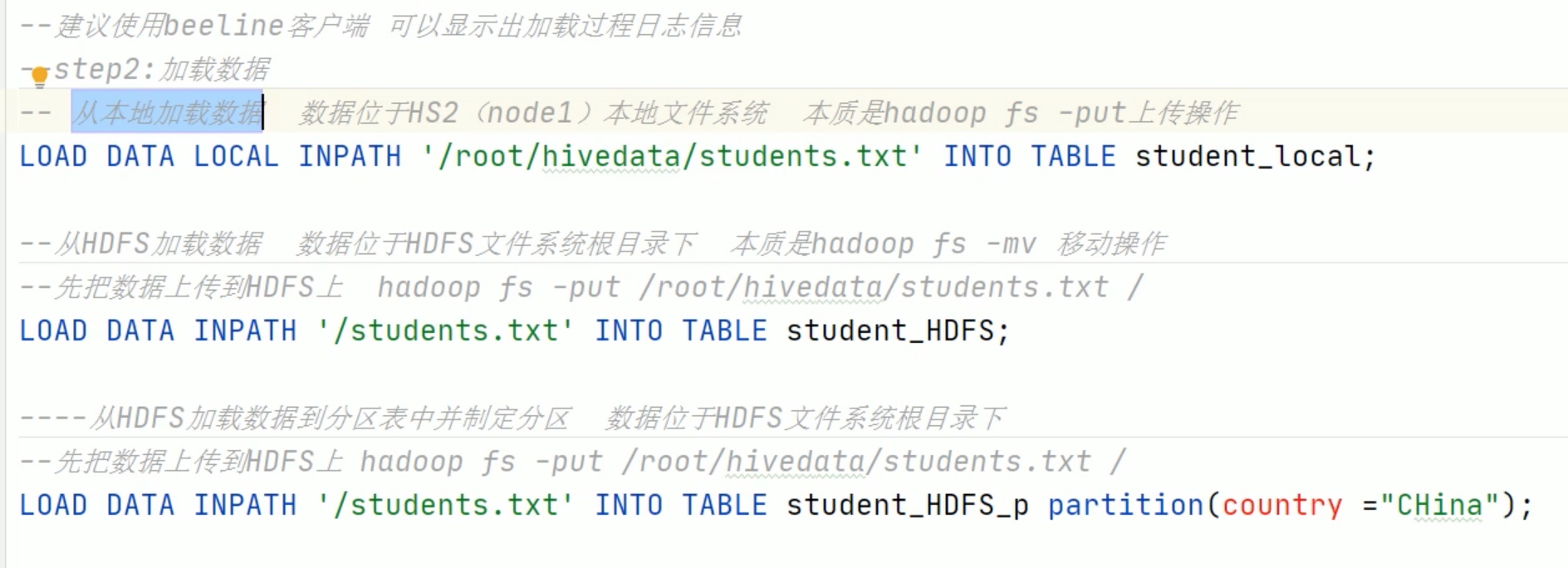
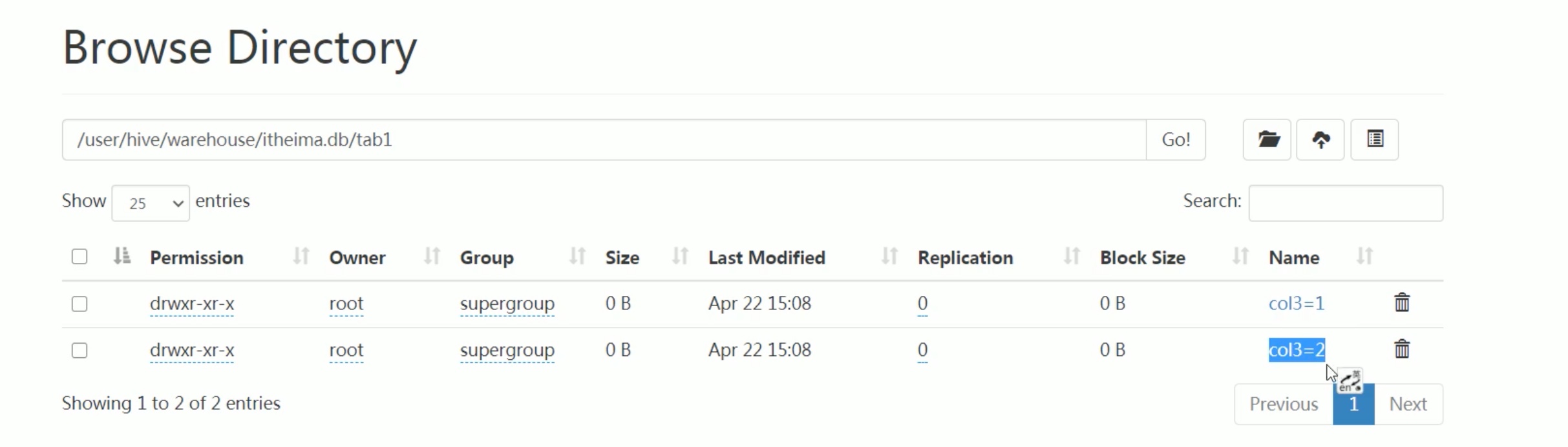
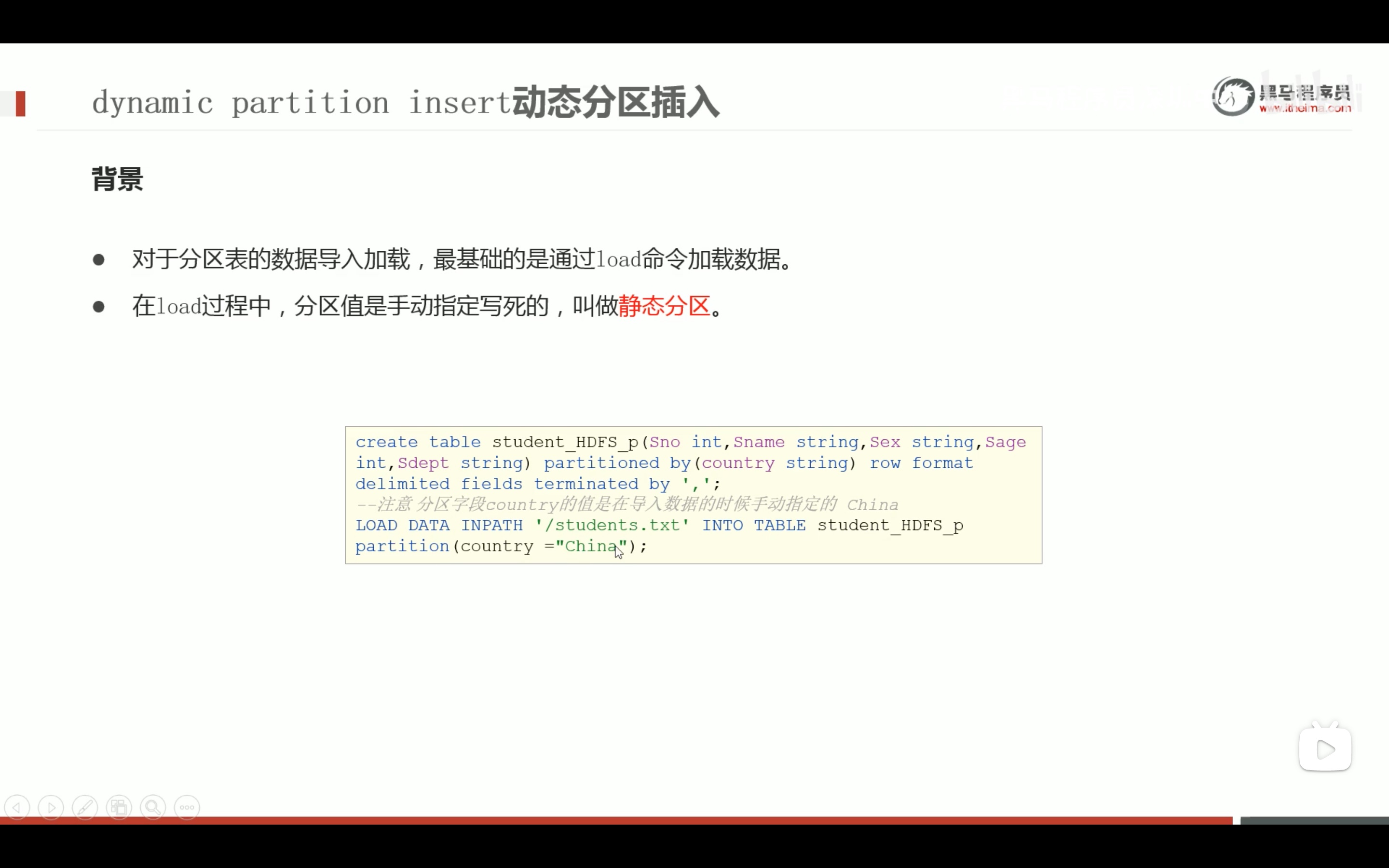
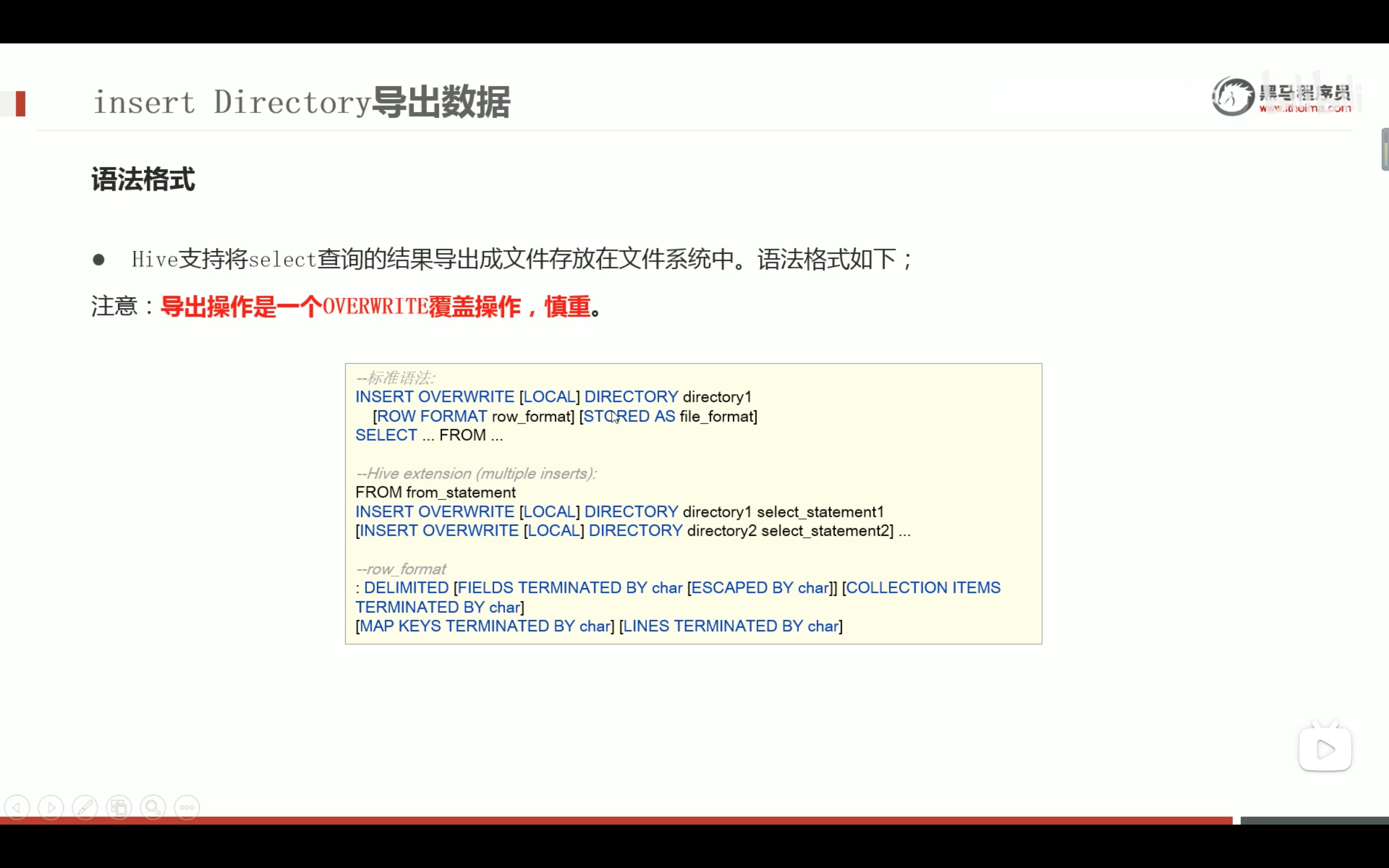
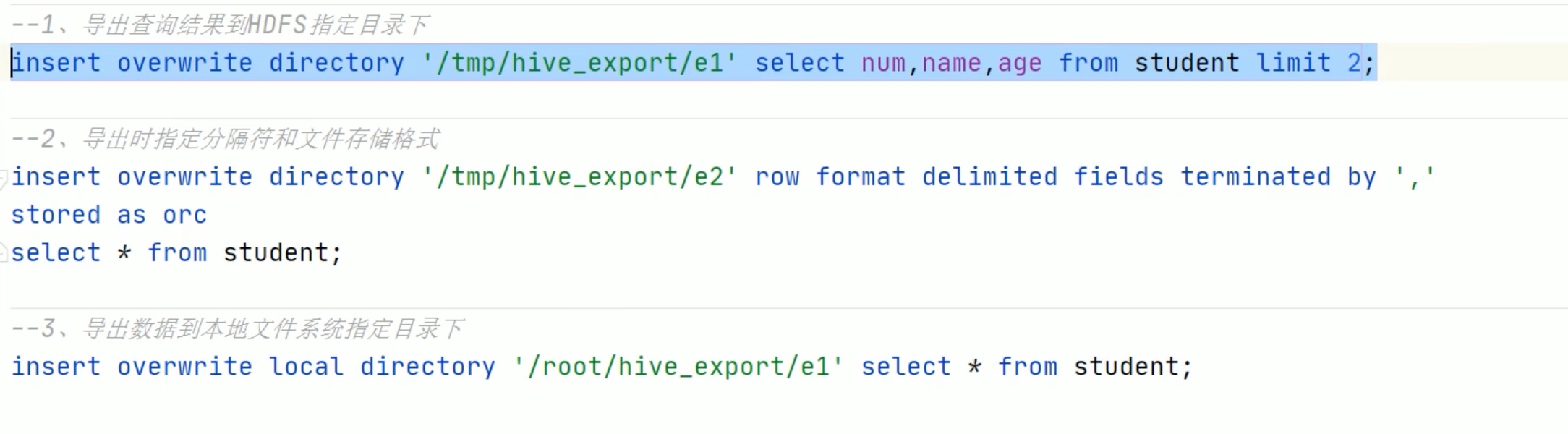
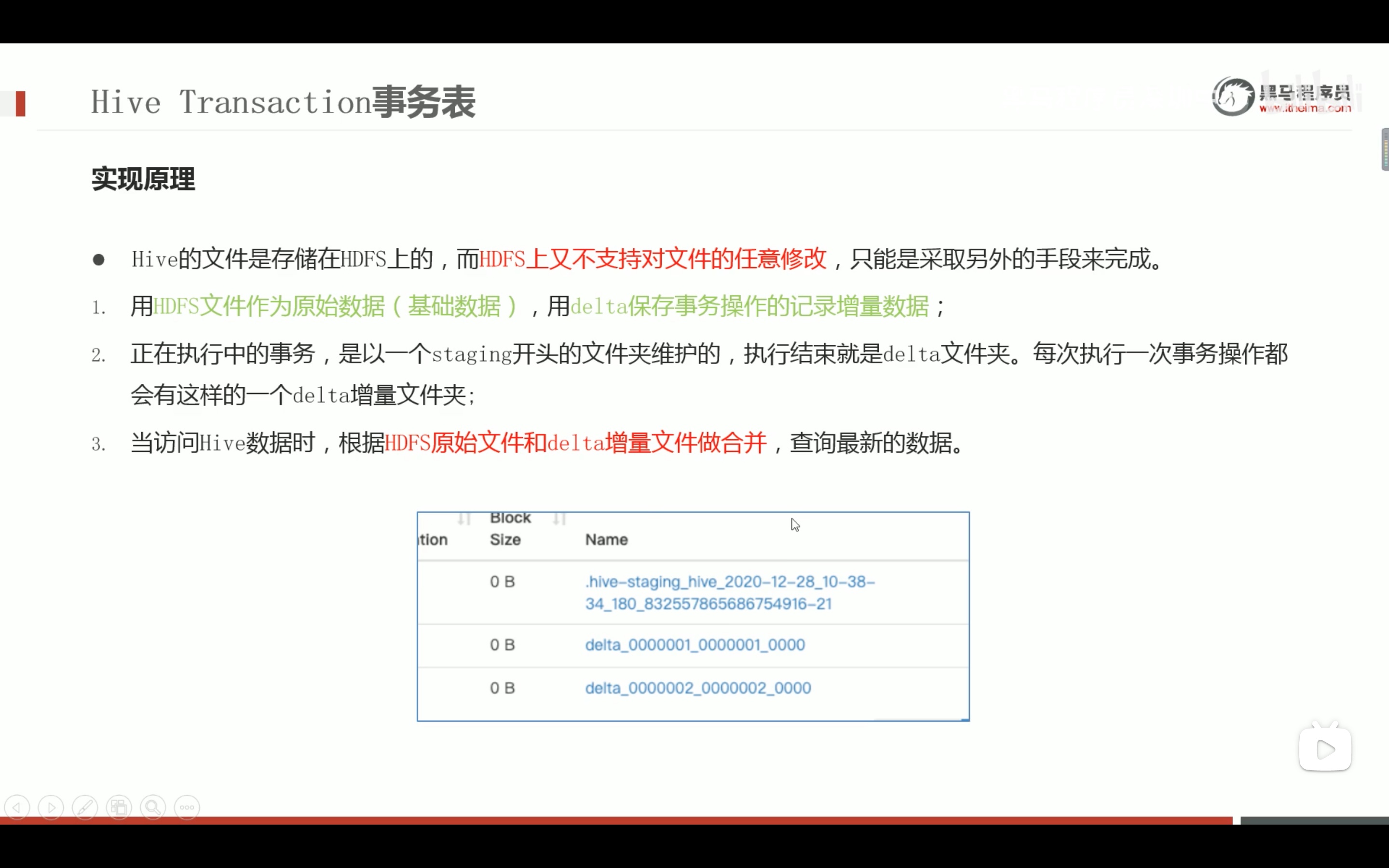
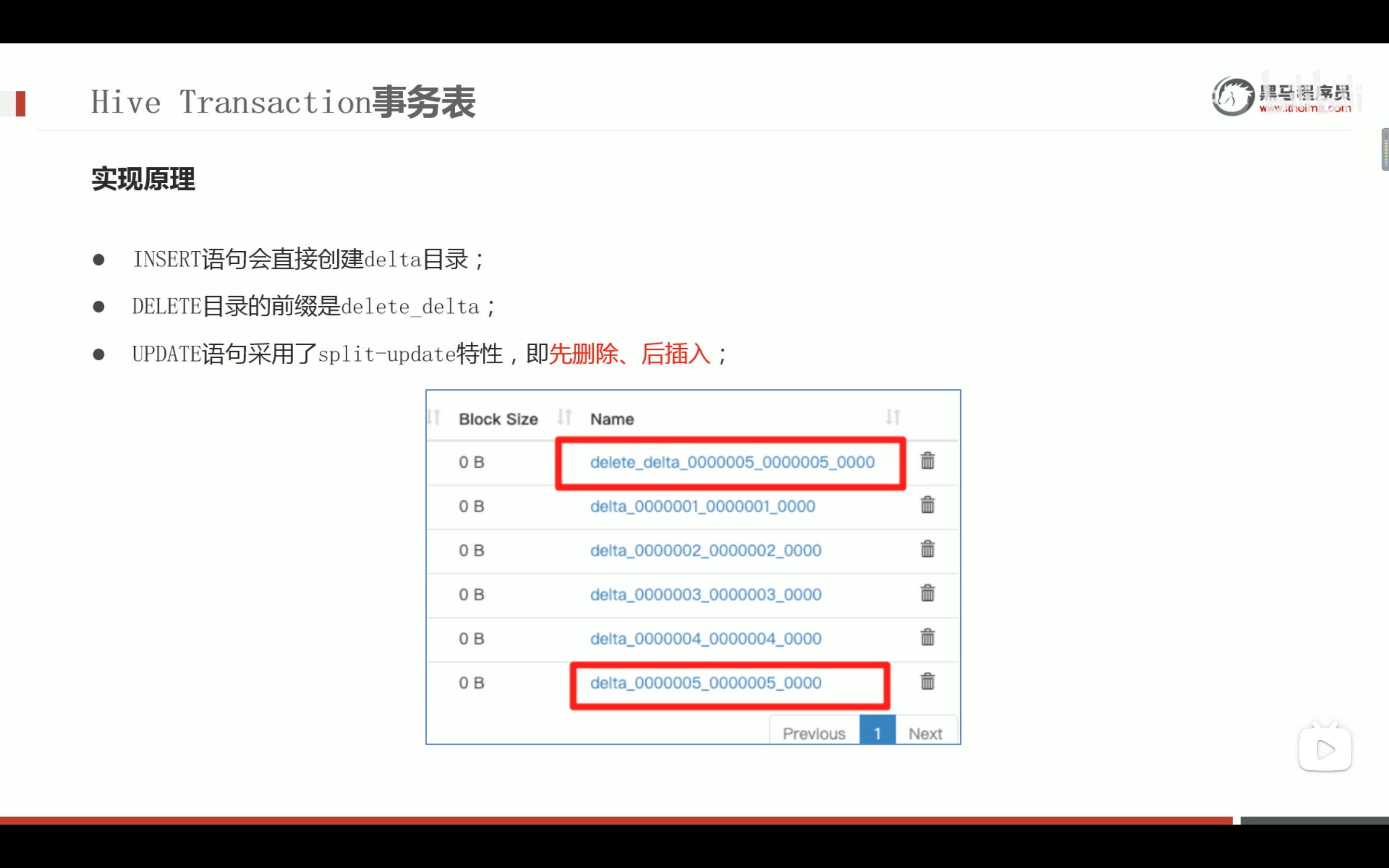
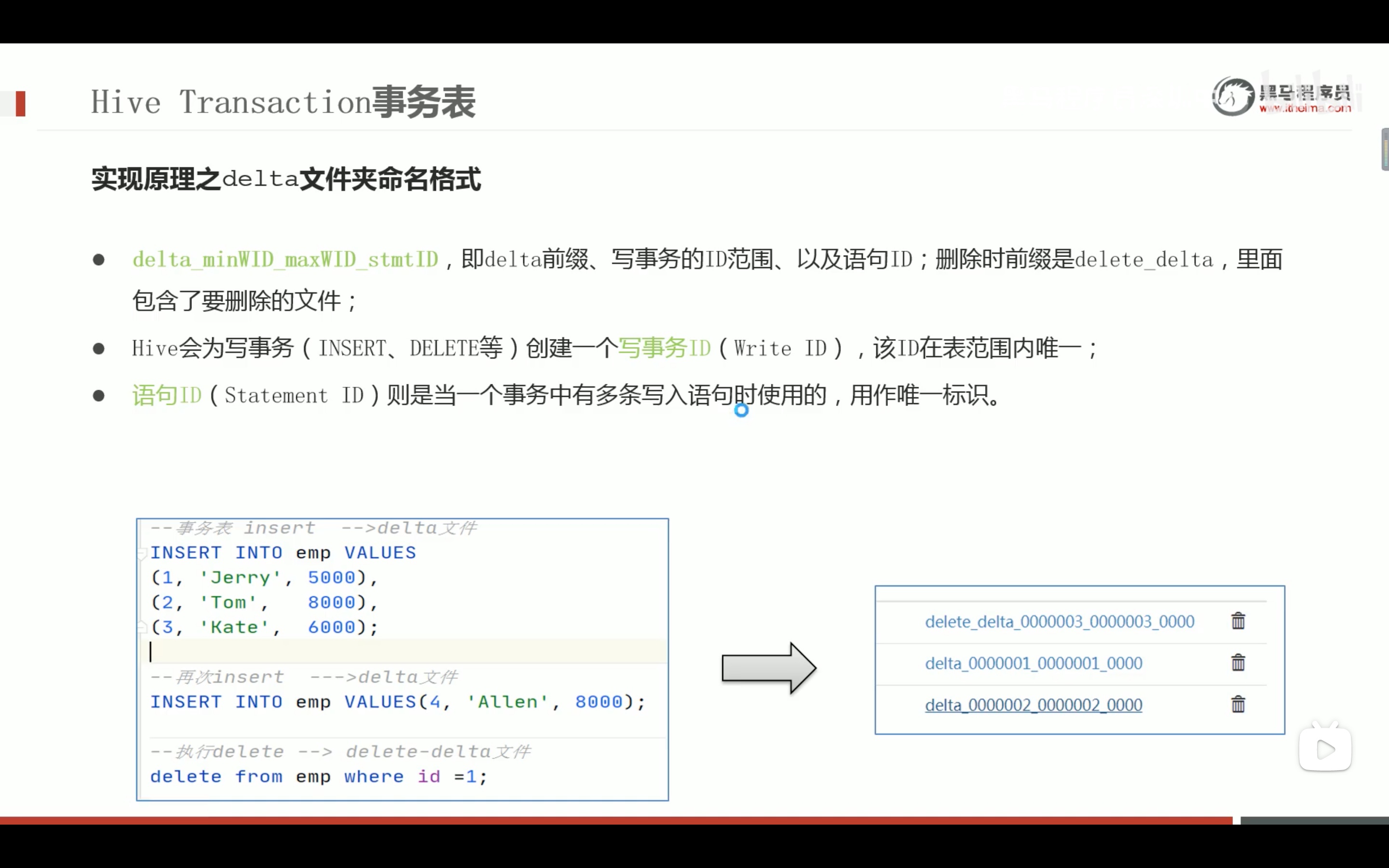
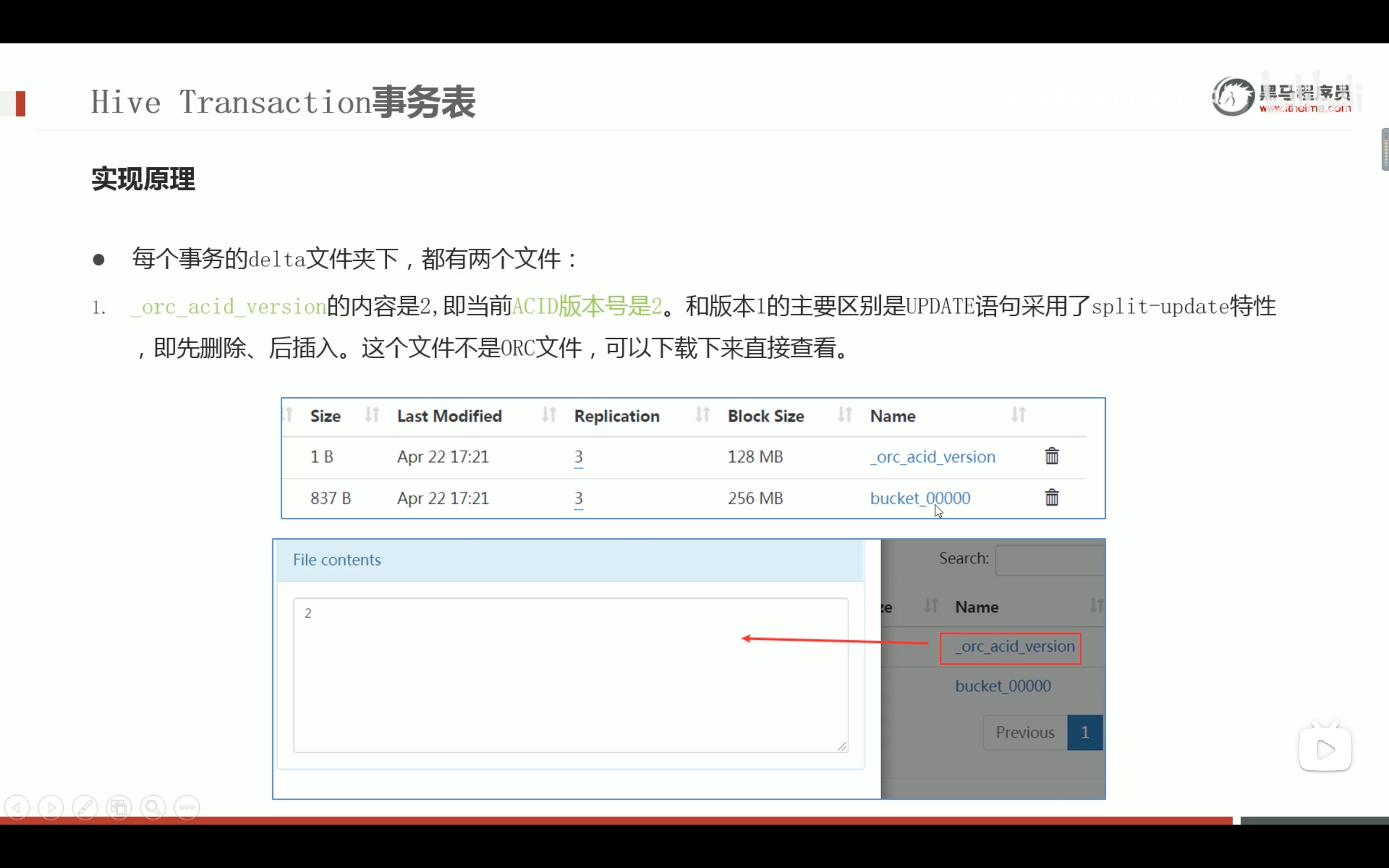
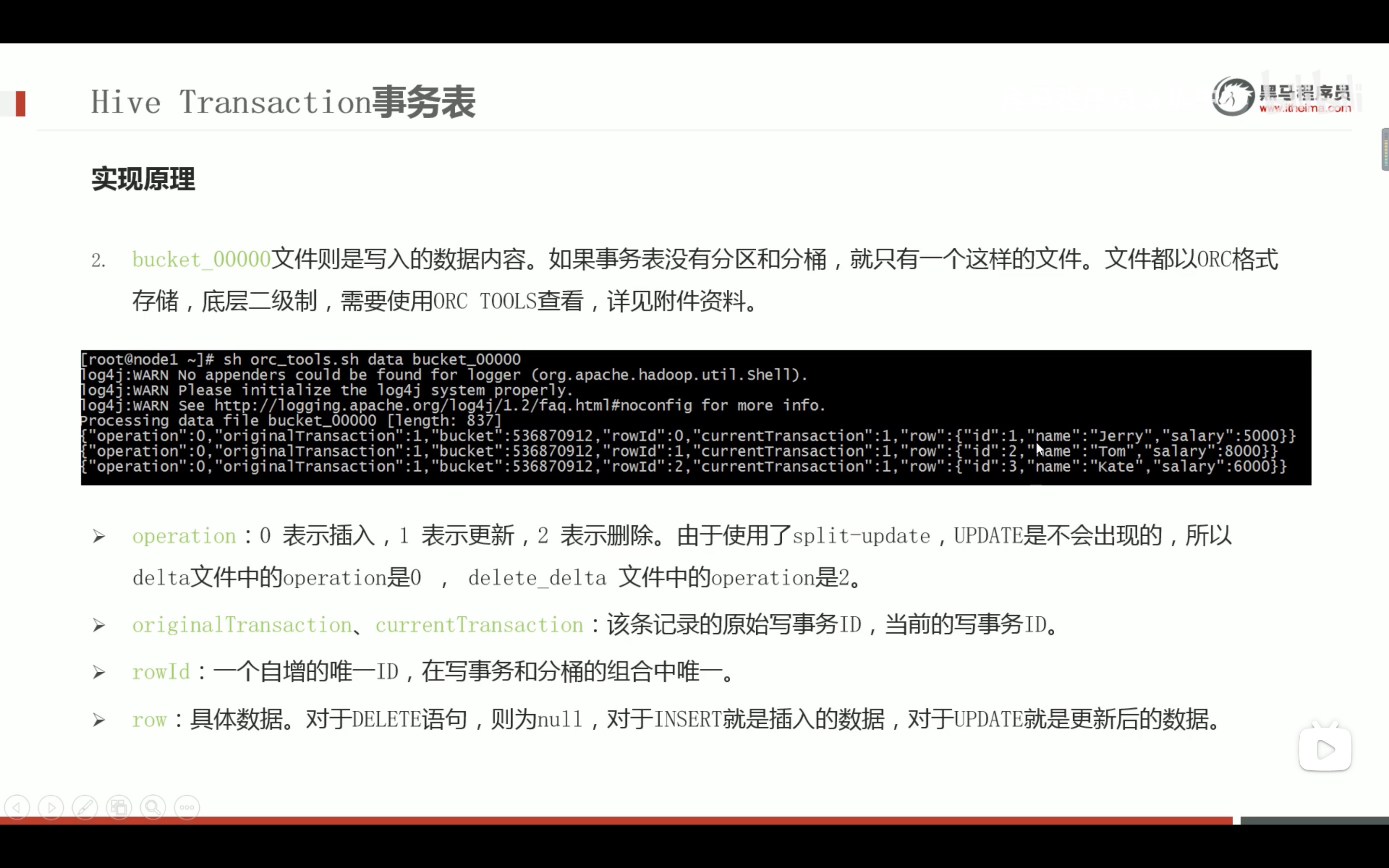
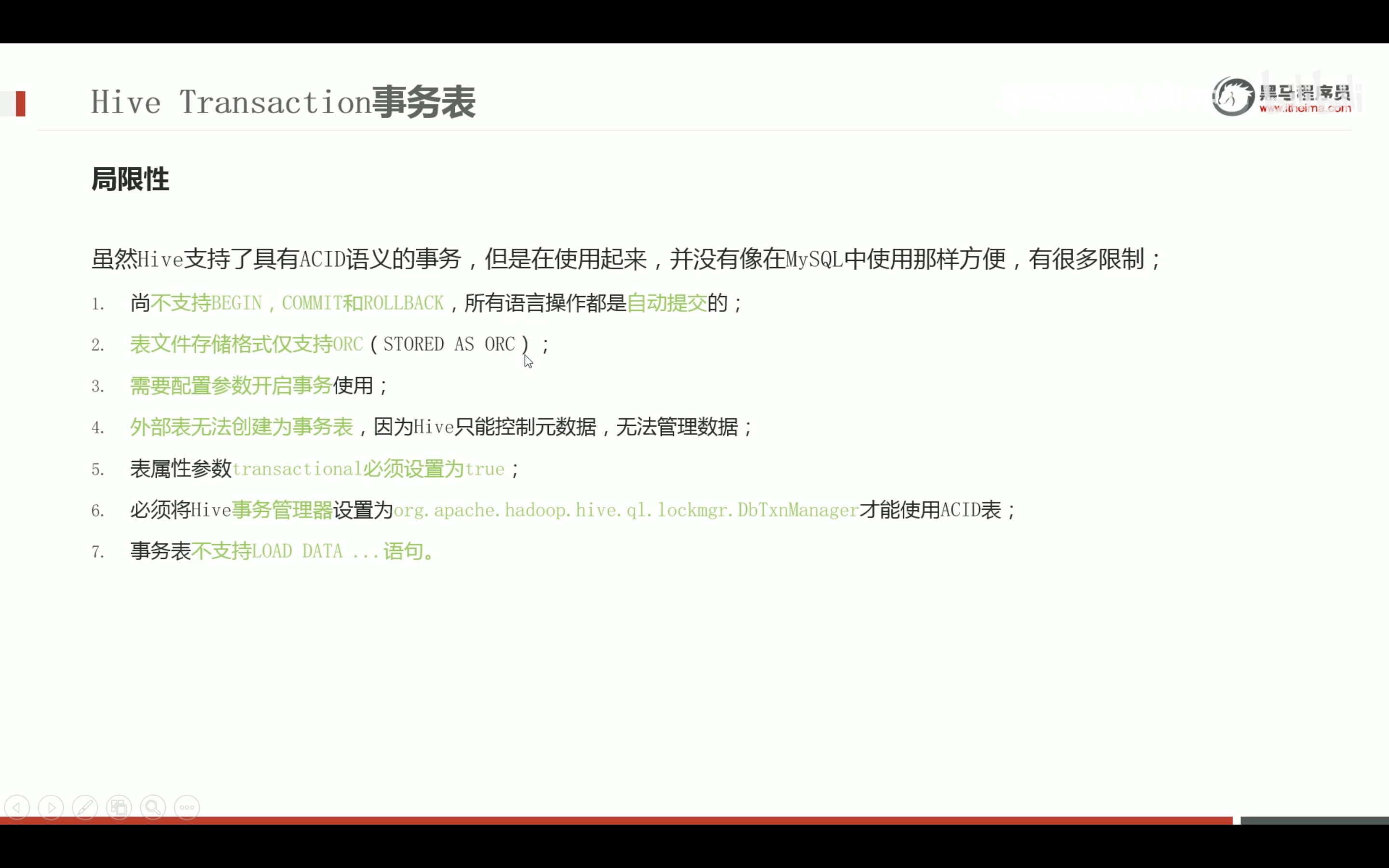
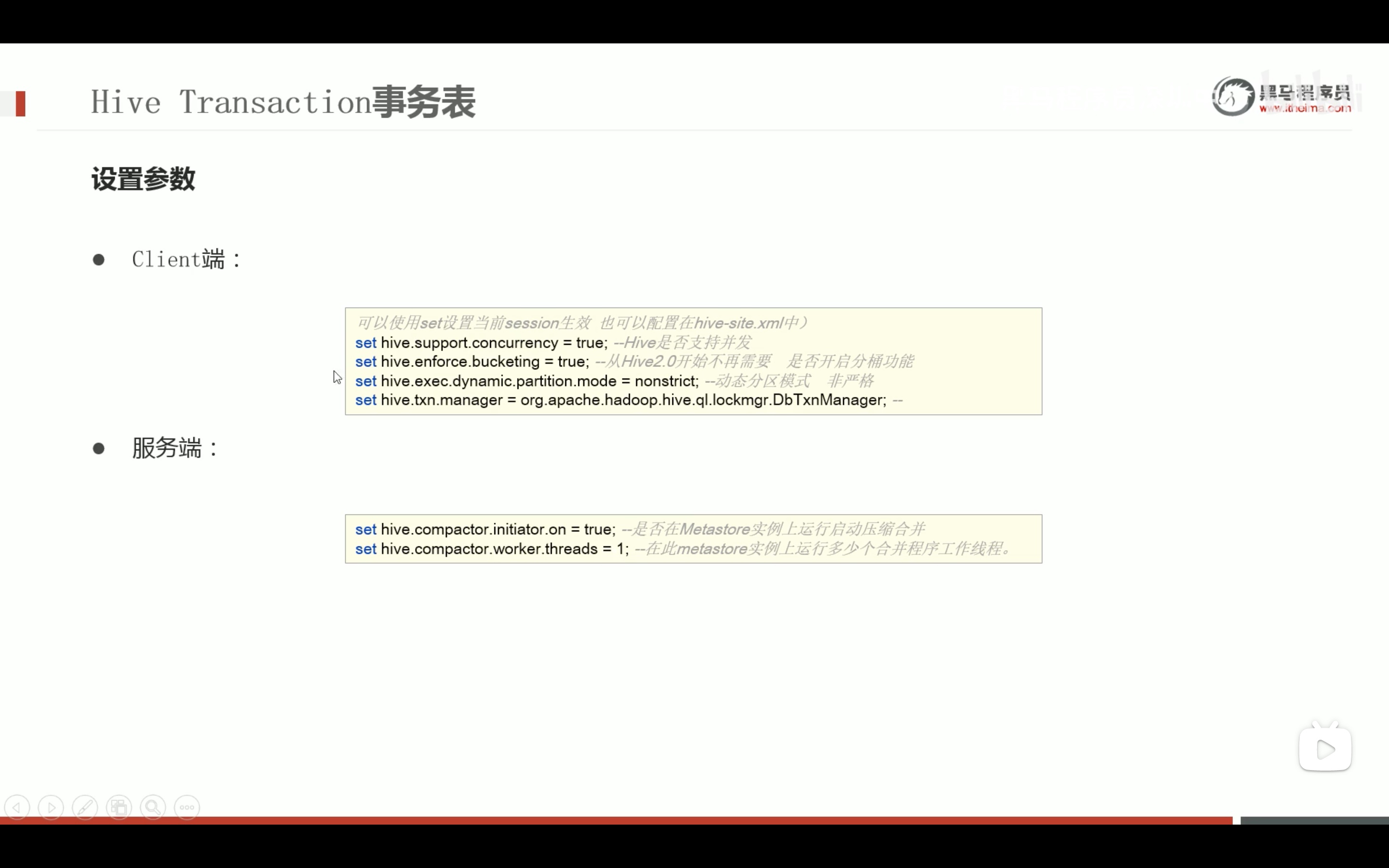
