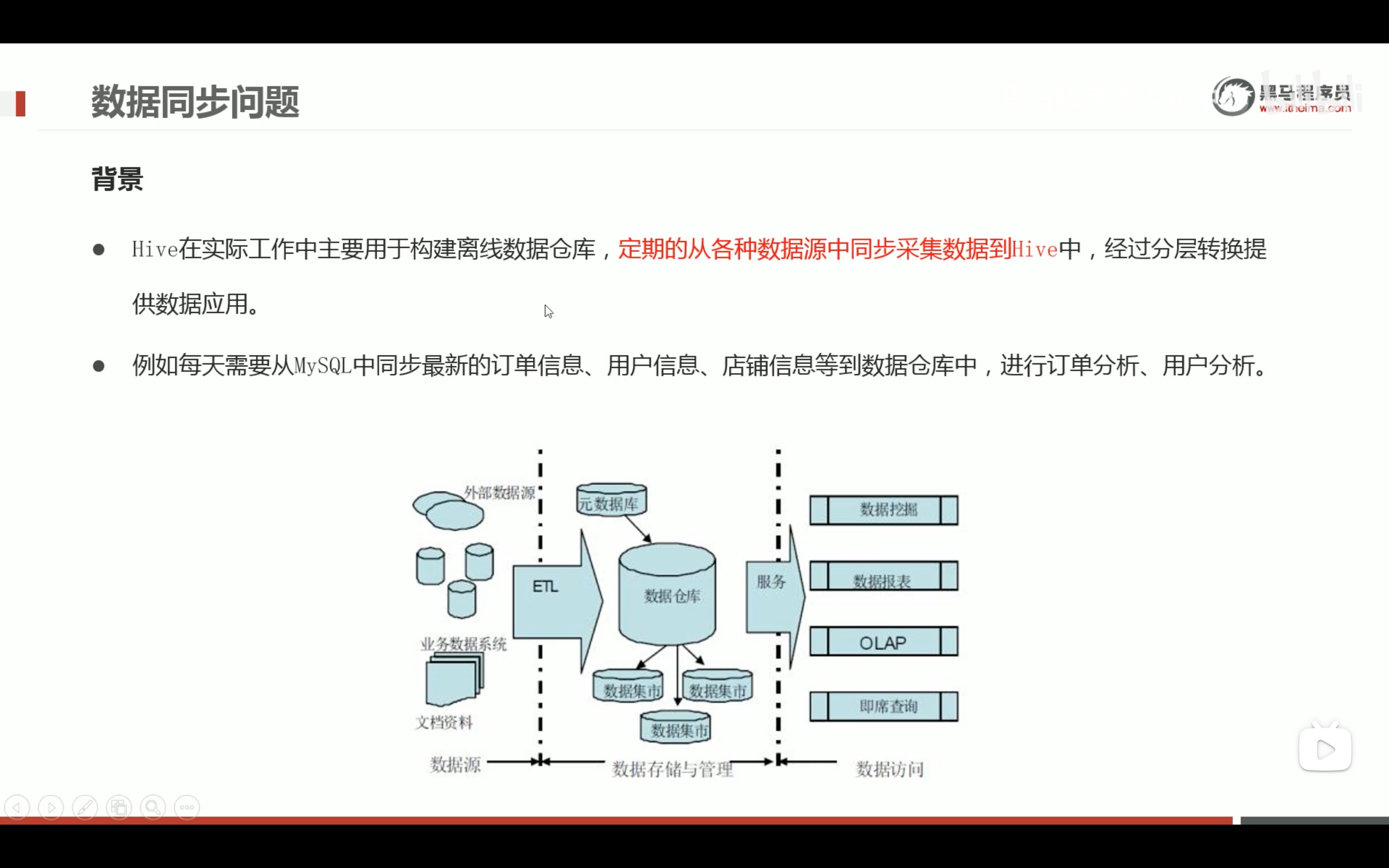
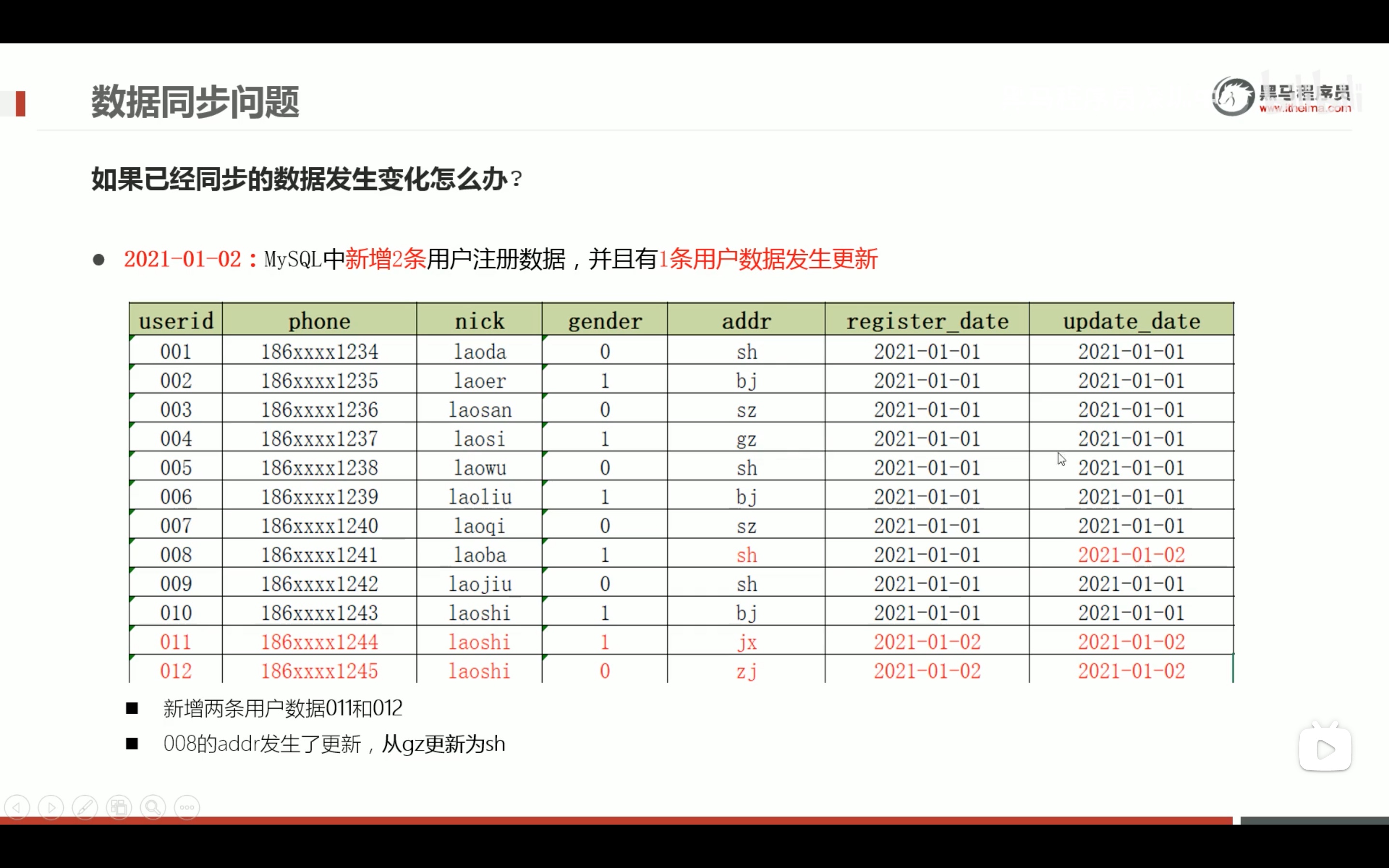
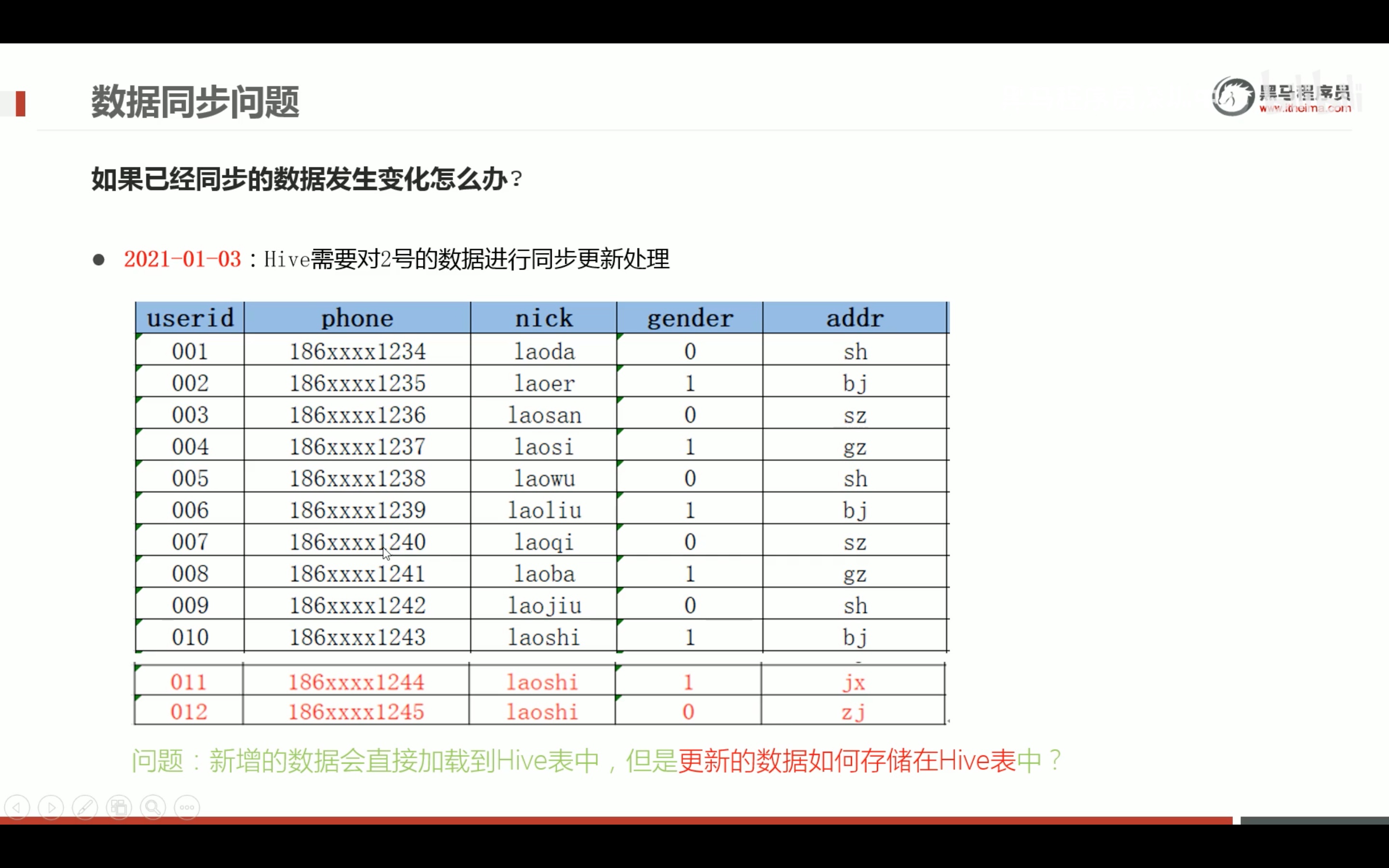
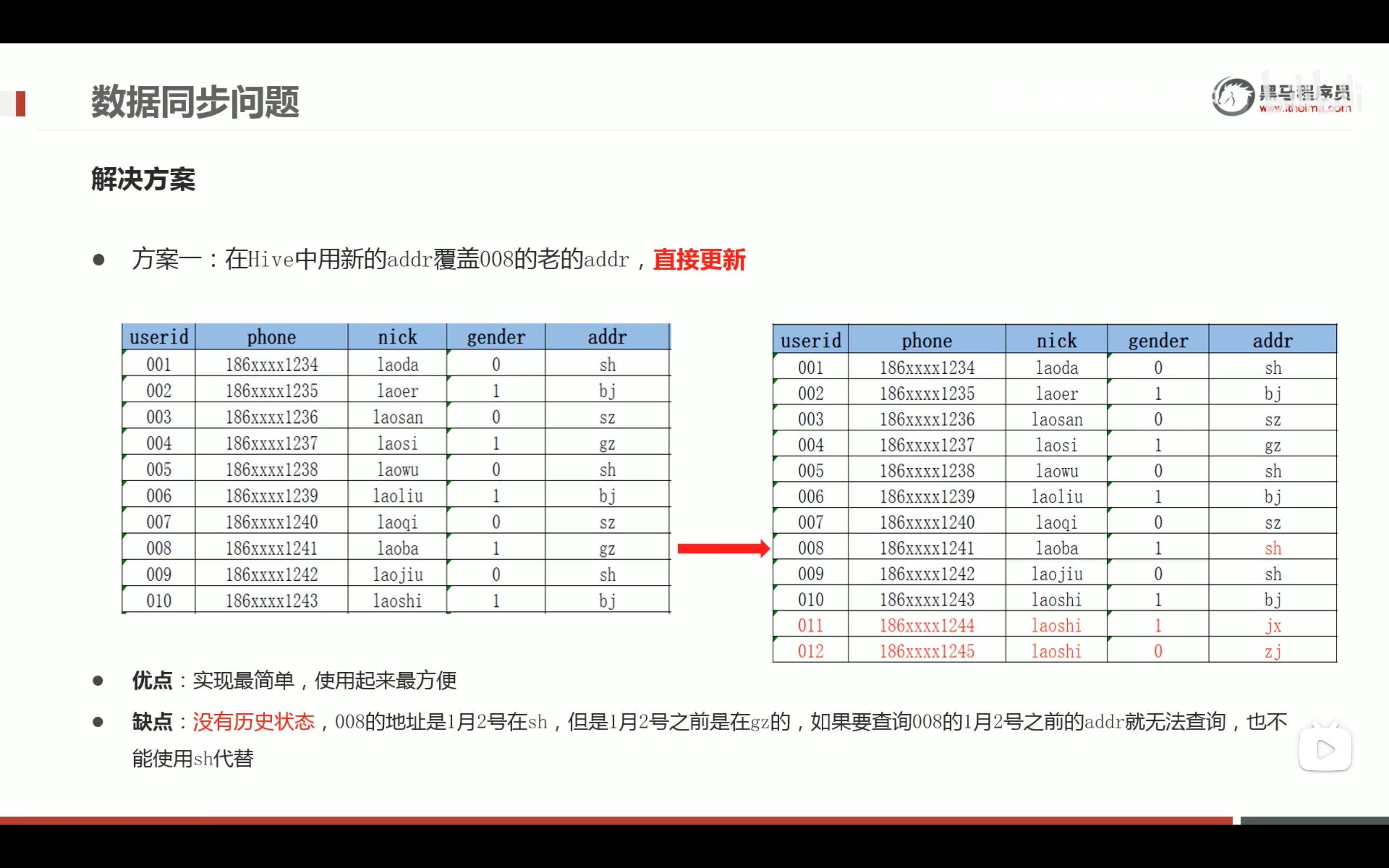
hive函数应用的案例
hive函数
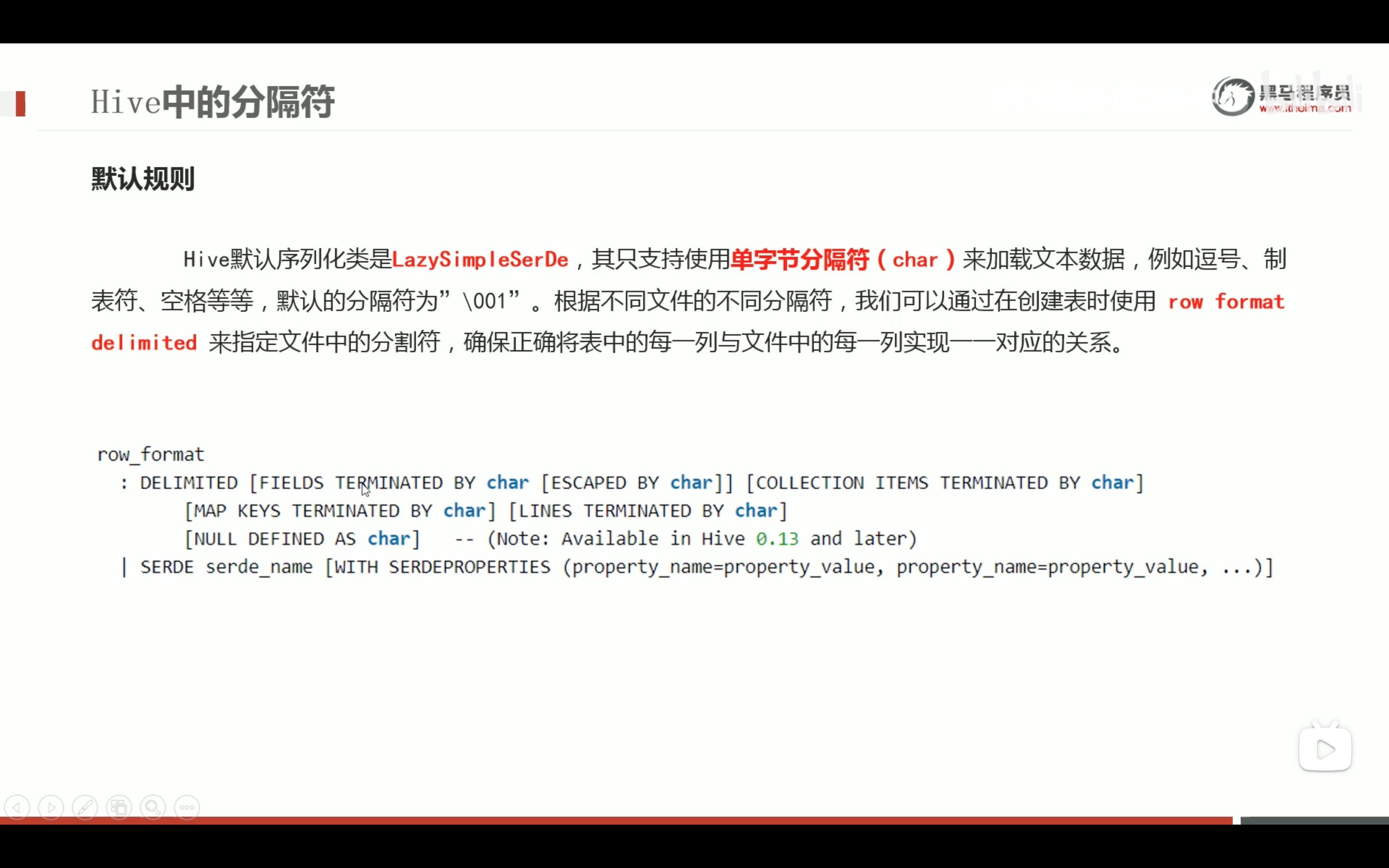
多字节分隔处理


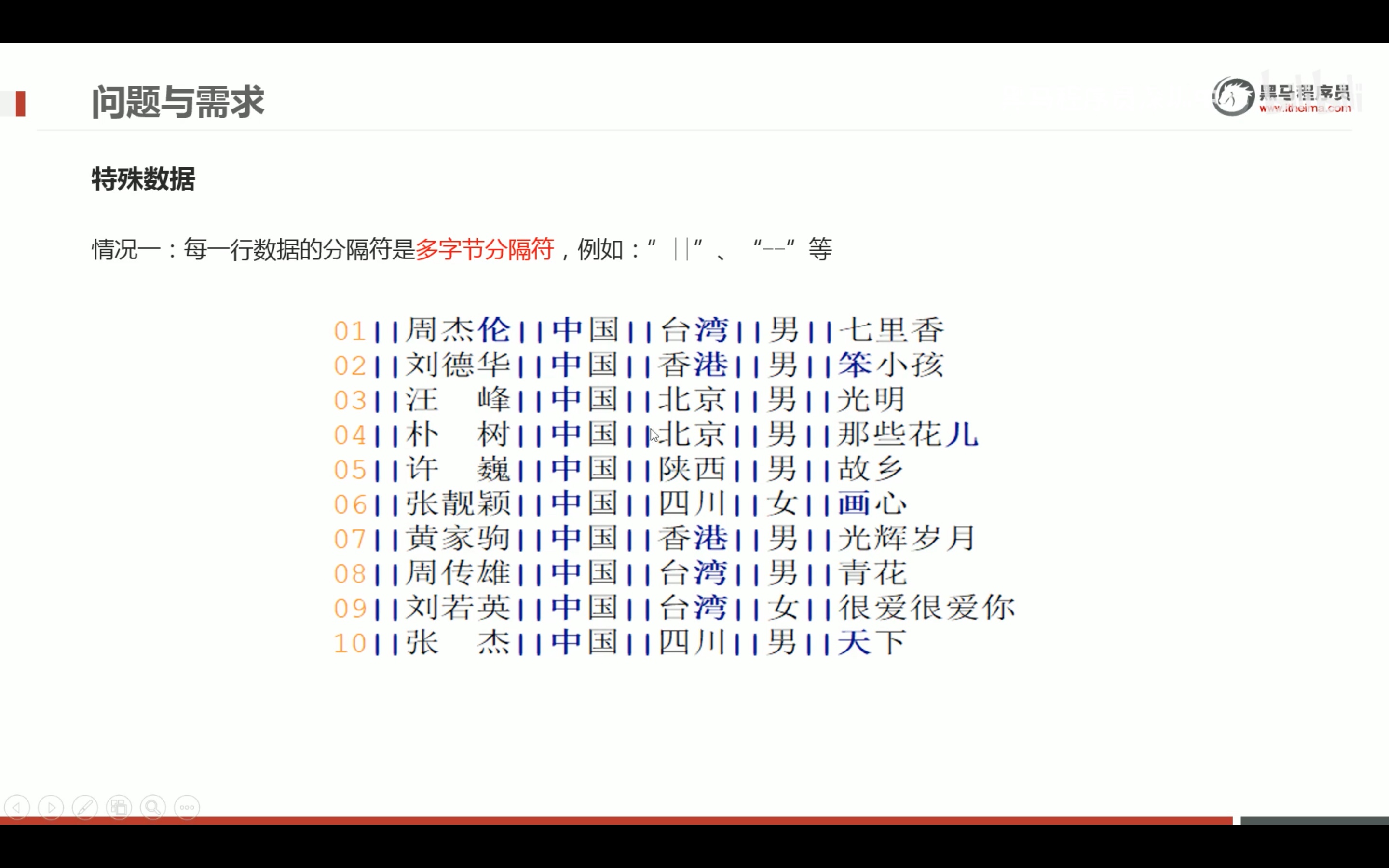
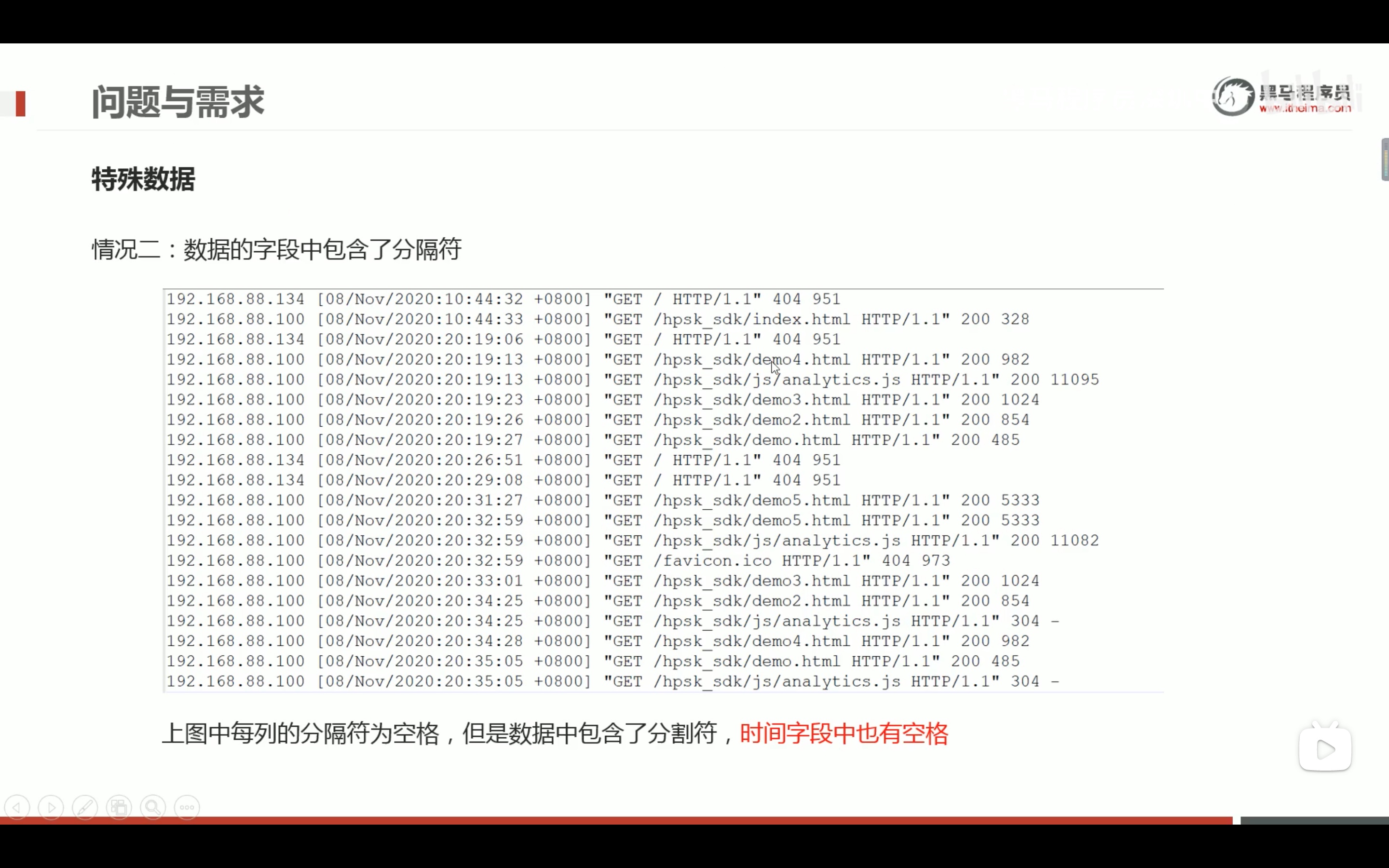

