简介
kafka简单介绍
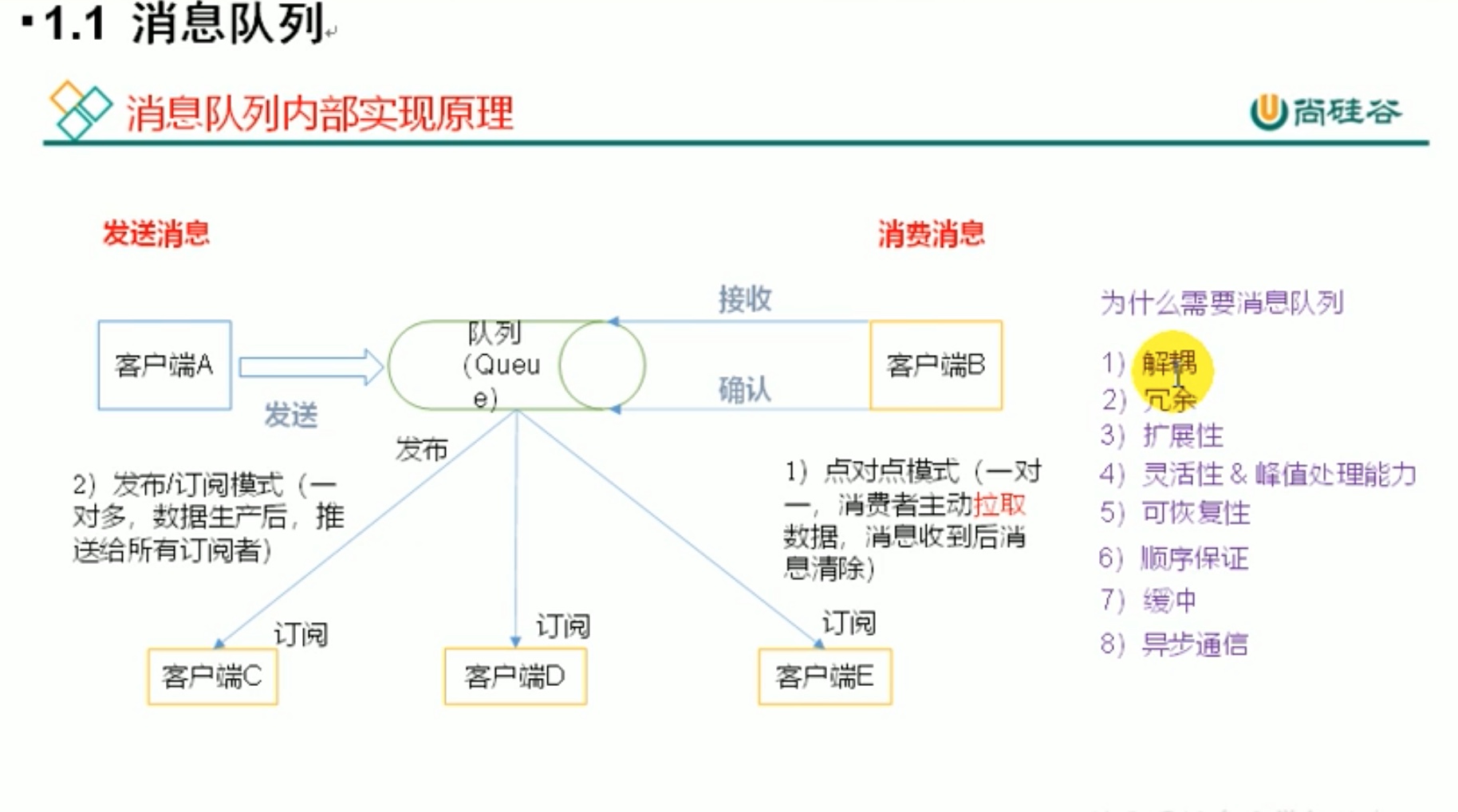
消息队列 的 发布订阅模式可以避免 拉取数据后就清除。
以上部分名词解释:
1、解耦:生成、消费、数据存储、三者分解开,耦合性低,拓展性就强。
2、冗余:数据存储有备份。像交叉存放等等。
3、拓展性:这样的分布式集群,可以自由加机器,多加机器可以提高负载能力。
4、峰值处理能力:可以均衡速率。不是由生产者一股脑推送给消费者,而是数据存放在这里,由消费者自由取数据,消费者高峰数据得到消峰处理。
5、可恢复性:一个服务器宕机了,别的有备份的服务器接替工作,但是此时宕机服务器又恢复了,数据又恢复在此服务器进行。
6、顺序保证:订单数据放入同一个分区中,可以保证顺序,因为是队列。但是订单数据有时候放1分区有时候放2分区就无法保证顺序。如何保证订单数据都往一个分区里送,就涉及到 hash 算法了。
8、异步通信:发送完,即可进行下一步操作;而同步通信则是发送完消息还要等接收方接收完毕才能下一步操作。
Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。broker 就是代理服务器agent的意思,也就是服务器server。
无论是kafka集群,还是consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
卡夫卡架构
名词:
replication: 拷贝(备份);
broker=agent=server,一个broker可以容纳多个topic;
topic: 消息管理工具,实际是一个队列;
consumer group: 消费者组:旨在增加消费能力,每个成员读一部分数据,大家凑一起读完即可,因为组内数据共享。这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。
leader: 主broker;producer 和 consumer 读与写都只针对 leader- broker。
follower: 从broker;仅仅作为leader的备份,当leader宕机follower顶上。
zookeeper: 之前spark配置时学过,这里zookeeper存放了集群信息、消息队列信息、消费者消费到的位置( offset偏移量 )。
Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序;
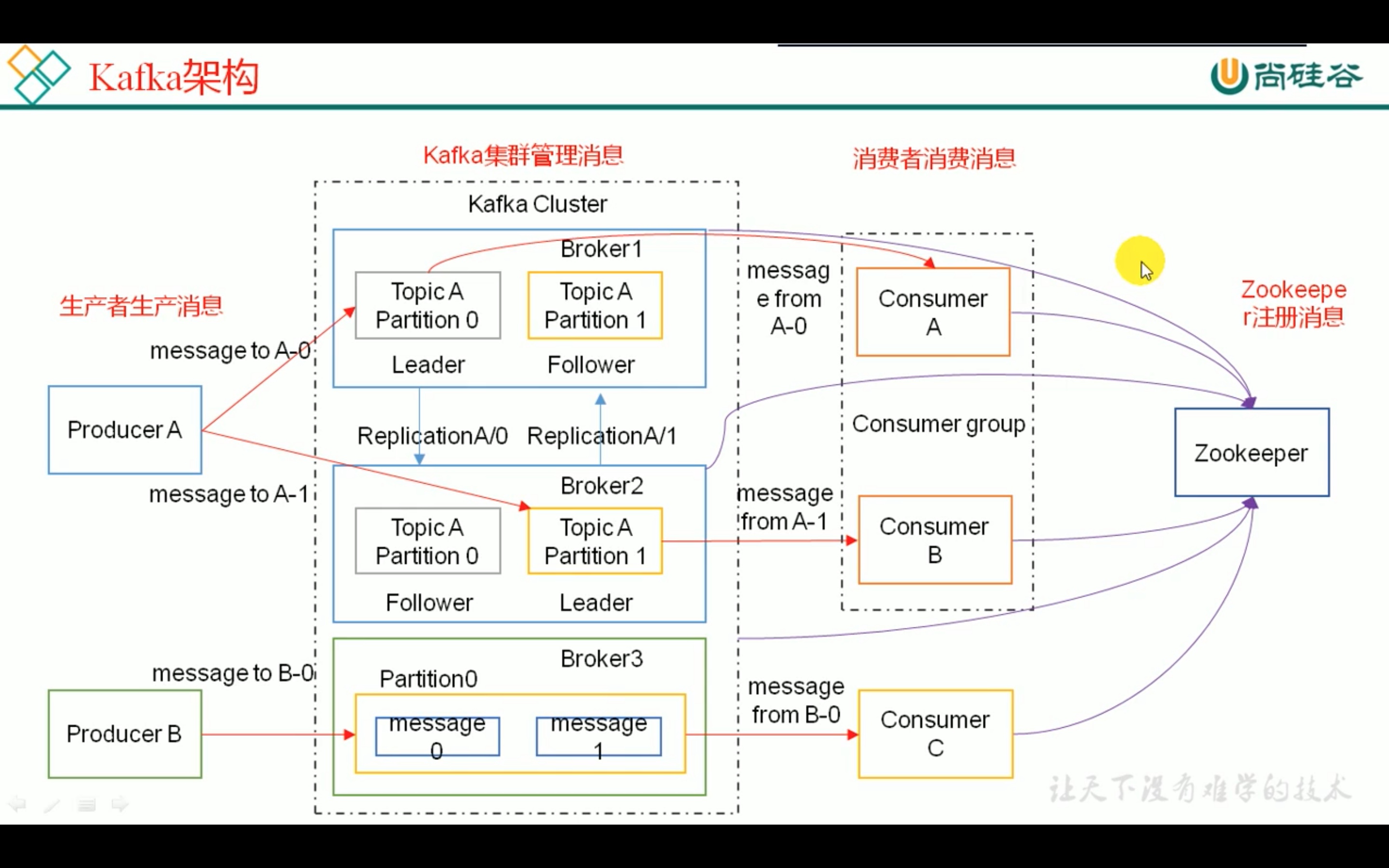
想要增加kafka的消费能力,增加partition数量,再增加消费者 是一个办法。
