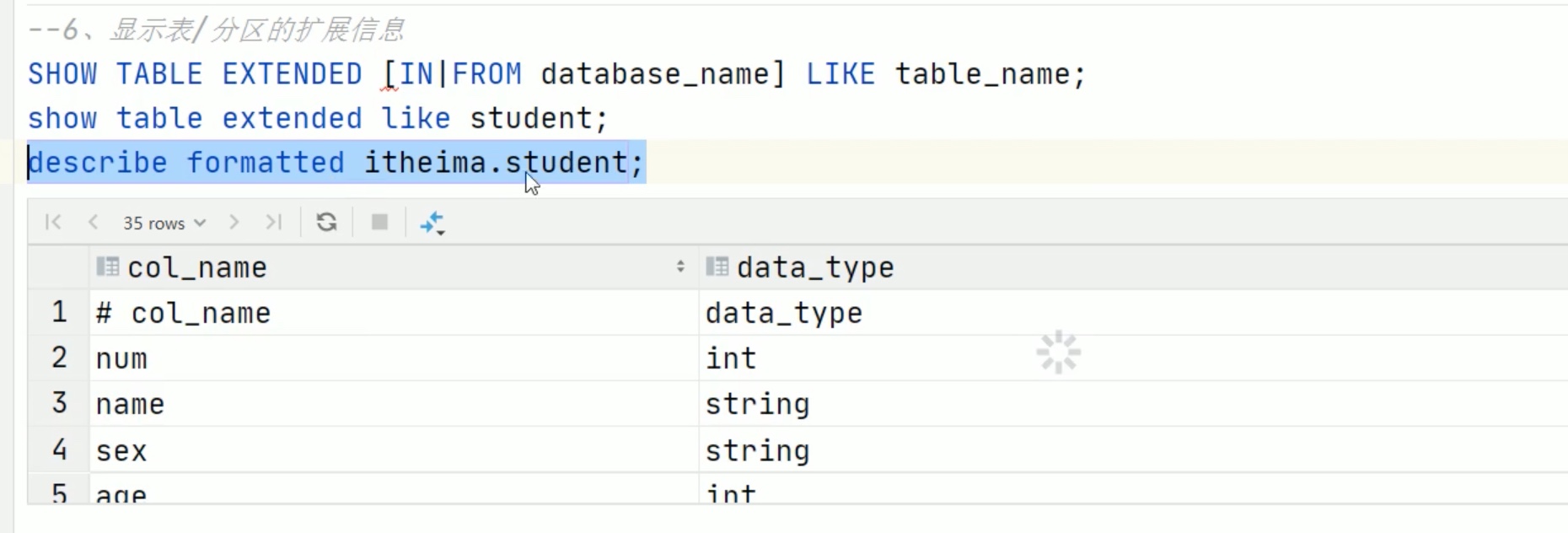
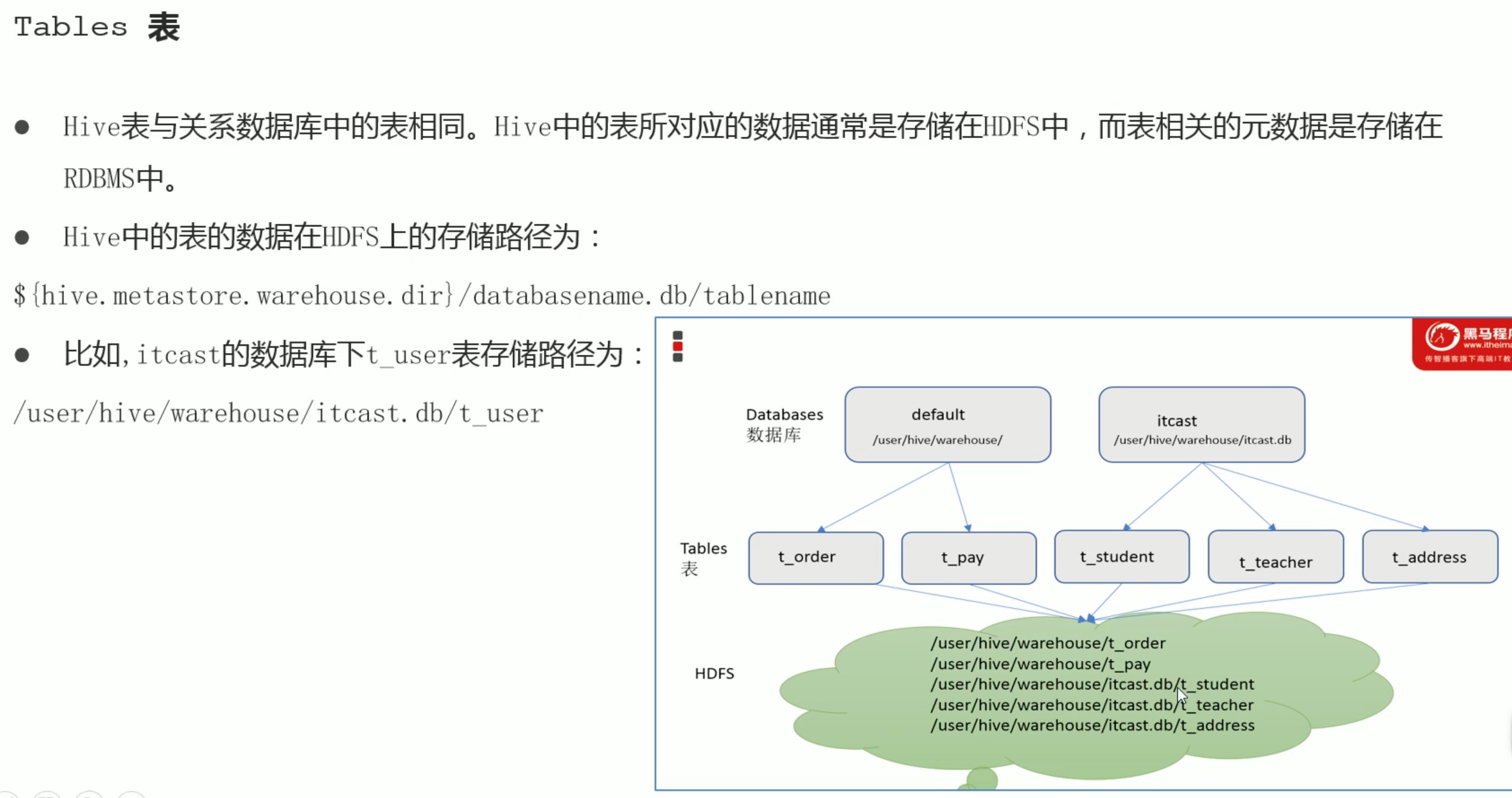
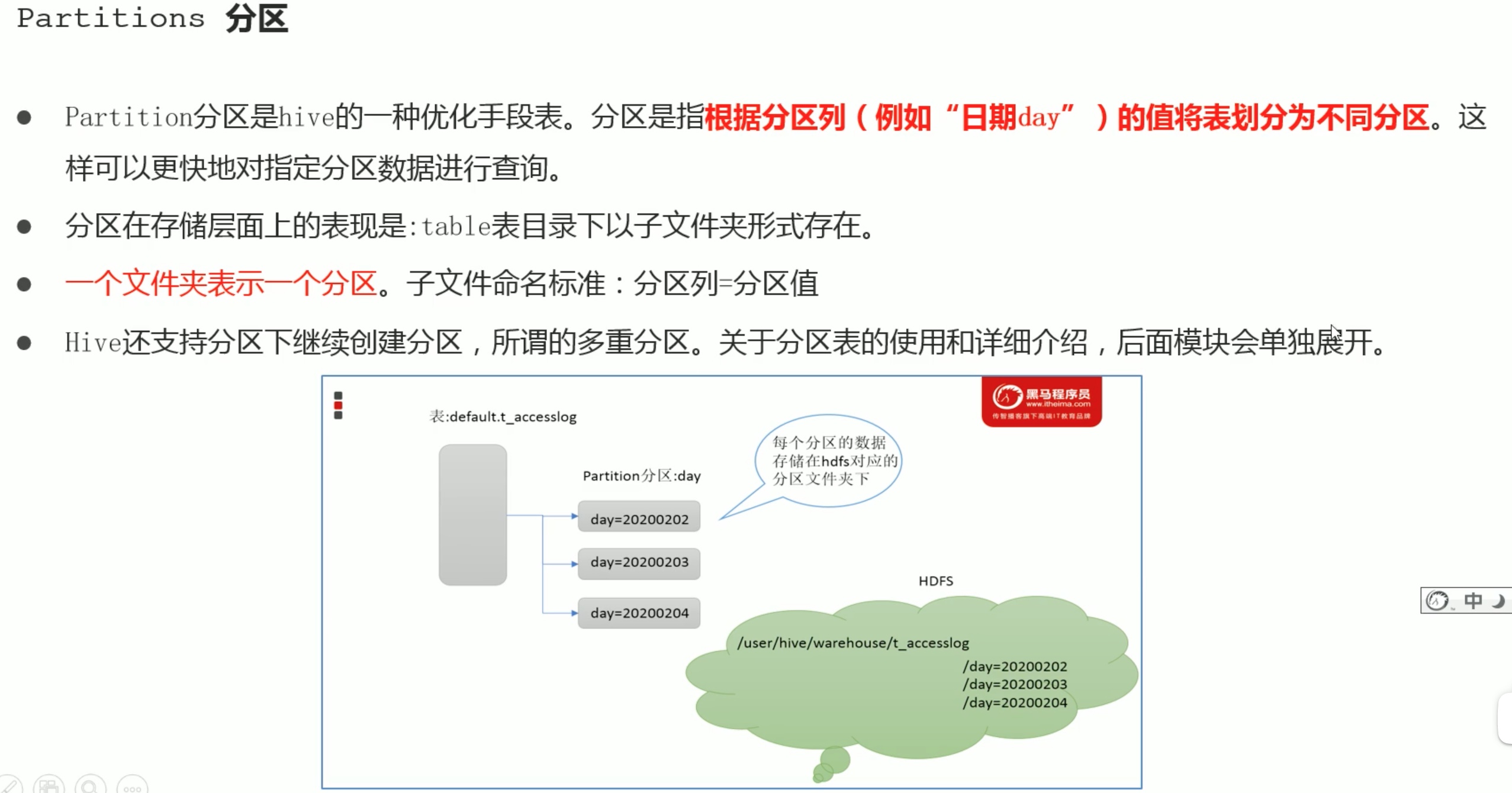
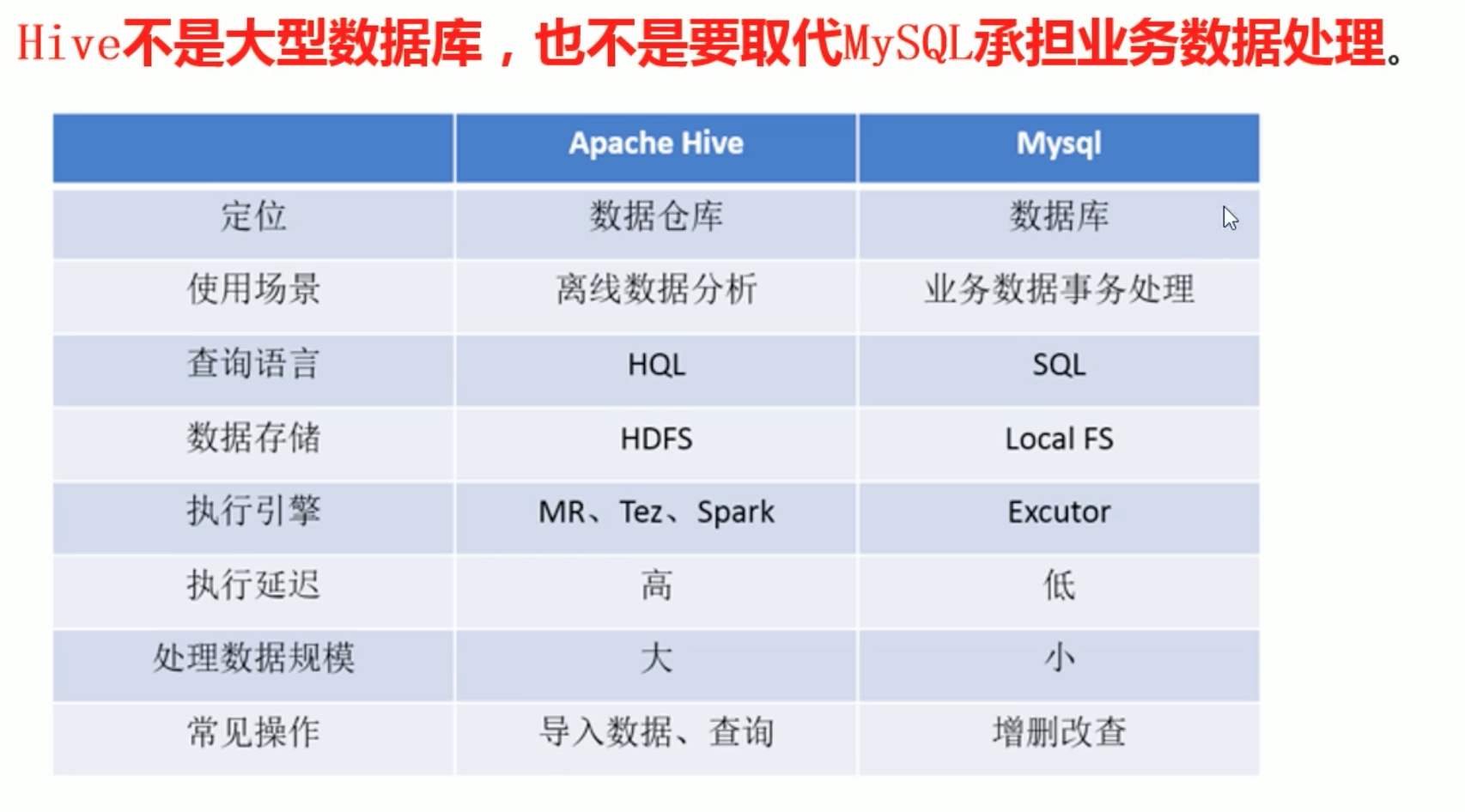
Hive_SQL数据定义语言_DDL
简介
简介

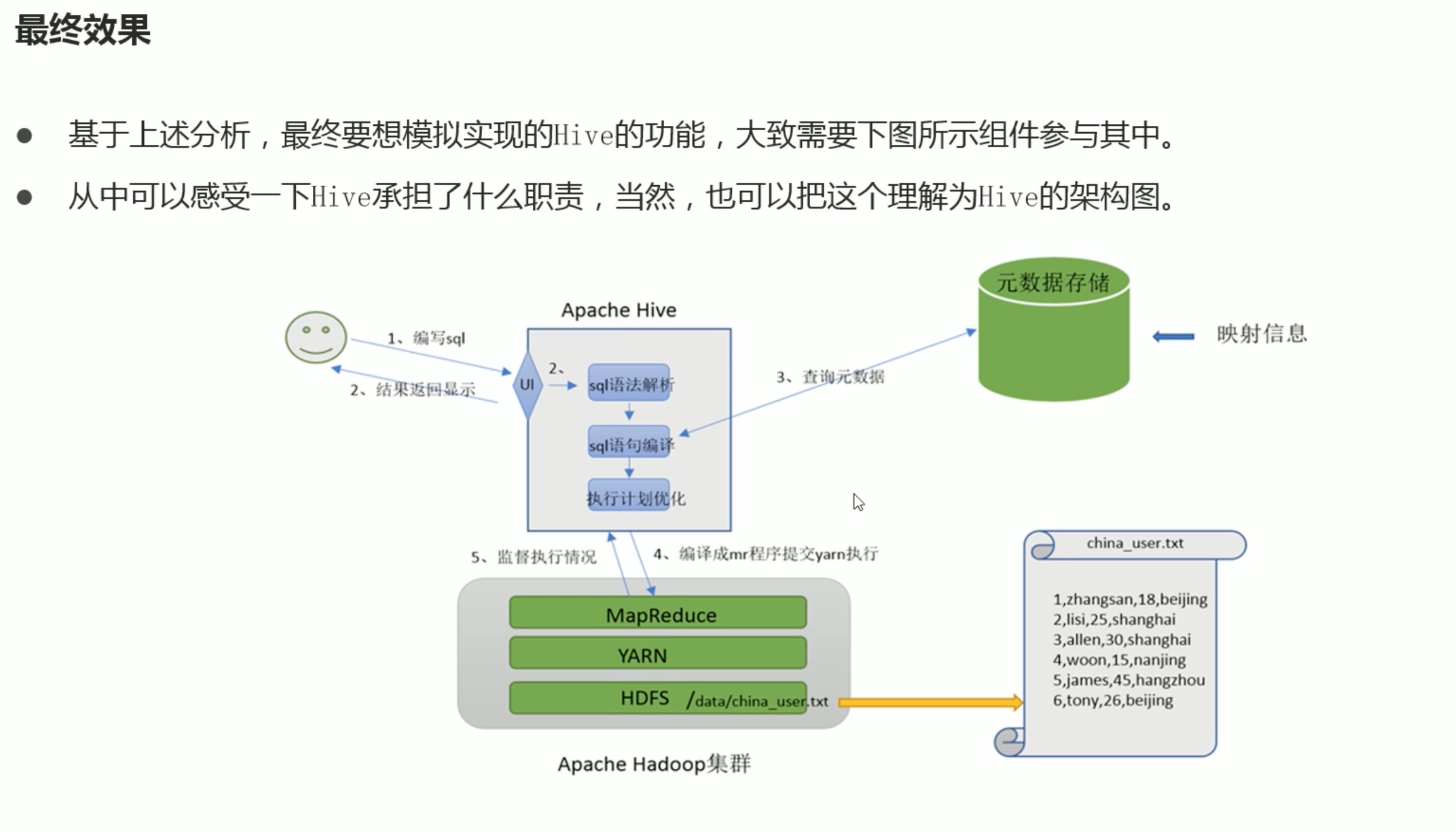
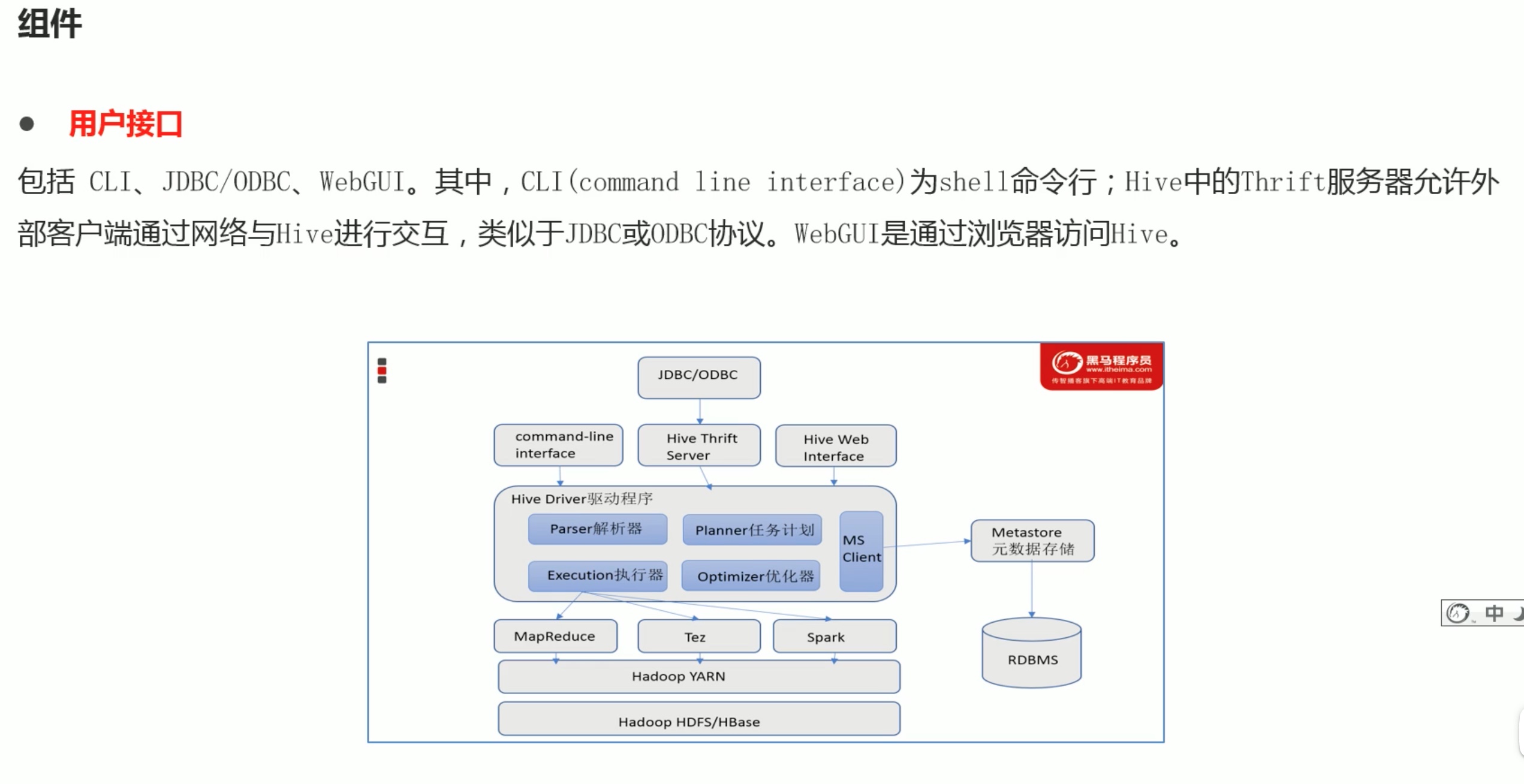
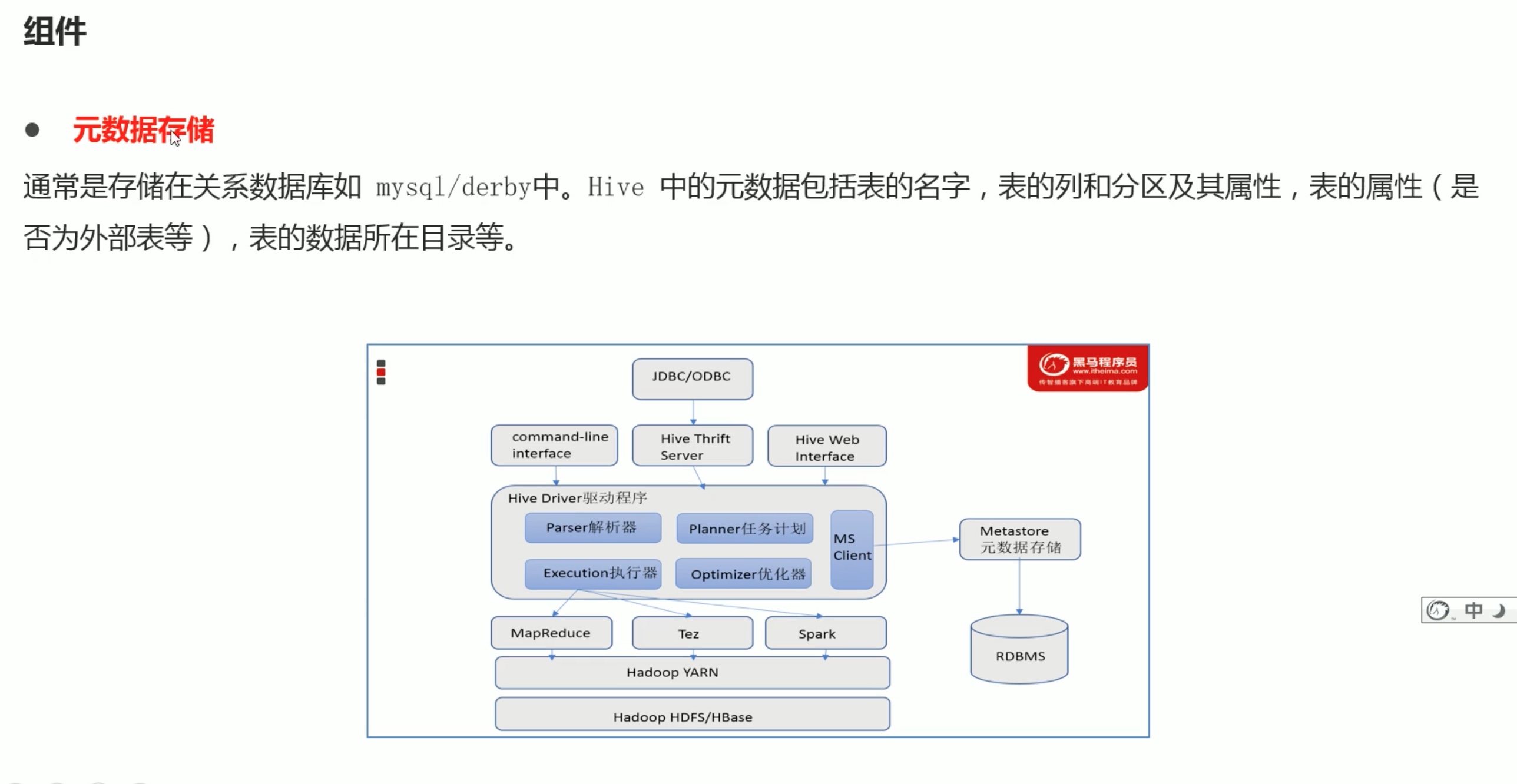
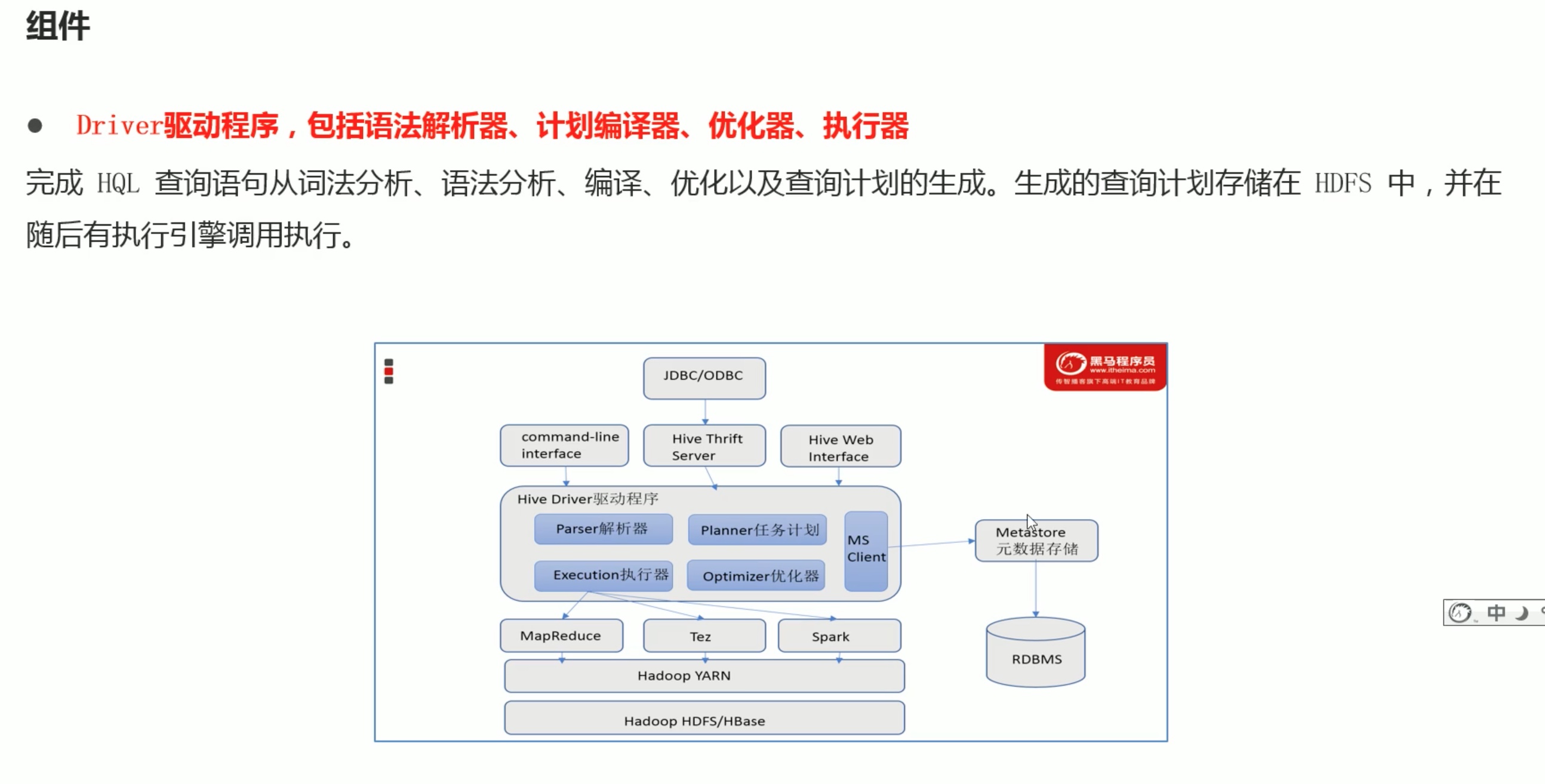
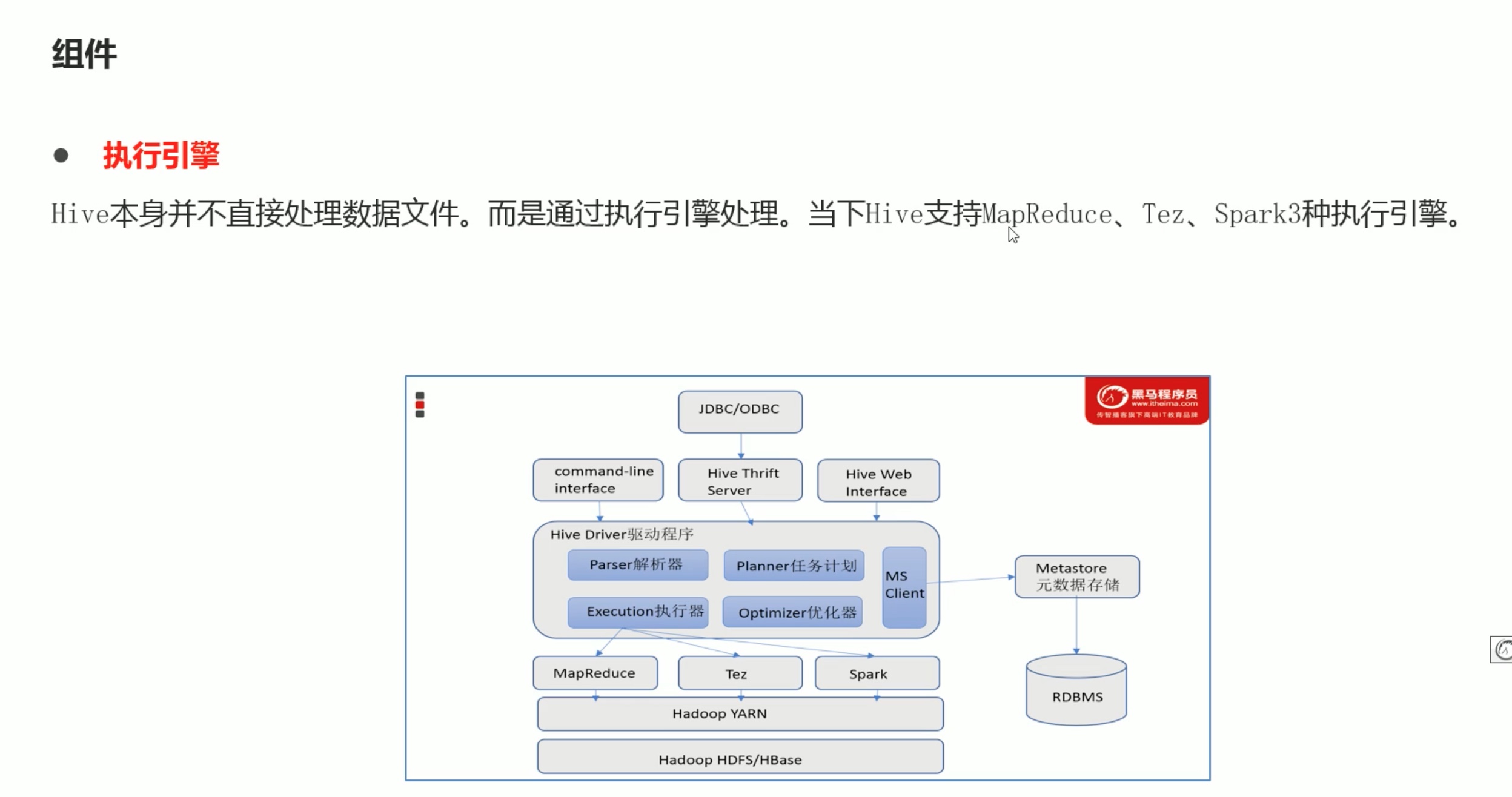