文件小的时候用python修改,多的时候,用mapreduce分布式处理。把两个|替换成一个| 。
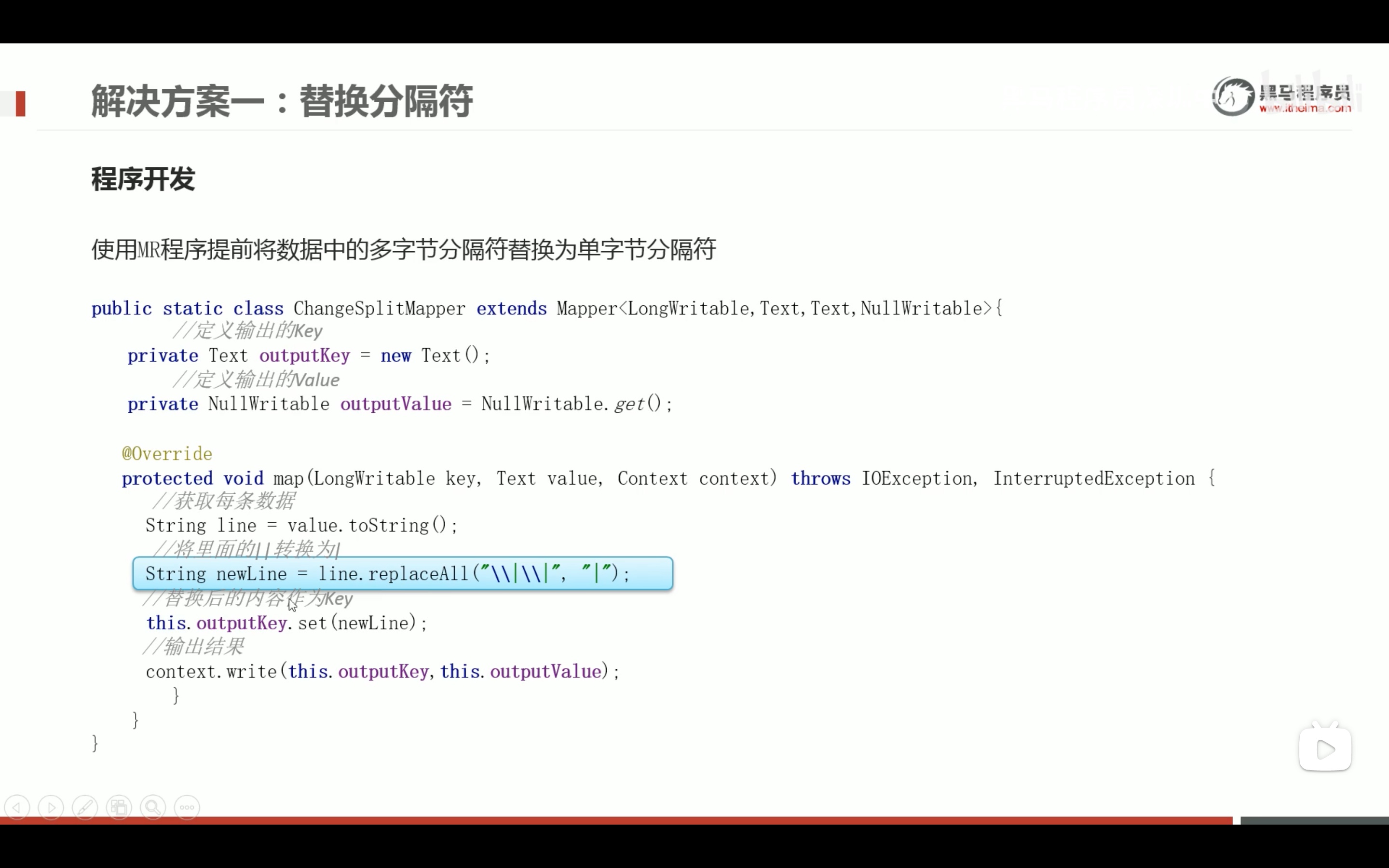


可以找一个在线正则表达式测试网站检查一下。这样挺方便。
第三种方法 ,相当于把第一种方法读的数据先清洗写进脚本,用自己写的脚本替代hive 的读取组件。不推荐使用。
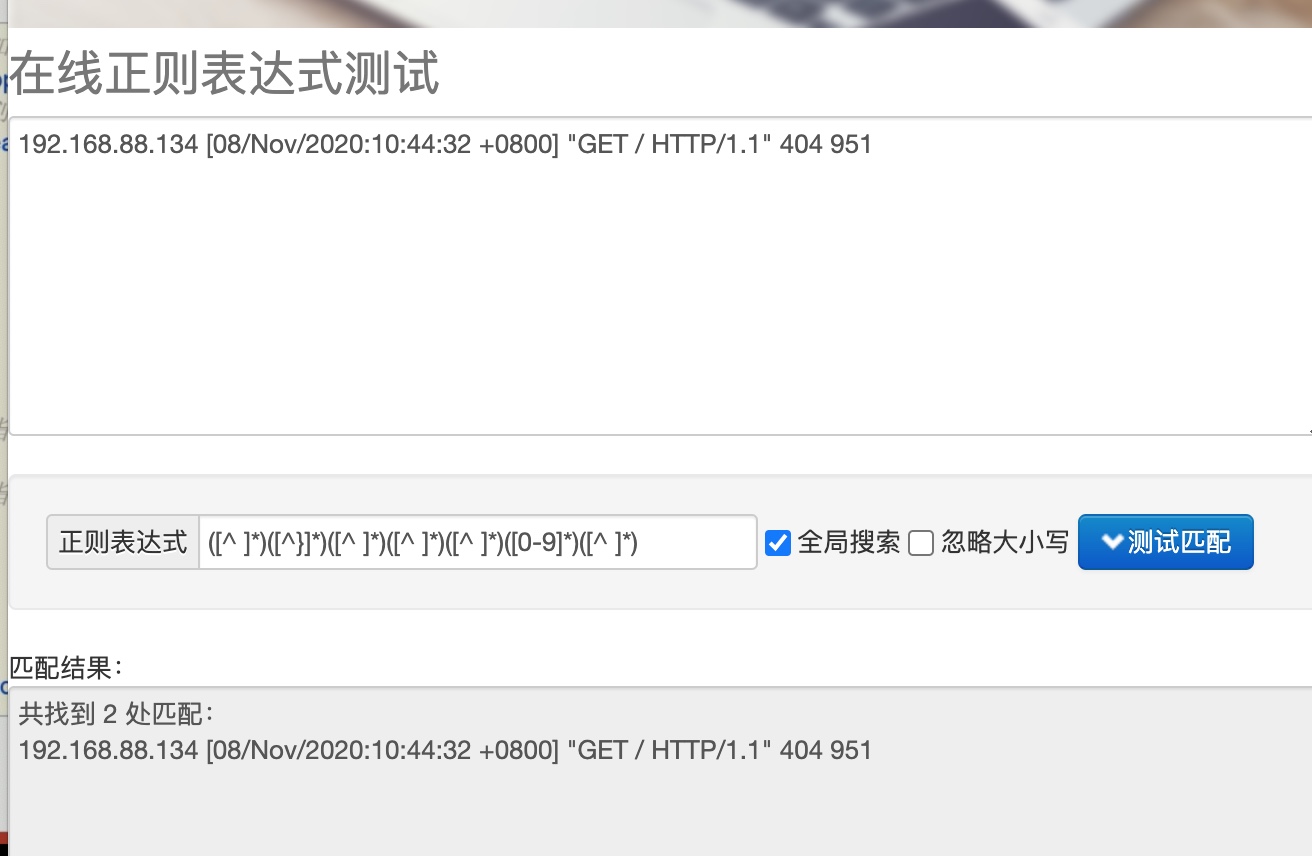
这里解释一下以上的正则表达式
在大的模式下,有7个()包裹的子模式,模式匹配时,从左至右匹配,每个成功匹配的子模式会被当成hive表中的一个字段。
1号子模式匹配任意多个非空格的字符,192.168.88.134已经匹配,遇到空格,1号子模式匹配失败。
2号子模式匹配任意多个非 } 字符,从1号子模式匹配失败的空格位置往后,一直到换行符,2号子模式匹配失败。
总模式的后面几个括号都没有用上。
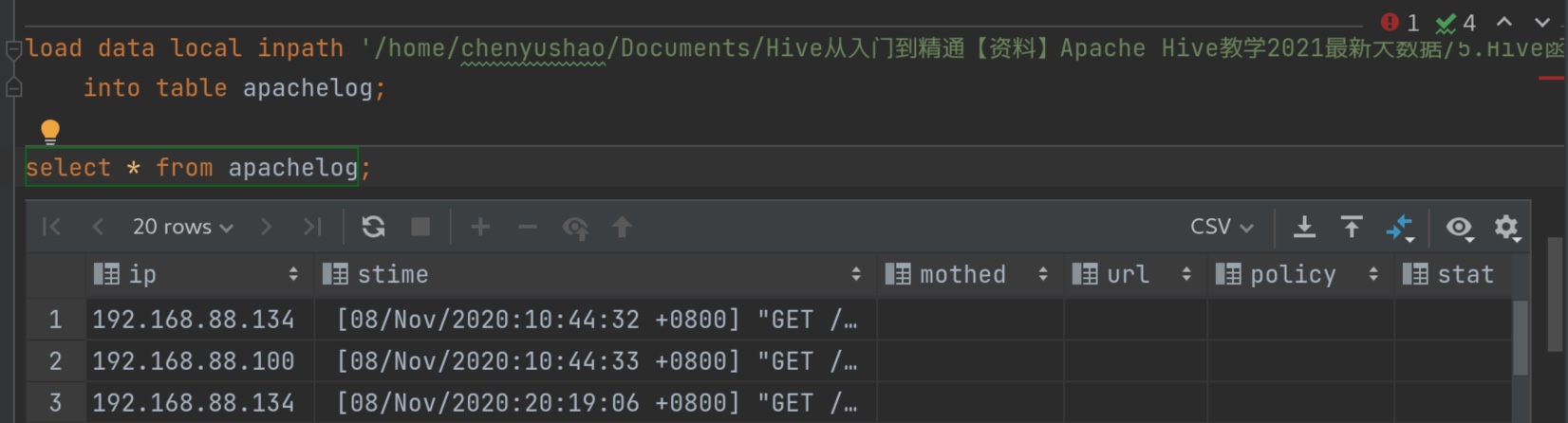
用正确的正则表达式:(注意:java的转义字符”\\“要两个,python一个\,hive是java写的,记得用java的转义字符写法。 )
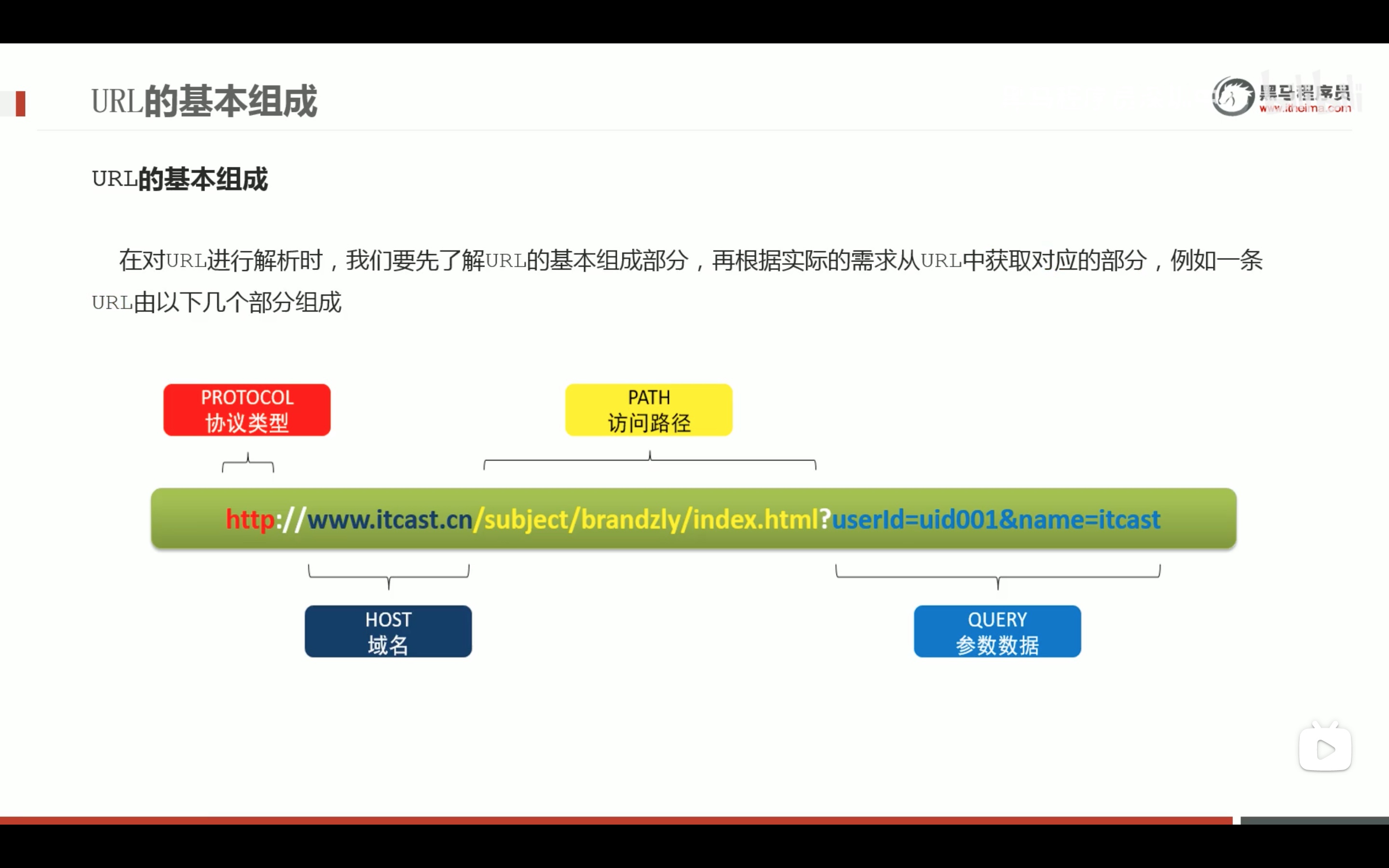
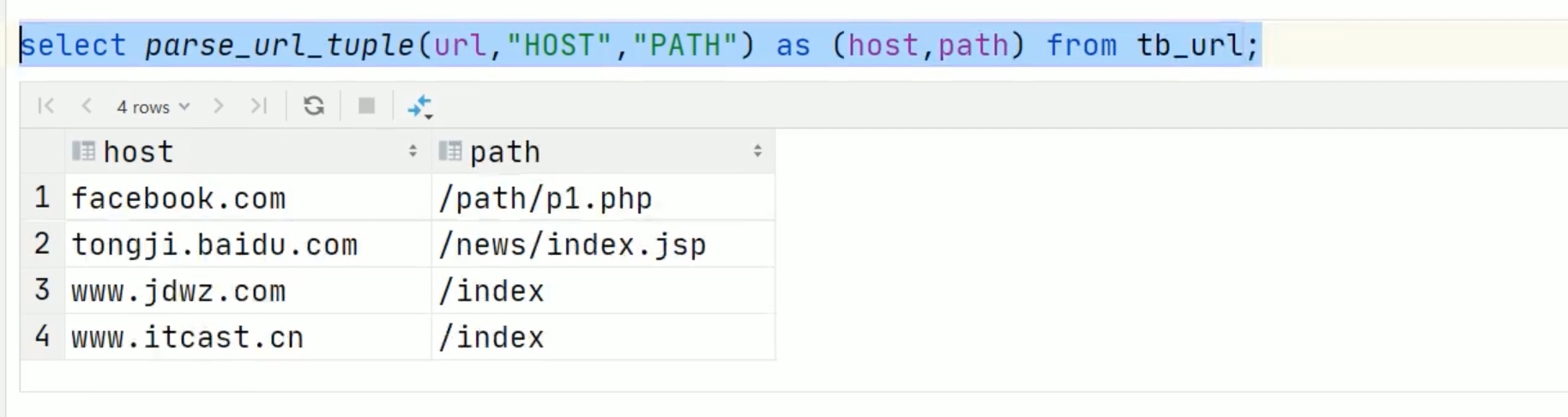
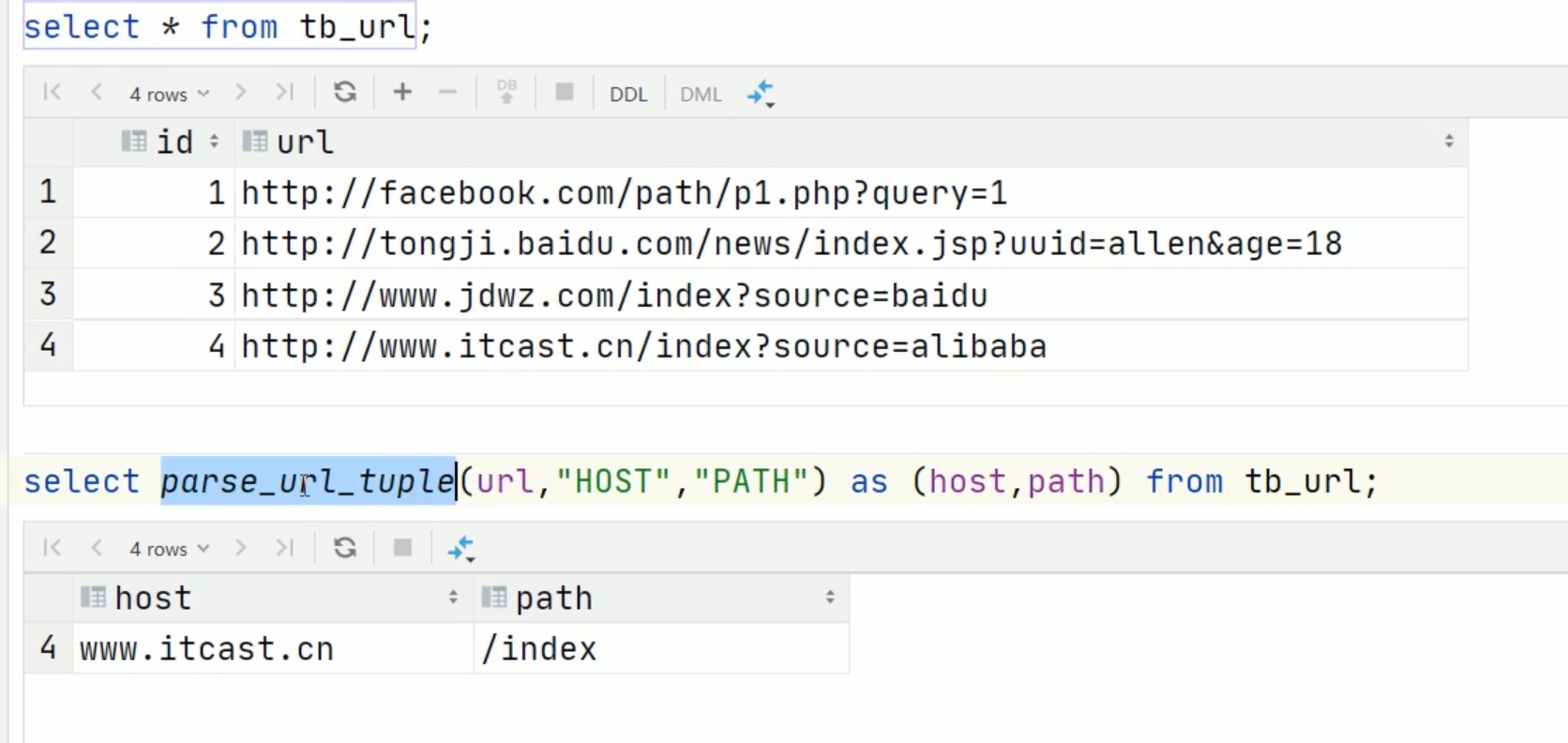
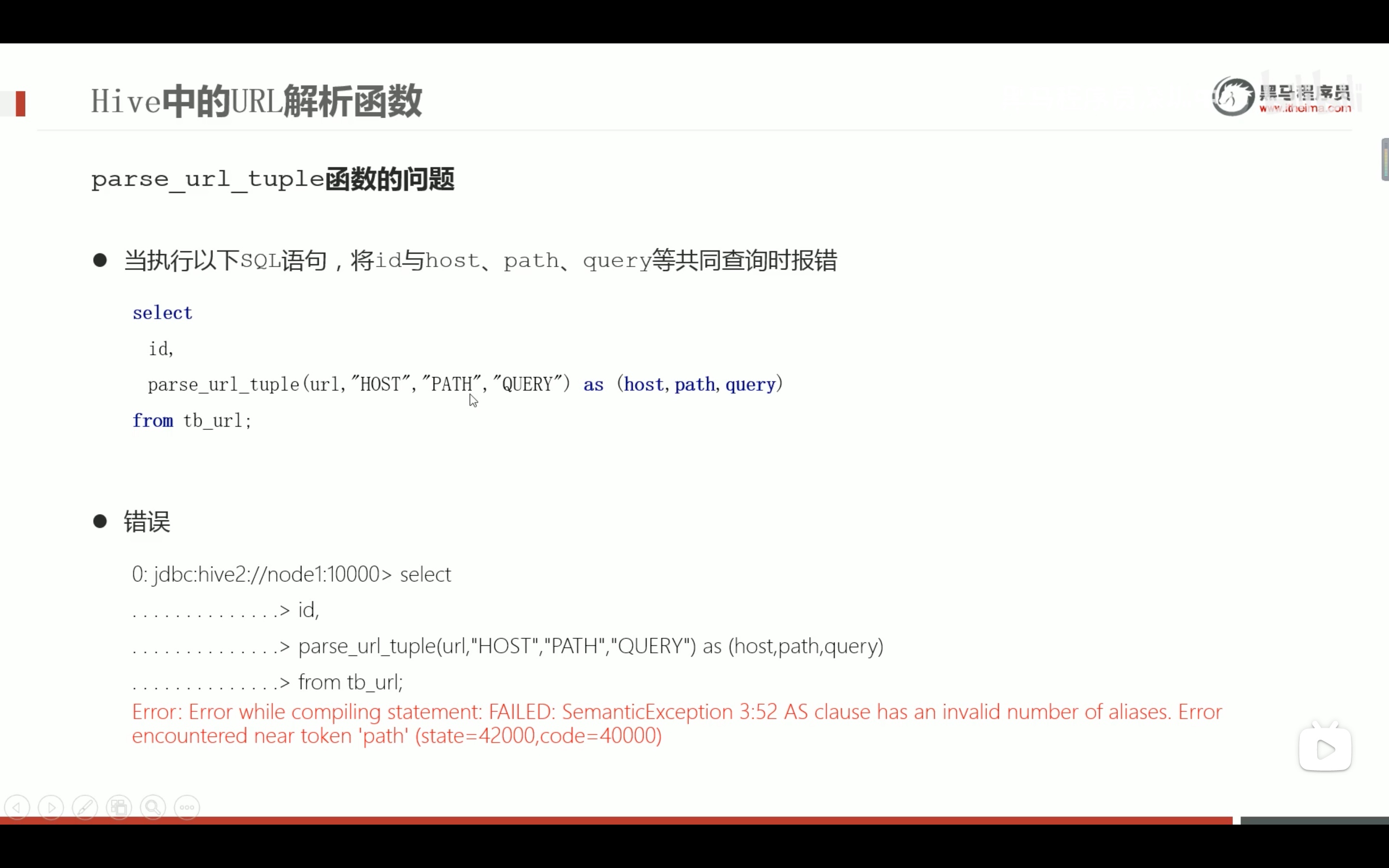
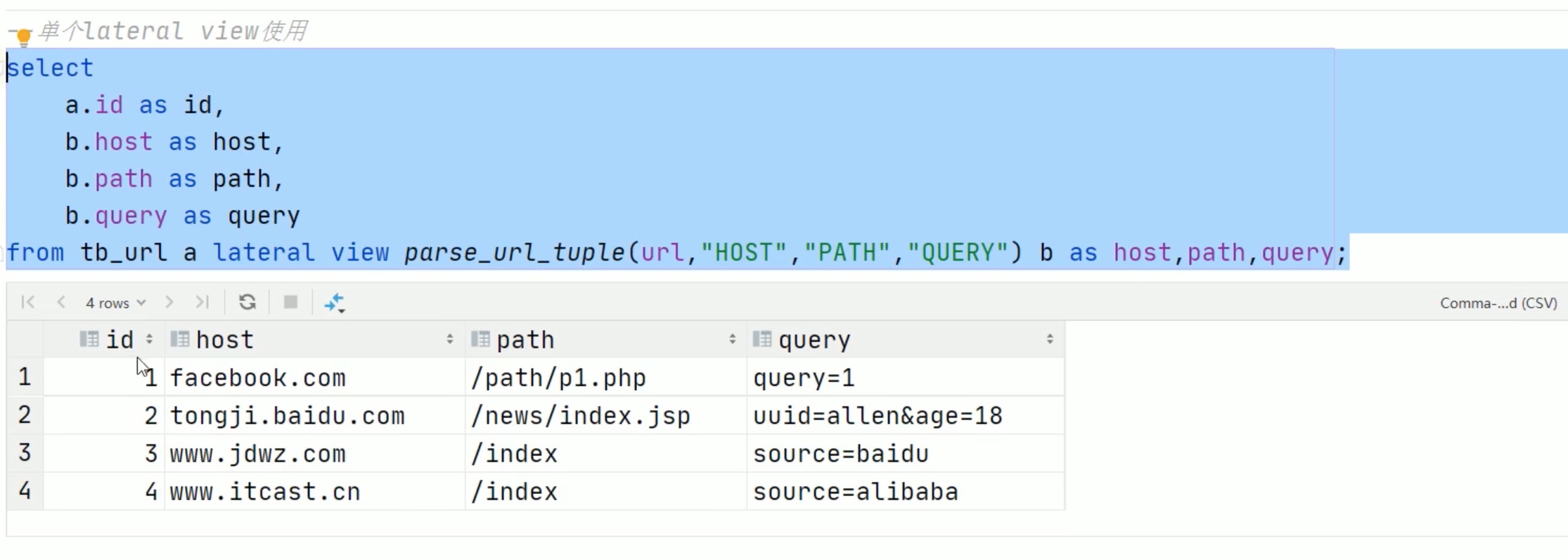
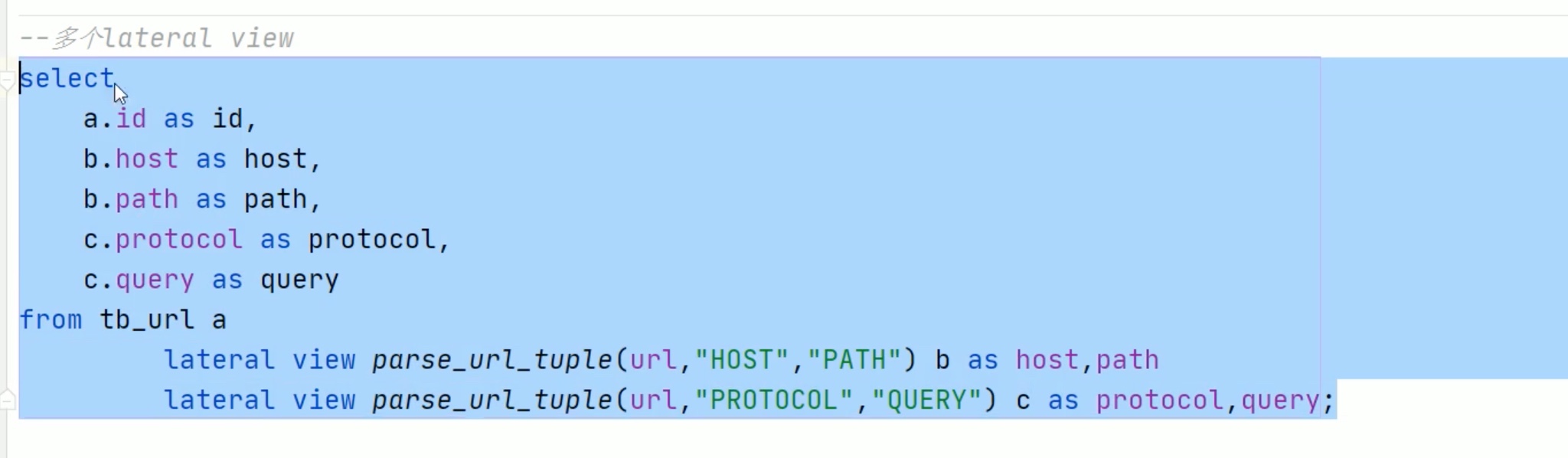
url专用解析函数
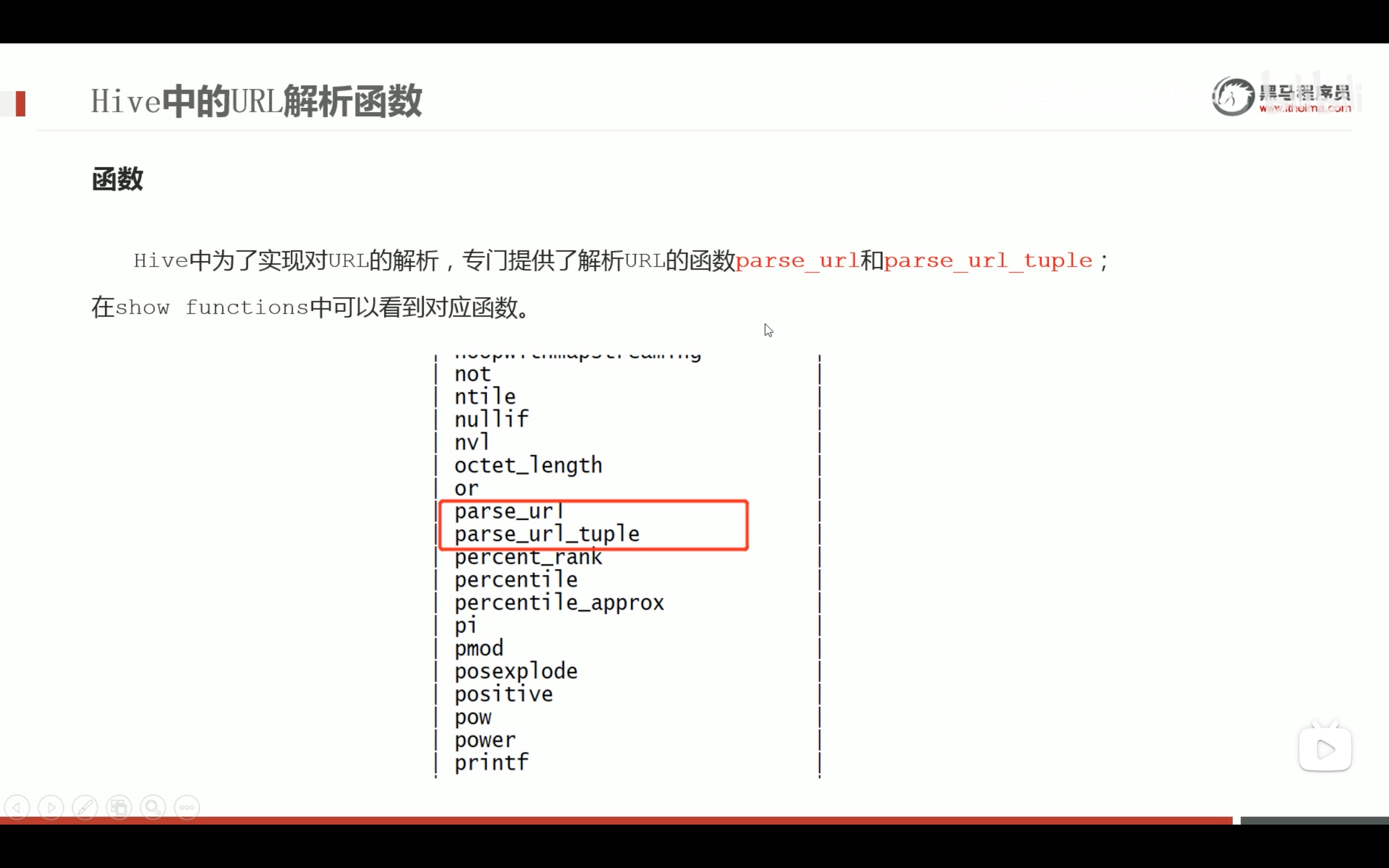
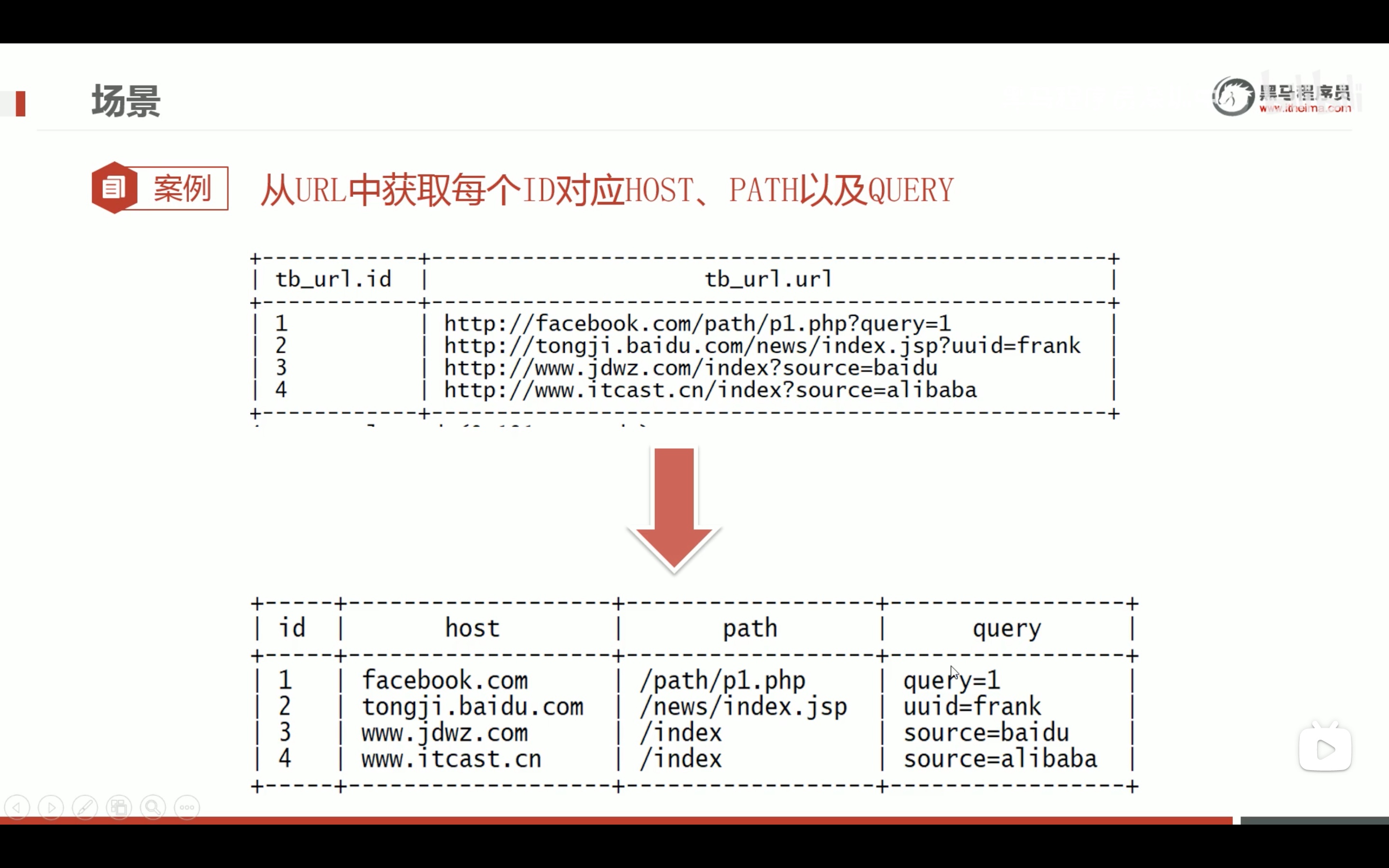
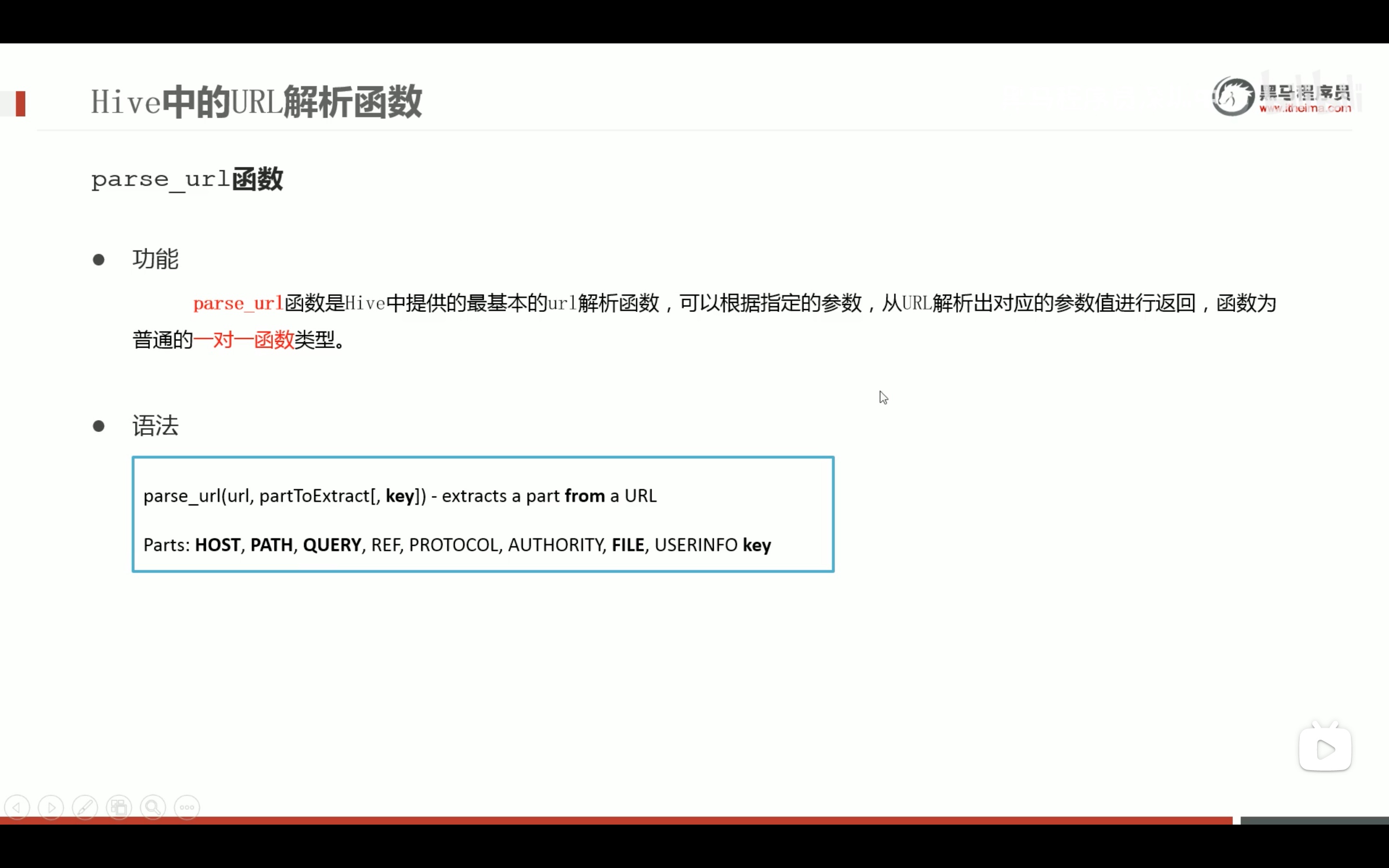
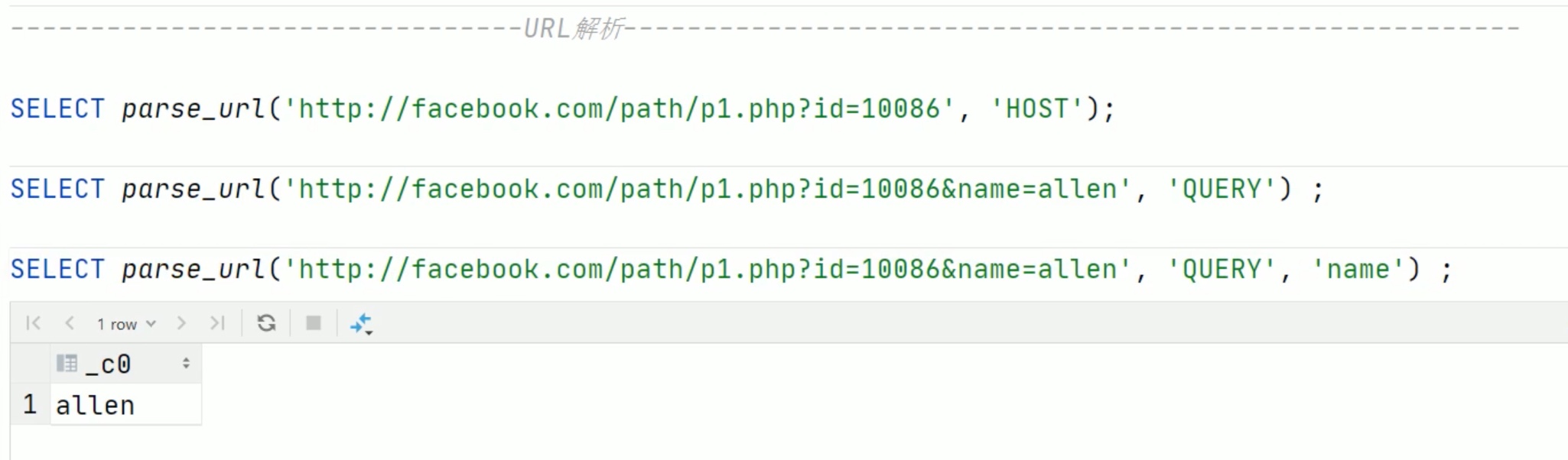