想要 保持 某一个业务的消息的顺序,要把此业务的消息都往一个partition中发送,(当然topic 不一定只有一个分区,这个两码事),一个partition中一定是有序队列,如果消息进入了两个partition ,消费者不能保证先读了哪一个partition,自然顺序就无法保证。
leader和follower都是副本,在replication-factor 参数设置时 设置2 就是一个leader一个follower的模式。
kafka集群部署
我这里是 安装配置好了 Hadoop、hive、spark、 zookeeper 之后再配置kafka 的,有的内容就不再重复了。
Kafka安装依赖Scala、ZooKeeper,所以需要先安装Scala与ZooKeeper。我们已经安装配置好了zookeeper ,所以先从安装scala 语言开始。
查询想要下载的kafka对应的scala版本号
https://kafka.apache.org/downloads.html
例如 kafka_2.13-3.1.0.tgz 中 2.13 对应的就是scala的版本号,3.10是kafka 的版本号。
下载Scala 2.13
https://www.scala-lang.org/download/all.html
下载 kafka- manager(管理工具,以后有需要再用)
https://github.com/yahoo/CMAK/releases
安装scala
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| # node01中开始
cd /opt
mkdir scala
# 把下载好的Scala文件 放进scale文件夹解压。
tar -zxvf scala-2.13.7.tgz
# 添加环境变量
vim /etc/profile
--------------------------------------------------------------
export SCALA_HOME=/opt/scala/scala-2.13.7
export PATH=$SCALA_HOME/bin # 这个是添加在最后的 :分隔。
source /etc/profile
--------------------------------------------------------------
# 分发配置好的文件
scp -r scala node02:/opt/
scp -r scala node03:/opt/
