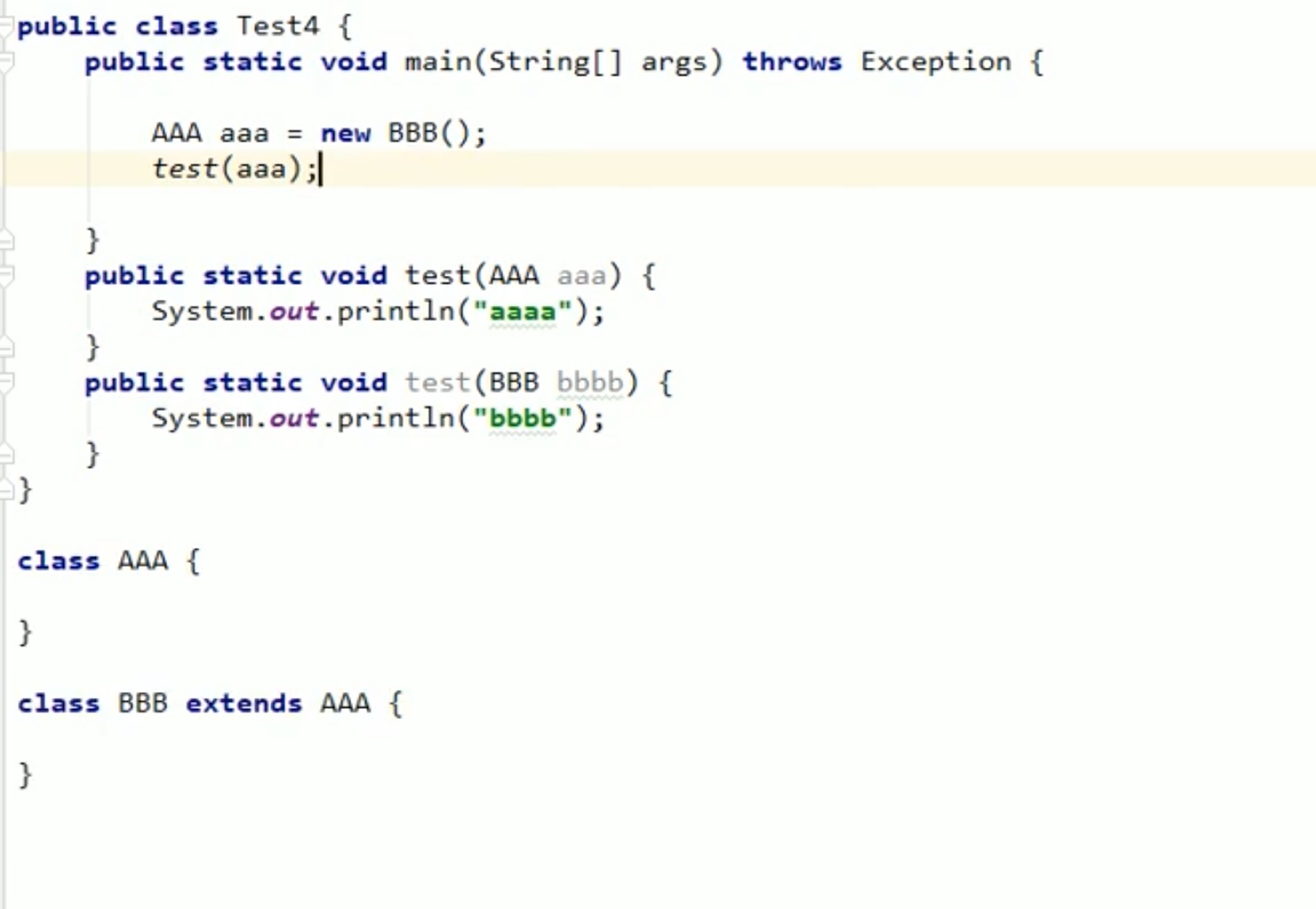
# 同步发送 数据 defsync_producer(self,data_list): for data in data_list: future = self.producer.send(self.topic,data) record_metadata = future.get(timeout=10) partition = record_metadata.partition offset = record_metadata.offset print('save success,partition:{},offset:{}'.format(partition,offset))
# 异步发送数据 defasyn_producer(self,data_list): for data in data_list: self.producer.send(self.topic,data) self.producer.flush() # 批量提交,触发真实_send()。多线程flush的话,一个flush在阻塞状态,不影响别的线程提交。
# 异步发送数据 + 用回调函数 调用指定方法。 defasyn_producer_callback(self,data_list): for data in data_list: self.producer.send(self.topic,data).\ add_callback(self.send_ok).\ add_errback(self.send_no_ok) self.producer.flush()
# this mathod must have args! otherwise the mathod no run. # 被回调函数调用的方法一定要有参数,此参数就是返回的recordmetadata类型数据,可以直接看partition和offset 等信息。此参数相当于同步发送时用get()后的返回值,可以看数据到底是发送到了哪个分区,偏移量是多少。 defsend_ok(self,record_meta): """异步发送成功回调函数""" print('asyn_callback save sucess') print(type(record_meta),'\n', 'partition:{},offset:{}'.format(record_meta.partition,record_meta.offset))
defsend_no_ok(self, *args, **kwargs): """异步发送错误回调函数""" print('asyn_callback save error')
defsimple_consumer(self): self.consumer.subscribe(self.topics) for message in self.consumer: print('consumer_id={}-->receive,key:{},value:{}'.format(self.consumer_id,message.key,message.value))
defconsumer_read_offset(self): c_offset = [(tp.partition,self.consumer.committed(tp)) for tp in self.tps] # return None if there was no prior commit. print('\n',c_offset) # [(0, 22), (1, 24), (2, 20)] return c_offset