注意参数要大写,小写不识别。


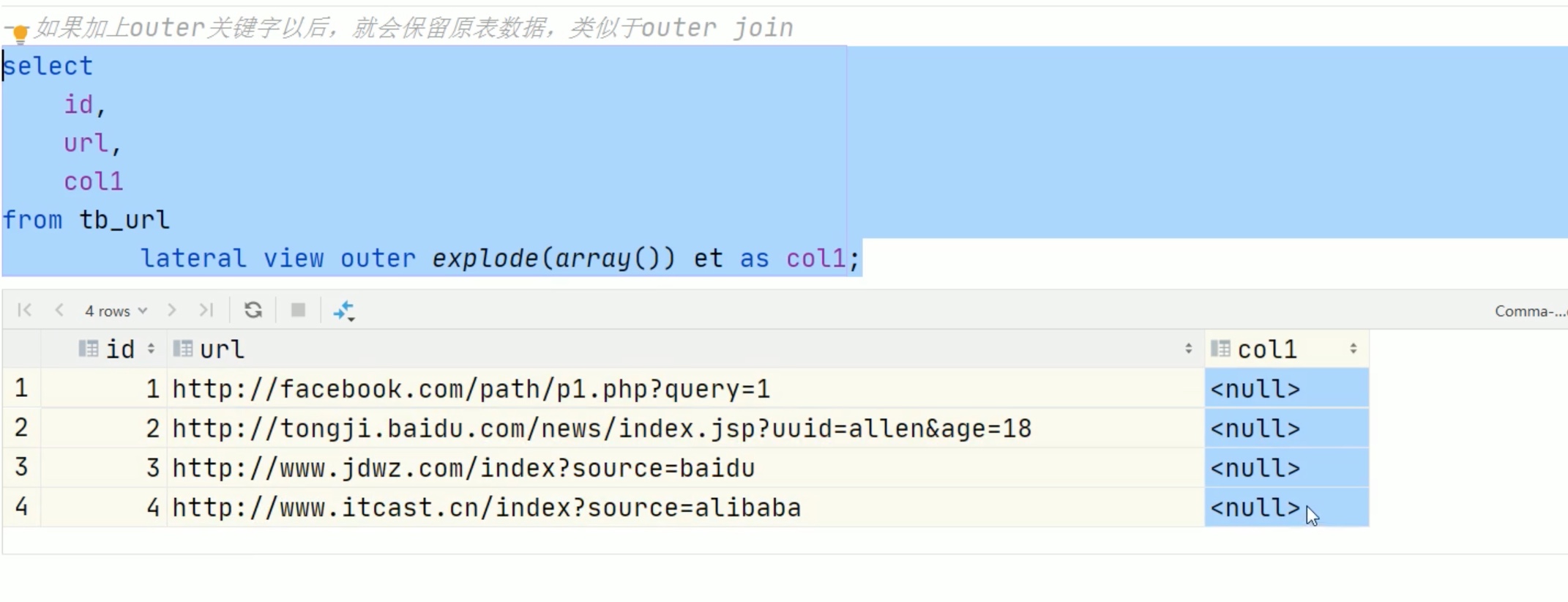
hive行列转换
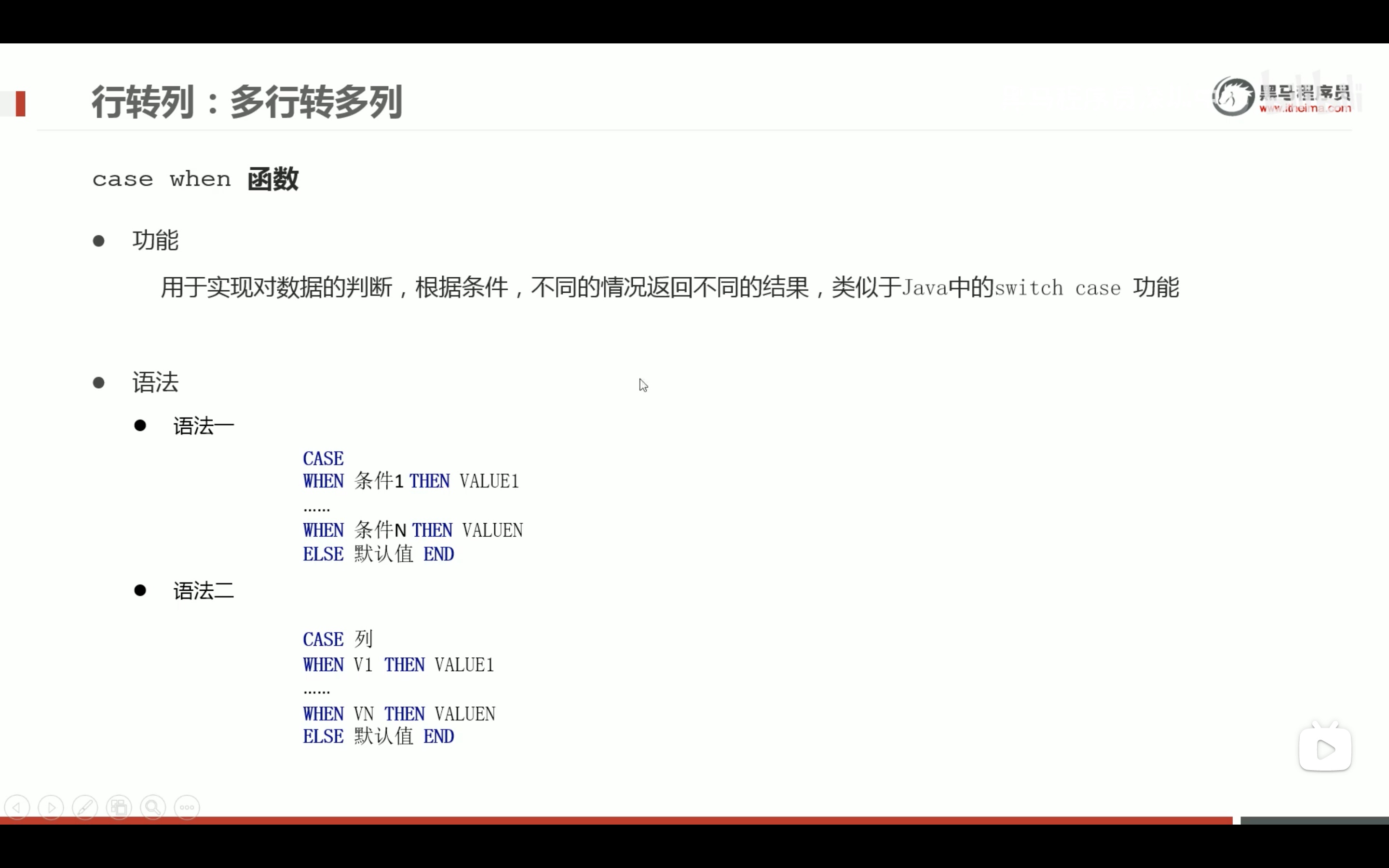
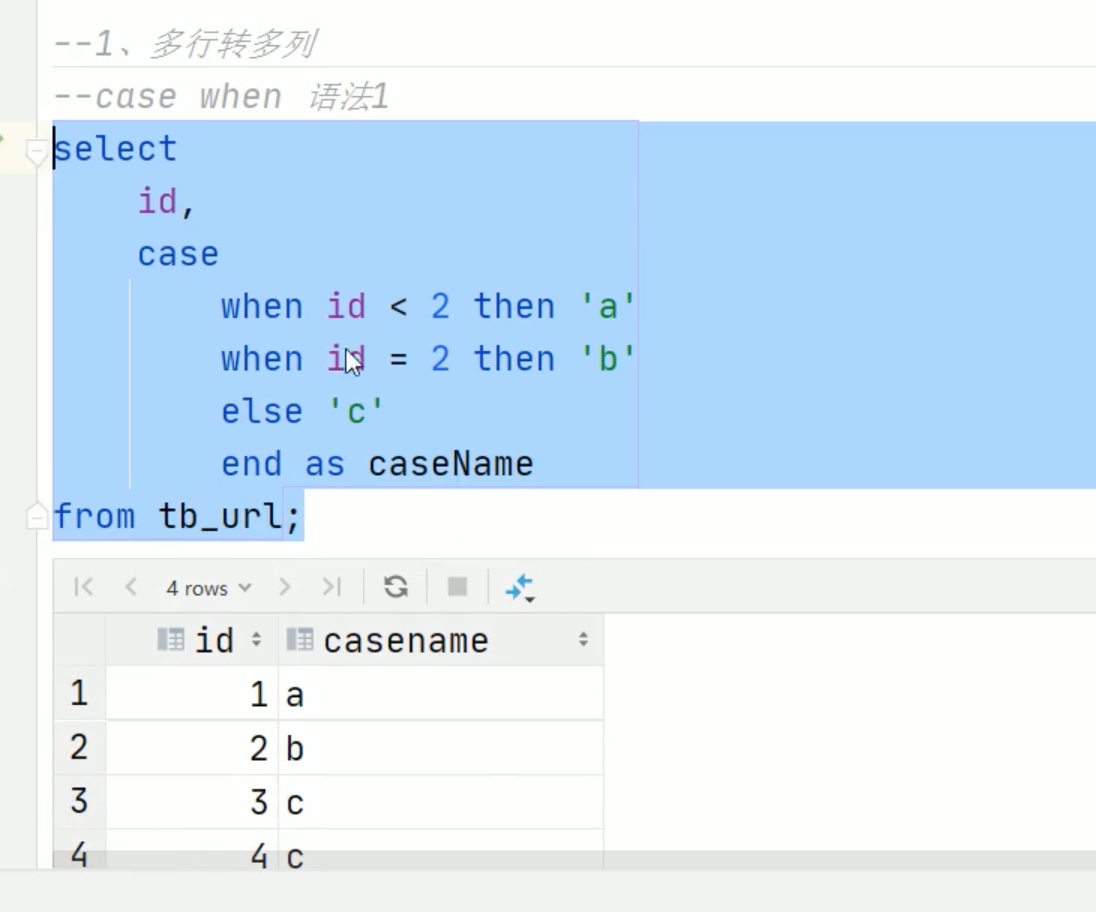
多行转多列