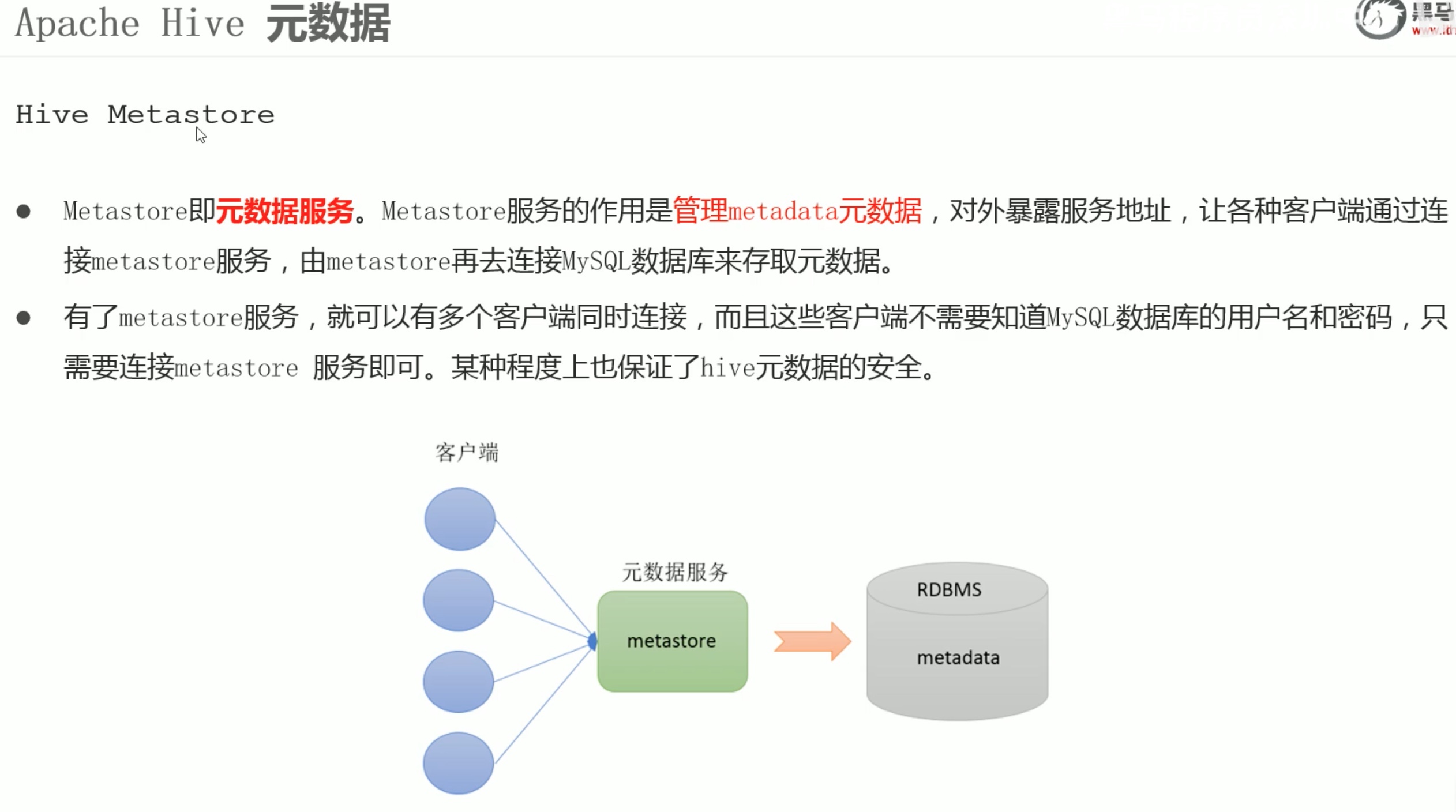


内嵌模式安装(这只是简介,具体的安装配置教程参考之前的hive安装笔记。):
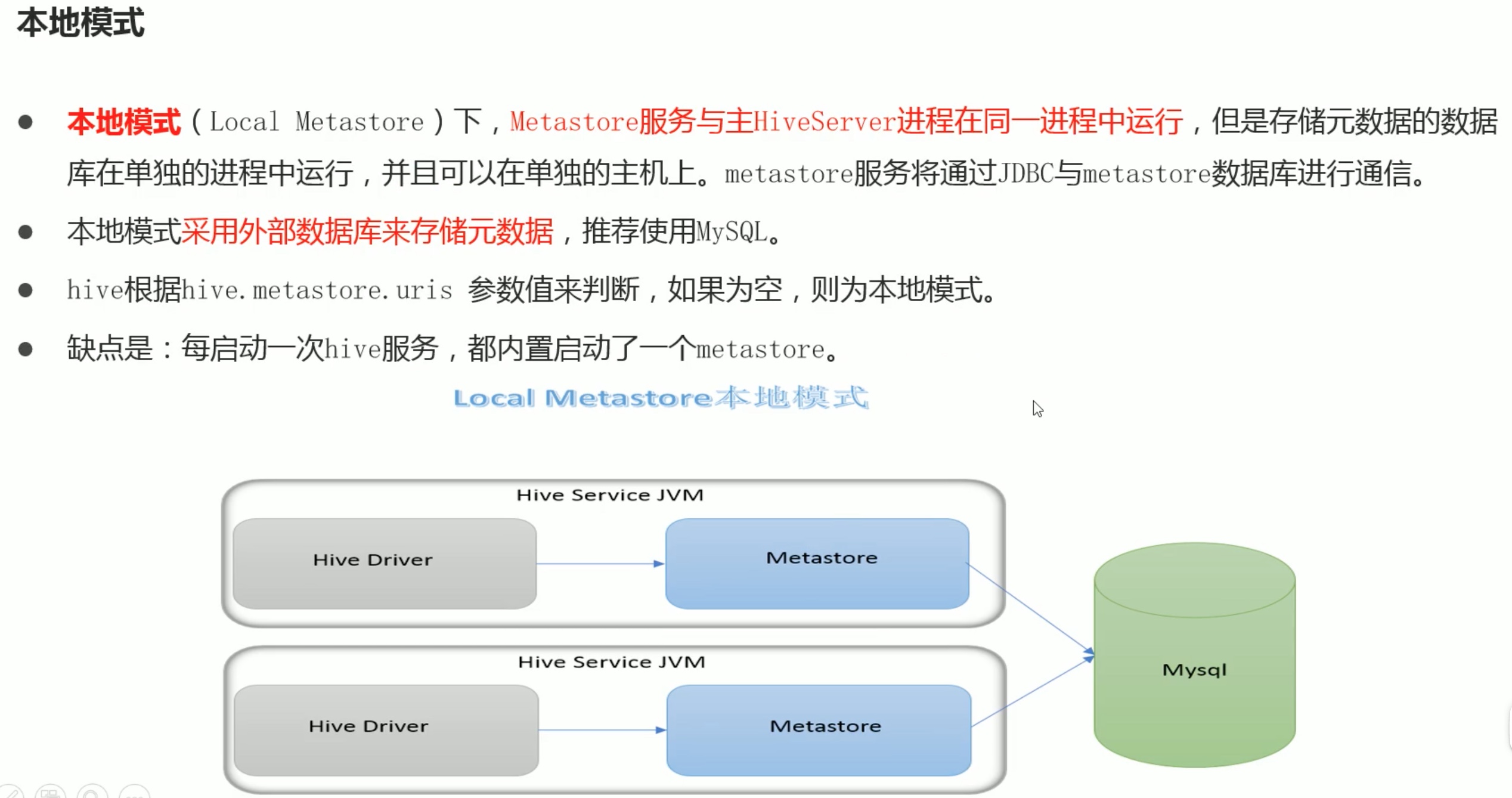
本地模式安装(这只是简介,具体的安装配置教程参考之前的hive安装笔记。):
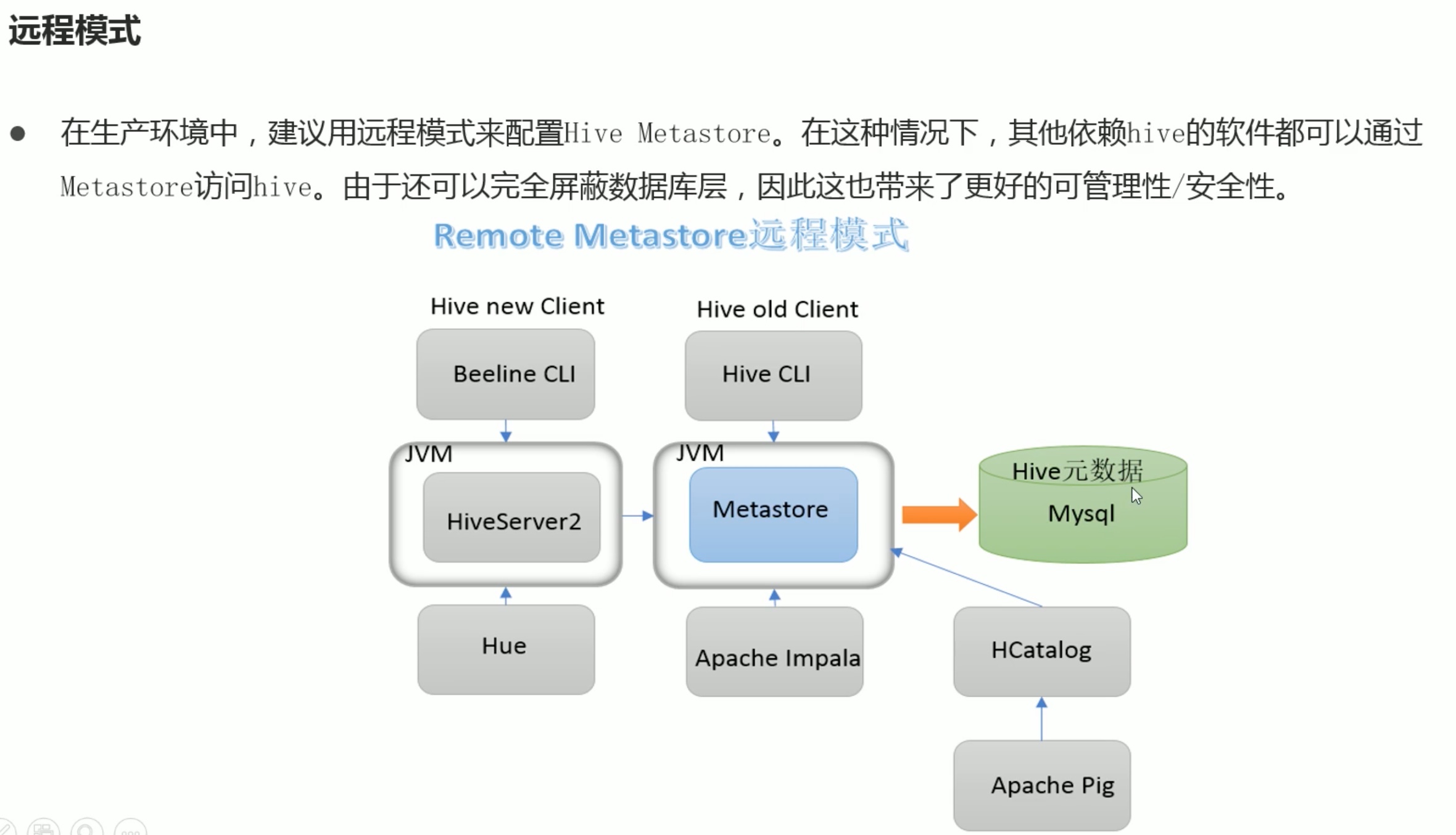
远程模式安装:

