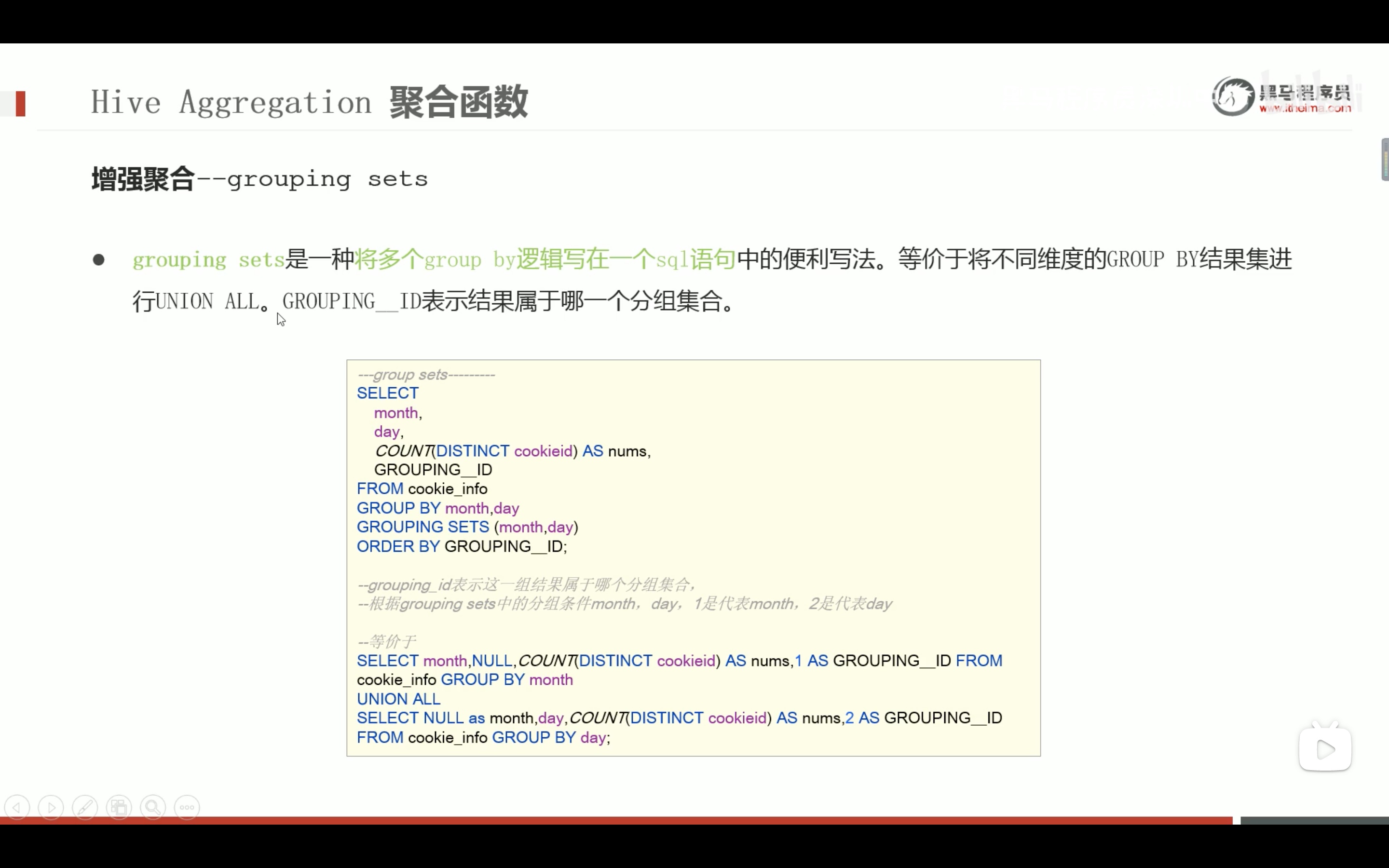
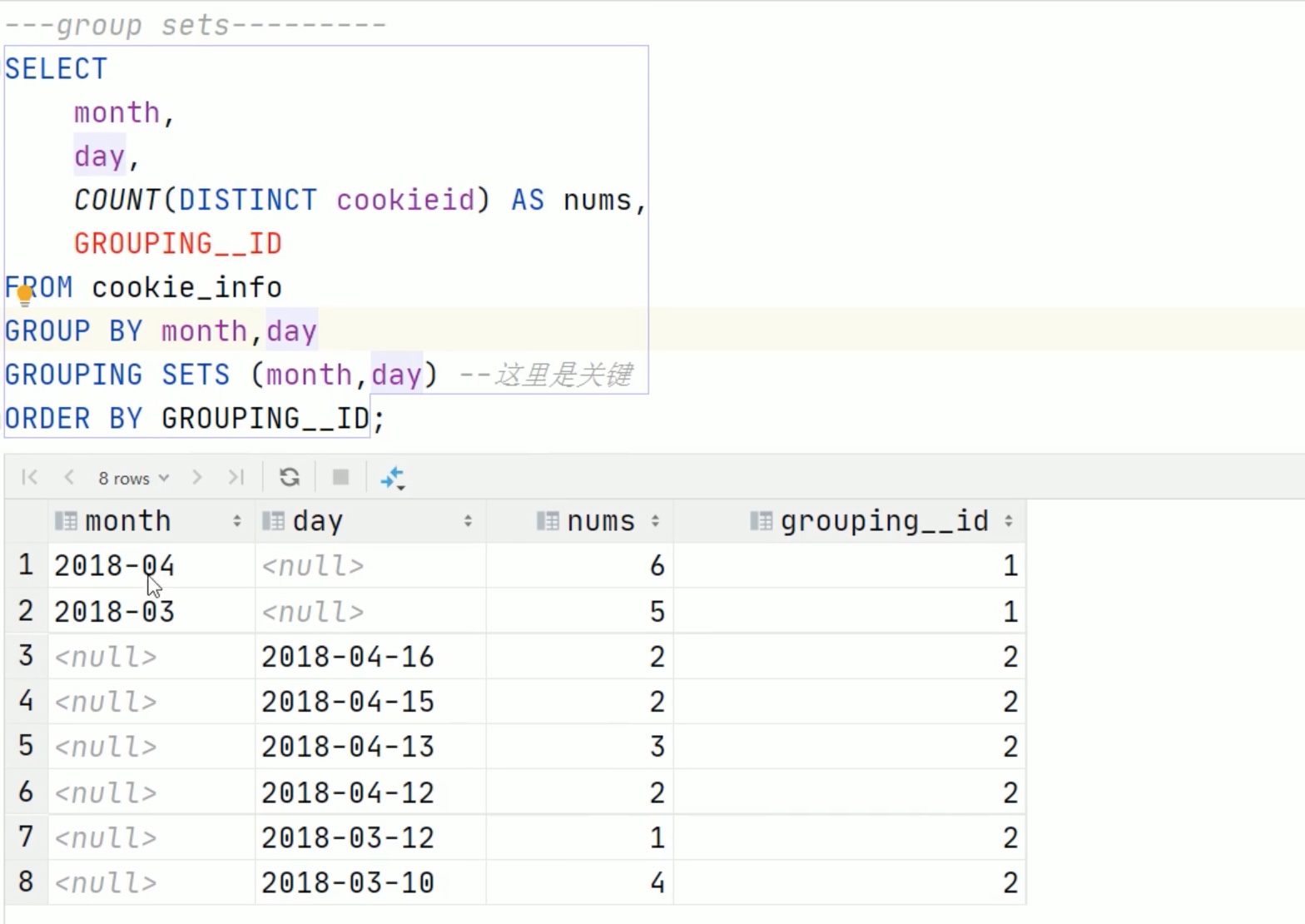
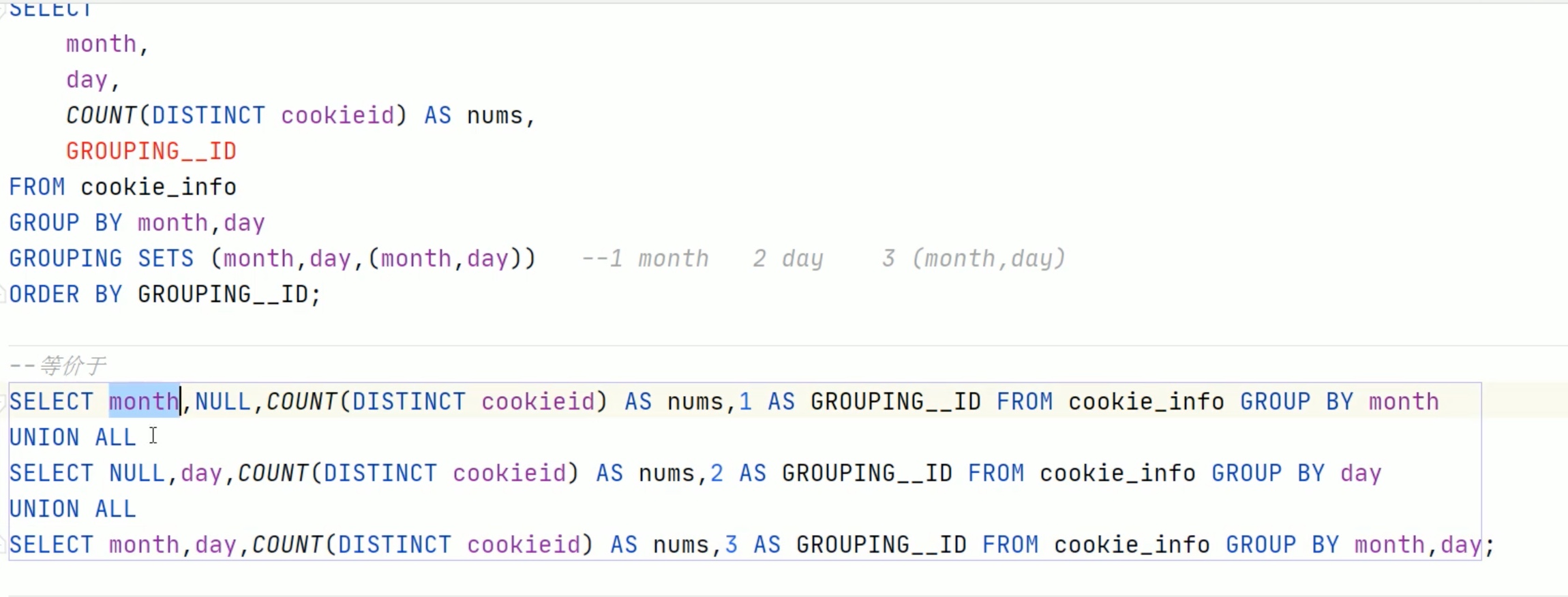
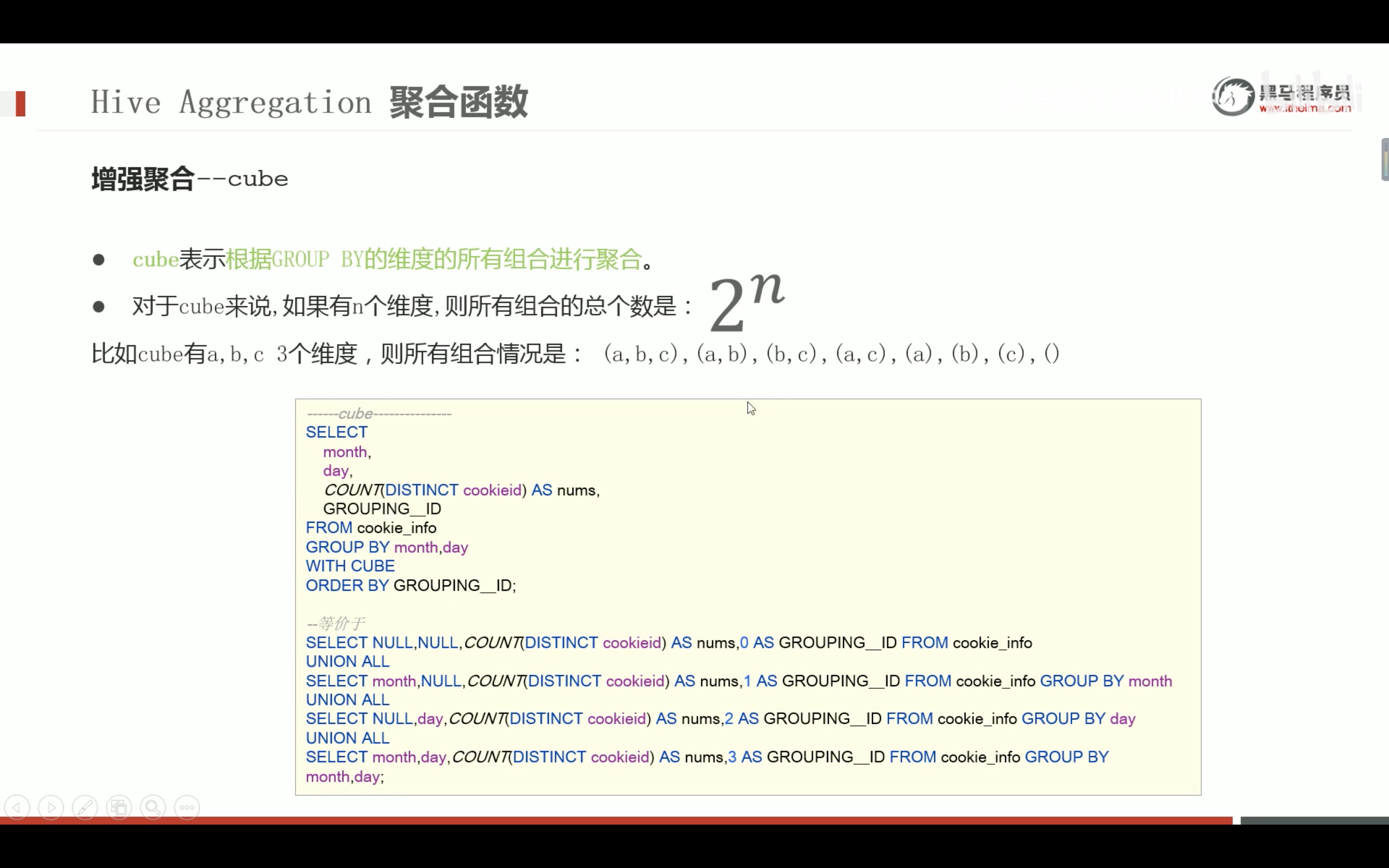
--is not null 非空值判断 select1from dual where'itcast'isnotnull;
--like比较: _表示任意单个字符 %表示任意数量字符 --否定比较: NOT A like B select1from dual where'itcast'like'it_'; select1from dual where'itcast'like'it%'; select1from dual where'itcast'notlike'hadoo_'; select1from dual wherenot'itcast'like'hadoo_';
Hive逻辑运算符 --与操作: A AND B 如果A和B均为TRUE,则为TRUE,否则为FALSE。如果A或B为NULL,则为NULL。 select1from dual where3>1and2>1; --或操作: A OR B 如果A或B或两者均为TRUE,则为TRUE,否则为FALSE。 