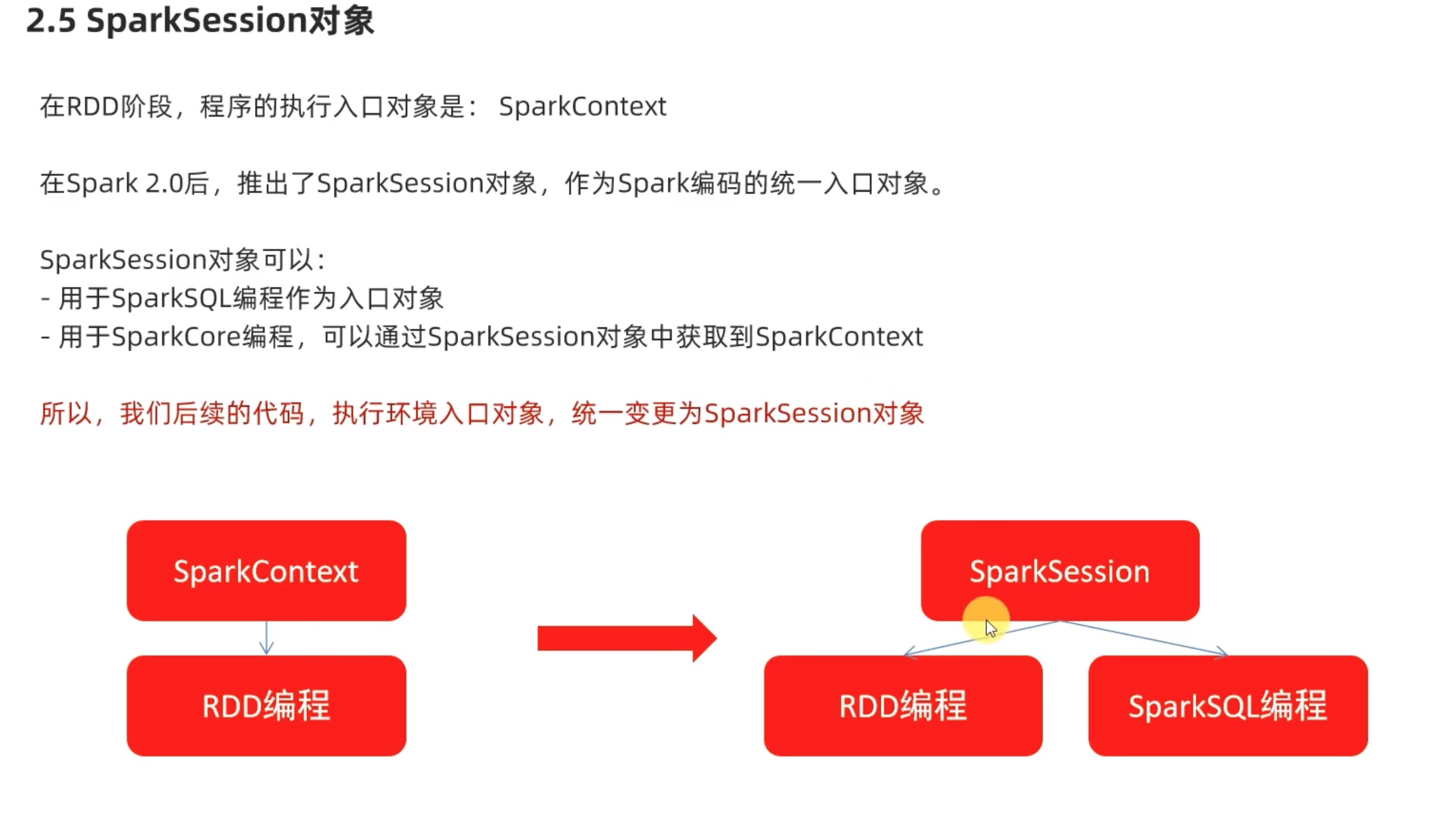
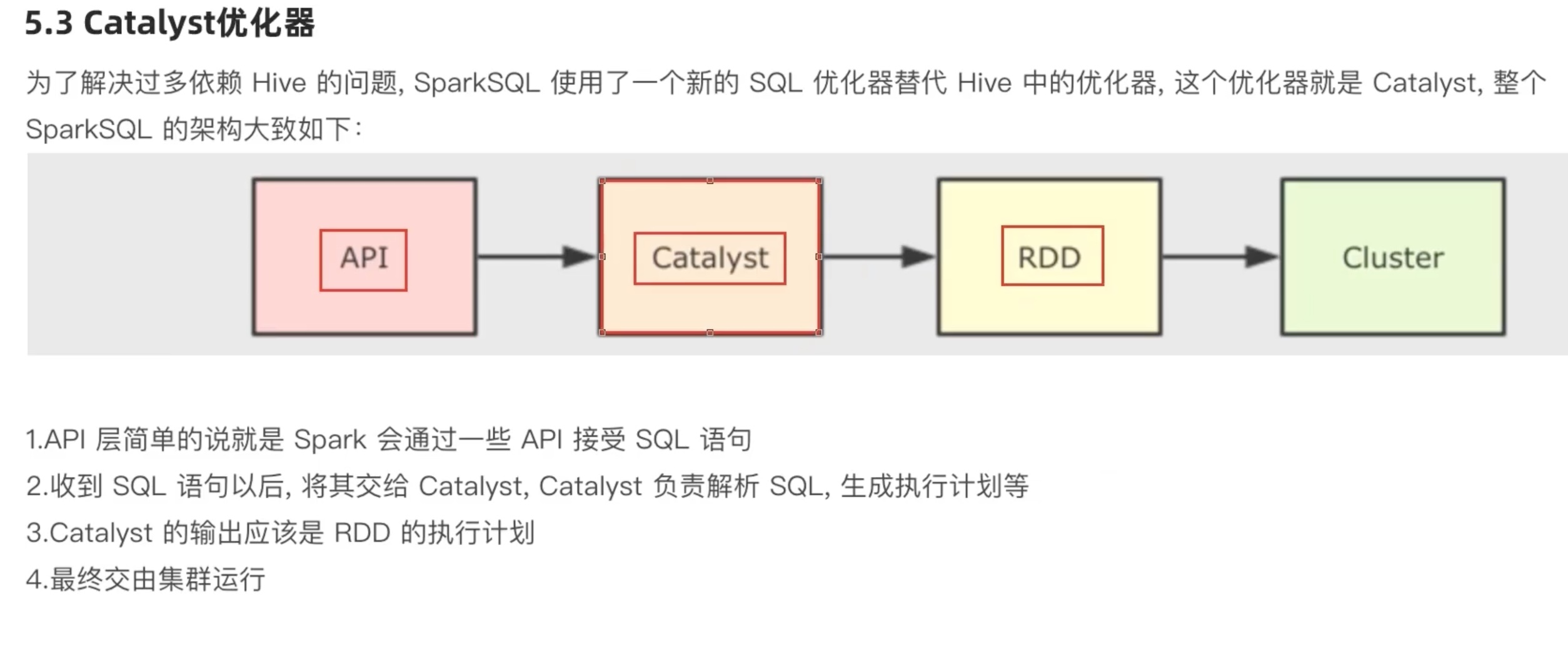
简介
python 开发spark 都是以dataframe 对象作为核心数据结构。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from pyspark.sql import SparkSessionif __name__=="__main__" : spark = SparkSession.builder.appName('test' ).master('local[*]' ).getOrCreate() sc = spark.sparkContext df = spark.read.csv('file:///home/chenyushao/Documents/spark测试数据/stu_score.txt' ,sep=',' ,header=False ) df2 = df.toDF('id' ,'name' ,'score' ) df2.printSchema() df2.show() df2.createTempView('score' ) spark.sql(''' select * from score where name='语文' LIMIT 5 ''' ).show() df2.where("name='语文'" ).limit(5 ).show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 root |-- id : string (nullable = true) |-- name: string (nullable = true) |-- score: string (nullable = true) +---+----+-----+ | id |name|score| +---+----+-----+ | 1 |语文| 99 | | 2 |语文| 99 | | 3 |语文| 99 | | 4 |语文| 99 | | 5 |语文| 99 | | 6 |语文| 99 | | 7 |语文| 99 | | 8 |语文| 99 | | 9 |语文| 99 | | 10 |语文| 99 | | 11 |语文| 99 | | 12 |语文| 99 | | 13 |语文| 99 | | 14 |语文| 99 | | 15 |语文| 99 | | 16 |语文| 99 | | 17 |语文| 99 | | 18 |语文| 99 | | 19 |语文| 99 | | 20 |语文| 99 | +---+----+-----+ only showing top 20 rows +---+----+-----+ | id |name|score| +---+----+-----+ | 1 |语文| 99 | | 2 |语文| 99 | | 3 |语文| 99 | | 4 |语文| 99 | | 5 |语文| 99 | +---+----+-----+ +---+----+-----+ | id |name|score| +---+----+-----+ | 1 |语文| 99 | | 2 |语文| 99 | | 3 |语文| 99 | | 4 |语文| 99 | | 5 |语文| 99 | +---+----+-----+
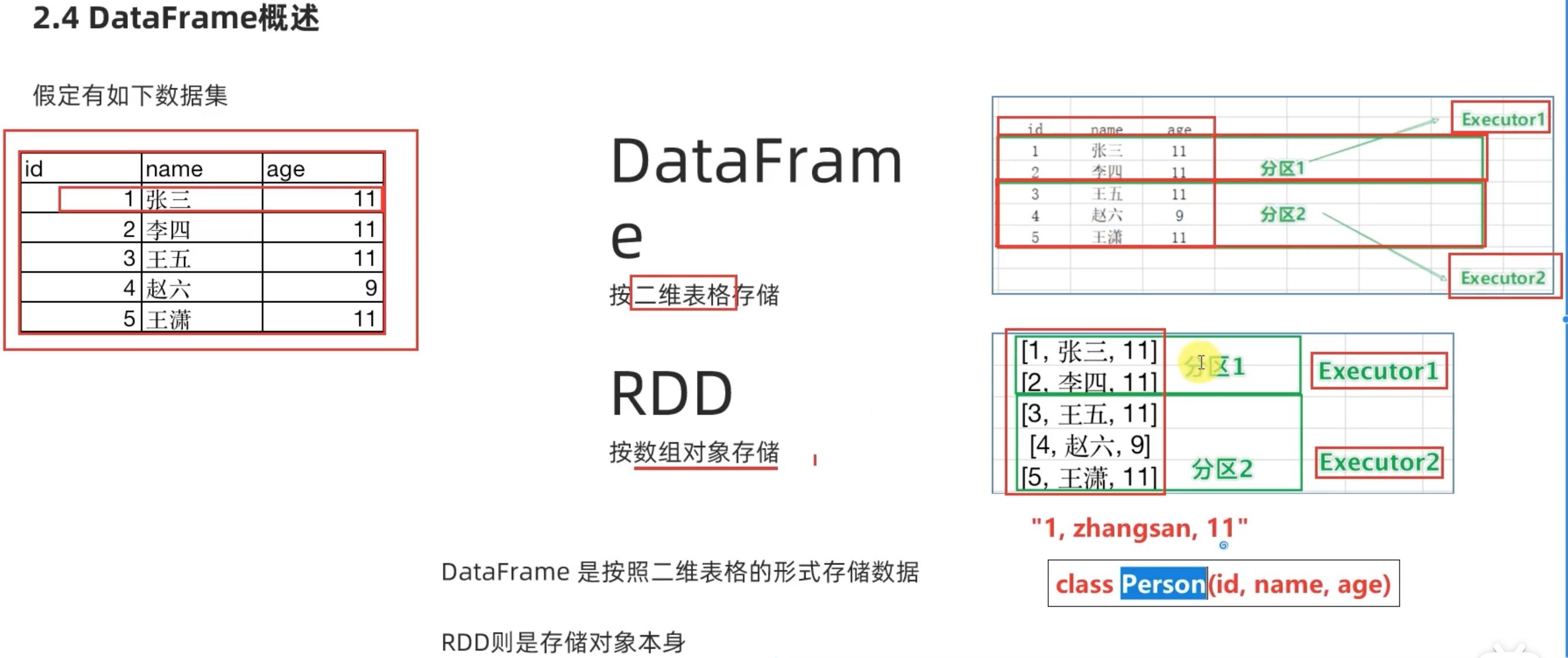
DataFrame 基础
dataframe 构建 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from pyspark.sql import SparkSessionif __name__=='__main__' : spark = SparkSession.builder.appName('create_sparksession' ).master('local[*]' ).getOrCreate() sc = spark.sparkContext rdd = sc.textFile('file:///home/chenyushao/Documents/spark测试数据/sql/people.txt' ) print (rdd.collect()) rdd1 = rdd.map (lambda x: x.split(',' )).map (lambda x: (x[0 ],int (x[1 ]))) df = spark.createDataFrame(rdd1,schema=['name' ,'age' ]) df.printSchema() df.show() df.createOrReplaceTempView('people' ) spark.sql('select * from people where age<30' ).show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringTypeif __name__=='__main__' : spark = SparkSession.builder.appName('create_sparksession' ).master('local[*]' ).getOrCreate() sc = spark.sparkContext rdd = sc.textFile('file:///home/chenyushao/Documents/spark测试数据/sql/people.txt' ) rdd1 = rdd.map (lambda x: x.split(',' )).map (lambda x: (x[0 ],int (x[1 ]))) schema = StructType().add('name' ,StringType(),nullable=False ).