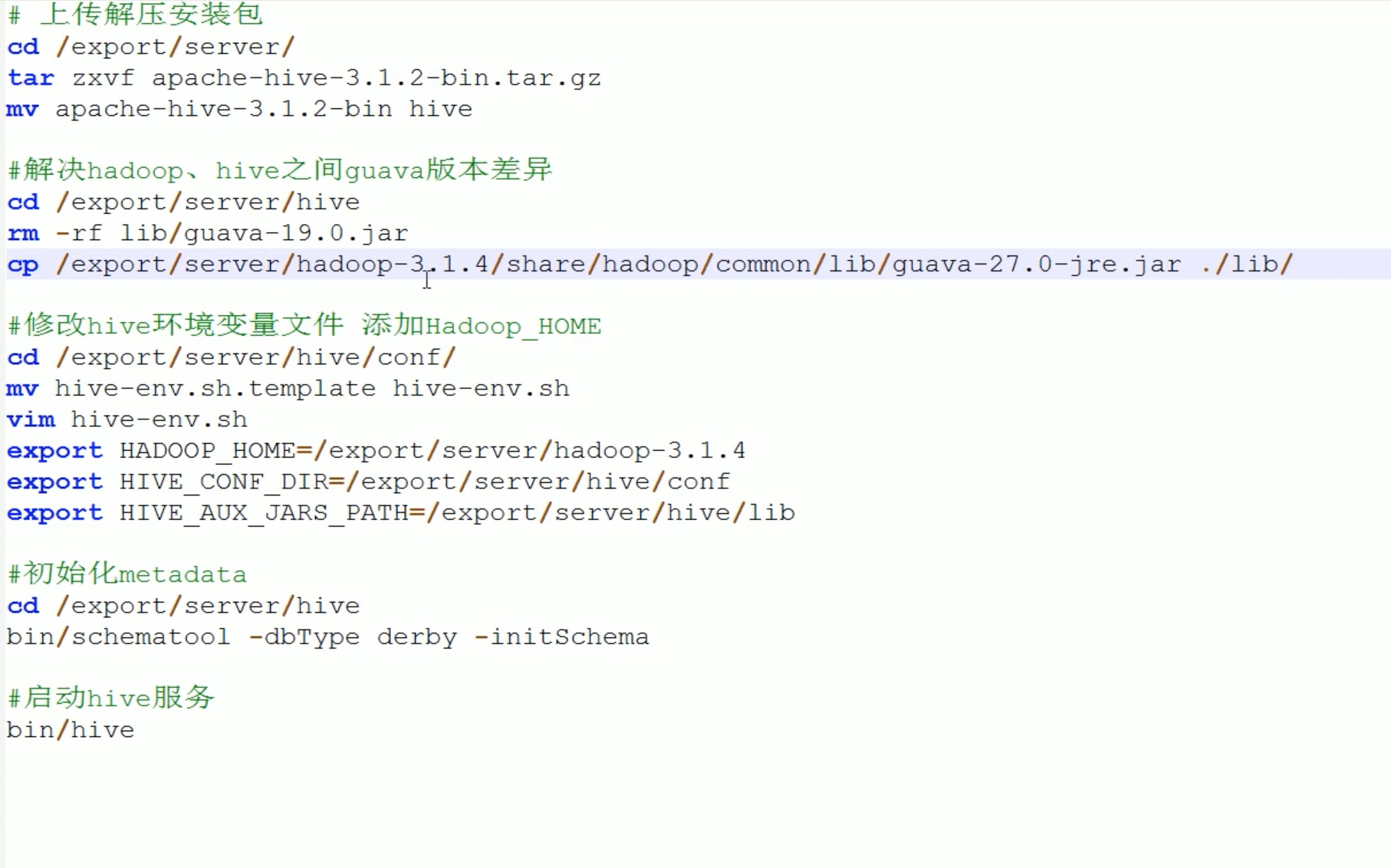
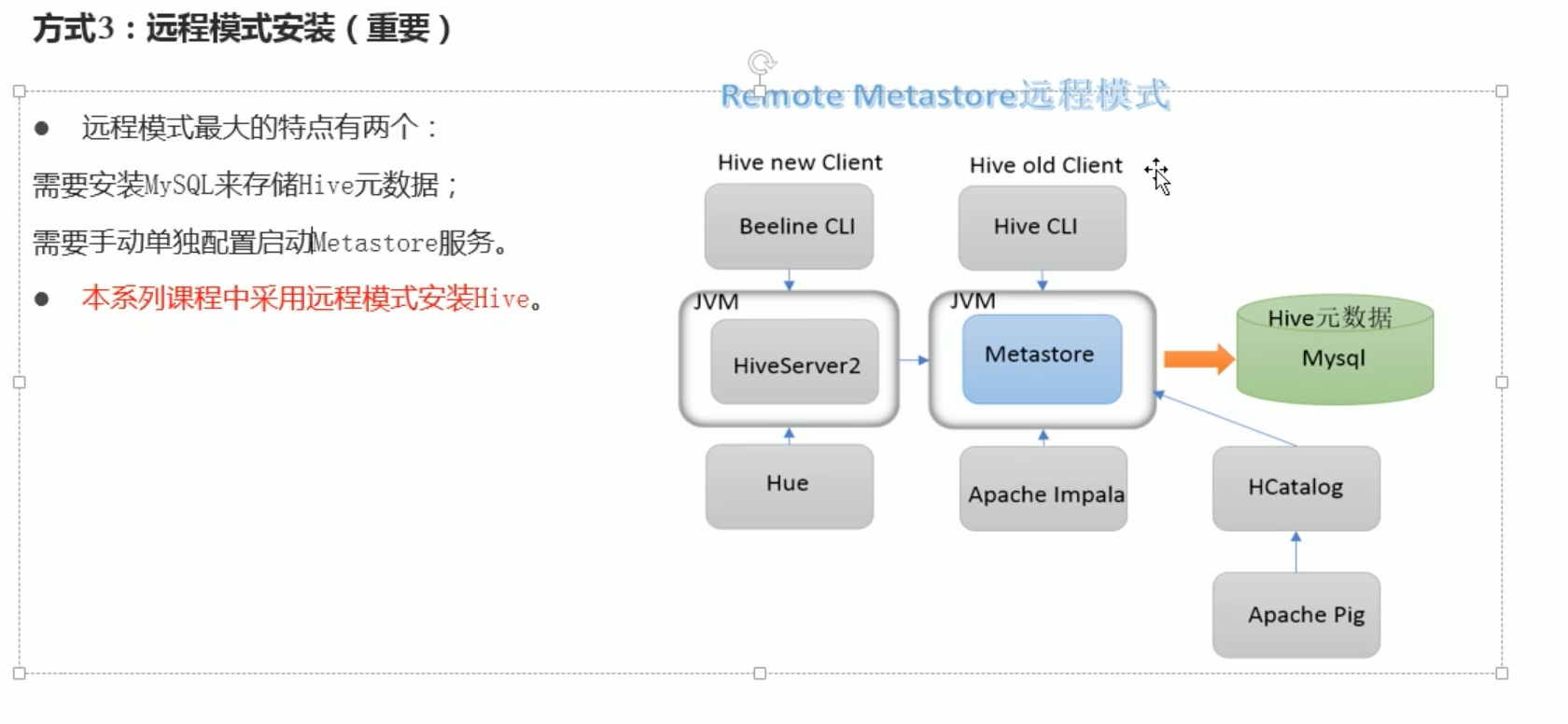
方式3 远程方式安装,这才是hive主要应用场景(这只是简介,具体的安装配置教程参考之前的hive安装笔记。):
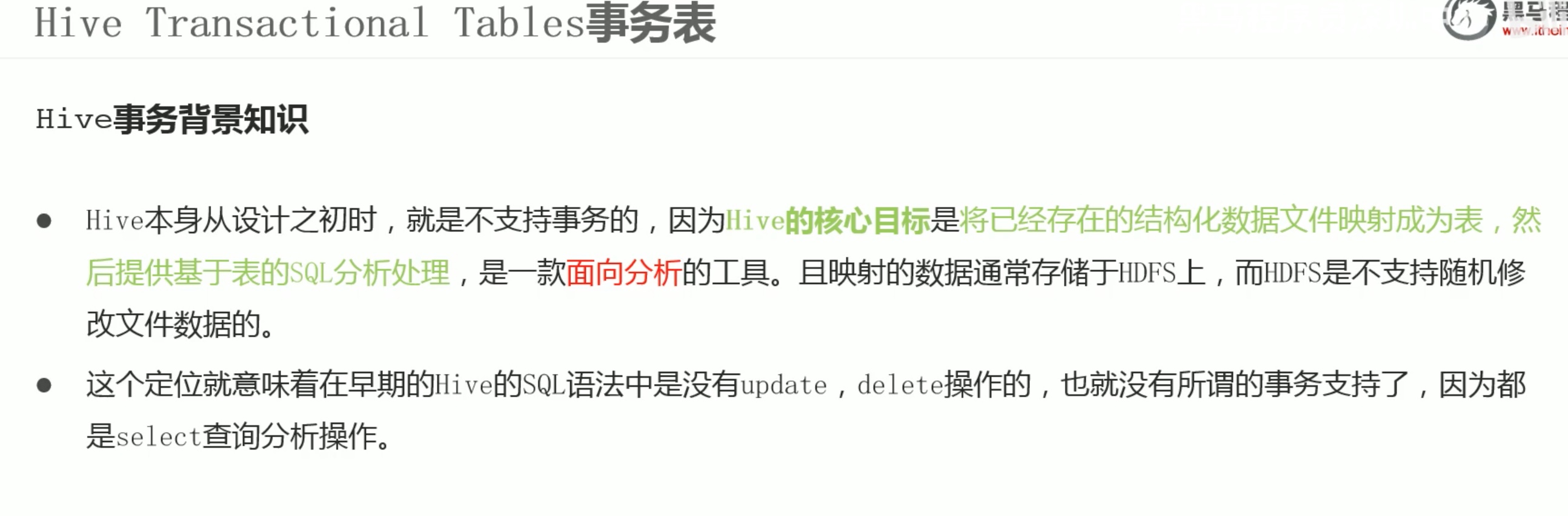
我们在用hive强行新建一个表,并插入数据时,速度很慢实际是运行一个java程序,此时我们打开yarn的监测端口可以看见一个mapreduce程序正在运行。
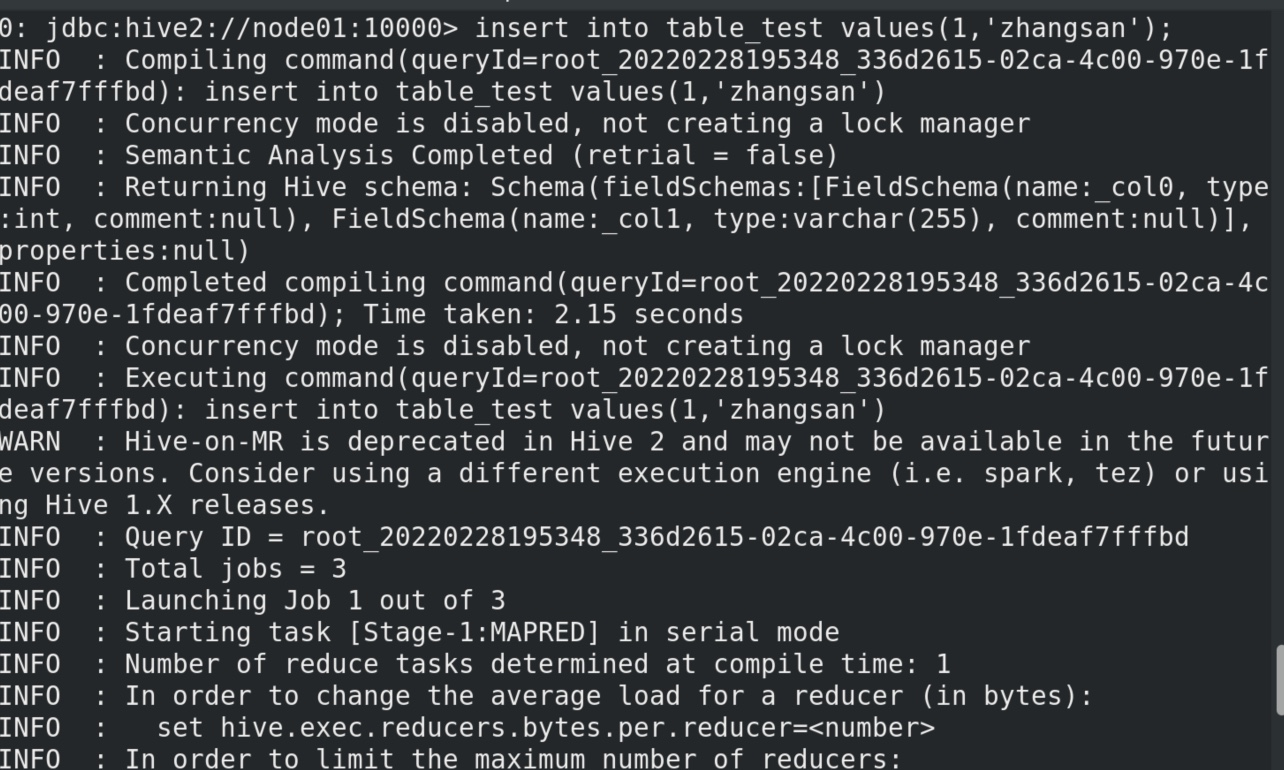
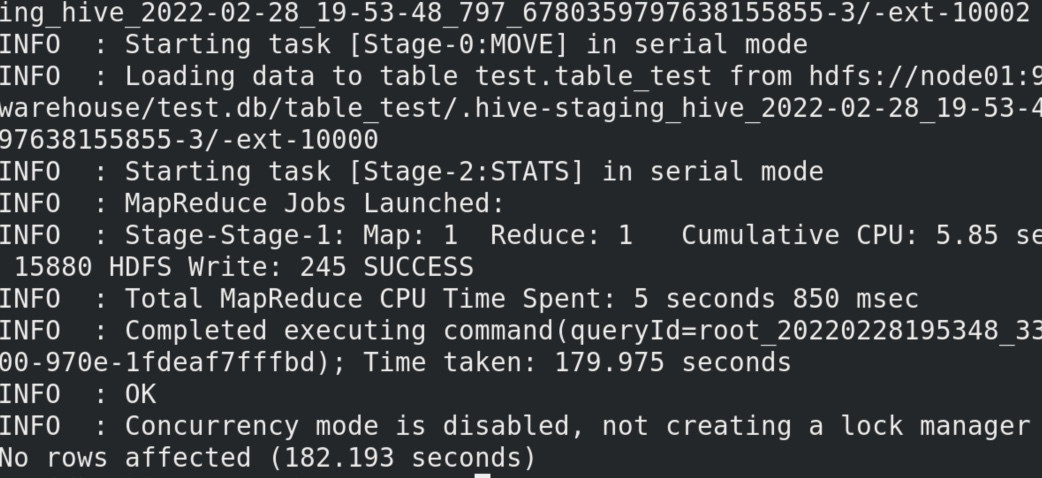
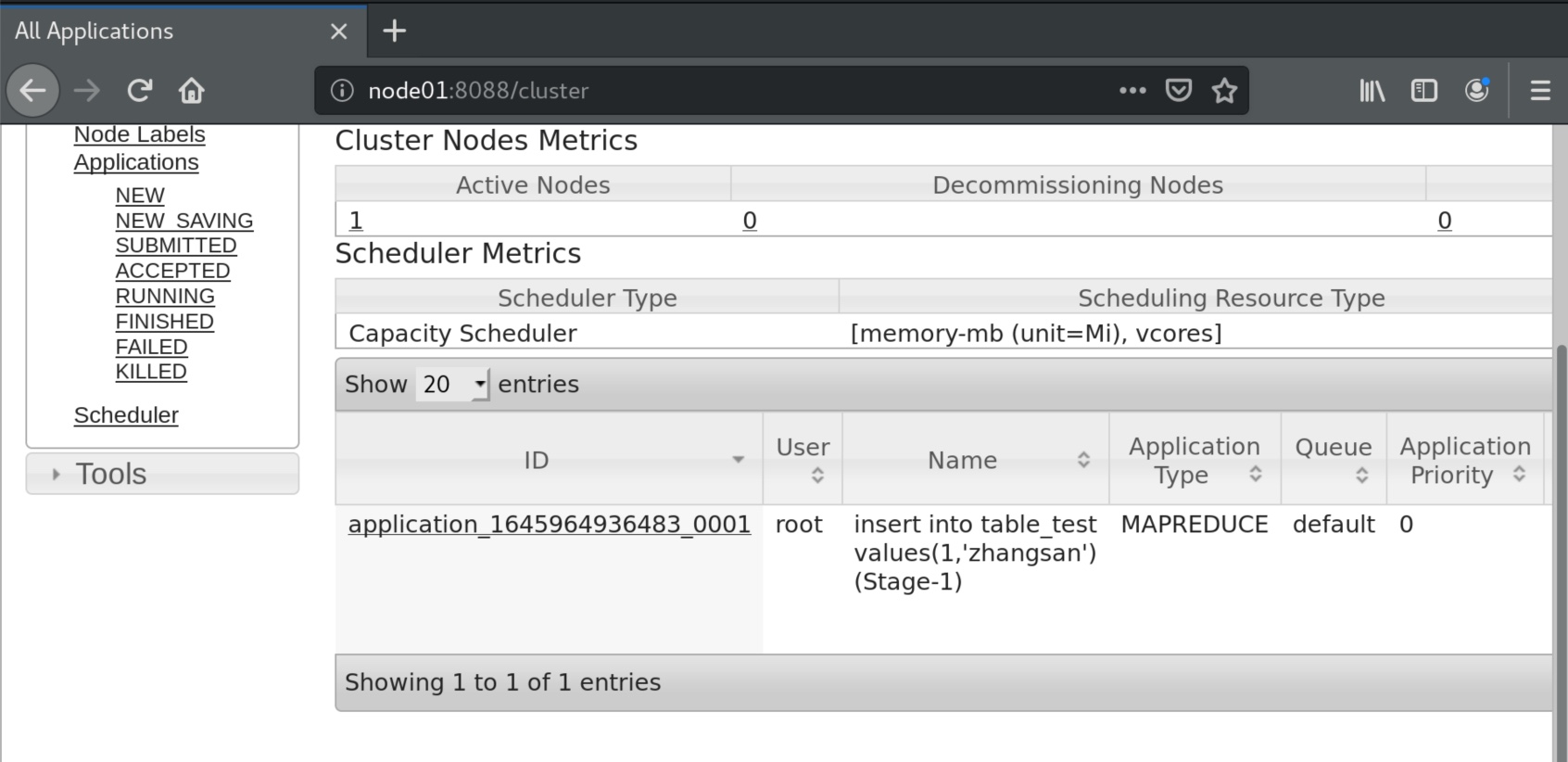
卧槽插入一条数据花了182秒,可见hive真的不是sql。
映射成表才是正解
1 | vim user.txt |
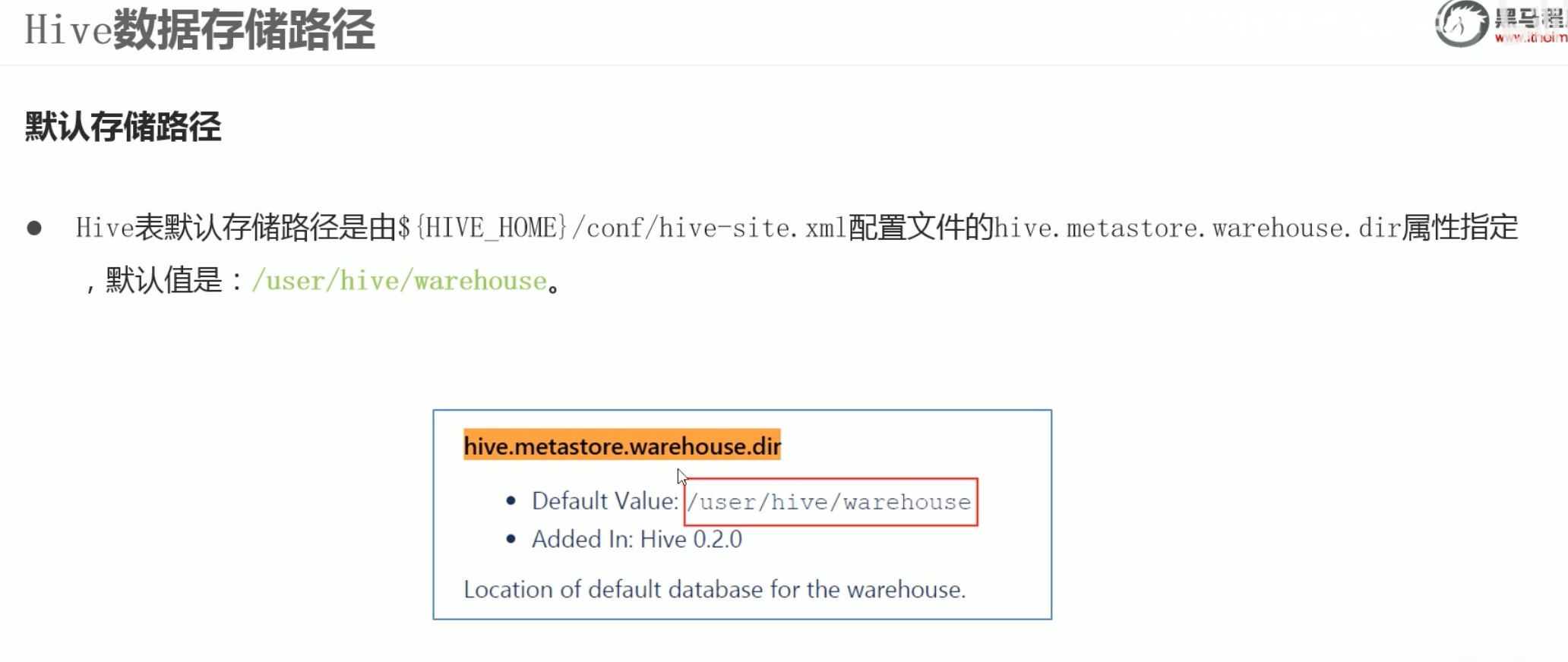
默认情况下,hive在 /user/hive/warehouse 中创建库和表。将我们刚才放在hdfs根目录的user.txt移动到 /user/hive/warehouse 与之对应的表中。
1 | bin/hadoop fs -mv /user.txt /user/hive/warehouse/test.db/table_test |
现在可以看见有东西存进来了,但是新的内容都是显示null,
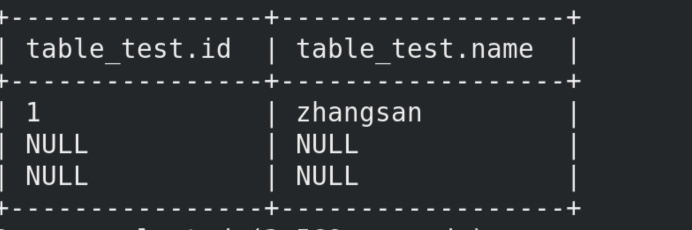
hive建立表的时间加上分隔符
1 | create table t_user(id int,name varchar(20))row format delimited fields terminated by ','; |
把user.txt 文件映射到指定位置的表中
1 | bin/hadoop fs -put user.txt /user/hive/warehouse/test.db/t_user |
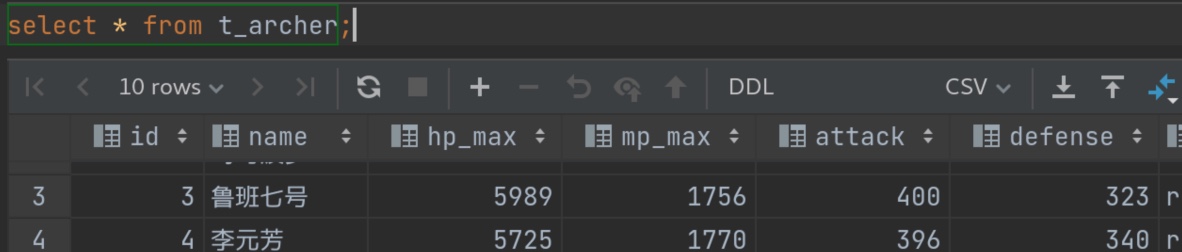
再在hive中 select * from t_user; 可见
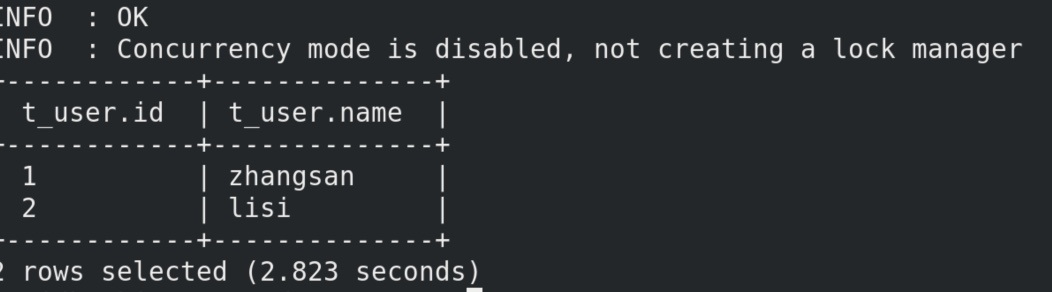
成功映射好了。
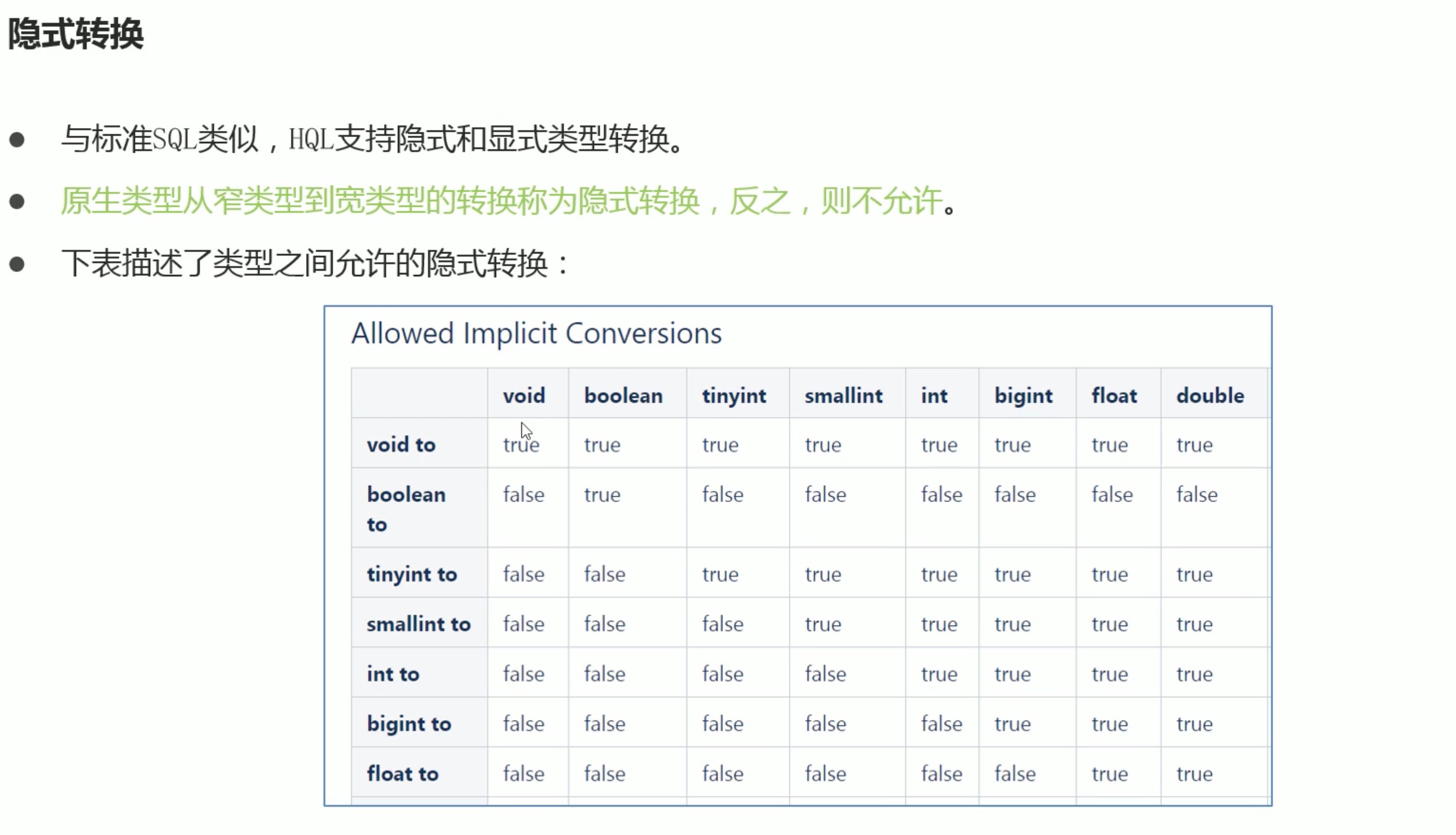
注意文件映射为表,hive会自己尝试着把类型对应,比如文件类型是int,映射的表中类型是varchar,那么hive可以帮我们自动类型转换,但是如果文件中类型是str字符串类型,表中定义时就定义了是int类型,hive自动类型转换str转int是转不过来的,有点像java的自动类型转换的级别特点。
所以建立表时,要把字段顺序和字段类型和文件保持一致。

