先下载
一、去各自官网先把东西都下载好

centos系统相关的安装部署可以参考之前Linux学习的笔记,什么固定虚拟机IP啦,安装mysql啦,远程文件传输啦,这里就不重复说了。
把这些工具下载好,然后在/opt 下新建hadoop文件夹、spark文件夹等等,把对应的压缩包放进去。
二、安装比较新的java:
三、复制一个虚拟机
(先关闭vmware程序,再把vmwarevm文件夹复制一个就好了,里面什么东西都是一样的,双击vmwarevm文件夹打开就能运行。)

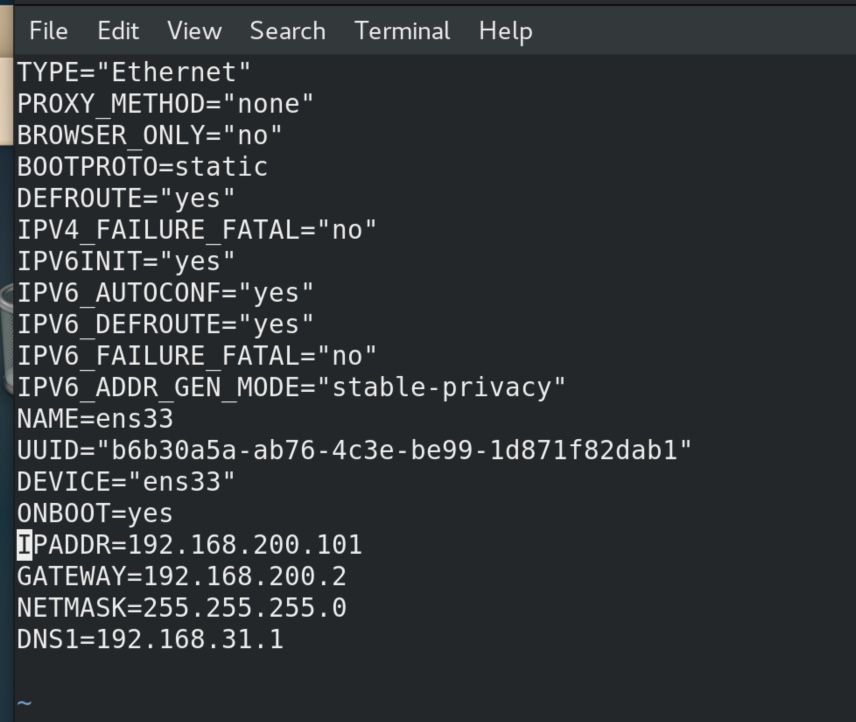
记得把不同机器的IP改一下,固定在同一网段不同的IP上。之前我固定的虚拟机的网关是192.168.200.2,node1机器固定的IP是192.168.200.100。记得把node2改为192.168.200.101。
1
2
|
vim /etc/sysconfig/network-scripts/ifcfg-ens33
|
四、修改主机名和hosts文件
1
2
3
4
|
su
vim /etc/hostname
vim /etc/hosts
|

五、虚拟机之间设置ssh无密码登录,同时关闭防火墙。
机器关闭防火墙(不然后面hadoop启动了找不到结点):
1
2
3
|
systemctl stop firewalld
systemctl disable firewalld
|
相互把公钥放在对面对应存公钥的位置。
补充知识点:


1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
ssh-keygen -t dsa -P ''
cat id_dsa.pub >> authorized_keys
scp authorized_keys root@node02:/root/.ssh/authorized_keys
cat id_dsa.pub >> authorized_keys
scp authorized_keys root@node01:/root/.ssh/authorized_keys
|
六、在node01安装Hadoop
1、配置java和Hadoop环境
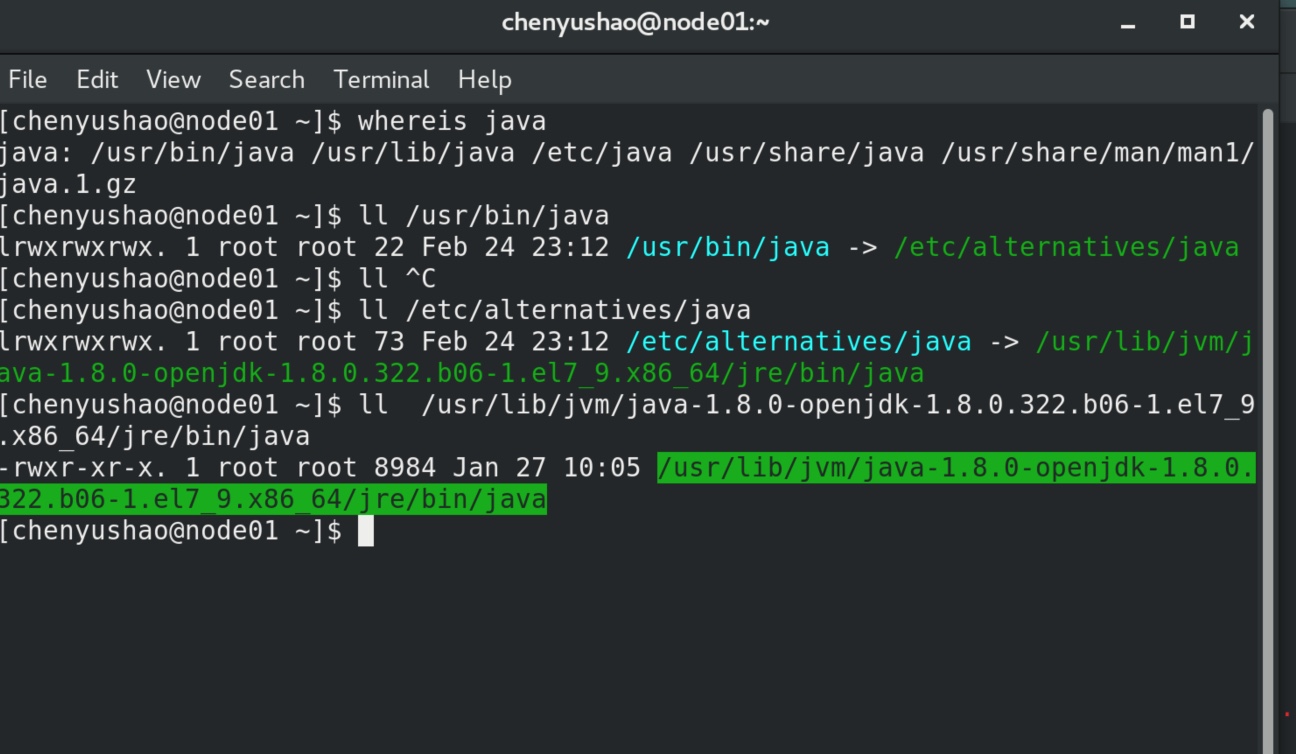
因为是yum安装的java,我们先whereis,再不断了 ll 软连接,溯源找到java实体文件,不再是软连接时,结合这个地址可以分析得到, JAVA_HOME 的值应该就是jre前面这一截。