\ add('age' ,IntegerType(),nullable=True ) df = spark.createDataFrame(rdd1,schema=schema) df.printSchema() df.show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringTypeif __name__=='__main__' : spark = SparkSession.builder.appName('create_sparksession' ).master('local[*]' ).getOrCreate() sc = spark.sparkContext rdd = sc.textFile('file:///home/chenyushao/Documents/spark测试数据/sql/people.txt' ) rdd1 = rdd.map (lambda x: x.split(',' )).map (lambda x: (x[0 ],int (x[1 ]))) rdd1.cache() df1 = rdd1.toDF(['name' ,'age' ]) df1.printSchema() df1.show() schema = StructType().add('name' ,StringType(),nullable=False ).\ add('age' ,IntegerType(),nullable=True ) df2 = rdd1.toDF(schema=schema) df2.printSchema() df2.show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructTypeimport pandas as pdif __name__=='__main__' : spark = SparkSession.builder.appName('create_sparksession' ).master('local[*]' ).getOrCreate() sc = spark.sparkContext pddf = pd.DataFrame( { 'id' :[1 ,2 ,3 ], 'name' :['zhangsan' ,'lisi' ,'wanwu' ], 'age' :[11 ,12 ,13 ] } ) df = spark.createDataFrame(pddf) df.printSchema() df.show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringTypeif __name__=='__main__' : spark = SparkSession.builder.appName('create_sparksession' ).master('local[*]' ).getOrCreate() sc = spark.sparkContext schema = StructType().add('just_one_filed' ,StringType(),nullable=True ) df = spark.read.format ('text' ).schema(schema=schema).\ load('file:///home/chenyushao/Documents/spark测试数据/sql/people.txt' ) df.printSchema() df.show()
1 2 3 4 5 6 7 8 9 10 11 root |-- just_one_filed: string (nullable = true) +--------------+ |just_one_filed| +--------------+ | Michael, 29 | | Andy, 30 | | Justin, 19 | +--------------+
1 2 3 4 5 6 7 8 9 10 11 12 13 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringTypeif __name__=='__main__' : spark = SparkSession.builder.appName('create_sparksession' ).master('local[*]' ).getOrCreate() sc = spark.sparkContext df = spark.read.format ('json' ).load('file:///home/chenyushao/Documents/spark测试数据/sql/people.json' ) df.printSchema() df.show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringTypeif __name__=='__main__' : spark = SparkSession.builder.appName('create_sparksession' ).master('local[*]' ).getOrCreate() sc = spark.sparkContext df = spark.read.format ('csv' ).\ option('sep' ,';' ).\ option('header' ,True ).\ option('encoding' ,'utf-8' ).\ schema('name STRING,age INT,job STRING' ).\ load('file:///home/chenyushao/Documents/spark测试数据/sql/people.csv' ) df.printSchema() df.show()