多行转单列

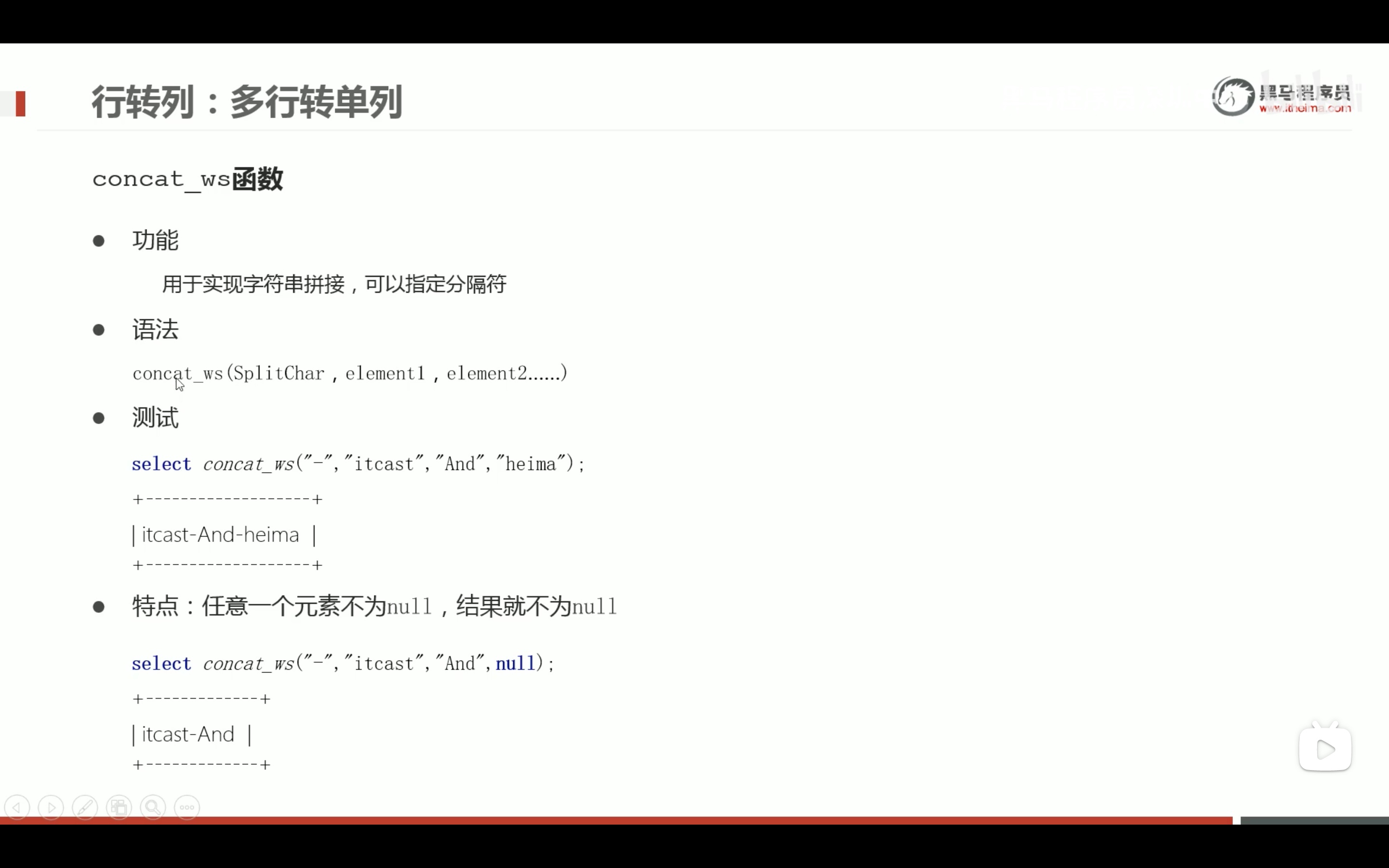
concat 拼接的元素有一个为null,拼接结果就是null,concat_ws拼接的元素有不为空的,结果就不会是空。
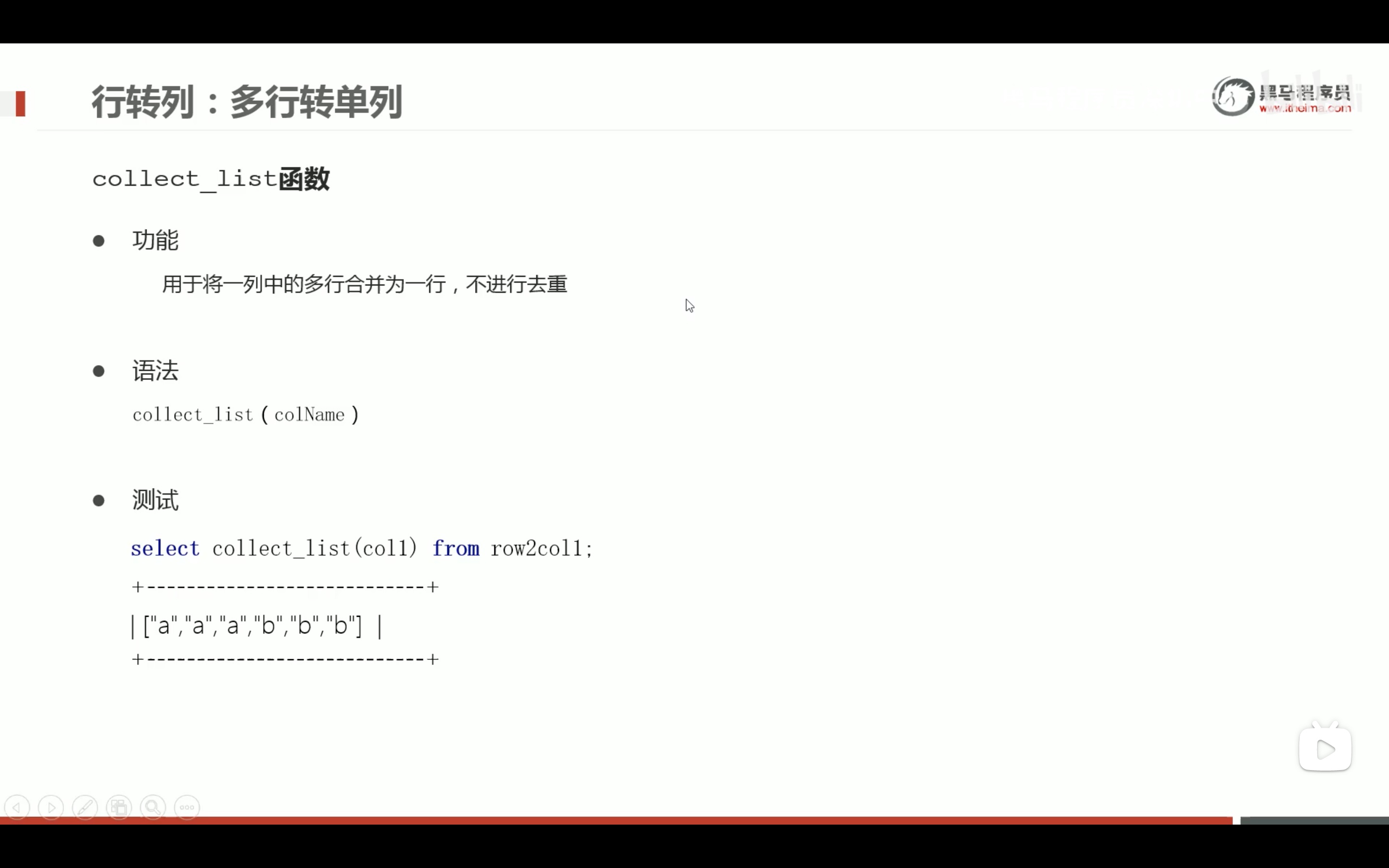
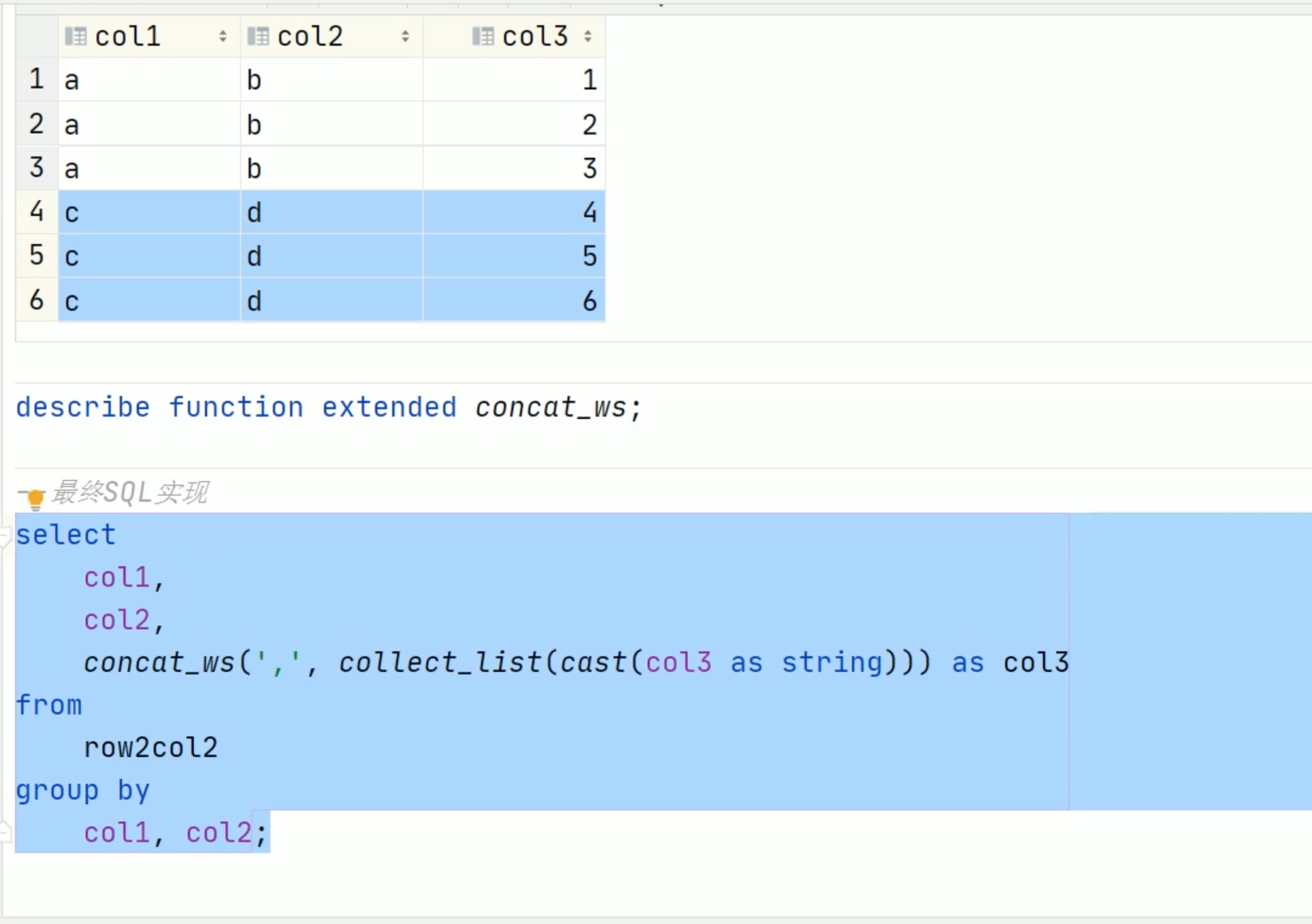
collect_list 收集元素保留元素类型,但是concat_ws 只能拼接string 类型,记得有时候要类型转换cast(a as string)。
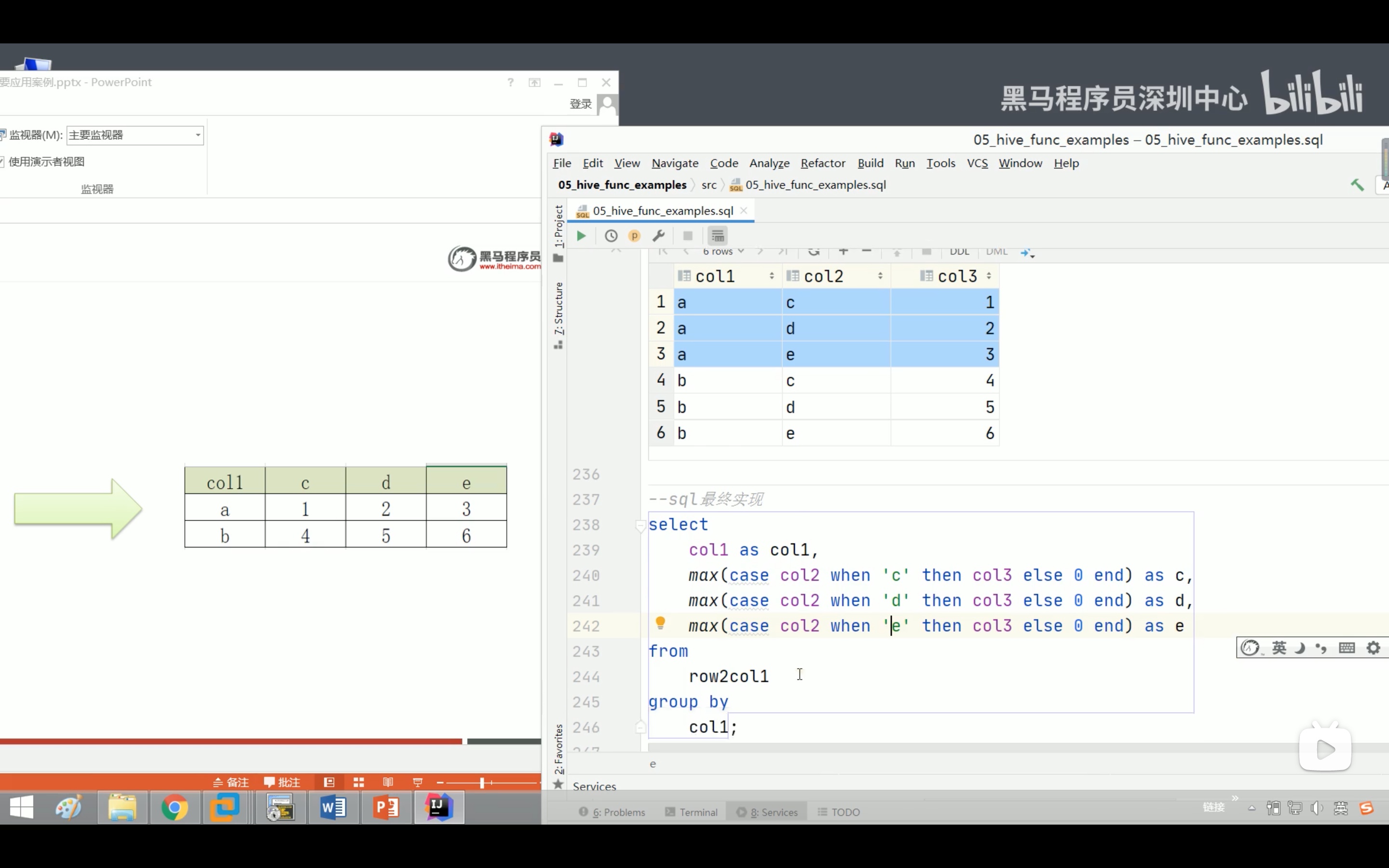
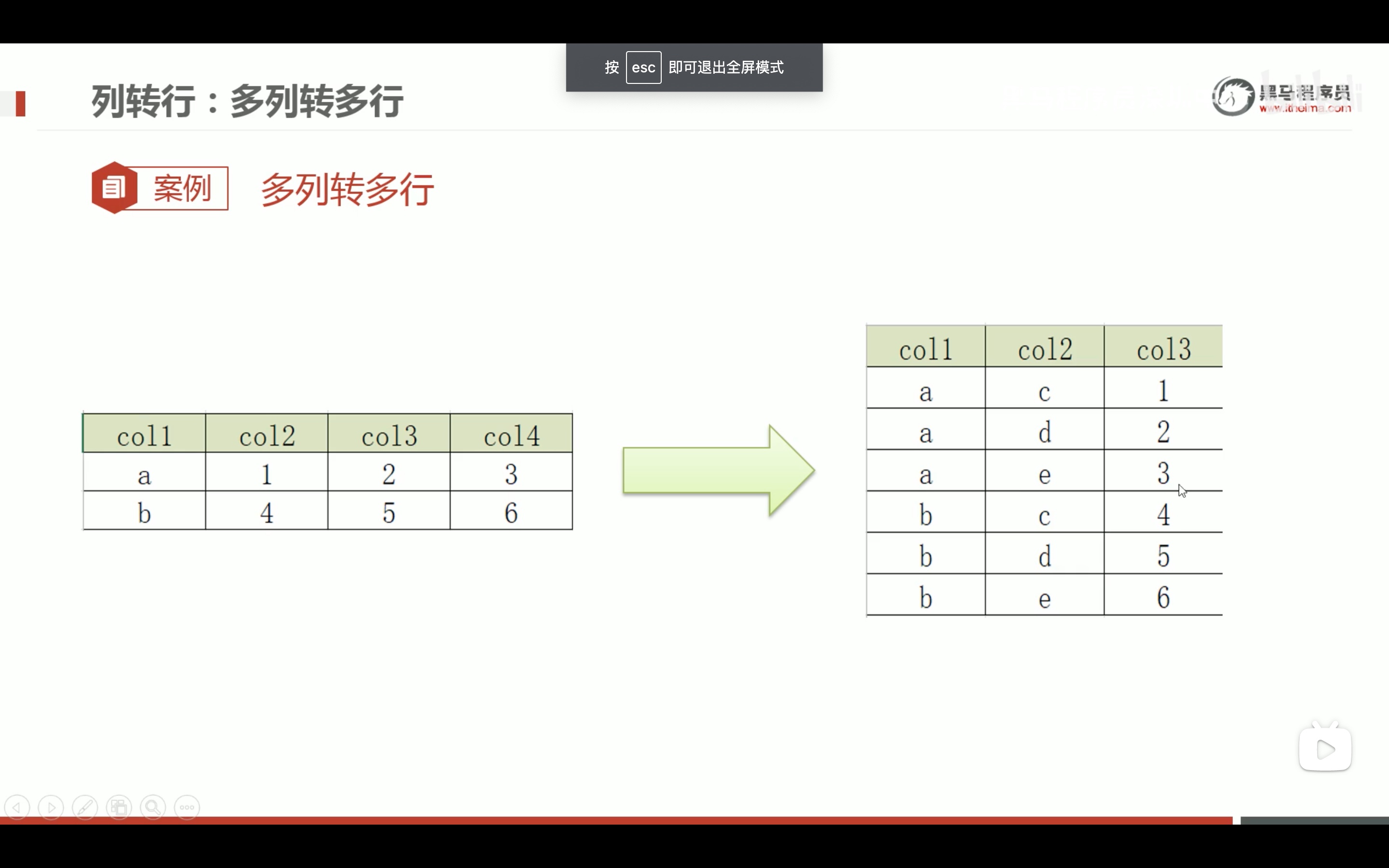
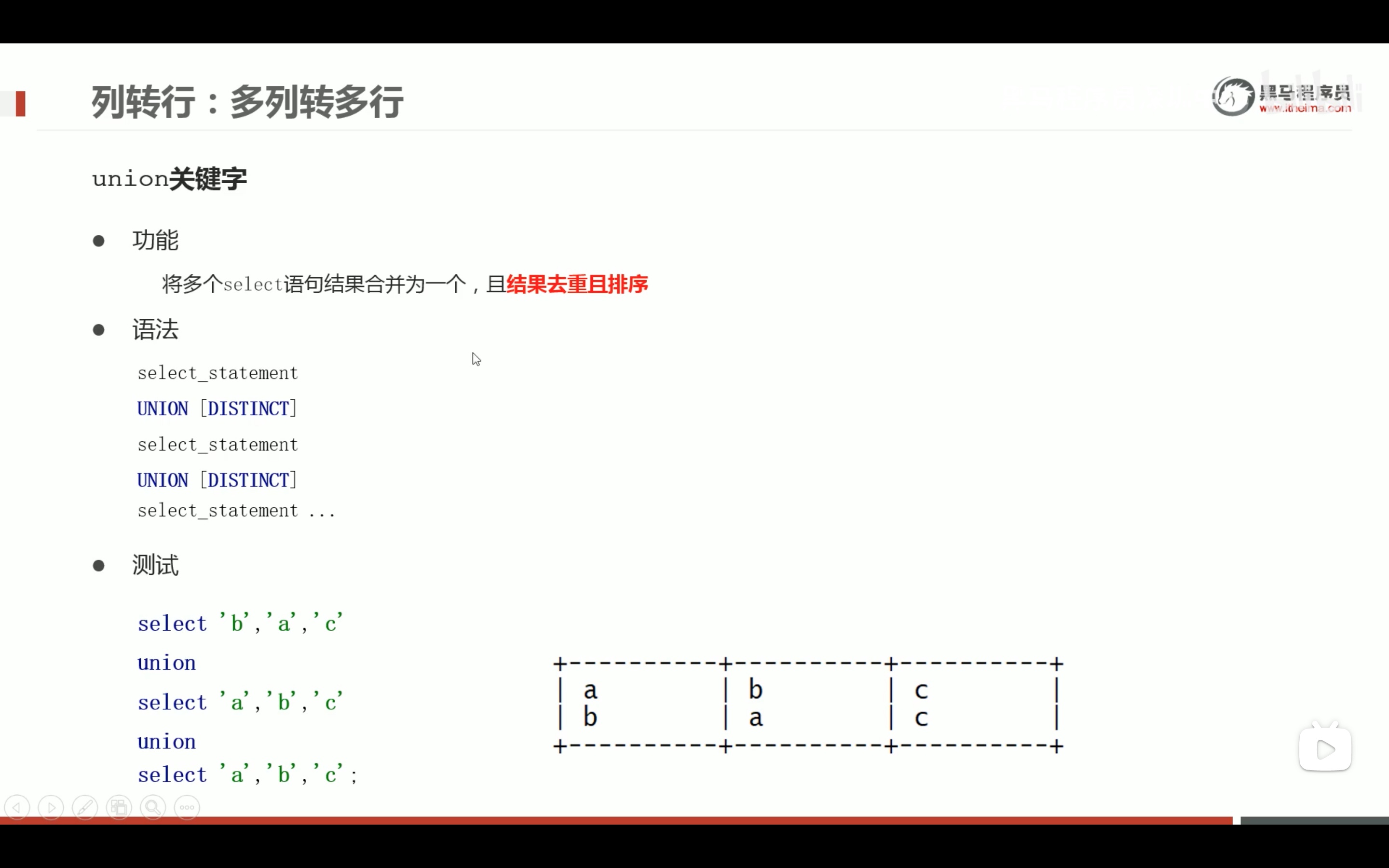
多列转多行
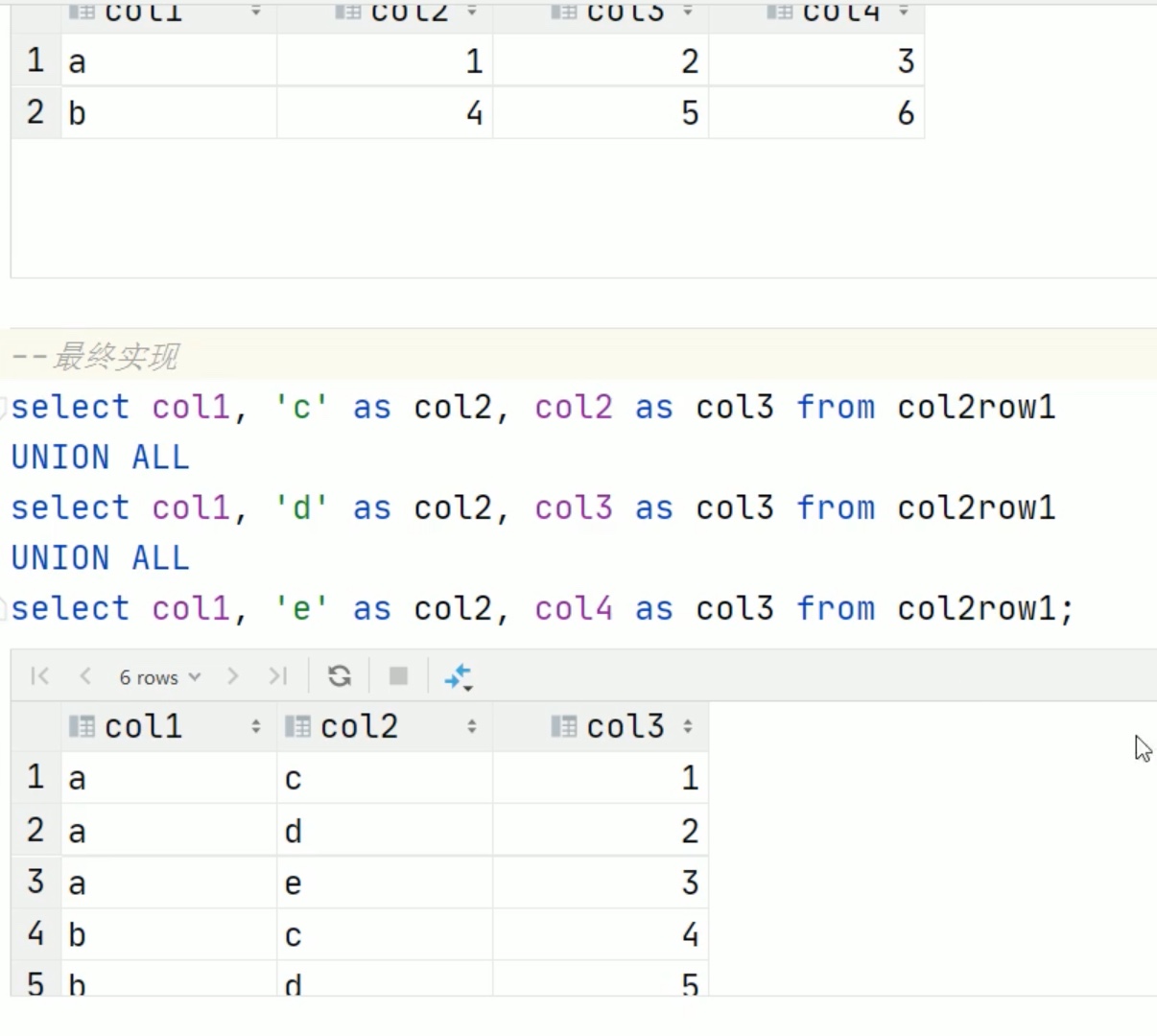
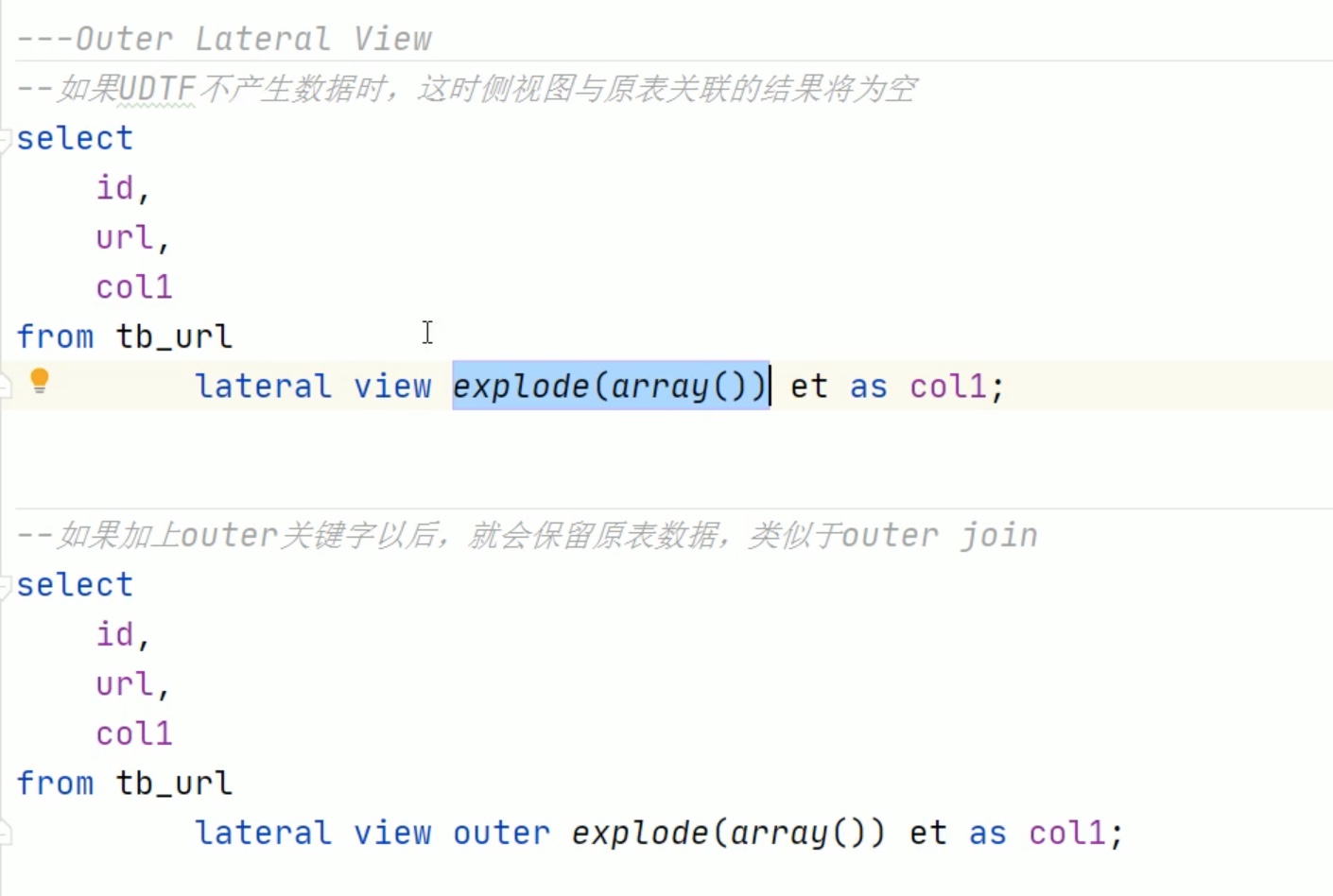
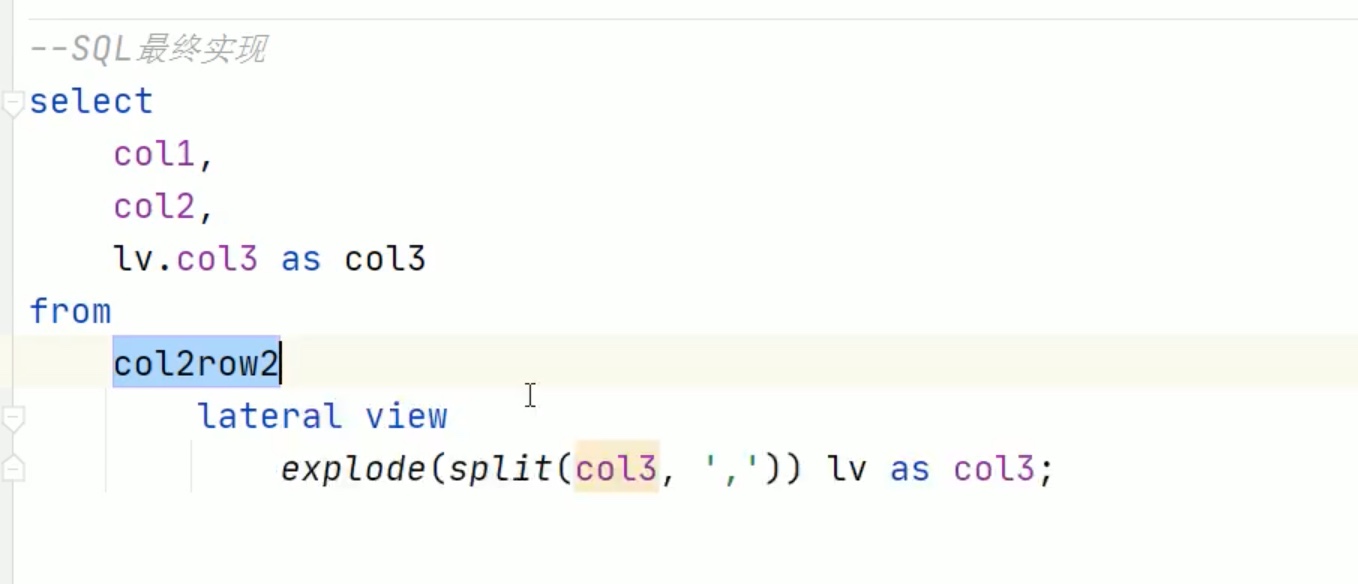
单列转多行(重要)

