kafka写入_存储_消费流程
简介
写入方式
producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障kafka吞吐率)。
kafka的 logs 直接存数据,不像别的框架的log 仅仅当日志。
为什么kafka顺序写磁盘 效率会高于 随机写内存?
kafka 高吞吐量;
kafka 顺写日志;
kafka 0复制;
kafka 分段日志 segment ;
kafka 预读read ahead ,后写write behind;
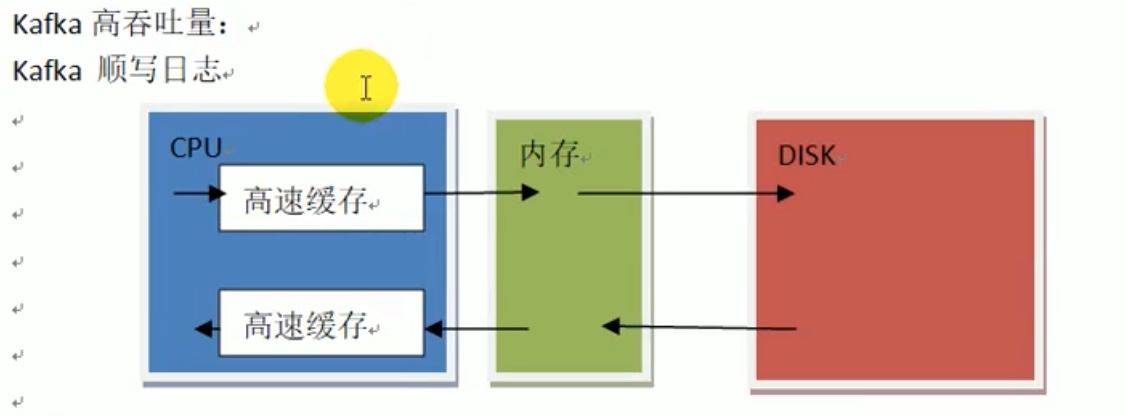
随机写内存 ,把OS 中的 A 复制一份到 B,一次数据传递 ,实际要经过 多个read buffer和 write buffer 、cache,实际要 拷贝 4次(每次进入缓冲区都要拷贝一次)。
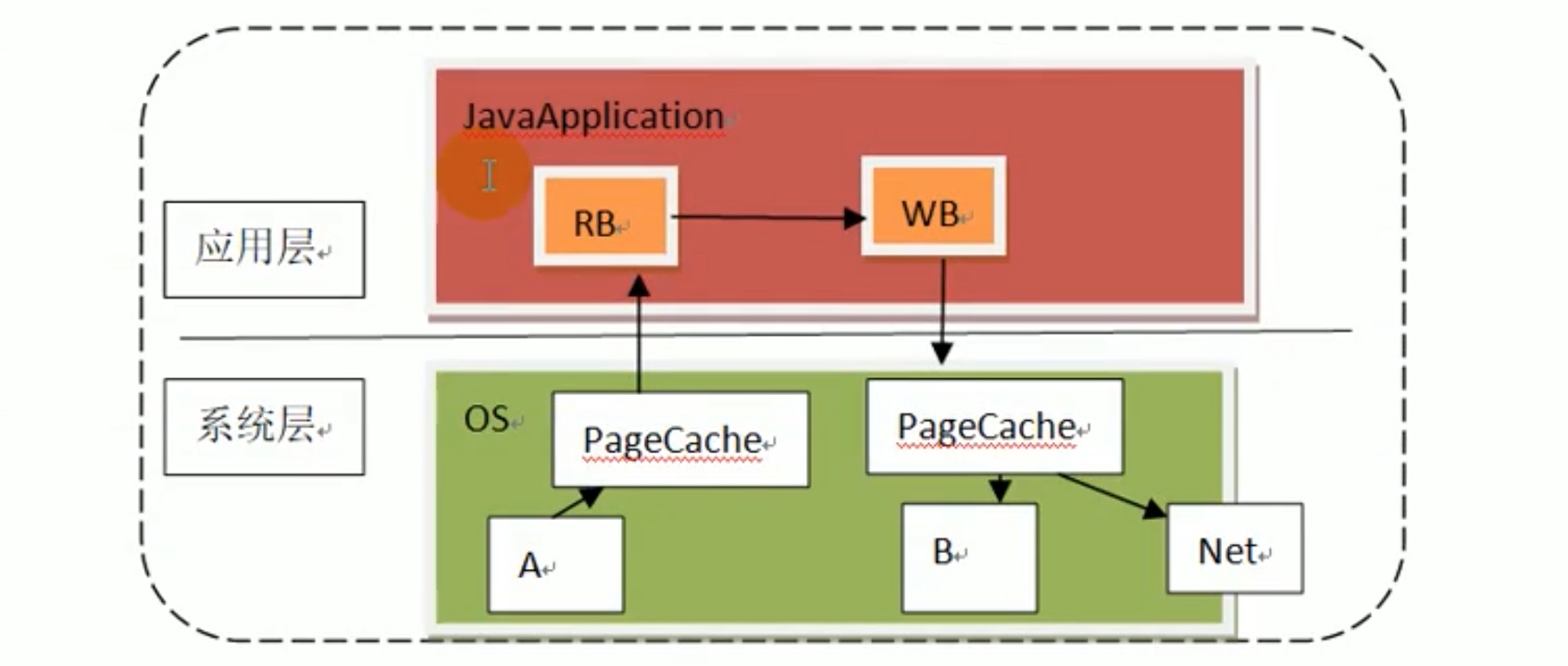
随机写内存,有10个数据,就至少要拷贝4*10=40次,如果要走网络传输net ,要 41次。
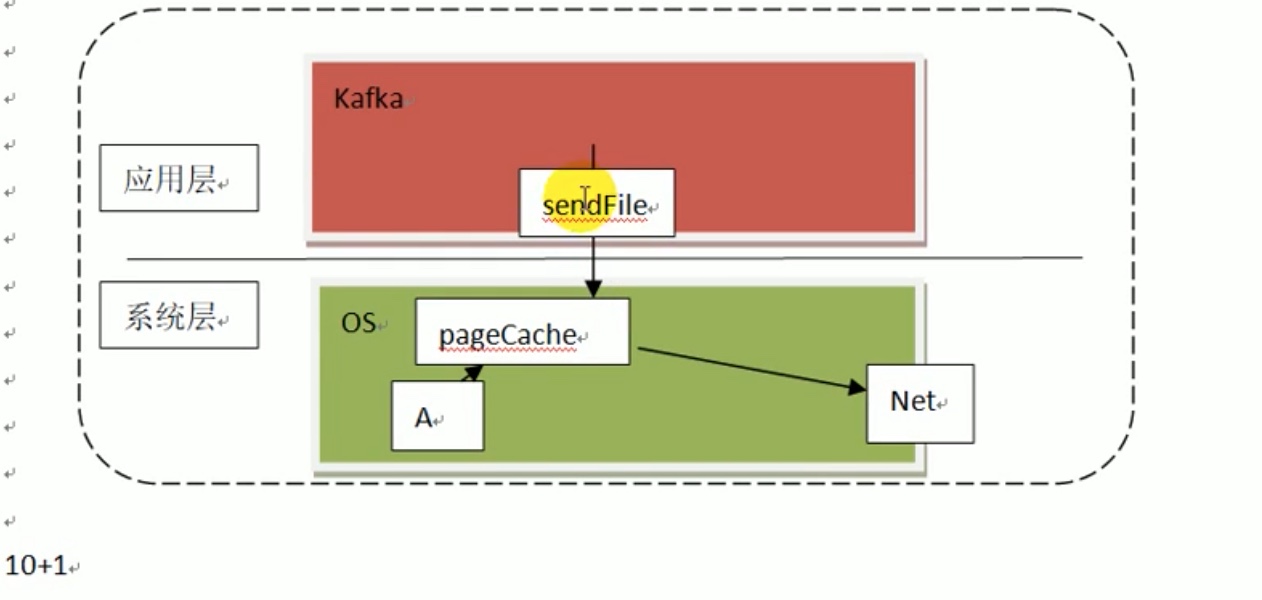
而kafka 做了改进,用一个底层指令 sendfile ,直接要操作系统 从cache中 传输数据 走了。如果是 走网络,同样10 个数据,每个拷贝一次进cache ,再一次性从cache 拷贝去 net 中传输,一共也就是 10+1=11 次拷贝。
可见 kafka 几乎实现了0拷贝。
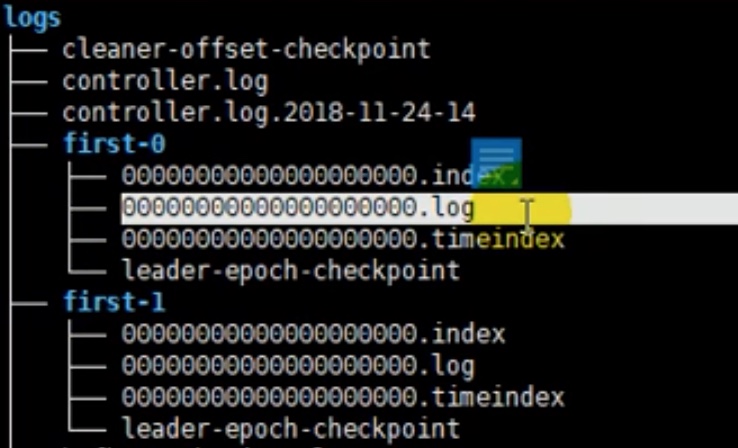
这个.log 文件是实际存放数据的。
.log 前面 这20 个0 ,实际是偏移量 offset 。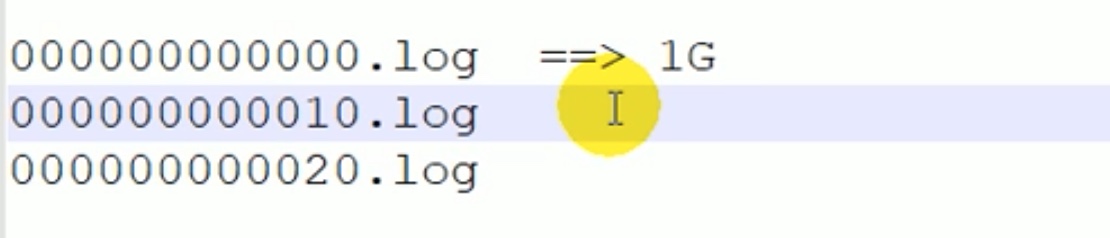
上图的意思是说,假如第一次存了10个数据,一共1g,第二次存的数据就给了一个偏移量10,标注为10.log ,以此类推,这样可以找数据更方便。
预读后写。