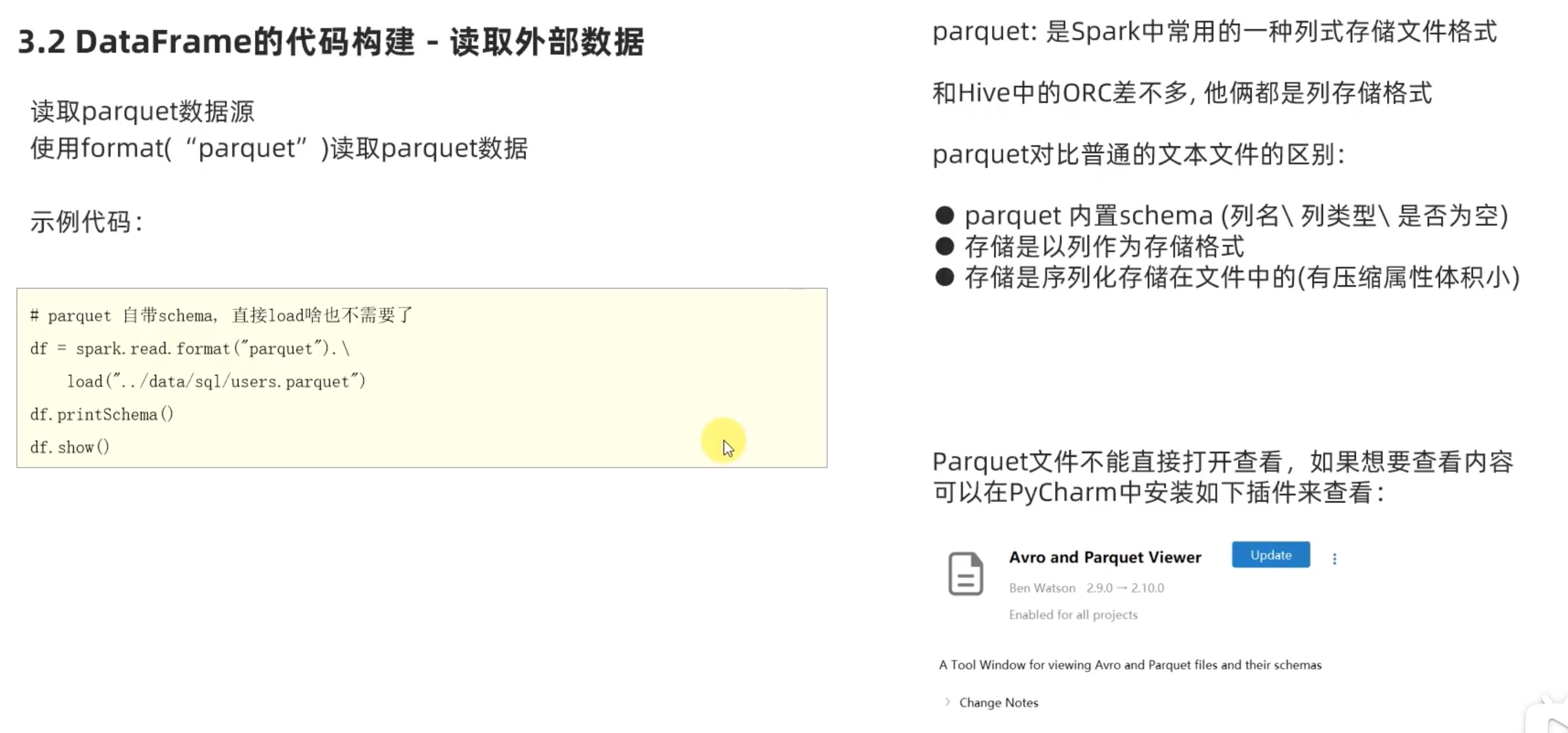
1 2 3 4 5 6 7 8 9 10 11 12 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringTypeif __name__=='__main__' : spark = SparkSession.builder.appName('create_sparksession' ).master('local[*]' ).getOrCreate() sc = spark.sparkContext df = spark.read.format ('parquet' ).load('file:///home/chenyushao/Documents/spark测试数据/sql/users.parquet' ) df.printSchema() df.show()
1 2 3 4 5 6 7 8 9 10 11 12 13 root |-- name: string (nullable = true) |-- favorite_color: string (nullable = true) |-- favorite_numbers: array (nullable = true) | |-- element: integer (containsNull = true) +------+--------------+----------------+ | name|favorite_color|favorite_numbers| +------+--------------+----------------+ |Alyssa| null| [3 , 9 , 15 , 20 ]| | Ben| red| []| +------+--------------+----------------+
在idea加载 Avro parquet view 工具,只需要把文件拖入代码框 下方的 Avro parquet view 窗口即可查看parquet 文件。
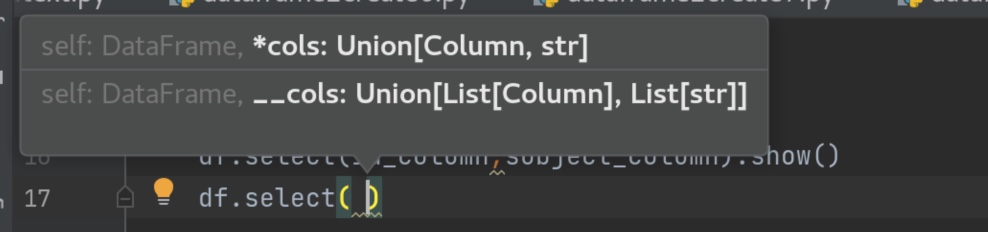
dataframe 编程 idea 编程小技巧。除了ctrl+command+点击查看方法源码。还可以 ctrl+p 大致查看方法需要的形参。
select有两种调用形式:
第一种*cols , 的形参要求是column或者str两种写法。
df.select('id','subject').show()
df.select(id_column,subject_column).show()
第二种 __cols , 的形参要求 是list包裹column或者list包裹str写法。
df.select(['id','subjuct']).show()
df.select([id_column,subject_column]).show()
DSL 代码风格 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringTypeif __name__=='__main__' : spark = SparkSession.builder.appName('test' ).master('local[*]' ).getOrCreate() sc = spark.sparkContext df = spark.read.format ('csv' ).schema('id INT,subject STRING,score INT' ).\ load('file:///home/chenyushao/Documents/spark测试数据/sql/stu_score.txt' ) id_column = df['id' ] subject_column = df['subject' ] df.select(['id' ,'subject' ]).show() df.select('id' ,'subject' ).show() df.select(id_column,subject_column).show() df.select([id_column,subject_column]).show() df.filter ('score<99' ).show() df.filter (df['score' ]<99 ).show() df.where('score<99' ).show() df.where(df['score' ]<99 ).show() df.groupBy('subject' ).count().show() df.groupBy(df['subject' ]).count().show() r = df.groupBy(df['subject' ]) print (type (r)) r.sum ().show() print (type (r.sum ()))