1
2
|
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64
|
运行javac命令报错:bash:javac:command not found;
最后发现自带的jdk是没有安装开发环境的,需要安装devel才有javac命令。
(找到jdk的安装目录下,发现只有jre文件夹,没有bin、lib等文件夹)。
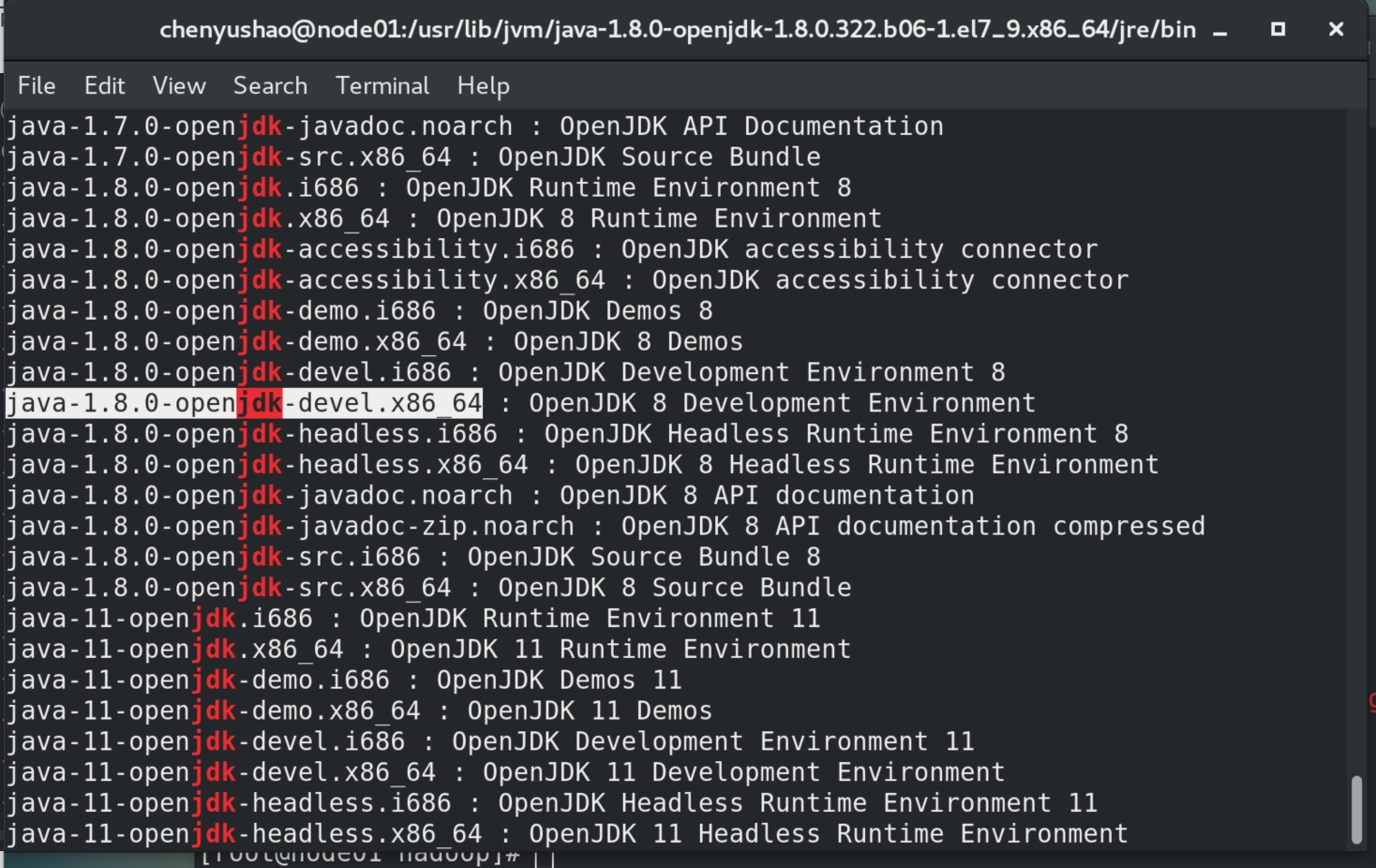
解决方法:使用yum安装开发环境 devel。(注意下载对应的版本。所以最好用yum找到准确的devel版本名字,精准下载)
用yum查找可以安装的jdk:yum search java|grep jdk
1
2
| yum install java-1.8.0-openjdk-devel.x86_64
|

1
2
3
4
5
6
7
8
9
10
11
12
| vim /root/.bash_profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64
export PATH=.:$JAVA_HOME:$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/hadoop/hadoop
export PATH=.:$JAVA_HOME:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /root/.bash_profile
hadoop version
|
(后续综述)
配置文件目录: /opt/hadoop/hadoop/etc/hadoop 需要修改的配置文件:hadoop-env.sh,core-site.xml, hdfs-site.xml ,(配置mapreduce)yarn-site.xml,mapred-site.xml ,workers
2、配置hadoop-env.sh(目的是绑定java和Hadoop)
1
2
3
| vim /opt/hadoop/hadoop/etc/hadoop/hadoop-env.sh
|
1
2
3
4
5
6
7
8
9
10
| export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_PID_DIR=/opt/hadoop/hadoop/data/pids
