简介



表设计优化
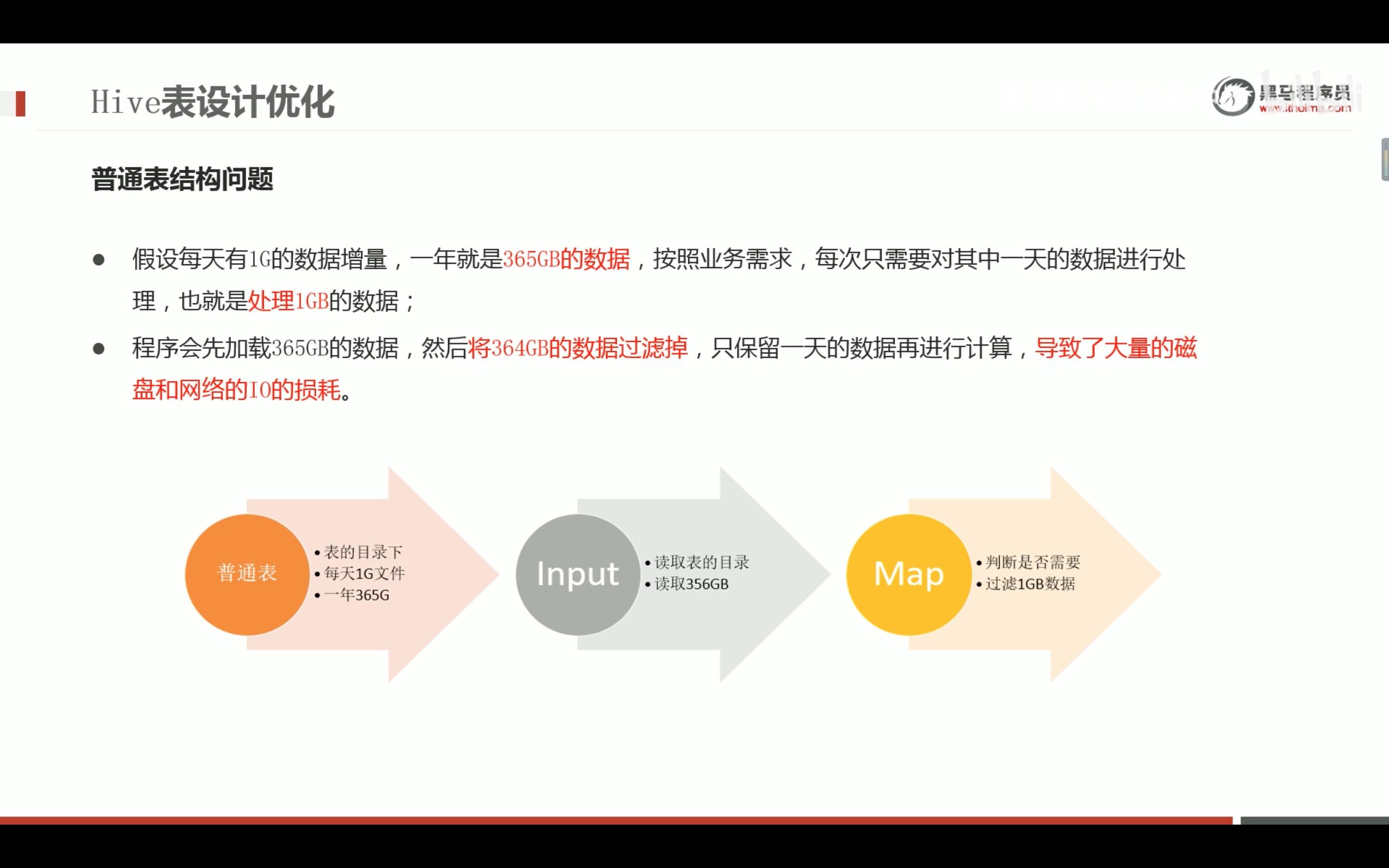
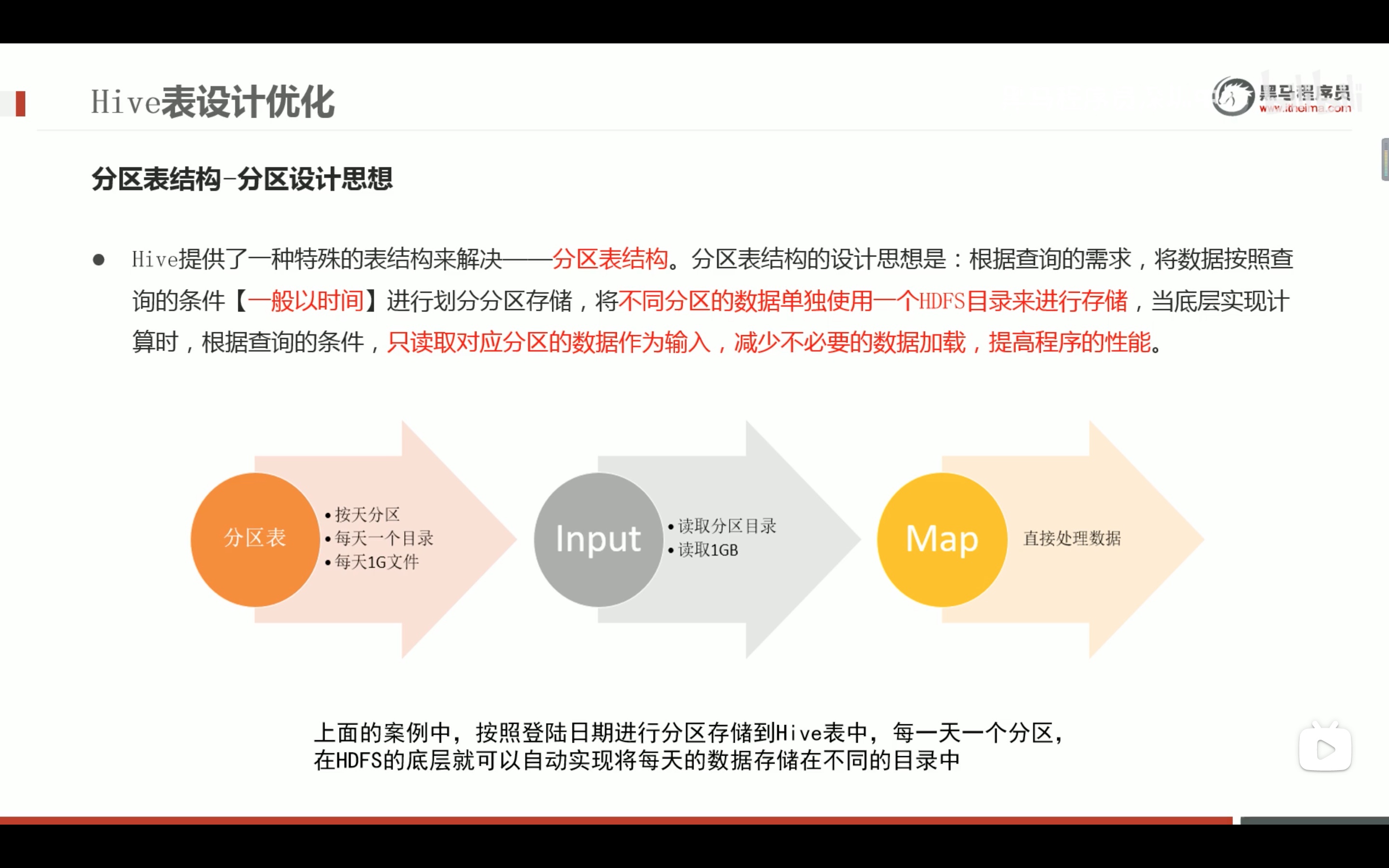

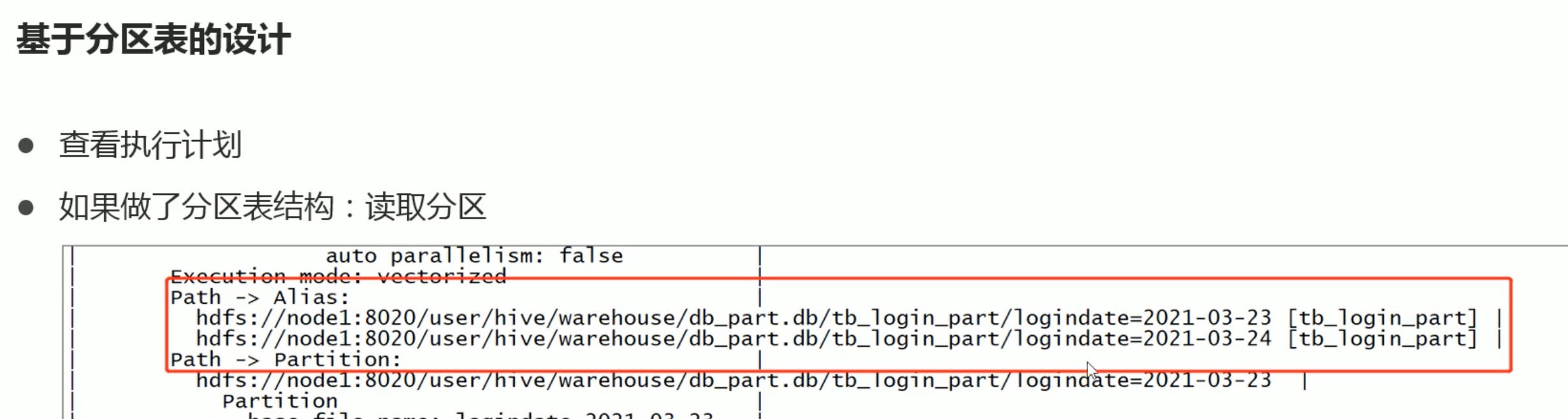
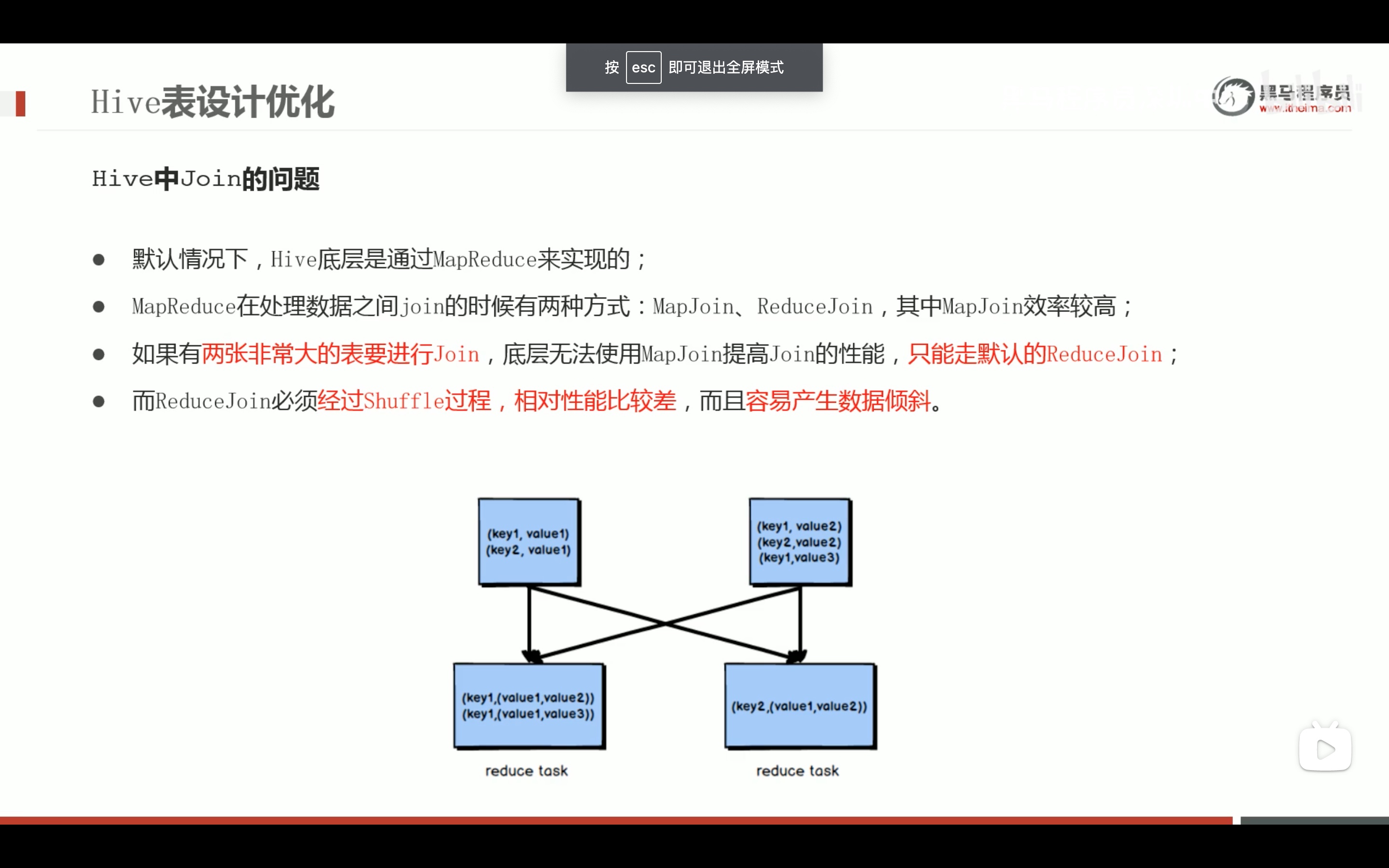
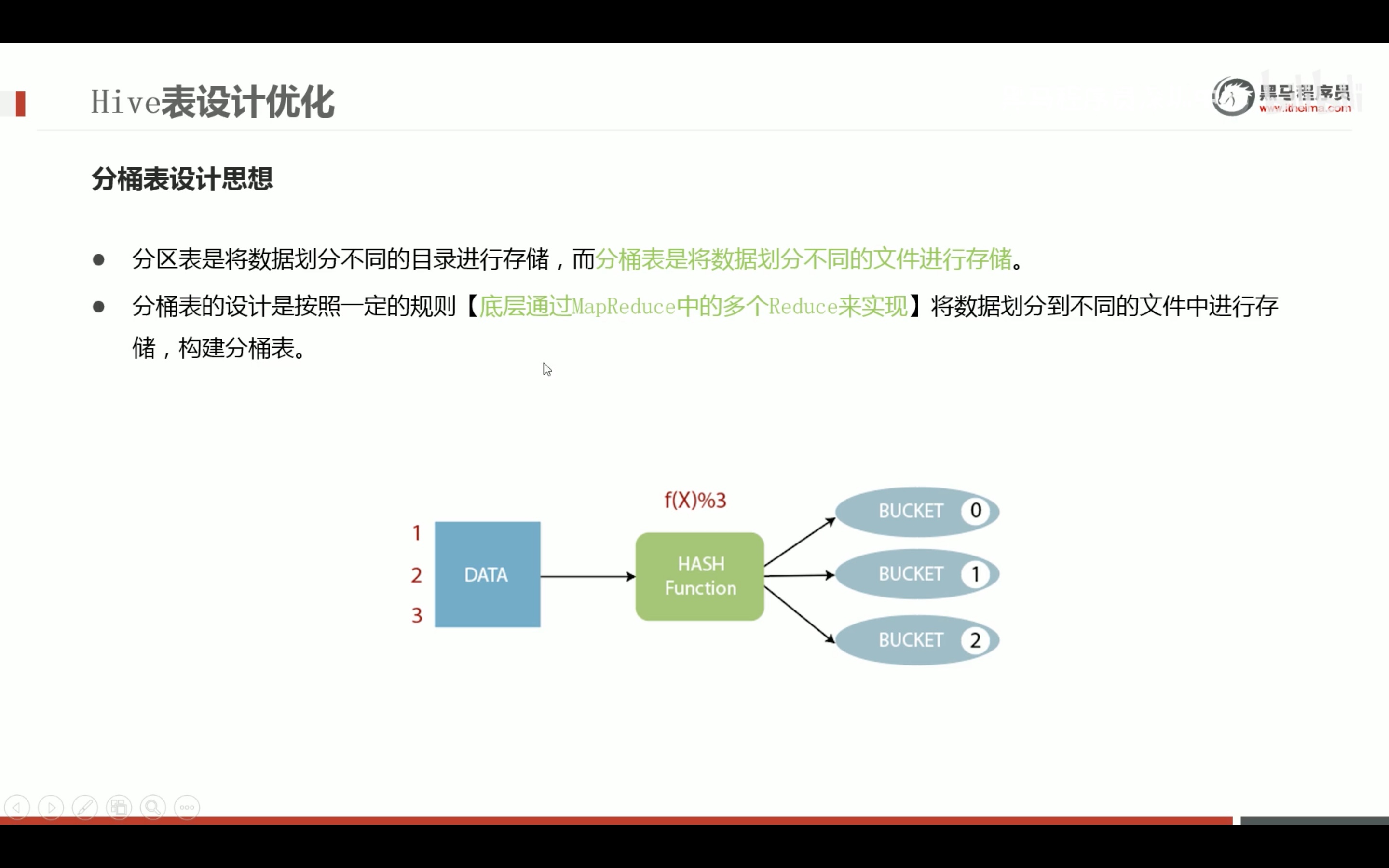
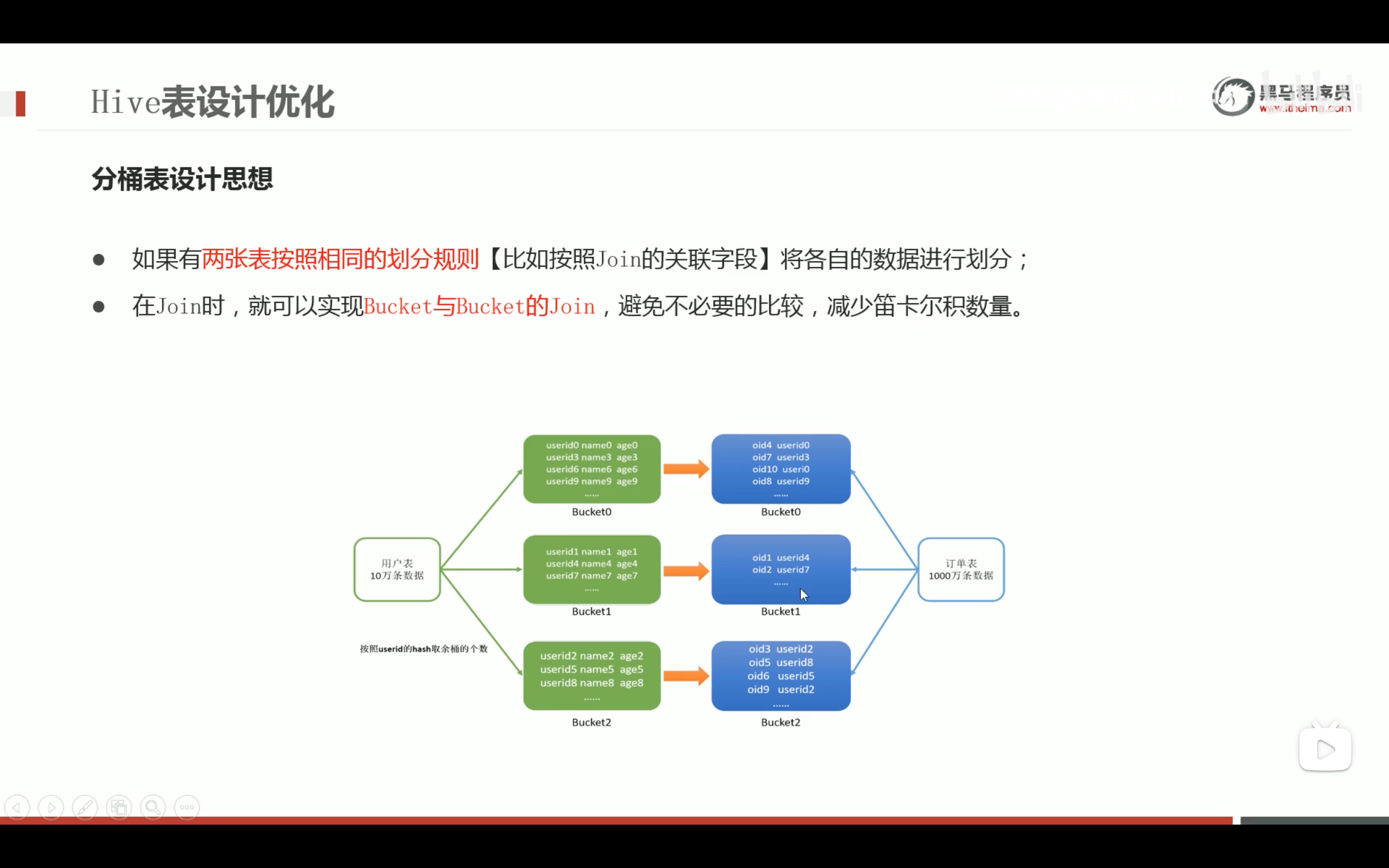
不按join字段分桶,将毫无意义。