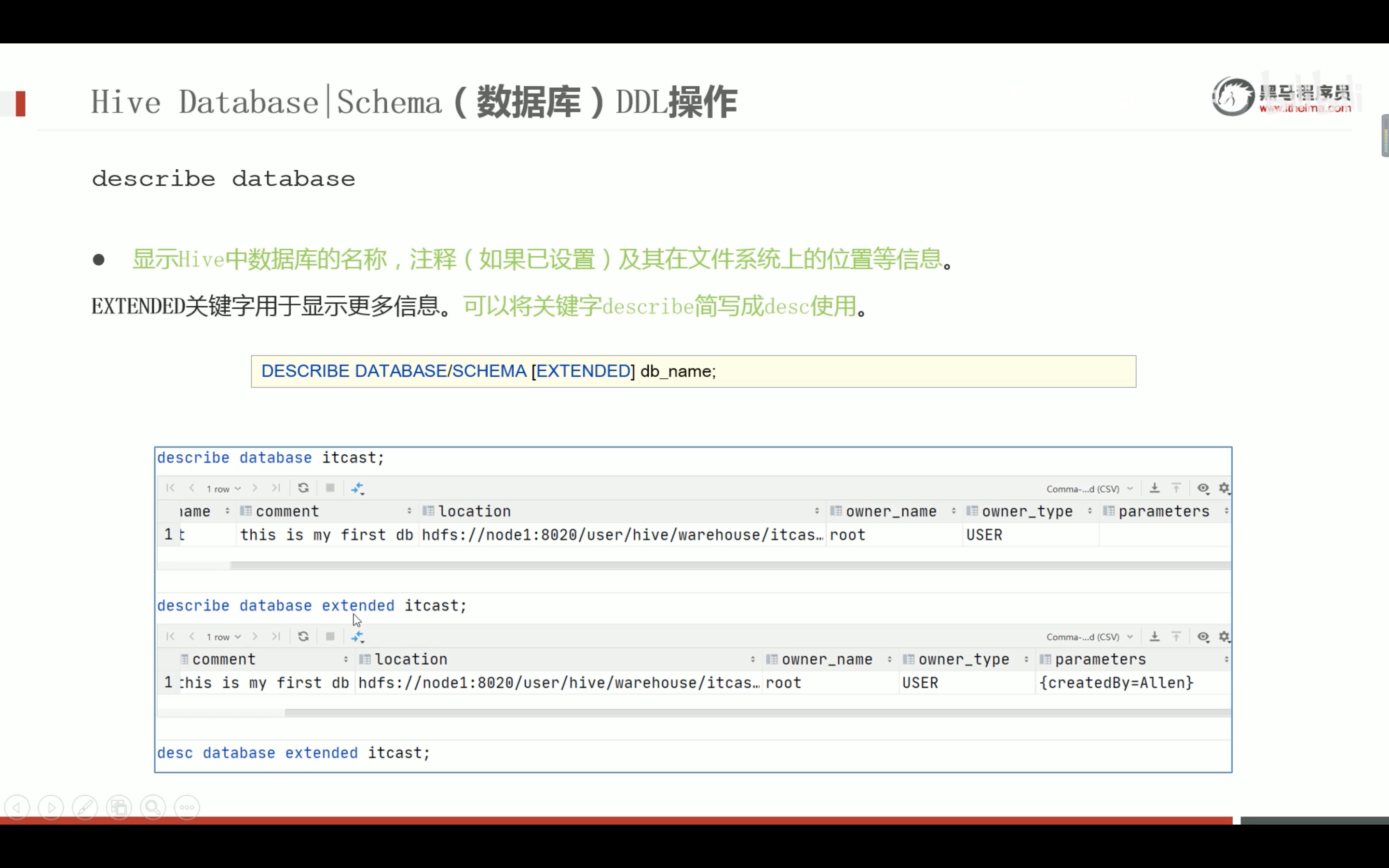
Hive SQL数据定义语言 DDL







新建完sql 记得新增数据源 configure data source,就是apache hive。改一下主机名,用户名,测试一下,然后链接。
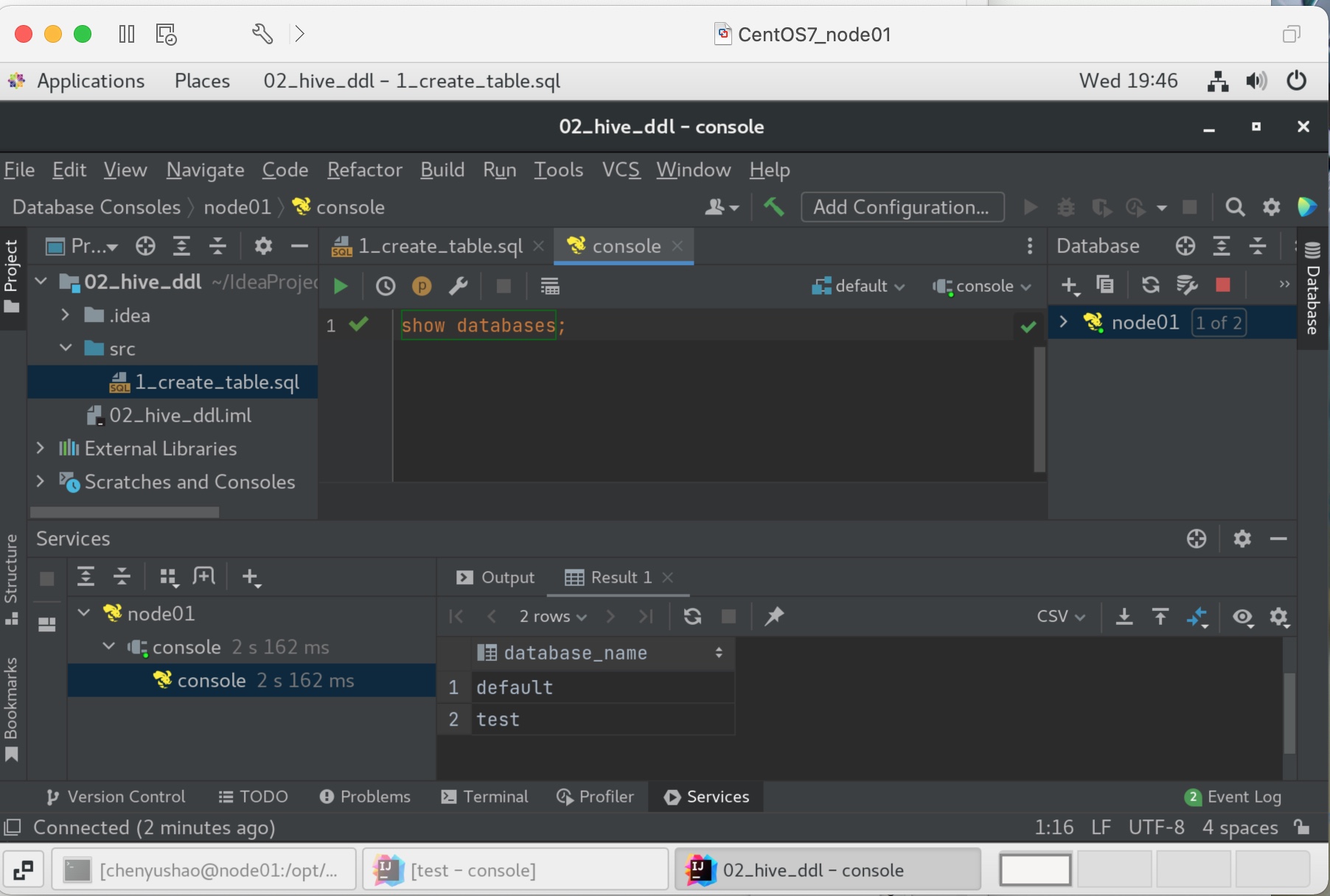
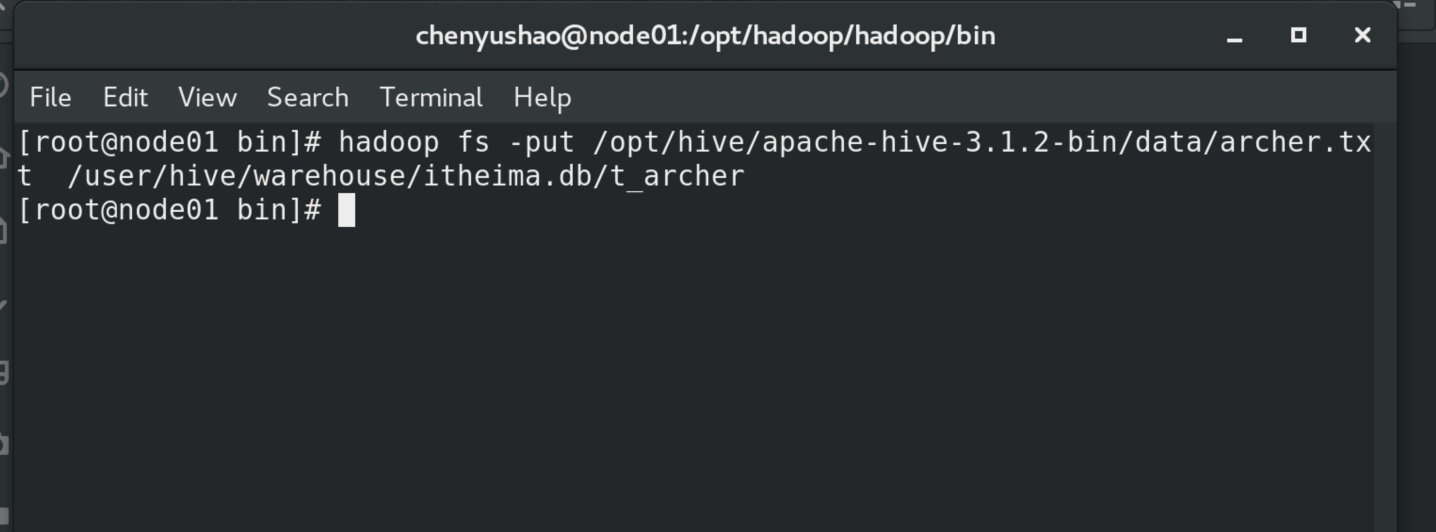
把文件放到hive表对应的的位置,马上就映射成功了。
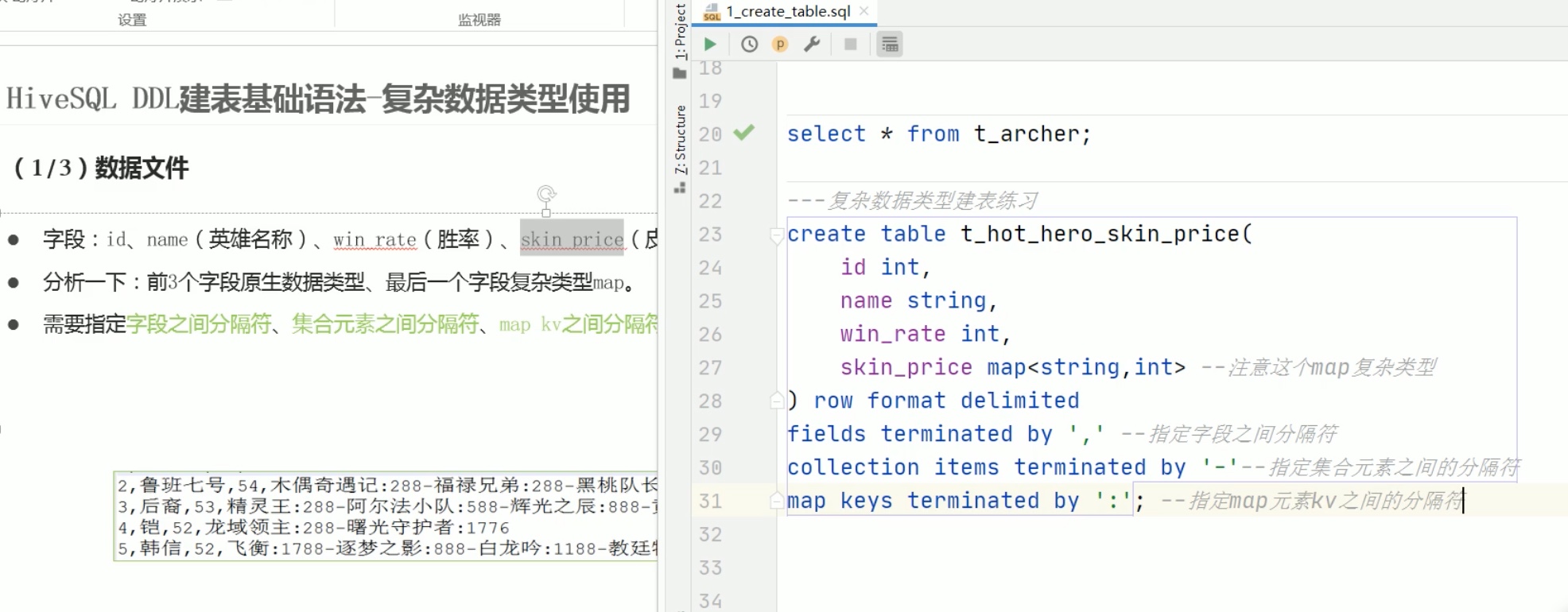
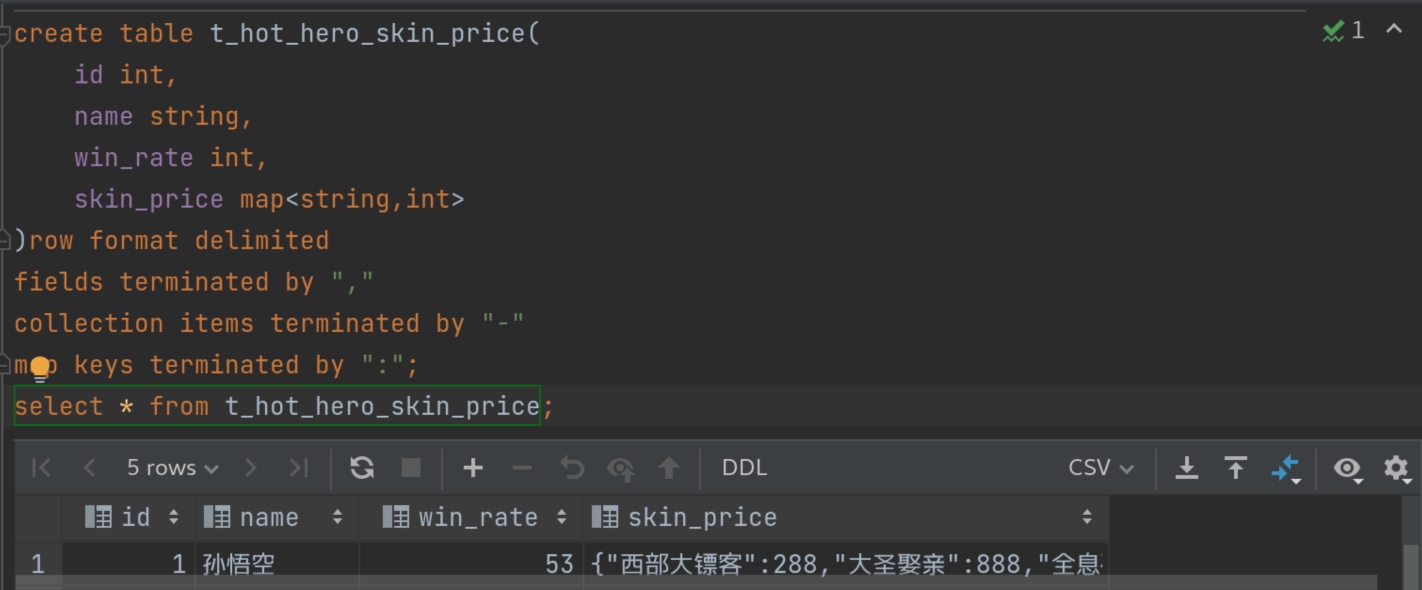
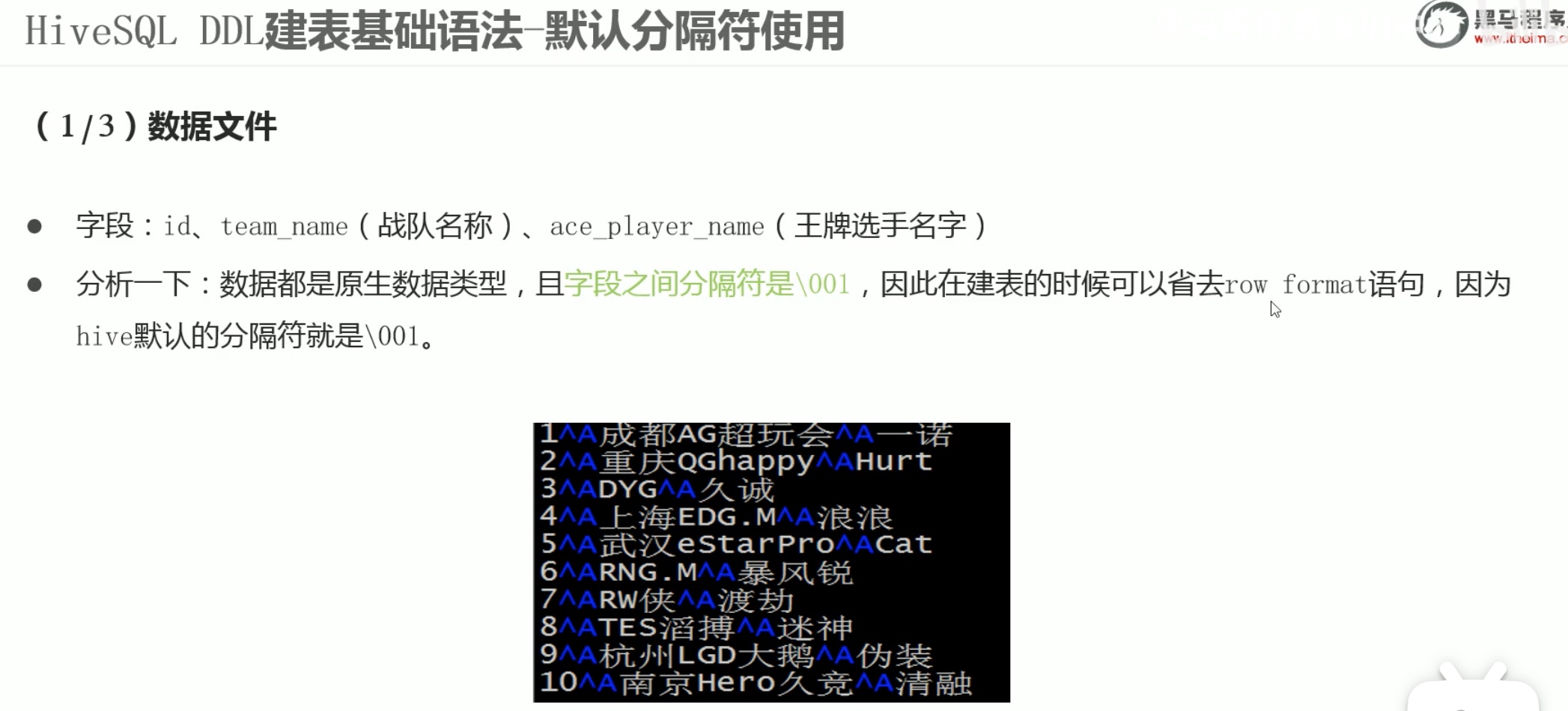
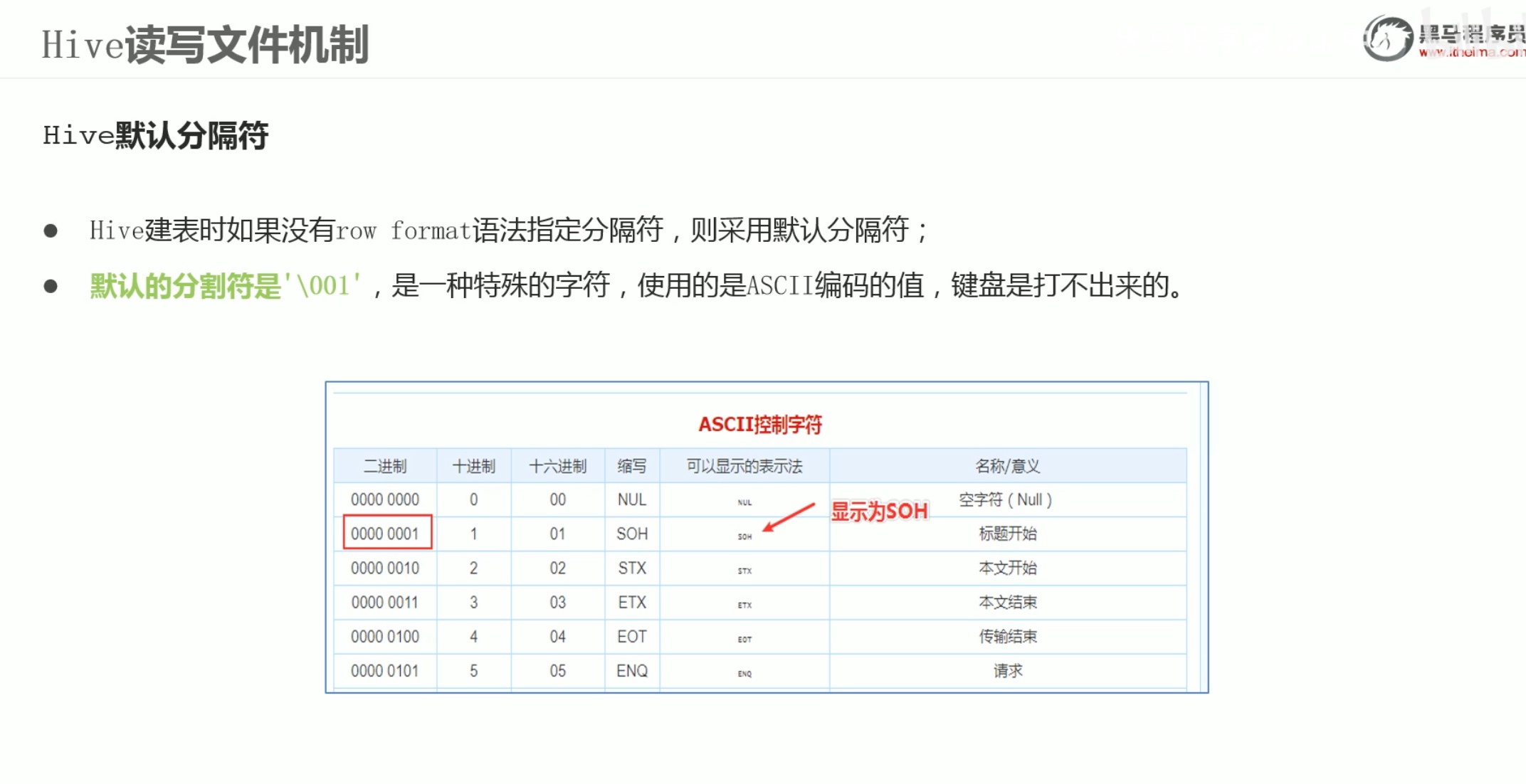
所以优先考虑 \001 作为分隔符。

注意上面的 / 是hdfs的根目录,不是系统根目录。
1 | hadoop fs -chmod -R 777 / # 可以让 node01:9870 浏览器中修改hdfs的目录文件夹。给了权限。 |