# 在node02\node03机器上配置环境变量
vim /etc/profile
--------------------------------------------------------------
export SCALA_HOME=/opt/scala/scala-2.13.7
export PATH=$SCALA_HOME/bin
source /etc/profile
--------------------------------------------------------------
|
安装kafka
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| # node01中开始
mkdir kafka
# 解压
tar -zxvf kafka_2.13-3.1.0.tgz
# 添加环境变量
vim /opt/profile
--------------------------------------------------------------
export KAFKA_HOME=/opt/kafka/kafka_2.13-3.1.0
export PATH=$KAFKA_HOME/bin
--------------------------------------------------------------
# 新建logs文件夹
mkdir /opt/kafka/kafka_2.13-3.1.0/logs
# 编辑配置文件
vim /opt/kafka/kafka_2.13-3.1.0/config/server.properties
--------------------------------------------------------------
//在配置集群的时候,必须设置,不然以后的操作会报找不到leader的错误
listeners = PLAINTEXT://node3.cn:9092
broker.id=1
//端口暂时不变
port=9092
//hostname修改为本机的主机名
host.name=node01
//可选配置项,将日志输出到指定的位置
log.dirs=/opt/kafka/kafka_2.13-3.1.0/logs
//必须配置自己的zookeeper
zookeeper.connect=node01:2181,node02:2181,node03:2181
--------------------------------------------------------------