读的时候,把周边的可能相关的数据一起读进cache 中,方便下次用;写的时候,kafka在应用层没有写入的操作,直接引导数据写进了系统层的cache中,要写到文件file中以后再由cache写过去就行了,在同一层级内部的写操作会高效很多,kafka利用这一点大幅提升了写的效率。下图可以解释后写的意思: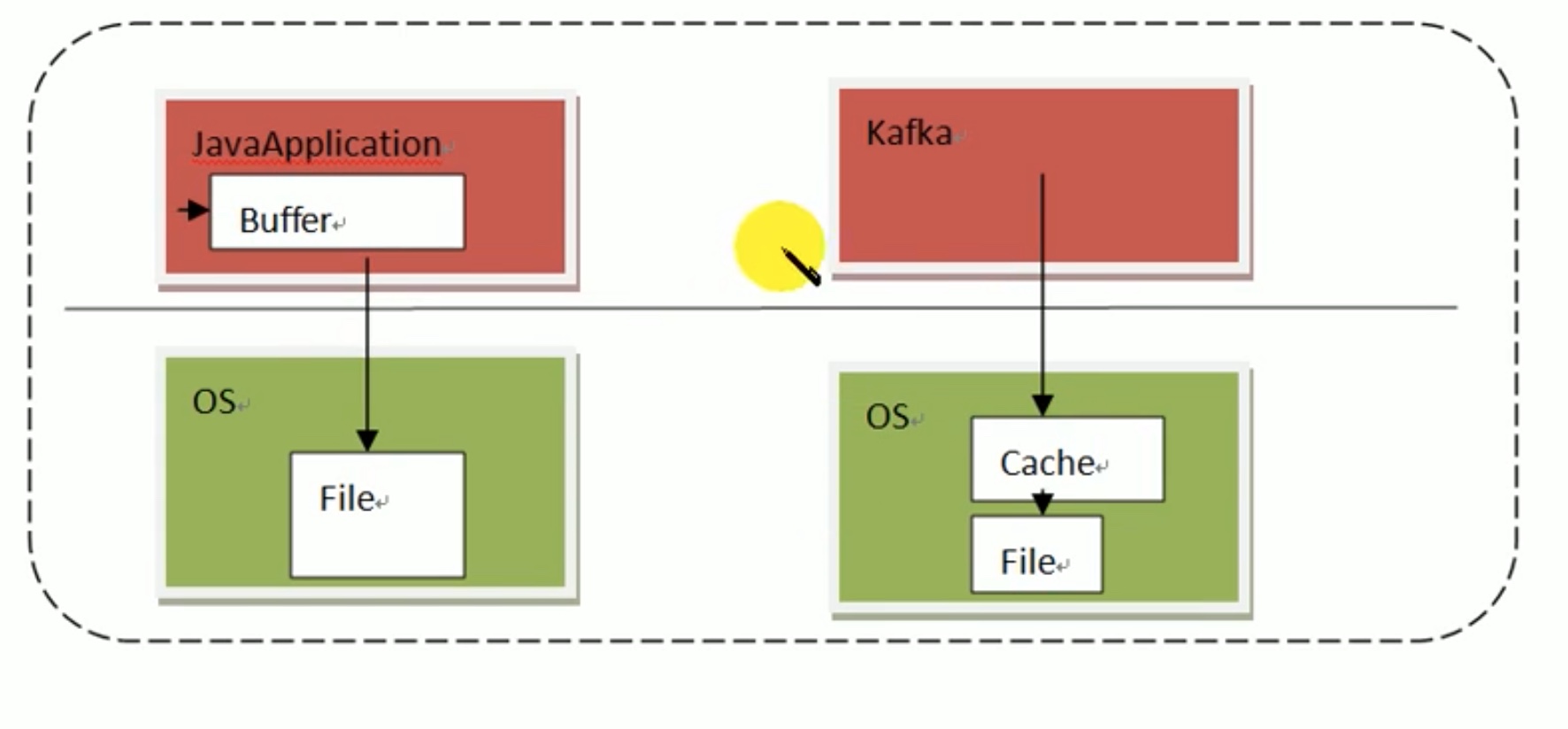
分区Partition
index用途
这里通过一个例子解释 .index 文件的用途。
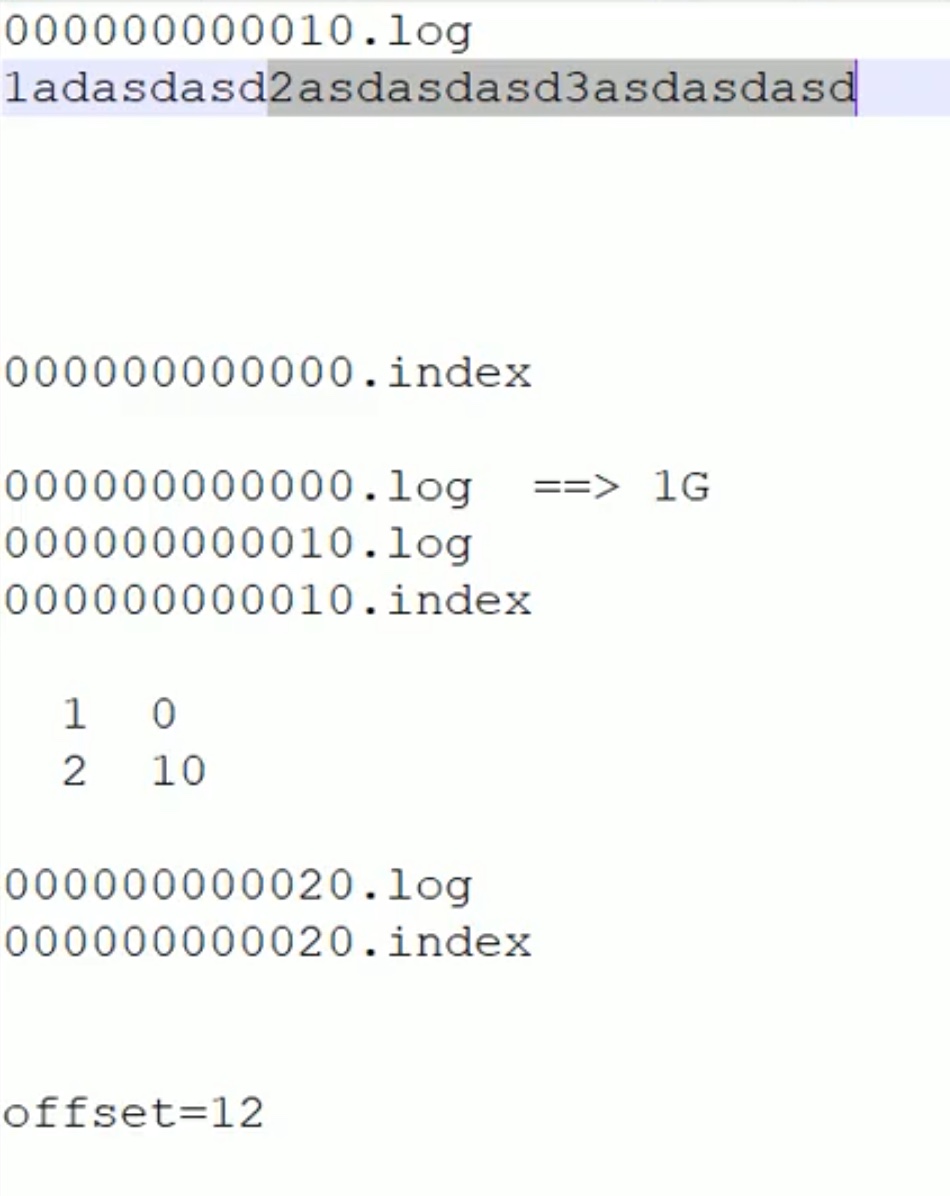
寻找目标数据,当目标数据偏移量offset = 12 时,可以初步定位到数据应该是在 10.log 这个文件中,并且对应的位置是 10.log 文件的 12-10=2 号数据;
但是如何定位 10.log文件 的2号数据在哪个位置呢?就要用到 10.index 索引文件。
上述索引文件中 1对应 index=0 位置,2对应 index=10 位置。
因此 offset=12 我们很快就从一大堆的log 文件中找出了对应的目标数据。
补充一点: offset 偏移量时按照consumer group消费者组来定的,不是根据某一个消费者,假如消费者a和消费者b在一个组内,某一个分区a读一半停了b来读,会继续从a停止的位置继续读。
分区
消息发送时都被发送到一个topic,其本质就是一个目录,而topic是由一些Partition Logs(分区日志)组成,其组织结构如下图所示:
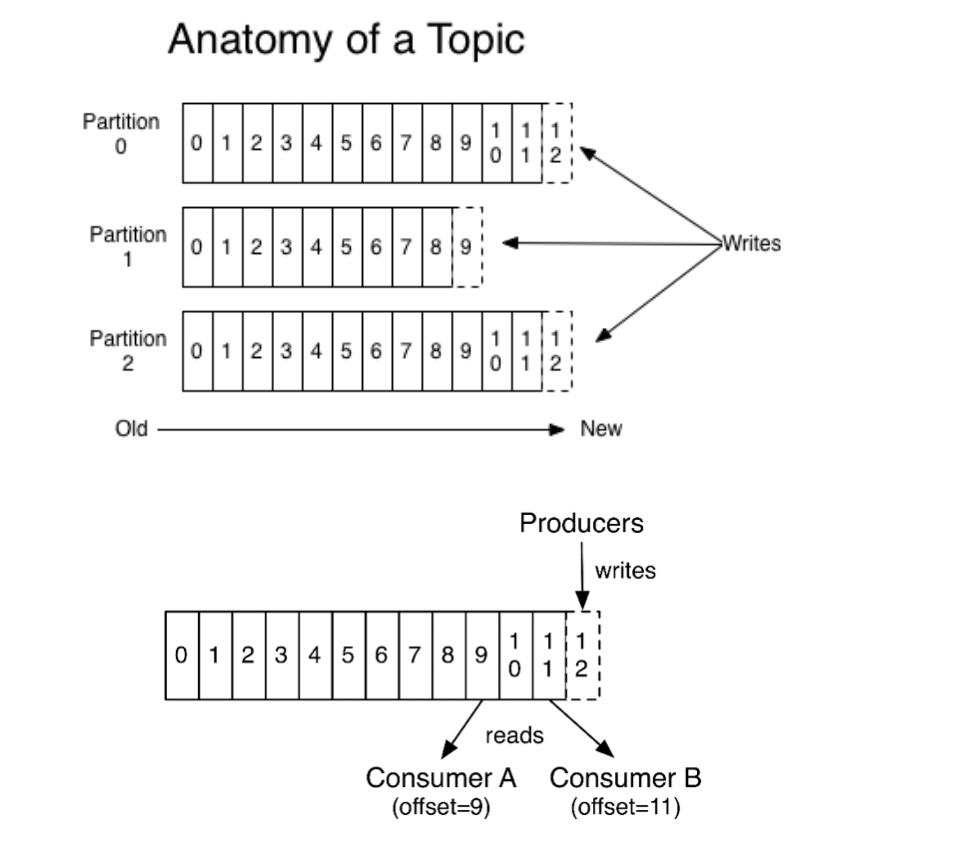
每个Partition中的消息都是有序的,生产的消息被不断追加到Partition log上,其中的每一个消息都被赋予了一个唯一的offset值。
1)分区的原因
(1)方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了,数据大了直接加分区,嘿嘿;
(2)可以提高并发,因为可以以Partition为单位读写了。