explode爆炸函数只接受array和map类型输入。

json格式处理




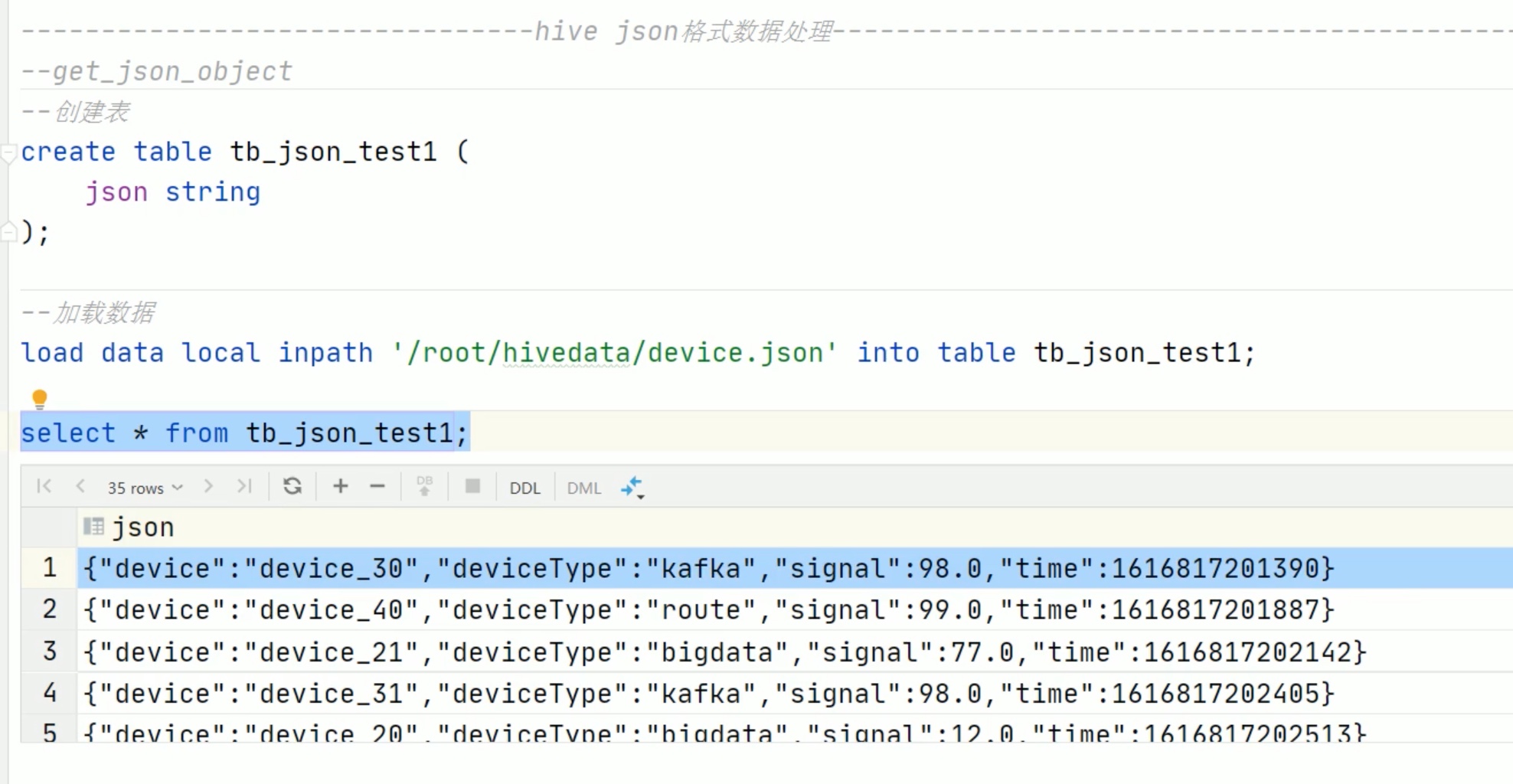


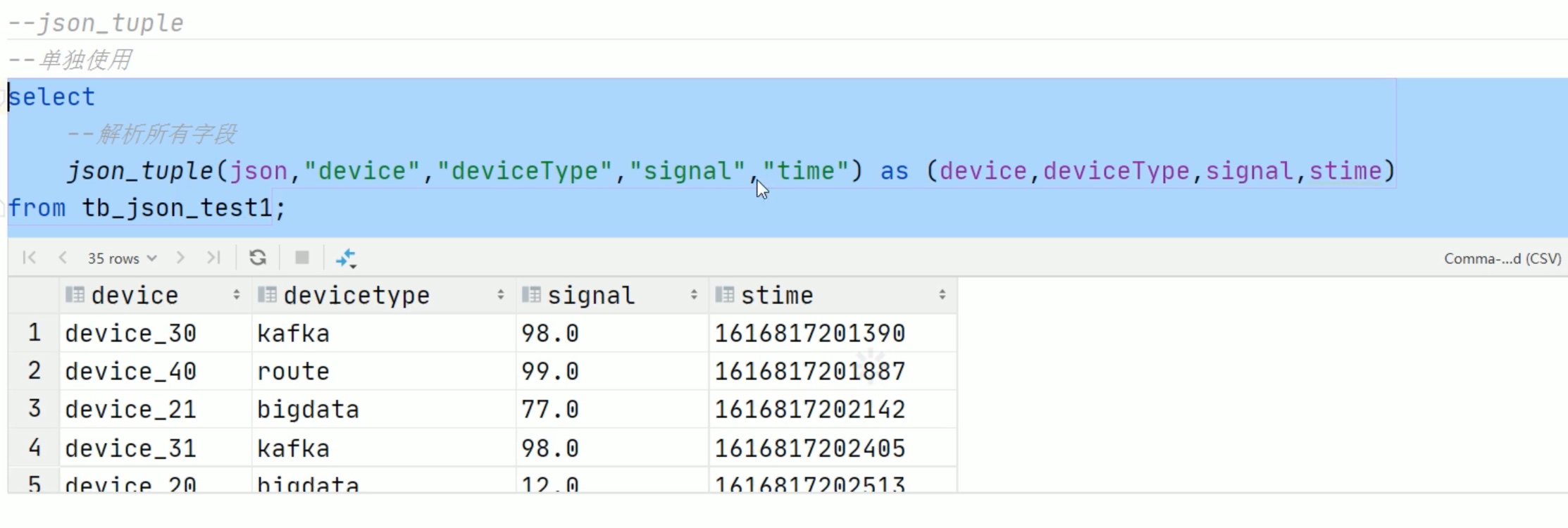
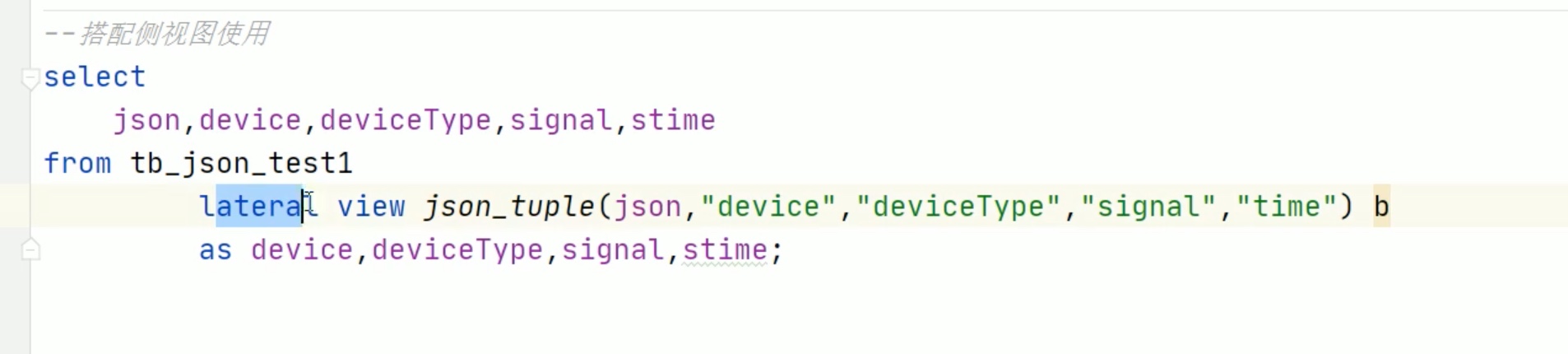

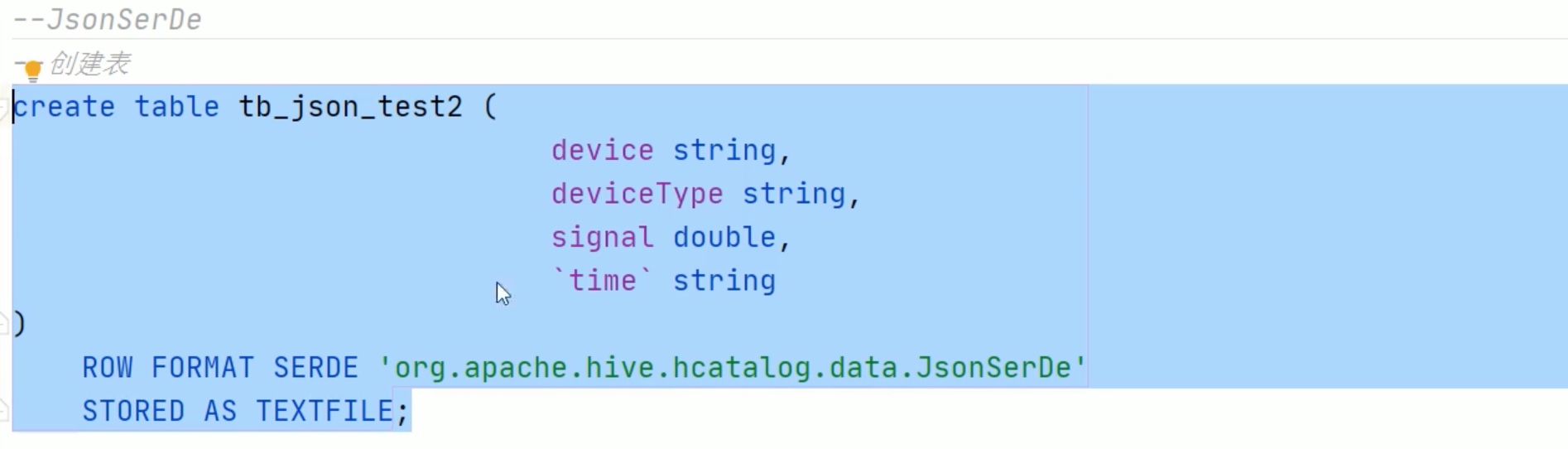
注意 time用了反引号 引起来了,不然会和 默认的 time 冲突。
连续登录统计