defcalculation_allowance(self): sum_of_p_offset = sum([x[1] for x in self.producer_write_offset()]) sum_of_c_offset = sum([x[1] if x[1]!=Noneelse0for x in self.consumer_read_offset() ]) allowance = sum_of_p_offset-sum_of_c_offset print('\n kafka accumulate space except_group_id {} is: \n{}'.format(self.group_id,allowance)) return allowance
if __name__=='__main__': v = view_accumulation(bootstrap_servers="node01:9092,node02:9092,node03:9092", topic='consumer_test', group_id="consumer_group_multifunction_test")
defget_sensor(self, name): """ Get the sensor with the given name if it exists Arguments: name (str): The name of the sensor Returns: Sensor: The sensor or None if no such sensor exists """ ifnot name: raise ValueError('name must be non-empty') return self._sensors.get(name, None)
defsensor(self, name, config=None, inactive_sensor_expiration_time_seconds=sys.maxsize, parents=None): """ Get or create a sensor with the given unique name and zero or more parent sensors. All parent sensors will receive every value recorded with this sensor. Arguments: name (str): The name of the sensor config (MetricConfig, optional): A default configuration to use for this sensor for metrics that don't have their own config inactive_sensor_expiration_time_seconds (int, optional): If no value if recorded on the Sensor for this duration of time, it is eligible for removal parents (list of Sensor): The parent sensors Returns: Sensor: The sensor that is created """ sensor = self.get_sensor(name) if sensor: return sensor