SQL风格
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringTypeif __name__=='__main__' : spark = SparkSession.builder.appName('test' ).master('local[*]' ).getOrCreate() sc = spark.sparkContext df = spark.read.format ('csv' ).schema('id INT,subject STRING,score INT' ). \ load('file:///home/chenyushao/Documents/spark测试数据/sql/stu_score.txt' ) df.createTempView('score' ) df.createOrReplaceTempView('score2' ) df.createGlobalTempView('score3' ) spark.sql('select subject, count(*) as cnt from score group by subject' ).show() spark.sql('select subject, count(*) as cnt from score2 group by subject' ).show() spark.sql('select subject, count(*) as cnt from global_temp.score3 group by subject' ).show()
wordcount 案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringTypefrom pyspark.sql import functions as Fif __name__=='__main__' : spark = SparkSession.builder.appName('test' ).master('local[*]' ).getOrCreate() sc = spark.sparkContext rdd = sc.textFile('file:///home/chenyushao/Documents/spark测试数据/words.txt' ).\ flatMap(lambda x: x.split(' ' )).map (lambda x: [x]) df = rdd.toDF(['word' ]) df.createTempView('words' ) spark.sql('select word ,count(*) as cnt from words group by word order by cnt DESC ' ).show() df = spark.read.format ('text' ).load('file:///home/chenyushao/Documents/spark测试数据/words.txt' ) df2 = df.withColumn('value' ,F.explode(F.split(df['value' ],' ' ))) df2.show() df2.groupBy('value' ).count().withColumnRenamed('value' ,'word' ).\ withColumnRenamed('count' ,'cnt' ).orderBy('cnt' ,ascending=False ).show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 +------+---+ | word|cnt| +------+---+ | hello| 3 | | spark| 1 | | flink| 1 | |hadoop| 1 | +------+---+ +------+ | value| +------+ | hello| | spark| | hello| |hadoop| | hello| | flink| +------+ +------+---+ | word|cnt| +------+---+ | hello| 3 | | spark| 1 | |hadoop| 1 | | flink| 1 | +------+---+
电影评分 分析案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringTypefrom pyspark.sql import functions as Fif __name__=='__main__' : spark = SparkSession.builder.appName('test' ).master('local[*]' ).getOrCreate() sc = spark.sparkContext schema = StructType().add('user_id' ,StringType(),nullable=True ).\ add('movie_id' ,IntegerType(),nullable=True ).\ add('rank' ,IntegerType(),nullable=True ).\ add('time' ,StringType(),nullable=True ) df = spark.read.format ('csv' ).