kafka分布式架构原理
简介
分布式架构原理
java 虚拟机中 栈负责运行,堆负责存储,方法区存的是class对应的东西。
java 虚拟机 中 一个线程 就会有一个栈空间,一个请求会开一个线程,多个请求很容易 开太多的栈空间,内存不够用(“栈内存溢出”)这个“栈内存溢出”不同于递归死循环导致的“栈溢出”,栈溢出是栈产生的深度超出了,java虚拟机限制了 压栈的深度。为了解决“栈内存溢出” 引入了多个 服务器,又为了解决访问分配端口的问题,引入了 负载均衡器。 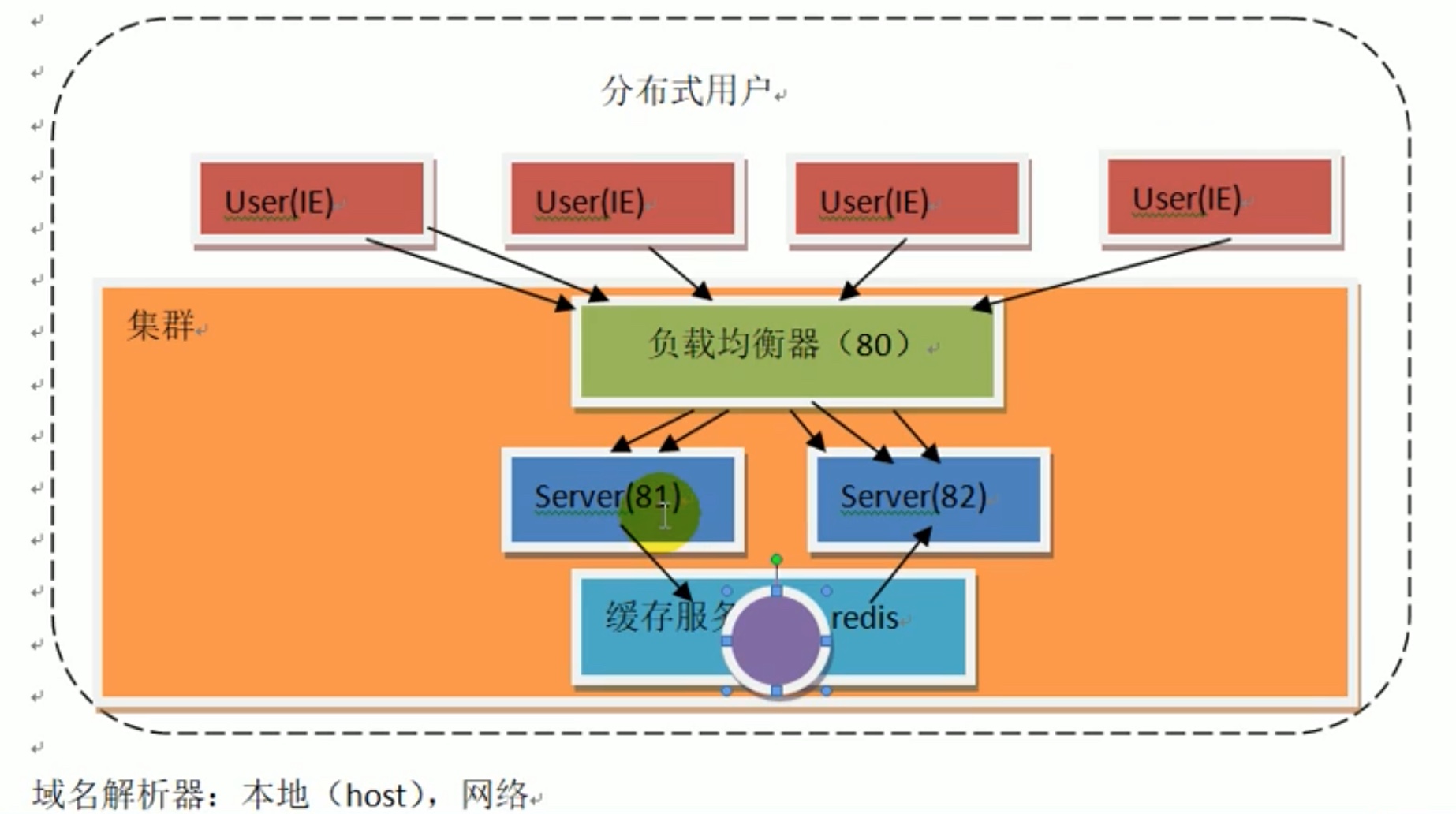