# 分发配置好的文件
scp -r /opt/kafka node02:/opt
scp -r /opt/kafka node03:/opt
# 在node02\node03机器上修改信息、配置环境变量。
vim /opt/profile
--------------------------------------------------------------
export KAFKA_HOME=/opt/kafka/kafka_2.13-3.1.0
export PATH=$KAFKA_HOME/bin
--------------------------------------------------------------
vim /opt/kafka/kafka_2.13-3.1.0/config/server.properties
--------------------------------------------------------------
//node02:
broker.id=2
listeners=PLAINTEXT://node02:9092
hostname=node02
//node03:
broker.id=3
listeners=PLAINTEXT://node03:9092
hostname=node03
--------------------------------------------------------------
|
检查是否安装成功
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| # 启动zookeeper集群,在每台机器上开启。
/opt/zookeeper/bin/zkServer.sh start
# 查看各个节点状态,在每台机器上查看。
/opt/zookeeper/bin/zkServer.sh status
# 集群各节点 启动 kafka 服务。
/opt/kafka/kafka_2.13-3.1.0/bin/kafka-server-start.sh -daemon /opt/kafka/kafka_2.13-3.1.0/config/server.properties
# 各个节点 jps 都可见 kafka 进程启动了。
jps
# 测试topic创建和删除
# 补充:(2.2 及更高版本)的 Kafka 不再需要 ZooKeeper 连接字符串,即 --zookeeper localhost:2181。使用 Kafka Broker的 --bootstrap-server localhost:9092来替代- -zookeeper localhost:2181。
kafka-topics.sh --bootstrap-server node01:9092 --create --topic test-topic --partitions 3 --replication-factor 2
# 补充:也可以用多个机器。
kafka-topics.sh --bootstrap-server node01:9092,node02:9092,node03:9092 --create --topic test-topic --partitions 3 --replication-factor 2
# 查看topic列表
kafka-topics.sh --bootstrap-server node01:9092 --list
# 验证创建的 topic
kafka-topics.sh --describe --topic test-topic --bootstrap-server node01:9092
|

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
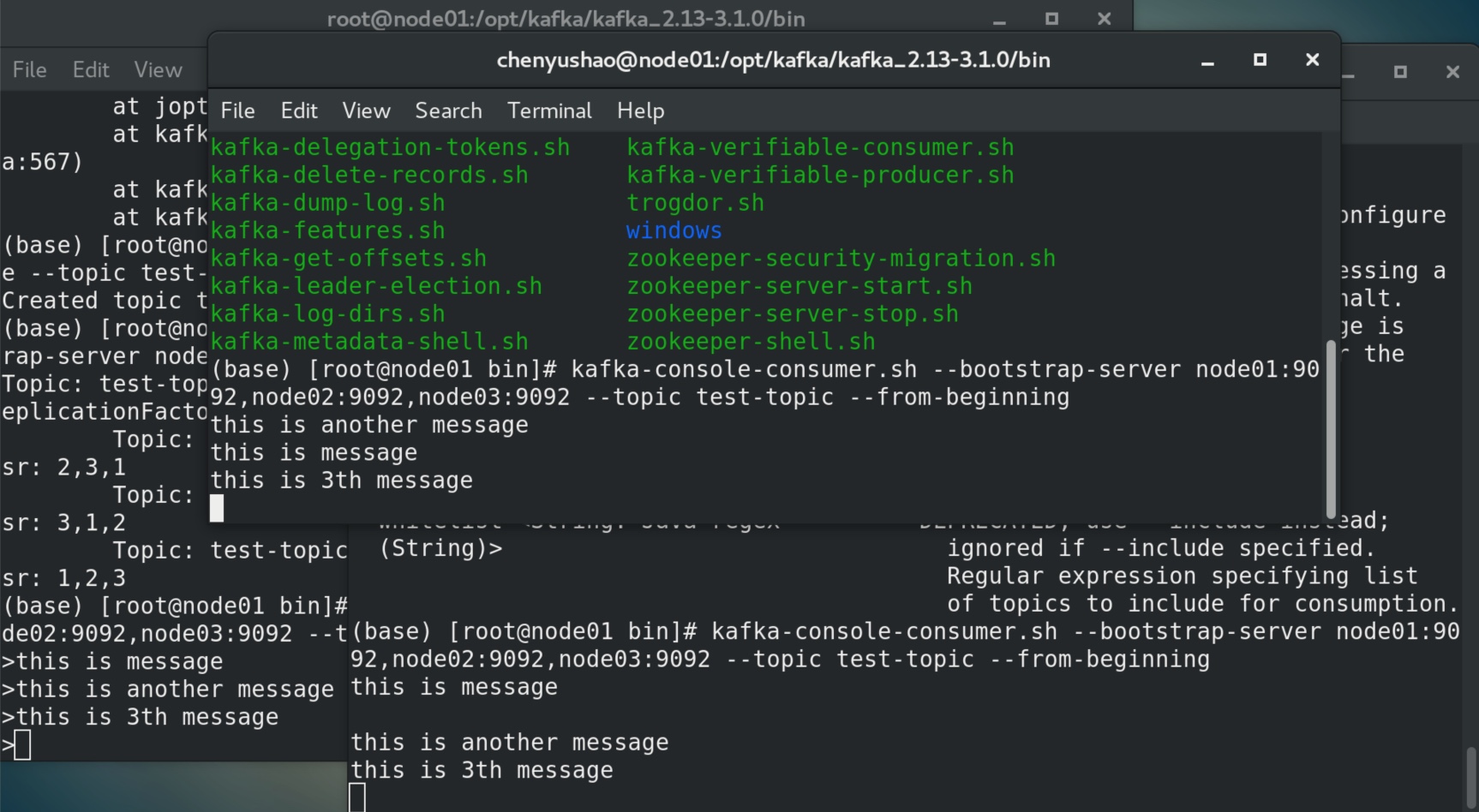
| # 测试消息发送与消费
# Kafka提供了一个命令行的工具,可以从输入文件或者命令行中读取消息并发送给Kafka集群。每一行是一条消息。
# 开一个终端作为producer: (然后在控制台输入几条消息到服务器)ctrl+c 退出生产者。
kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic test-topic
>this is message
>this is another message
>
# 开一个终端作为consumer: (producer输入完消息一回车,consumer这就显示出那边的消息,一行一行显示。)ctrl+c 退出消费者。
kafka-console-consumer.sh --bootstrap-server node01:9092,node02:9092,node03:9092 --topic test-topic --from-beginning
this is message
this is another message
# 如果你有2台不同的终端上运行上述命令,那么当你在运行生产者时,两个消费者都能消费到生产者发送的消息,如下图:
|
1
2
3
4
5
6
| # 删除创建的topic。(删除topic后,消费者很快就停了,生产者不受影响。)