2)分区的原则
(1)指定了patition,则直接使用;
(2)未指定patition但指定key,通过对key的value进行hash出一个patition;
(3)patition和key都未指定,使用轮询选出一个patition。
1 | DefaultPartitioner类 |
在idea 中不断的往上 找方法的源代码,会发现,这个hash 底层也是 按位求与运算。类似如下:
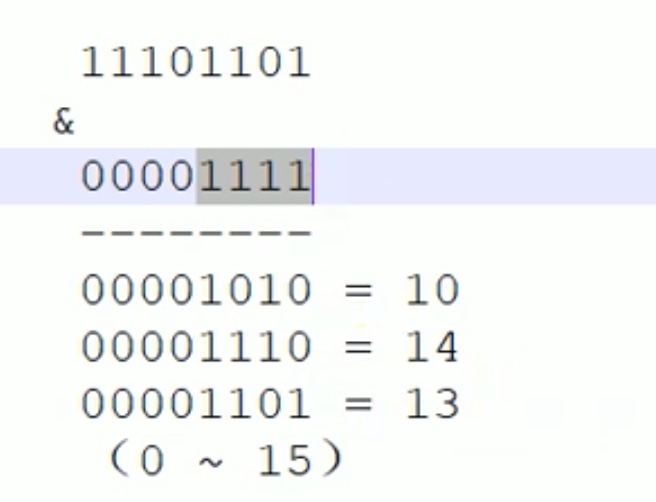
放松一下:java中
1 | int i = 0; |
副本(Replication)
同一个partition可能会有多个replication(对应 server.properties 配置中的 default.replication.factor=N)。没有replication的情况下,一旦broker 宕机,其上所有 patition 的数据都不可被消费,同时producer也不能再将数据存于其上的patition。引入replication之后,同一个partition可能会有多个replication,而这时需要在这些replication之间选出一个leader,producer和consumer只与这个leader交互,其它replication作为follower从leader 中复制数据。
zookeeper 和 producer 没有关系。zookeeper只管理集群和consumer偏移量数据。都是集群中哪个partition副本是leader,这样的信息存储在zookeeper中。
——————————————————————————————————-
补充: 设置topic时,partition数目 可以大于 broker的数目,但是replication factor 设置一定不能 大于 broker的 数目;