export HADOOP_LOG_DIR=/opt/hadoop/hadoop/data/logs
|
3、配置core-site.xml(Hadoop核心文件配置)
1
2
| vim /opt/hadoop/hadoop/etc/hadoop/core-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| <configuration>
<!--指定文件系统的入口地址,可以为主机名或IP -->
<!--端口默认8020 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<!--HDFS的存储目录,也就是Hadoop临时工作存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop/tmp</value>
</property>
</configuration>
|
4、配置yarn-env.sh
1
| vim /opt/hadoop/hadoop/etc/hadoop/yarn-env.sh
|
1
2
|
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64
|
5、配置hdfs-site.xml (hdfs存储配置)
1
2
| vim /opt/hadoop/hadoop/etc/hadoop/hdfs-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| <configuration>
<!--指定hdfs备份数量,小于等于从节点数目,就是从属设备的数量。 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--自定义hdfs的namenode存储位置。 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/hadoop/data/name</value>
</property>
<!--自定义hdfs的datanode存储位置。 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/hadoop/data/data</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--注意Hadoop3以后端口由50070改为了9870 -->
<property>
<name>dfs.namenode.http-address</name>
<value>node01:9870</value>
</property>
</configuration>
|
6、配置mapred-site.xml
1
| vim /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| <configuration>
<property>
<name>mapred.job.tracker</name>
<value>node01:9001</value>
</property>
<!--hadoop的mapreduce程序运行在yarn上,默认值为local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/hadoop/hadoop/share/hadoop/mapreduce/*, /opt/hadoop/hadoop/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
|
7、配置yarn-site.xml(定义yarn集群)
1
| vim /opt/hadoop/hadoop/etc/hadoop/yarn-site.xml
|
1
2
3
4
5
6
7
8
9
10
| <configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
</configuration>
|
8、配置workers
1
2
| vim /opt/hadoop/hadoop/etc/hadoop/workers
|
9、将Hadoop文件发送到其它节点
1
2
|
scp -r /opt/hadoop/hadoop node02:/opt/hadoop
|
七、初始化、启动、验证Hadoop。
1
2
3
4
5
6
7
8
9
10
11
| cd /opt/hadoop/hadoop/bin
hdfs namenode -format
cd /opt/hadoop/hadoop/sbin
source /root/.bash_profile
start-dfs.sh
start-yarn.sh
|