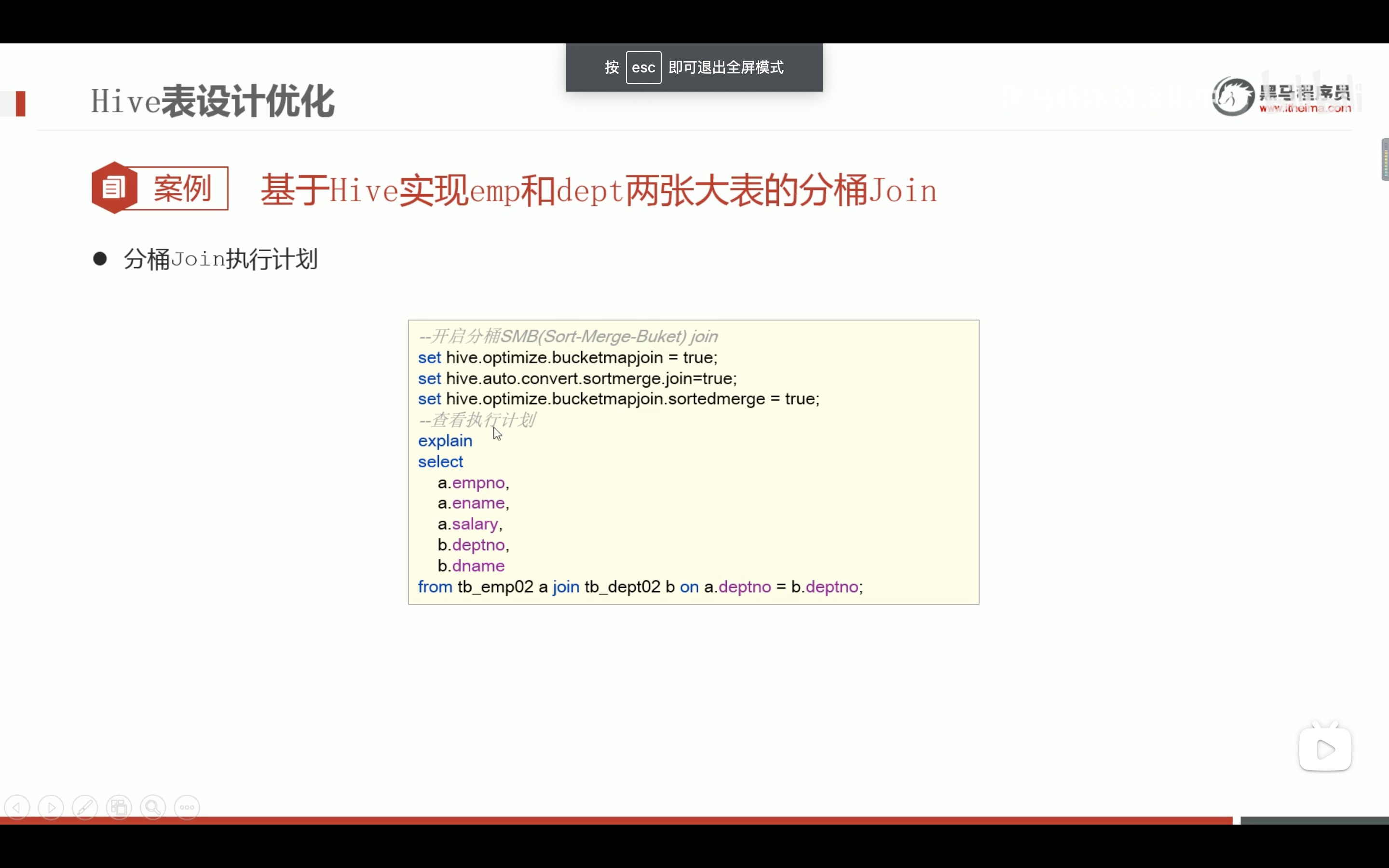

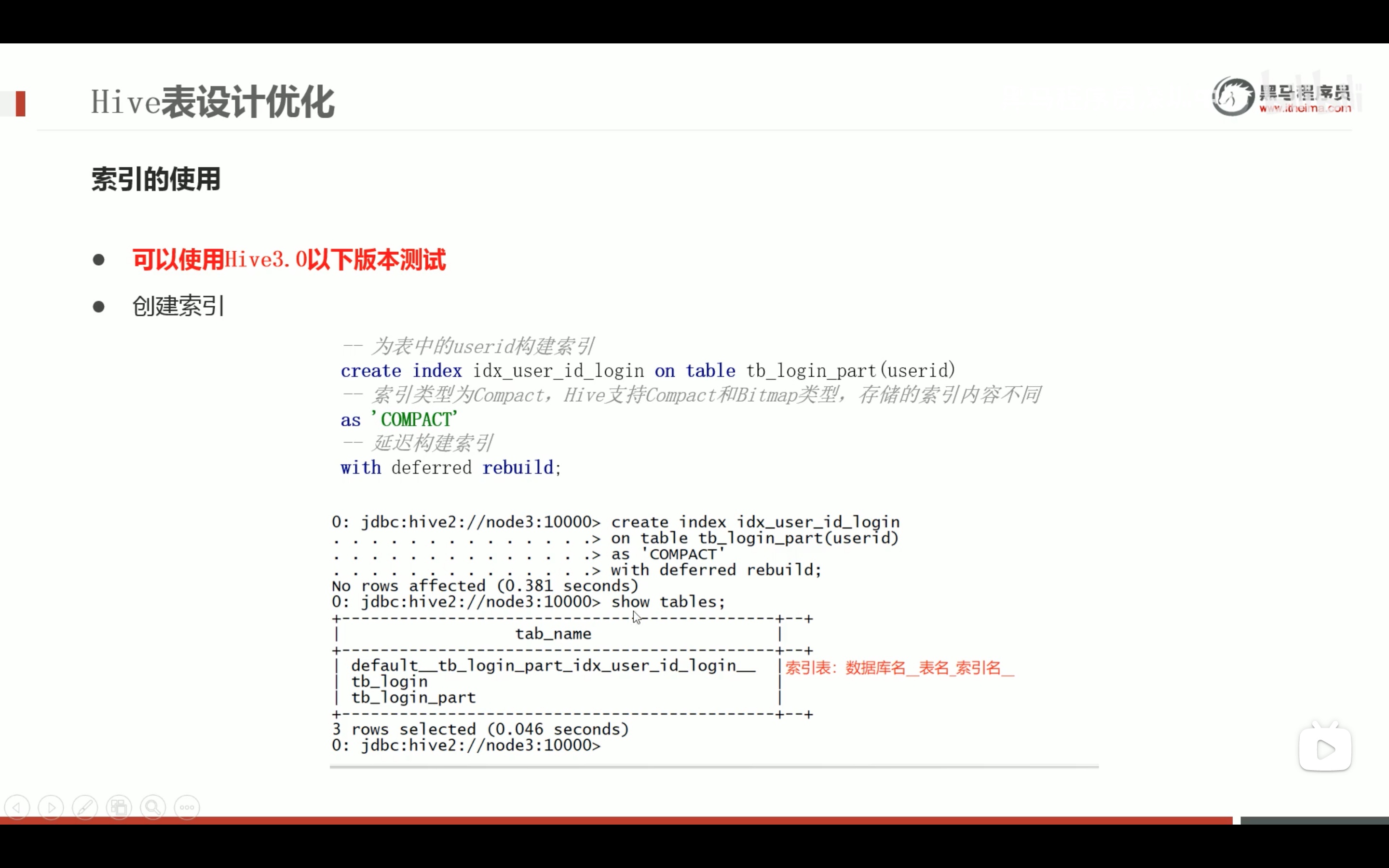
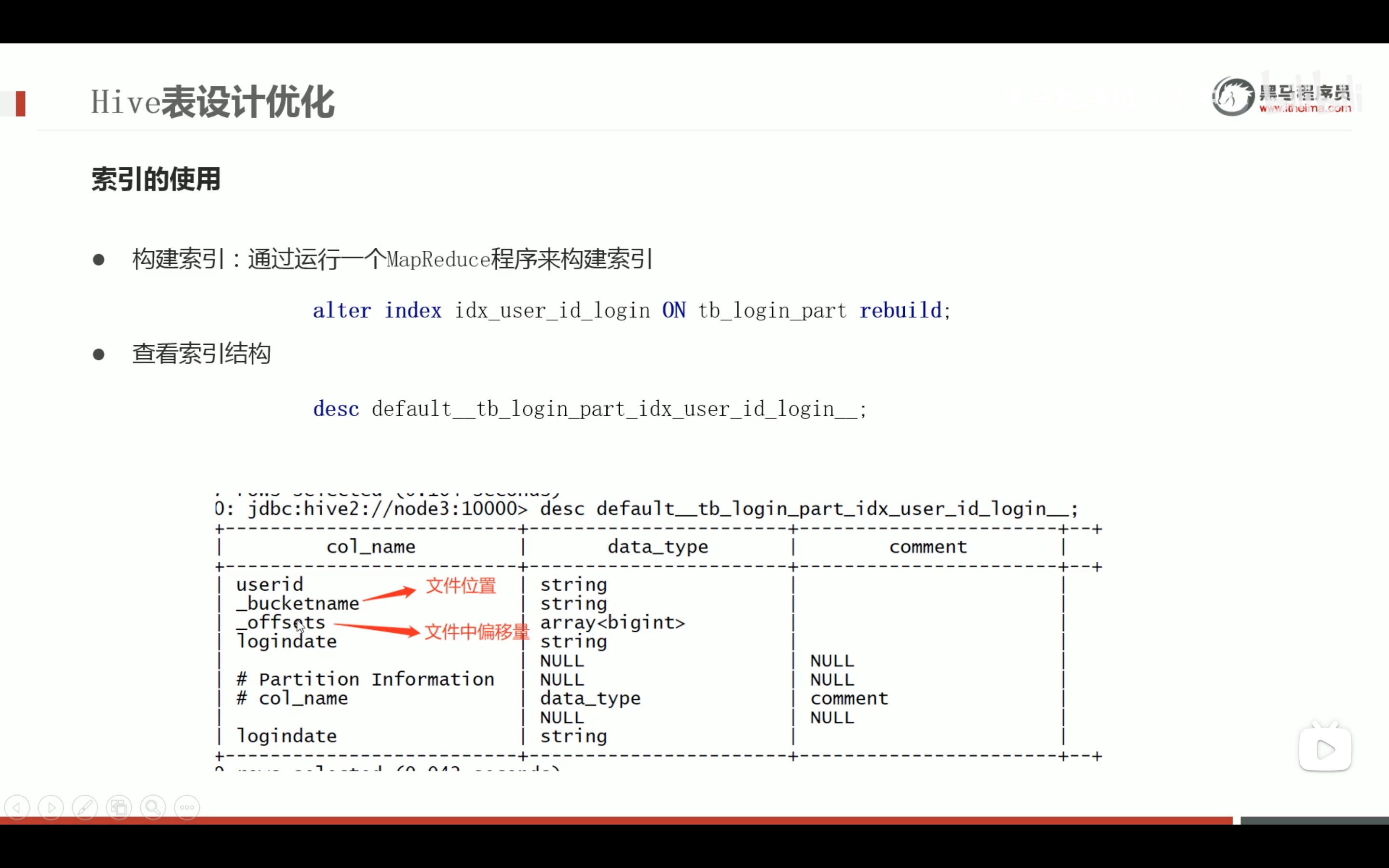
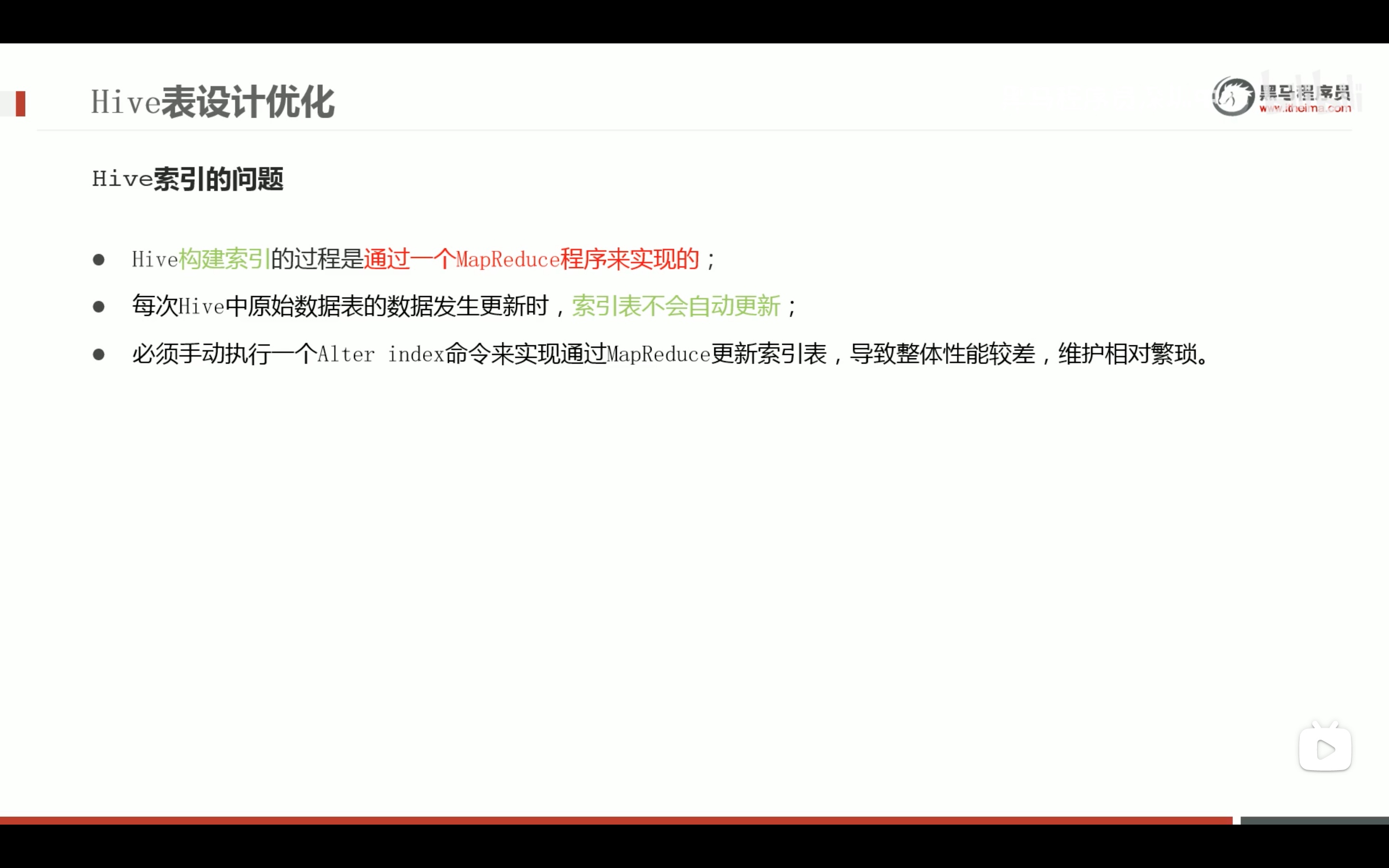
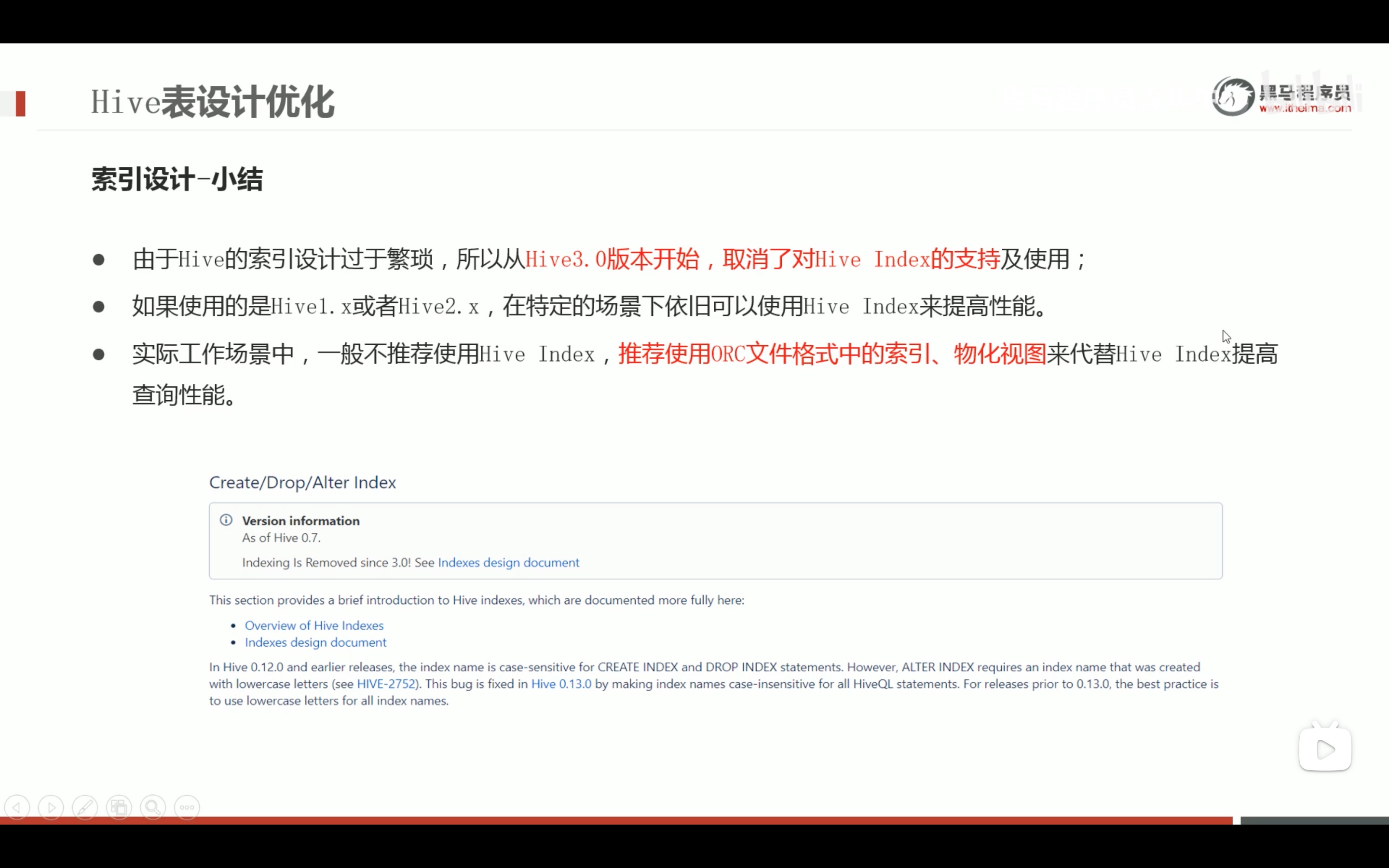
表数据优化