上图的负载均衡器,在接收了用户请求之后,还要去调配用户访问哪个服务器,压力全部都在 负载均衡器上,也有可能崩溃。
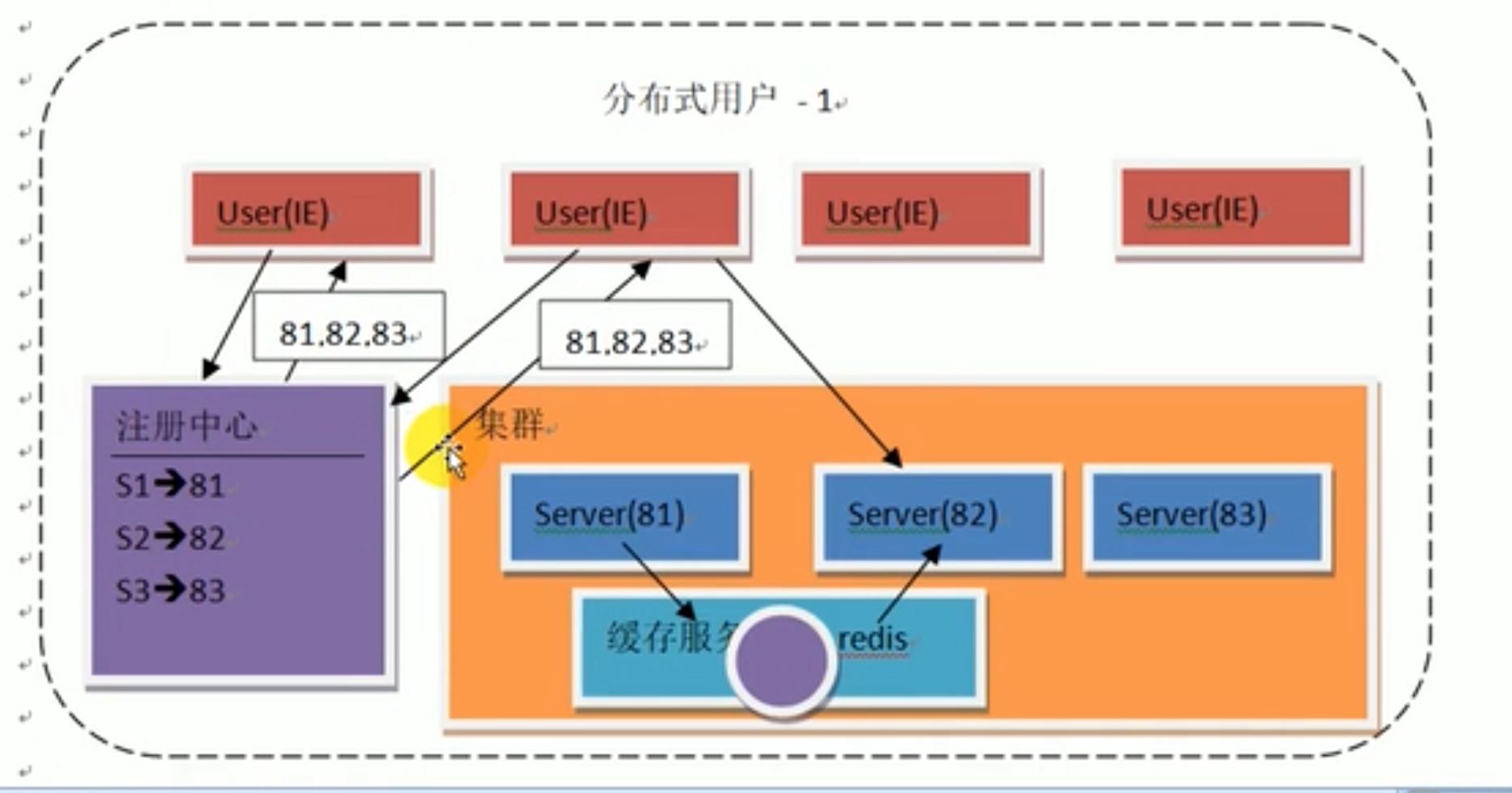
改进方法如下图所示,建立一个 “注册中心” 用户访问注册中心会得到集群内所有服务器的端口地址,由用户自己去选择访问哪一个服务器,由于负载均衡器要掉配而注册中心仅仅需要返回地址,所以压力大大缓解(压力放到了用户端)。spark学习中用到的zookeeper 就是一个注册中心。