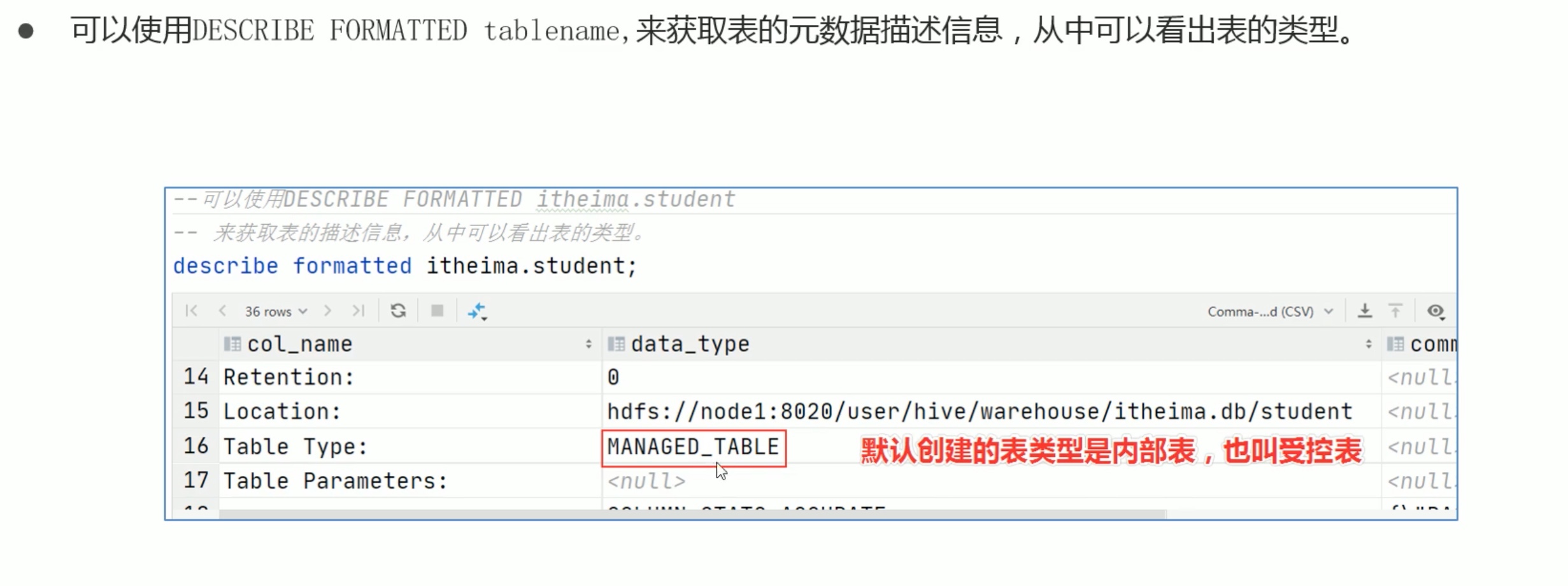

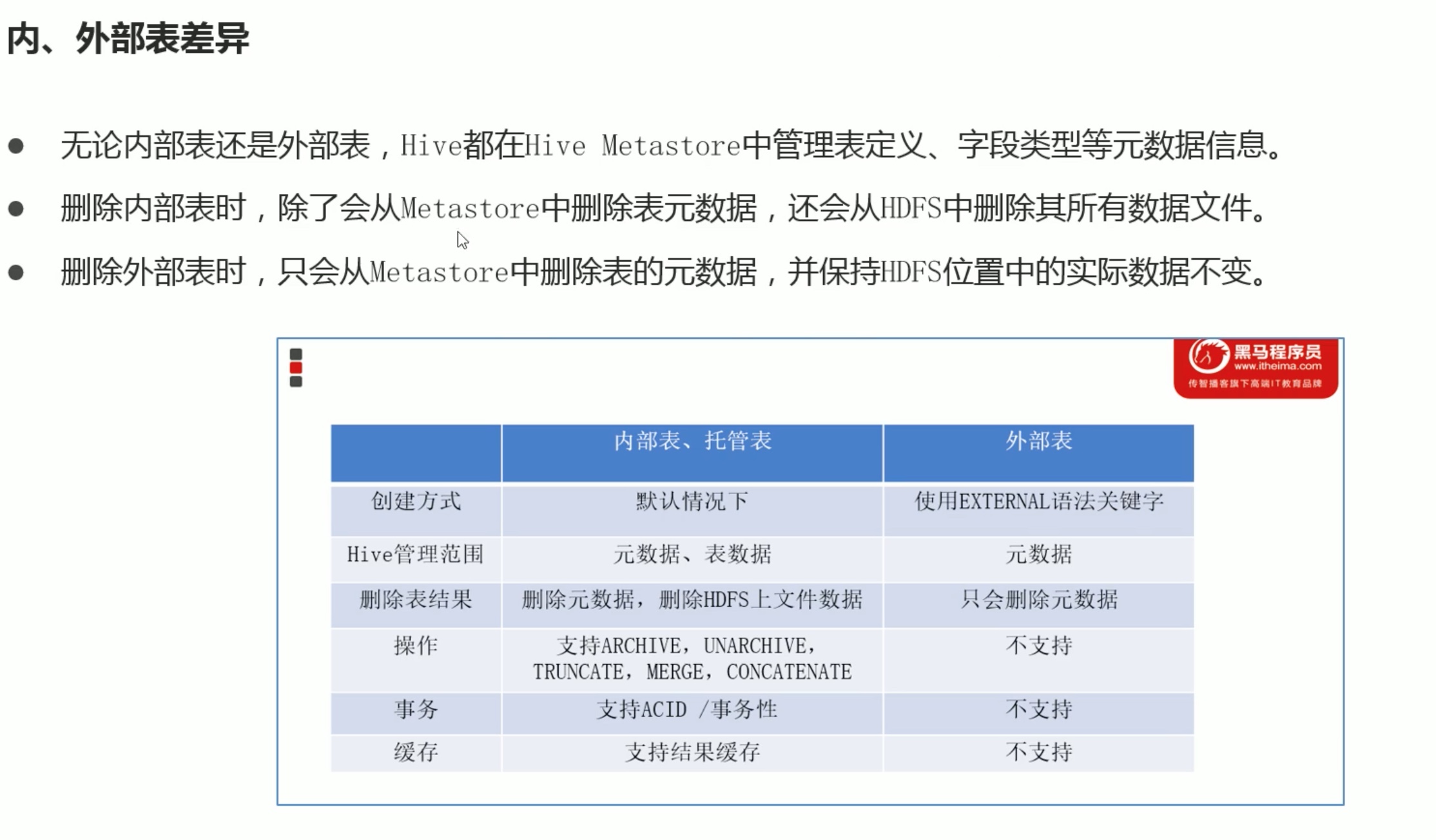

external创建外部表,但是不添加location,存放位置还是在/usr/hive/warehouse 中。但是它还是外部表,删除操作保留原文件。
内部表还是外部表由external存在与否决定,location在哪里和这点没关系。
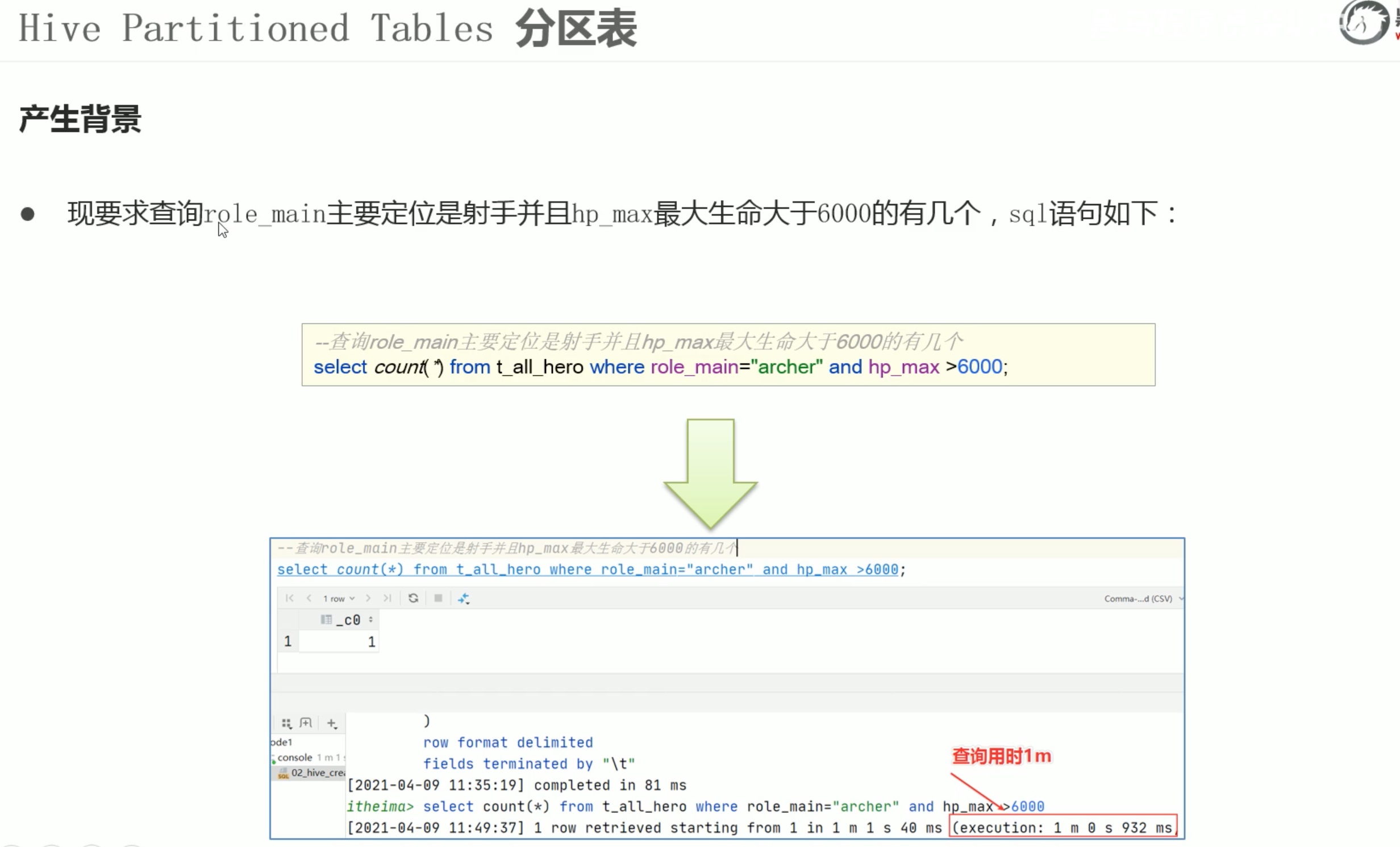

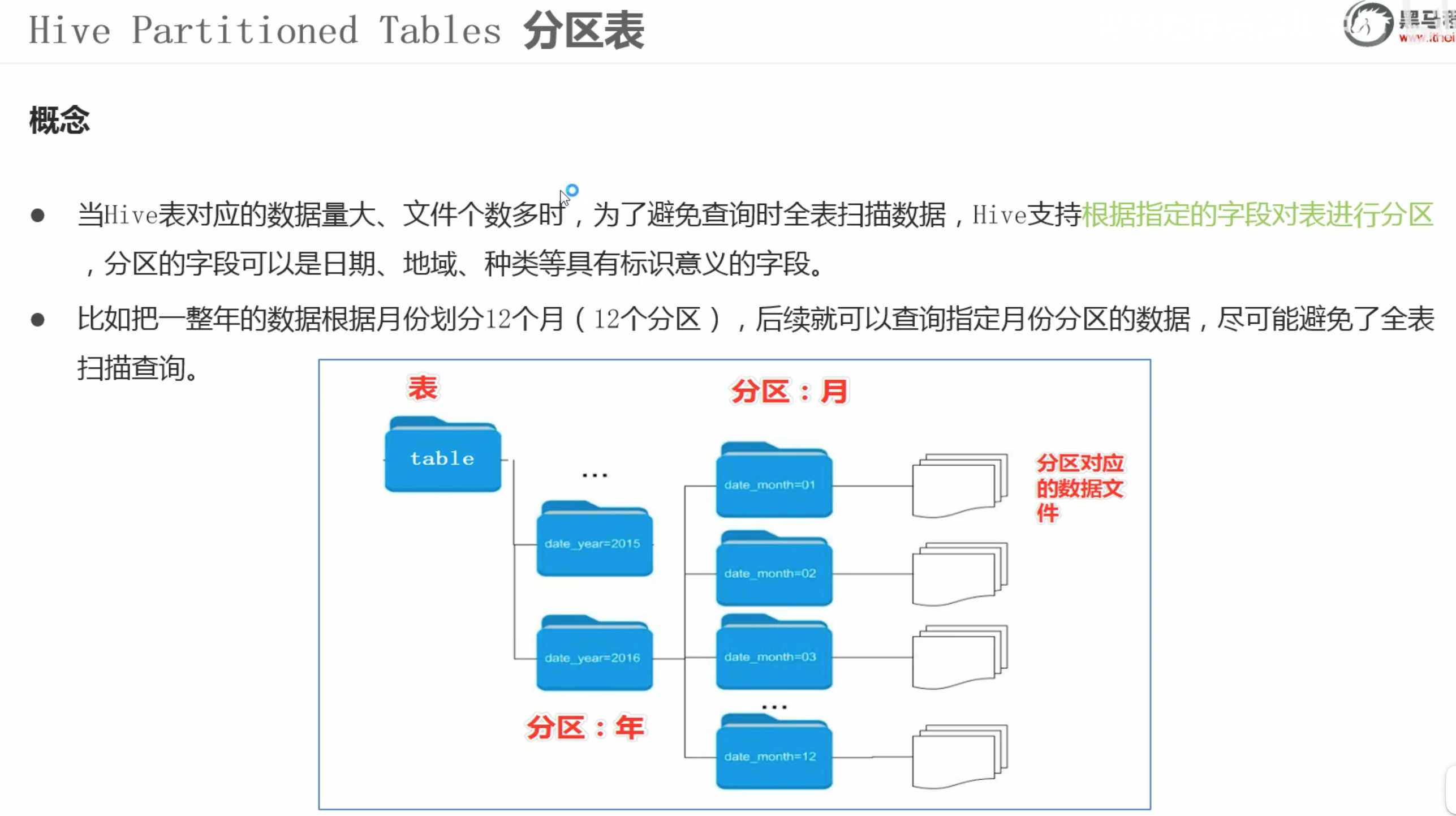


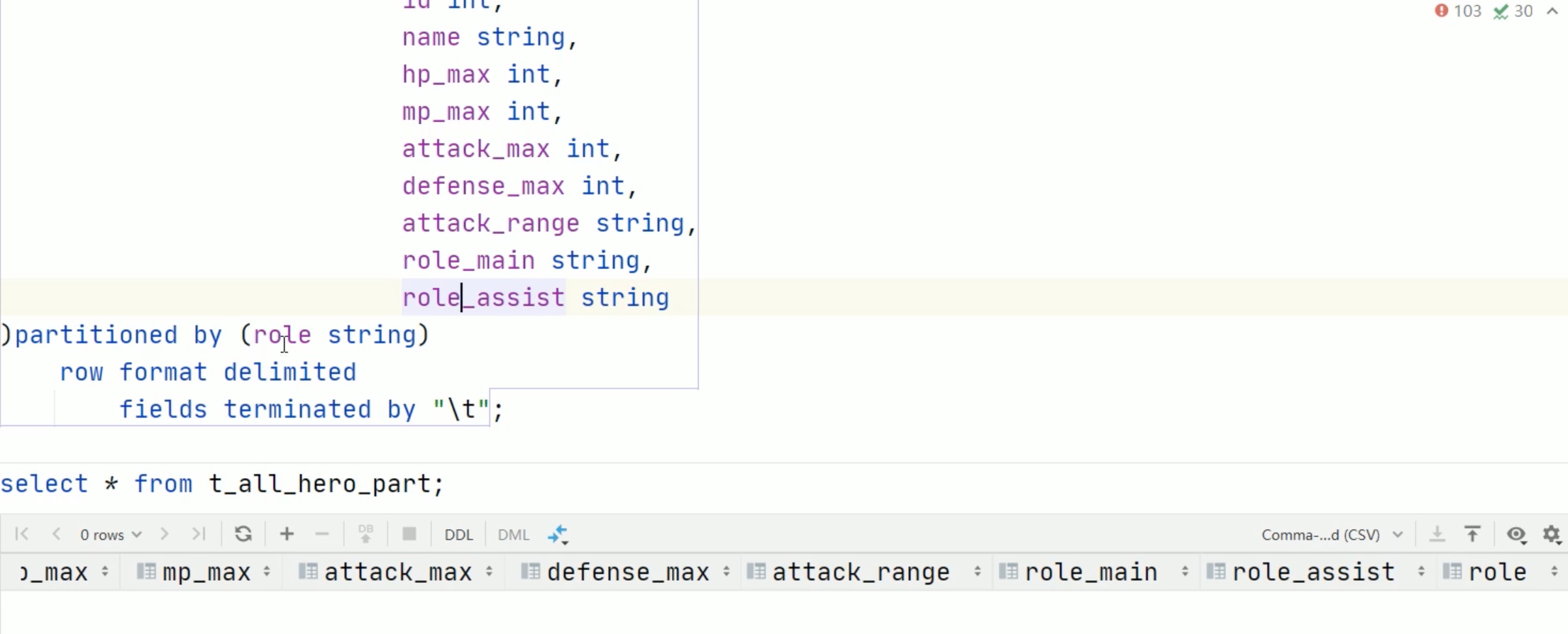

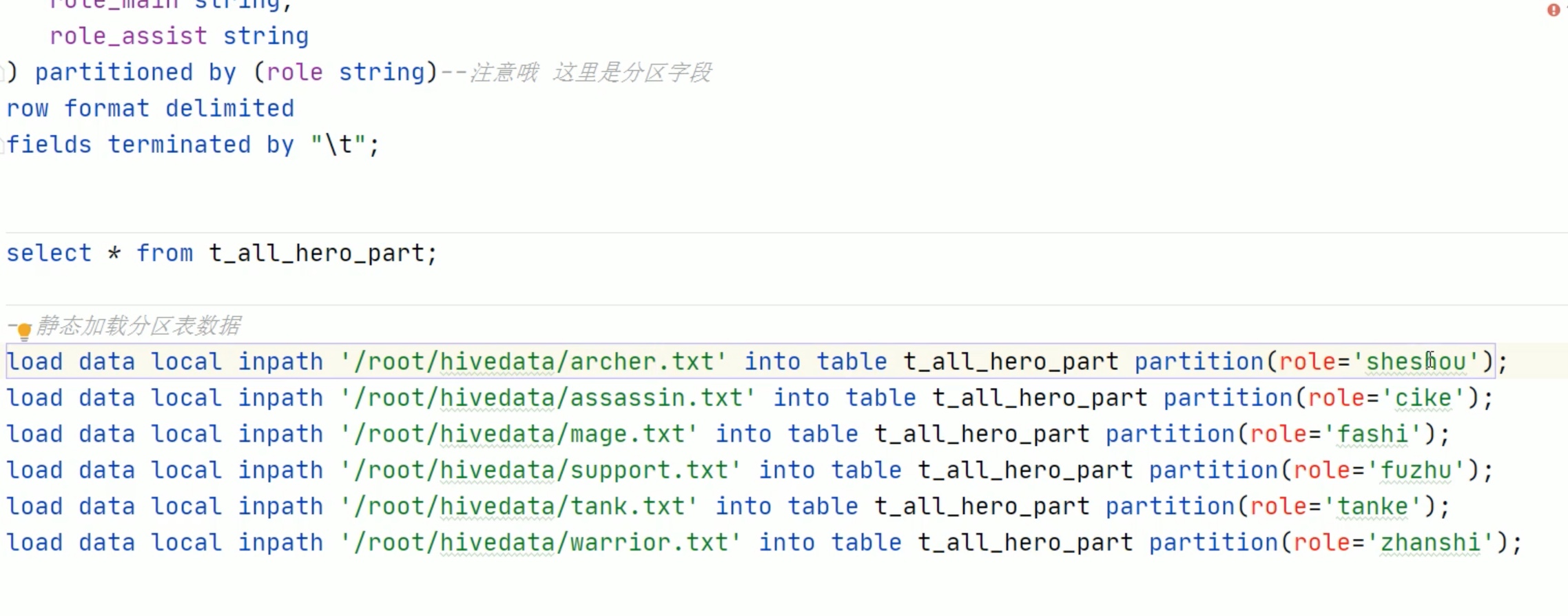
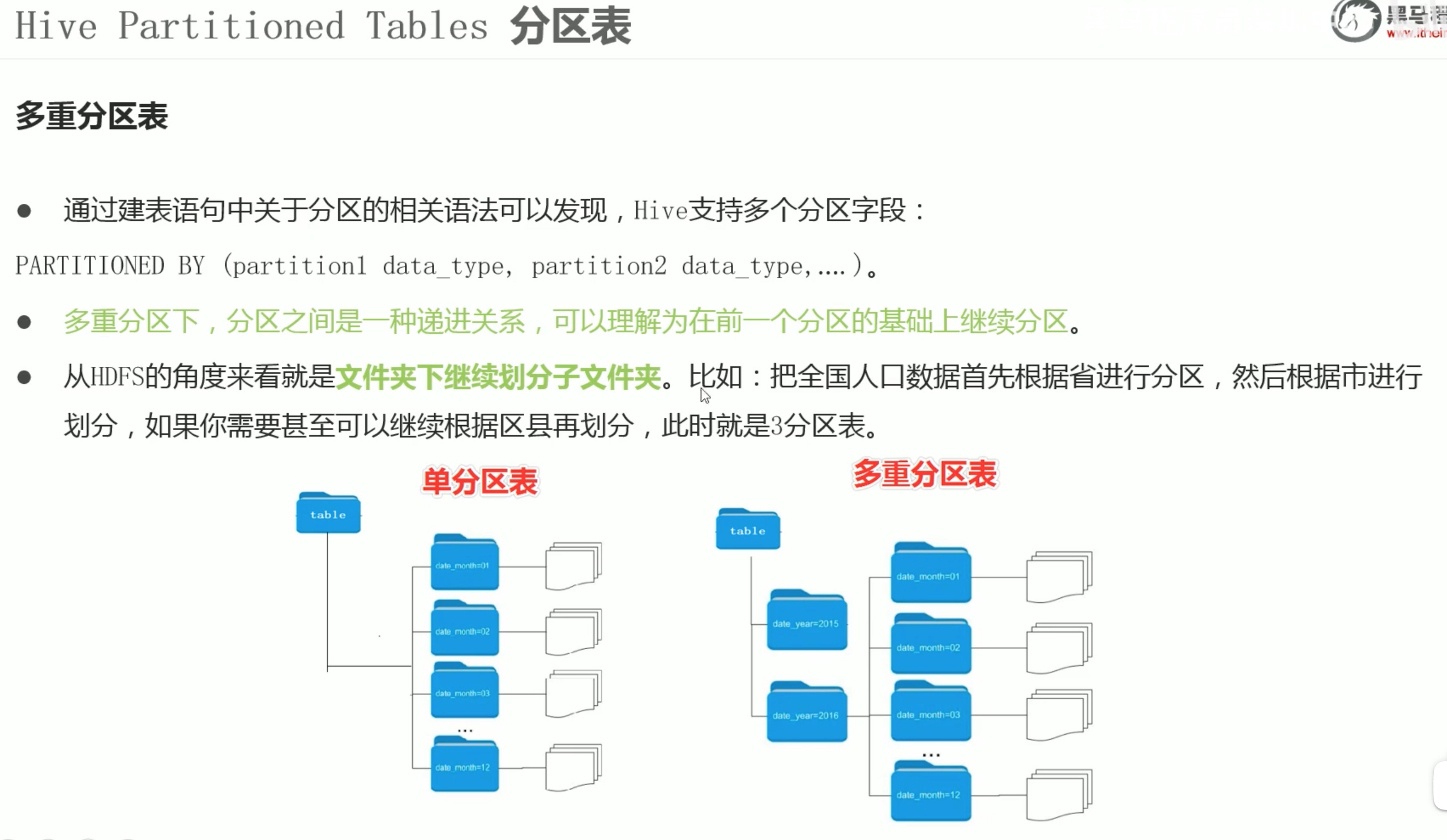
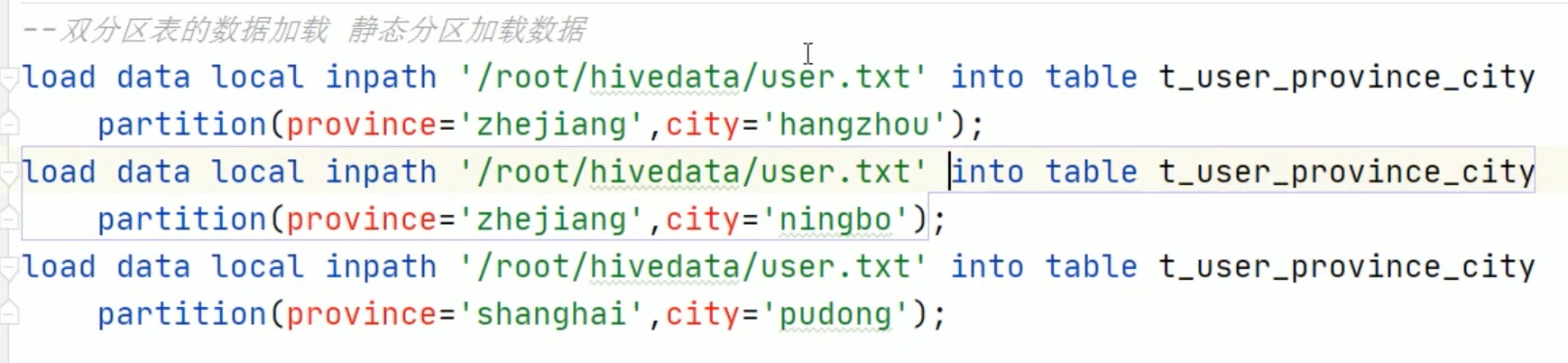
分区表数据不能想原来一样 put 进指定位置映射就完事,需要每一个源文件在 hive console控制台内 静态加载到 hdfs 对应表中。