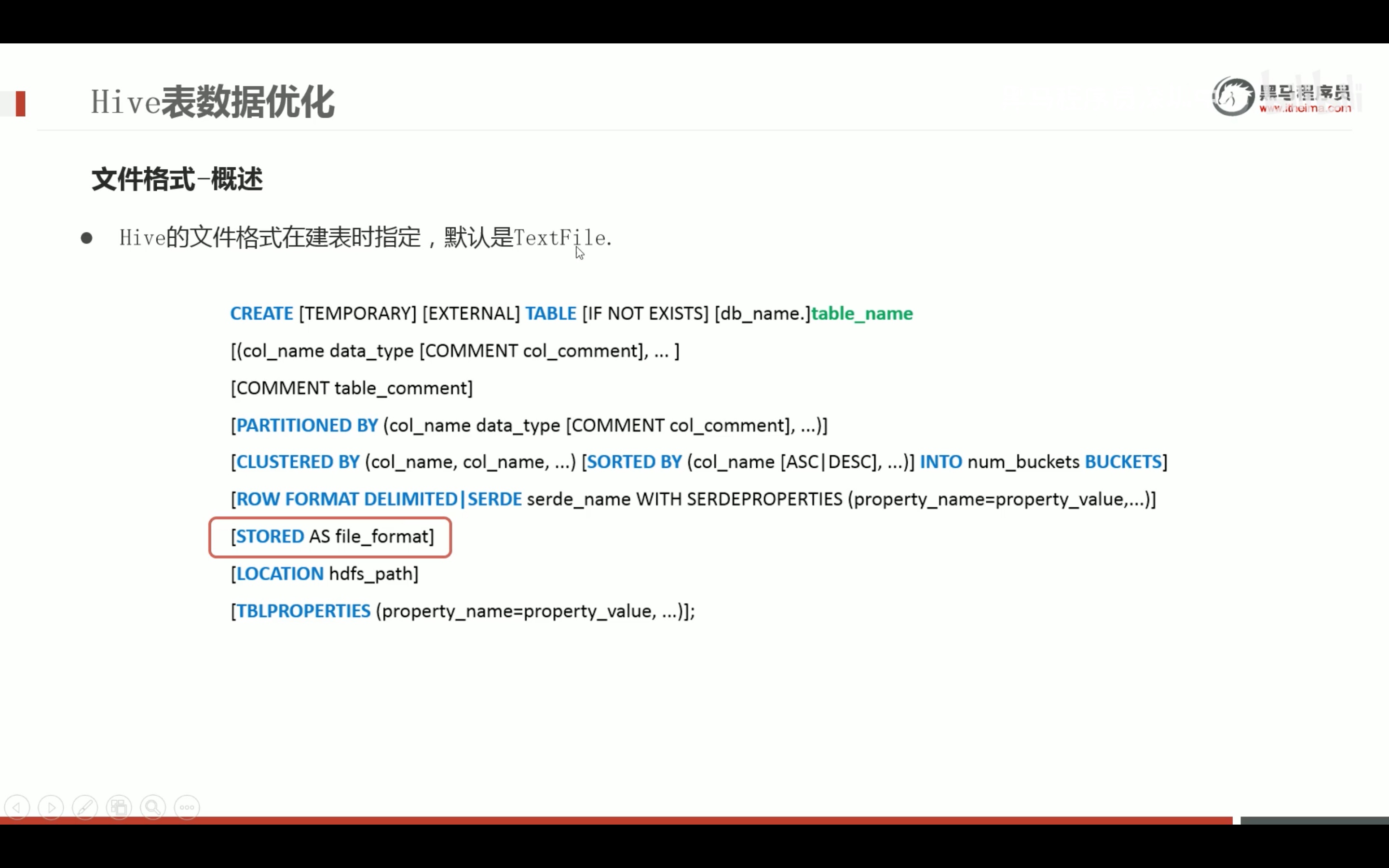

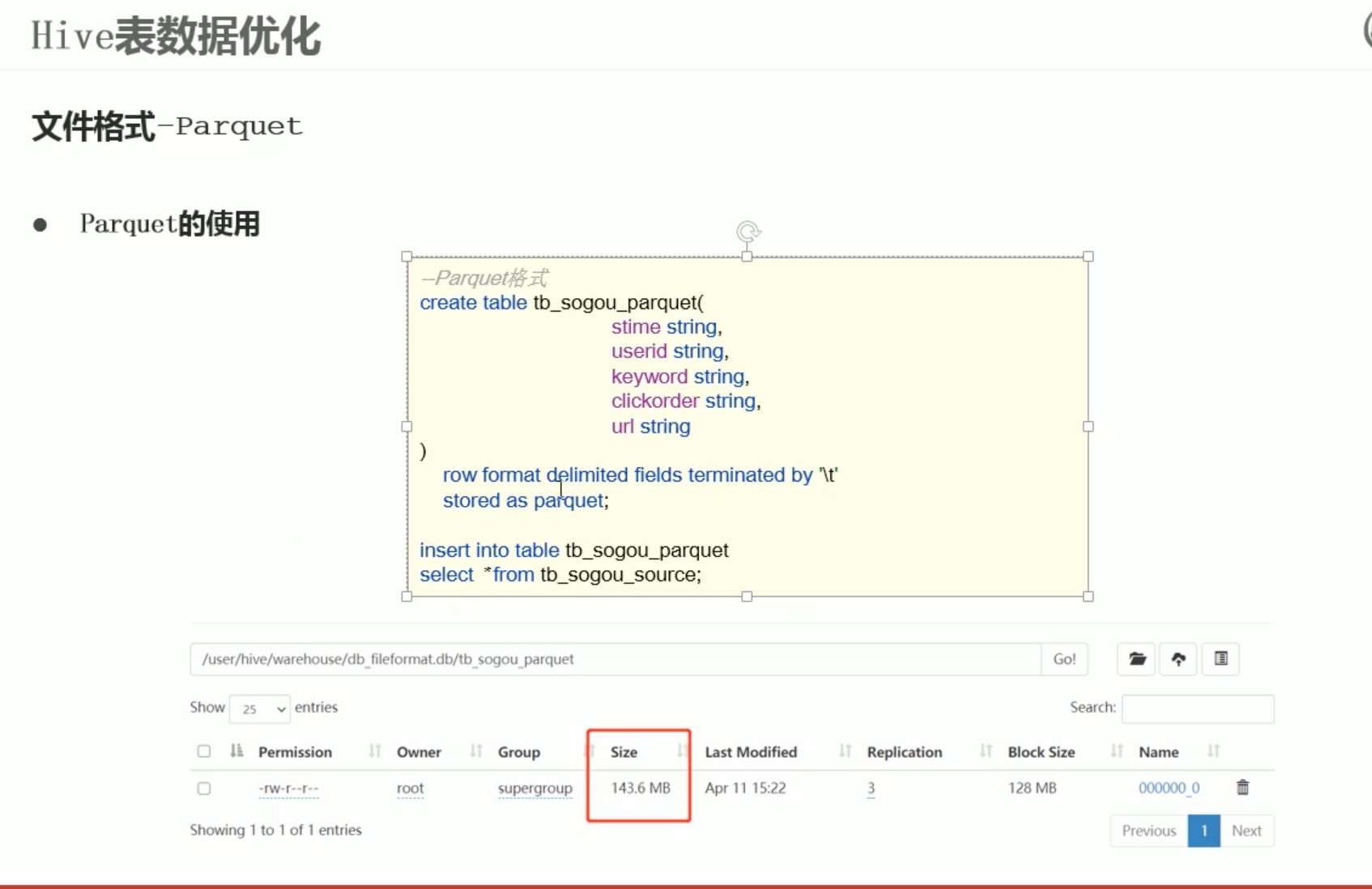

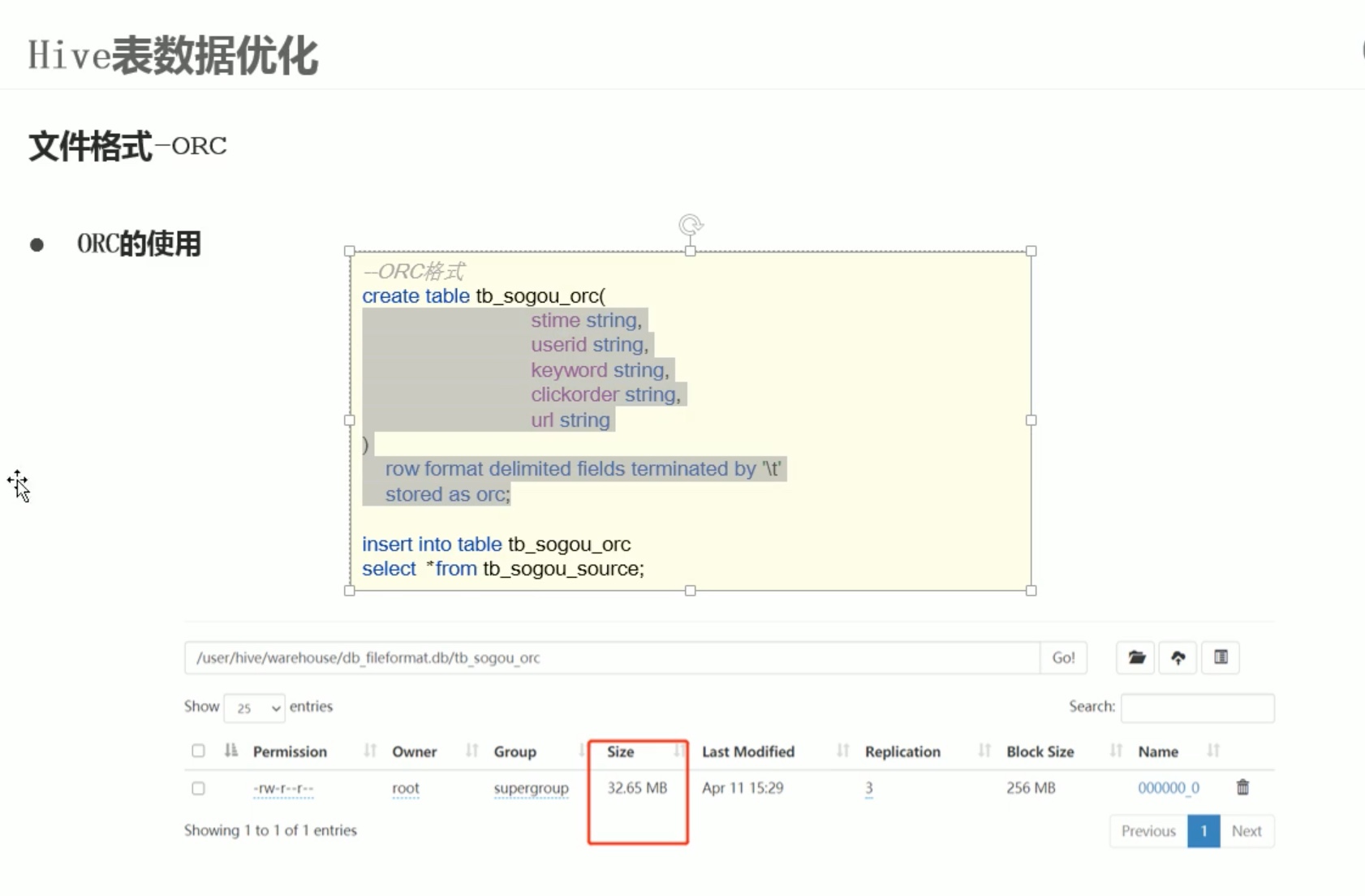
load 只是搬运数据,不改变数据结构,用orc格式或者别的什么格式,都用insert into加载。
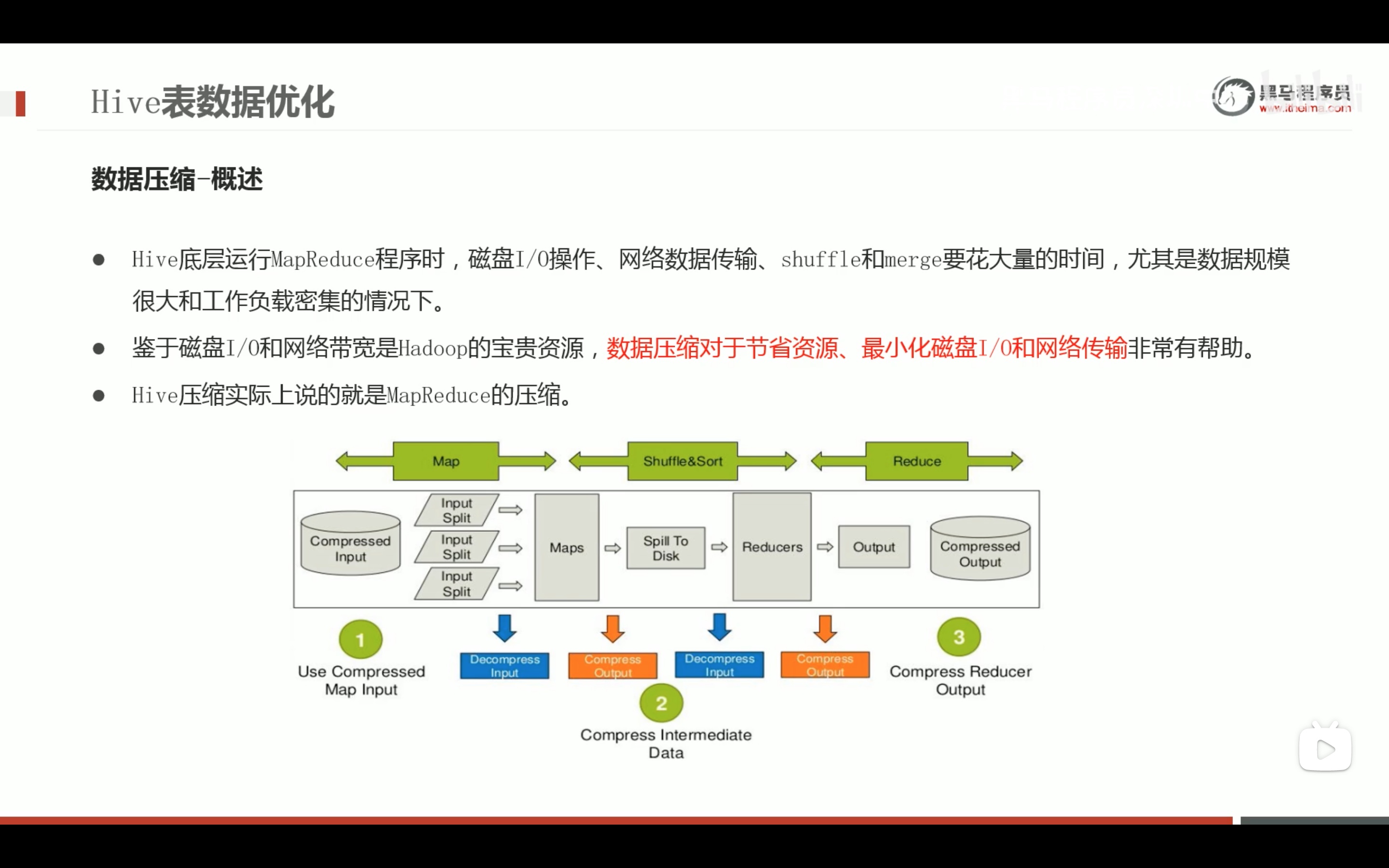