细心的看看可以发现我前面有个小问题,因为我复制出node02时,node02继承了node01的java,但是那时node01还没有装devel开发环境,我们在node02机器javac会说找不到此命令,因此我回到 《六-1、配置java和Hadoop环境》在node02机器重复一遍
1
2
3
4
5
6
7
8
9
10
11
12
|
yum install java-1.8.0-openjdk-devel.x86_64
vim /root/.bash_profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64
export PATH=.:$JAVA_HOME:$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/hadoop/hadoop
export PATH=.:$JAVA_HOME:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /root/.bash_profile
|
1
2
3
4
5
6
7
8
9
10
|
source /root/.bash_profile
cd /opt/hadoop/hadoop/bin
hdfs namenode -format
cd /opt/hadoop/hadoop/sbin
start-dfs.sh
start-yarn.sh
|
此时在主节点node01 输入 jps可以看到已经成功启动的进程:
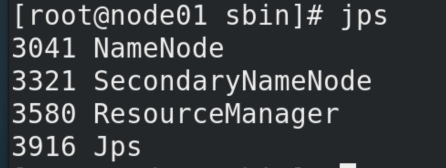
此时在从属节点node012输入 jps可以看到已经成功启动的进程: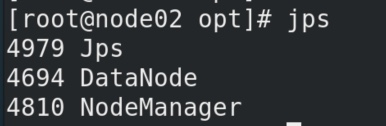
特殊情况补充:
如果 jps 之后 看见了
【进程号】 – process information unavailable
这时可以通过进入本地文件系统的/tmp目录下,删除名称为
hsperfdata_{username}的文件夹,然后重新启动Hadoop。
注意:要将所有用户的这个类似的文件夹全部删除掉才行。
1
2
3
| cd /tmp
ls | grep hsperfdata
|

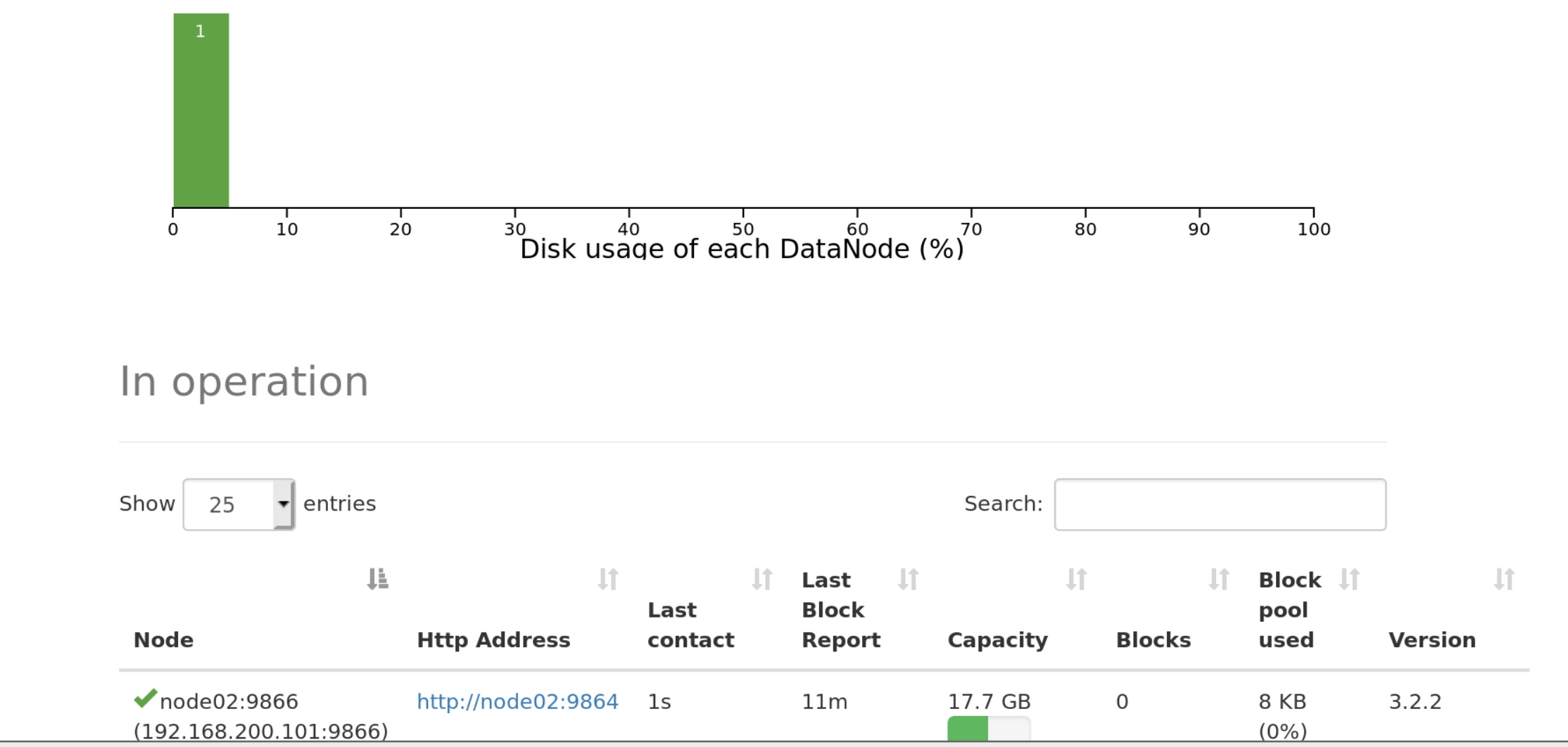
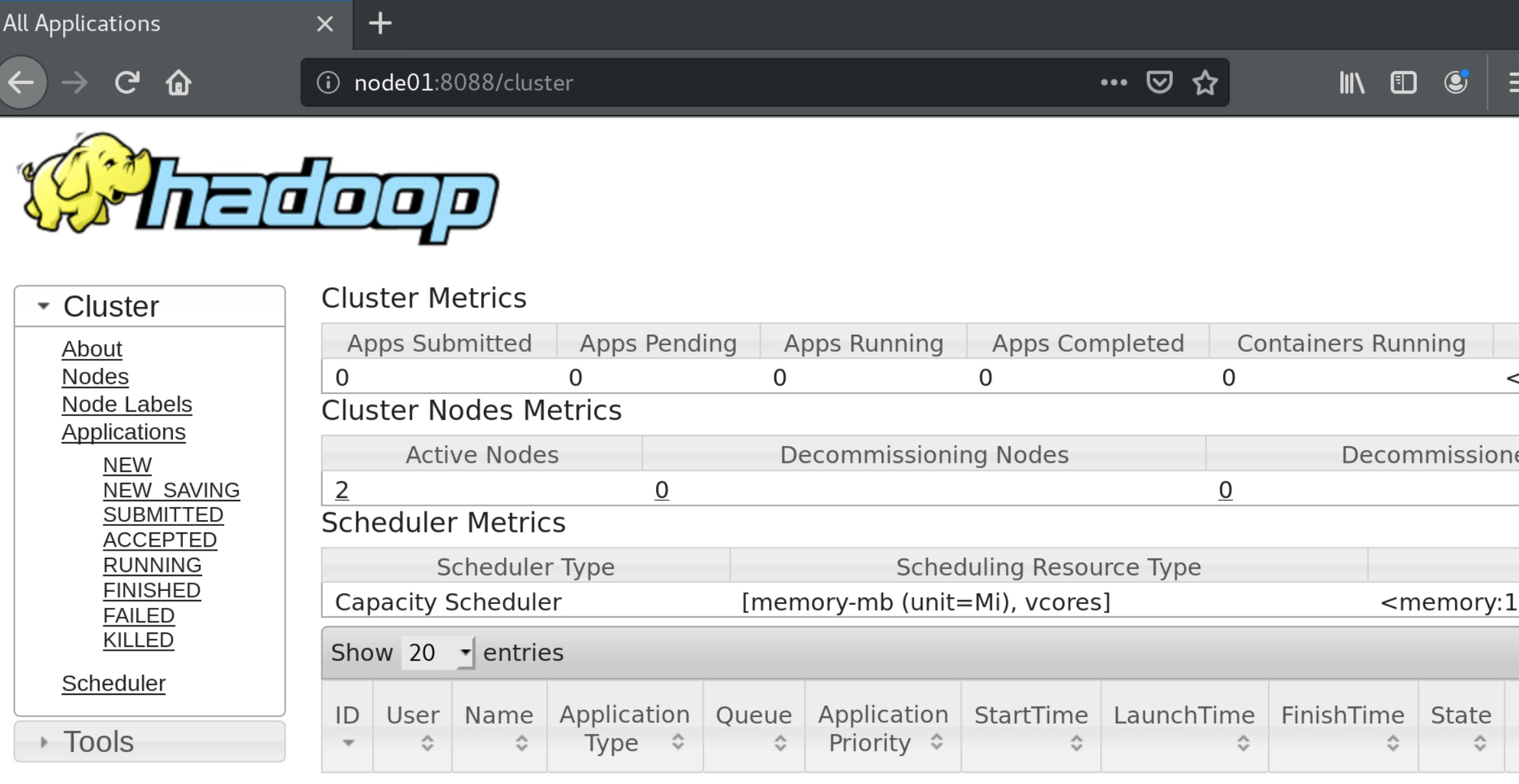