select1from dual where3>1or2!=2; --非操作: NOT A 、!A 如果A为FALSE,则为TRUE;如果A为NULL,则为NULL。否则为FALSE。 select1from dual wherenot2>1; select1from dual where!2=1; --在:A IN (val1, val2, ...) 如果A等于任何值,则为TRUE。 select1from dual where11in(11,22,33); --不在:A NOT IN (val1, val2, ...) 如果A不等于任何值,则为TRUE select1from dual where11notin(22,33,44); --逻辑是否存在: [NOT] EXISTS (subquery) --将主查询的数据,放到子查询中做条件验证,根据验证结果(TRUE 或 FALSE)来决定主查询的数据结果是否得以保留。 select A.*from A whereexists (select B.id from B where A.id = B.id);
--if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull) select if(1=2,100,200); select if(sex ='男','M','W') from student limit 3;
--空判断函数: isnull( a ) select isnull("allen"); select isnull(null);
--非空判断函数: isnotnull ( a ) select isnotnull("allen"); select isnotnull(null);
--空值转换函数: nvl(T value, T default_value) select nvl("allen","itcast"); select nvl(null,"itcast"); --非空查找函数: COALESCE(T v1, T v2, ...) --返回参数中的第一个非空值;如果所有值都为NULL,那么返回NULL selectCOALESCE(null,11,22,33); selectCOALESCE(null,null,null,33); selectCOALESCE(null,null,null);
--条件转换函数: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END selectcase100when50then'tom'when100then'mary'else'tim'end; selectcase sex when'男'then'male'else'female'endfrom student limit 3;