with self._lock: sensor = self.get_sensor(name) ifnot sensor: # 点进去可以看sensor.py 模块的内容。 sensor = Sensor(self, name, parents, config or self.config, inactive_sensor_expiration_time_seconds) self._sensors[name] = sensor if parents: for parent in parents: children = self._children_sensors.get(parent) ifnot children: children = [] self._children_sensors[parent] = children children.append(sensor) logger.debug('Added sensor with name %s', name) return sensor
defremove_sensor(self, name): """ Remove a sensor (if it exists), associated metrics and its children. Arguments: name (str): The name of the sensor to be removed """ sensor = self._sensors.get(name) if sensor: child_sensors = None with sensor._lock: with self._lock: val = self._sensors.pop(name, None) if val and val == sensor: for metric in sensor.metrics: self.remove_metric(metric.metric_name) logger.debug('Removed sensor with name %s', name) child_sensors = self._children_sensors.pop(sensor, None) if child_sensors: for child_sensor in child_sensors: self.remove_sensor(child_sensor.name)
defadd_metric(self, metric_name, measurable, config=None): """ Add a metric to monitor an object that implements measurable. This metric won't be associated with any sensor. This is a way to expose existing values as metrics. Arguments: metricName (MetricName): The name of the metric measurable (AbstractMeasurable): The measurable that will be measured by this metric config (MetricConfig, optional): The configuration to use when measuring this measurable """ # NOTE there was a lock here, but i don't think it's needed metric = KafkaMetric(metric_name, measurable, config or self.config) self.register_metric(metric)