kafka-topics.sh --bootstrap-server node01:9092 --delete --topic test-topic
# Kafka——彻底删除Topic
# 彻底退出消费者、生产者,才能删除topic。
# 但是这样的删除是逻辑删除,实际文件还啊是存在,要物理删除,需要在配置文件中打开 delete.topic.enable=true .
|
1
2
3
4
5
6
| # 停止kafka(每台机器都运行一遍)
1、ctrl+c 退出生产者、消费者。
2、/opt/kafka/kafka_2.13-3.1.0/bin/kafka-server-stop.sh
# 停止zookeeper(每台机器都运行一遍)
/opt/zookeeper/bin/zkServer.sh stop
|
kafka 粗略讲解
在3个机器组成的kafka集群中,开启了一个3分区2备份的topic test-topic。
kafka-topics.sh --bootstrap-server node01:9092 --create --topic test-topic --partitions 3 --replication-factor 2
此时node01在kafka的自定义logs 文件夹上层文件夹 tree logs 可见2个分区: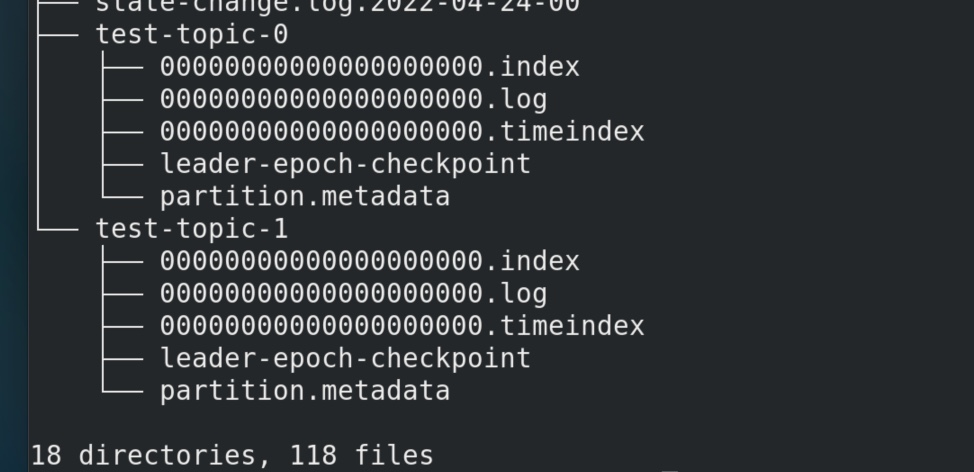
补充:如果改动一下,改成2个机器组成的kafka集群,开3个分区2个备份的topic,logs中会有3个分区。理由其实很简单 ,一共要6个,均分到两台机器一个上面就要放3个,logs 中会是如下情况: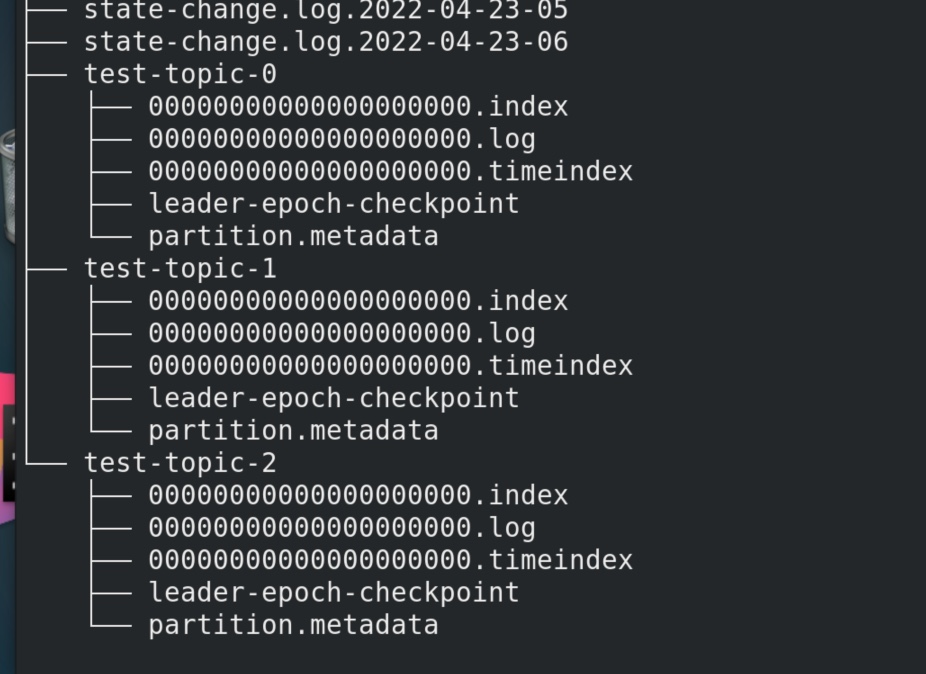
node01的logs内是test- topic-0、test- topic-1;
node02的logs内是test- topic-1、test- topic-2;
node03的logs内是test- topic-0、test- topic-2;
查看 topic 的分配情况:
kafka-topics.sh --bootstrap-server node01:9092 --describe --topic test-topic

解释一下上图:
partition0 的leader副本 放在 3号机器(配置文件中定义了机器号);
partition0 的replicas副本 放在 1号机器;
partition1 的leader副本 放在 1号机器;
partition1 的replicas副本 放在 2号机器;
partition2 的leader副本 放在 2号机器;
partition2 的replicas副本 放在 3号机器;
前面说过,实际操作都是针对 leader副本进行。
Isr: 哪些机器正在同步此分区副本。