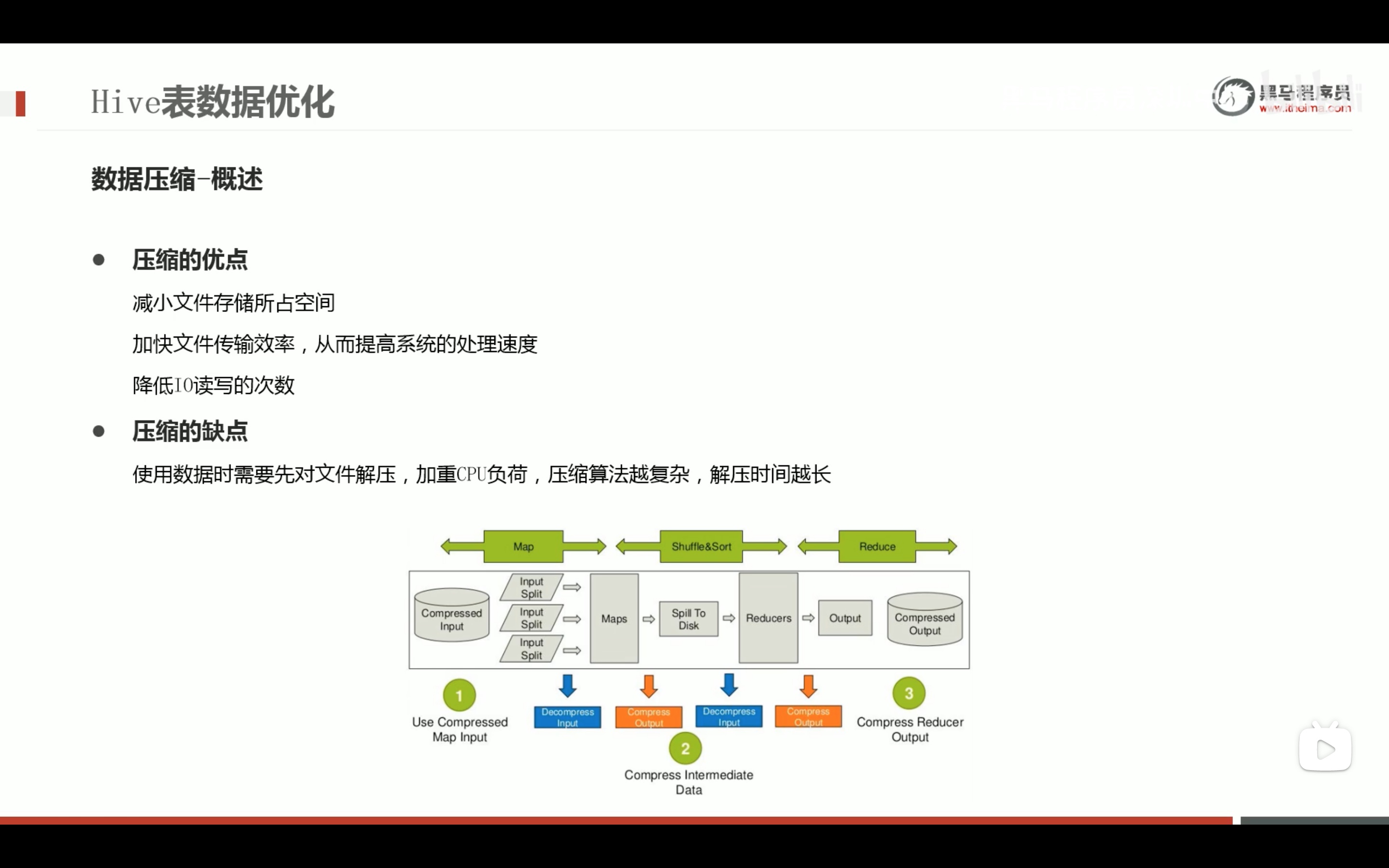
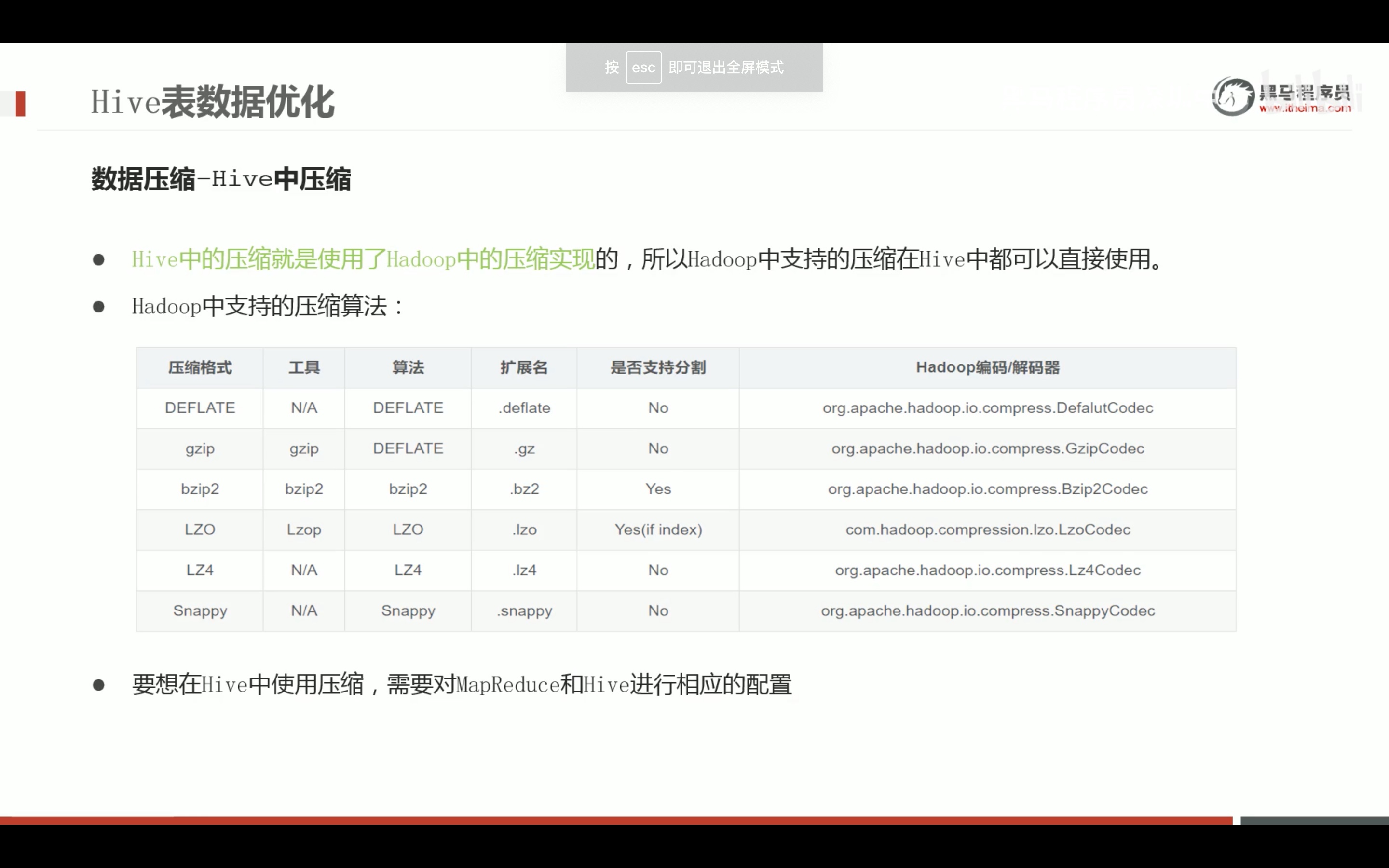
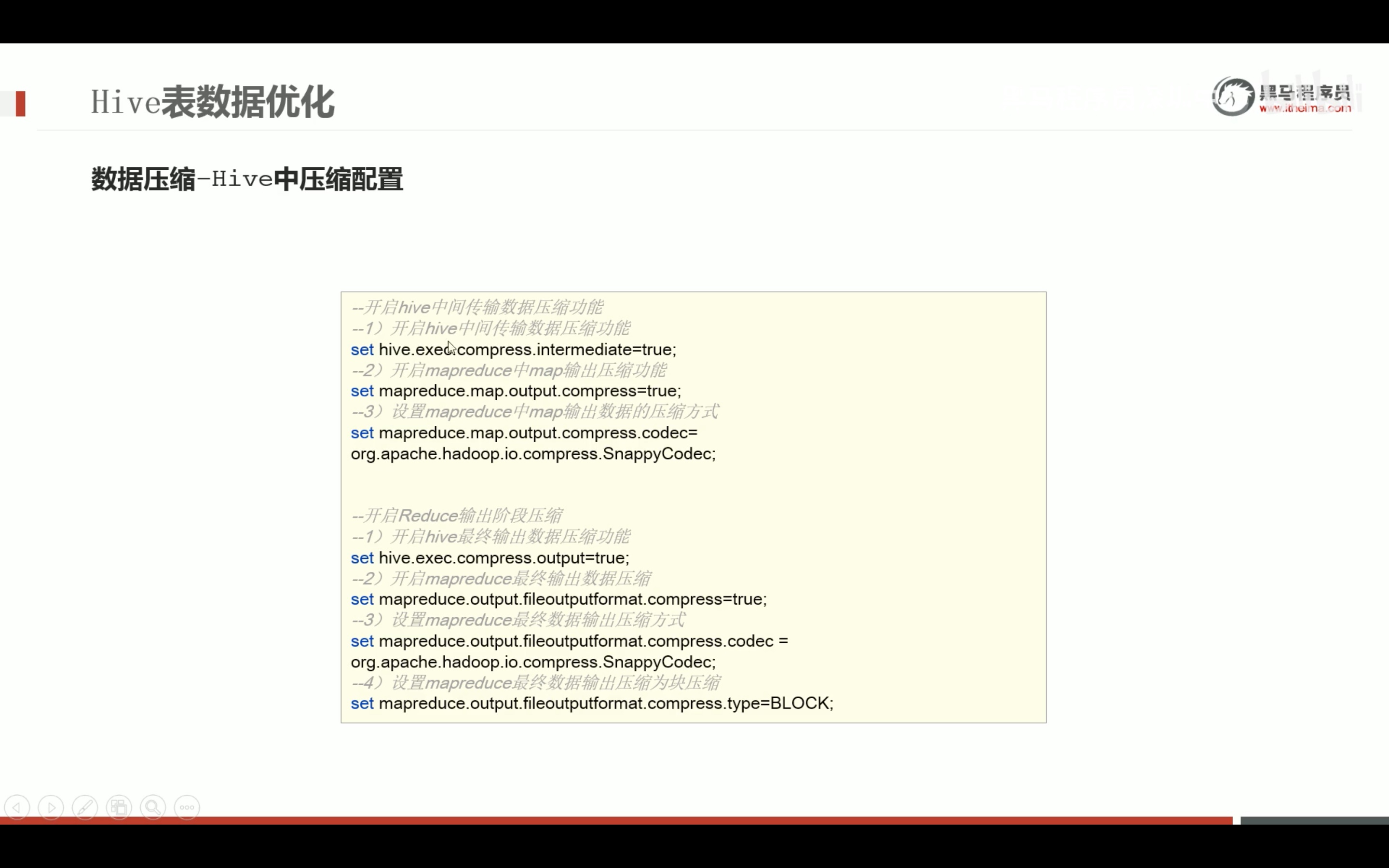
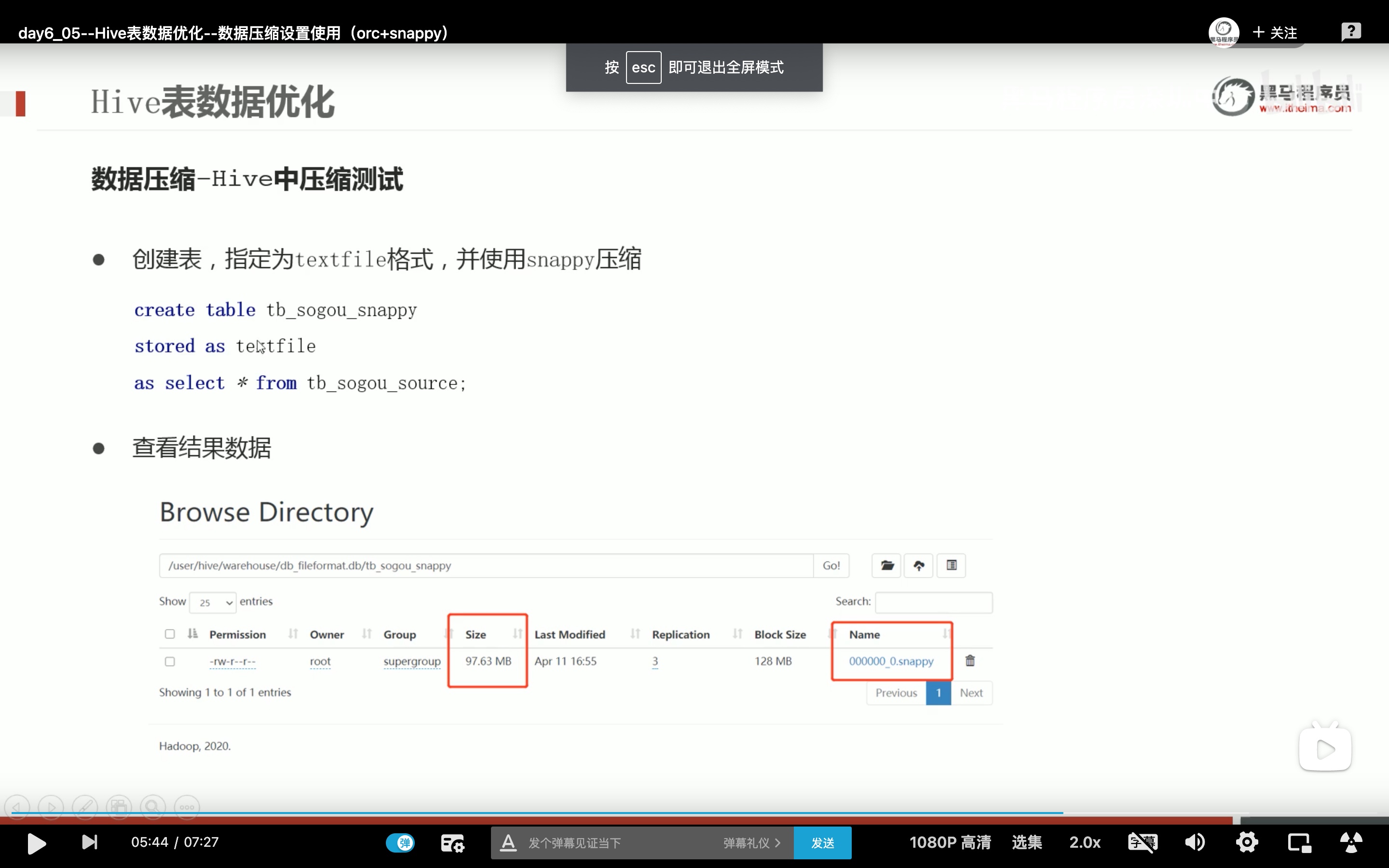
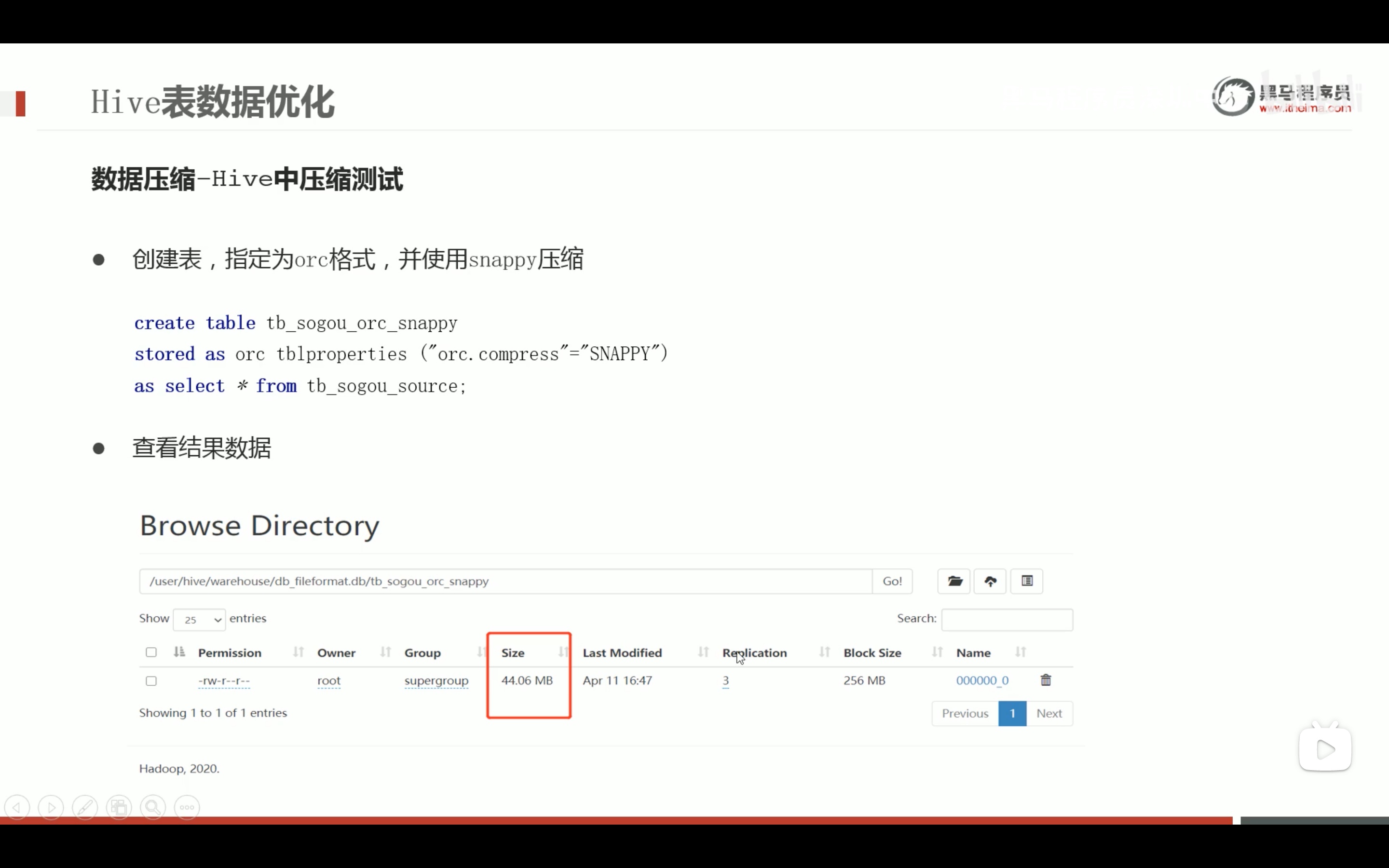