--step1:创建普通表t_usa_covid19 droptable if exists t_usa_covid19; CREATETABLE t_usa_covid19( count_date string, county string, state string, fips int, cases int, deaths int) row format delimited fields terminated by ","; --将源数据load加载到t_usa_covid19表对应的路径下 load data local inpath '/root/hivedata/us-covid19-counties.dat'intotable t_usa_covid19;
select*from t_usa_covid19;
--step2:创建一张分区表 基于count_date日期,state州进行分区 CREATETABLE if notexists t_usa_covid19_p( county string, fips int, cases int, deaths int) partitioned by(count_date string,state string) row format delimited fields terminated by ",";
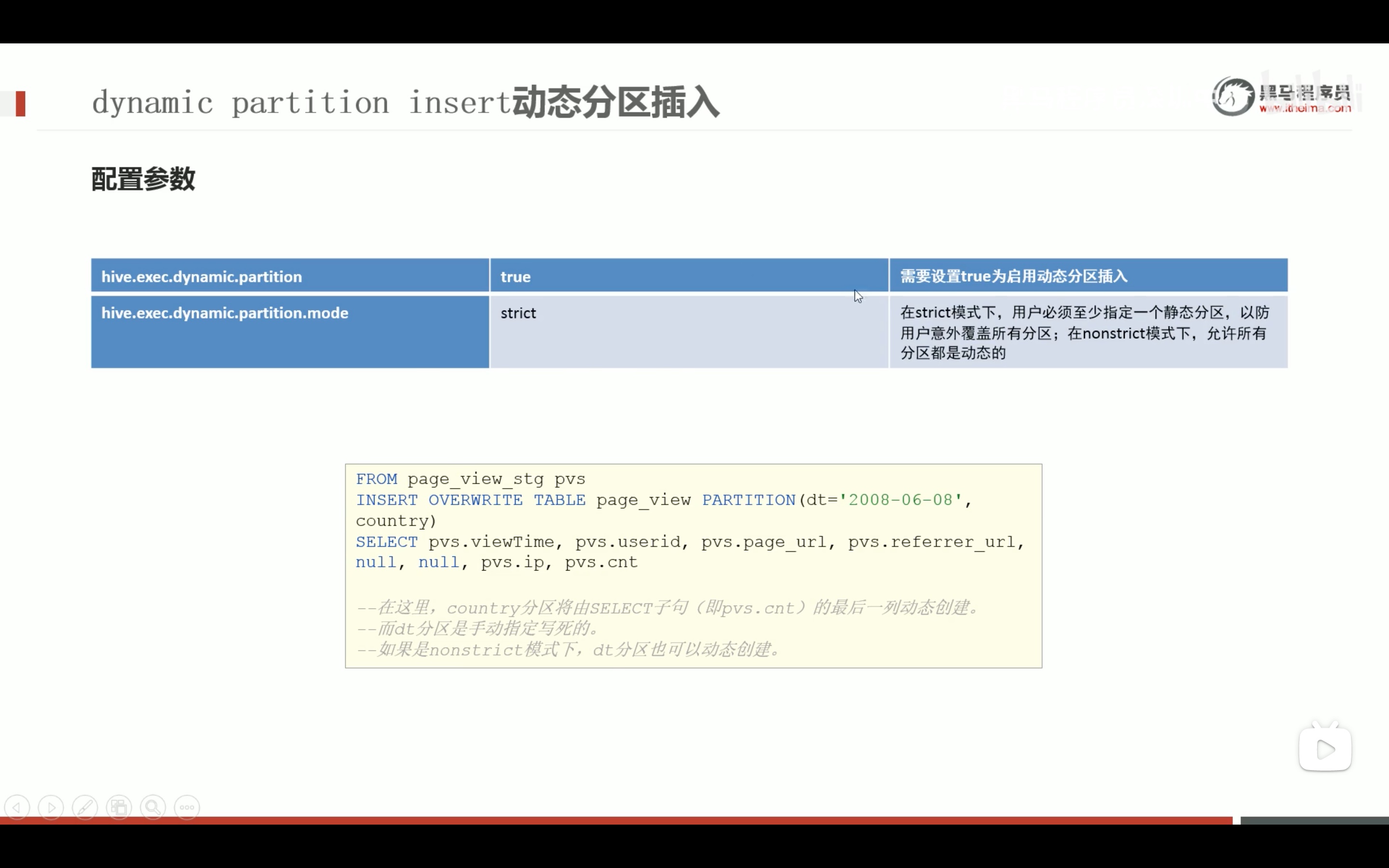