例如: kafka集群 3台机器 broker =3;一旦设置partition=2,replication factor =4 ,某一台机器中会同时出现 partition0 分区的leader副本和follower副本,一旦此机器宕机,极有可能数据全部丢失!!!
所以 ,不允许把 replication factor 设置的超过 broker的数目。
生成数据时应答机制ACK
ack=0: 生产者发送完数据,不关心数据是否到达kafka集群,然后直接发送下一条数据,效率高、易丢失;
ack=1: 生产者发送数据,需要等待leader副本的应答,leader副本把数据在log存放好了完成应答,生产者才发送下一条数据(不关心follower是否从leader中把数据备份成功,存在leader刚刚接收完数据就宕机,follower没来得及备份生产者又停止发送,导致数据丢失的可能);
ack=-1: (all 模式)生产者发送数据,需要等待leader和follower都接收完成做出应答,才发送下一条数据,这样最安全,但是效率低一些;
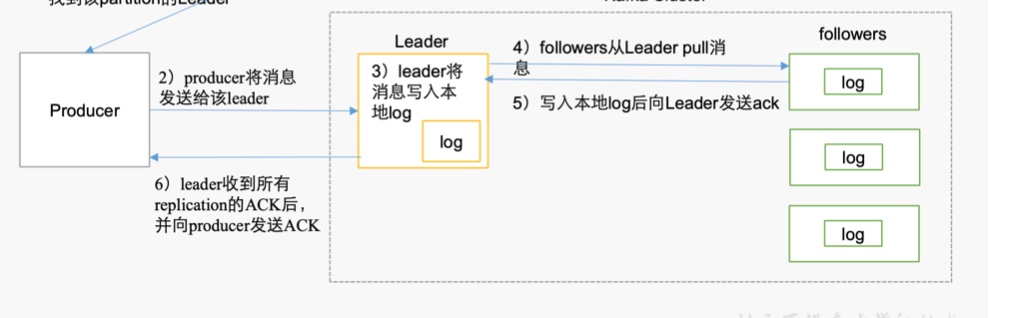
数据生产流程
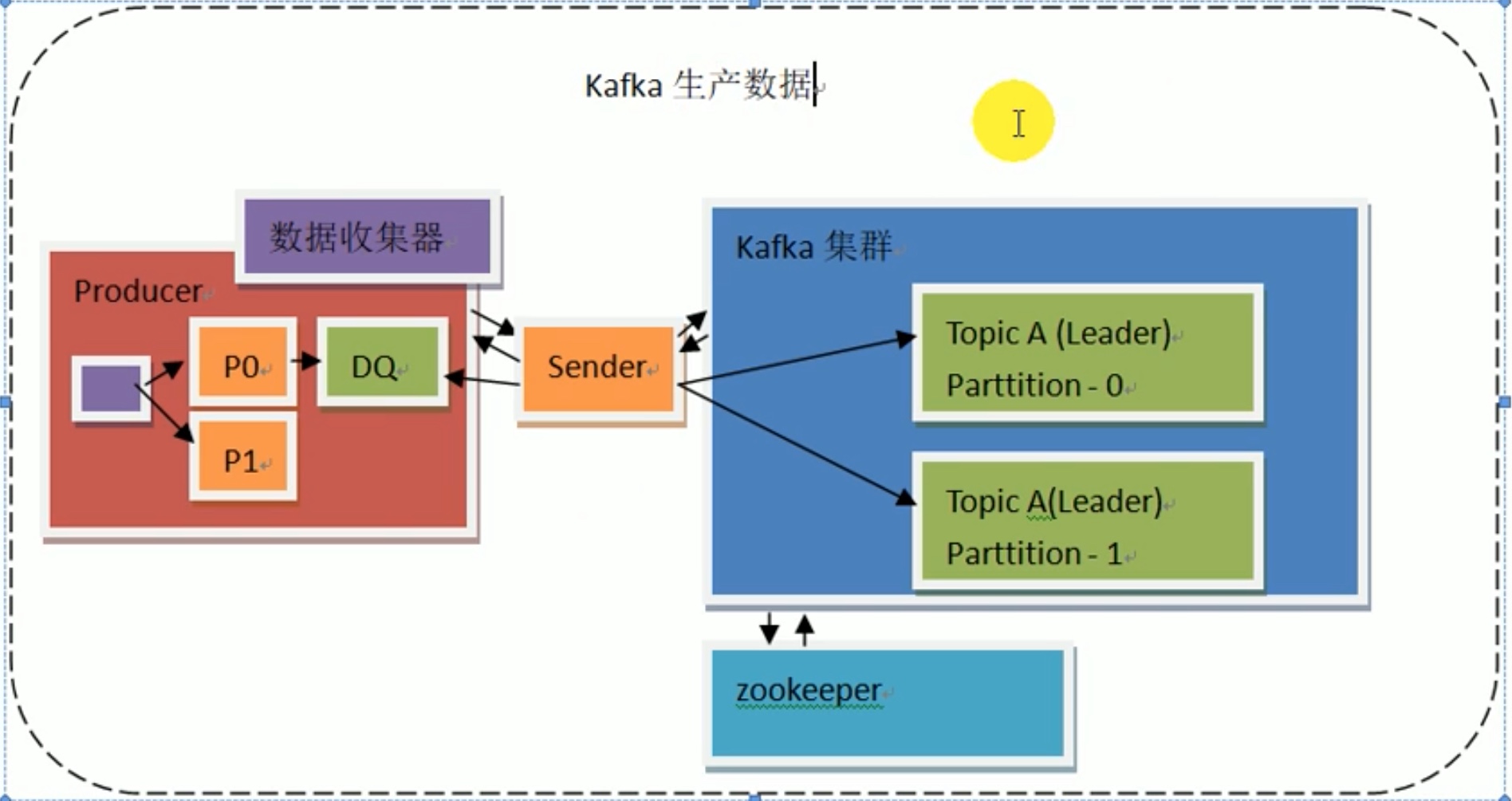
生产者想要把数据发送给 leader,虽然不知道leader是哪个,但是也没必要向zookeeper通信拿leader数据,因为zookeeper一直保持和kafka的通信,生产者直接送数据到kafka集群,kafka集群会自己和zookeeper通信,安排好数据发送到leader中。
由一个 sender 管理消息发送/退回 环节。如果 ack 无应答,消息传递失败,消息由sender原路返回producer的deque(双端队列)中。
producer 用批量传输的经典方式 避免频繁的消息传递资源浪费,于是在内部按照想要发送的分区 先 批量写好到一处p0等,后放进由数据收集器搭建的双端队列DQ(deque)中,由DQ进入sender。之所以要双端队列,是考虑到应答失败消息退回的存放。
数据保存流程
HW: high watermark 高水位。