defremove_metric(self, metric_name): """ Remove a metric if it exists and return it. Return None otherwise. If a metric is removed, `metric_removal` will be invoked for each reporter. Arguments: metric_name (MetricName): The name of the metric Returns: KafkaMetric: the removed `KafkaMetric` or None if no such metric exists """ with self._lock: metric = self._metrics.pop(metric_name, None) if metric: for reporter in self._reporters: reporter.metric_removal(metric) return metric
defadd_reporter(self, reporter): """Add a MetricReporter""" with self._lock: reporter.init(list(self.metrics.values())) self._reporters.append(reporter)
defregister_metric(self, metric): with self._lock: if metric.metric_name in self.metrics: raise ValueError('A metric named "%s" already exists, cannot' ' register another one.' % (metric.metric_name,)) self.metrics[metric.metric_name] = metric for reporter in self._reporters: reporter.metric_change(metric)
classExpireSensorTask(object): """ This iterates over every Sensor and triggers a remove_sensor if it has expired. Package private for testing """ @staticmethod defrun(metrics): items = list(metrics._sensors.items()) for name, sensor in items: # remove_sensor also locks the sensor object. This is fine # because synchronized is reentrant. There is however a minor # race condition here. Assume we have a parent sensor P and # child sensor C. Calling record on C would cause a record on # P as well. So expiration time for P == expiration time for C. # If the record on P happens via C just after