--step3:使用动态分区插入将数据导入t_usa_covid19_p中 set hive.exec.dynamic.partition.mode = nonstrict;
insertintotable t_usa_covid19_p partition (count_date,state) select county,fips,cases,deaths,count_date,state from t_usa_covid19;
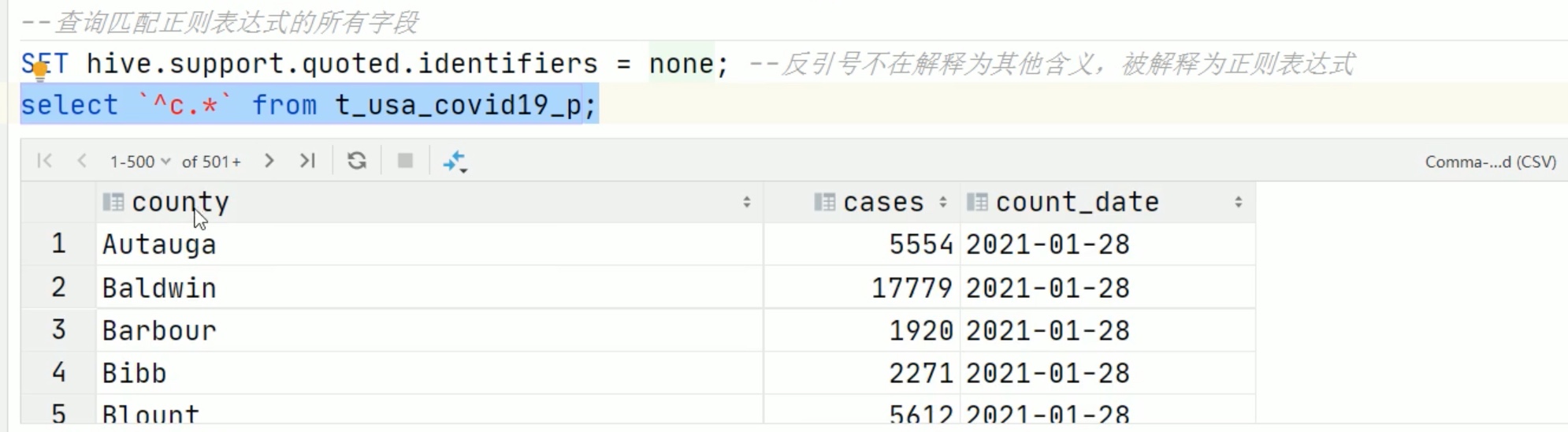
--1、select_expr --查询所有字段或者指定字段 select*from t_usa_covid19_p; select county, cases, deaths from t_usa_covid19_p; --查询匹配正则表达式的所有字段 SET hive.support.quoted.identifiers =none; --反引号不在解释为其他含义,被解释为正则表达式 select `^c.*` from t_usa_covid19_p; --查询当前数据库 select current_database(); --省去from关键字 --查询使用函数 selectcount(county) from t_usa_covid19_p;