此时,我们突然kill掉node03机器的kafka进程,再describe 一下此topic,可见:

isr 正在同步的机器里看不见 3号机器了,原本partition0 的leader副本在3好机器上,partition0的 replicas 副本在 1号机器上。3号机器一出问题,备用的副本马上转正,1号机器上的partition0 replicas副本转为leader副本投入使用。1号机器上运行着 分区0和分区1 两个leader副本了。
如果node03的kafka服务 又重新恢复,describe 里面可见 isr 同步中3号机器又回来了,别的机器宕机3号机器又会顶上。

此时虽然3号机器回来了,但是partition0和partition1 的leader 副本都集中到了 1号机器中,这样的集中并不是好事,此时我们可以选择手动让分配再平衡一些,如下操作。
1
2
3
| # 该 bin/kafka-preferred-replica-election.sh 命令行工具已被弃用。已由代替 bin/kafka-leader-election.sh
# 对 指定topic 的0分区 重新选举一个最优 的leader 副本存放位置。
kafka-leader-election.sh --bootstrap-server node01:9092 --topic test-topic --election-type preferred --partition 0
|

此时我们再 查看topic 分配情况 kafka-topics.sh --bootstrap-server node01:9092 --describe --topic test-topic,可见partition0 的leader副本 回到了3号机器上 :

1
2
3
4
5
6
7
| # 开一个终端作为producer: (然后在控制台输入几条消息到服务器)ctrl+c 退出生产者。
kafka-console-producer.sh --broker-list node01:9092 --topic test-topic
>I love kafka !
# 开一个终端作为consumer: (producer输入完消息一回车,consumer这就显示出那边的消息,一行一行显示。)ctrl+c 退出消费者,--from-beginning是从头读取的意思。
kafka-console-consumer.sh --bootstrap-server node01:9092 --topic test-topic --from-beginning
|
此时我们从3台机器的logs 文件夹中找 消息到底存放在哪里。我的这个消息出现在 node01的logs的 test- topic-0 中,实际上,这个消息发送到了哪个partition 目前来看还是随机的。