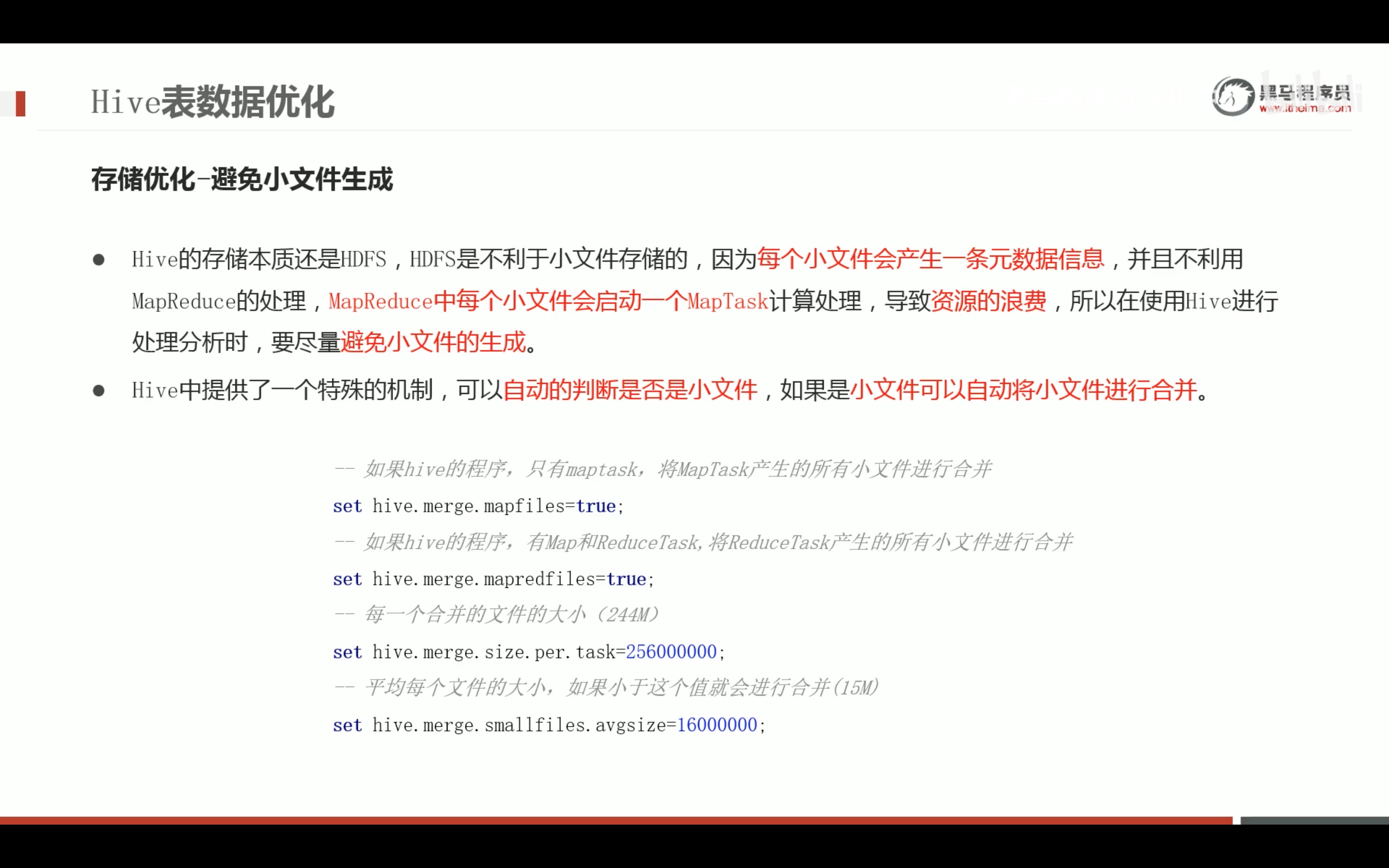
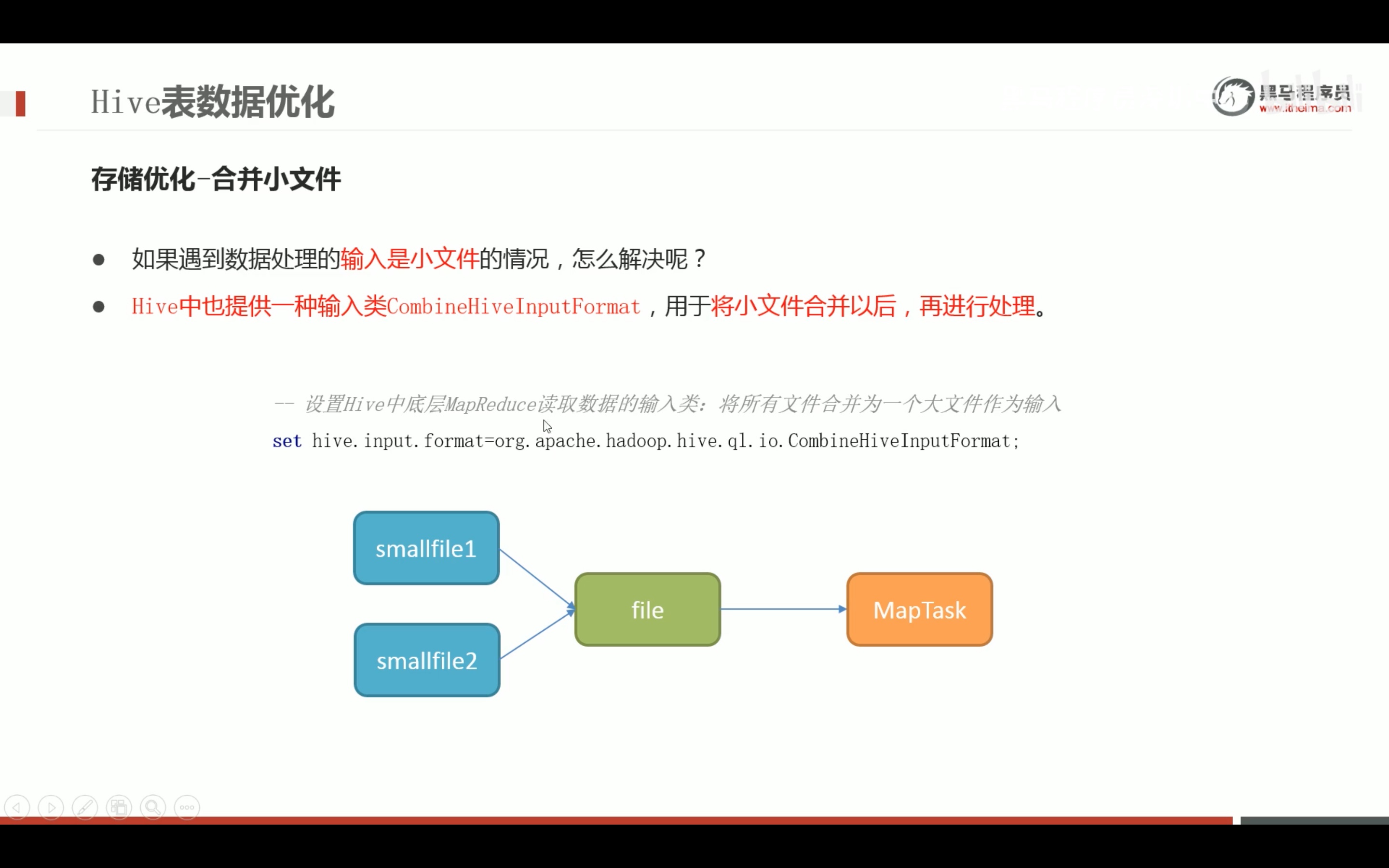
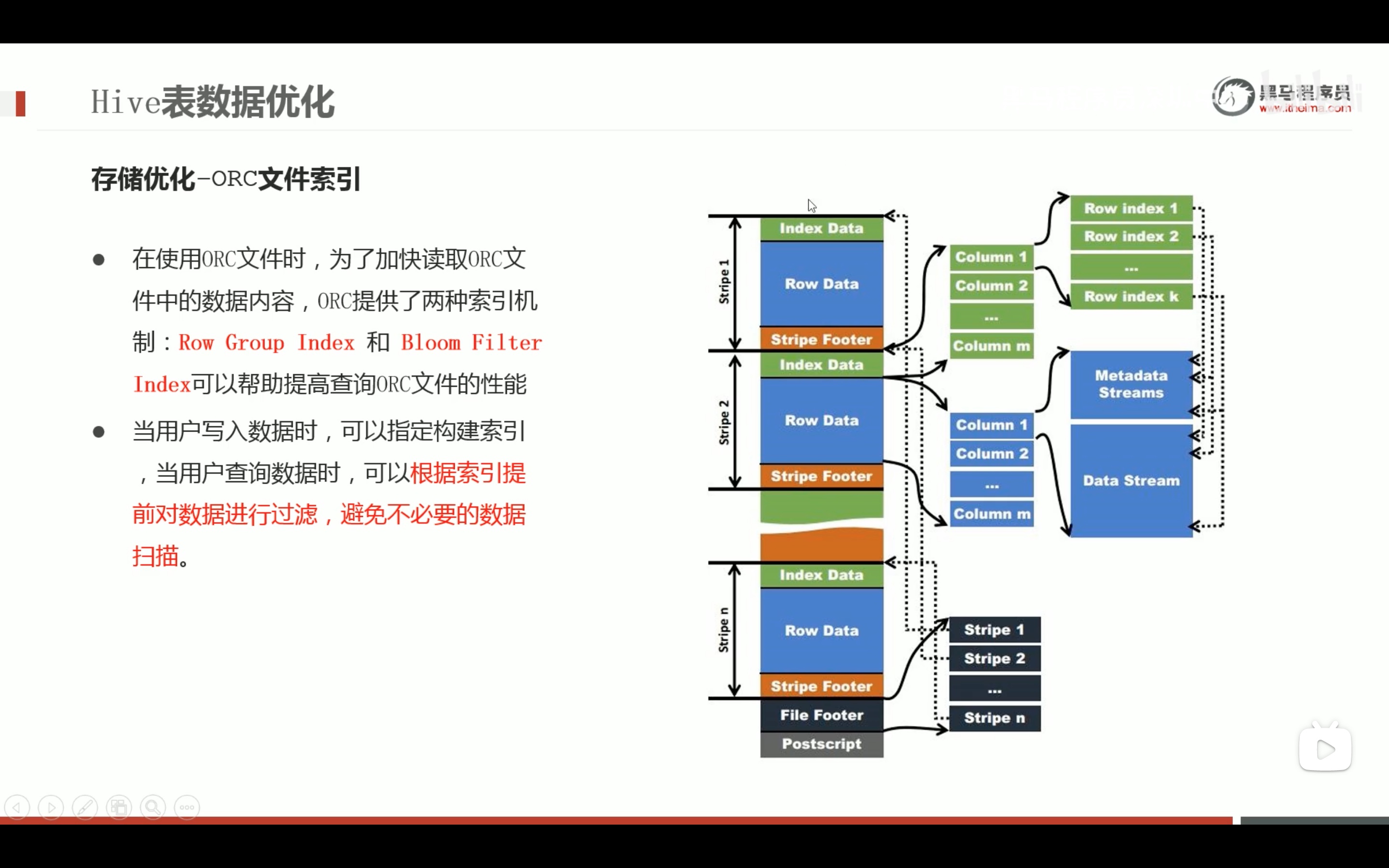
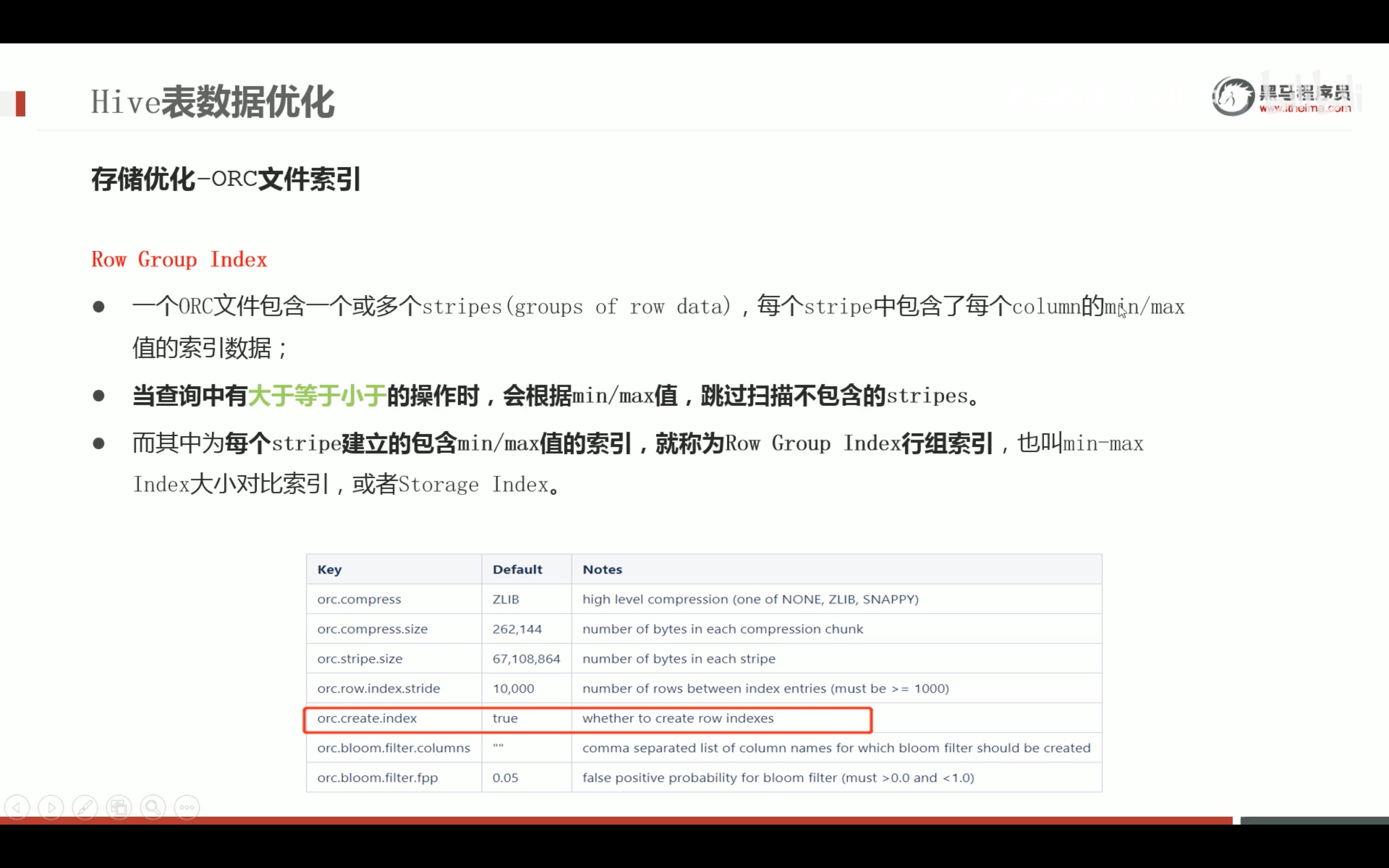
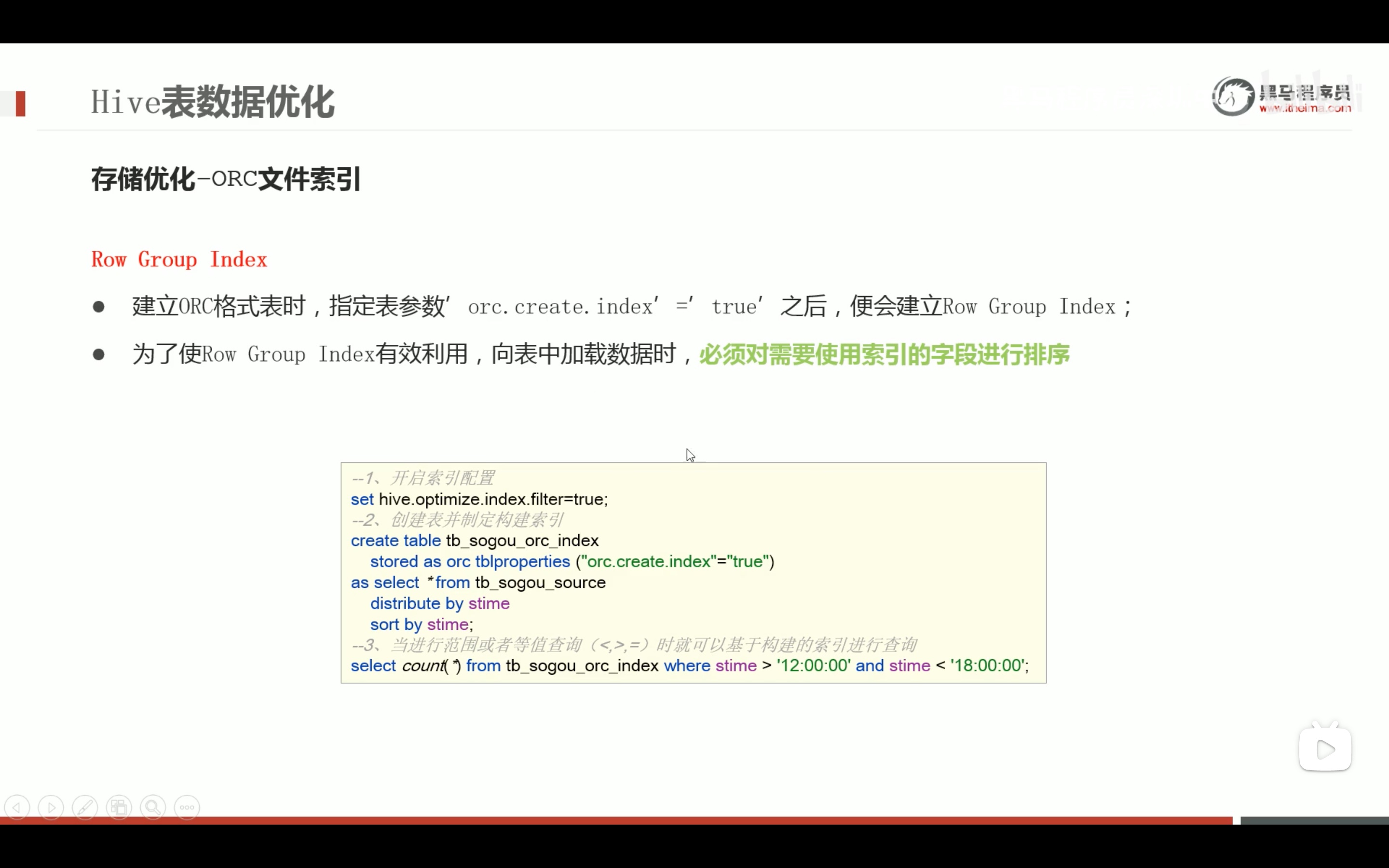