P is removed, # that will cause C to also get removed. Since the expiration # time is typically high it is not expected to be a significant # concern and thus not necessary to optimize with sensor._lock: if sensor.has_expired(): logger.debug('Removing expired sensor %s', name) metrics.remove_sensor(name)
defclose(self): """Close this metrics repository.""" for reporter in self._reporters: reporter.close()
defappend(self, tp, timestamp_ms, key, value, headers, max_time_to_block_ms, estimated_size=0): """Add a record to the accumulator, return the append result. The append result will contain the future metadata, and flag for whether the appended batch is full or a new batch is created Arguments: tp (TopicPartition): The topic/partition to which this record is being sent timestamp_ms (int): The timestamp of the record (epoch ms) key (bytes): The key for the record value (bytes): The value for the record headers (List[Tuple[str, bytes]]): The header fields for the record max_time_to_block_ms (int): The maximum time in milliseconds to block for buffer memory to be available Returns: tuple: (future, batch_is_full, new_batch_created) """ assertisinstance(tp, TopicPartition), 'not TopicPartition' assertnot self._closed, 'RecordAccumulator is closed' # We keep track of the number of appending thread to make sure we do # not miss batches in abortIncompleteBatches(). self._appends_in_progress.increment() try: if tp notin self._tp_locks: with self._tp_locks[None]: if tp notin self._tp_locks: self._tp_locks[tp] = threading.Lock()