LEO: log end offset 最后偏移量。
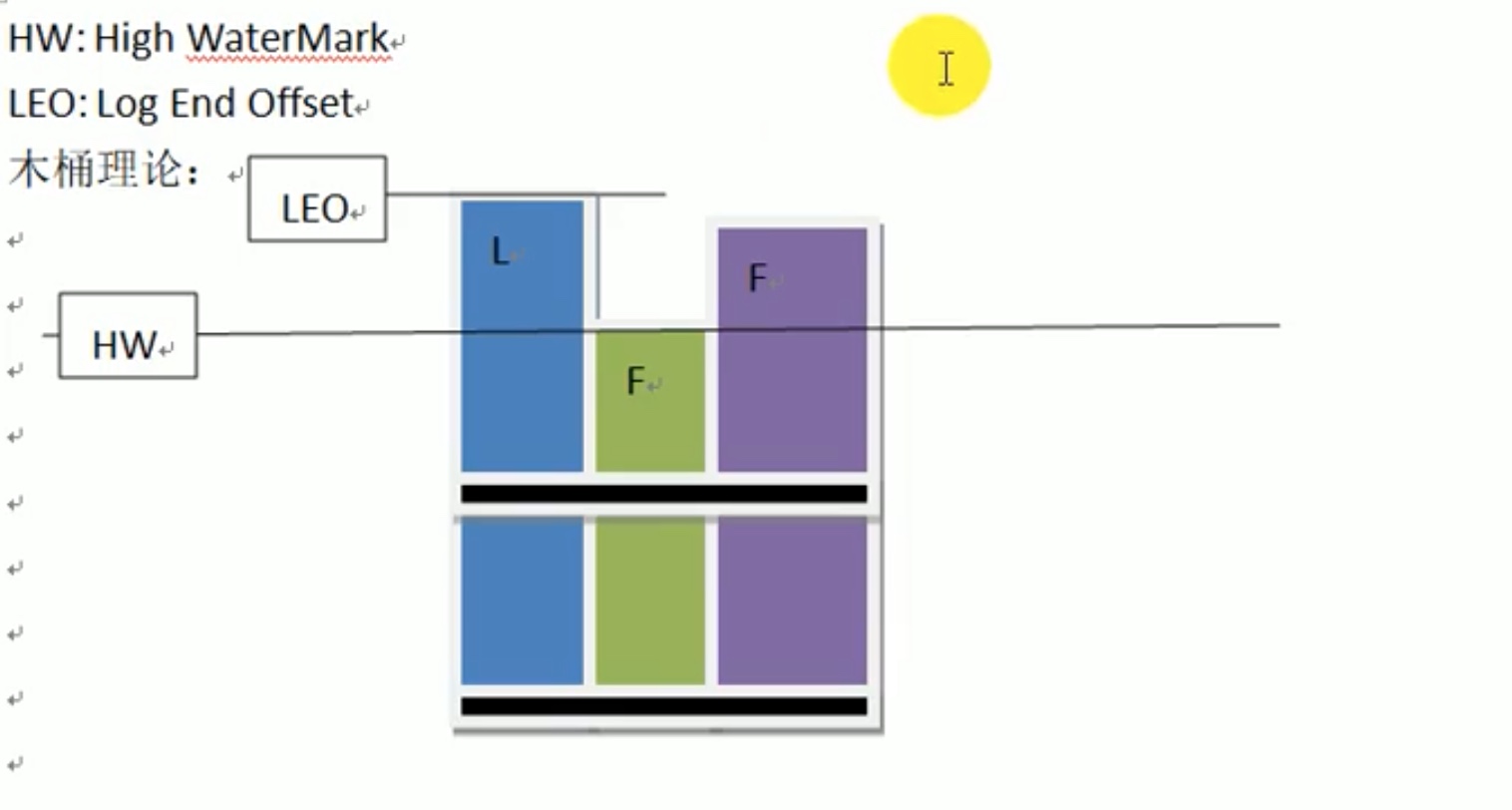
情形一:假设 下图时 leader突然宕机了。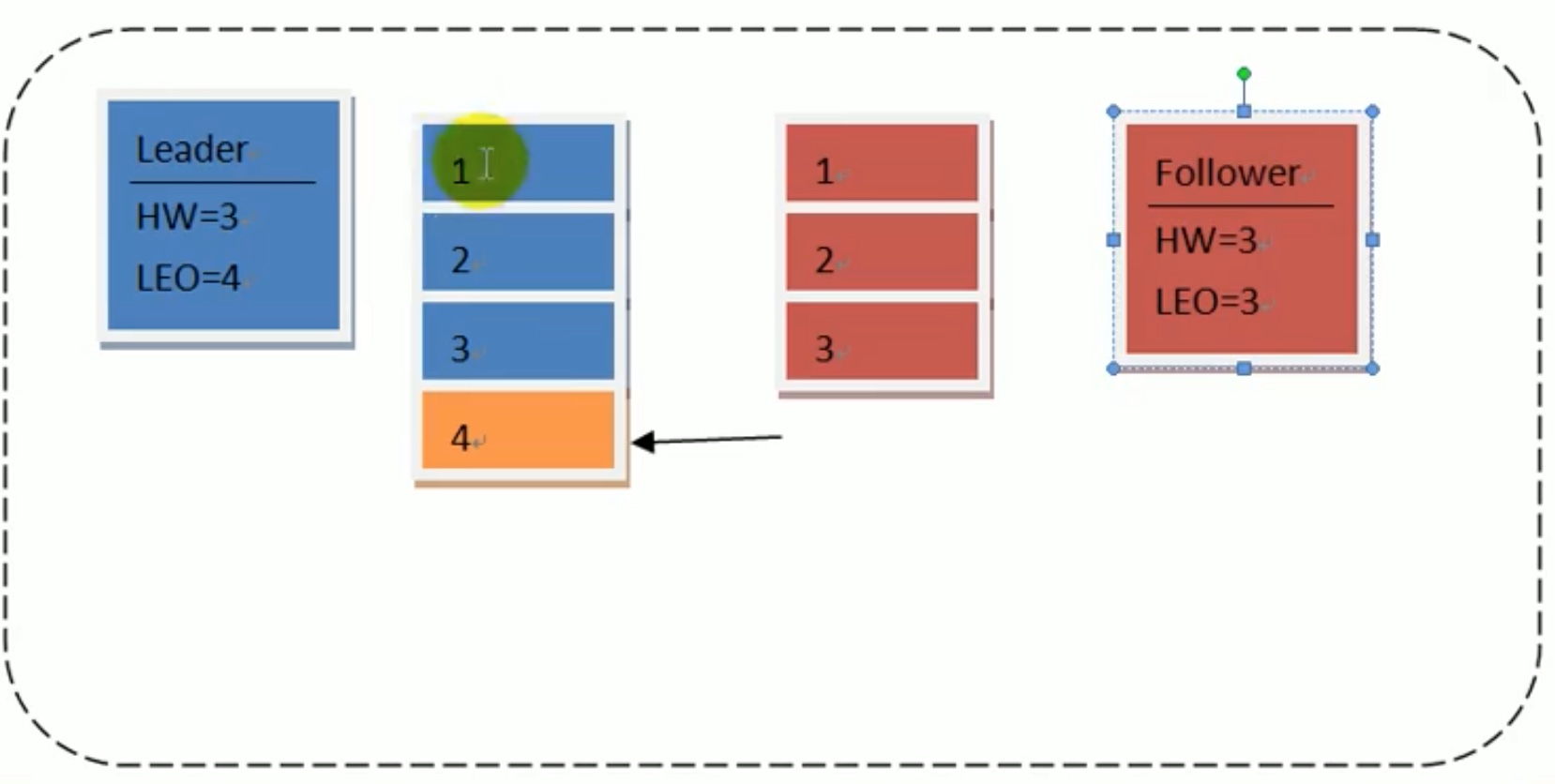
上图是 假定 leader拿到了一个新的数据4,high watermark 还是3,logend offset 变成了4。
正常情况下,follower找leader备份数据,会把消息4备份过来,然后leader的 hw 赋值 为 4,follower再把 leader中的 hw =4 备份过来让follower中同步 hw=4。
但是此时leader宕机,follower看不见leader的数据了, follower 的hw=3,leo=3 不会发生改变,并且转正成新的leader,此时用户都不知道数据发生了丢失。
情形二:假设 下图时 leader突然宕机了。
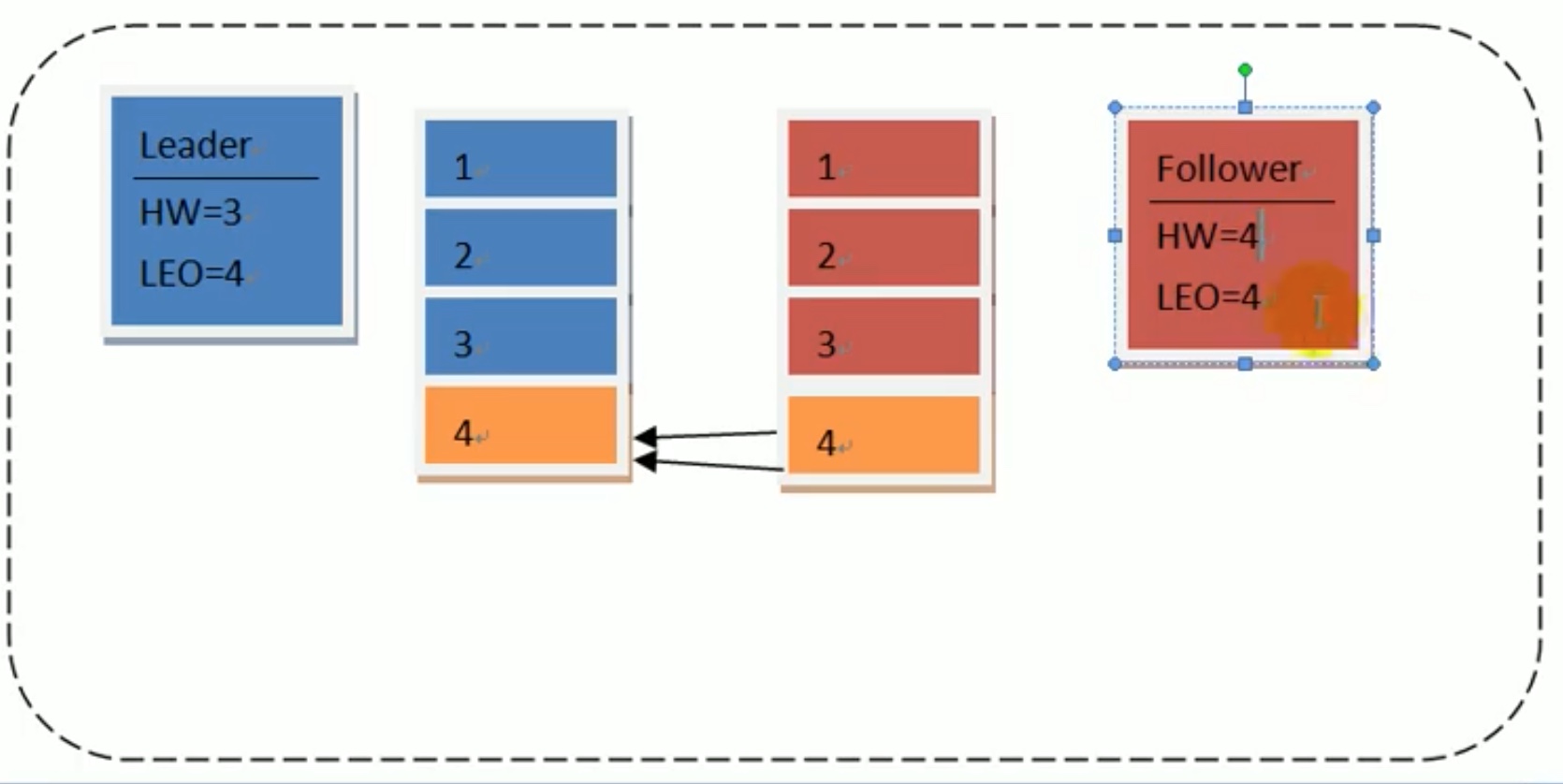 此时,follower 已经备份好了leader的数据,由于只有自己存在了,所以follower中 hw=4,leo=4,并且随后转正成leader,数据未发生丢失。
此时,follower 已经备份好了leader的数据,由于只有自己存在了,所以follower中 hw=4,leo=4,并且随后转正成leader,数据未发生丢失。
情形三:正常成功备份。
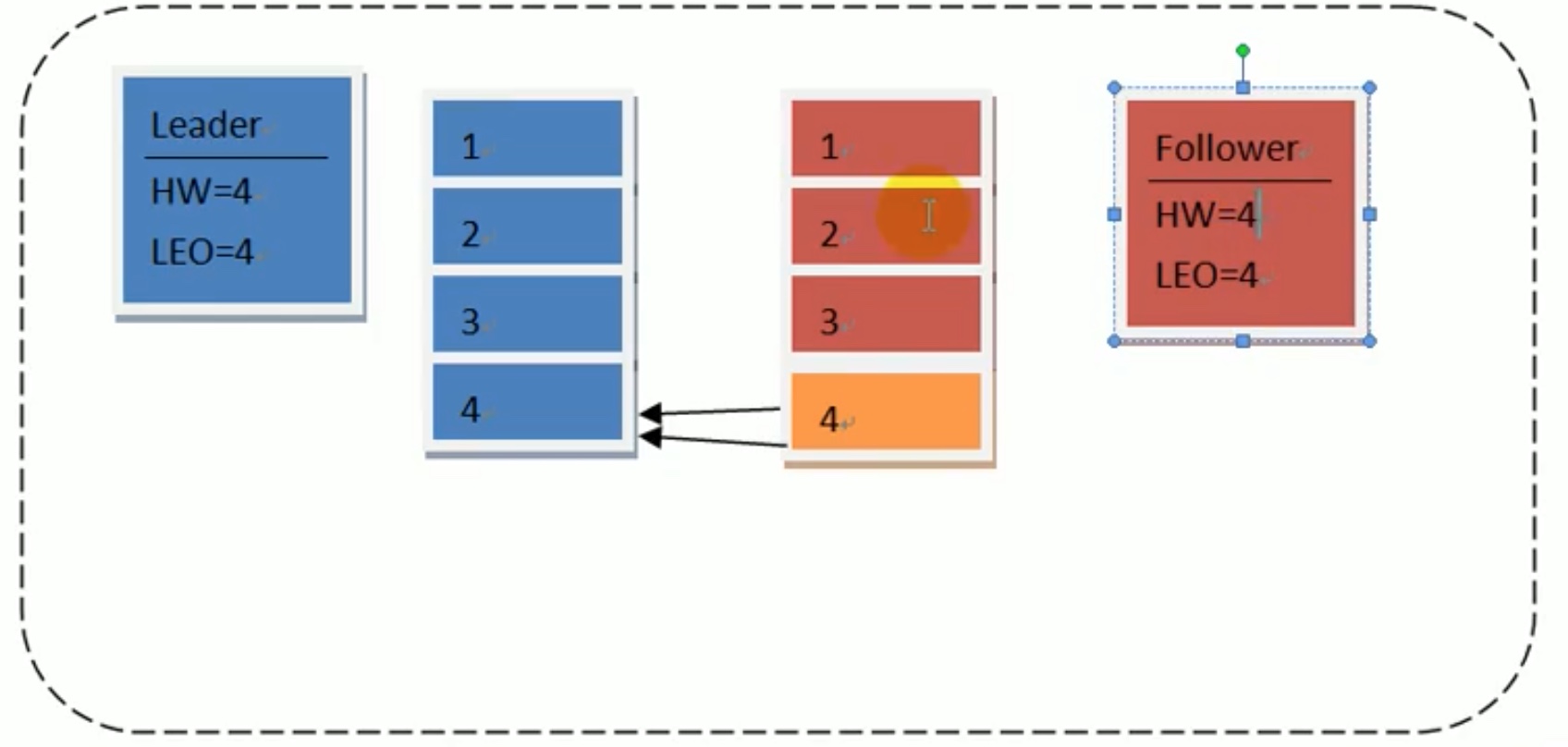
follower 备份好了数据4 ,follower 的 leo=4完成,leader 接收到follower 的 leo=4 完成的信息,leader中 hw从 3 改为 4,follower 看见leader的hw=4,也把自己的hw 同步为 4。
数据消费流程
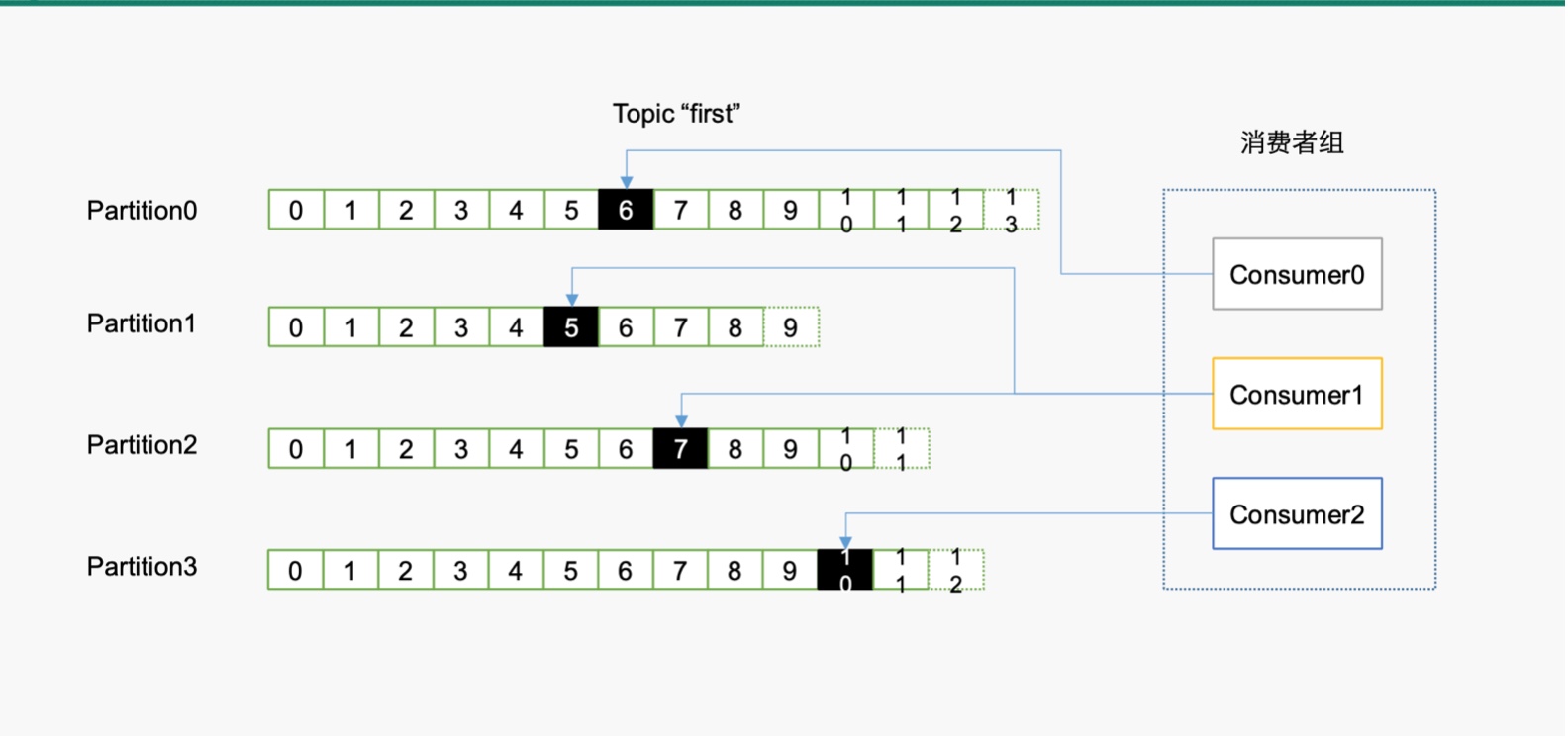