利用笛卡尔积,把所有的可能性都列出来,再筛选。
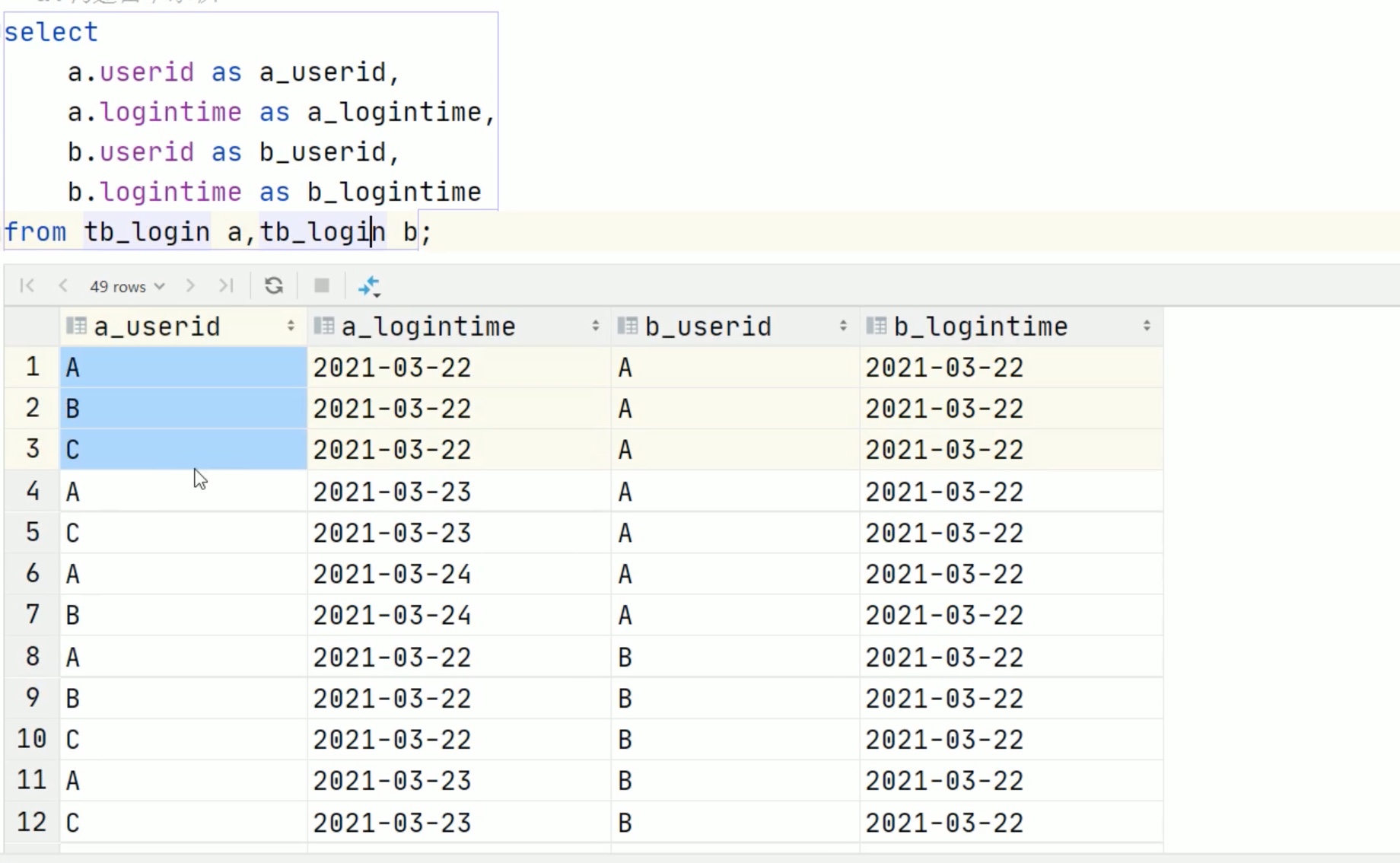

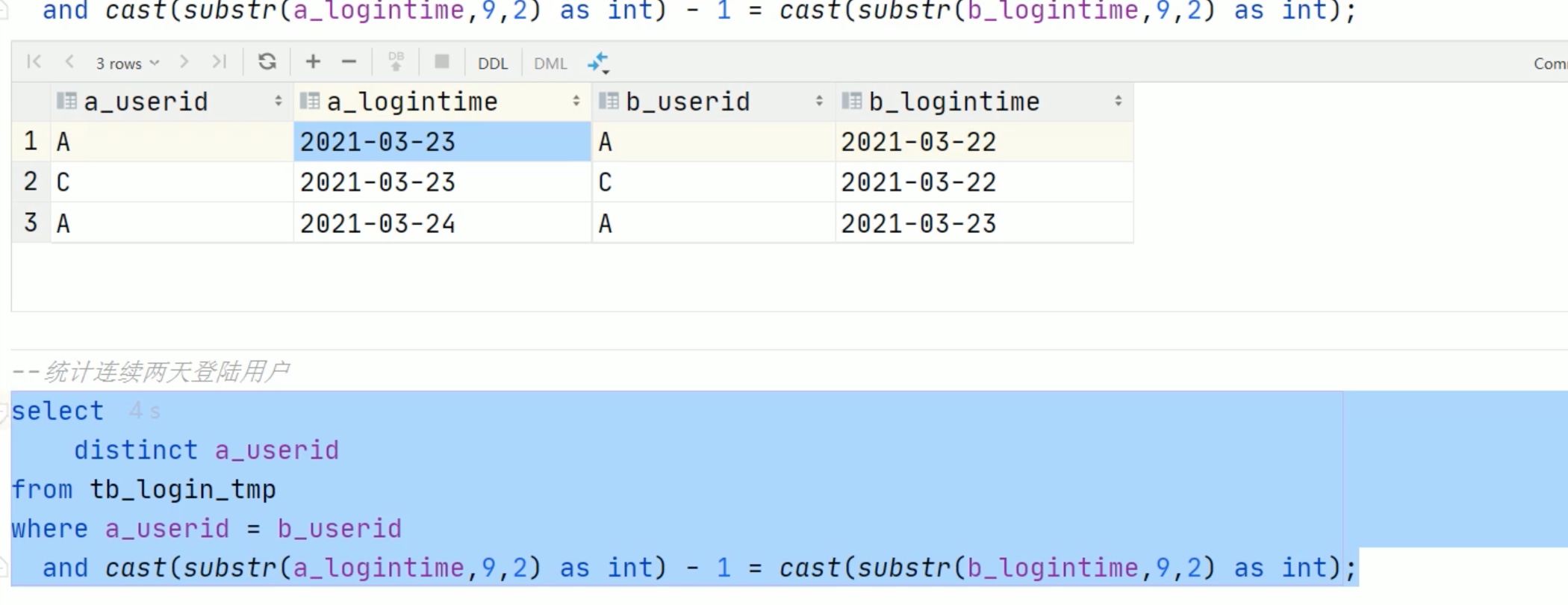

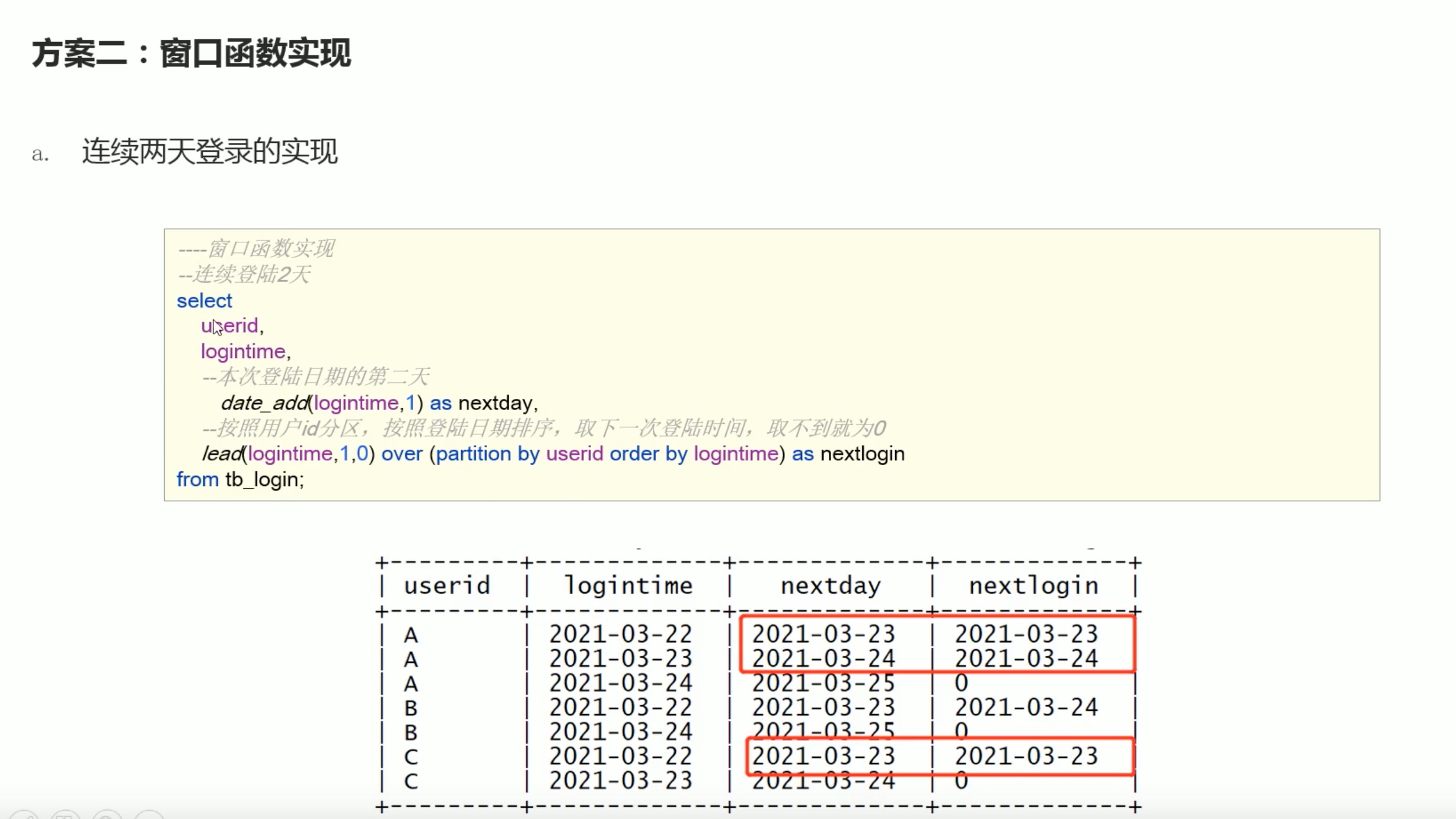
比较 下一次登录的日期 和 明天的日期,两者相等就是连续登录。
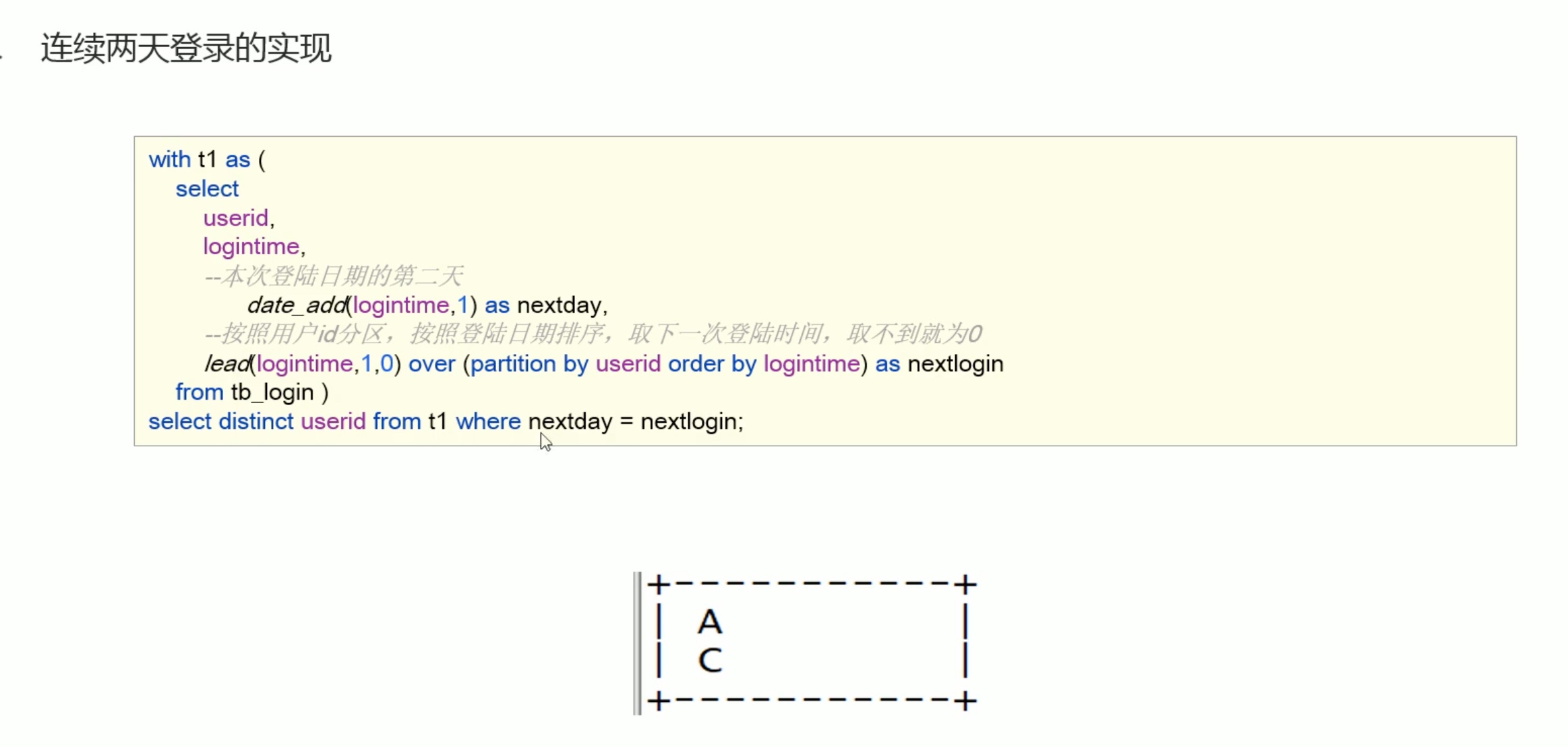
注意:
1 | select |
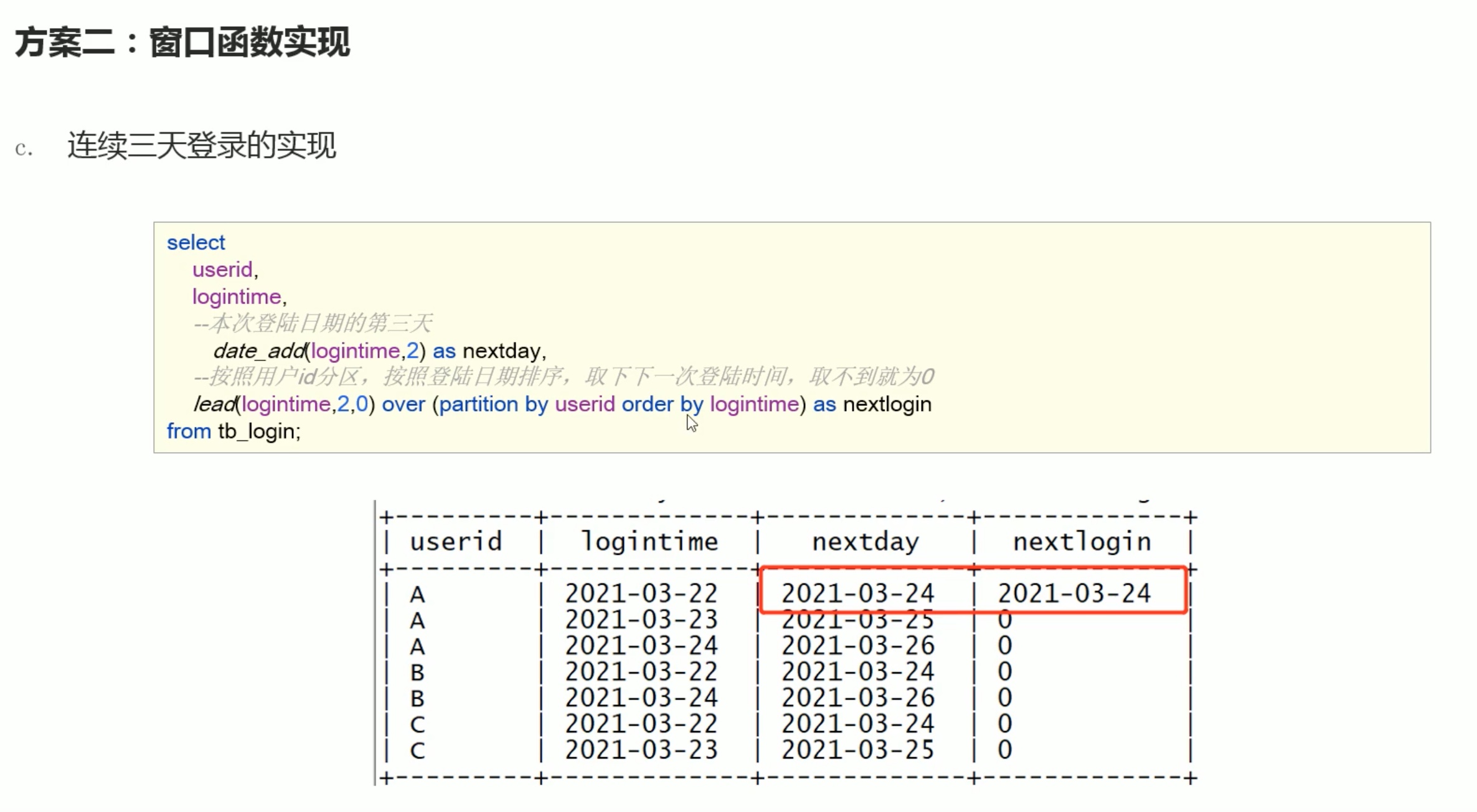
同样的道理,如果往后推3天,正好是登录的第3天,说明这三天一定是连续登录的 。
连续n 天登录用窗口函数over实现,有共性,比前面的方法要好,前提是要分好组排好序。
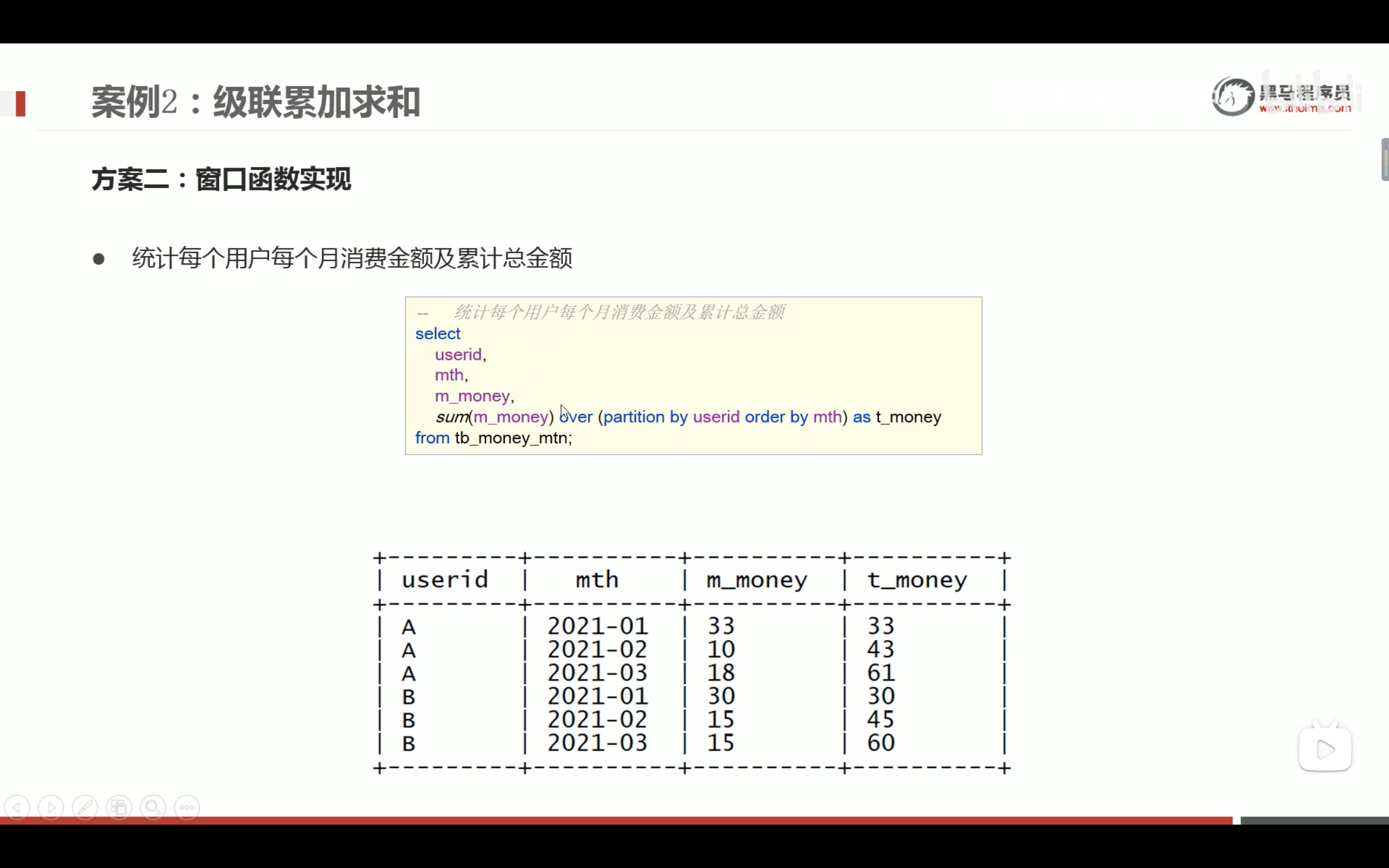
级连累加求和
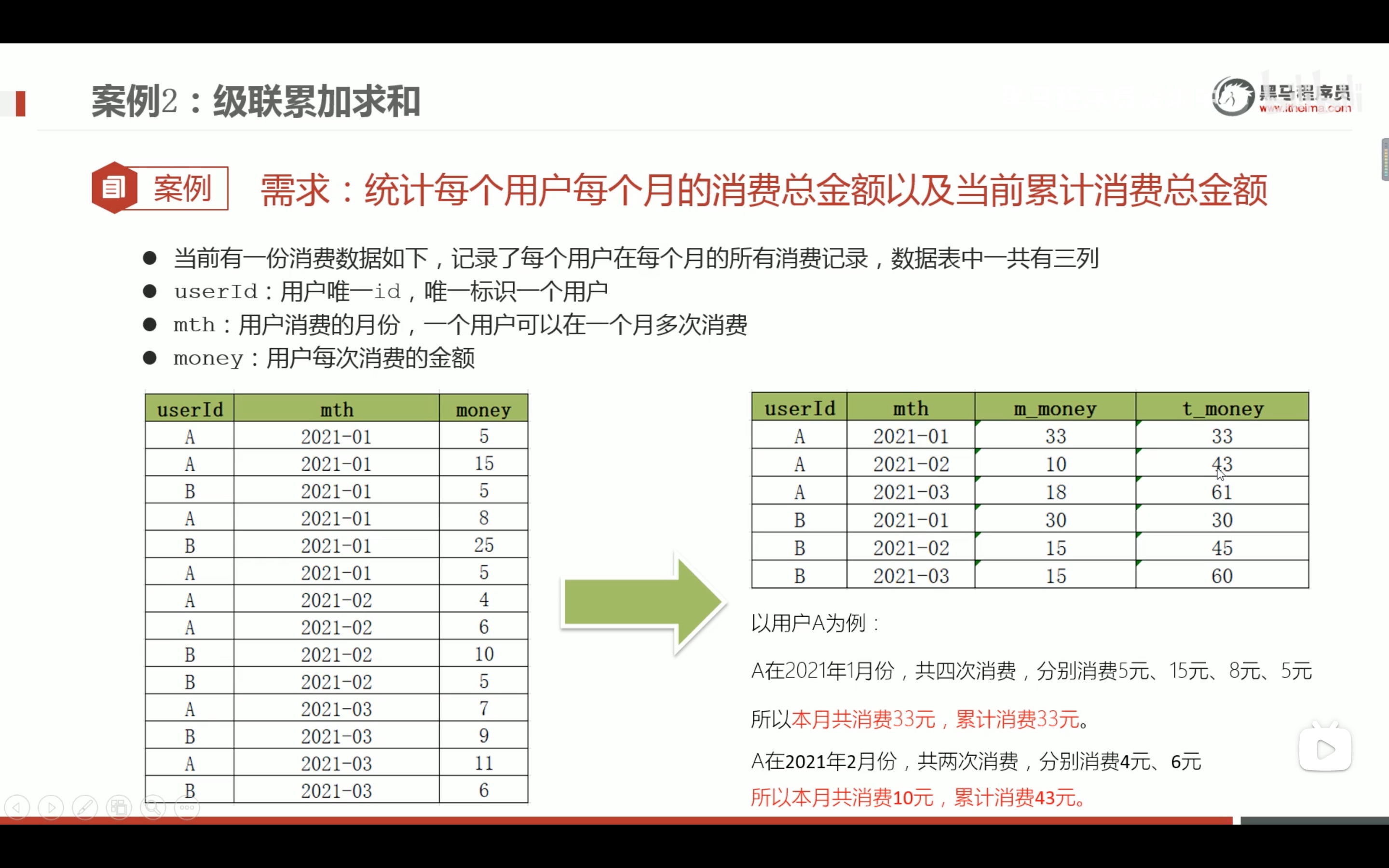
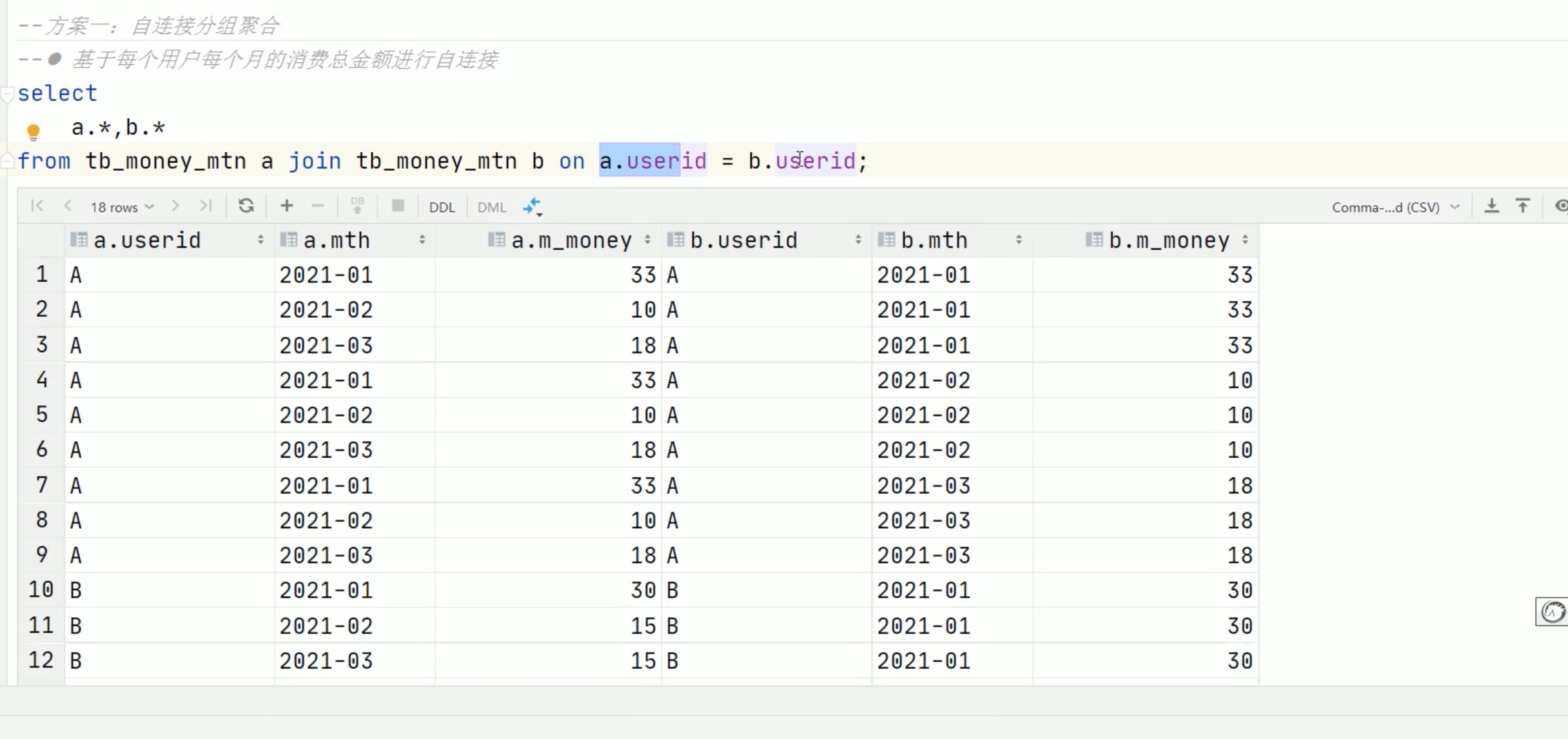
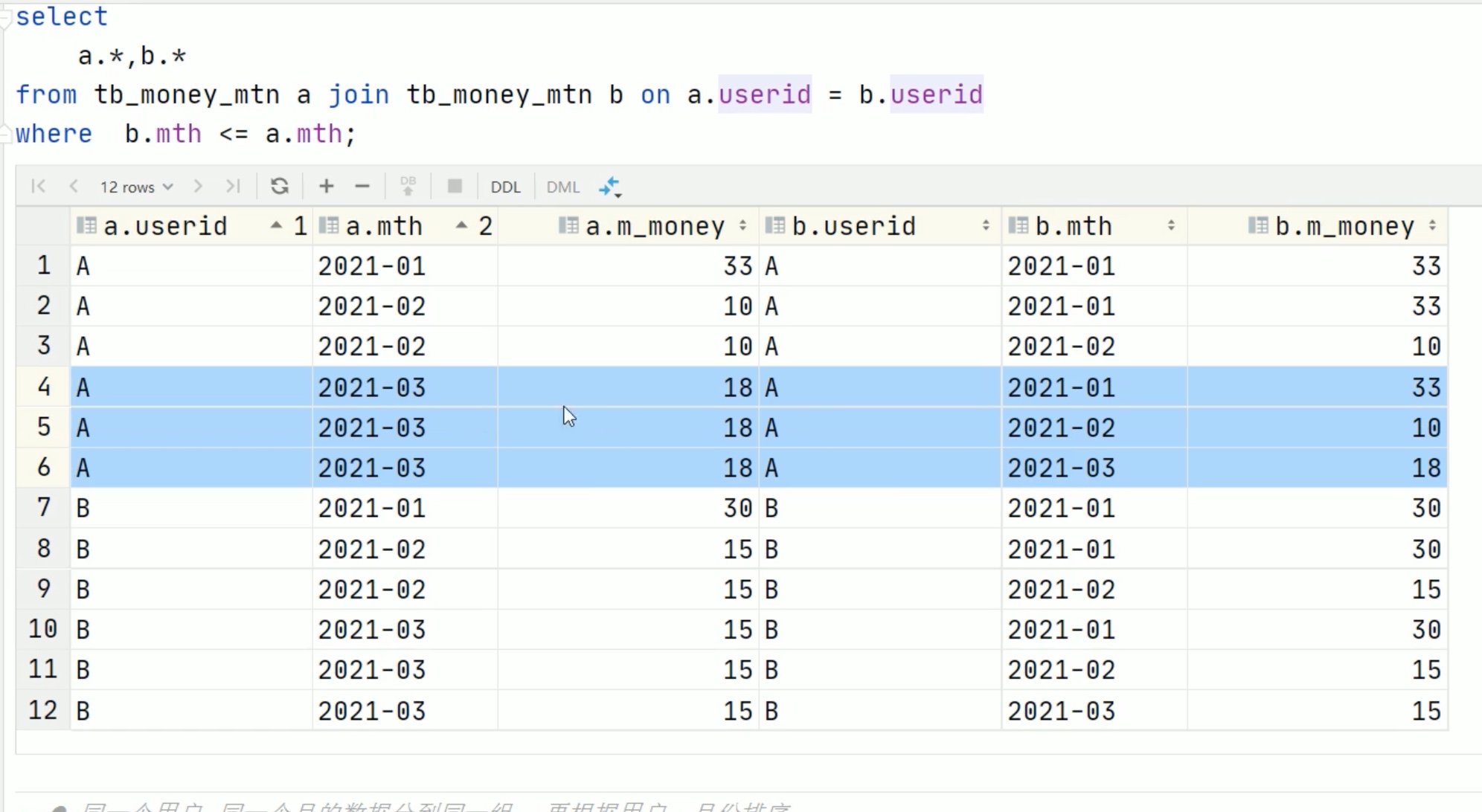
先自己对自己做cross join 笛卡尔积,但是要用on去限定笛卡尔积的范围,那就是a.userid=b.userid 的部分,用A 和 A 、B 和 B做笛卡尔积。
1 | 注意: |
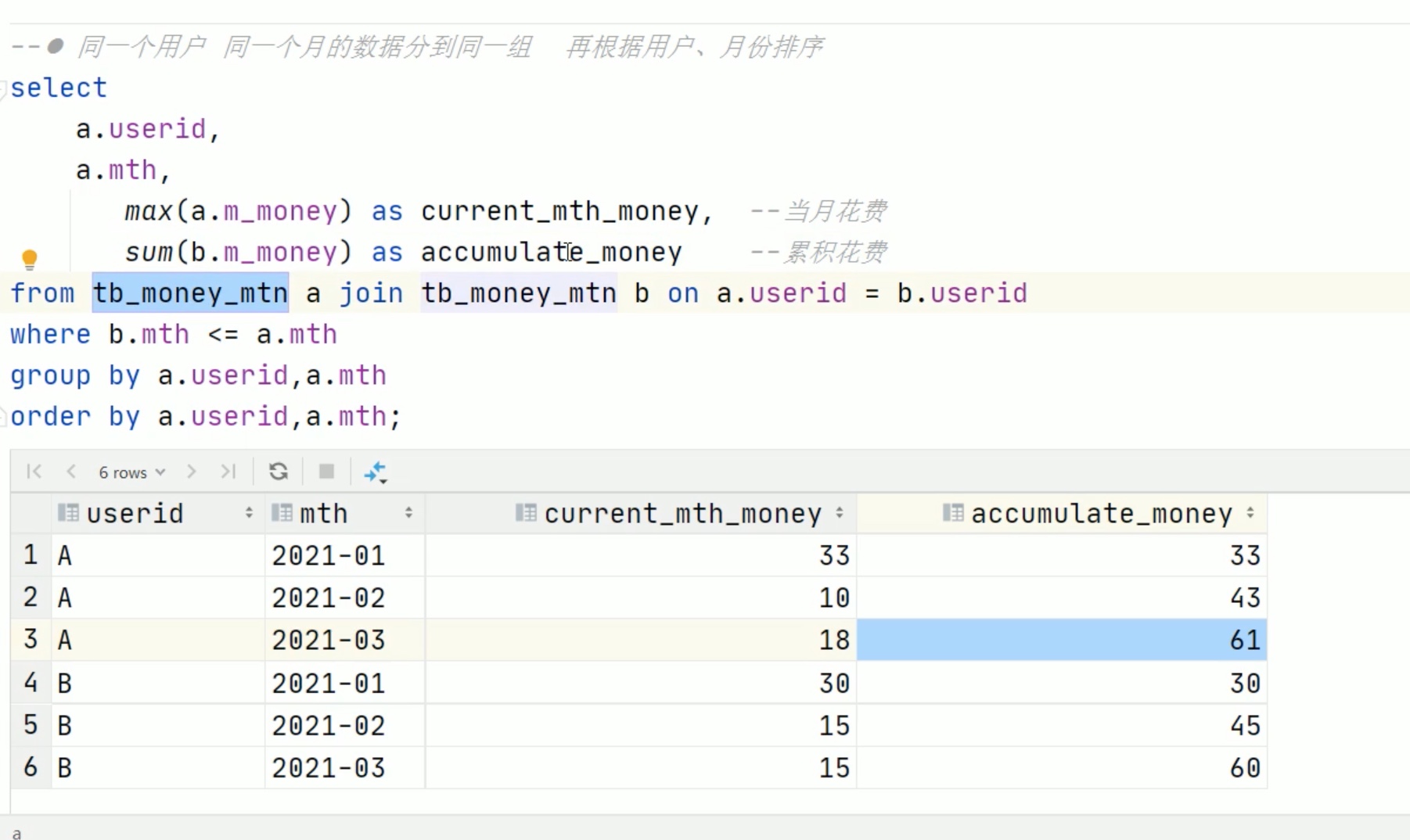