with self._tp_locks[tp]: # check if we have an in-progress batch dq = self._batches[tp] if dq: last = dq[-1] future = last.try_append(timestamp_ms, key, value, headers) if future isnotNone: batch_is_full = len(dq) > 1or last.records.is_full() return future, batch_is_full, False
size = max(self.config['batch_size'], estimated_size) log.debug("Allocating a new %d byte message buffer for %s", size, tp) # trace buf = self._free.allocate(size, max_time_to_block_ms) with self._tp_locks[tp]: # Need to check if producer is closed again after grabbing the # dequeue lock. assertnot self._closed, 'RecordAccumulator is closed'
if dq: last = dq[-1] future = last.try_append(timestamp_ms, key, value, headers) if future isnotNone: # Somebody else found us a batch, return the one we # waited for! Hopefully this doesn't happen often... self._free.deallocate(buf) batch_is_full = len(dq) > 1or last.records.is_full() return future, batch_is_full, False
records = MemoryRecordsBuilder( self.config['message_version'], self.config['compression_attrs'], self.config['batch_size'] )
defrun_once(self): """Run a single iteration of sending.""" while self._topics_to_add: self._client.add_topic(self._topics_to_add.pop())
# get the list of partitions with data ready to send result = self._accumulator.ready(self._metadata) ready_nodes, next_ready_check_delay, unknown_leaders_exist = result
# if there are any partitions whose leaders are not known yet, force # metadata update if unknown_leaders_exist: log.debug('Unknown leaders exist, requesting metadata update') self._metadata.request_update()
# remove any nodes we aren't