\ option('sep' ,'\t' ).\ option('header' ,False ).\ option('encoding' ,'utf-8' ).\ schema(schema=schema).\ load('/home/chenyushao/Documents/spark测试数据/sql/u.data' ) df.groupBy('user_id' ).avg('rank' ).\ withColumn('avg(rank)' ,F.round ('avg(rank)' ,2 )).\ orderBy('avg(rank)' ,ascending=False ).show() df.createTempView('movie' ) spark.sql('select movie_id,round(avg(rank),2) as a_r from movie group by movie_id order by a_r DESC' ).show() df.select(F.avg(df['rank' ])).show() num = df.where( df['rank' ] > df.select(F.avg(df['rank' ])).first()['avg(rank)' ]).count() print ('大于平均分电影的数量: ' ,num ) user_id = df.where(df['rank' ]>3 ).groupBy('user_id' ).count().\ orderBy('count' ,ascending=False ).\ first()['user_id' ] print (user_id) df.filter (df['user_id' ]==user_id).\ select(F.round (F.avg(df['rank' ]),2 )).show() df.groupBy('user_id' ).\ agg( F.round (F.avg(df['rank' ]),2 ).alias('avg_rank' ), F.min (df['rank' ]).alias('min_rank' ), F.max ('rank' ).alias('max_rank' ) ).show() df.groupBy('movie_id' ).\ agg( F.count('rank' ).alias('cnt' ), F.round (F.avg(df['rank' ]),2 ).alias('avg_rank' ) ).where('cnt > 100' ).\ orderBy('avg_rank' ,ascending=False ).\ limit(10 ).show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 +-------+---------+ |user_id|avg(rank)| +-------+---------+ | 849 | 4.87 | | 688 | 4.83 | | 507 | 4.72 | | 628 | 4.7 | | 928 | 4.69 | | 118 | 4.66 | | 907 | 4.57 | | 686 | 4.56 | | 427 | 4.55 | | 565 | 4.54 | | 469 | 4.53 | | 850 | 4.53 | | 225 | 4.52 | | 330 | 4.5 | | 477 | 4.46 | | 636 | 4.45 | | 242 | 4.45 | | 583 | 4.44 | | 252 | 4.43 | | 767 | 4.43 | +-------+---------+ only showing top 20 rows +--------+----+ |movie_id| a_r| +--------+----+ | 1653 | 5.0 | | 1122 | 5.0 | | 1467 | 5.0 | | 1201 | 5.0 | | 1189 | 5.0 | | 1293 | 5.0 | | 1599 | 5.0 | | 1536 | 5.0 | | 814 | 5.0 | | 1500 | 5.0 | | 1449 |4.63 | | 1398 | 4.5 | | 1594 | 4.5 | | 119 | 4.5 | | 1642 | 4.5 | | 408 |4.49 | | 169 |4.47 | | 318 |4.47 | | 483 |4.46 | | 64 |4.45 | +--------+----+ only showing top 20 rows +---------+ |avg(rank)| +---------+ | 3.52986 | +---------+ 大于平均分电影的数量: 55375 450 +-------------------+ |round (avg(rank), 2 )| +-------------------+ | 3.86 | +-------------------+ +-------+--------+--------+--------+ |user_id|avg_rank|min_rank|max_rank| +-------+--------+--------+--------+ | 296 | 4.18 | 1 | 5 | | 467 | 3.68 | 2 | 5 | | 691 | 