老版本的offset 是放在zookeeper中的,所以老版本的consumer 要调用zookeeper 集群拿数据,但是新版kafka 的offset 数据放在 kafka 集群的logs 文件中,用 bootstrap- server 直接从kafka集群中拿offset,来代替从zookeeper 中拿offset 数据了。其实offset 的数据还能放在redis 中,等等。
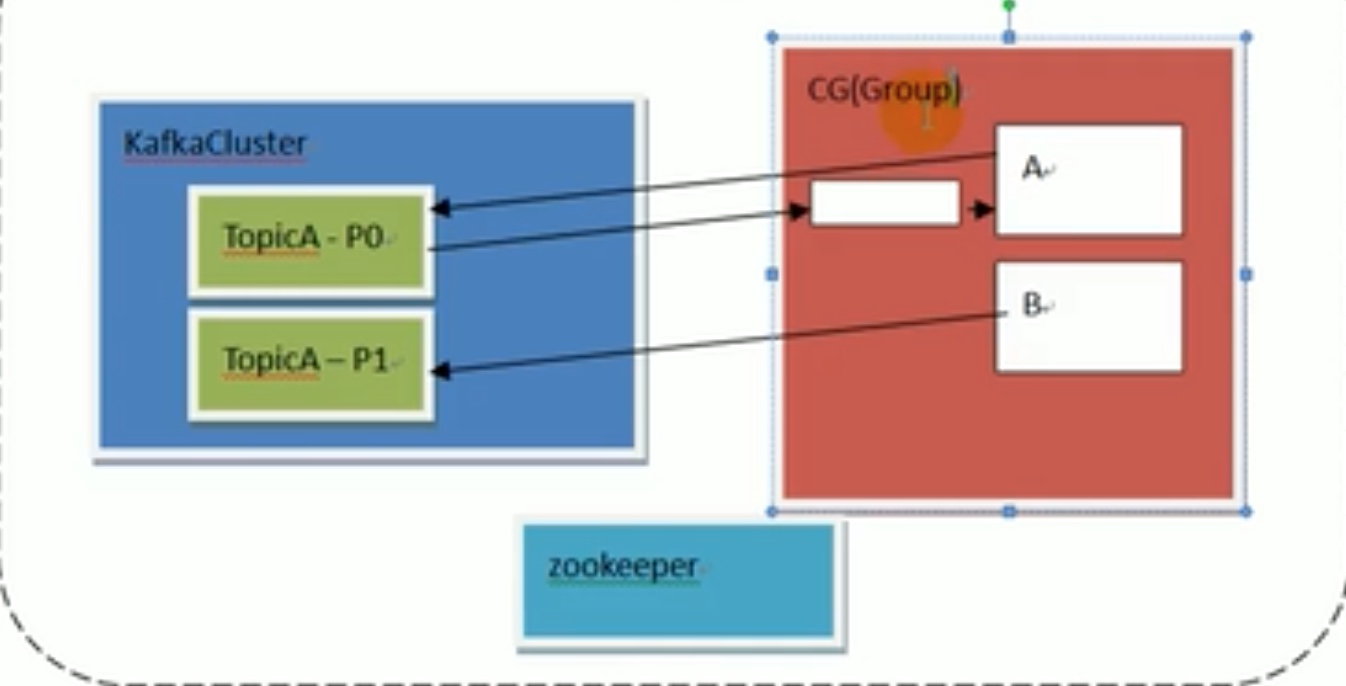
对某一个时刻而言,1个消费者可以消费多个partition,但是 1个partition 在这一时刻 只能 被一个消费者消费。
因为 offset 偏移量是以 group 为单位标记的,如上图,a、b在一个组内,只能是a消费完了以后,b才能接着a消费完的offset位置继续消费。
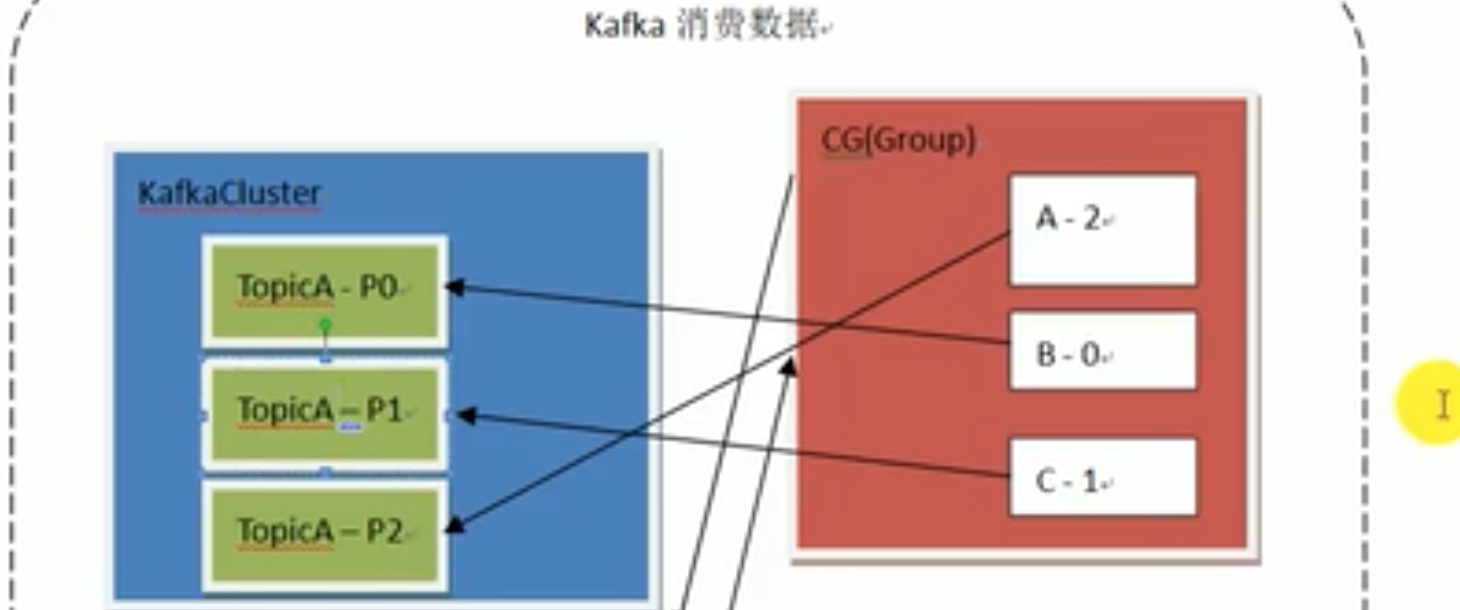
再平衡策略
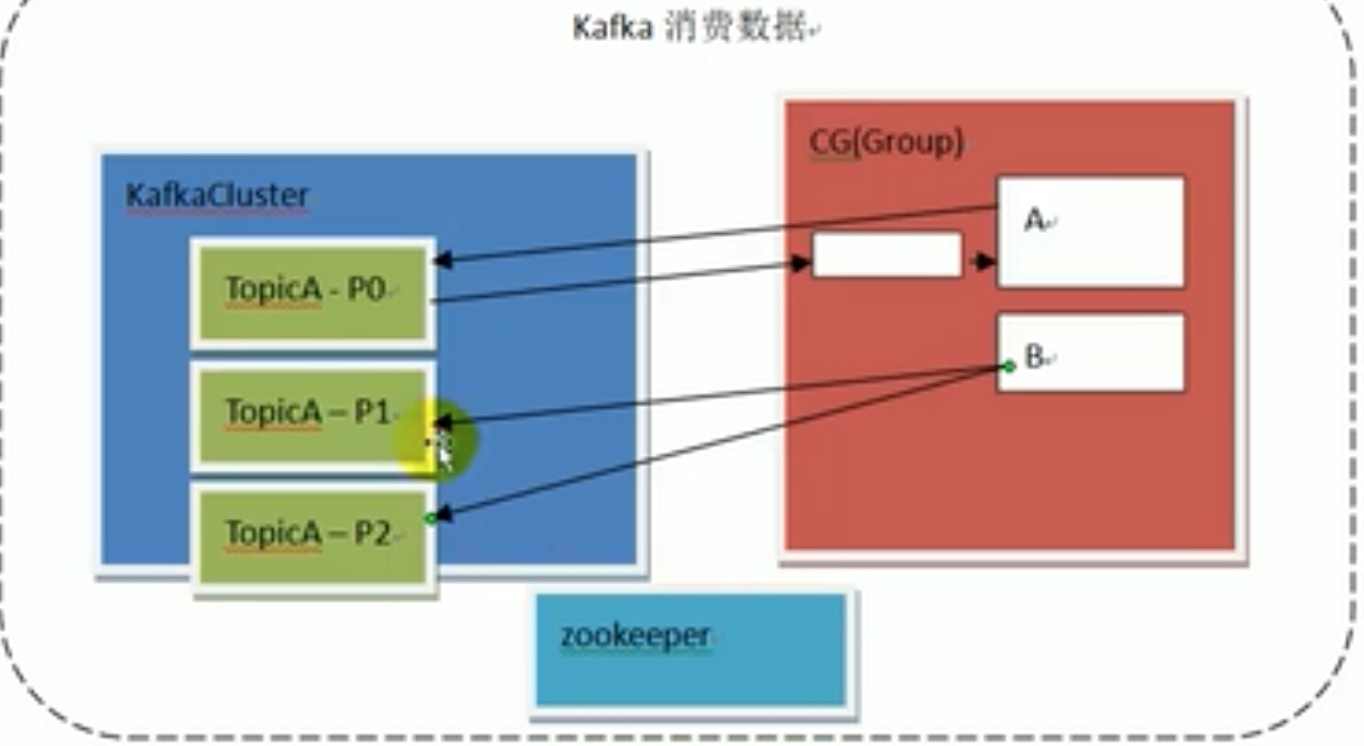
上图中,三个partition 一个消费组,两个消费者,b消费者消费两个分区。为了效率我们再组内加入了一个新的消费者,会触发 “再平衡”策略,在组内选leader消费者,合理安排组内成员消费,尽可能一一对应分组消费。如下图:
broker消息存储
存储方式
物理上把topic分成一个或多个patition(对应 server.properties 中的num.partitions=3配置),每个patition物理上对应一个文件夹(该文件夹存储该patition的所有消息和索引文件)
存储策略
无论消息是否被消费,kafka都会保留所有消息。有两种策略可以删除旧数据:
1)基于时间:log.retention.hours=168(7天)
2)基于大小:log.retention.bytes=1073741824(1g)
需要注意的是,因为Kafka读取特定消息的时间复杂度为O(1),因为index的存在,即与文件大小无关,所以这里删除过期文件与提高 Kafka 性能无关。