窗口函数over里面有order by 外面的sum 就自动是累积排序的了。

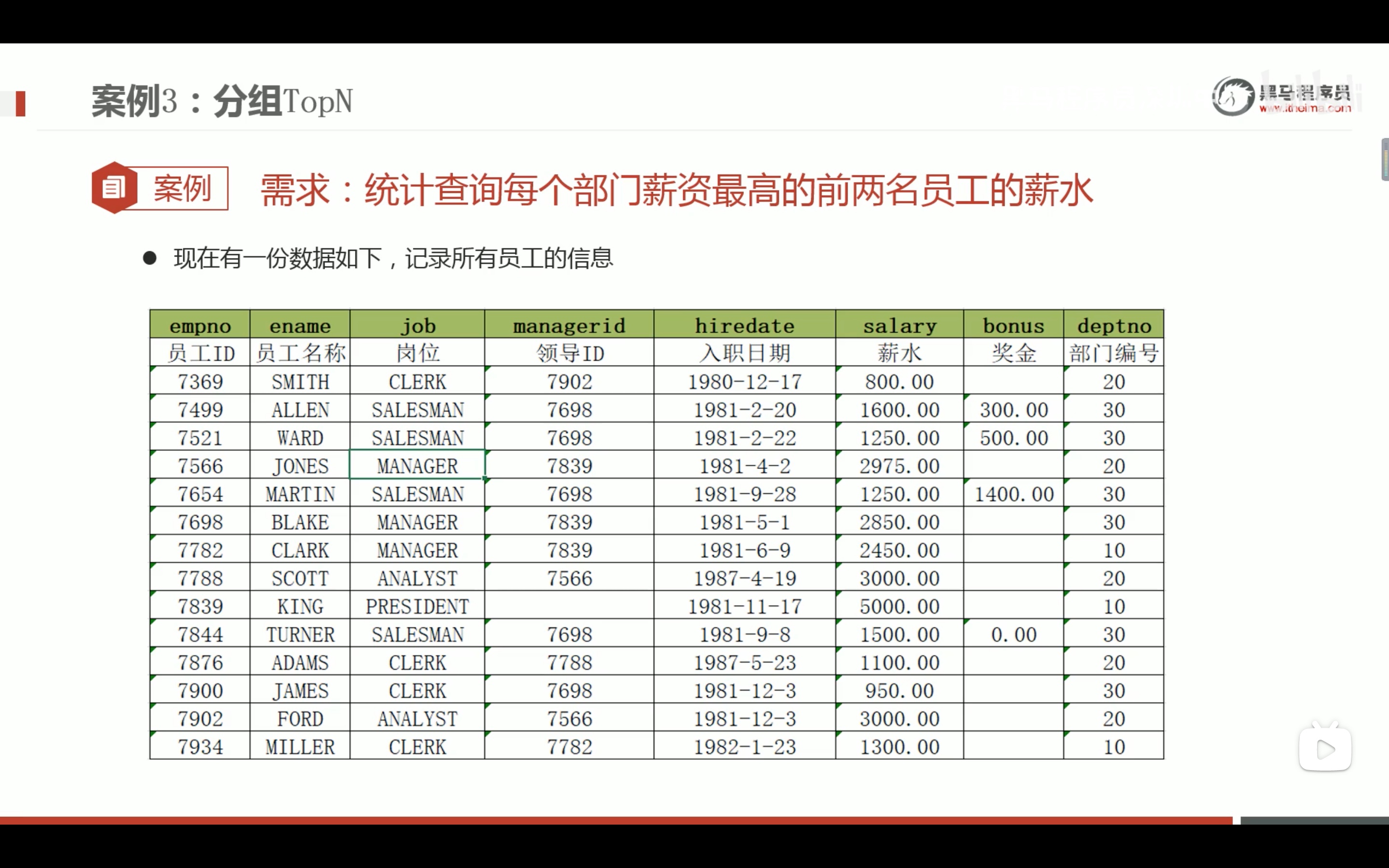
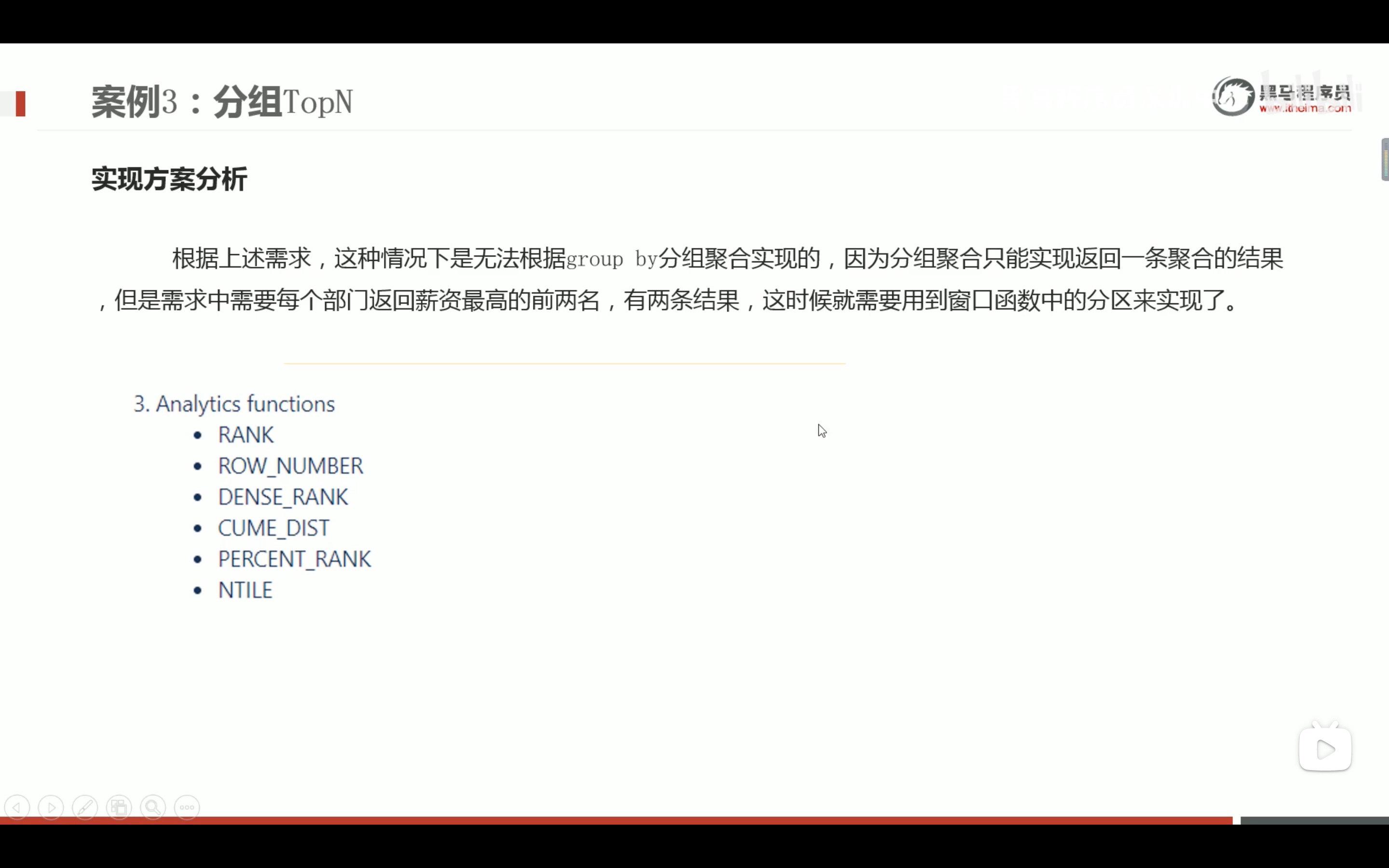
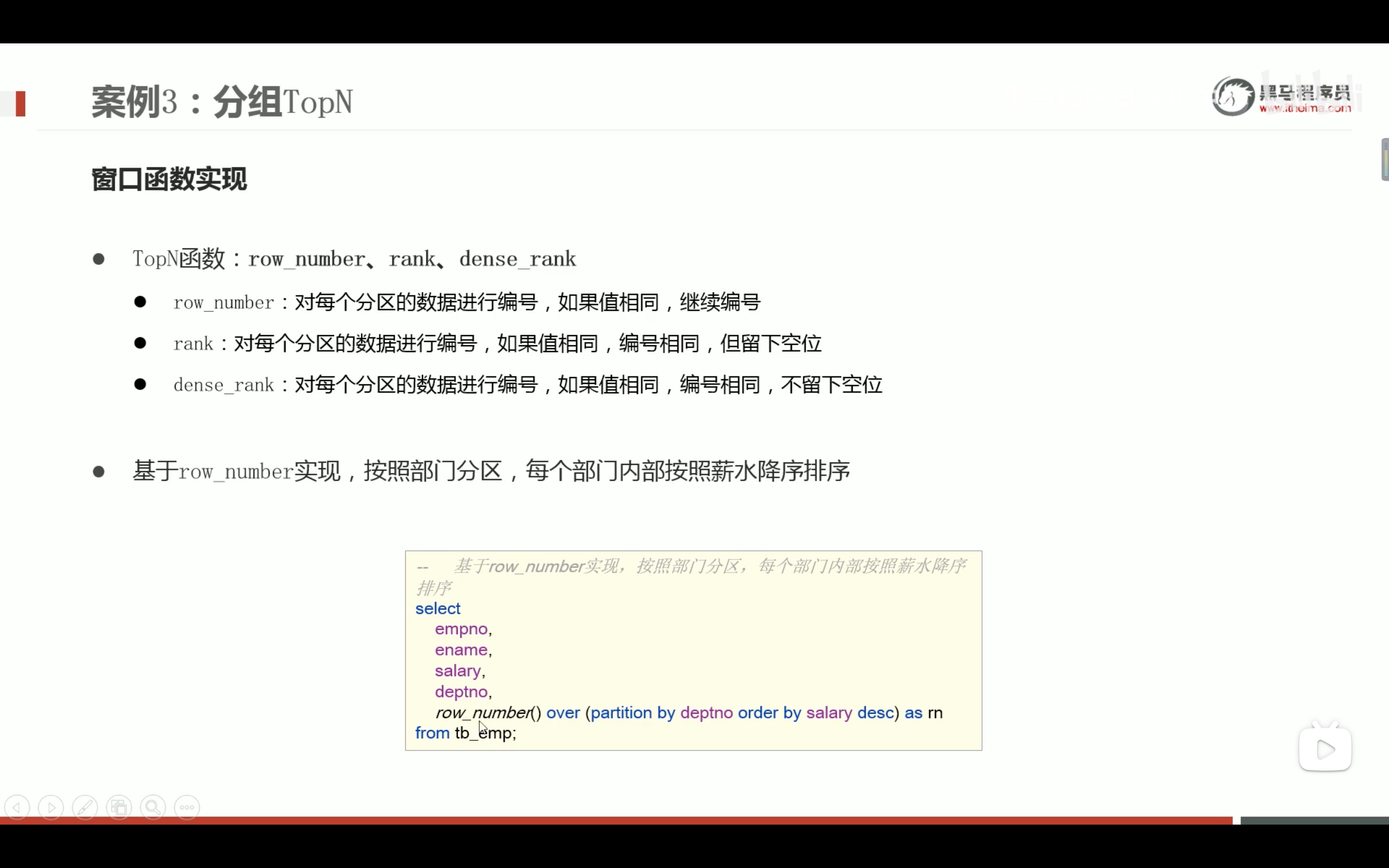
分组top n
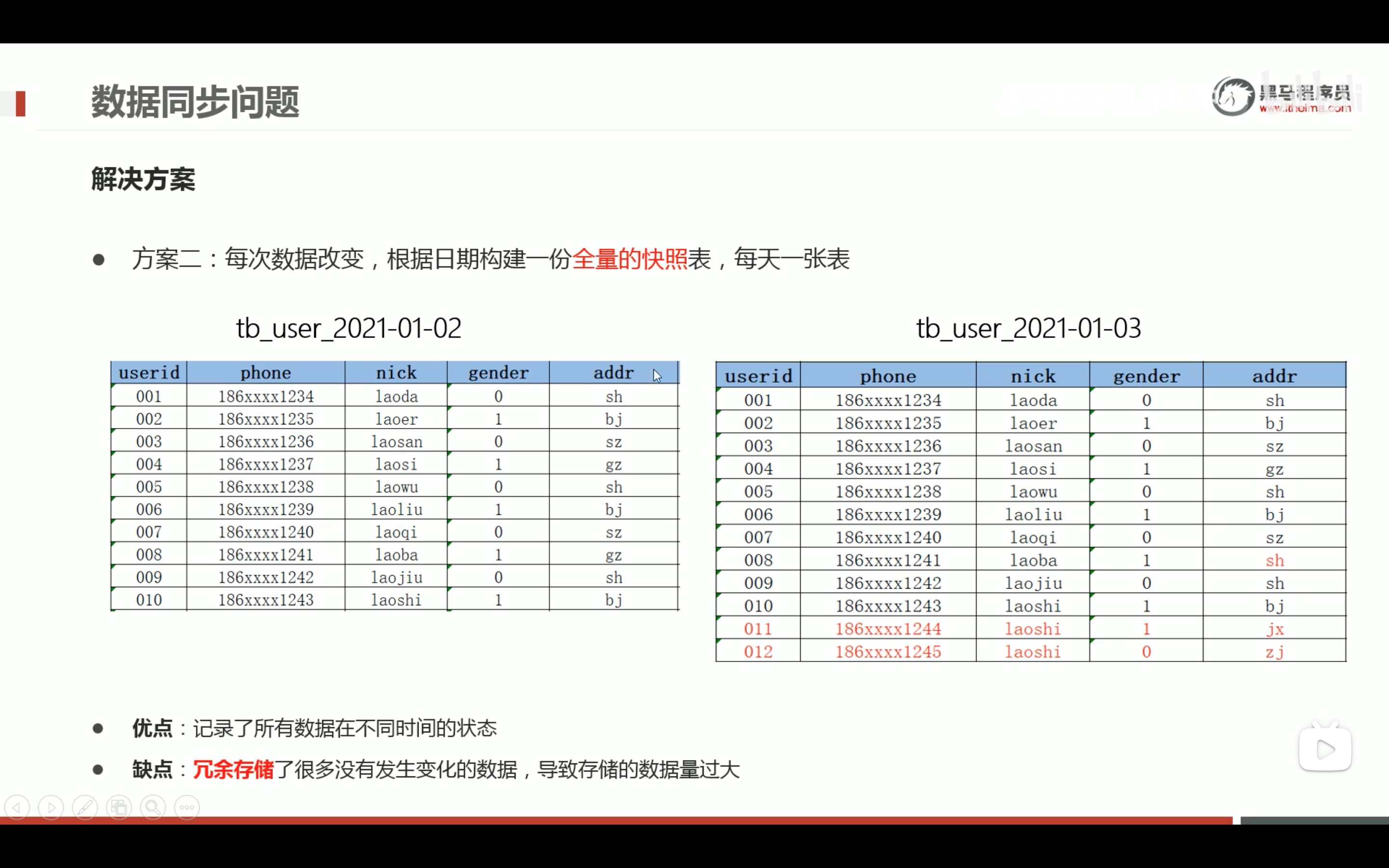
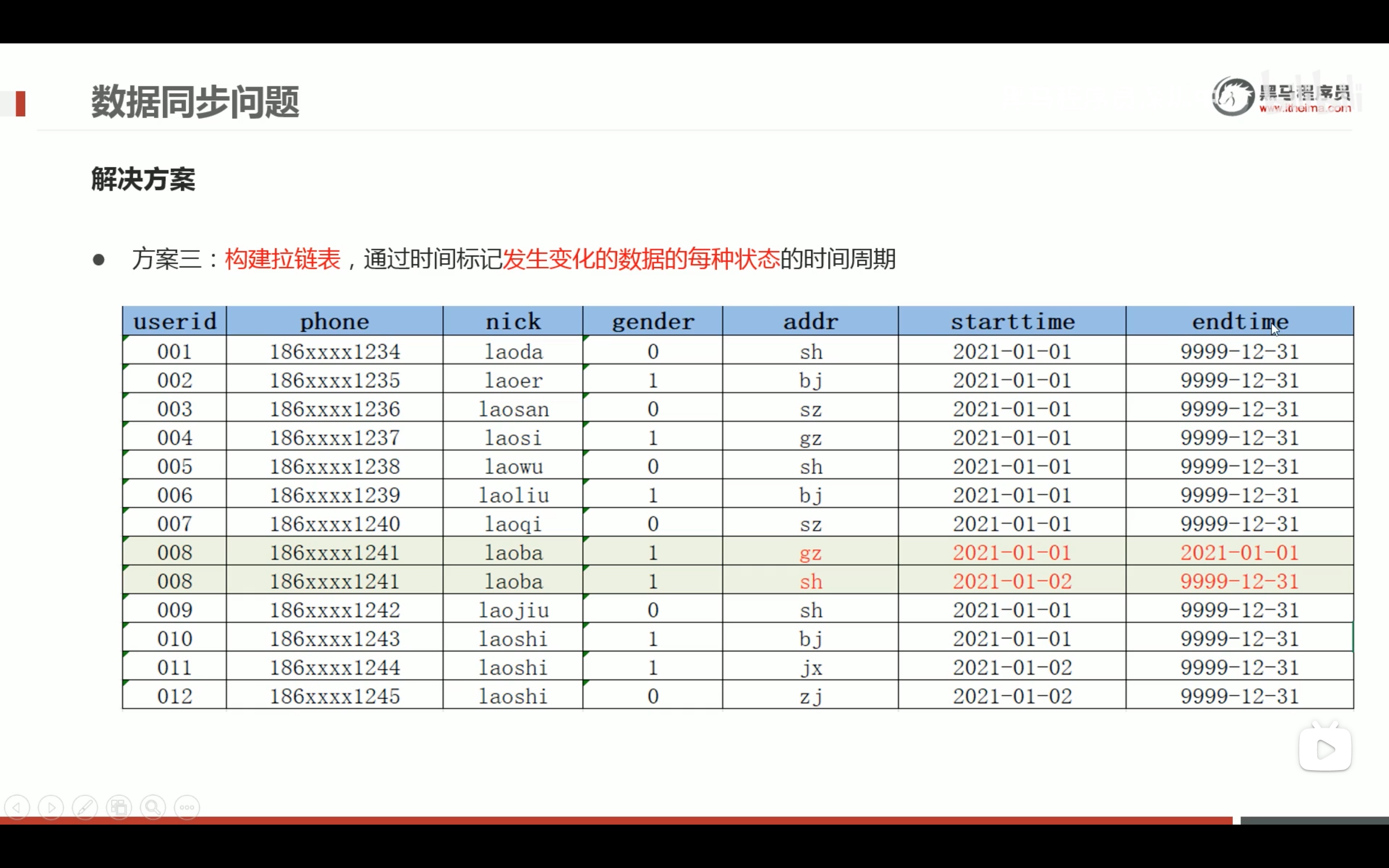
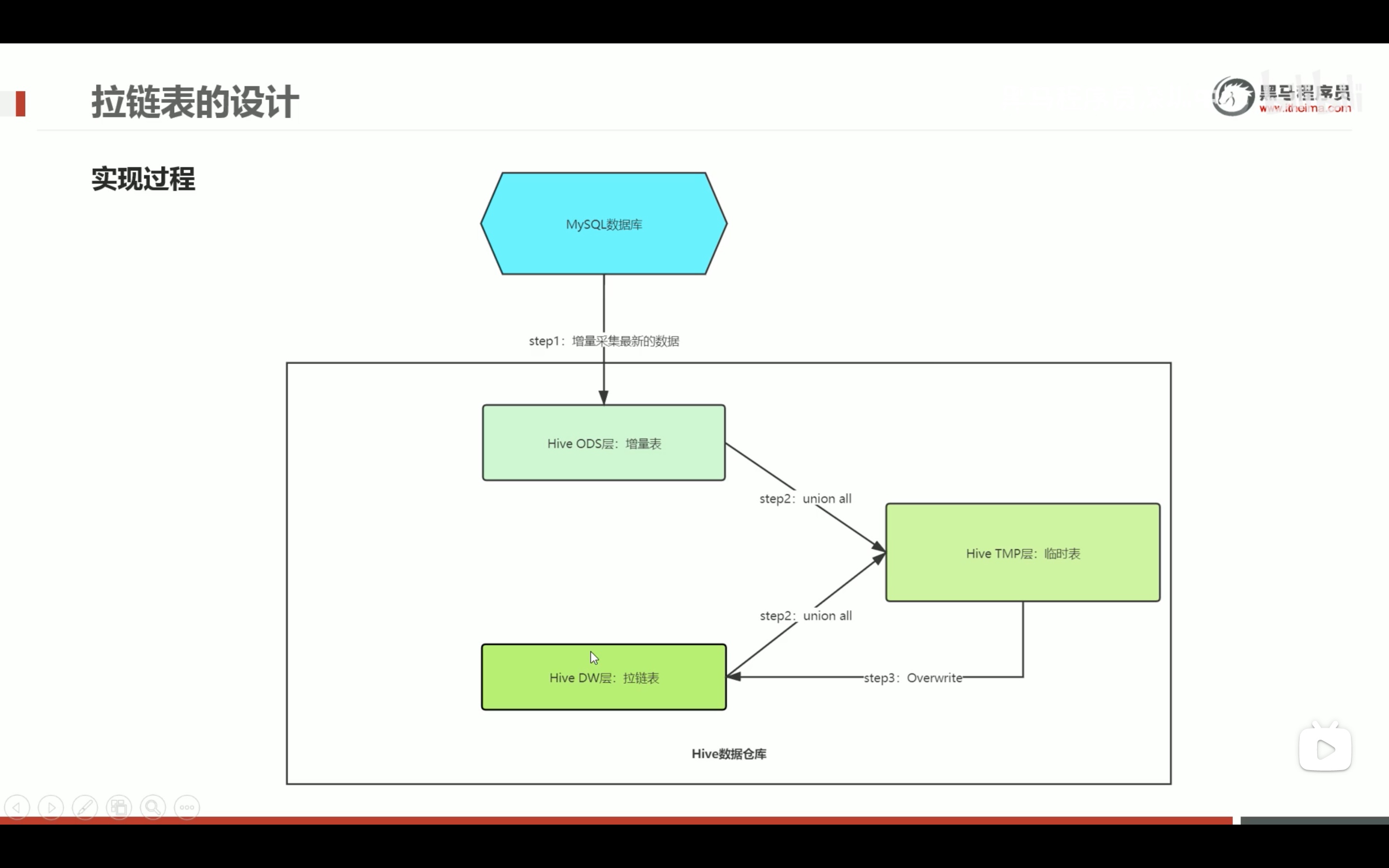