4.22 | 1 | 5 | | 675 | 3.71 | 1 | 5 | | 829 | 3.55 | 1 | 5 | | 125 | 3.44 | 1 | 5 | | 451 | 2.73 | 1 | 5 | | 800 | 3.75 | 2 | 5 | | 853 | 2.98 | 1 | 5 | | 666 | 3.67 | 2 | 5 | | 870 | 3.45 | 1 | 5 | | 919 | 3.47 | 1 | 5 | | 926 | 3.3 | 1 | 5 | | 7 | 3.97 | 1 | 5 | | 124 | 3.5 | 1 | 5 | | 51 | 3.57 | 1 | 5 | | 447 | 3.6 | 1 | 5 | | 591 | 3.65 | 2 | 5 | | 307 | 3.79 | 1 | 5 | | 475 | 3.6 | 1 | 5 | +-------+--------+--------+--------+ only showing top 20 rows +--------+---+--------+ |movie_id|cnt|avg_rank| +--------+---+--------+ | 408 |112 | 4.49 | | 318 |298 | 4.47 | | 169 |118 | 4.47 | | 483 |243 | 4.46 | | 64 |283 | 4.45 | | 12 |267 | 4.39 | | 603 |209 | 4.39 | | 50 |583 | 4.36 | | 178 |125 | 4.34 | | 357 |264 | 4.29 | +--------+---+--------+
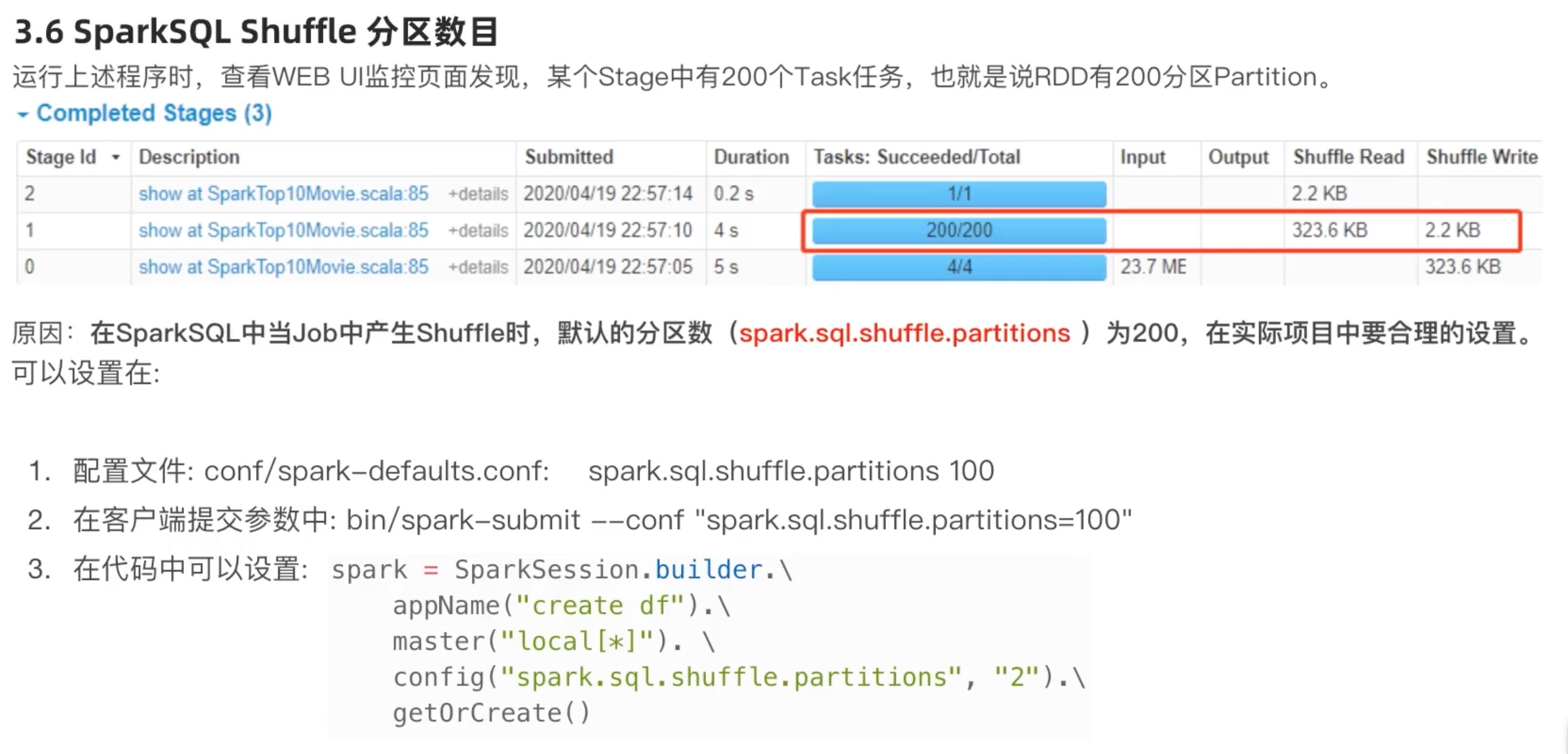
sparkSQL shuffle 分区数目 在前面电影评分的案例中,加上time.sleep(10000) ,再在4040端口查看。
task 也就是线程默认200个,分区有200个,太多了。最多的task 数目匹配机器的CPU核心数目,效率才能最大化。
注意:config('spark.sql.shuffle.partitions','2') 这个设置和rdd 的并行度设置 是相互独0立的!
sparkSQL 数据清洗API
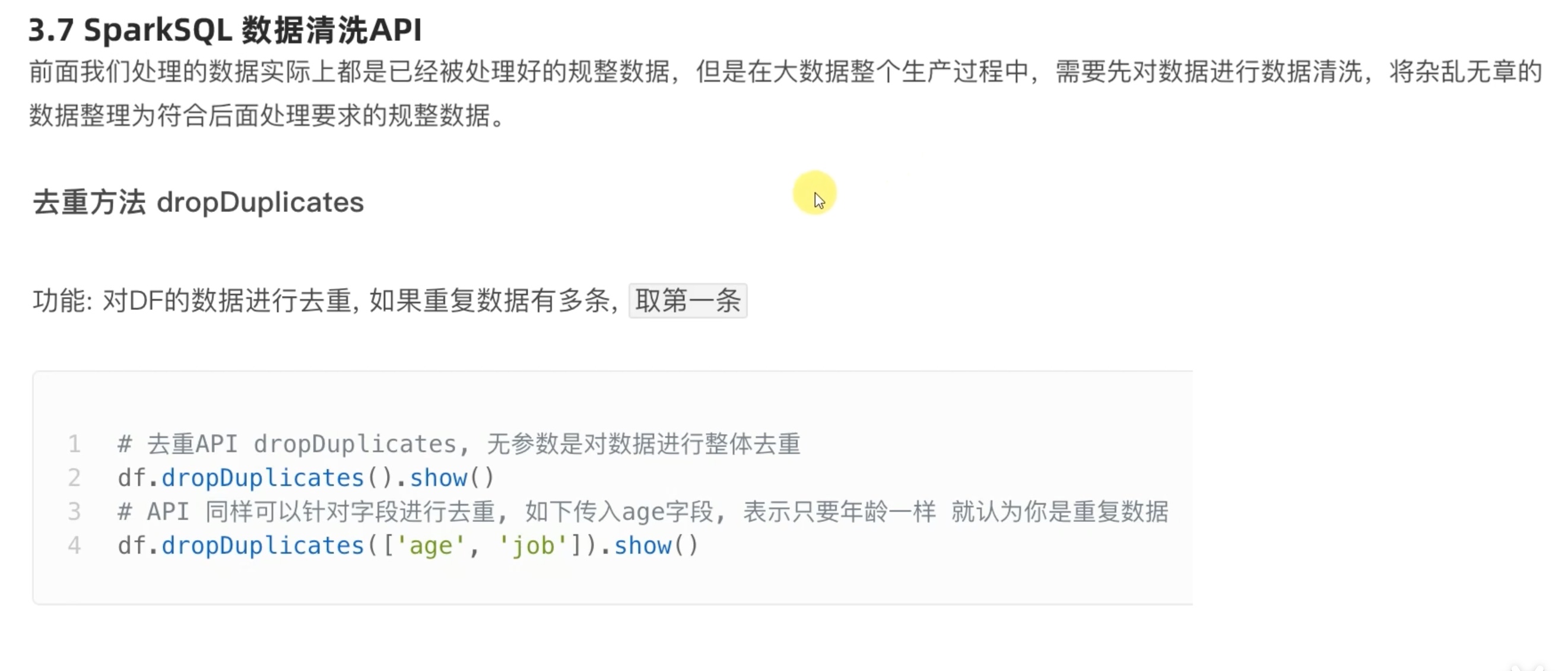
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringTypefrom pyspark.sql import functions as Fif __name__=='__main__' : spark = SparkSession.builder.appName('test' ). \ config('spark.sql.shuffle.partitions' ,'2' ). \ master('local[*]' ).getOrCreate() sc = spark.sparkContext df = spark.read.format ('csv' ).option('sep' ,';' ).option('header' ,True ).\ load('file:///home/chenyushao/Documents/spark测试数据/sql/people.csv' ) df.dropDuplicates().show() df.dropDuplicates(['age' ,'job' ]).show() df.dropna().show() df.dropna(thresh=2 ,subset=['name' ,'age' ]).show() df.fillna('loss' ).show() df.fillna('N/A' ,subset=['job' ]).show() df.fillna({'name' :'unknow_name' ,'age' :1 ,'job' :'work' }).show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 +-----+----+---------+ | name| age| job| +-----+----+---------+ | Bob| 32 |Developer| | Lily| 11 | Manager| |Alice| 9 | null| |Jorge| 30 |Developer| | Ani| 11 |Developer| | Put| 11 |Developer| |Alice| 9 | Manager| |Alice|null| Manager| +-----+----+---------+ +-----+----+---------+ | name| age| job| +-----+----+---------+ |Alice|null| Manager| | Ani| 11 |Developer| | Lily| 11 | Manager| |Jorge| 30 |Developer| | Bob| 32 |Developer| |Alice| 9 | null| |Alice| 9 | Manager| +-----+----+---------+ +-----+---+---------+ | name|age| job| +-----+---+---------+ |Jorge| 30 |Developer| | Bob| 32 |Developer| | Ani| 11 |Developer| | Lily| 11 | Manager| | Put| 11 |Developer| |Alice| 9 | Manager| |Alice| 9 | Manager| |Alice| 9 | Manager| |Alice| 9 | Manager| +-----+---+---------+ +-----+---+---------+ | name|age| job| +-----+---+---------+ |Jorge| 30 |Developer| | Bob| 32 |Developer| | Ani| 11 |Developer| | Lily| 11 | Manager| | Put| 11 |Developer| |Alice| 9 | Manager| |Alice| 9 | Manager| |Alice| 9 | Manager| |Alice| 9 | Manager| |Alice| 9 | null| +-----+---+---------+ +-----+----+---------+ | name| age| job| +-----+----+---------+ |Jorge| 30 |Developer| | Bob| 32 |Developer| | Ani| 11 |Developer| | Lily| 11 | Manager| | Put| 11 |Developer| |Alice| 9 | Manager| |Alice| 9 | Manager| |Alice| 9 | Manager| |Alice| 9 | Manager| |Alice|loss| Manager| |Alice| 9 | loss| +-----+----+---------+ +-----+----+---------+ | name| age| job| +-----+----+---------+ |Jorge| 30 |Developer| | Bob| 32 |Developer| | Ani| 11 |Developer| | Lily| 11 | Manager| | Put| 11 |Developer| |Alice| 9 | Manager| |Alice| 9 | Manager| |Alice| 9 | Manager| |Alice| 9 | Manager| |Alice|null| Manager| |Alice| 9 | N/A| +-----+----+---------+ +-----+---+---------+ | name|age| job| +-----+---+---------+ |Jorge| 30 |Developer| | Bob| 32 |Developer| | Ani| 11 |Developer| | Lily| 11 | Manager| | Put| 11 |Developer| |Alice| 9 | Manager| |Alice| 9 | Manager| |Alice| 9 | Manager| |Alice| 9 | Manager| |Alice| 1 | Manager| |Alice| 9 | work| +-----+---+---------+
dataframe数据写出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringTypefrom pyspark.sql import functions as Fif __name__=='__main__' : spark = SparkSession.builder.appName('test' ). \ config('spark.sql.shuffle.partitions' ,'2' ). \ master('local[*]' ).getOrCreate() sc = spark.sparkContext schema = StructType().add('user_id' ,StringType(),nullable=True ). \ add('movie_id' ,IntegerType(),nullable=True ). \ add('rank' ,IntegerType(),nullable=True ). \ add('time' ,StringType(),nullable=True ) df = spark.read.format ('csv' ). \ option('sep' ,'\t' ). \ option('header' ,False ). \ option('encoding' ,'utf-8' ). \ schema(schema=schema). \ load('file:///home/chenyushao/Documents/spark测试数据/sql/u.data' ) df.select(F.concat_ws('\t' ,'user_id' ,'movie_id' ,'rank' ,'time' )).\ write.mode('overwrite' ).format ('text' ).\ save('file:///home/chenyushao/Documents/spark测试数据/output/text' ) df.write.mode('overwrite' ).format ('csv' ).\ option('sep' ,';' ).option('header' ,True ).\ save('file:///home/chenyushao/Documents/spark测试数据/output/csv' ) df.write.mode('overwrite' ).format ('json' ).\ save('file:///home/chenyushao/Documents/spark测试数据/output/json' ) df.write.mode('overwrite' ).format ('parquet' ).\ save('file:///home/chenyushao/Documents/spark测试数据/output/parquet' )