Zookeeper 存储结构(matedata)
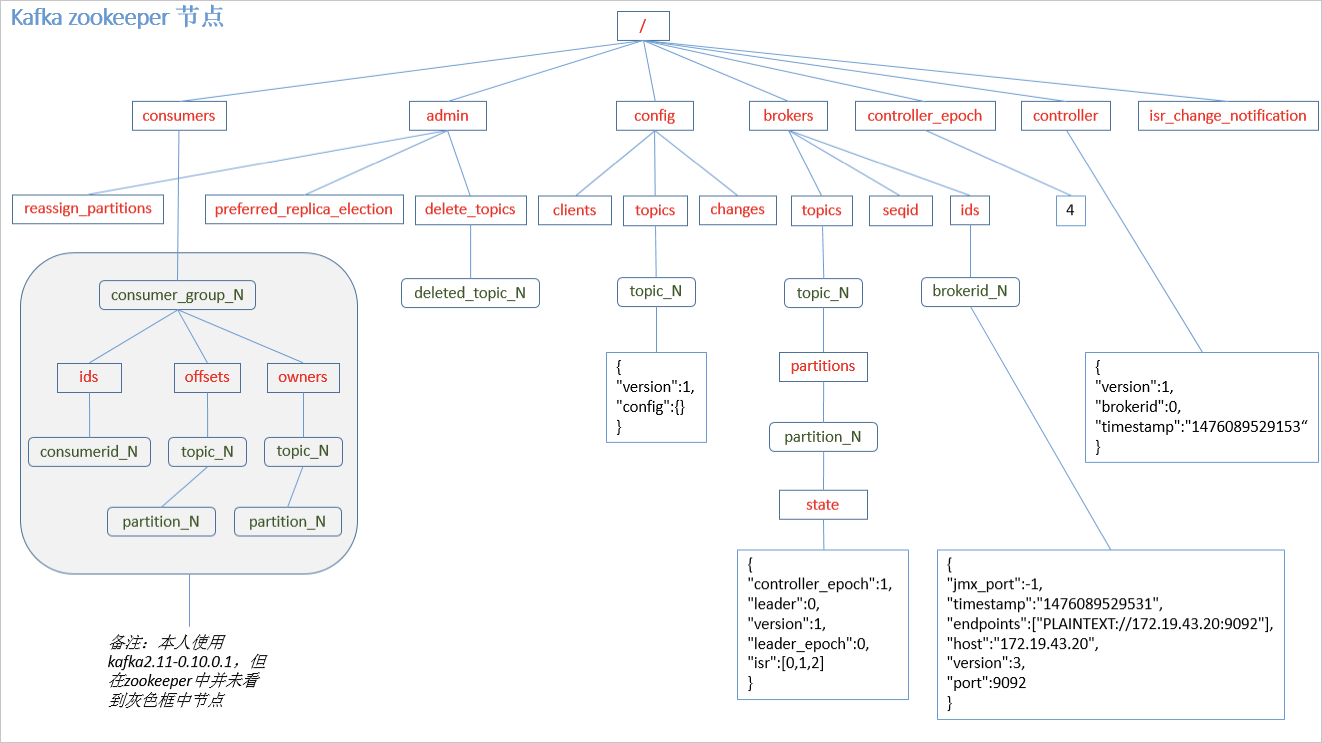 producer不在zk中注册,消费者在zk中注册(新版本也不在zk中了,直接放在logs中,以组脚本命令查看)。
producer不在zk中注册,消费者在zk中注册(新版本也不在zk中了,直接放在logs中,以组脚本命令查看)。
我们在zookeeper 的bin 文件夹中 zkCli.sh 然后 回车 ls / 查看zookeeper的根目录中有什么,发现全部都是kafka存入的文件,如下: 
我们加入这些文件夹,看看这些元数据到底是什么。
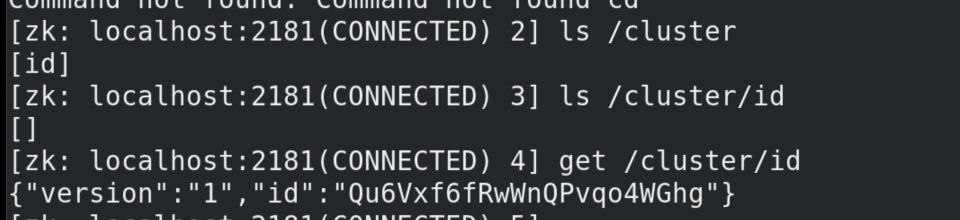
在/cluster/id 中 有版本1,kafka集群 的id号。

在controller中,指定了集群的 “老大” 是 brokerid =1 的那个。由它来安排kafka 的其他broker,zookeeper 有选举机制,“老大”没了能选个新的。

“老大” broker 挂掉 一次,就要竞选一次,竞选一次就进入一个新的纪元epoch,上图说明竞选了3次。
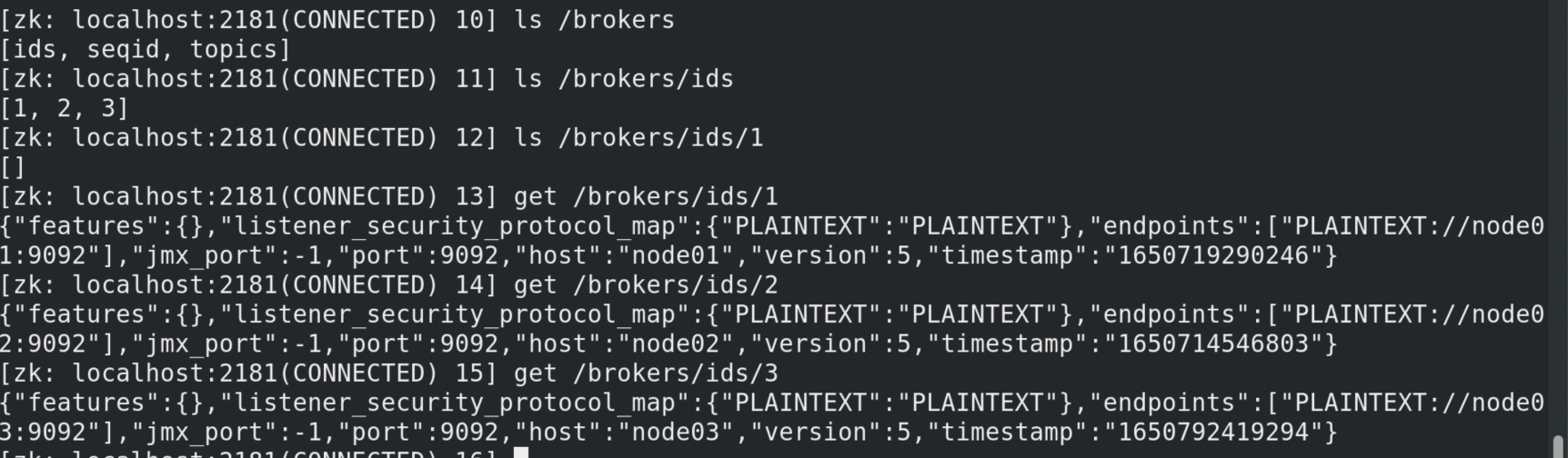

/brokers 中有 broker的信息,id 是 broker相关,topic 有消费者偏移量 50份、topic信息等等 ,如上图。还挺详细。
消费者组信息存储
1 | bootstrap-server打开一个消费者 |
消费者组消费 topic 的元数据信息,在旧版本里面是存储在 zookeeper 中,但由于 zookeeper 并不适合大批量的频繁写入操作,新版 kafka 已将消费者组的元数据信息保存在 kafka 内部的 topic 中,即 __consumer_offsets ,并提供了kafka-consumer-groups.sh 脚本供用户查看消费者组的元数据信息。
那么如何使用 kafka 提供的脚本查询某消费者组的元数据信息呢?