如果一个服务器内有多个功能,用户访问一些功能多一些功能少,会出现资源被过多占用影响部分功能,所以我们让一个服务器一个功能,但是这也是理论上,因为总体的io资源有限,访问一个服务器太多也会影响别的服务器。 如果出现 管理不同用途的服务器 之间直接交互,会产生耦合,违背了开发原则(可以新加入功能,但是不能修改旧有代码,比如新加一个财务服务器,订单服务器就要修改目的端口地址)。
以下就是不良的耦合情况。
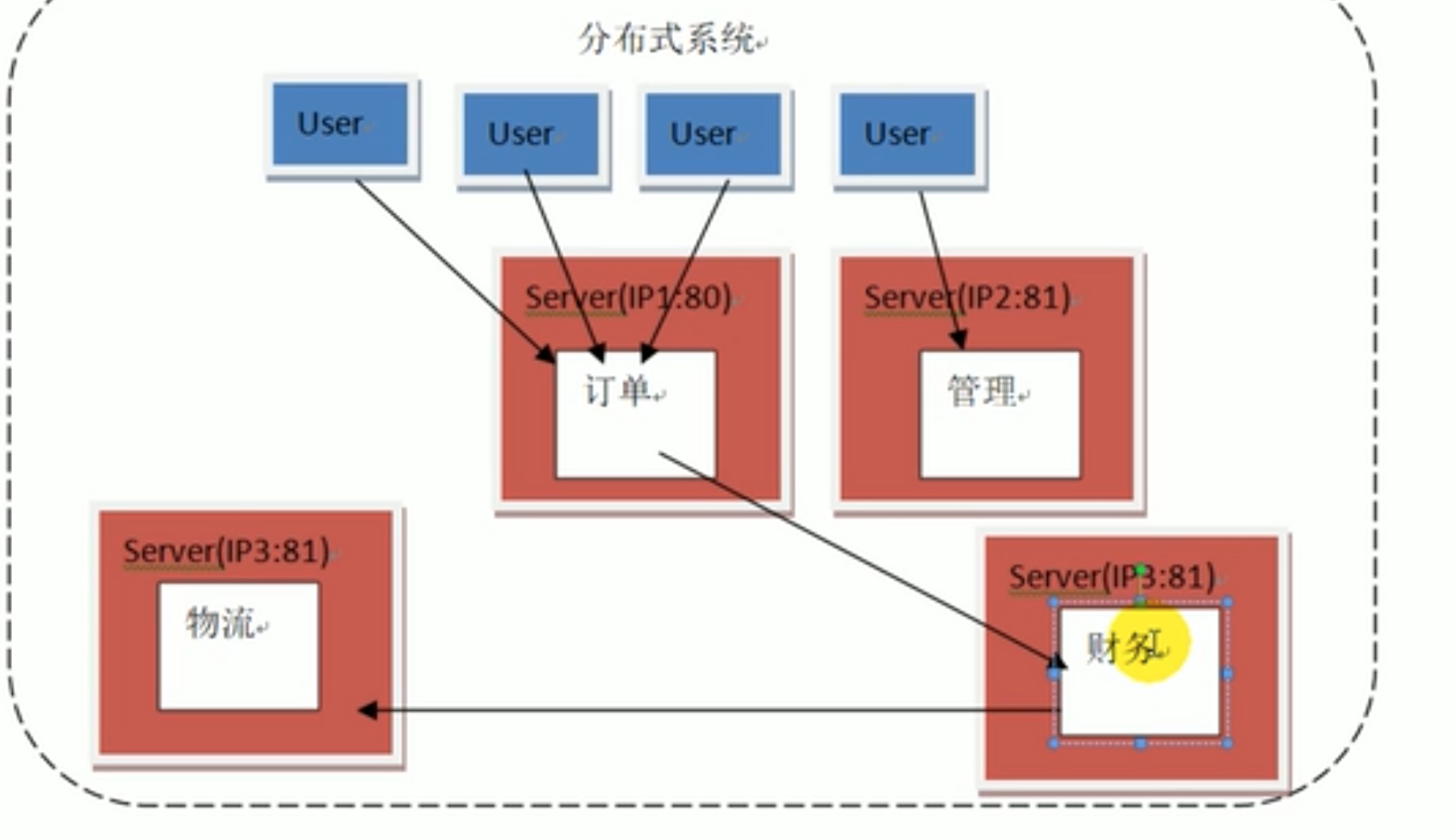