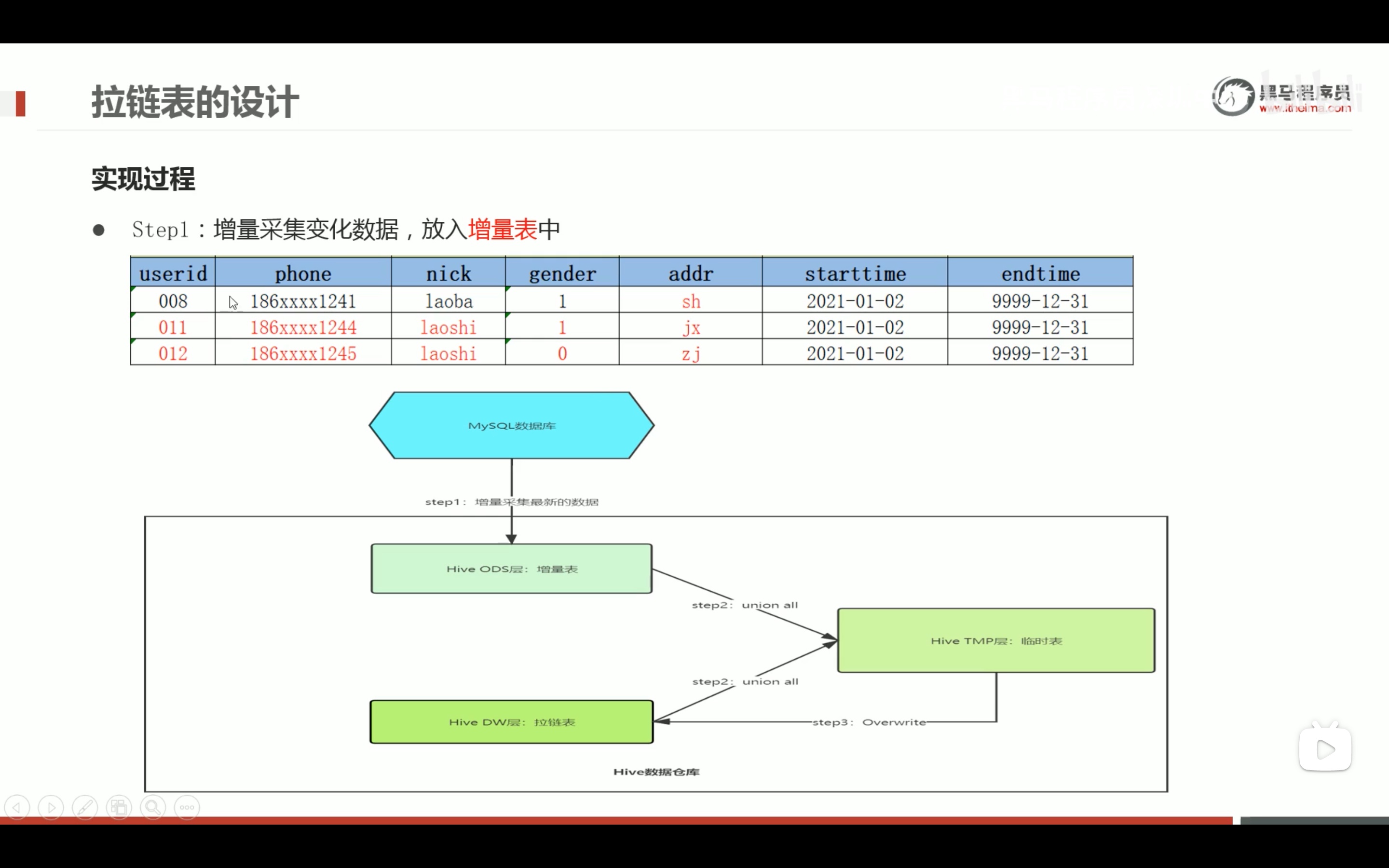
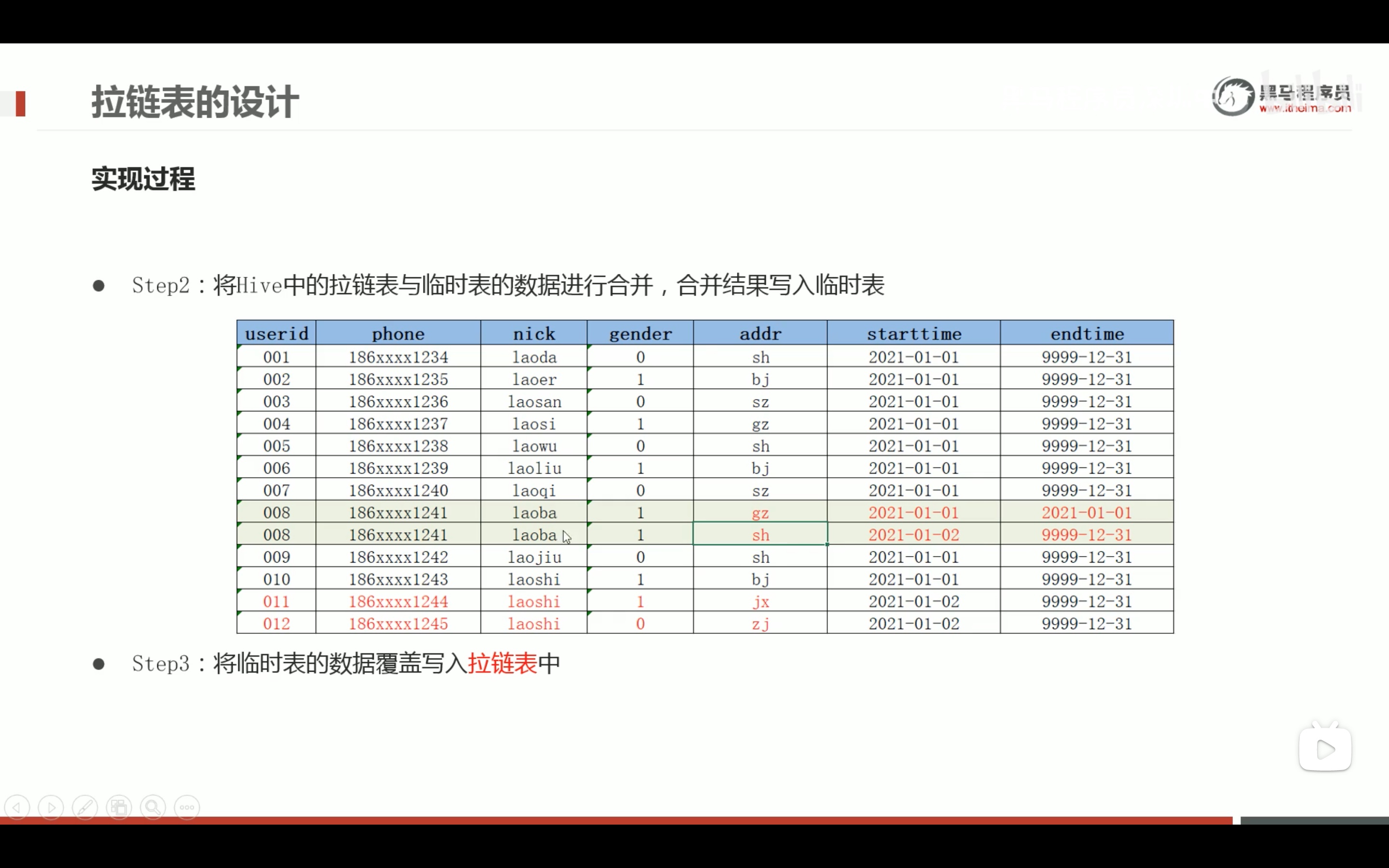
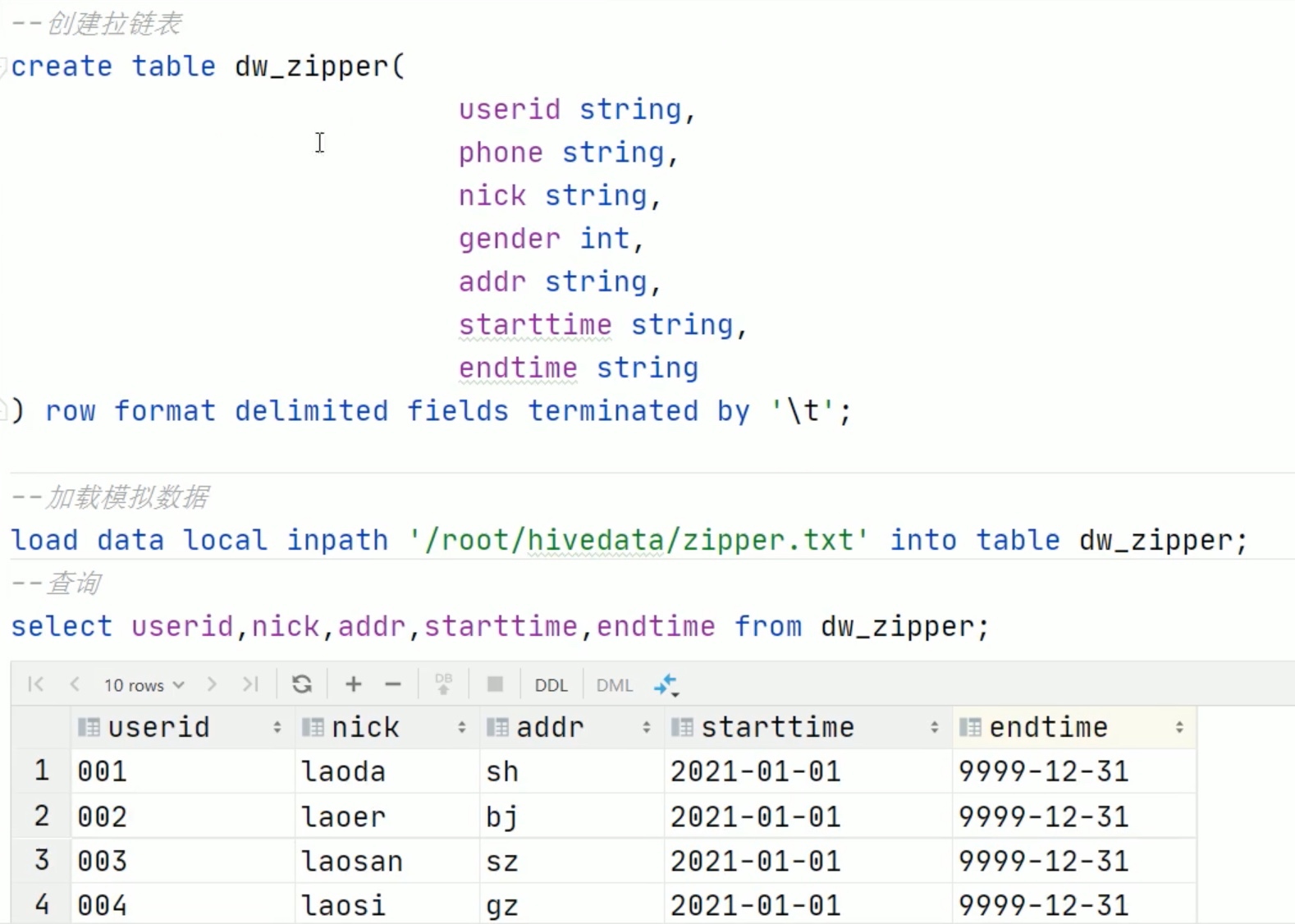
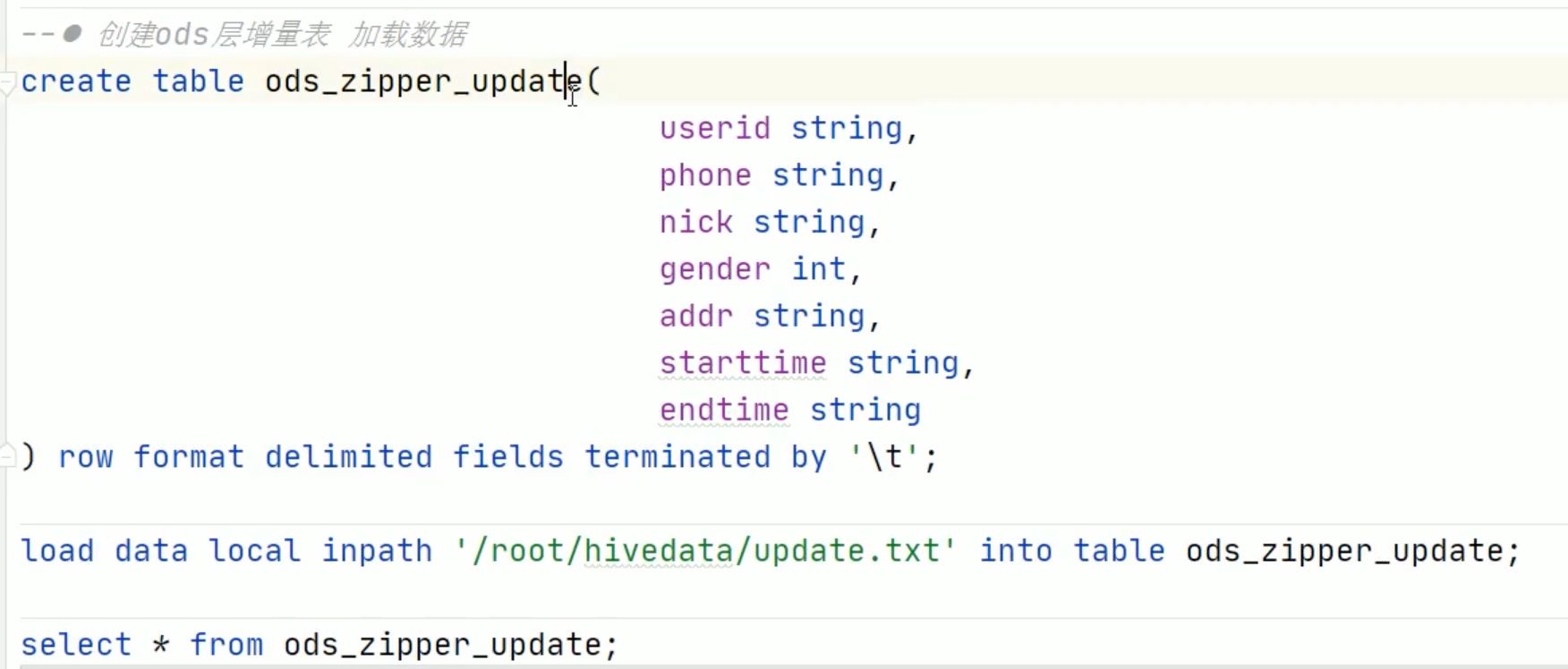
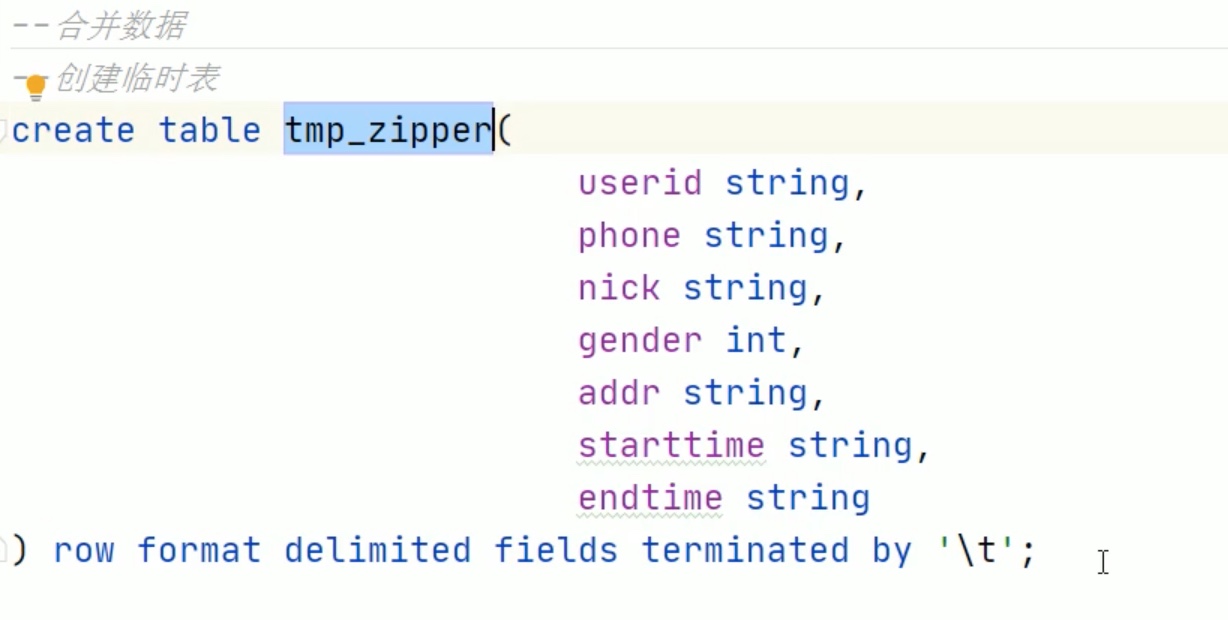
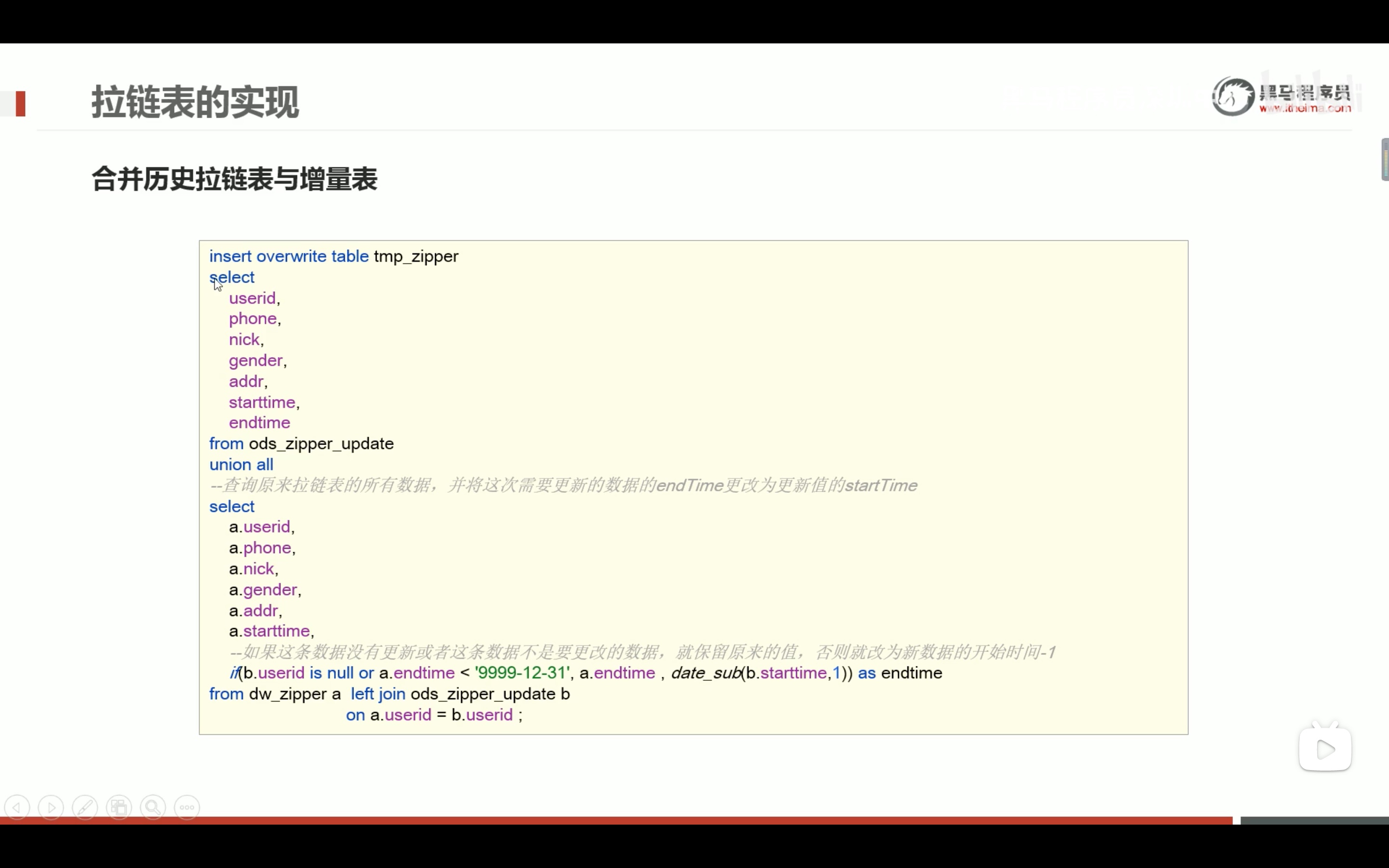
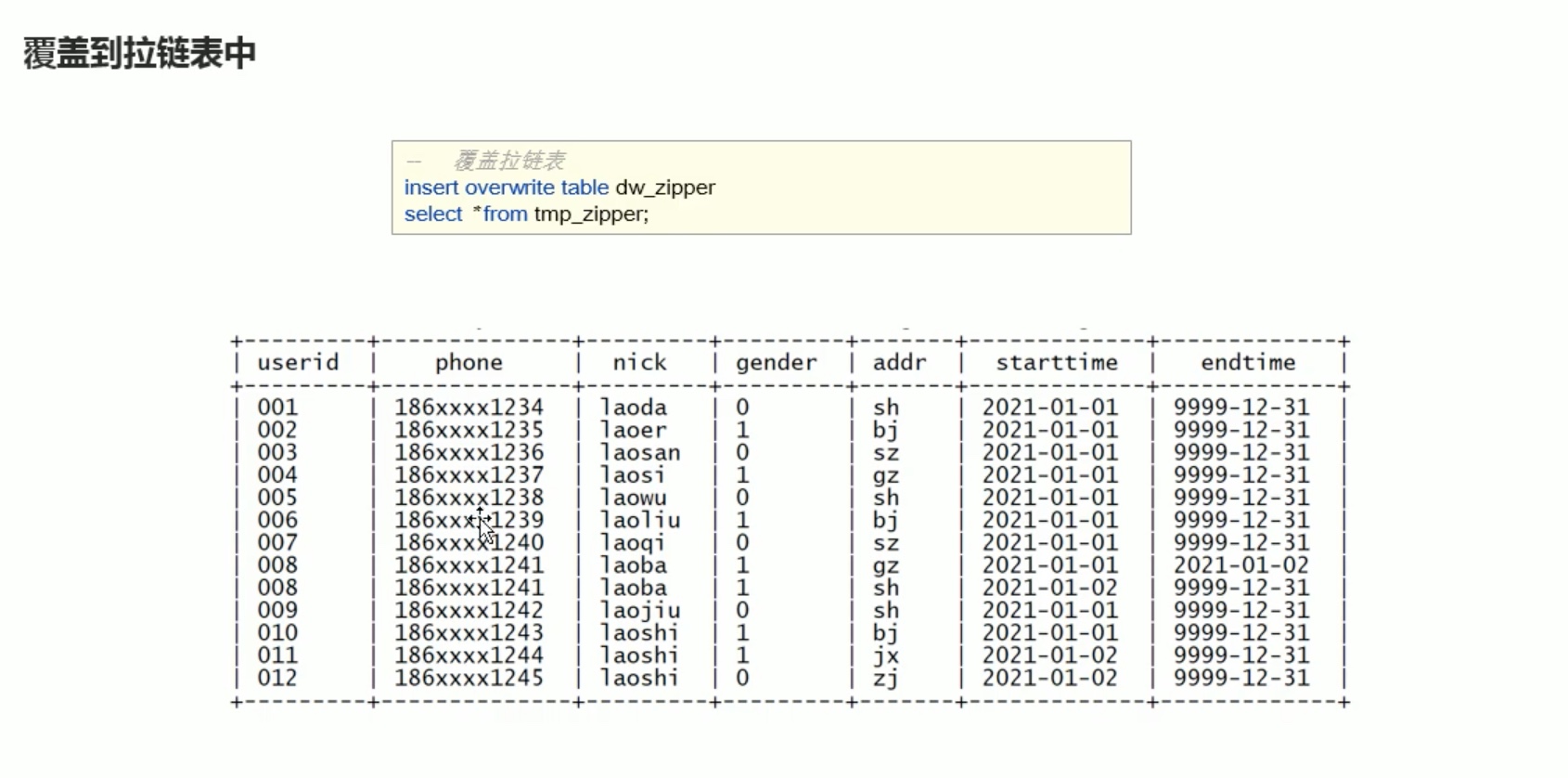
拉链表的设计和实现