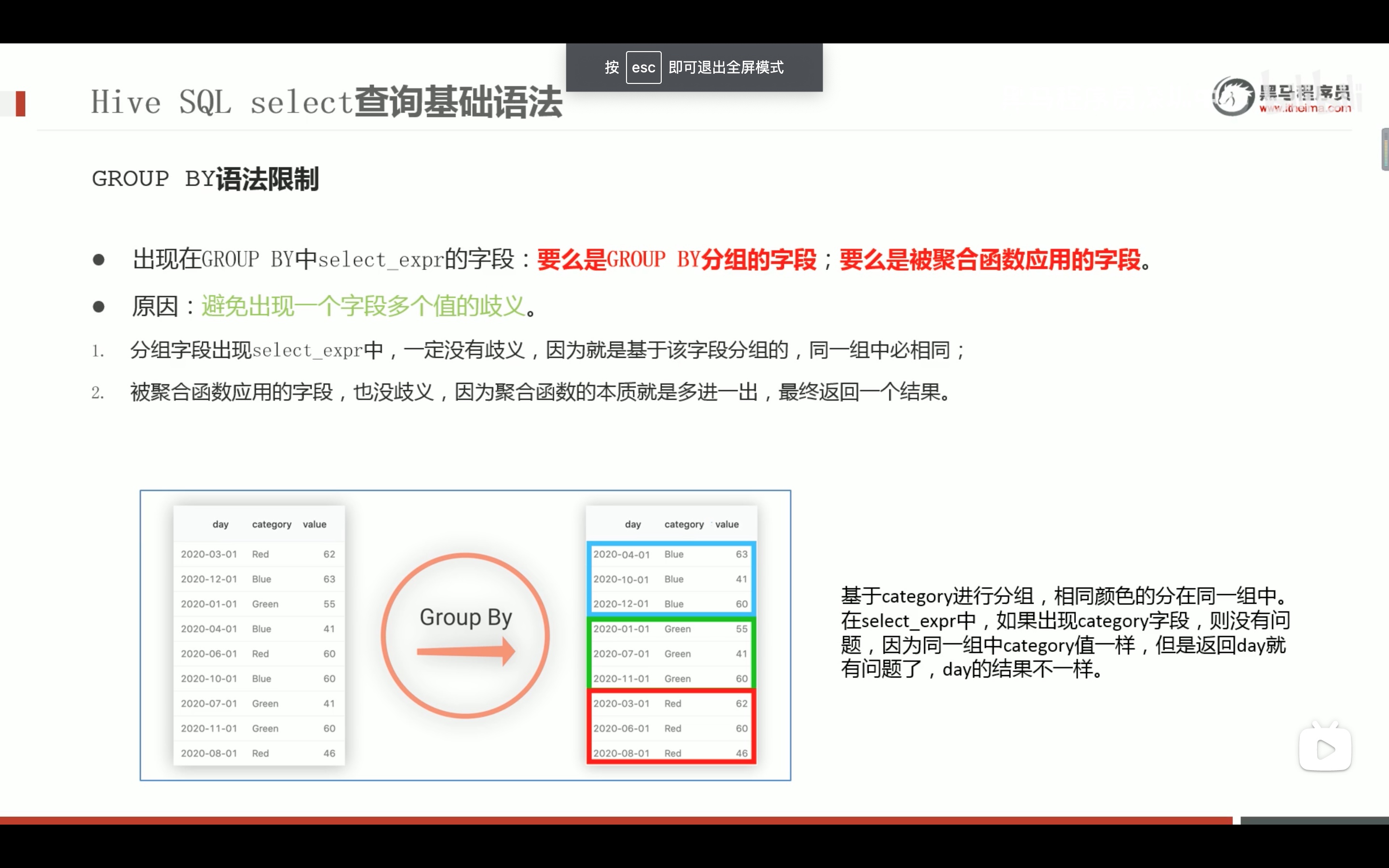
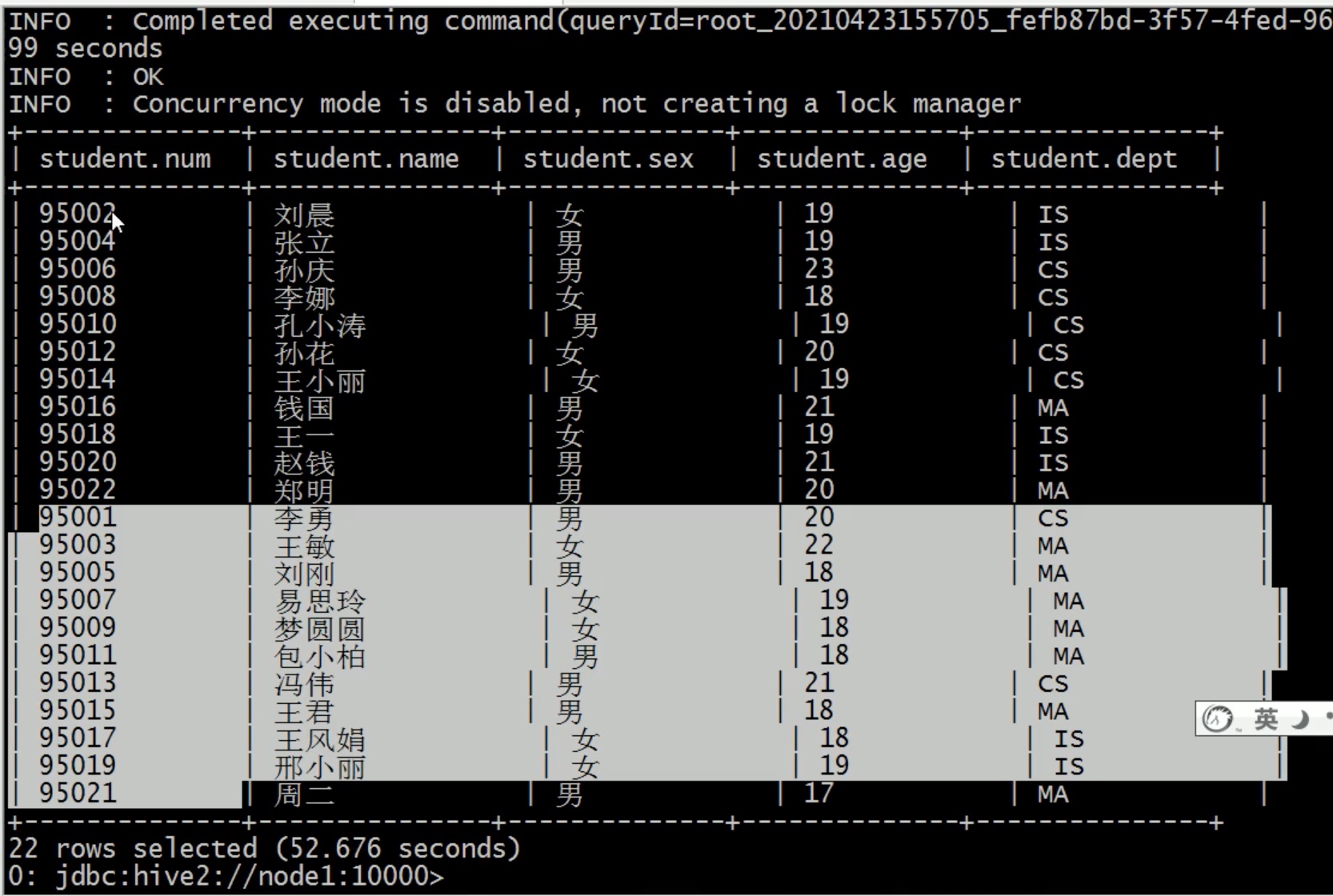
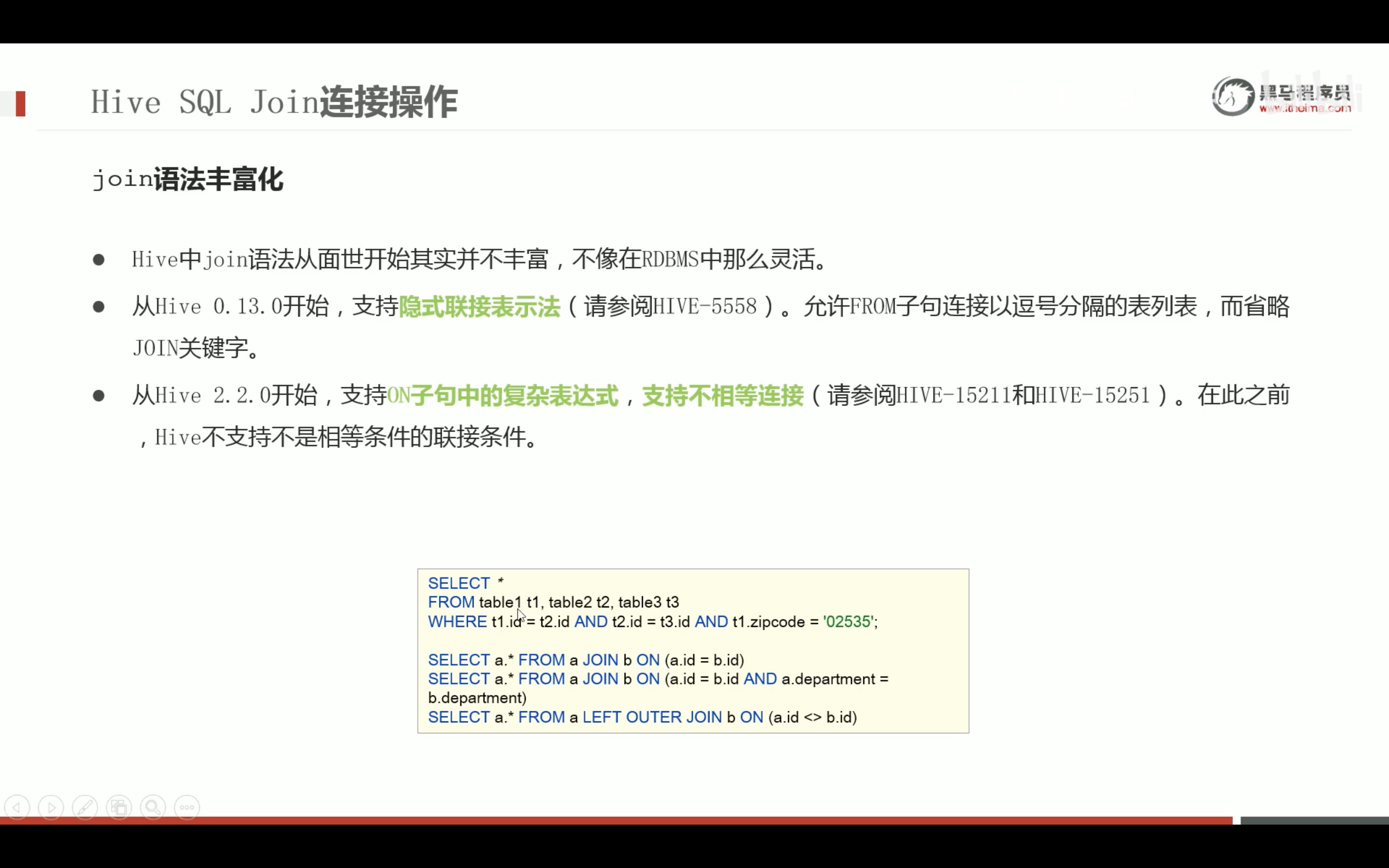
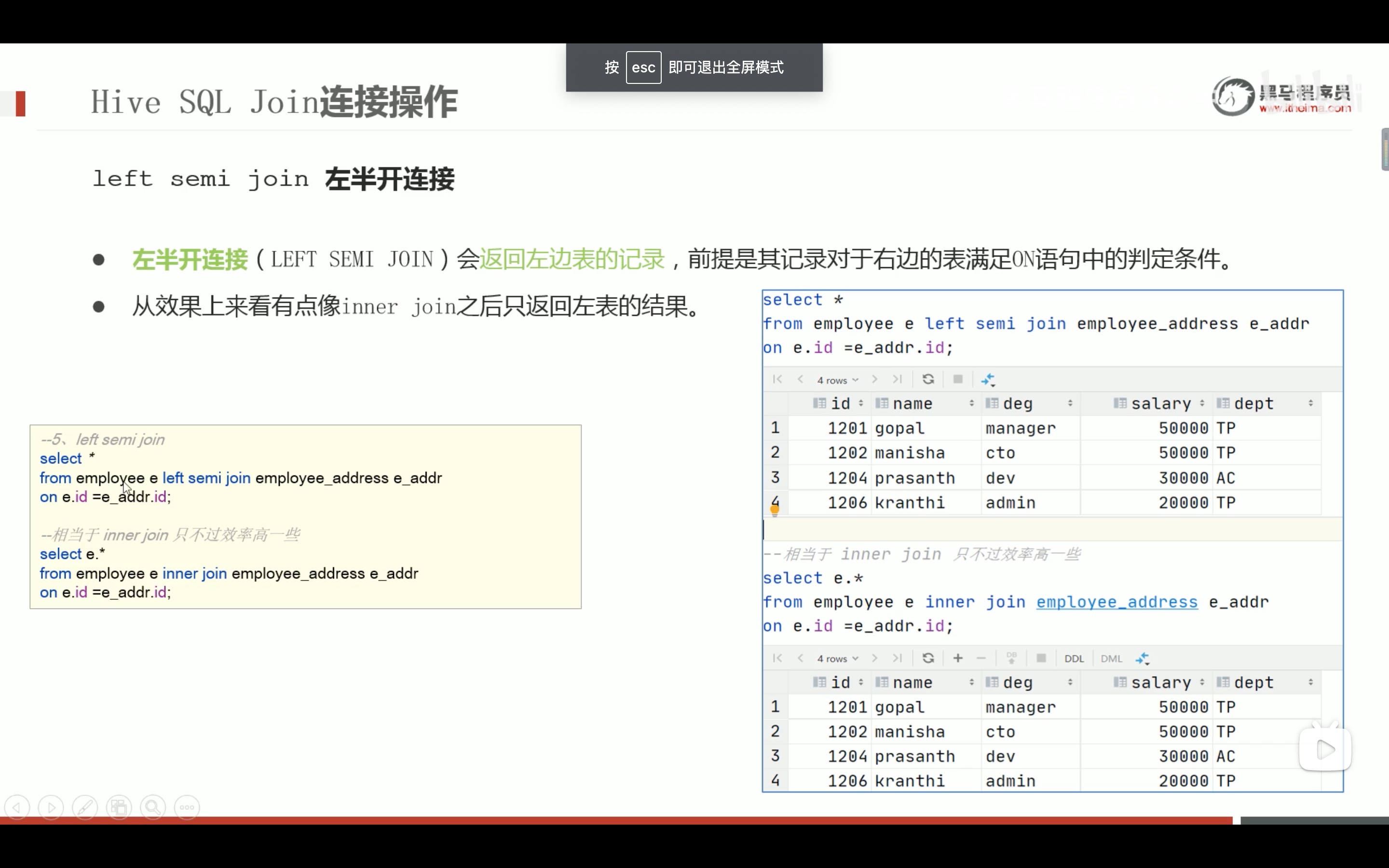
--2、ALL DISTINCT --返回所有匹配的行 select state from t_usa_covid19_p; --相当于 selectall state from t_usa_covid19_p; --返回所有匹配的行 去除重复的结果 selectdistinct state from t_usa_covid19_p; --多个字段distinct 整体去重 select county,state from t_usa_covid19_p; selectdistinct county,state from t_usa_covid19_p; selectdistinct sex from student;
典型错误如下
1 2 3 4 5 6 7 8 9 10 11 12 13
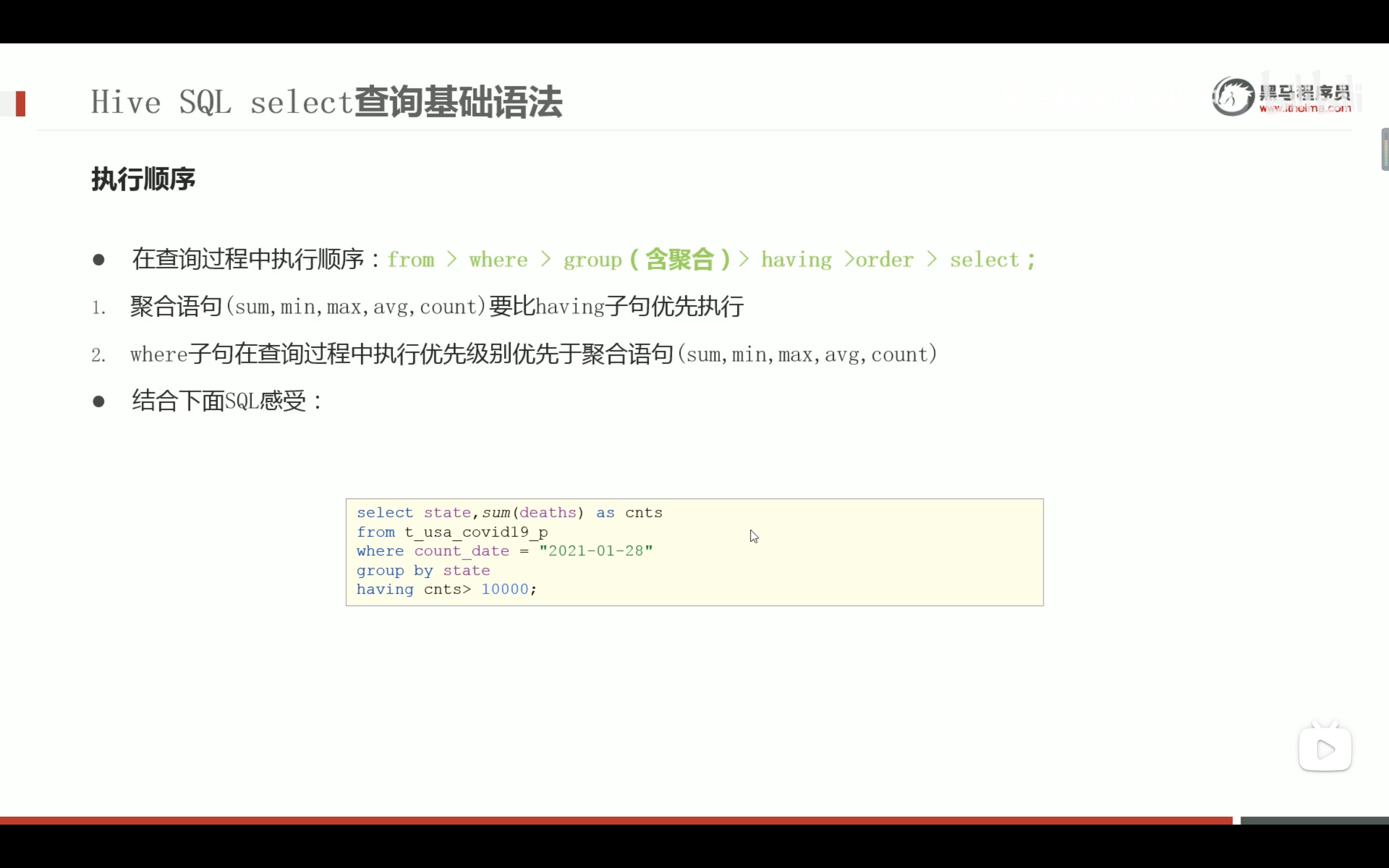