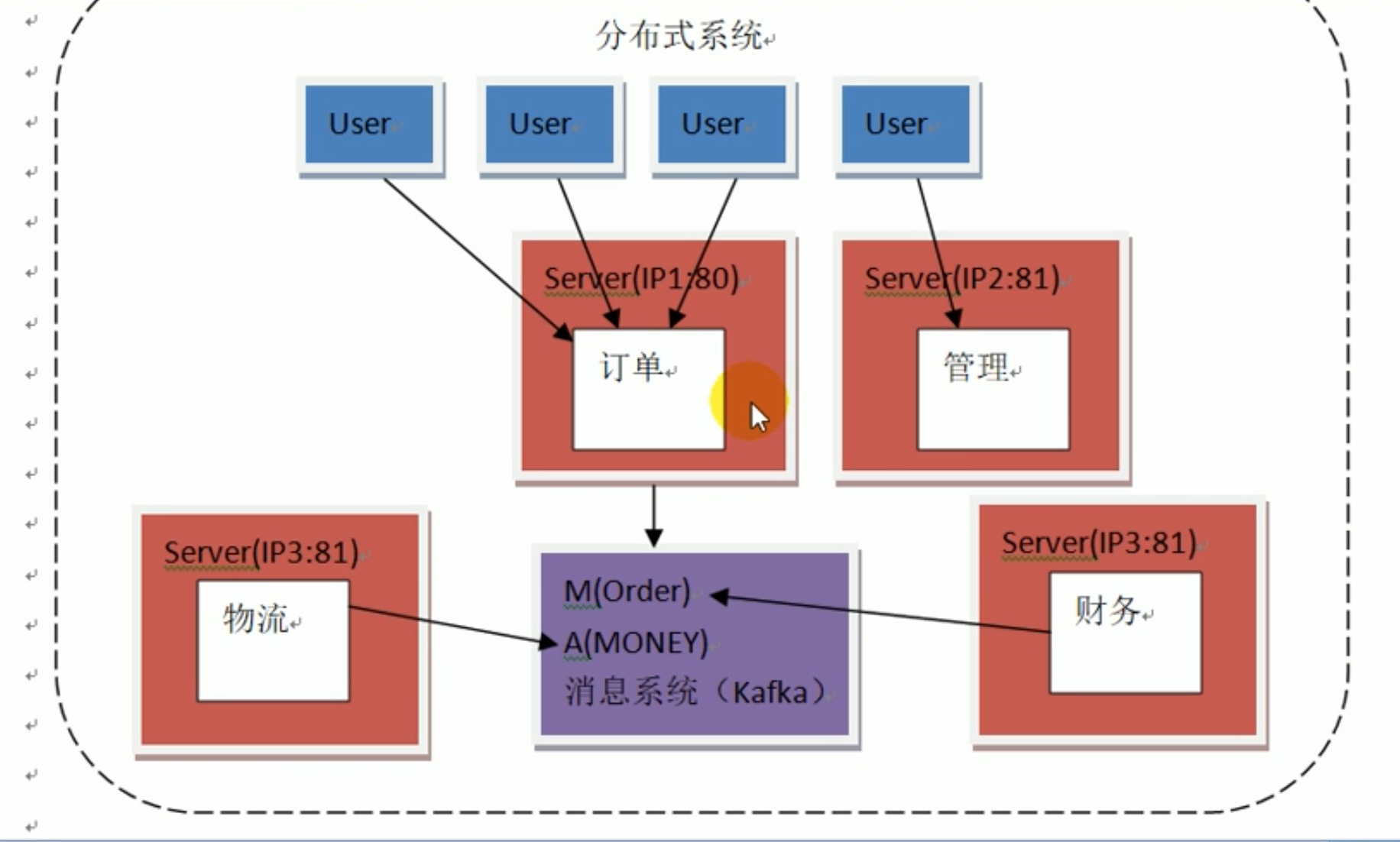
为了避免服务器之间直接交互产生 “耦合”,我们引入“消息系统”;
“消息系统”操作流程如下:
订单服务器把新生成的订单信息 放入“消息系统”中,财务服务器和物流服务器定时来 “消息系统” 中取数据。每个系统只从消息系统中获取他们关心的数据。kafka 就是这样一个消息系统。
Flume
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单,特点就是实时,有缓存,快速,相比较于普通的API上传到hdfs,flume会更快,所以,flume是非常好用的传输层系统。