ready to send to not_ready_timeout = float('inf') for node inlist(ready_nodes): ifnot self._client.is_ready(node): log.debug('Node %s not ready; delaying produce of accumulated batch', node) self._client.maybe_connect(node, wakeup=False) ready_nodes.remove(node) not_ready_timeout = min(not_ready_timeout, self._client.connection_delay(node))
# create produce requests batches_by_node = self._accumulator.drain( self._metadata, ready_nodes, self.config['max_request_size'])
if self.config['guarantee_message_order']: # Mute all the partitions drained for batch_list in six.itervalues(batches_by_node): for batch in batch_list: self._accumulator.muted.add(batch.topic_partition)
expired_batches = self._accumulator.abort_expired_batches( self.config['request_timeout_ms'], self._metadata) for expired_batch in expired_batches: self._sensors.record_errors(expired_batch.topic_partition.topic, expired_batch.record_count)
self._sensors.update_produce_request_metrics(batches_by_node) requests = self._create_produce_requests(batches_by_node) # If we have any nodes that are ready to send + have sendable data, # poll with 0 timeout so this can immediately loop and try sending more # data. Otherwise, the timeout is determined by nodes that have # partitions with data that isn't yet sendable (e.g. lingering, backing # off). Note that this specifically does not include nodes with # sendable data that aren't ready to send since they would cause busy # looping. poll_timeout_ms = min(next_ready_check_delay * 1000, not_ready_timeout) if ready_nodes: log.debug("Nodes with data ready to send: %s", ready_nodes) # trace log.debug("Created %d produce requests: %s", len(requests), requests) # trace poll_timeout_ms = 0