我的分区优化后的查询用时1分59秒,没有分区的查询时间是2分7秒。

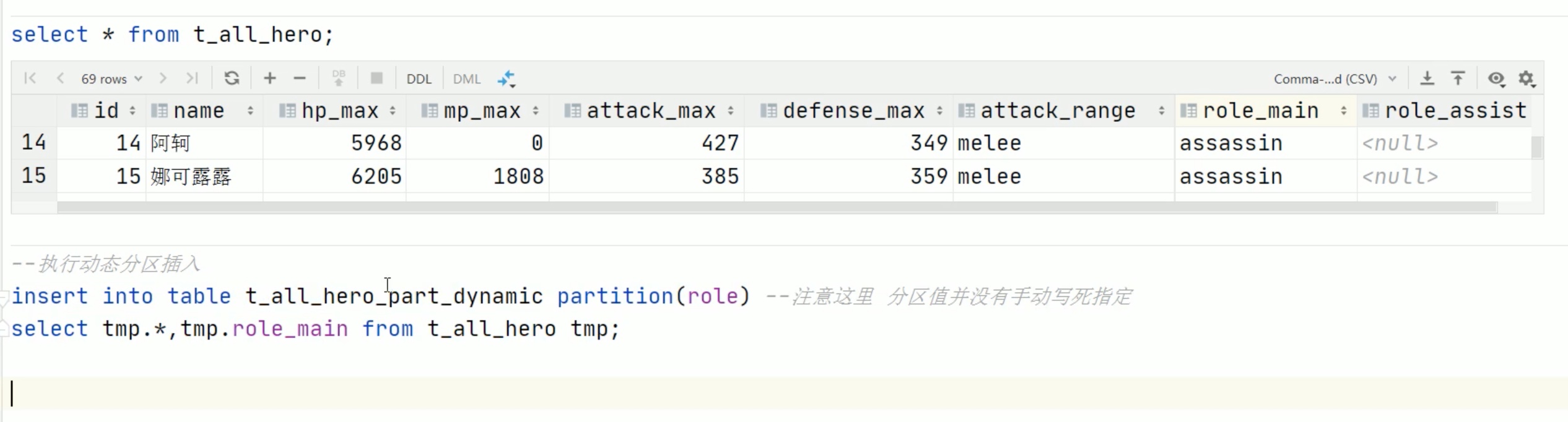

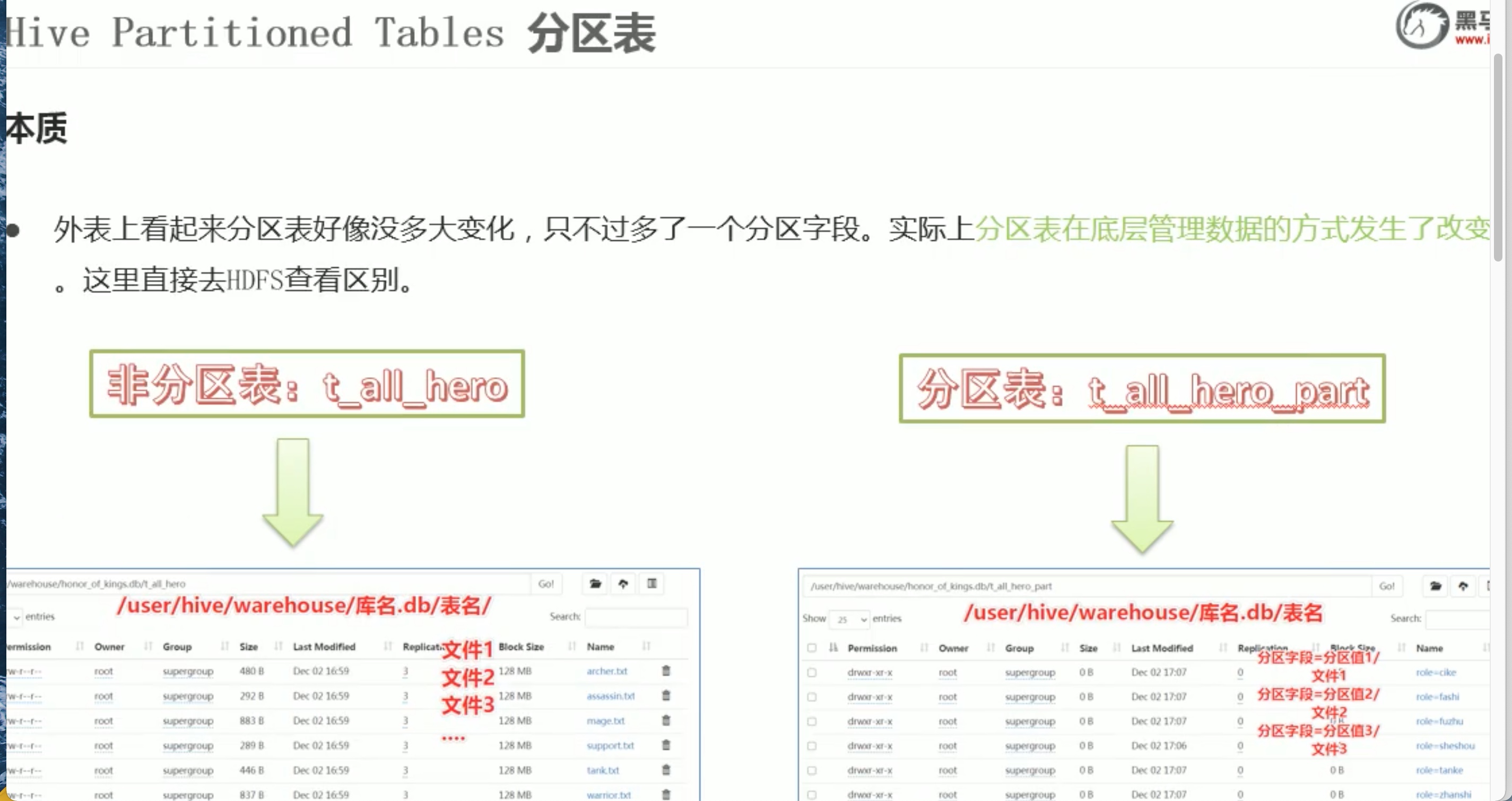
第三点中,底层原数据没有变化,显示的分区字段其实是 hive 中生成的。
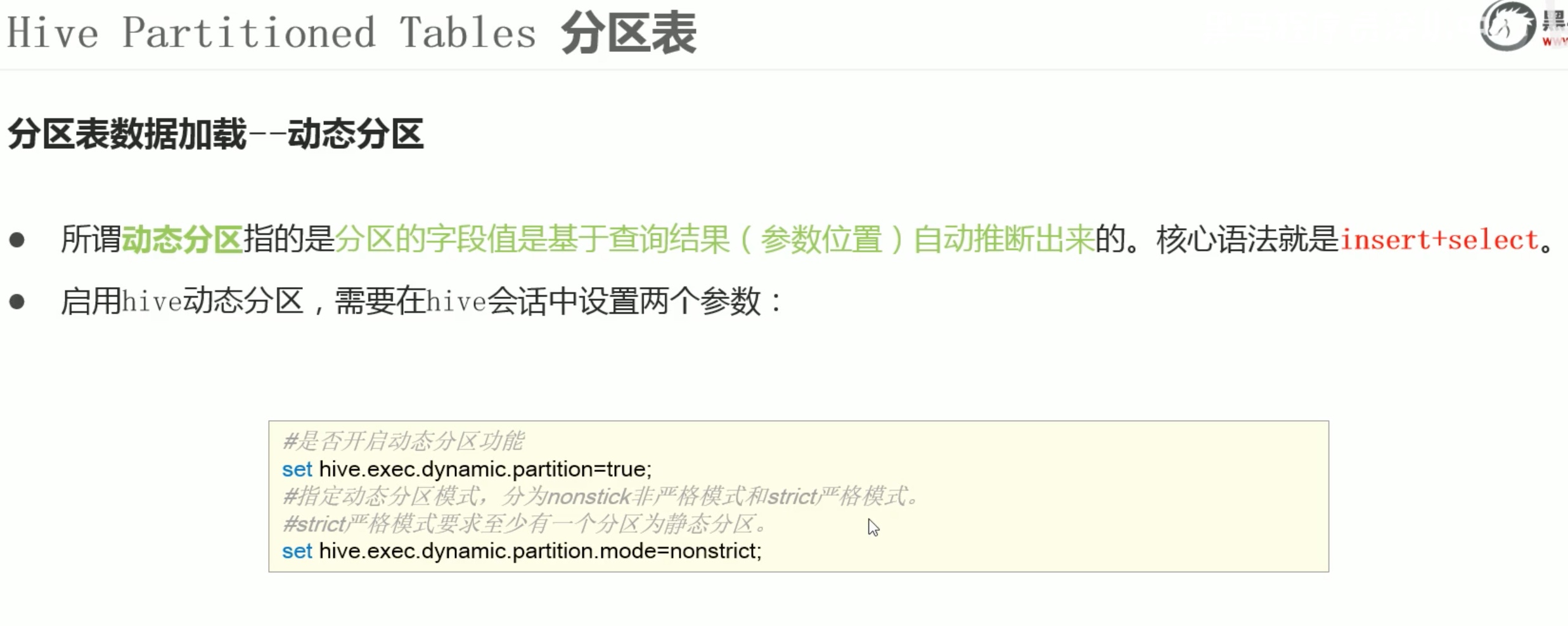
1 | set hive.exec.dynamic.partition=true; |
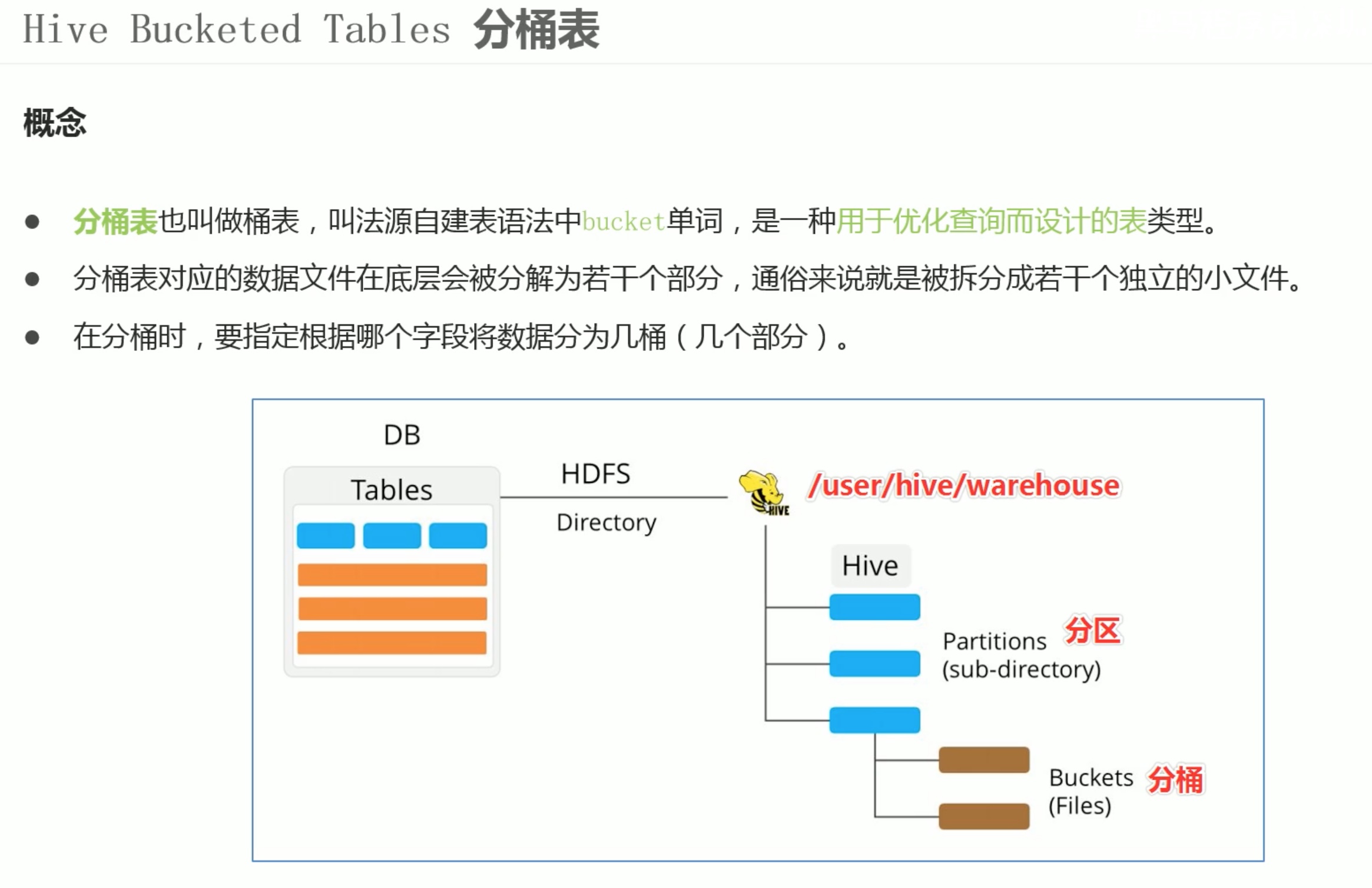
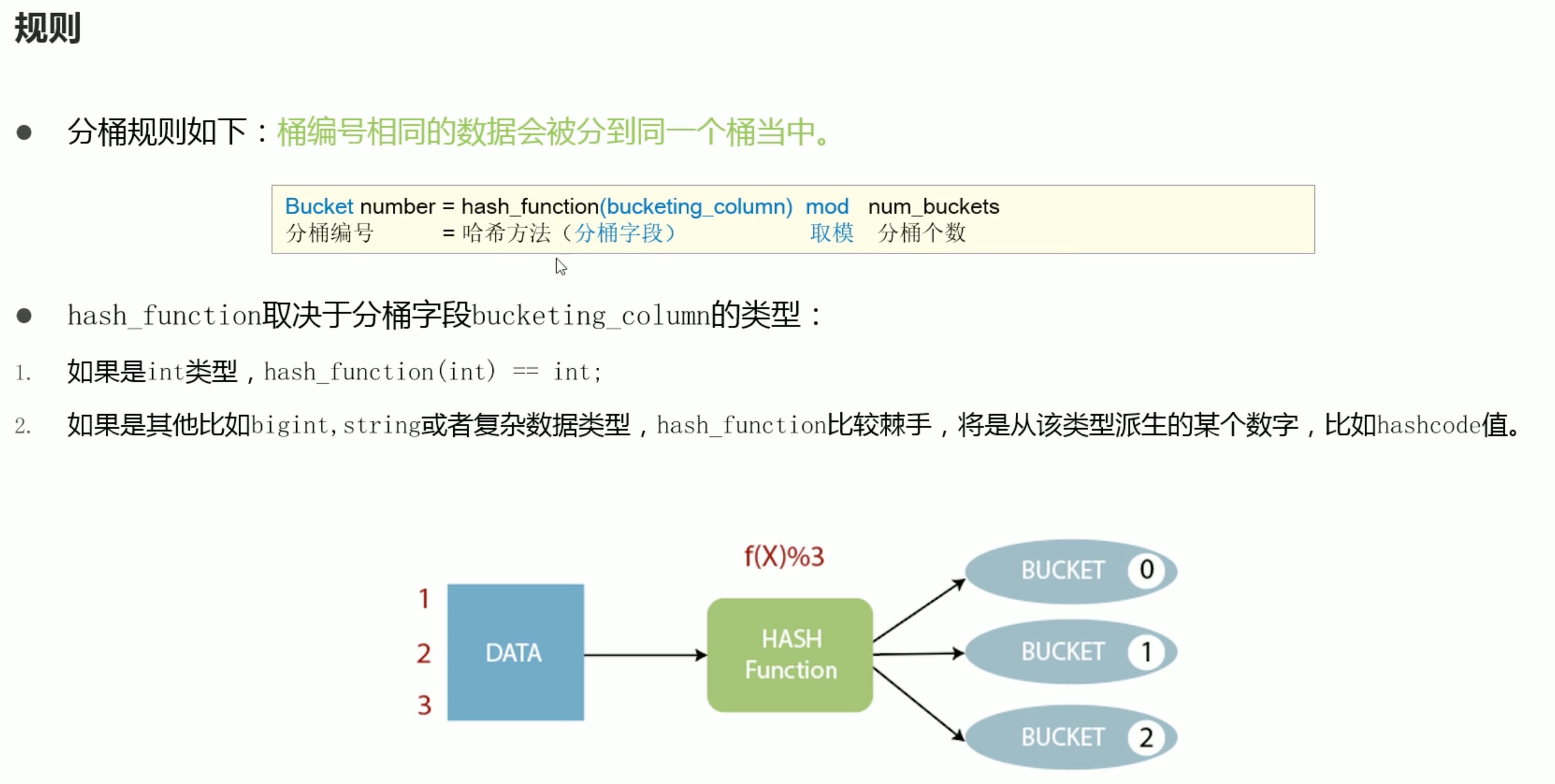
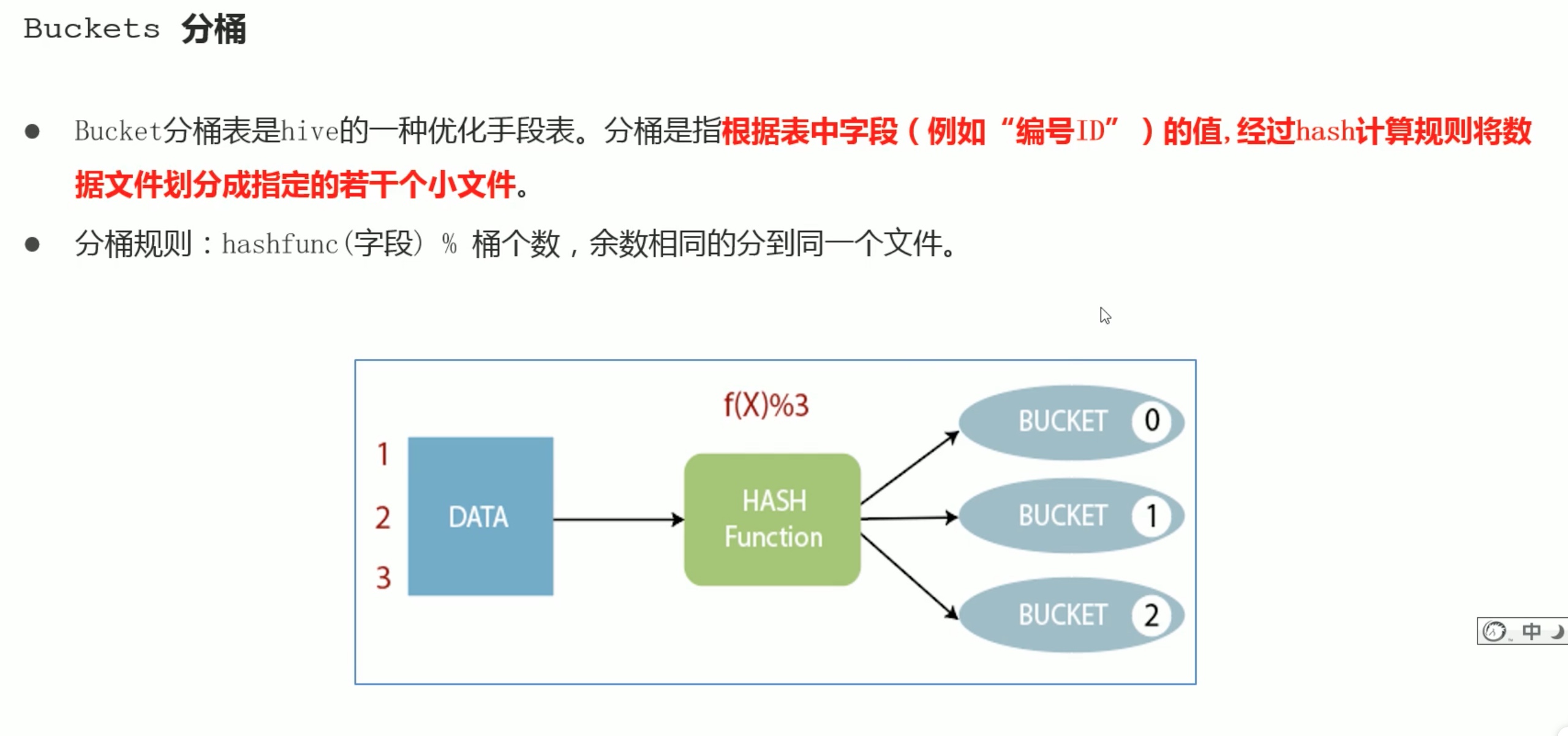
这里可以回顾一下,之前学习的算法与数据结构中的 散列表。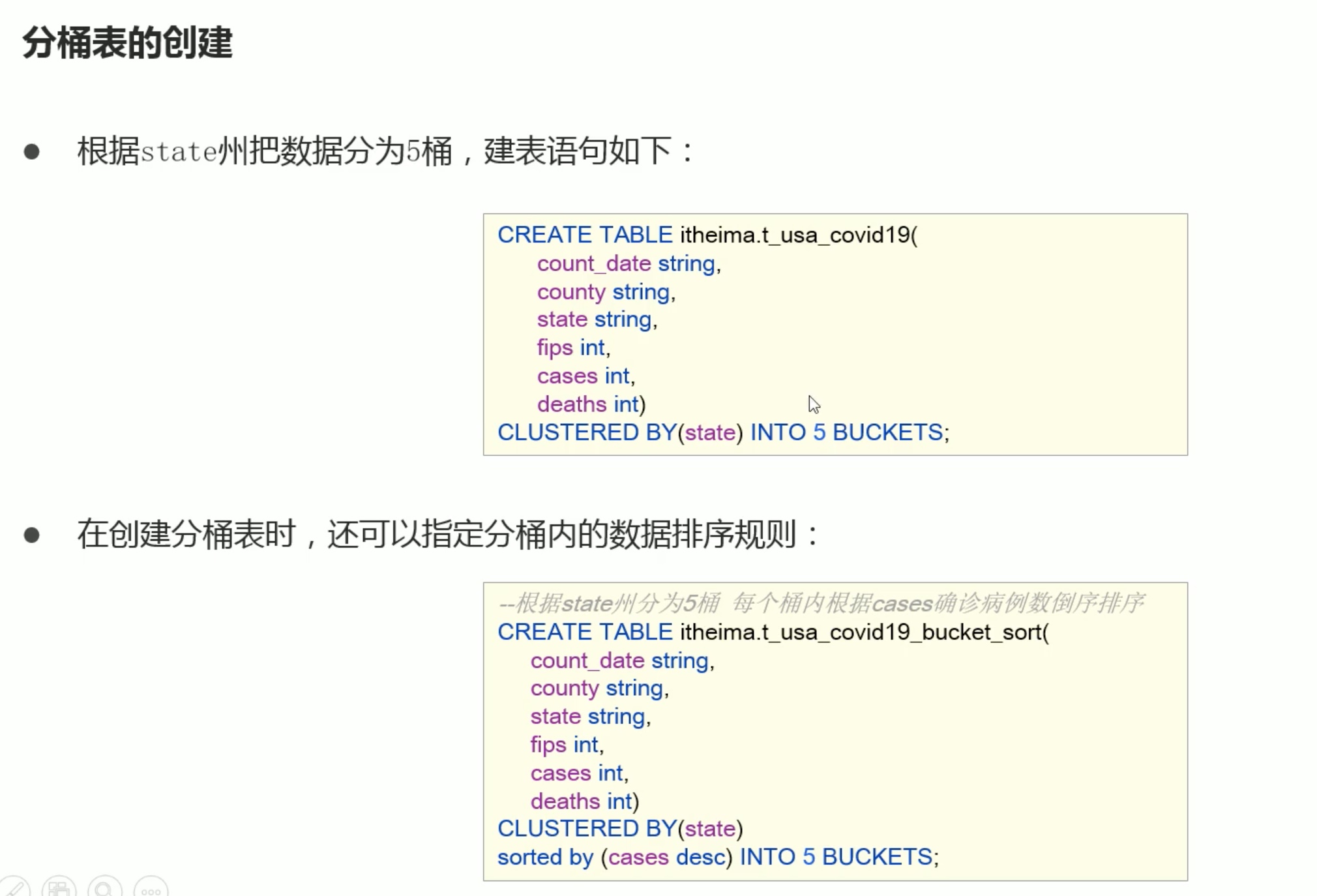
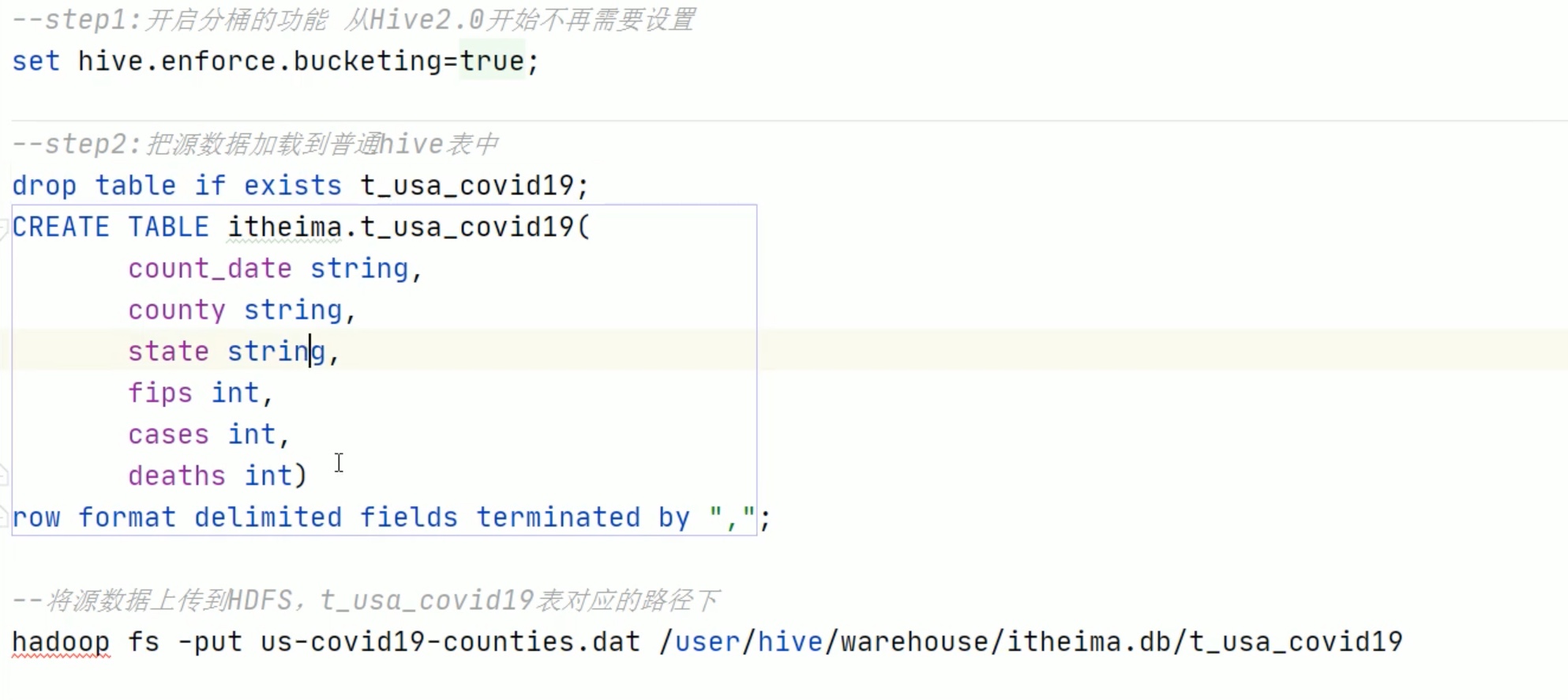