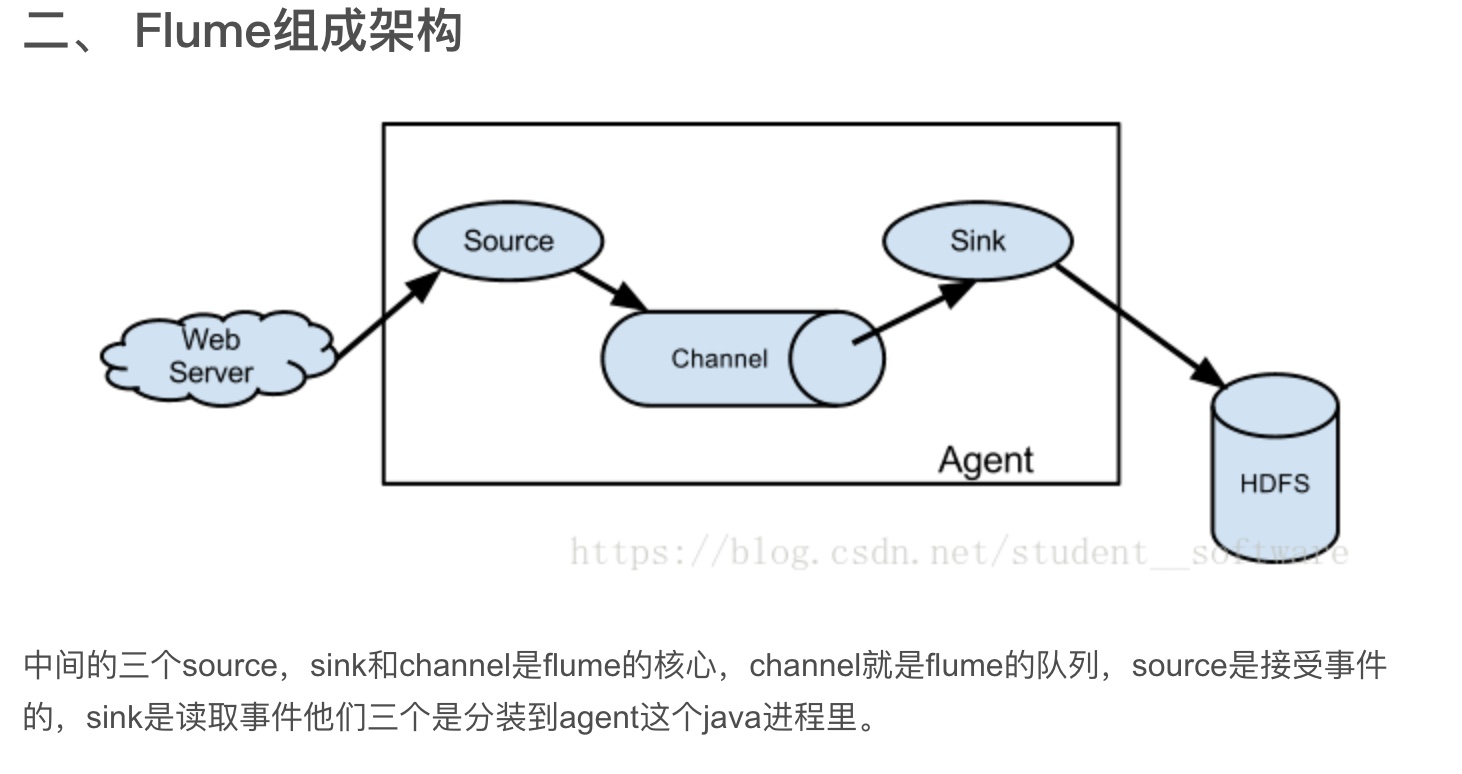





Flume存在的问题
说到底flume 是一个 数据传输系统。
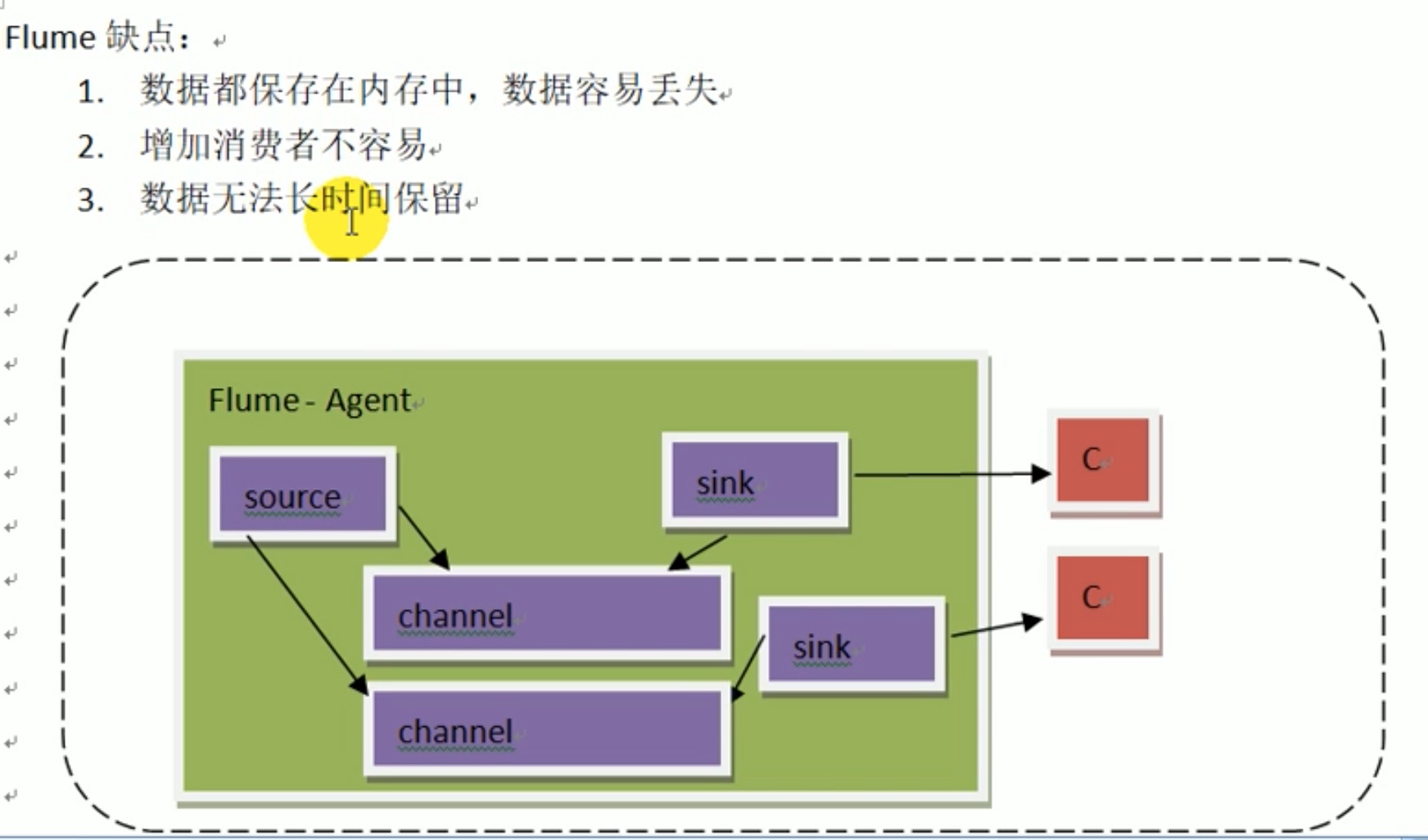
新增一个c,要对agent 改动太多,或者又要加agent,违背了开发原则(新加不改旧)。
改进一个新系统来实现 数据长时间存储。
同时考虑到访问量可能很大,所以用分布式的多服务器集群 来实现。