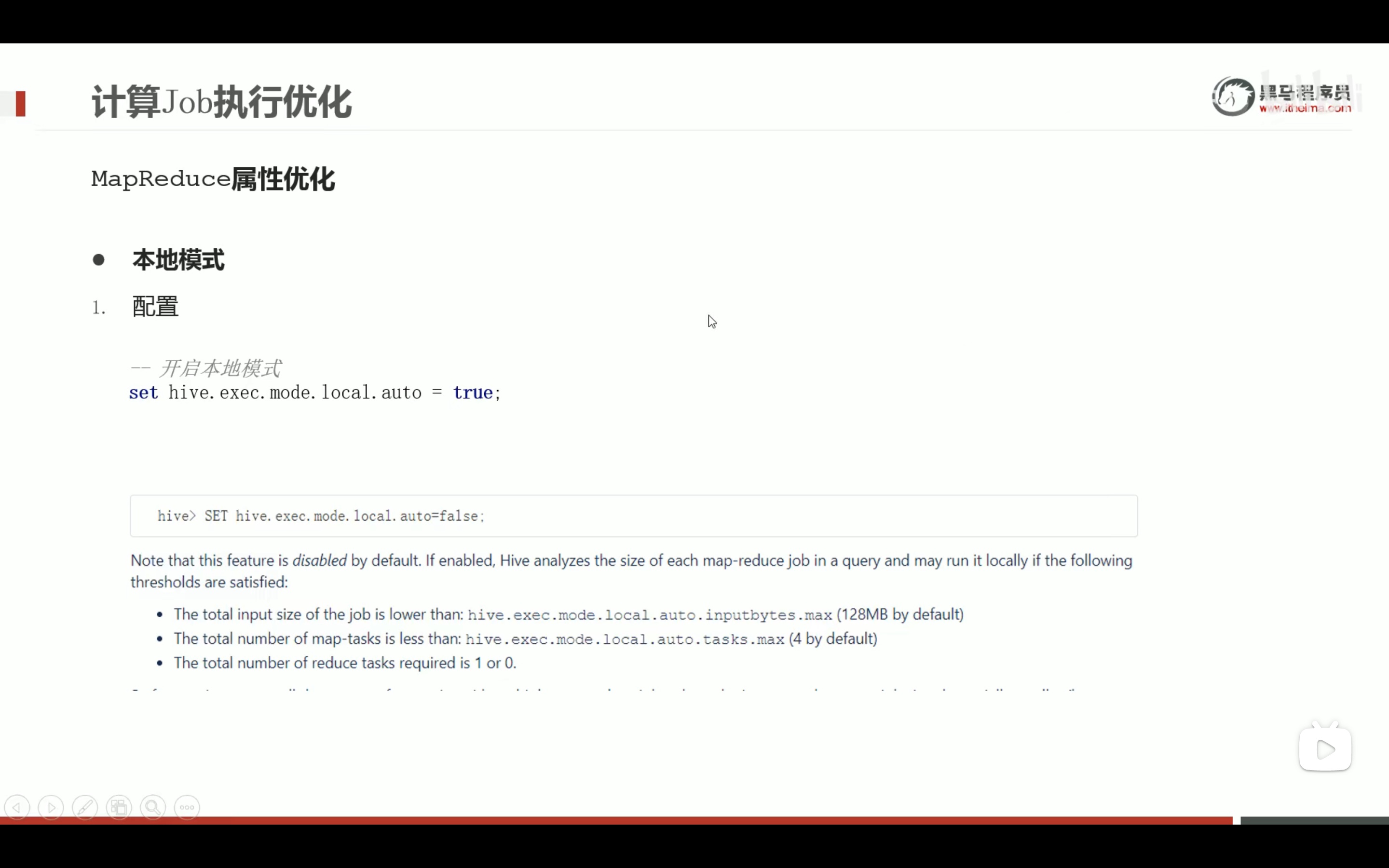
任务执行优化

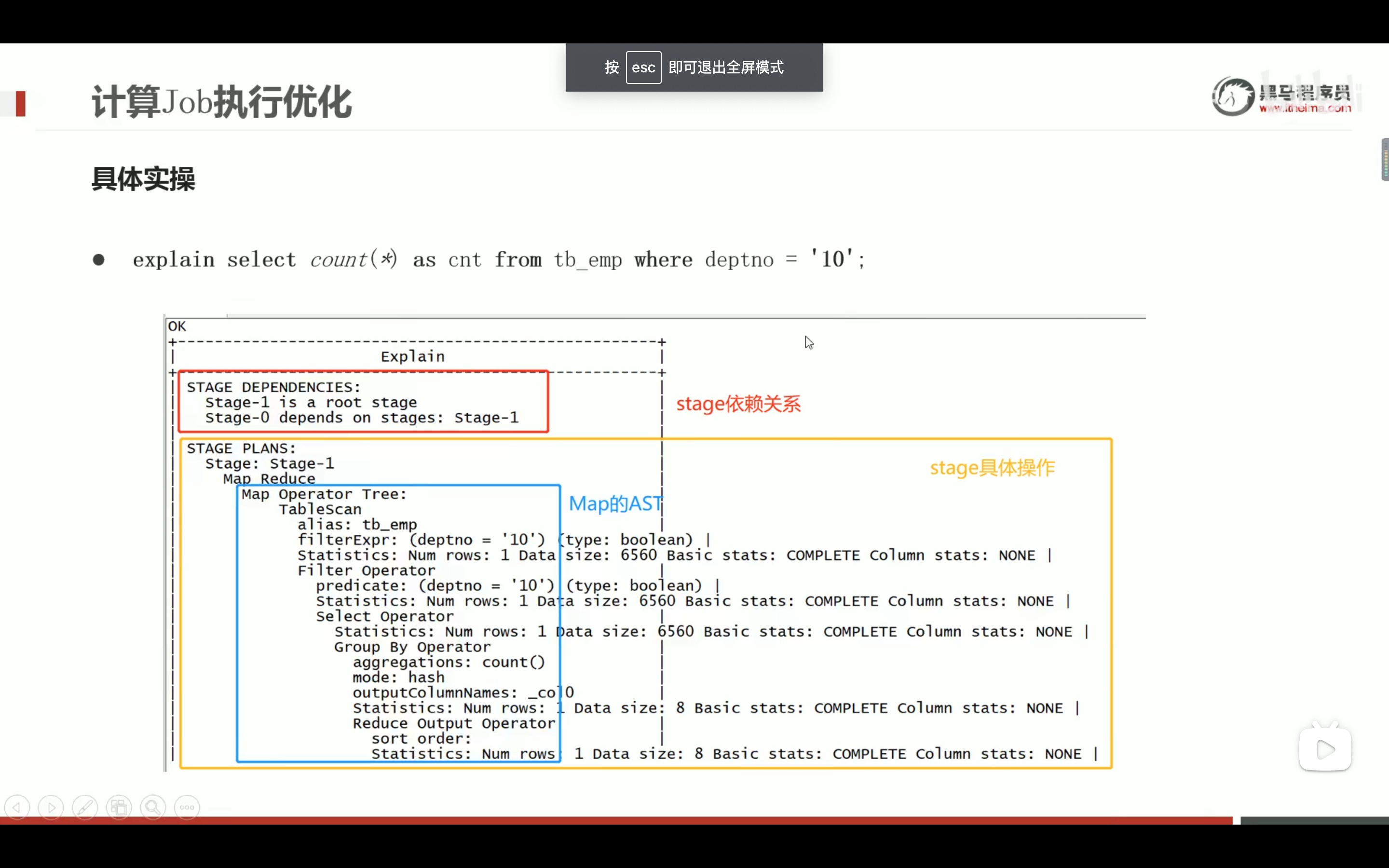

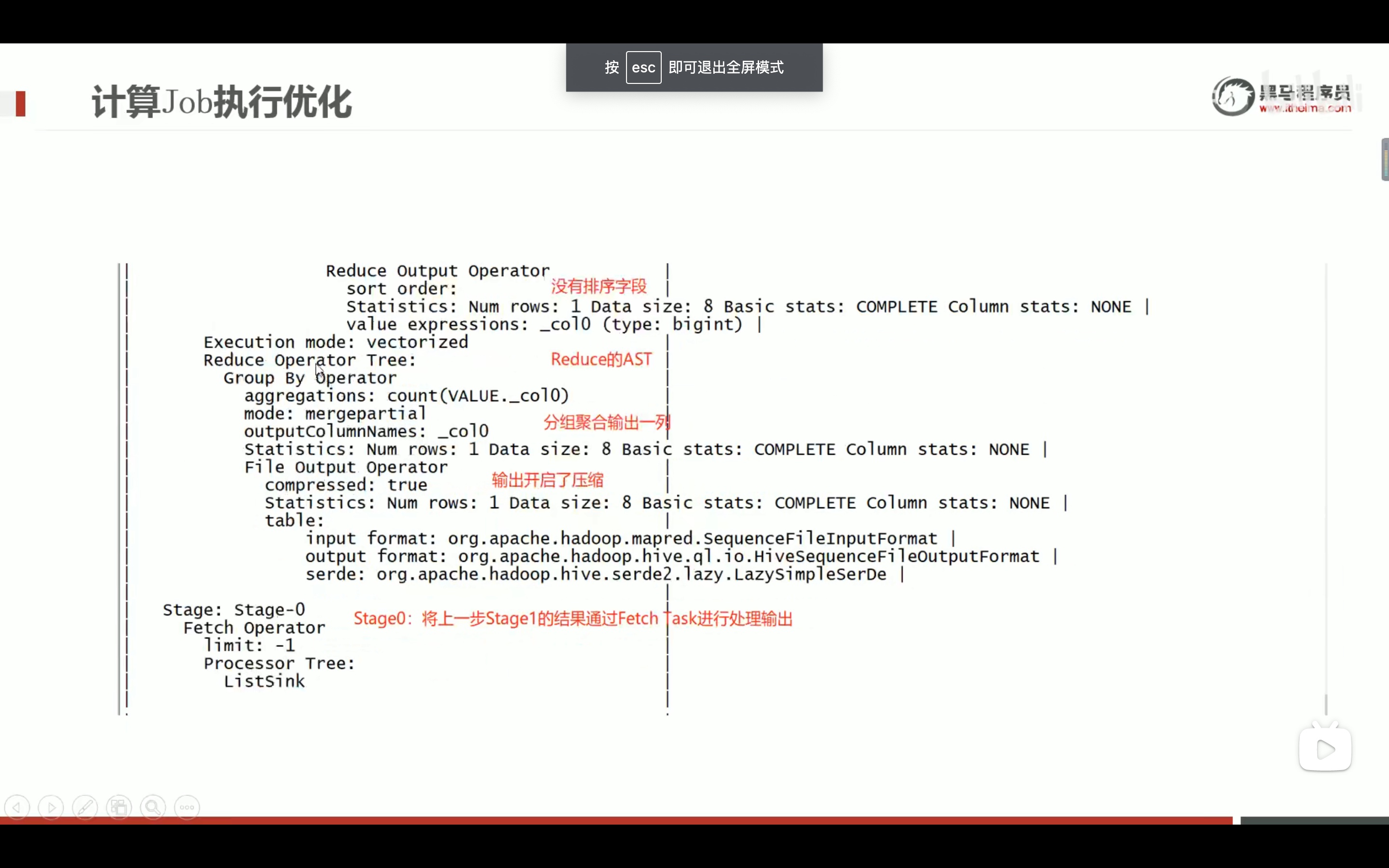


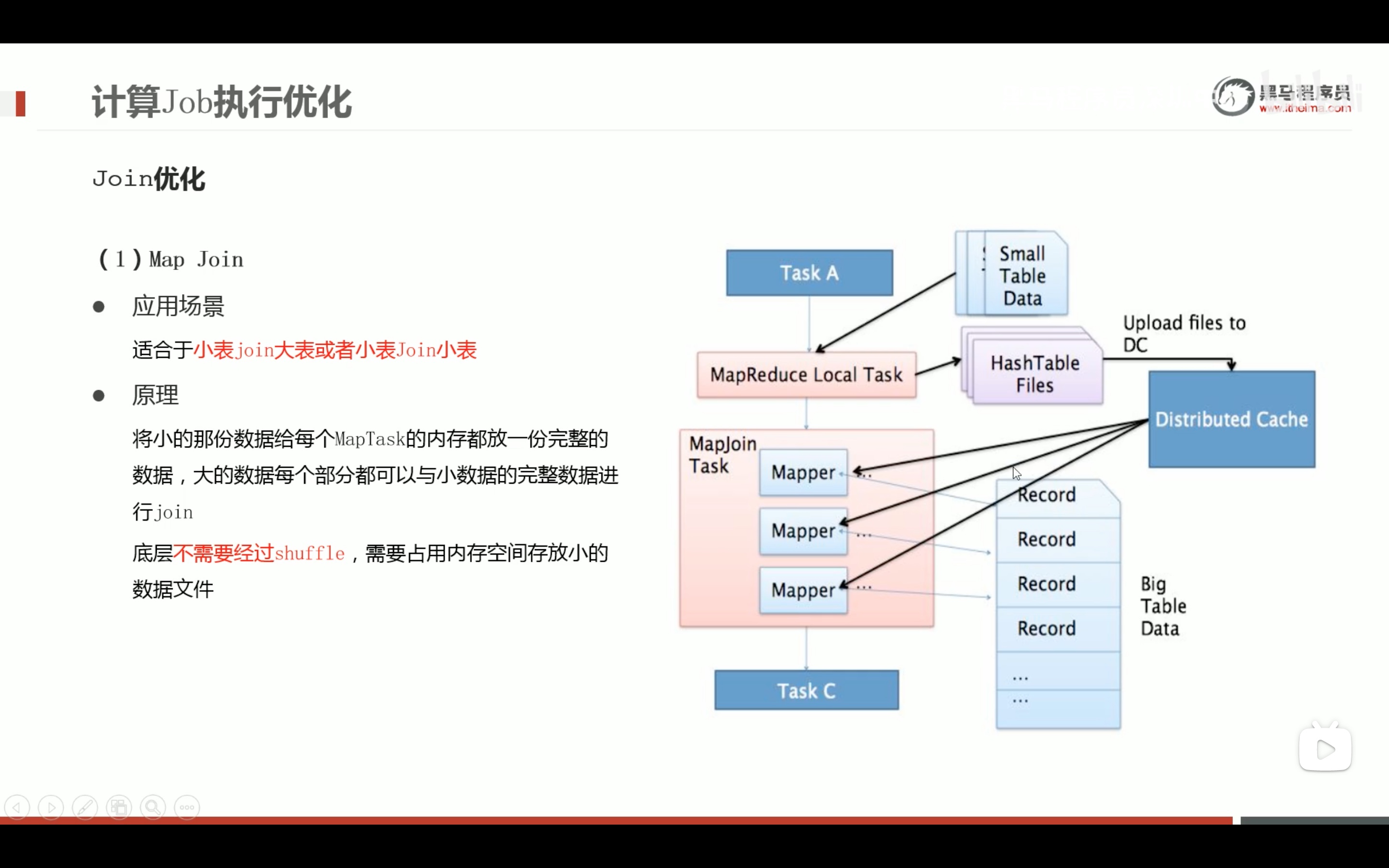
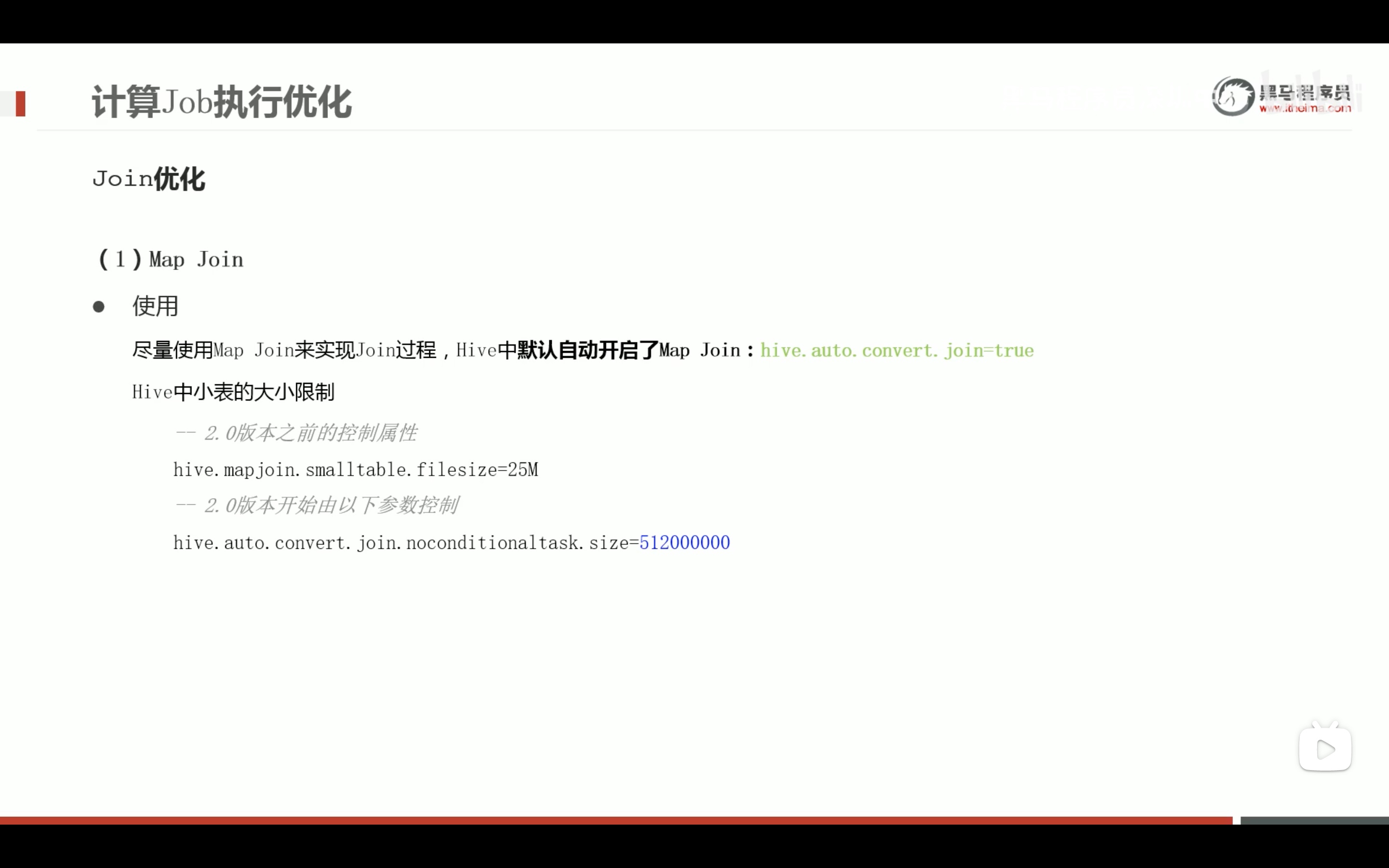
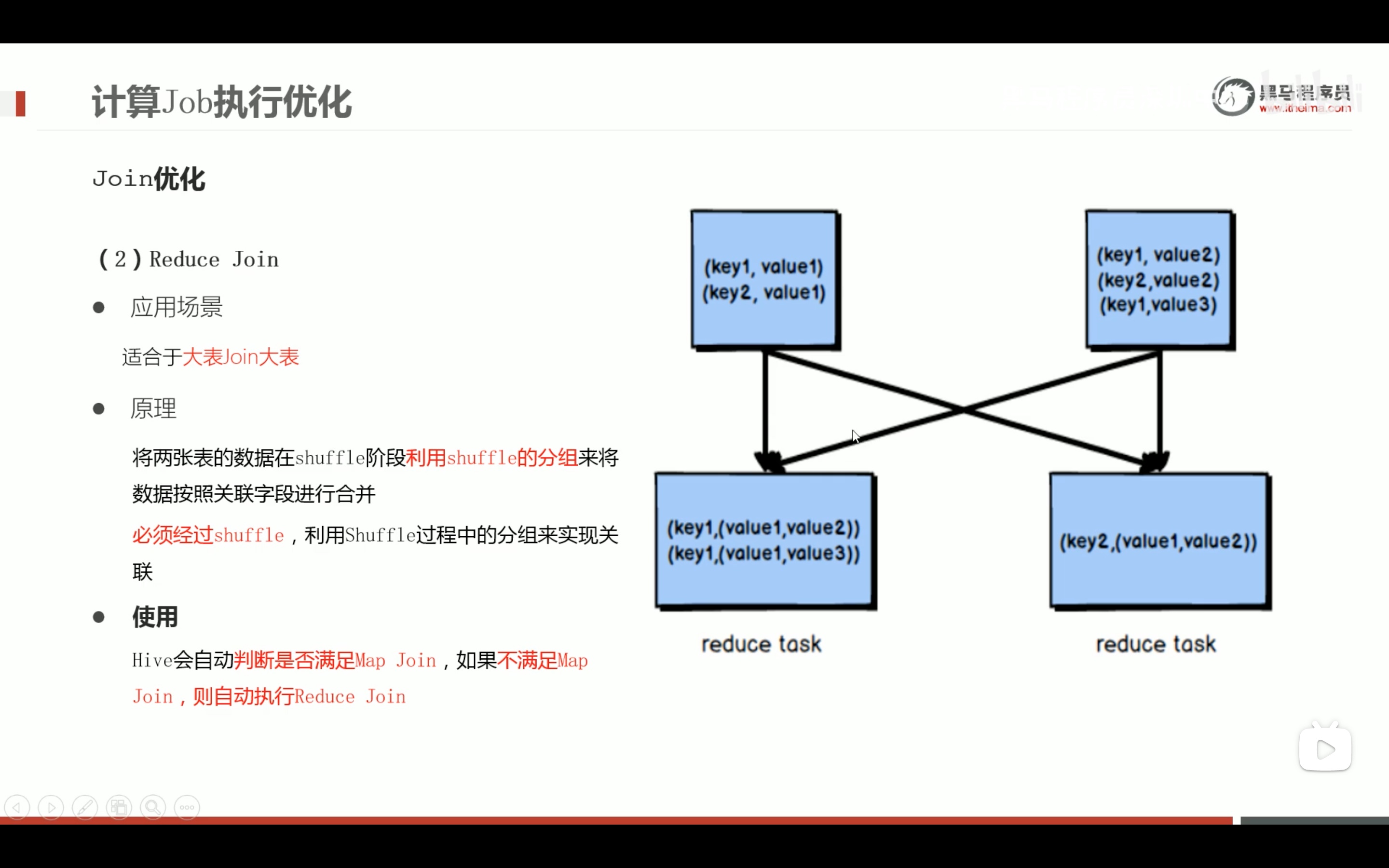
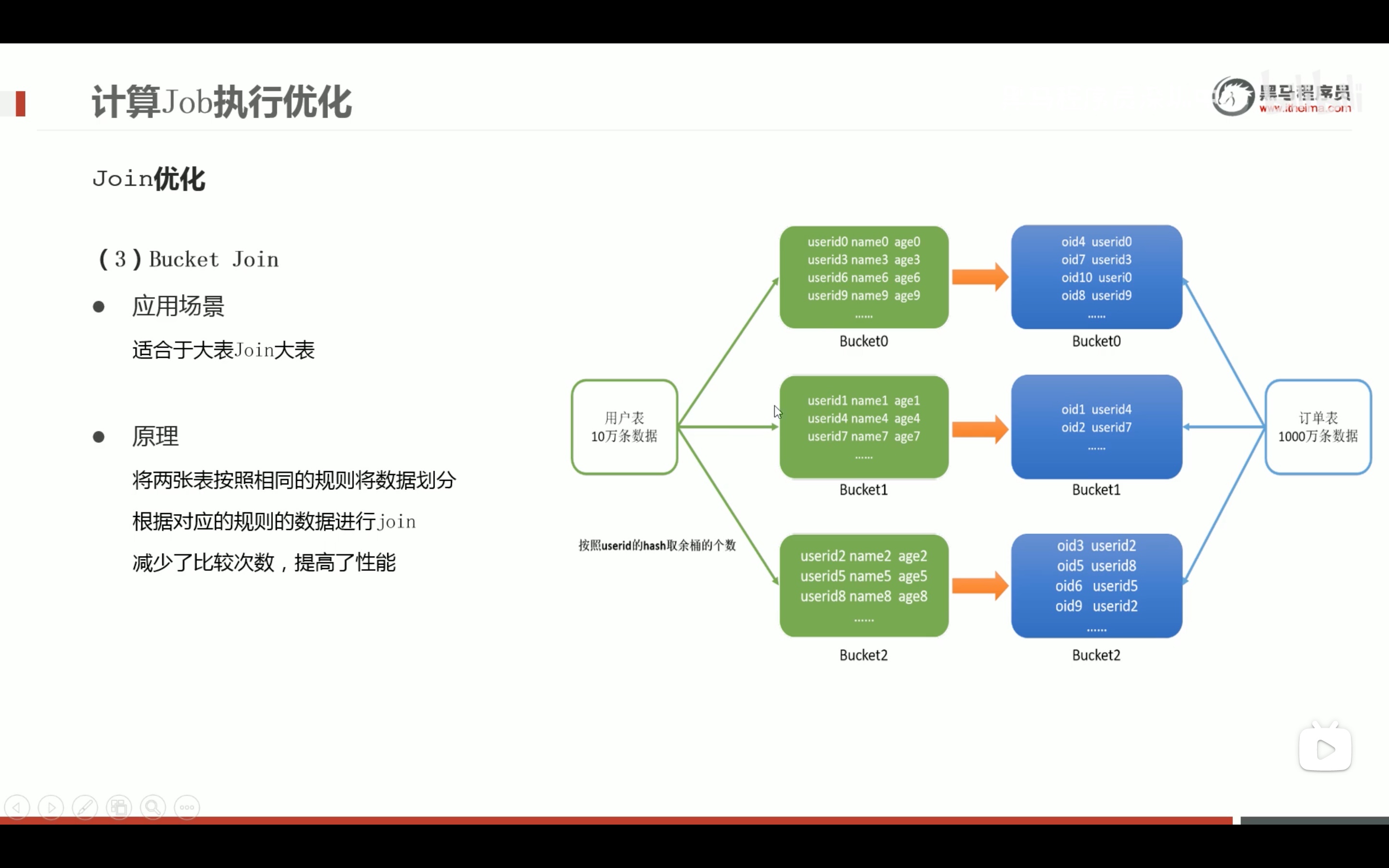
减少笛卡尔积的好方法。






