kafka和flume的集成
简介
先说一下,为什么要使用 Flume + Kafka?
以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将 Flume 聚合后的数据输入到 Storm 等分布式计算框架中,可能就会超过集群的处理能力,这时采用 Kafka 就可以起到削峰的作用。Kafka 天生为大数据场景而设计,具有高吞吐的特性,能很好地抗住峰值数据的冲击。
一、flume-to-kafka整合流程
官方文档
https://flume.liyifeng.org/#kafka-source
Flume 发送数据到 Kafka 上主要是通过 Kafka Sink 来实现
1. 启动Zookeeper和Kafka
1 | 启动zookeeper集群,在每台机器上开启。 |
2. 创建主题
1 | 创建主题 |
3. 启动kafka消费者
1 | 这里不用kafka-python 自己写了,直接用终端开。 |
4. 配置Flume
新建配置文件 flume-to-kafka.properties,文件内容如下。这里我们监听一个名为 flume_to_kafka.log 的文件,当文件内容有变化时,将新增加的内容发送到 Kafka 的 flume-kafka 主题上。
1 | cd /opt/data/ |
1 | cd /opt/flume/conf |
5. 启动Flume
1 | bin/flume-ng agent \ |
6. 测试
向监听的 flume_to_kafka.log 文件中追加内容,查看 Kafka 消费者的输出:


可见,日志改变,改变的内容被kafkasink 实现kafka生产者发送进了kafka的cluster集群,最后被kafka的consumer消费掉了。
二、kafka-to-flume整合
官方文档
https://flume.liyifeng.org/#kafka-source
基本流程和flume to kafka 一样,在配置上改一改就行了。
启动Zookeeper和Kafka
创建主题
1
2
3
4
5创建主题
/opt/kafka/kafka_2.13-3.1.0/bin/kafka-topics.sh --create \
--bootstrap-server node01:9092 \
--replication-factor 2 \
--partitions 3 --topic kafka-flume启动kafka生产者
1
/opt/kafka/kafka_2.13-3.1.0/bin/kafka-console-producer.sh --broker-list node01:9092 --topic kafka-flume
配置Flume
1
cd /opt/flume/conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41vim kafka_to_flume.properties
a1.sources = s1
a1.channels = c1
a1.sinks = k1
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
设置Kafka类来源端(kafkasource实际是实现了一个kafka消费者)
a1.sources.s1.type = org.apache.flume.source.kafka.KafkaSource
设置Kafka地址
a1.sources.s1.kafka.bootstrap.servers = node01:9092