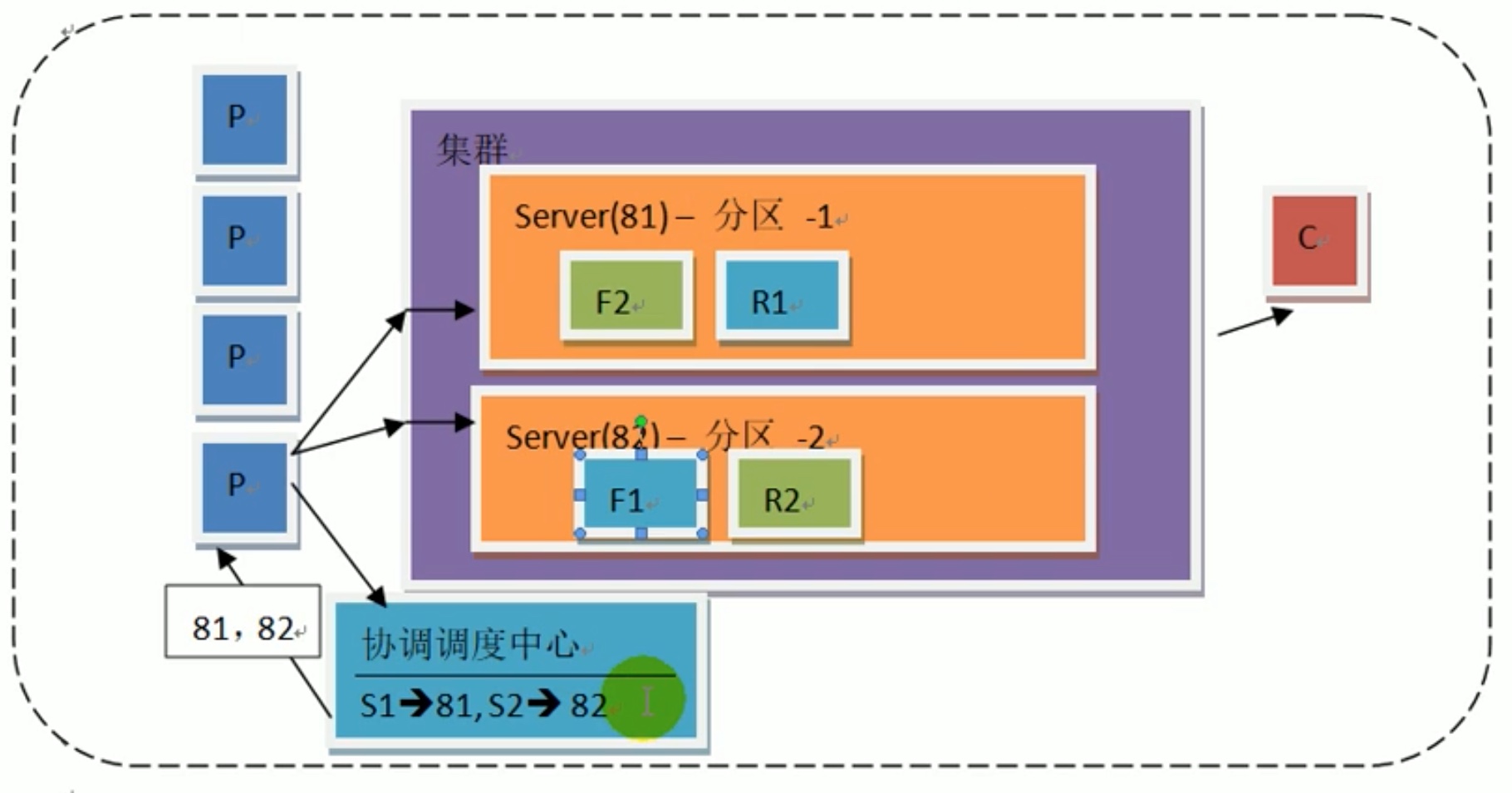
如果一个服务器宕机了怎么办?于是我们把服务器1备份服务器2的数据,服务器2备份服务器1的数据,交叉备份,宕机一个也没事。这视为分区。
如果此时有两条消息,发到分区1还是分区2呢?
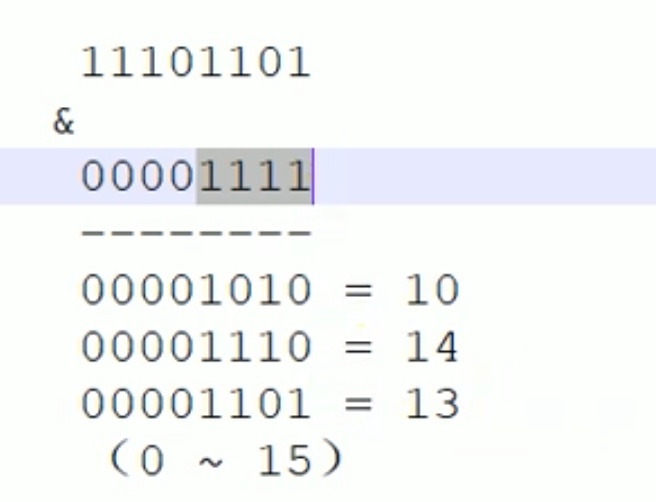
这里要用到hash算法,但是大数据中我们用到的hash算法源码一般不是取mod,而是进行二进制&运算,2^4-1=15, 0~15一共16个位置,满足16个字母的位置。