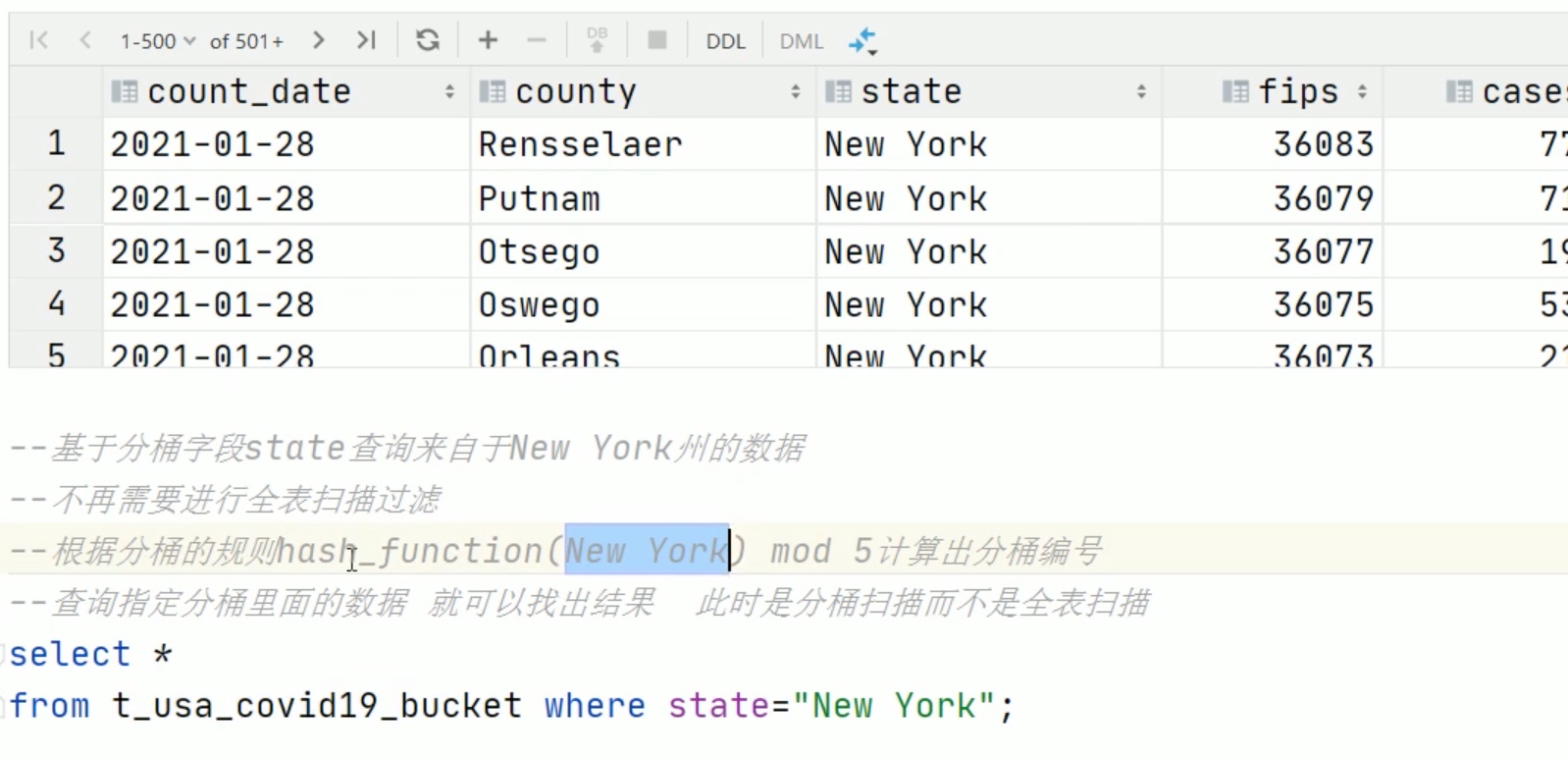

分桶表还可以提高抽样的效率。





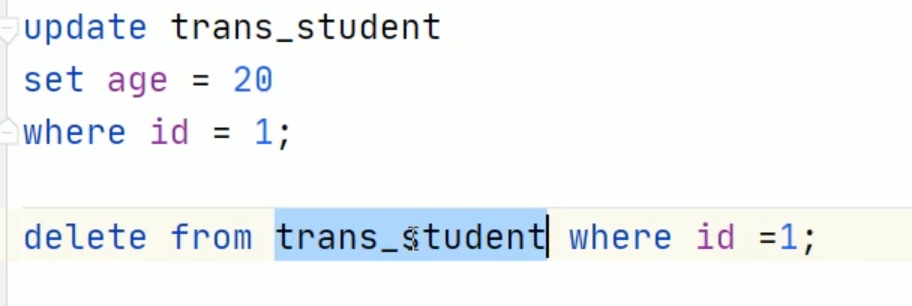
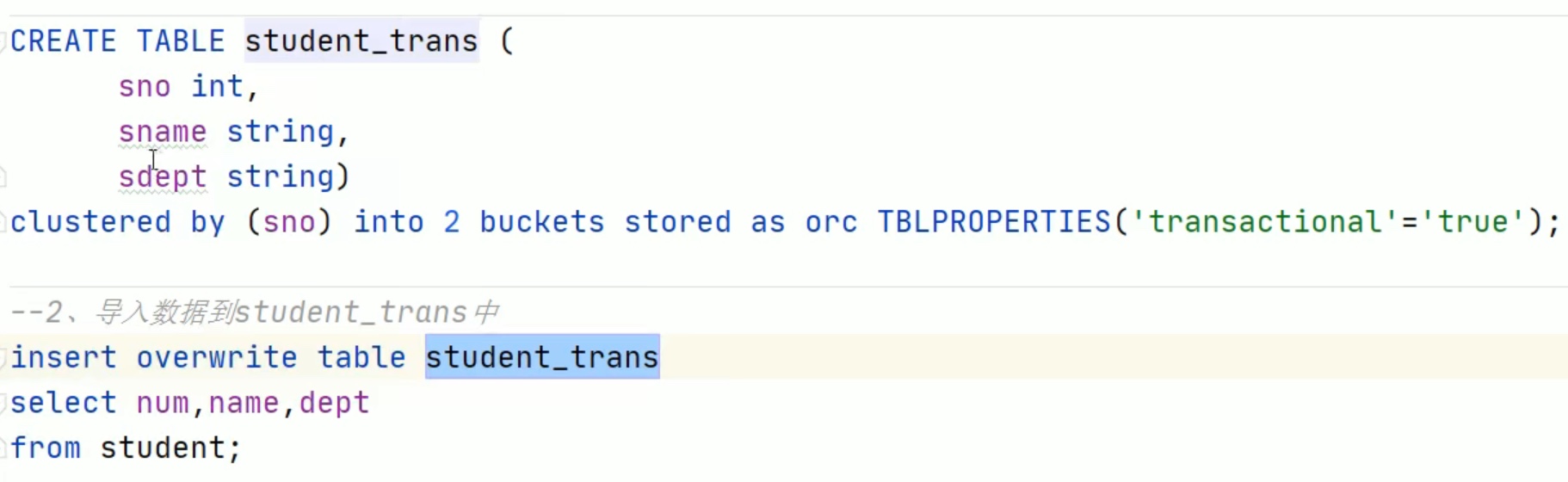
insert into trans_student values(1,’chenyushao’,29);
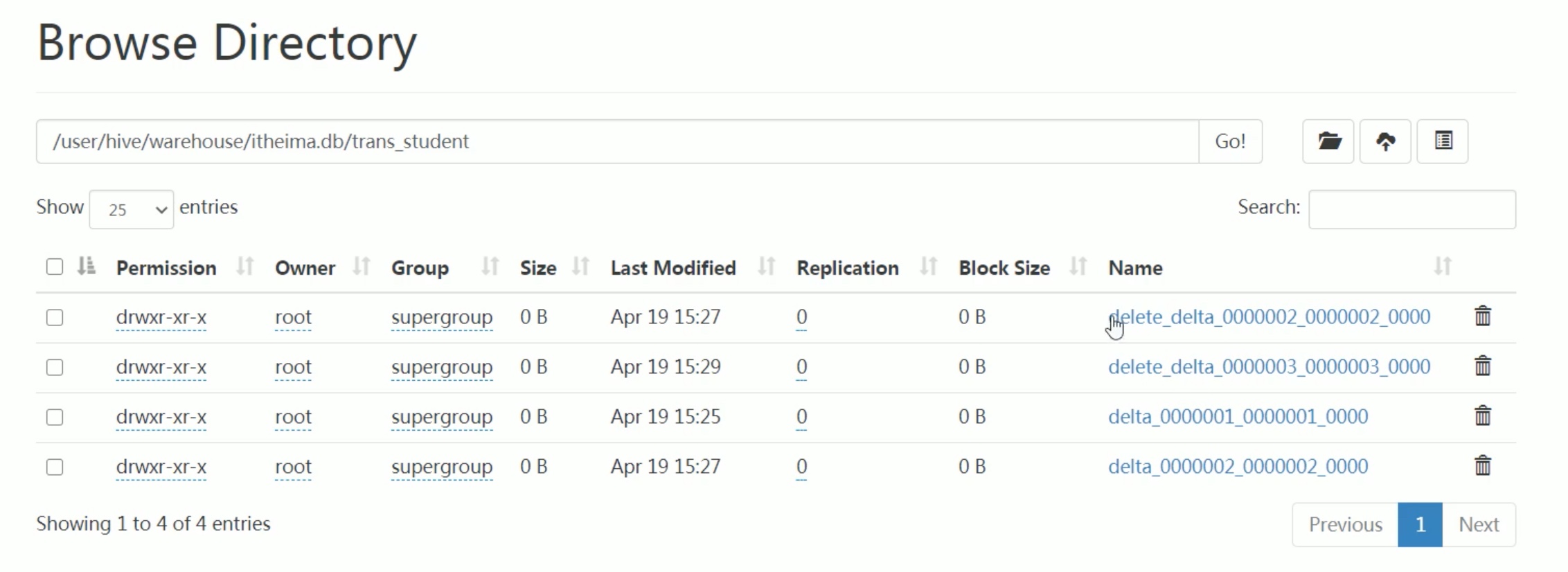
可以看见其实hive没有删除原文件,只是用了新的 “事务操作” 产生新的版本而已。
1 | set hive.support.concurrency=true; |
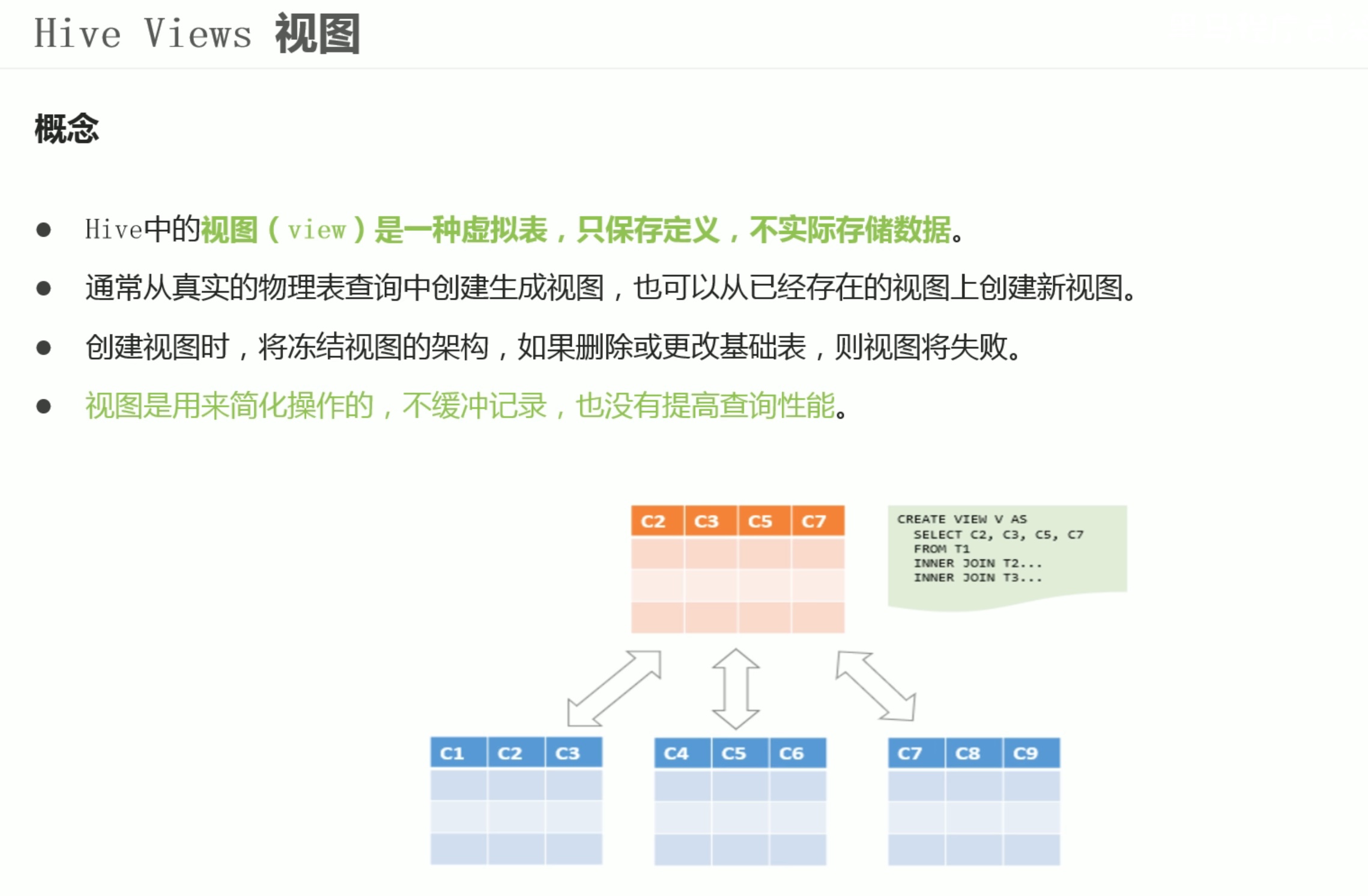
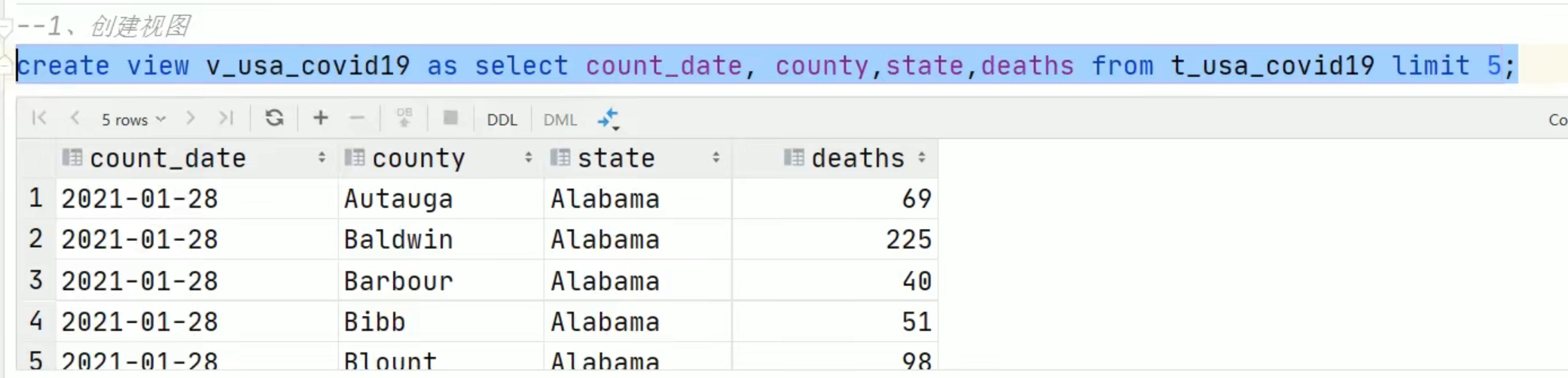
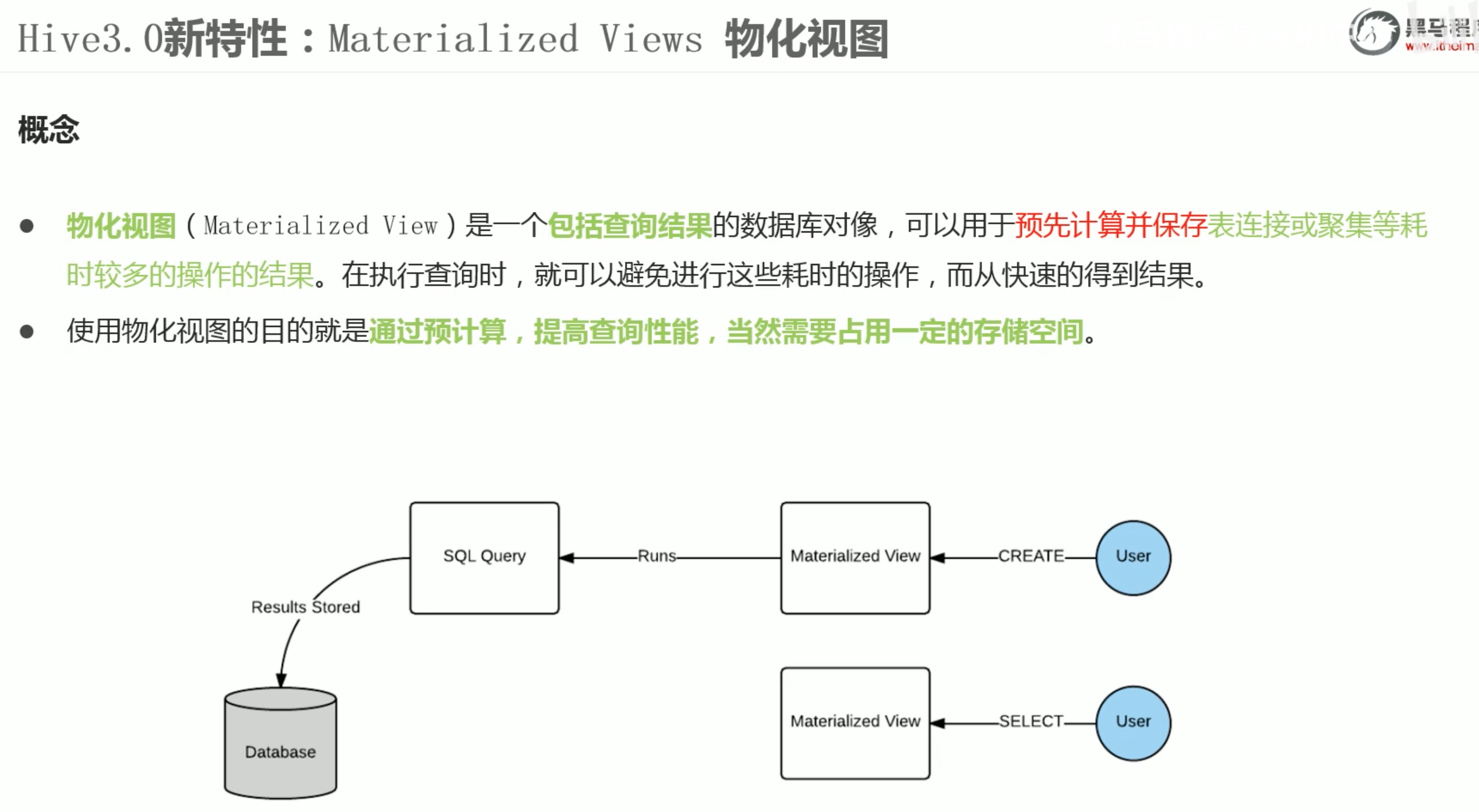
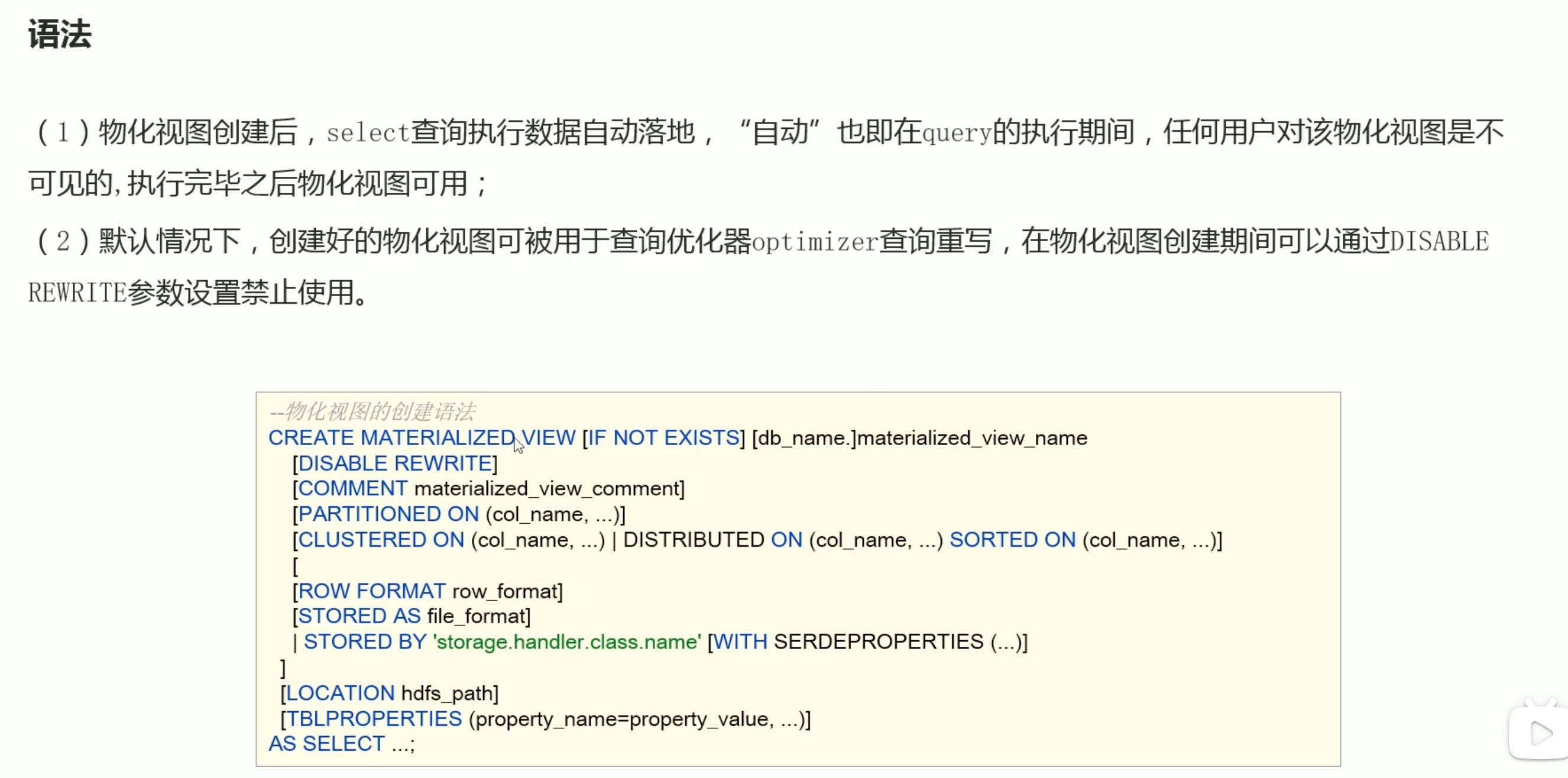
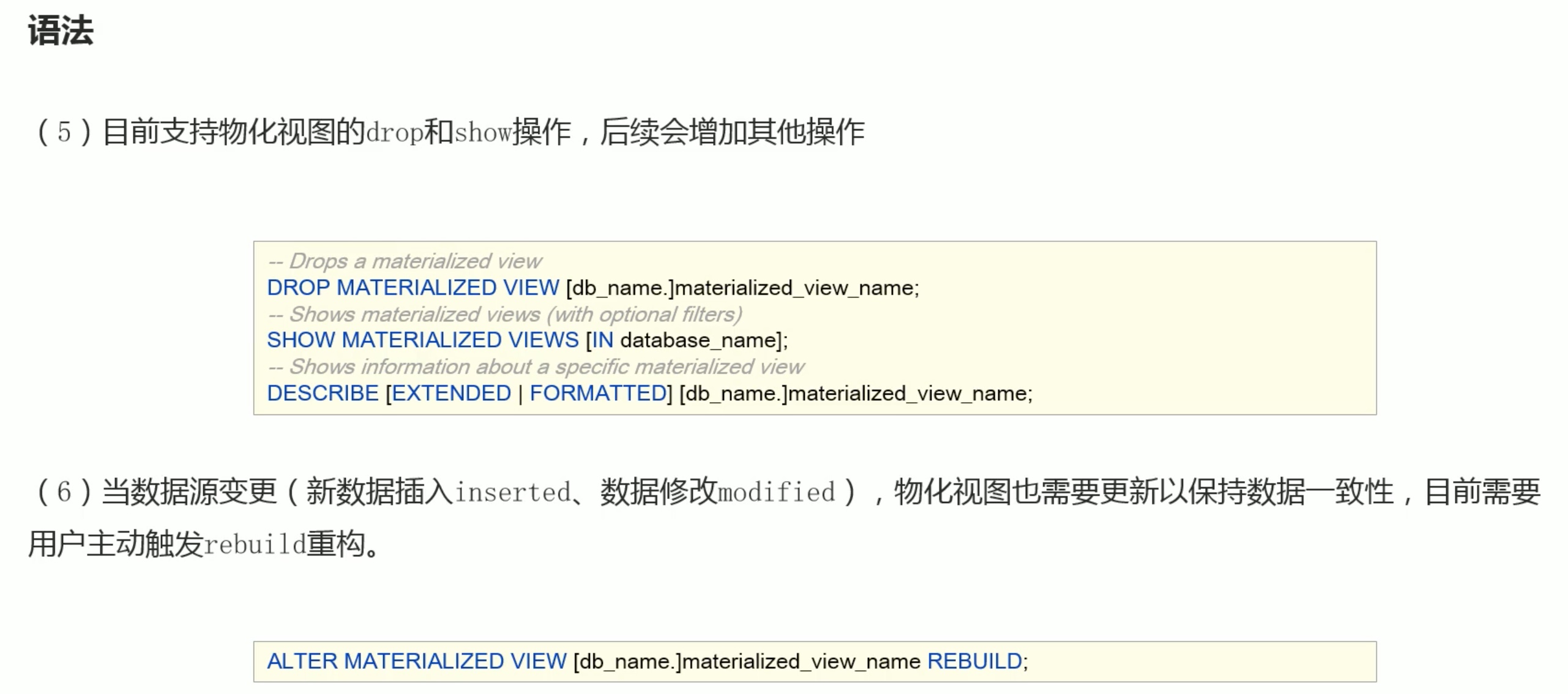
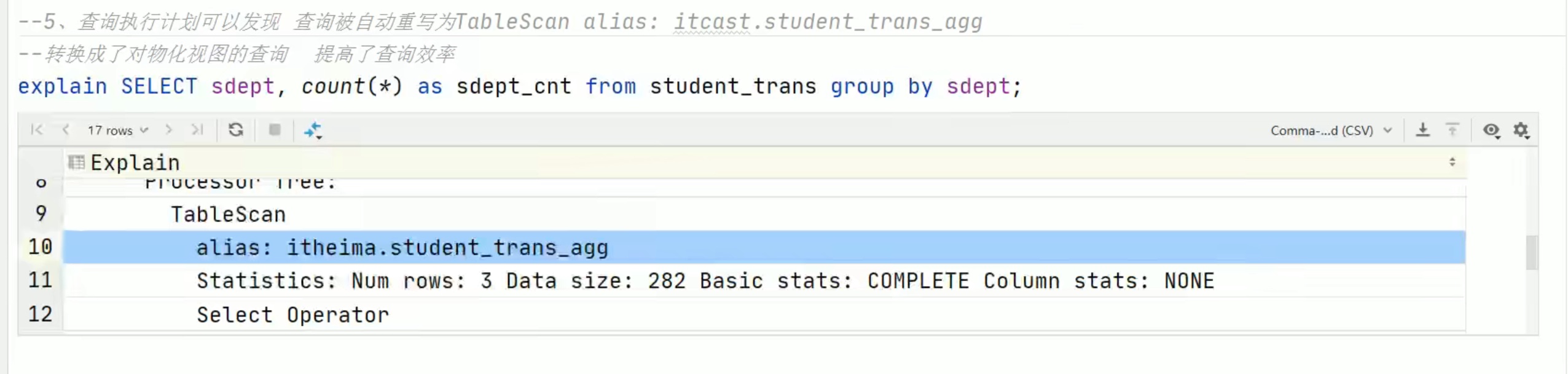
基于select 创建视图,只看前面5项。