--nullif( a, b ): -- 如果a = b,则返回NULL,否则返回一个 selectnullif(11,11); selectnullif(11,12);
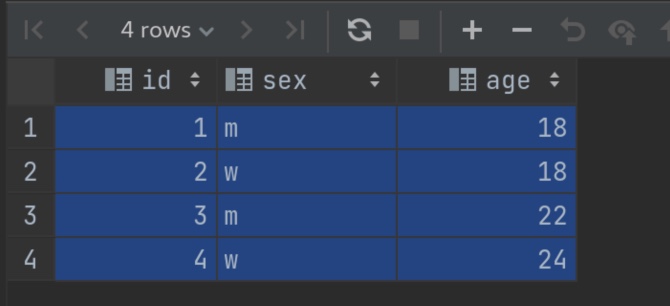
droptable t_python_test; createtable t_python_test( id int, sex string, age int )row format delimited fields terminated by "\t";
load data local inpath '/opt/data/python_test.txt'intotable t_python_test; # 加载数据 select*from t_python_test; # 原表如下
2、写python脚本;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
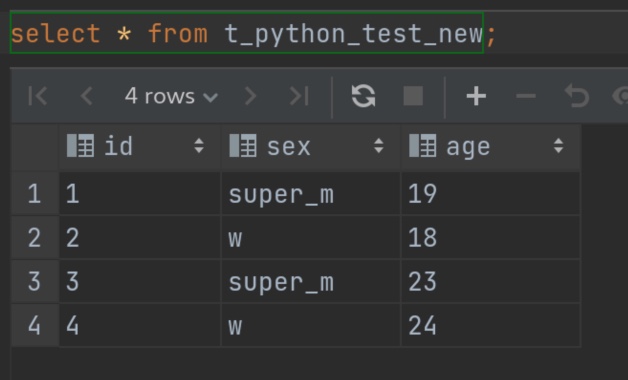
# coding:utf-8 import sys try: for line in sys.stdin: # python脚本以sys.stdin 读hive输入。其输入是以字段拼接字段而形成的字符串,这样的字符串有多行。 line = line.strip() # 读取一行,去头尾的空格。 [t_id,t_sex,t_age] = line.split('\t') #print( t_id,t_sex,t_age) if t_sex == 'm': t_age =int(t_age) + 1 t_sex = 'super_m' print('\t'.join([str(t_id),t_sex,str(t_age)])) # python脚本输出一个字符串,hive读取python脚本输出的时候会根据 字段名 自动切分好此字符串。 except print('\t'.join(['0','modify failed','0']))
注意:一定要记得在hive、Hadoop环境之外先用python检查一下有没有什么python编写错误,因为在hive里运行的速度太慢了,每一次排错都要花太多太多的时间,并且报错以后的提示看不到错在哪里,只是简单的说你的自定义脚本有问题Execution Error, return code 20003 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. An error occurred when trying to close the Operator running your custom script.。