for node_id, request in six.iteritems(requests): batches = batches_by_node[node_id] log.debug('Sending Produce Request: %r', request) (self._client.send(node_id, request, wakeup=False) .add_callback( self._handle_produce_response, node_id, time.time(), batches) .add_errback( self._failed_produce, batches, node_id))
# if some partitions are already ready to be sent, the select time # would be 0; otherwise if some partition already has some data # accumulated but not ready yet, the select time will be the time # difference between now and its linger expiry time; otherwise the # select time will be the time difference between now and the # metadata expiry time self._client.poll(timeout_ms=poll_timeout_ms)

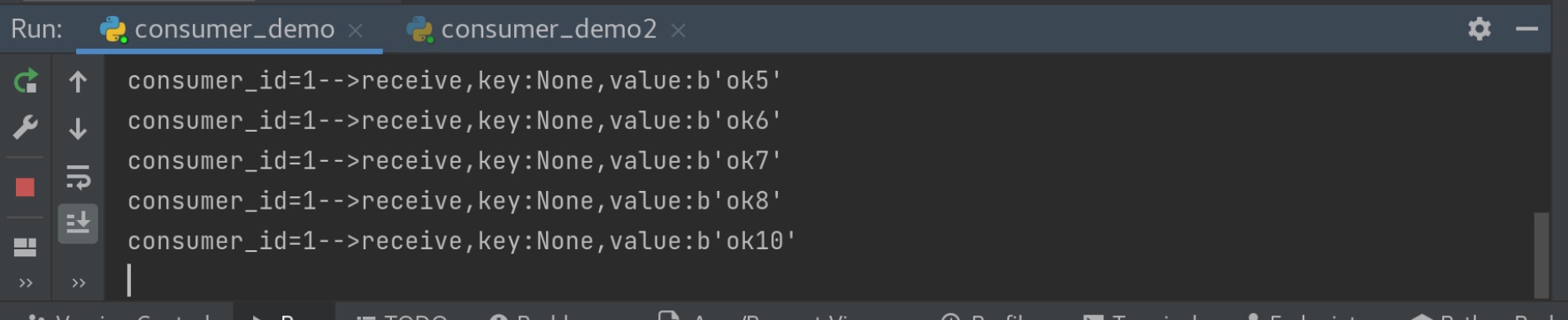




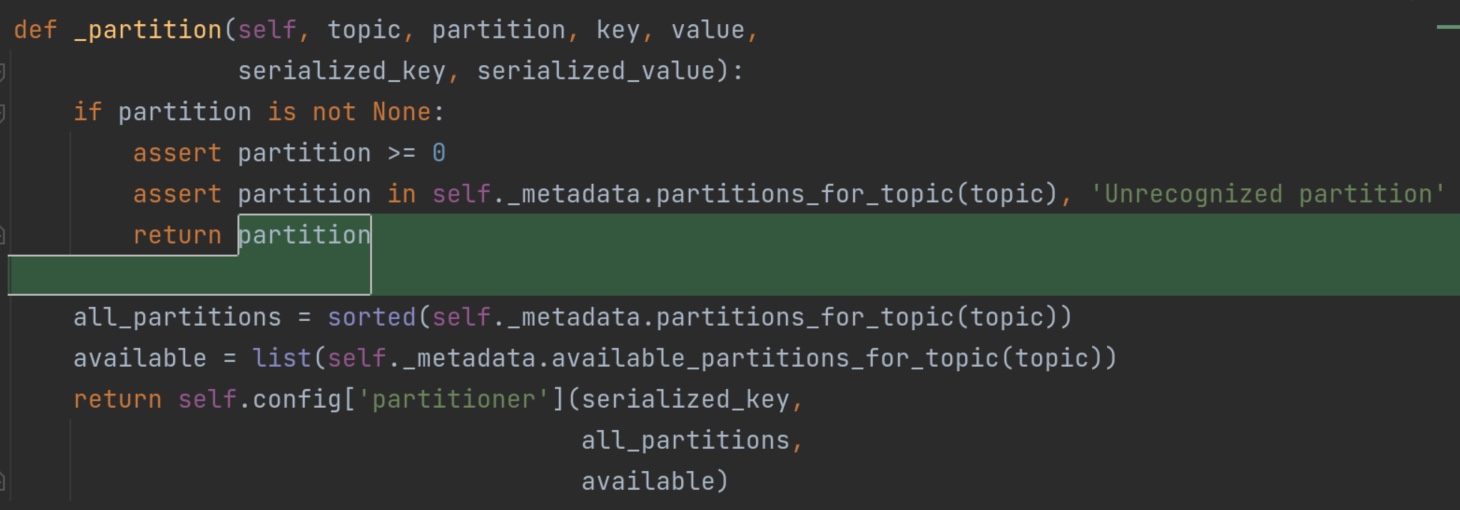
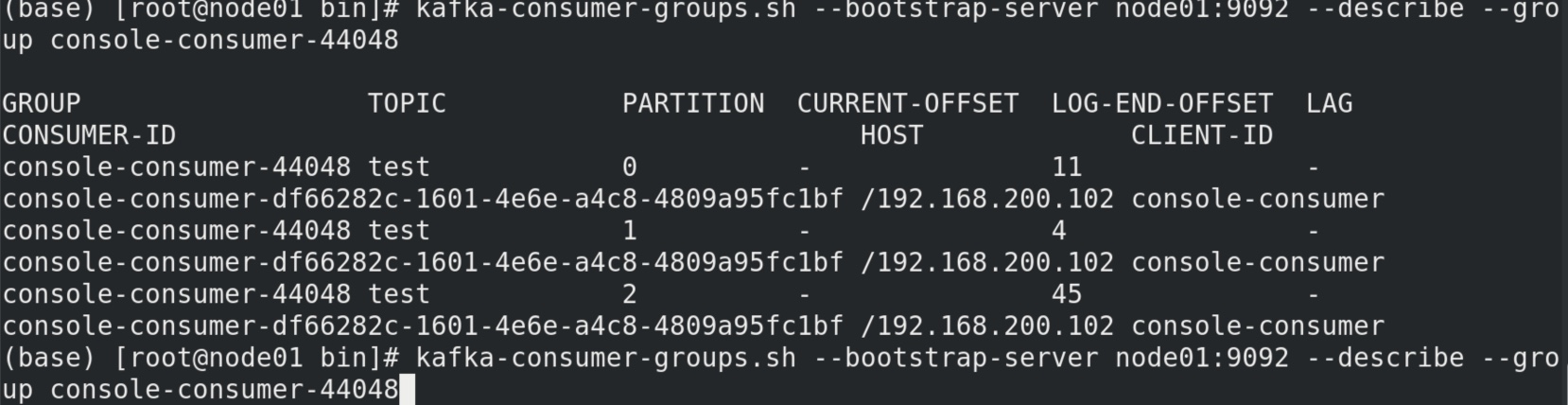
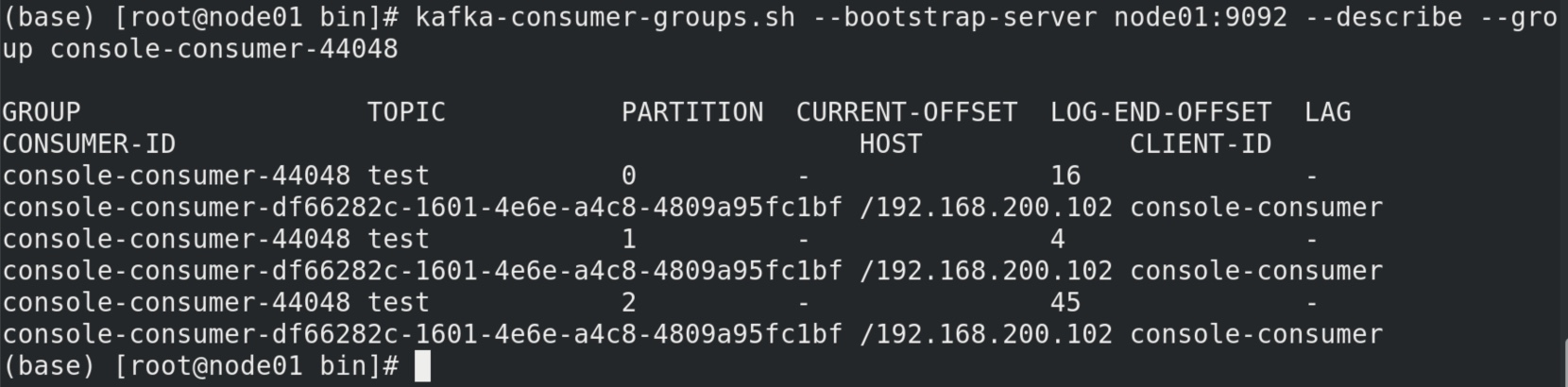
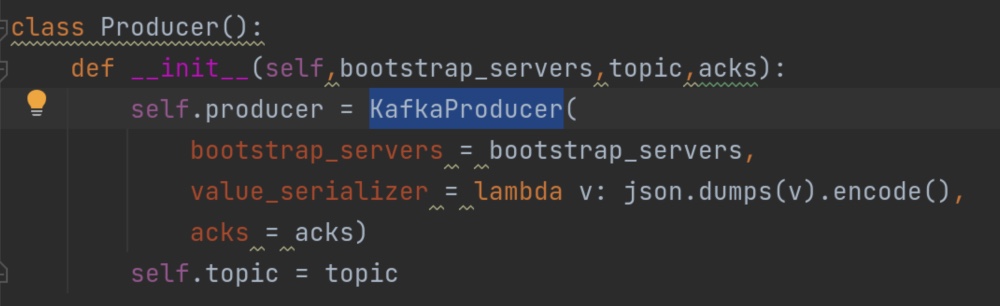
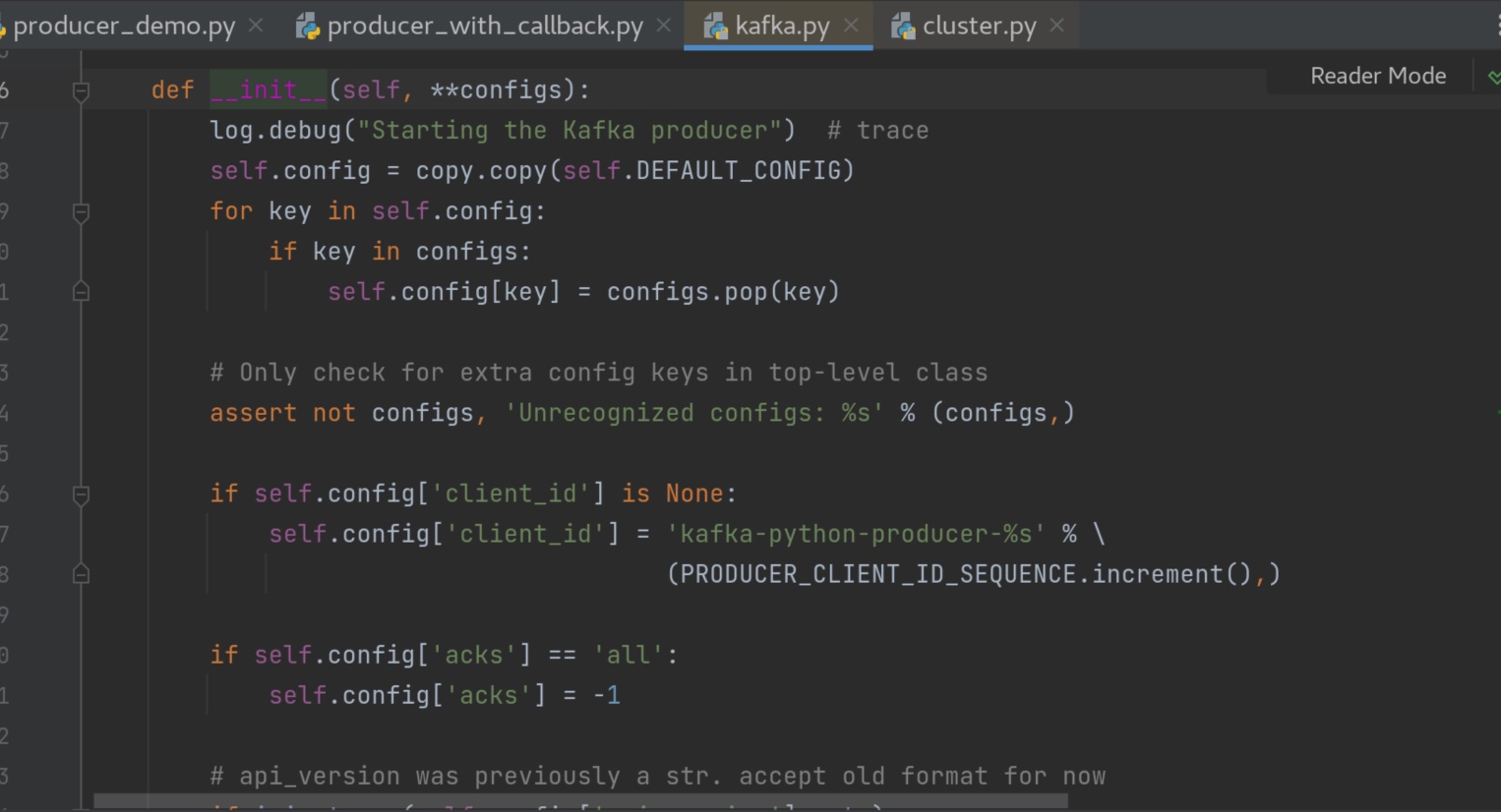
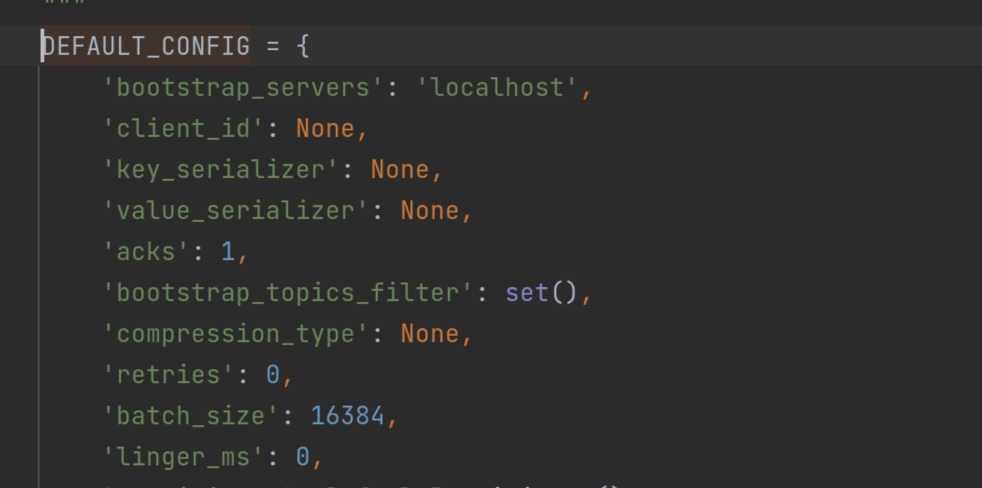
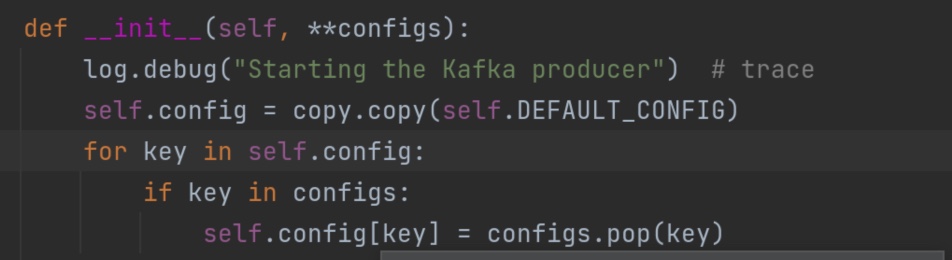


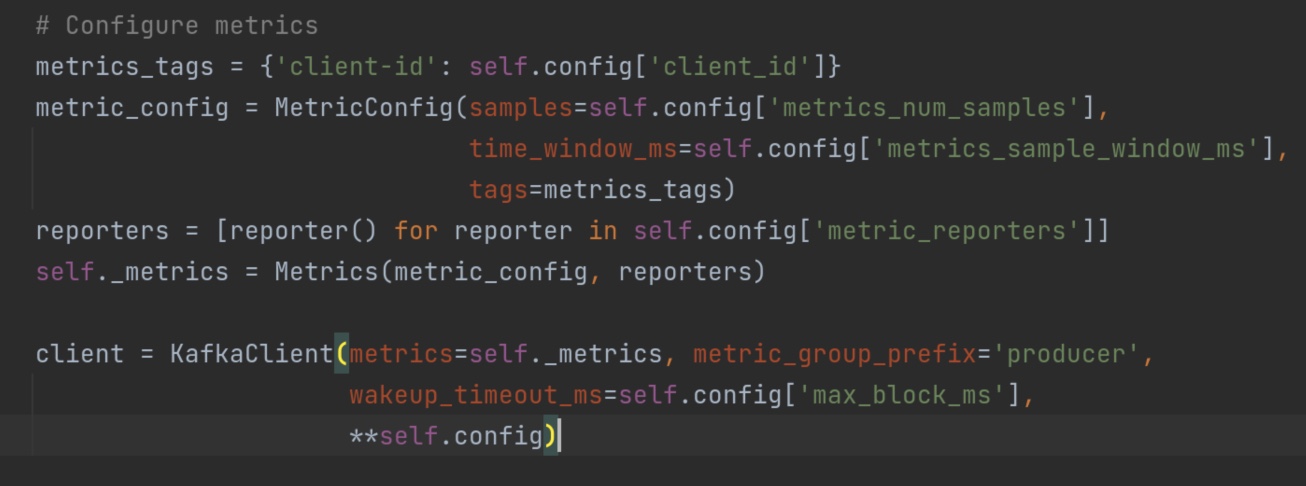

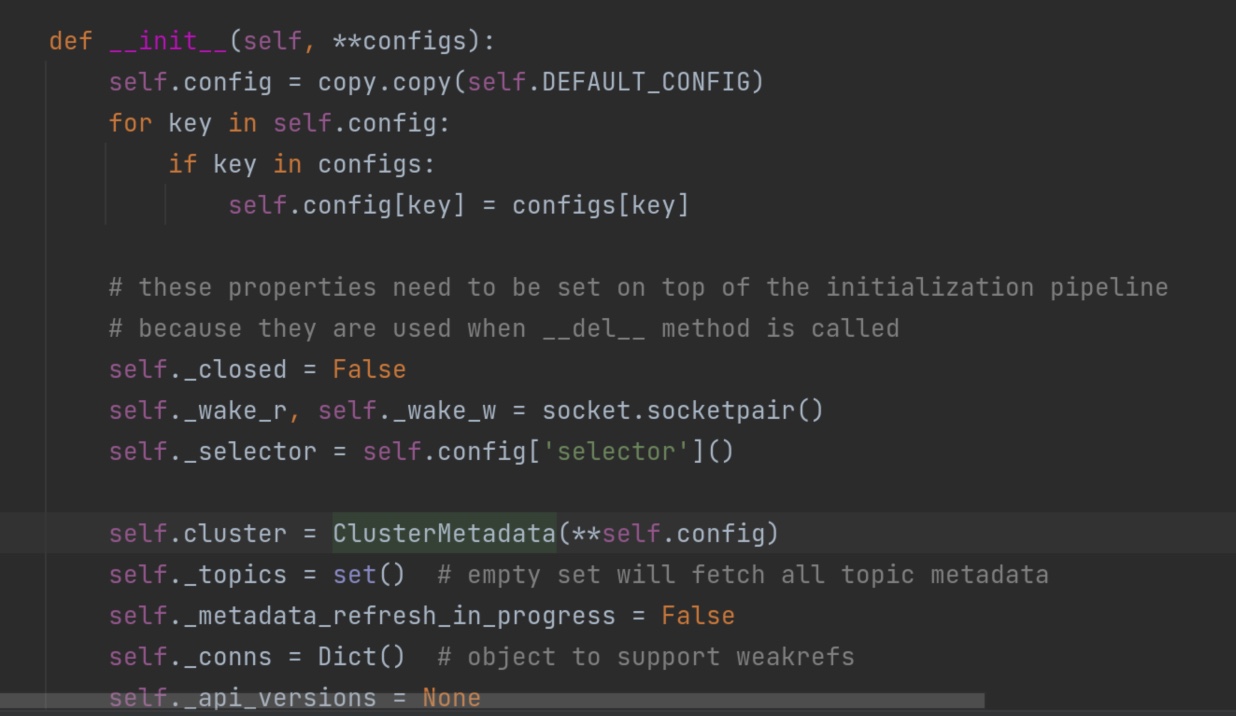

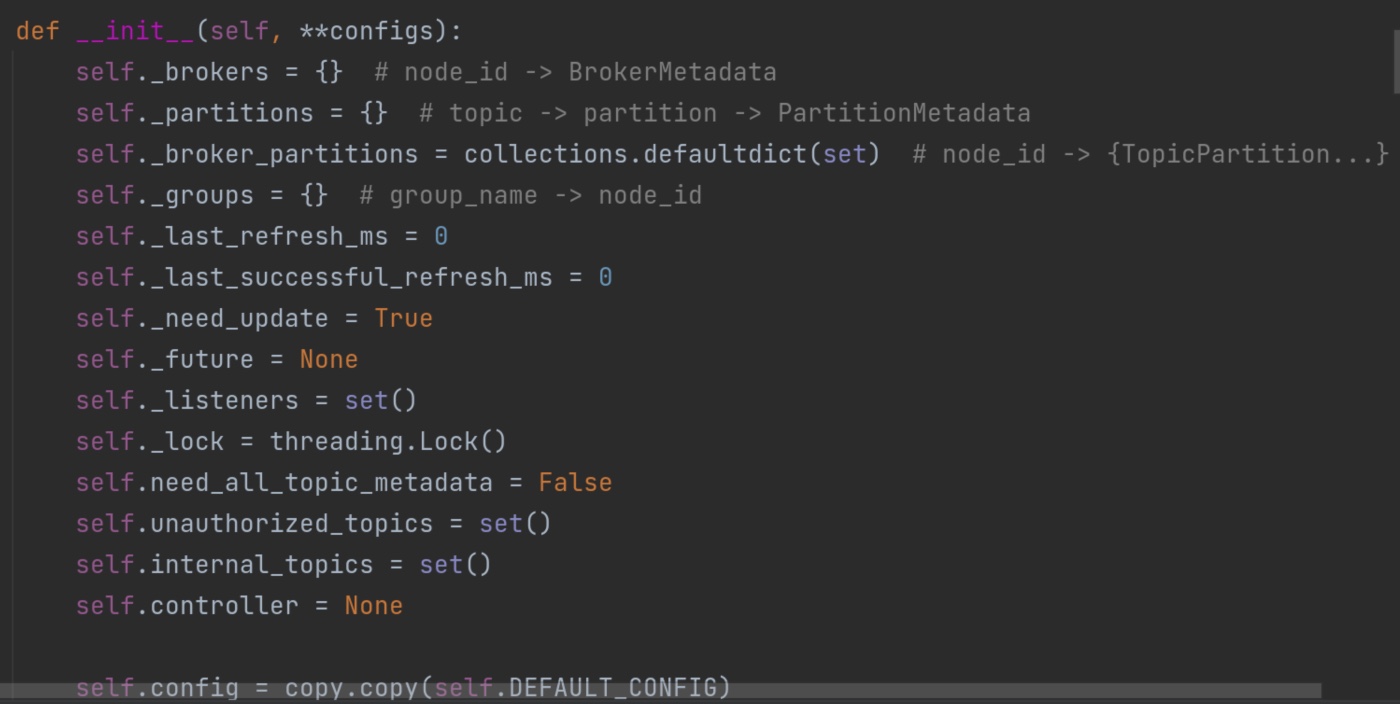
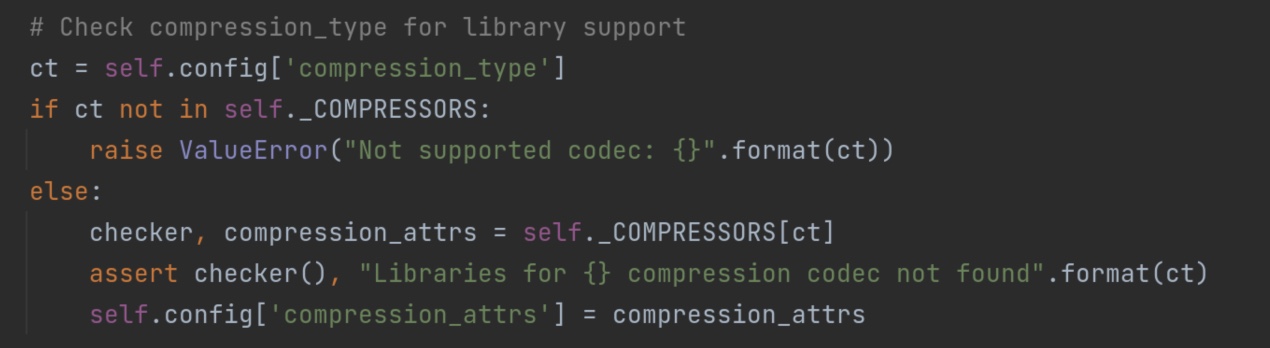
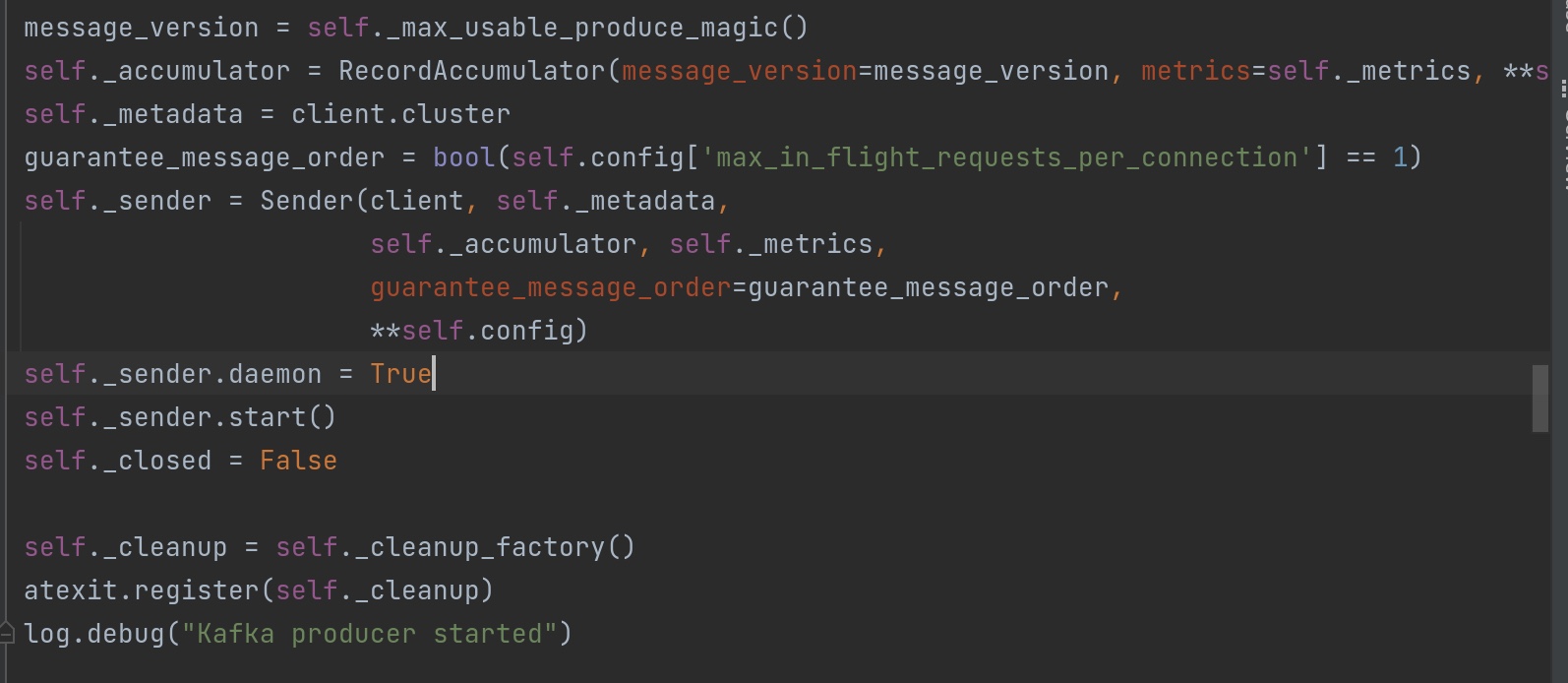
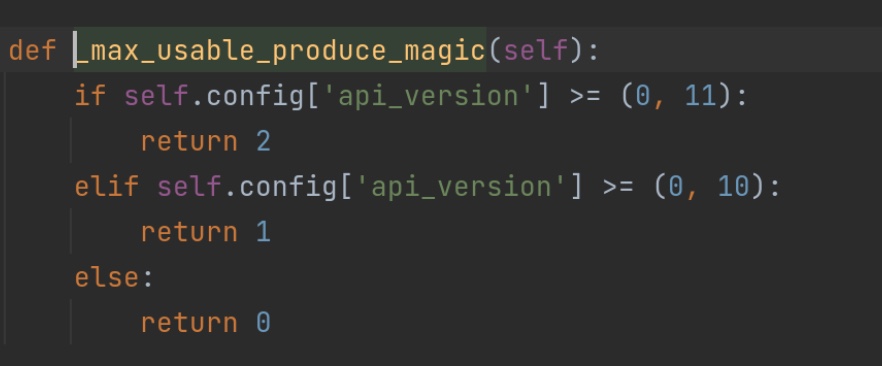
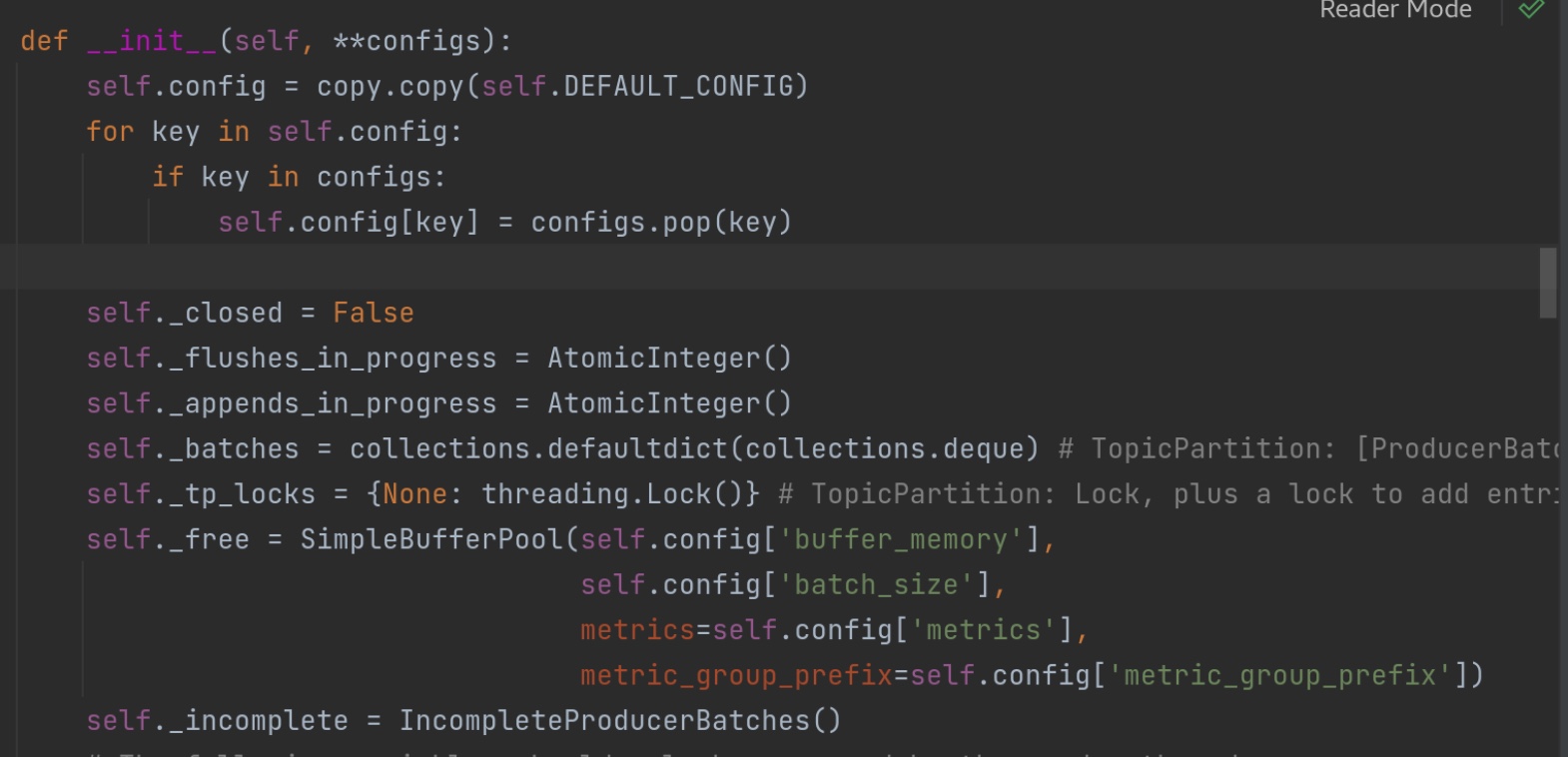
 这个recordaccumulator 累加器中有一个方法append()值得读一遍。它创造了一个双端队列dq。
这个recordaccumulator 累加器中有一个方法append()值得读一遍。它创造了一个双端队列dq。