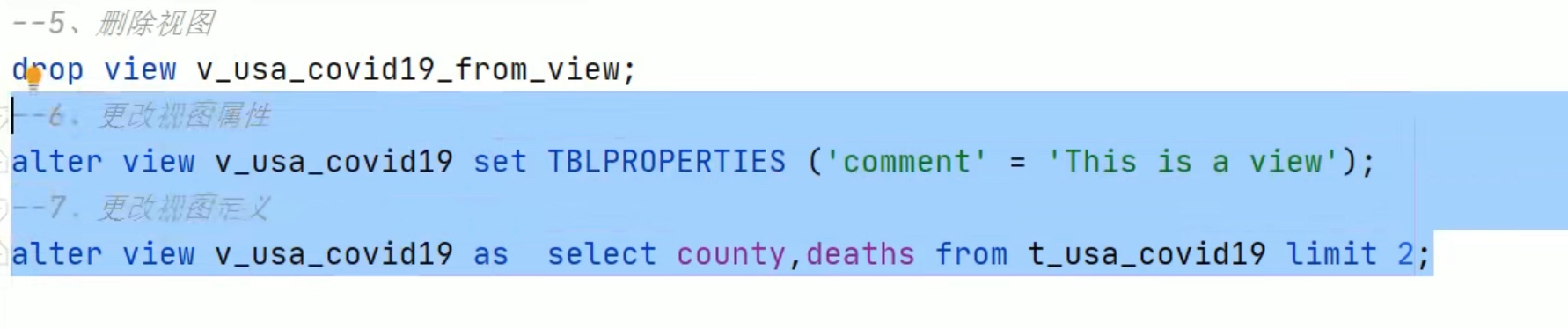

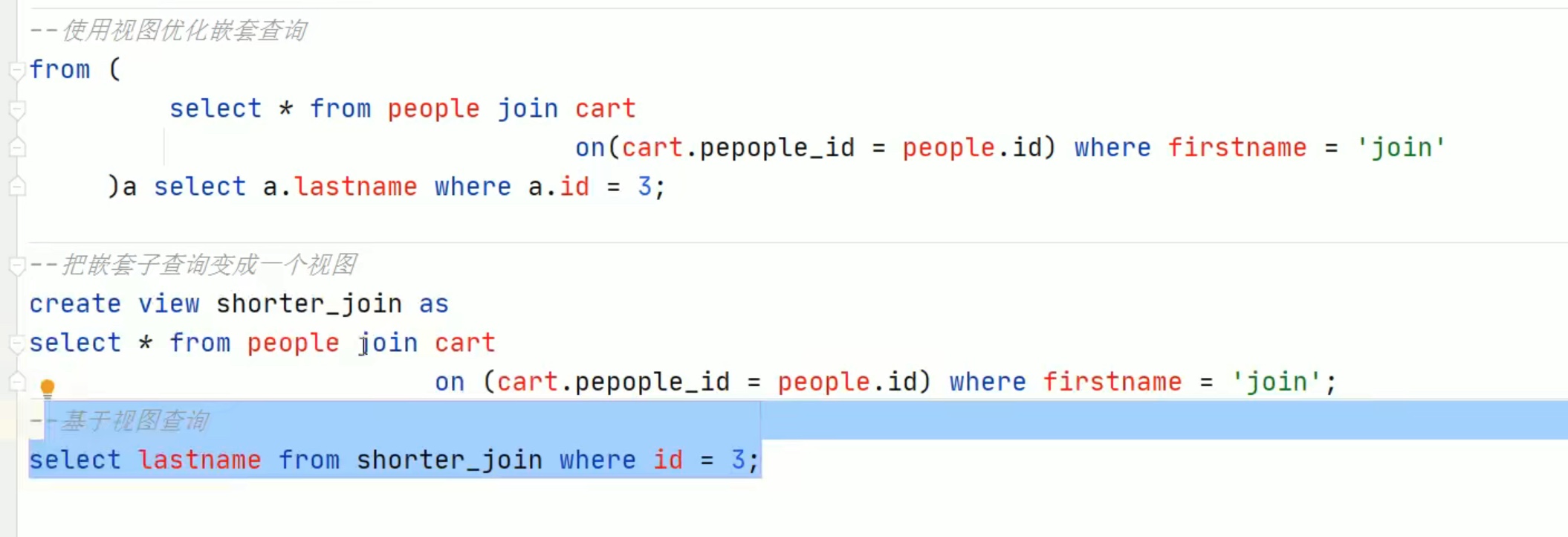
注意:view只是让我们方便查看语句,并不是真的优化了查询的性能。




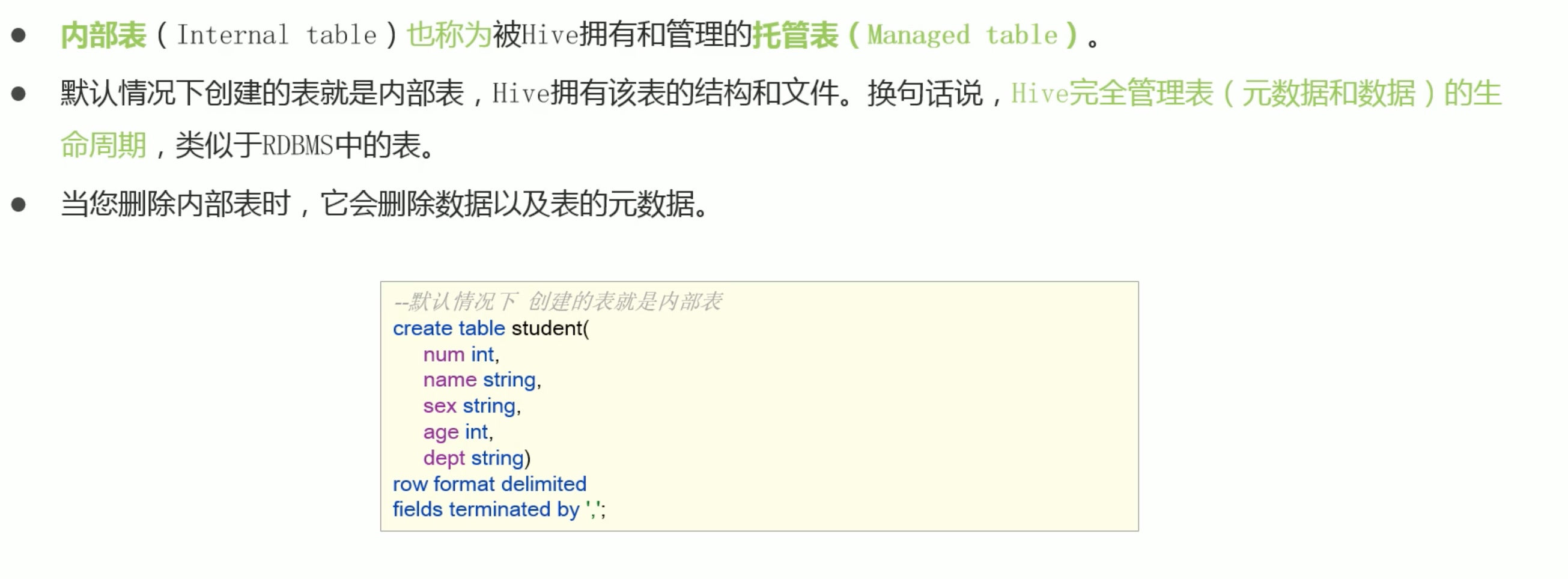
1 | create table student( |


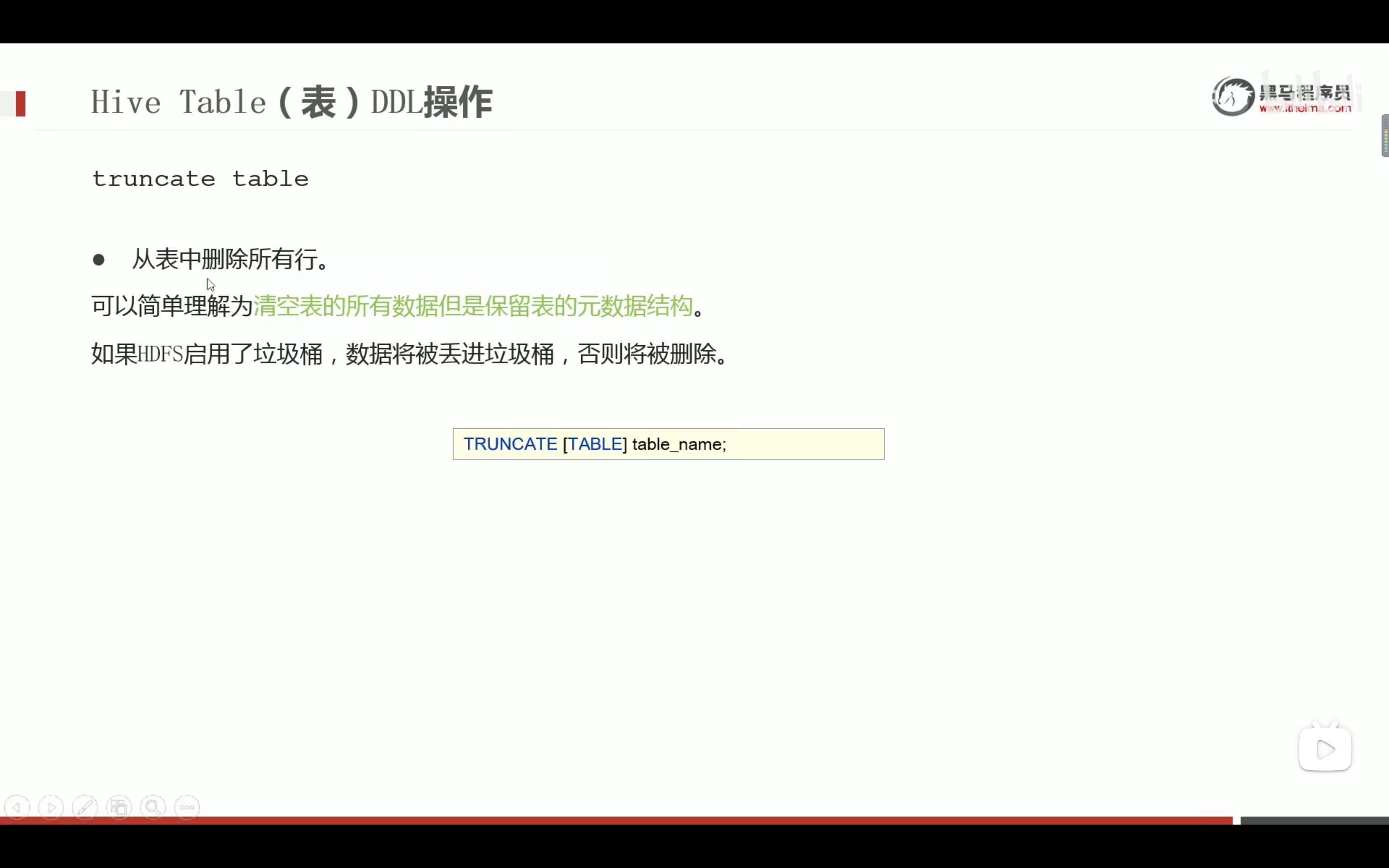
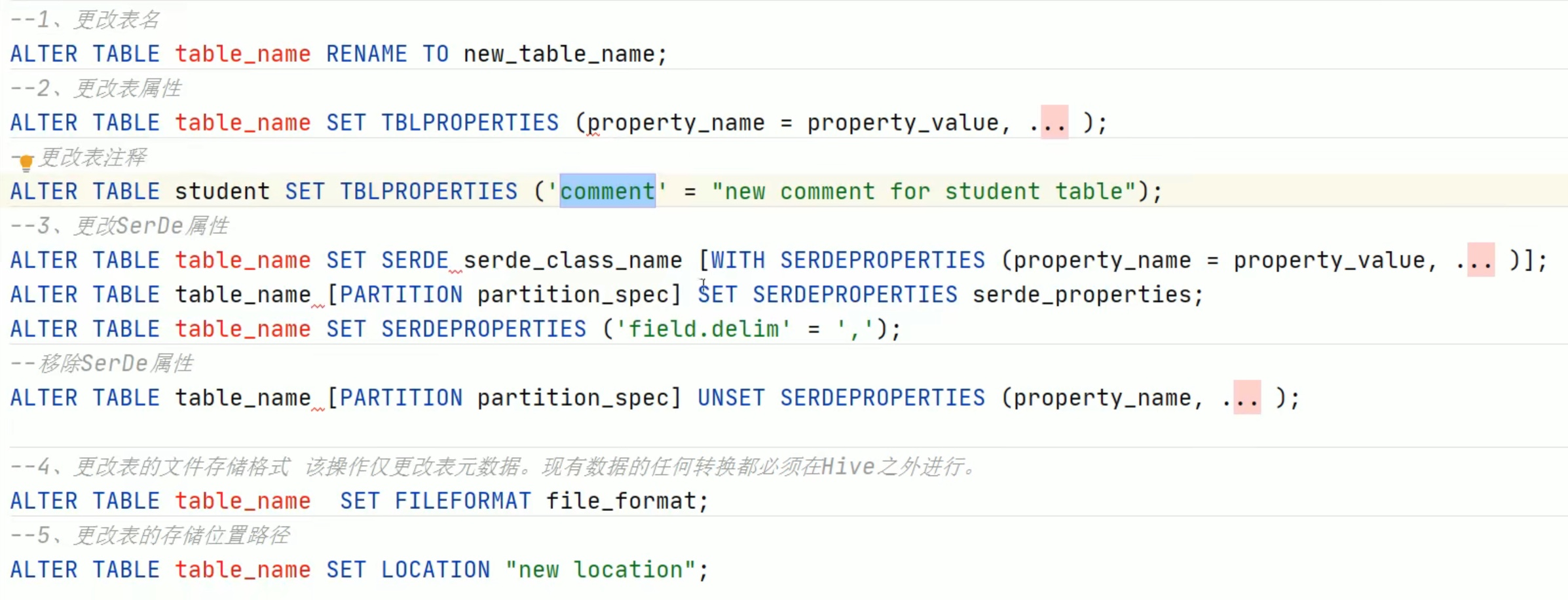
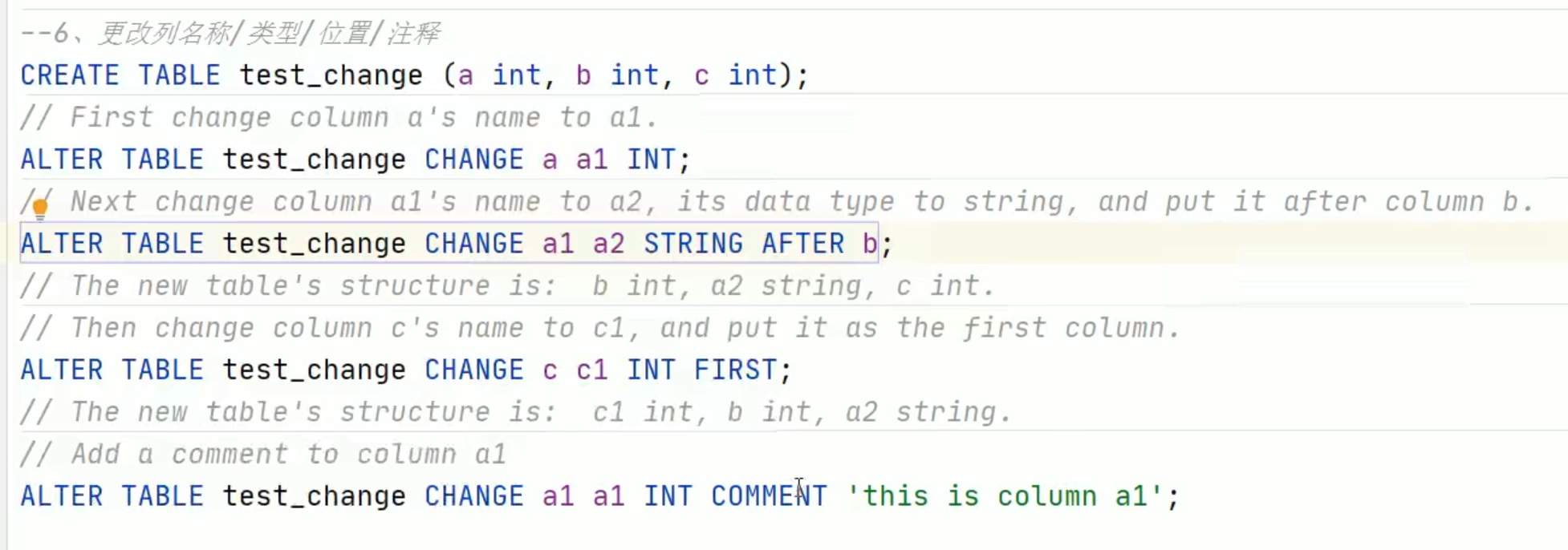



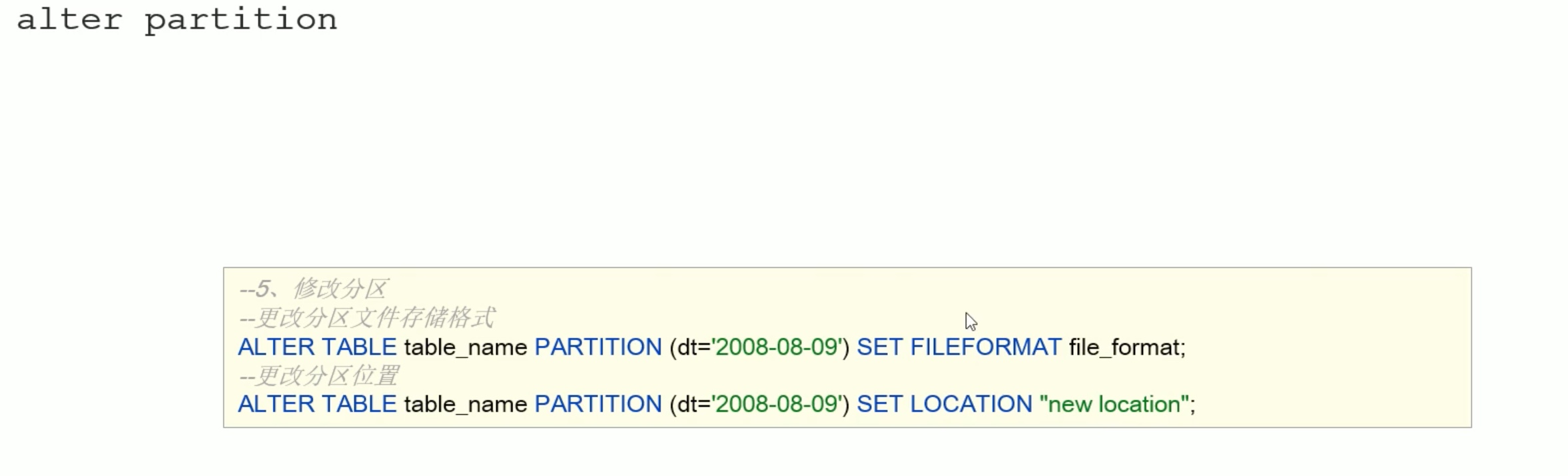
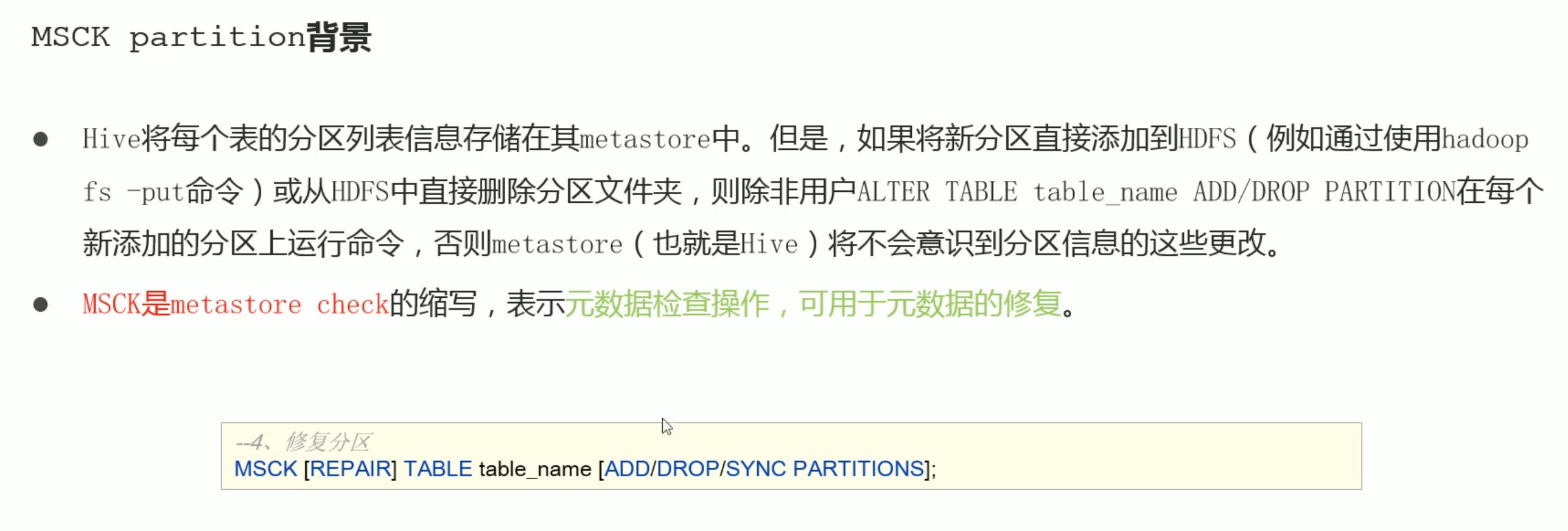

1、在hive的console创建一个分区的表;
2、直接用hdfs命令创建分区文件夹;hadoop fs -mkdir -p /user/hive/marehouse/databasename/tablename/role=sheshou(分区名)
3、hdfs 命令直接 put 数据上 对应的分区位置;
4、hive 的select 看不见上面的分区表;
5、用msck 修复分区,msck repair table 【tablename】 add partition;add partition 可以不写、msck默认添加分区。
6、hive可以操作新分区表了。
1、hdfs 直接删除分区表的一个分区;
2、hive 看不见变化,还误以为没有变;
3、msck repair table 【tablename】drop partition; 修复删除分区。
4、hive 正常了。
【sync】同步hive 的分区表元存储 与 hdfs上的内容。操作同上。