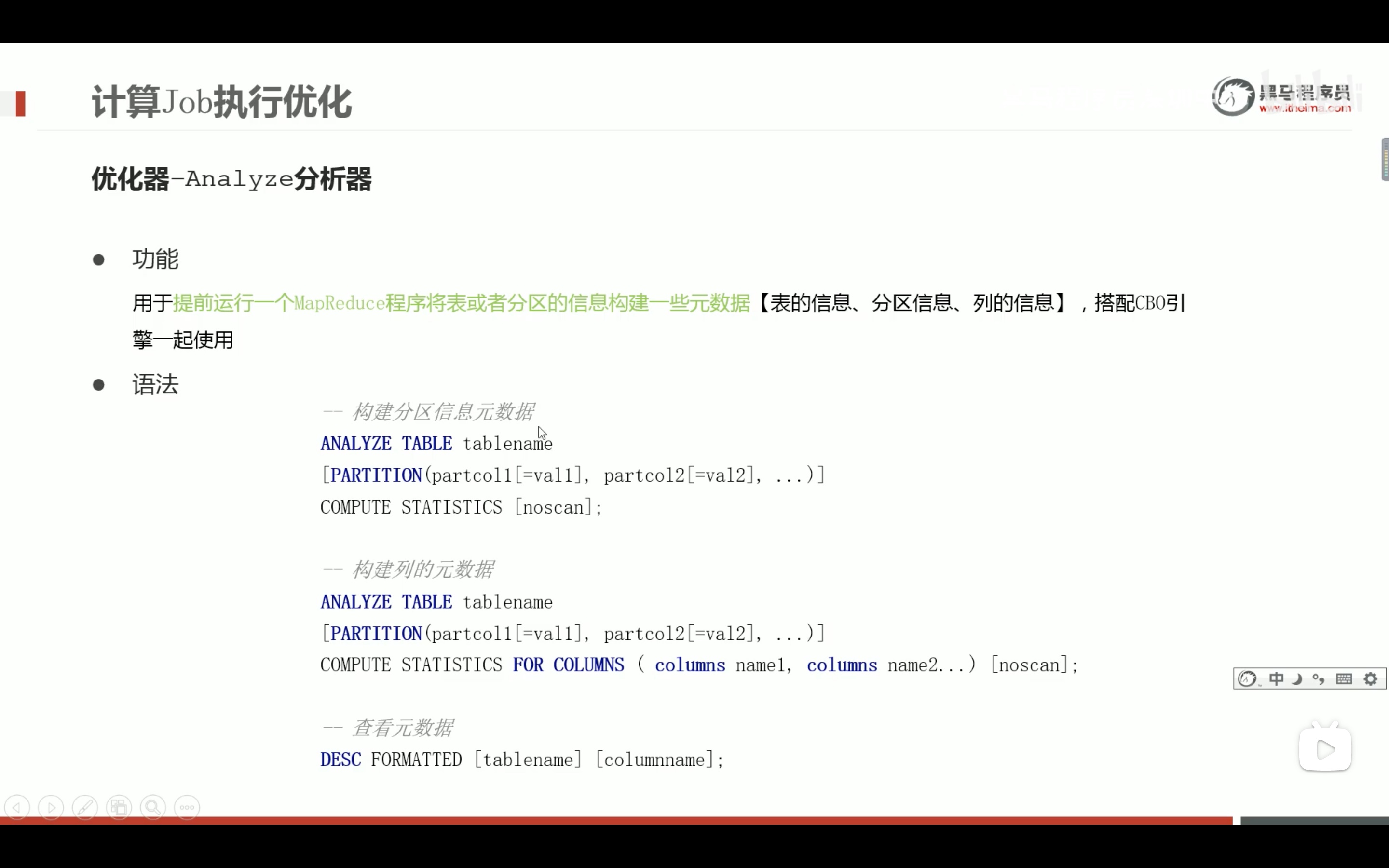
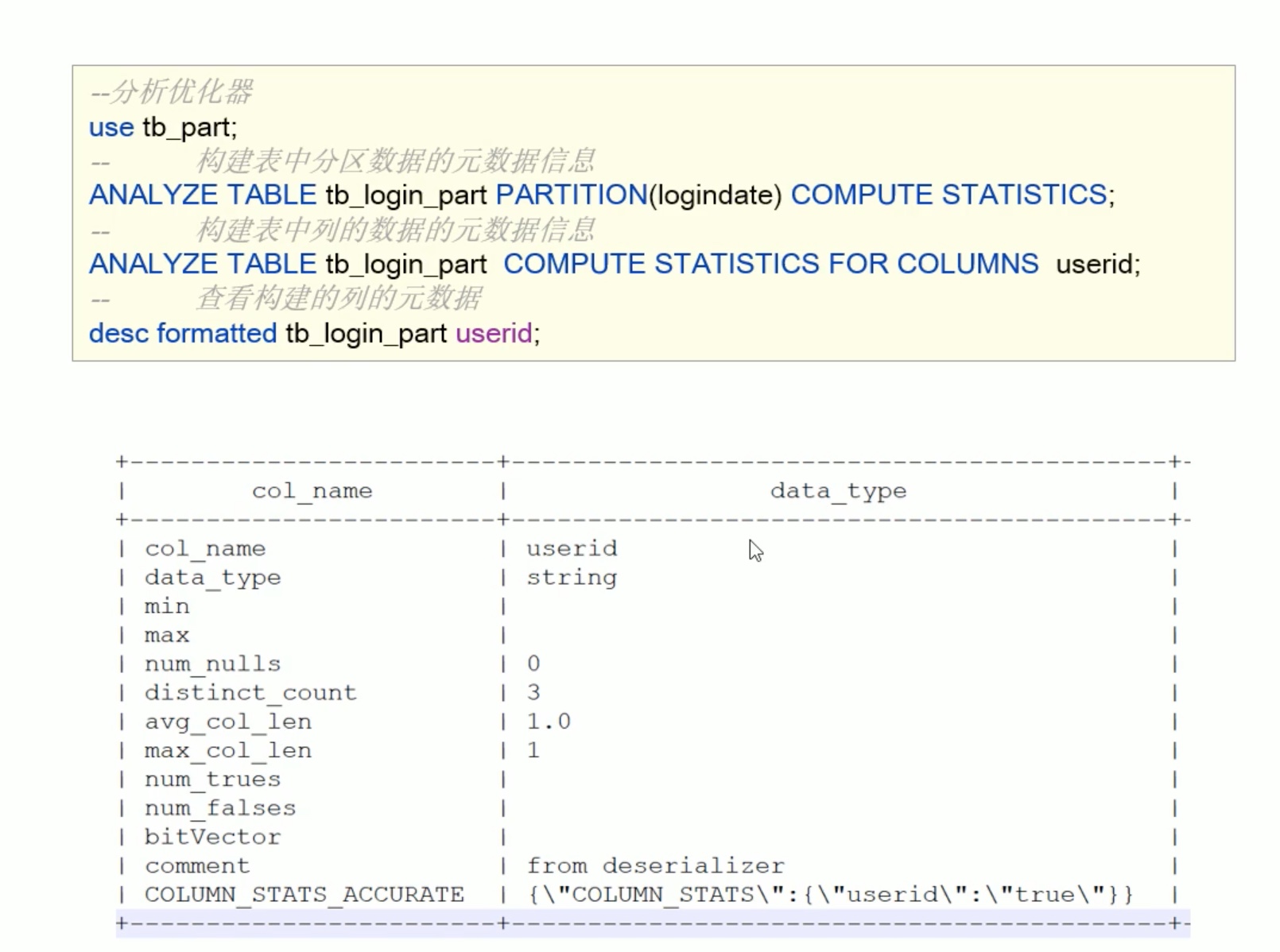

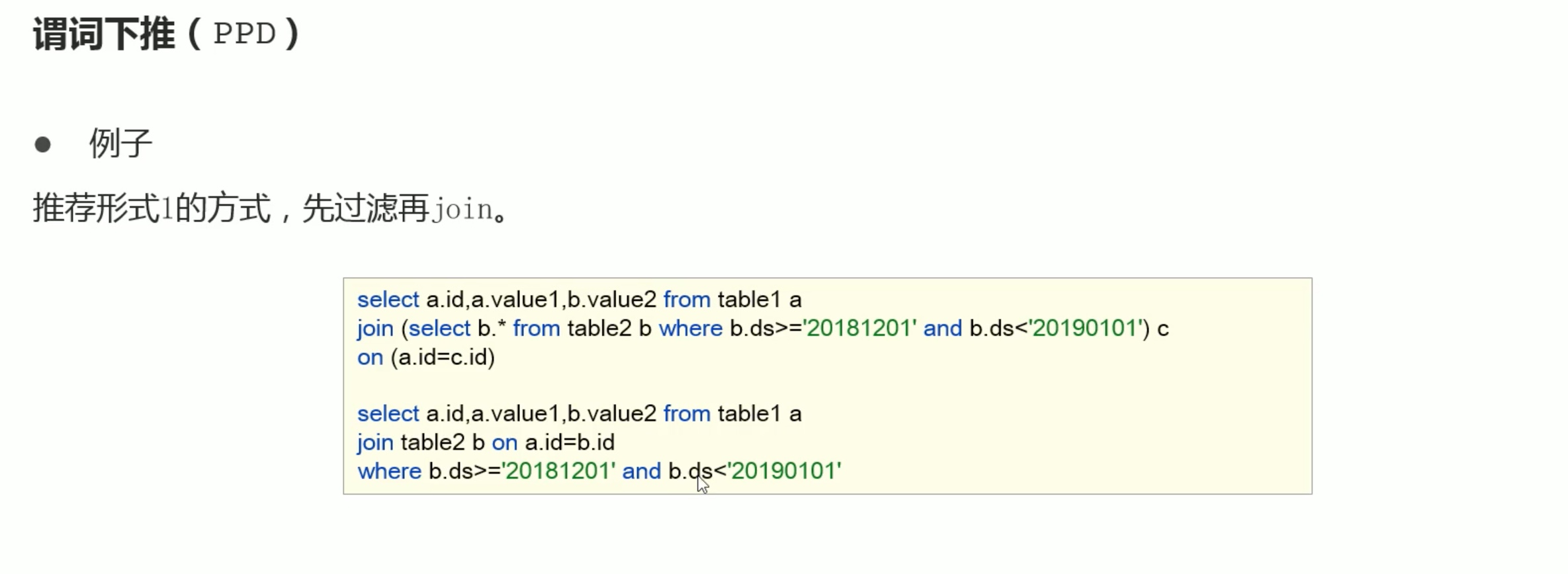
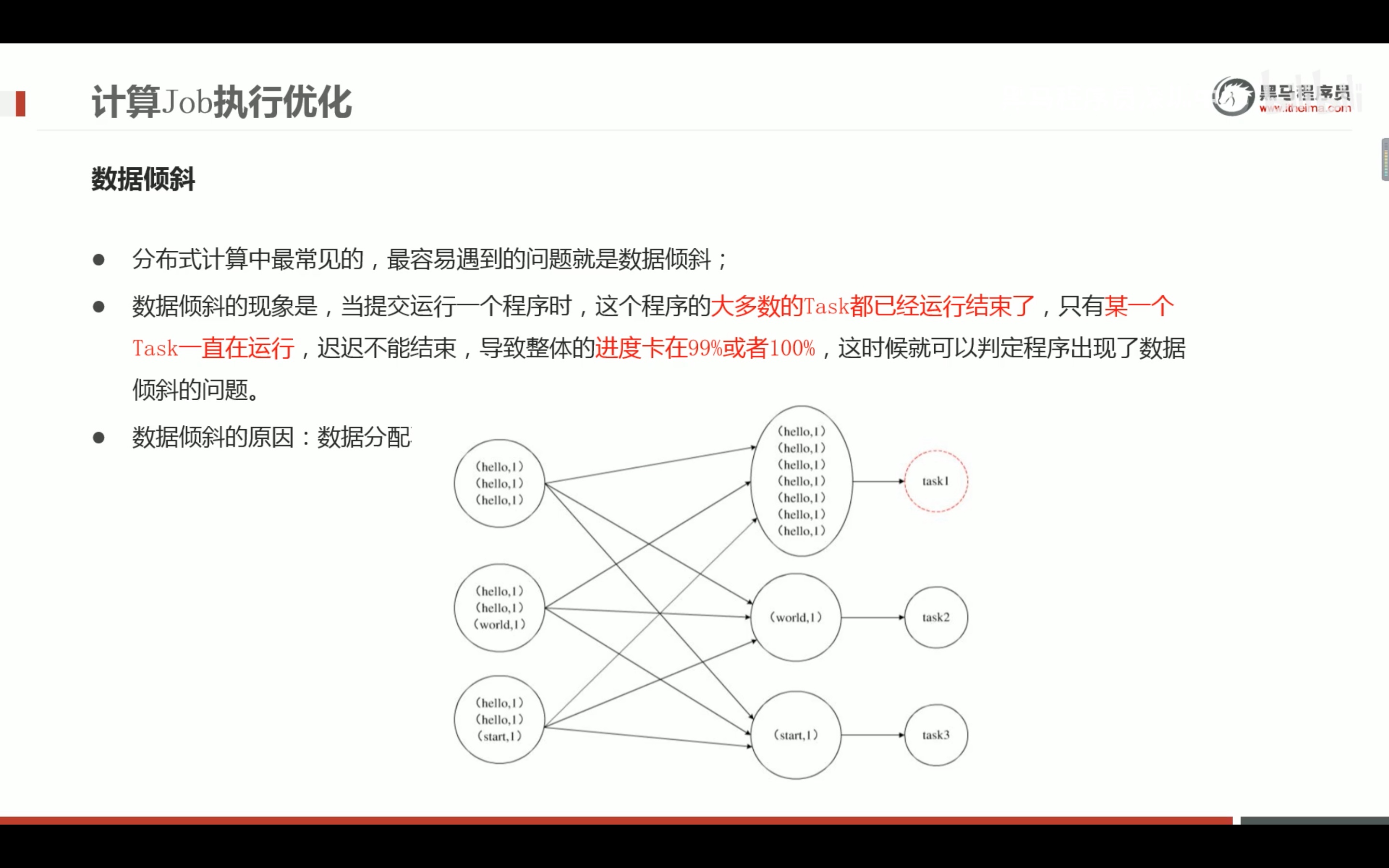
数据倾斜