设置发送到Kafka上的主题
a1.sources.s1.kafka.topics = kafka-flume
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
定义拦截器,为消息添加时间戳
a1.sources.s1.interceptors = i1
a1.sources.s1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
sink 传到hdfs 中。
a1.sinks.k1.type= hdfs
a1.sinks.k1.hdfs.path = hdfs://node01:9000/flume/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.fileType = DataStream
不按照条数生成文件
a1.sinks.k1.hdfs.rollCount = 0
HDFS上的文件达到128M时生成一个文件
a1.sinks.k1.hdfs.rollSize = 134217728
HDFS上的文件达到60秒生成一个文件
a1.sinks.k1.hdfs.rollInterval = 60
a1.sinks.k1.channel=c1
a1.sources.s1.channels=c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=10000
a1.channels.c1.transactionCapacity=1000启动Flume
1
bin/flume-ng agent --conf /opt/flume/conf --conf-file /opt/flume/conf/kafka_to_flume.properties --name a1 -Dflume.root.logger
测试
向kafka的生产者写入任意内容。查看hdfs 的flume文件夹中中有没有生成相应文件。


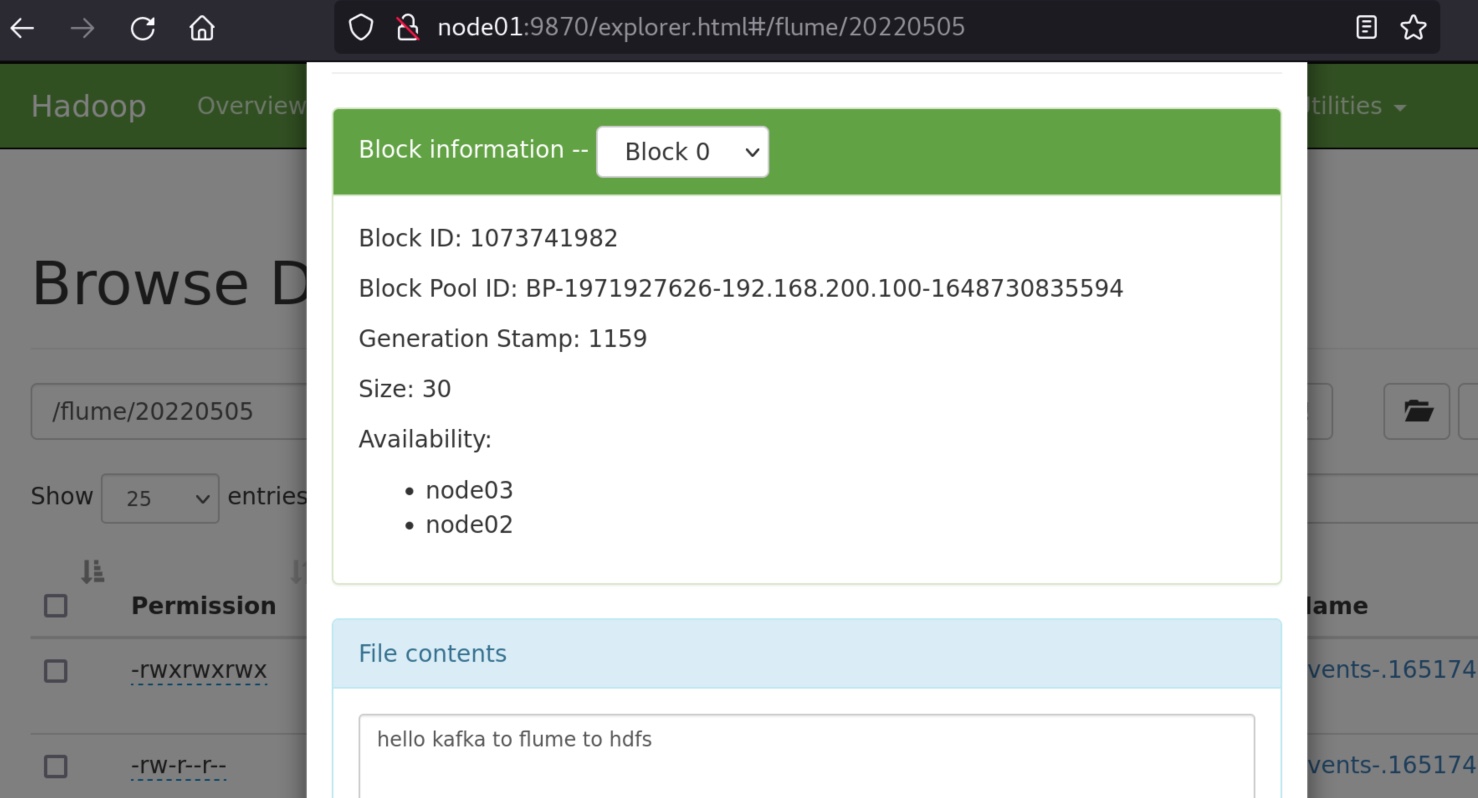
补充:可能遇到的报错。
启动 Flume 时,会看到如下内容:
Class path [contains](https://so.csdn.net/so/search?q=contains&spm=1001.2101.3001.7020) multiple SLF4J bindings.
启动 Flume 时,找到了多个 SLF4J bindings(绑定),SLF4J 如同 log4j 一样,是打印日志的工具。
Found binding in...,在加载 jar 包时,找到了两个本版本不同的 SLF4J,导致了程序出错。
错误原因:
启动 Flume 时,在 /flume-1.9.0 目录下找到了 SLF4J,又在 /hadoop-2.7.7 目录下找到了 SLF4J。
由于 Flume 是 Hadoop 生态的一个日志采集工具,所以当启动 Flume 后,Flume 就会去加载 Hadoop_HOME 中的类,所以启动时可以看到加载了许多 Hadoop 下的包,当 SLF4J 时,在 Flume 自己目录下也有 SLF4J,就导致了类的冲突,而且版本不一样。
解决办法:
在提示中的路径下,对 Flume 的 SLF4J 删除或重命名。
比如:将该 jar 包重命名为 .jar.bak 结尾的文件,bak 表示 backup(备份)。我这里的Hadoop和hive、flume三个 里面都有log4j,我决定仅保留Hadoop的吧。
1 | cd /opt/flume/lib |