可以看见我只有两个运行的结点,子结点只有一个,实际上应该至少搞三个子结点,重复操作几遍新建结点的步骤即可。
安装配置完之后的小插曲:
第二天
第二天我重新又装了一遍Hadoop练手,jps后发现secondarynamenode死活没有启动,按照网上的建议删进程重新开服务也不行,我只好去logs里找:

发现问题原来出在这里!!
1
| vim /opt/hadoop/hadoop/etc/hadoop/hdfs-site.xml
|
1
2
3
4
5
6
| <property>
<name>dfs.namenode.http-address</name>
<value>node01:9870</value>
</property>
|
结论:一定要养成常看logs文件排错的好习惯!
半个月以后
问题:在slave子机器node02 上 启动Hadoop时,通过jps目录发现没有datanode进程。
解决方案: clusterID不匹配导致的问题,步骤如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| 1、执行./stop-all.sh关闭集群
2、在slave机器上直接删除Hadoop。
3、在master上 删除存放hdfs数据块的文件夹(hadoop/tmp/),然后重建该文件夹
4、在master上 删除hadoop下的日志文件logs,我的在hadoop/data/logs,这个直接删除即可。
5、在master上 把 namenode和datanode 存放位置的文件夹删除,我的在 hadoop/data/name和hadoop/data/data。
6、在master上 将Hadoop文件发送到slave机器:scp -r /opt/hadoop/hadoop node02:/opt/hadoop
7、在master上 执行hadoop namenode -format格式化hadoop
1、再mysql内删除 hive生成的存储元数据的database(从hive-site.xml 中可以看见 我之前设置的就是 一个叫 ”hive“ 的databases,里面74个表)。
2、开启Hadoop服务。
3、在hive 的bin中初始化metadata,指定元数据在mysql当中。
cd /opt/hive/apache-hive-3.1.2-bin/bin
schematool -initSchema -dbType mysql -verbos
|