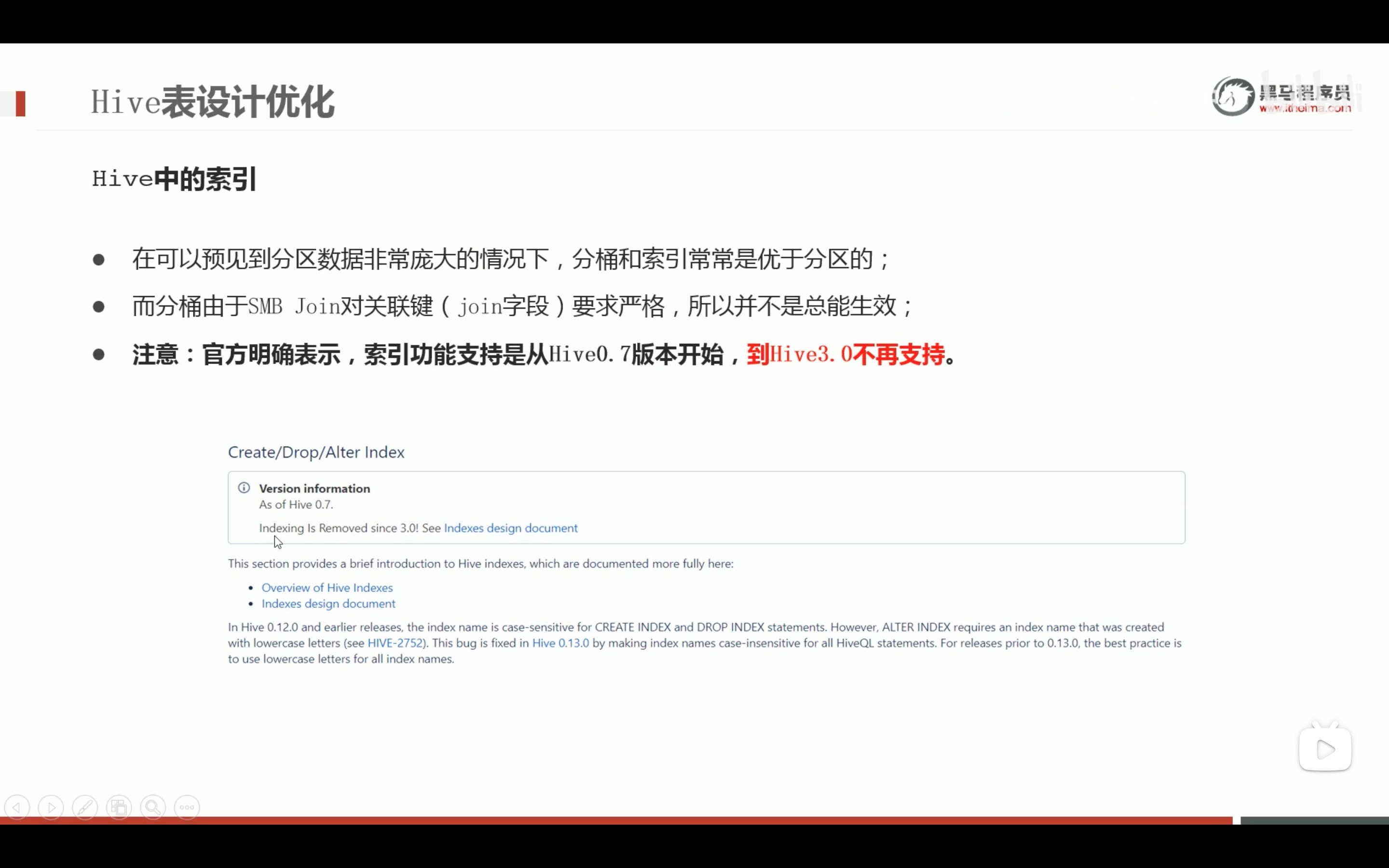
新特性
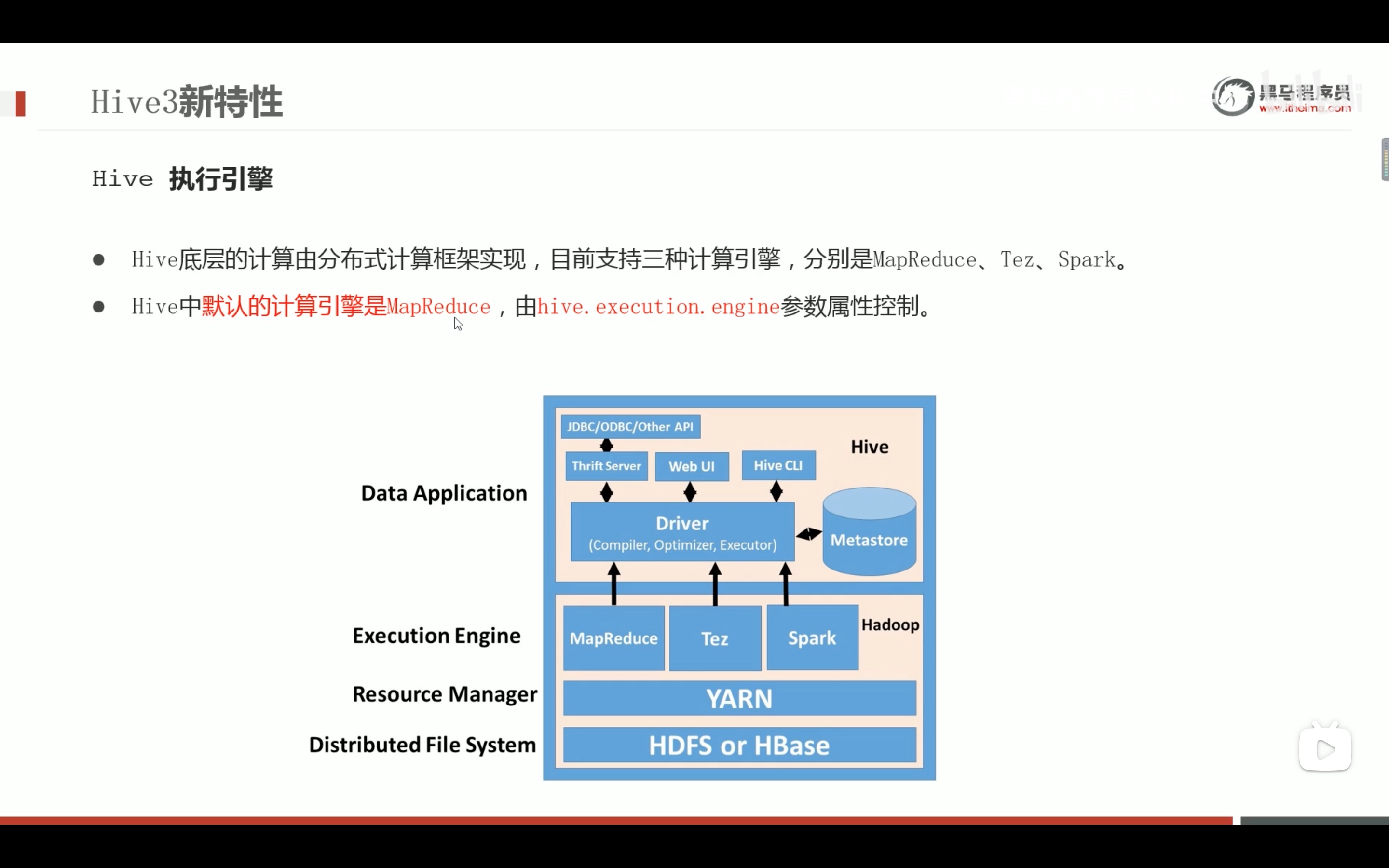
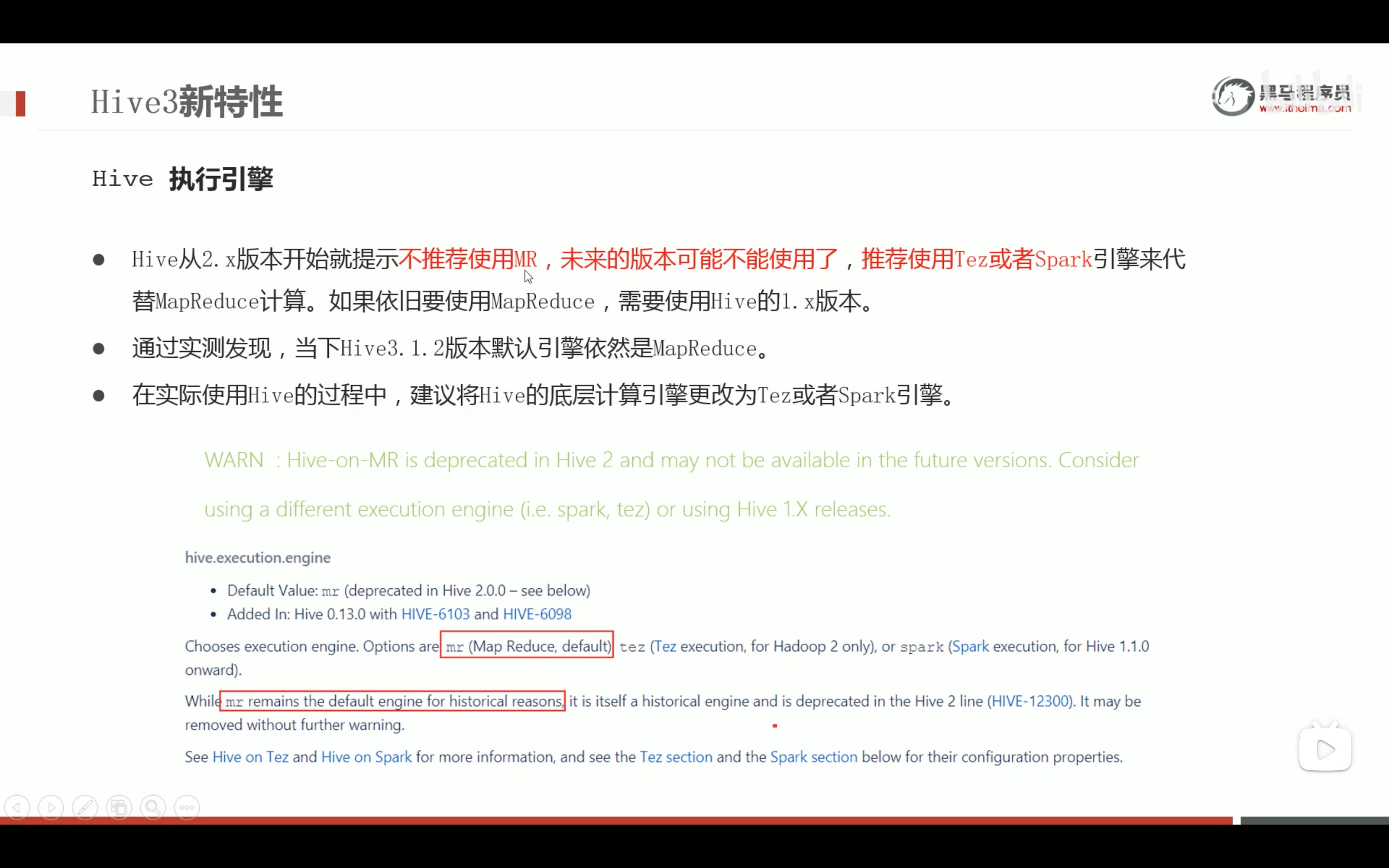
不推荐再使用mapreduce引擎,推荐用spark。
DAG有向无环图

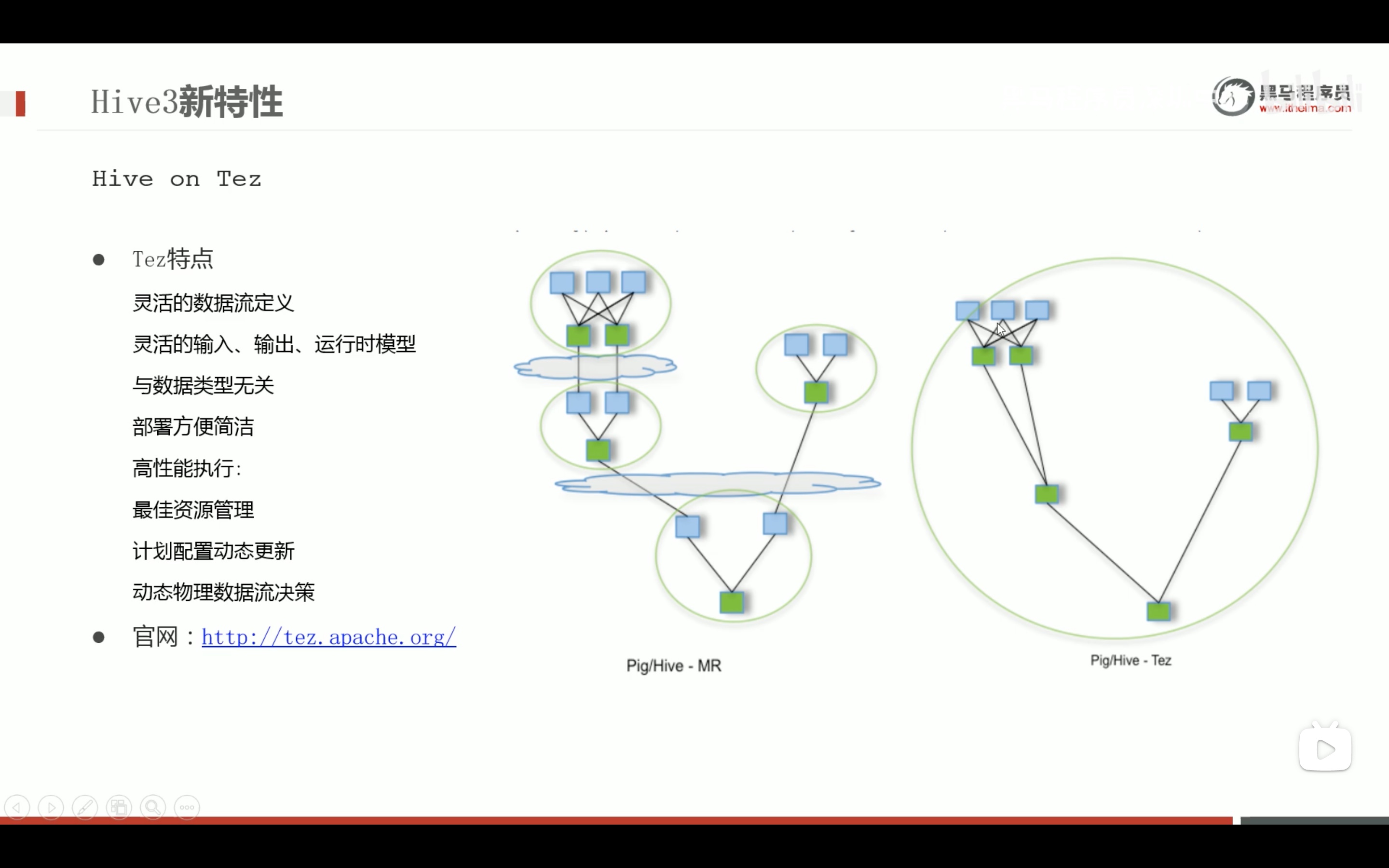
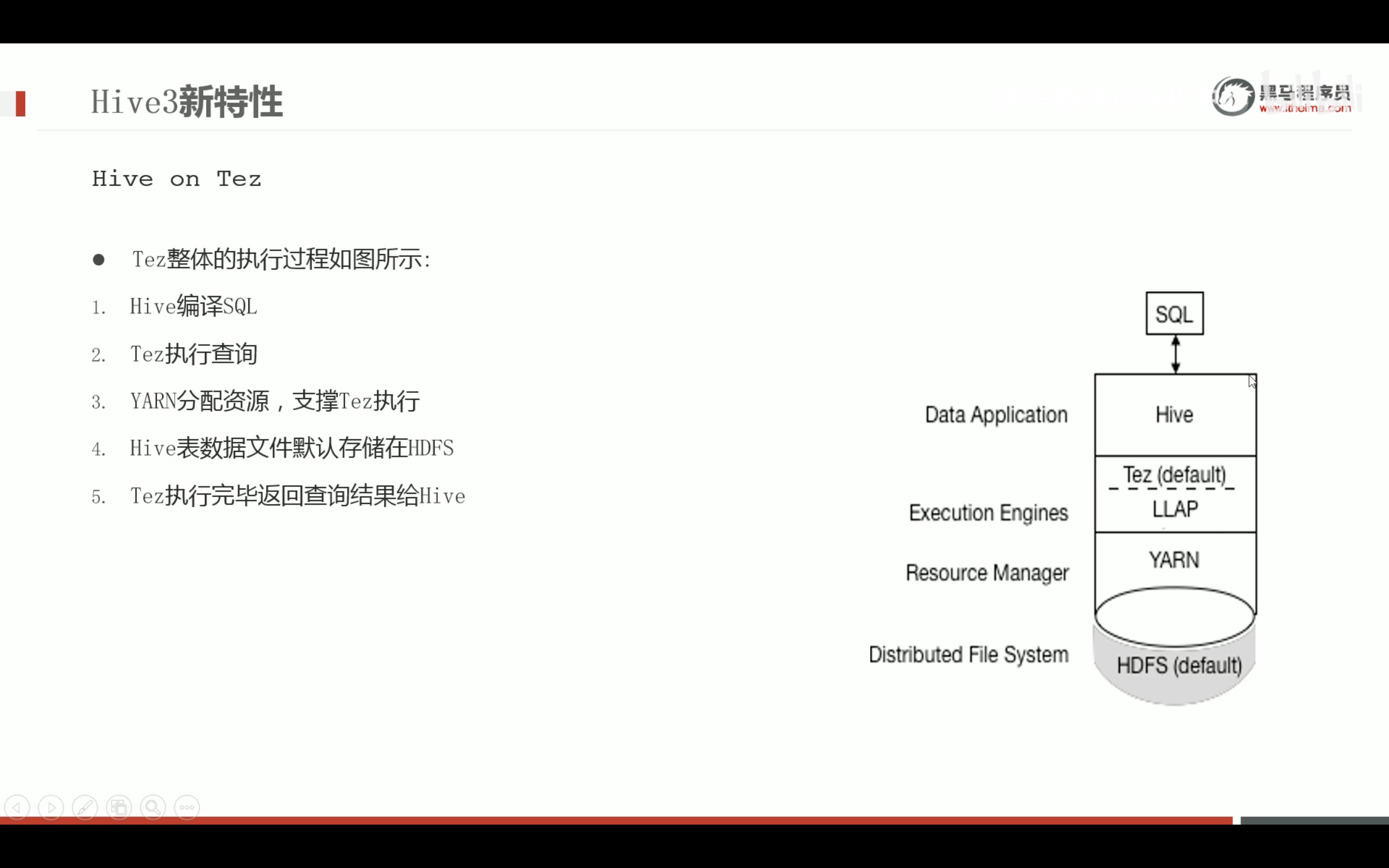
tez 引擎安装 集成到Hadoop和hive中,参考别的资料,这里就不再介绍了。

spark 好于 tez 好于 mapreduce。
独立于hive的metastore也可以安装部署,脱离hive自己运行的metastore,不做过多介绍。