--先where分组前过滤(此处是分区裁剪),再进行group by分组, 分组后每个分组结果集确定 再使用having过滤 select state,sum(deaths) from t_usa_covid19_p where count_date = "2021-01-28" groupby state havingsum(deaths) >10000;
--这样写更好 即在group by的时候聚合函数已经作用得出结果 having直接引用结果过滤 不需要再单独计算一次了 select state,sum(deaths) as cnts from t_usa_covid19_p where count_date = "2021-01-28" groupby state having cnts>10000;
1 2 3 4 5 6 7 8 9 10 11
--返回结果集的前5条 select * from t_usa_covid19_p where count_date = "2021-01-28" and state ="California" limit 5;
--返回结果集从第1行开始 共3行 select * from t_usa_covid19_p where count_date = "2021-01-28" and state ="California" limit 2,3; --注意 第一个参数偏移量是从0开始的
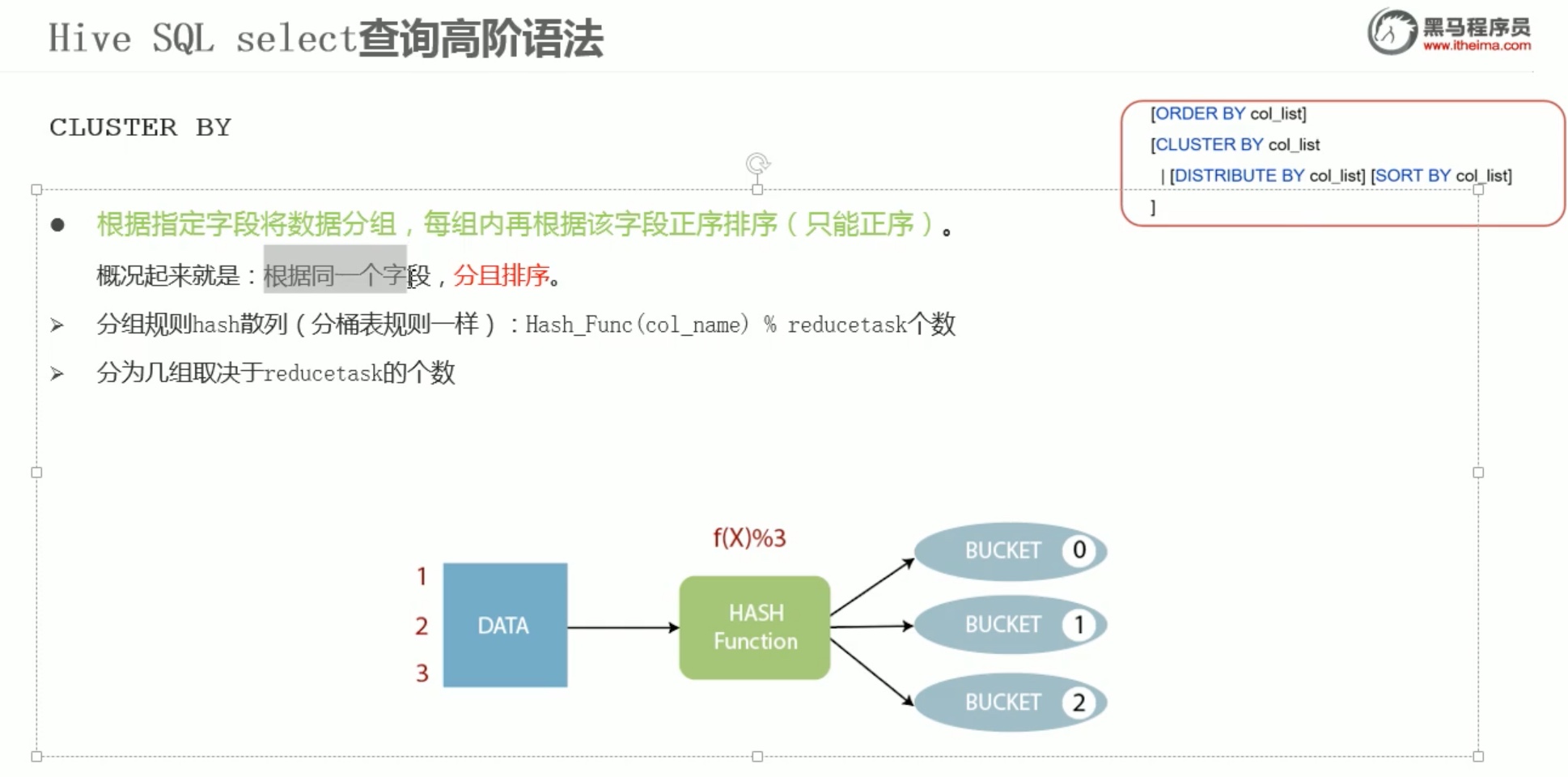
hash函数对2取mod,分成 奇偶 两个组,且每组排了序。
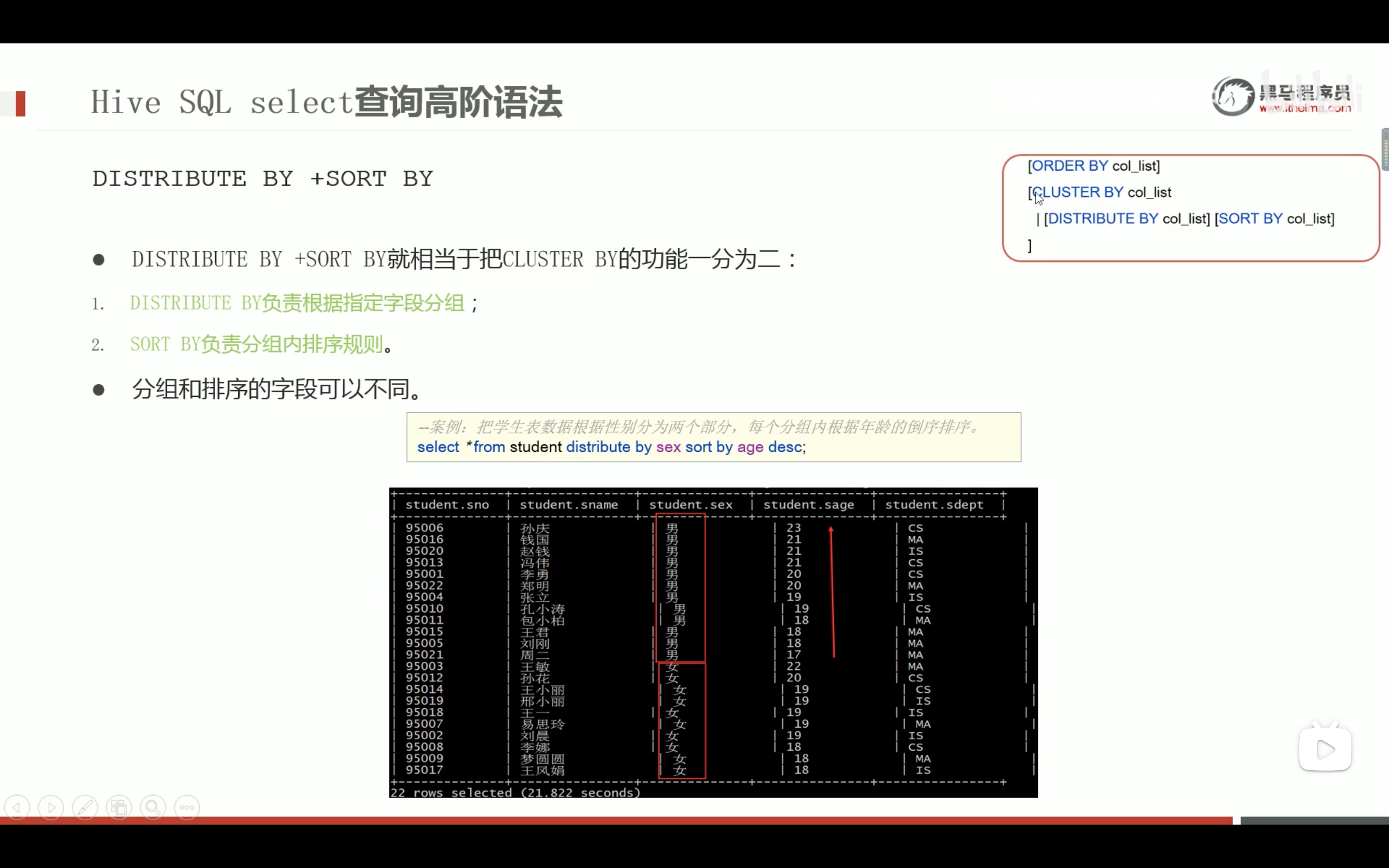
我们可以知道cluster by 的局限性,cluster by 的使用只能 针对同一个字段分组,且每组内排序只能是正序。 比如目的是按sex 分组且 按age的降序排列;这样的要求cluster by 就是不能满足的,若先cluster by 再 order by 会报错,因为order by 是全局排序的。
-----------------Common Table Expressions(CTE)----------------------------------- --select语句中的CTE with q1 as (select num,name,age from student where num =95002) select* from q1;
-- from风格 with q1 as (select num,name,age from student where num =95002) from q1 select*;