1 | 查看消费者列表 |
__consumer_offsets 默认有 50 个 partition,kafka 会根据 group.id 的 hash 值选择往哪个 partition 里面存放该 group 的元数据信息。
计算 group.id 对应的 partition 的公式为:
Math.abs(groupID.hashCode()) % numPartitions
举例:Math.abs(“test-17”.hashCode()) % 50,其中 test-17 是 group.id 。
找到 group.id 对应的 partition 后,就可以指定分区消费了:
1 | ./bin/kafka-console-consumer.sh --bootstrap-server message-1:9092 --topic __consumer_offsets --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --partition 45 |

开一个producer和两个consumer窗口(实际生成了两个消费者组),陆续在producer写入多行数据,我们在 group 内 describe检查,发现log-end- offset一直在变化,不停写入不同的分区中: 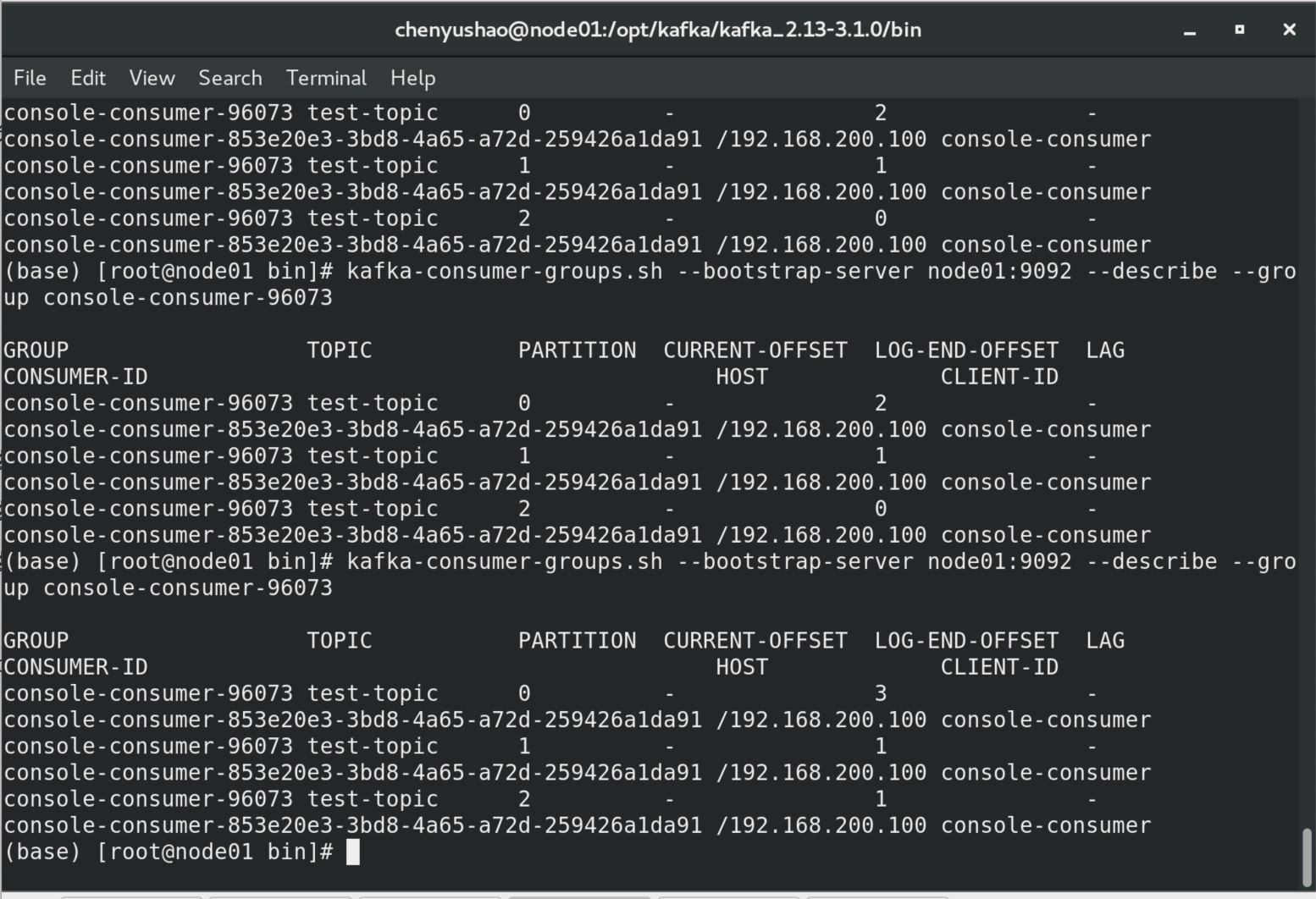
实现消费者组
案例实操
(1)在node02、node03 上修改 config/consumer.properties配置文件中的group.id属性为任意组名。
(2)在node02、node03 上分别启动消费者(带上参数–consumer.config )
1 | kafka-console-consumer.sh --bootstrap-server node01:9092 --topic test-topic --consumer.config ../config/consumer.properties |
(3)在node01 上启动生产者,随便输入一堆数据。
1 | kafka-console-producer.sh --broker-list node01:9092 --topic test-topic |
(4)查看node02、node03的接收者。
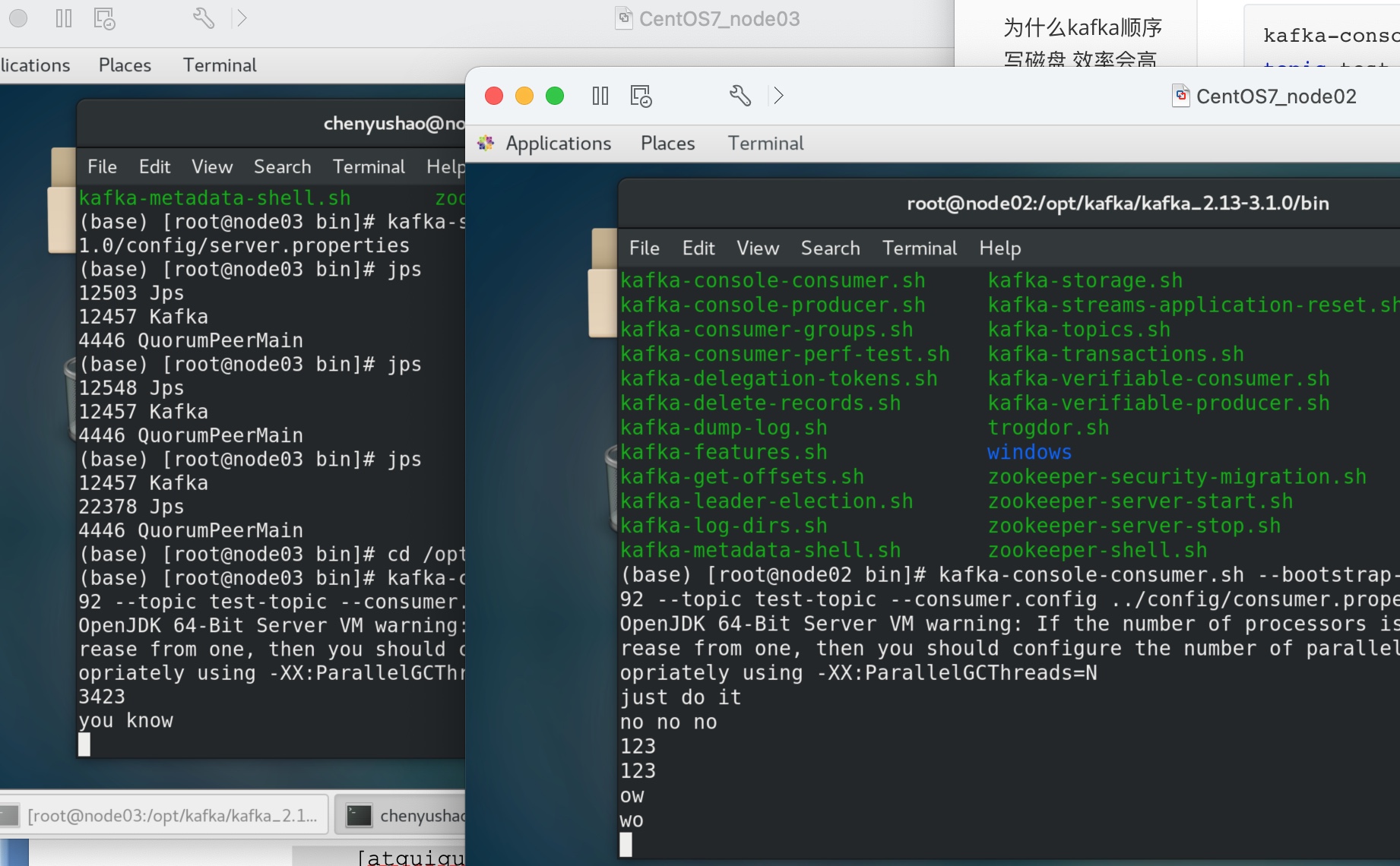
可见同一时刻只有一个消费者接收到消息。
offset管理高级API
1)高级API优点
高级API 写起来简单
不需要自行去管理offset,系统通过自行管理。
不需要管理分区,副本等情况,.系统自动管理。
消费者断线会自动根据上一次记录的offset去接着获取数据(默认设置1分钟更新一下__consumer_offset中存的offset)
可以使用group来区分对同一个topic 的不同程序访问分离开来(不同的group记录不同的offset,这样不同程序读取同一个topic才不会因为offset互相影响)
2)高级API缺点
不能自行控制offset(对于某些特殊需求来说)
比如“去重”,offset没更新就挂了,又消费一遍导致重复消费,我们最好手动给offset一个去重处理,遇到一样的部分跳过,这样消费时去重也可以把生产者带来的重复数据一并处理,但是高级API做不到。
不能细化控制如分区、副本 等
offset管理低级API
1)低级 API 优点
能够让开发者自己控制offset,想从哪里读取就从哪里读取。
自行控制连接分区,对分区自定义进行负载均衡
2)低级API缺点
太过复杂,需要自行控制offset,连接哪个分区,找到分区leader 等。