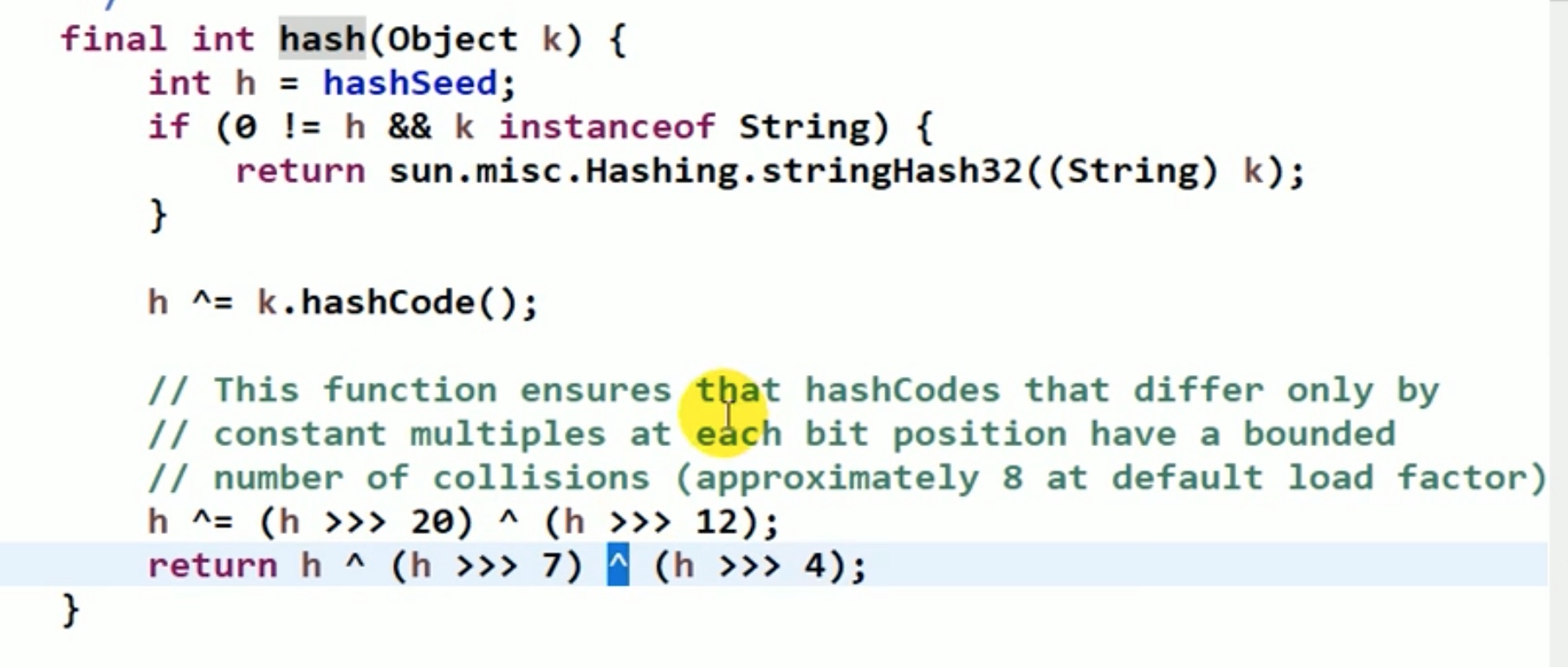
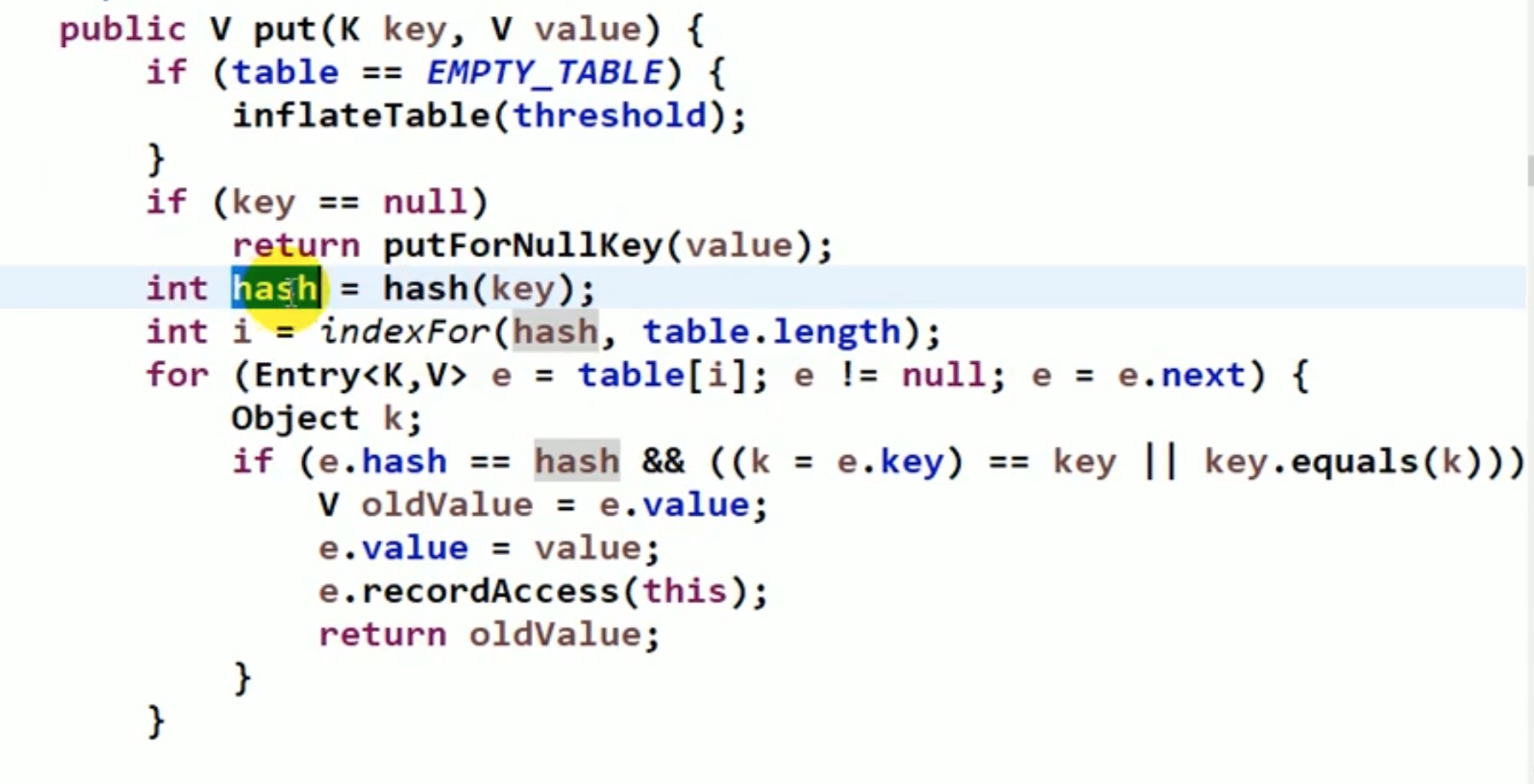
也只有 2^n 这样的 2倍关系的扩容才行(length*2^n),因为只有这样,二进制&运算才能 得到 111…111这样能够覆盖住所有连续数字的区域,例如 00001001就不能覆盖住 2、3、4等数字,只有全1 ,才能全覆盖。
在用hash散列解决完数据 进入哪个分区之后,还要解决 c客户端增加带来的 可能要改动集群的问题,怎么处理呢?