-- chaining CTEs 链式 with q1 as ( select*from student where num =95002), q2 as ( select num,name,age from q1) select*from (select num from q2) a;
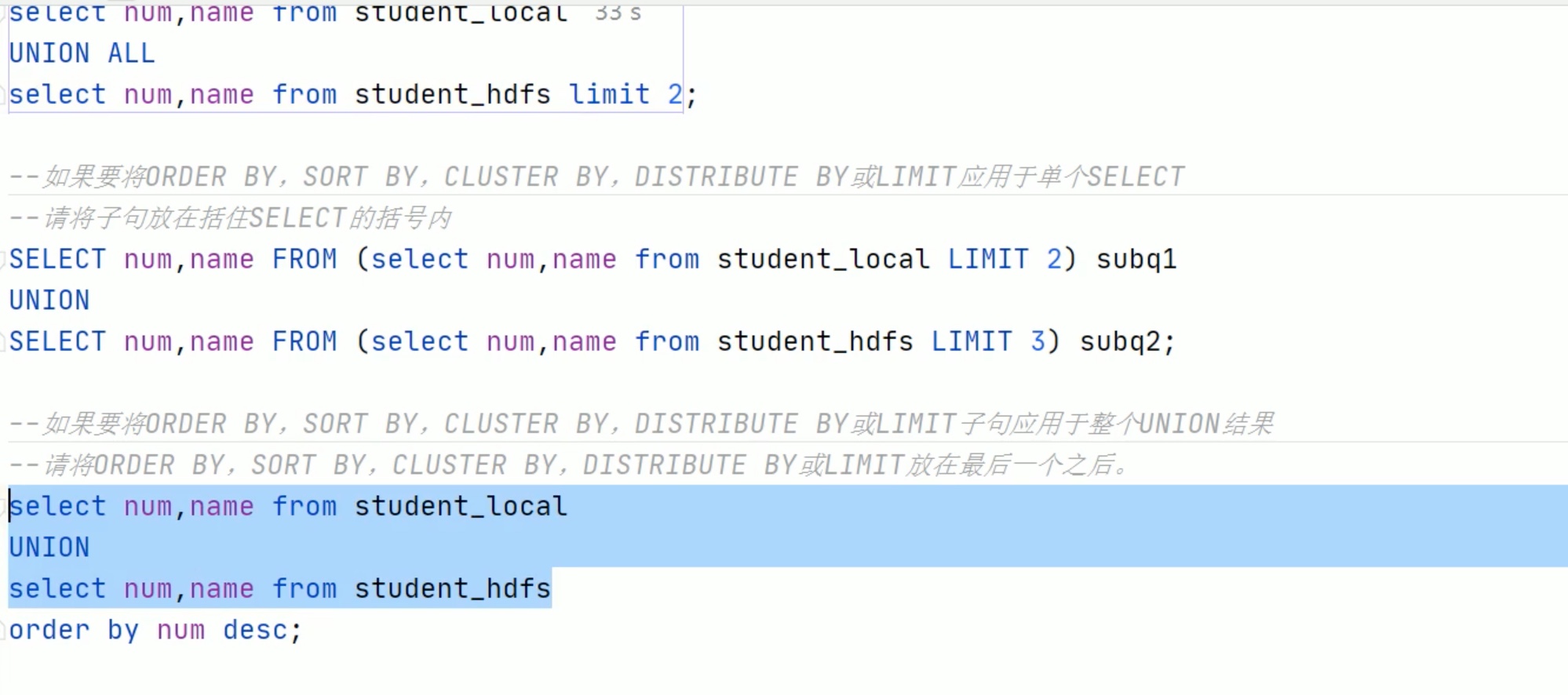
-- union with q1 as (select*from student where num =95002), q2 as (select*from student where num =95004) select*from q1 unionallselect*from q2;
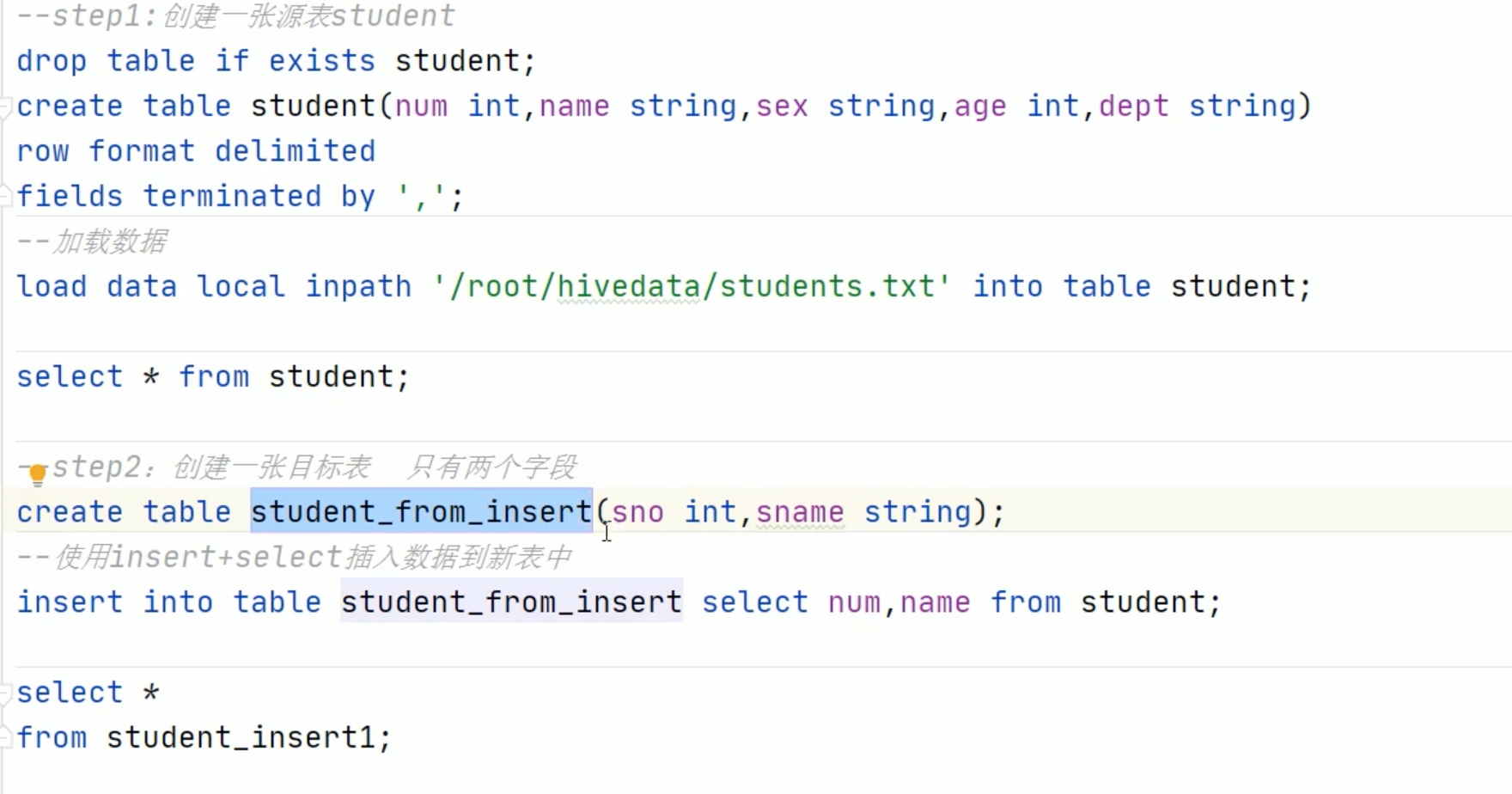
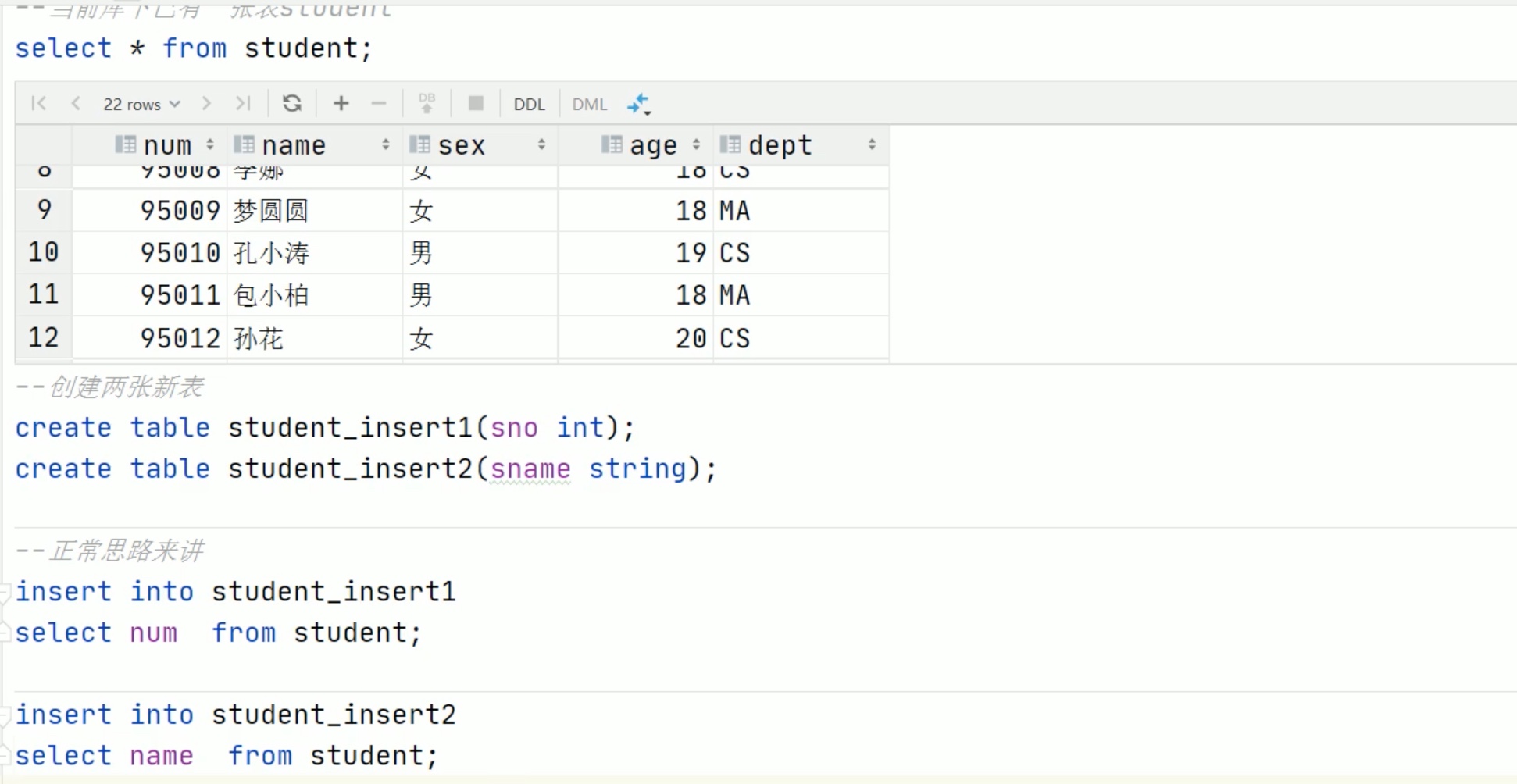
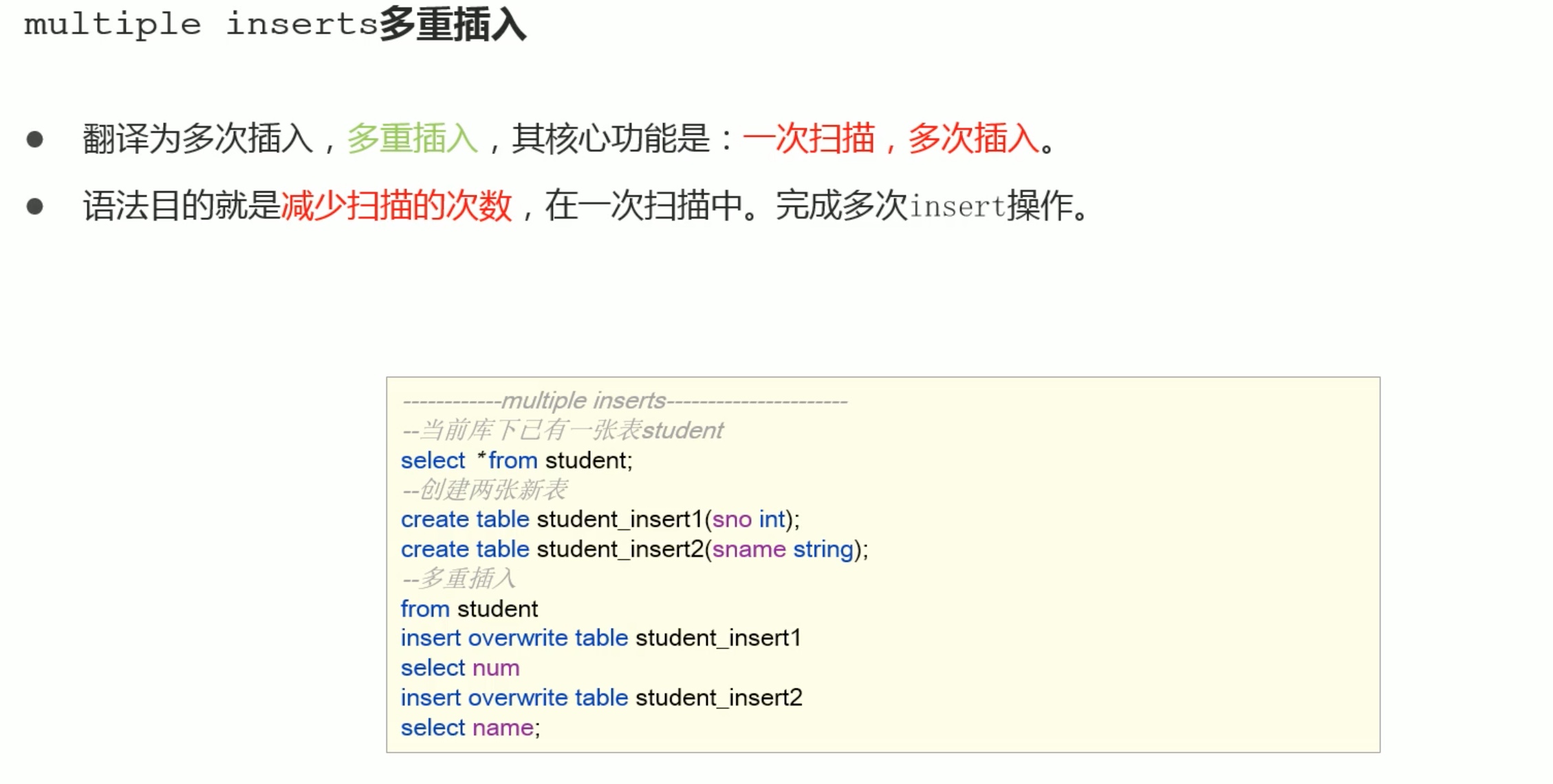
--视图,CTAS和插入语句中的CTE -- insert createtable s1 like student;
with q1 as ( select*from student where num =95002) from q1 insert overwrite table s1 select*;
select*from s1;
-- ctas createtable s2 as with q1 as ( select*from student where num =95002) select*from q1;
-- view createview v1 as with q1 as ( select*from student where num =95002) select*from q1;
mapper (filename, file-contents): for each word in file-contents: emit (word, 1) # 遇到重复的word, 就把 values 的后面再追加一个 1,values初始是 [1],遇到两次相同word ,values就变成 [1,1];丰富出多个 键值对。 reducer (word, values): sum = 0 for each value in values: sum = sum + value emit (word, sum) # 给出一个键值对 :{word单词 : 出现次数的统计}