把数据主动从集群分发到每个c客户端,改为,由c客户端主动找集群要数据,c主动把每个服务器都访问一遍,这样,加多少个c,集群不用改变。
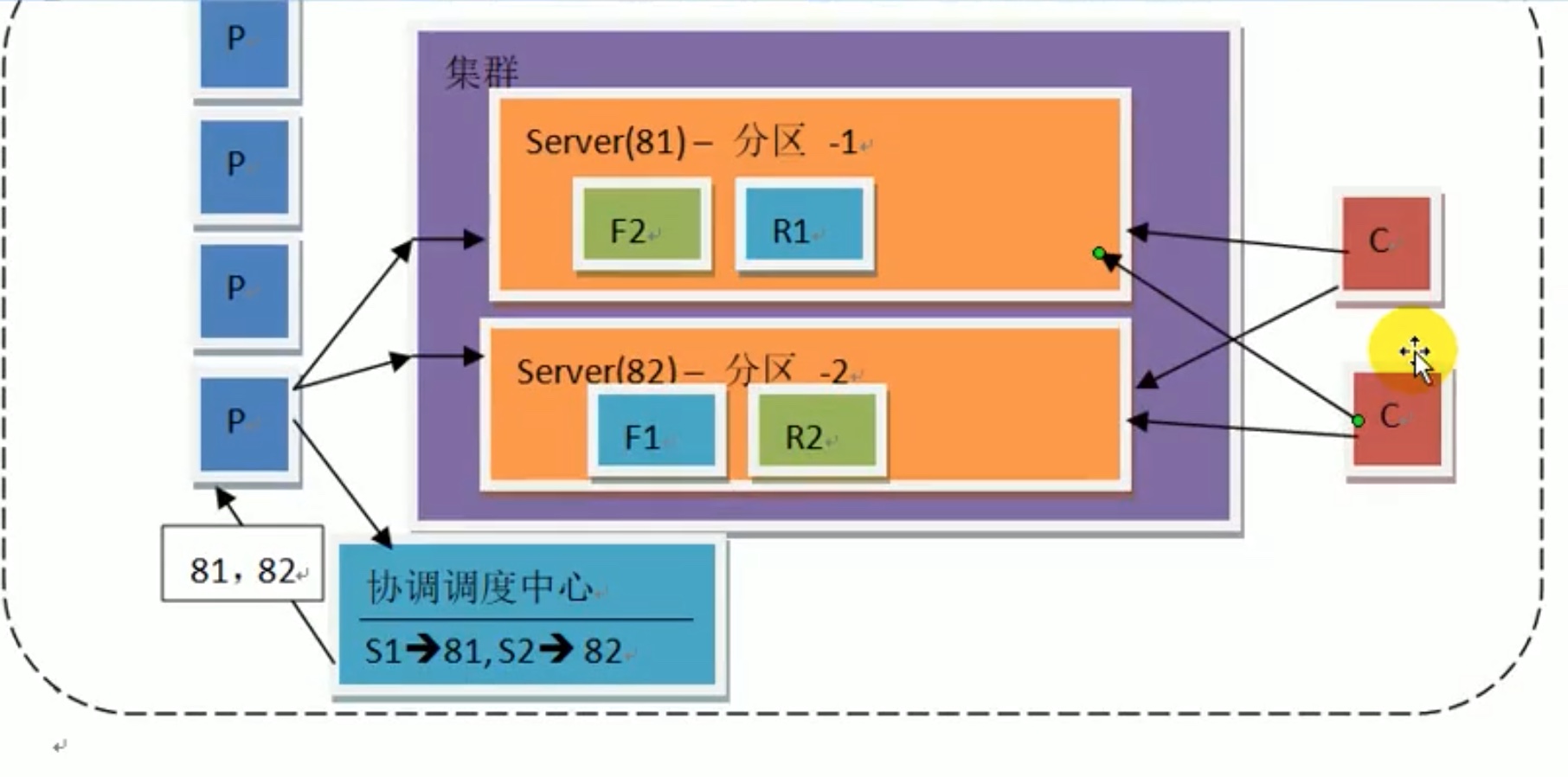
卡夫卡就是按照这样的设计思路来的,当然集群内部不一样。