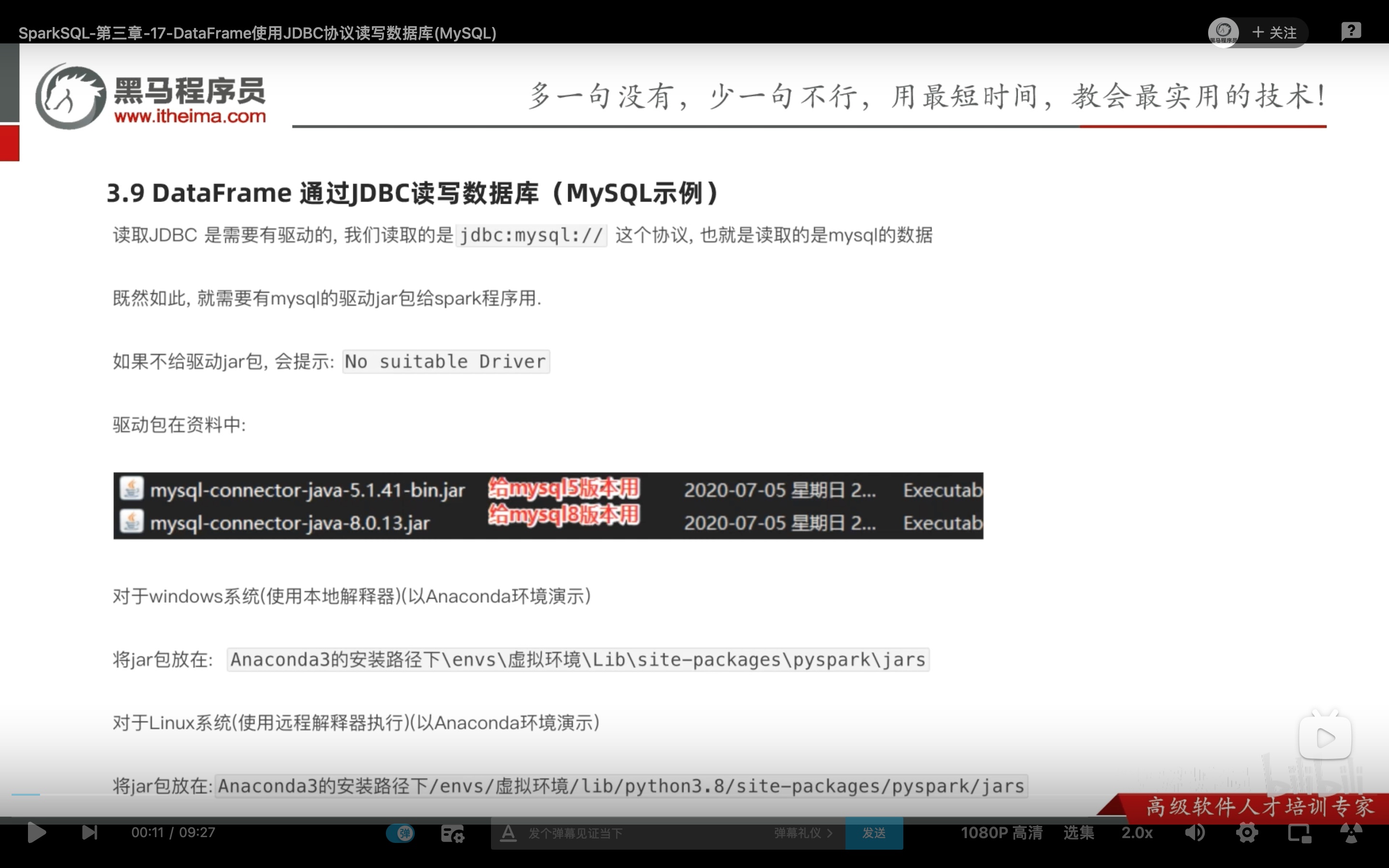
读入和写出 jdbc 数据 读入和写出 jdbc 数据(连接mysql数据库),会稍微有一点不一样,因为涉及到登录mysql和驱动。
这个mysql的java驱动jar包,我们在之前hive安装中,在hive的lib包内配置好了,但是当时我们是放入hive 的lib 内 ,这个路径 spark是找不到的。
1 2 3 # 我的mysql版本 Server version: 5.7.26 MySQL # mysql官方推荐mysql5.6以上 使用connector/j 8.0 ,而且在使用时需要对时区进行设置。java推荐java1.8以后都用connector/j 8.0 。 cp mysql-connector-java-8.0.25.jar /opt/hive/apache-hive-3.1.2-bin/lib # 或者用finalshell直接传进hive的lib中。
(一)这里教程推荐我们把 驱动包直接 放入 conda –我们用的虚拟环境– site-packages包集合– 我们用的虚拟环境对应的jar下面。以方便spark使用jdbc。(以后别的jar包也可以这么加)
1 cp mysql-connector-java-8.0.25.jar /opt/anaconda3/envs/pyspark/lib/python3.8/site-packages/pyspark/jars
(二)在mysql中新建一个databases,专门来存放spark保存过来的数据。
1 create database spark_databases;
(三)打开mysql的远程权限。
1 2 grant all privileges on *.* to 'root'@'node01' identified by '自己的密码' with grant option; flush privileges;
(四)写出 读入 jdbc 数据。数据存放在mysql中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringTypefrom pyspark.sql import functions as Fif __name__=='__main__' : spark = SparkSession.builder.appName('test' ). \ config('spark.sql.shuffle.partitions' ,'2' ). \ master('local[*]' ).getOrCreate() sc = spark.sparkContext schema = StructType().add('user_id' ,StringType(),nullable=True ). \ add('movie_id' ,IntegerType(),nullable=True ). \ add('rank' ,IntegerType(),nullable=True ). \ add('time' ,StringType(),nullable=True ) df = spark.read.format ('csv' ). \ option('sep' ,'\t' ). \ option('header' ,False ). \ option('encoding' ,'utf-8' ). \ schema(schema=schema). \ load('file:///home/chenyushao/Documents/spark测试数据/sql/u.data' ) df.write.mode('overwrite' ).\ format ('jdbc' ).\ option('url' ,'jdbc:mysql://node01:3306/spark_databases?useSSL=false&useUnicode=true' ).\ option('dbtable' ,'movie_table' ).\ option('user' ,'root' ).\ option('password' ,'自己的密码' ).\ save() df2 = spark.read. \ format ('jdbc' ). \ option('url' ,'jdbc:mysql://node01:3306/spark_databases?useSSL=false&useUnicode=true' ). \ option('dbtable' ,'movie_table' ). \ option('user' ,'root' ). \ option('password' ,'自己的密码' ).\ load() df2.printSchema() df2.show()
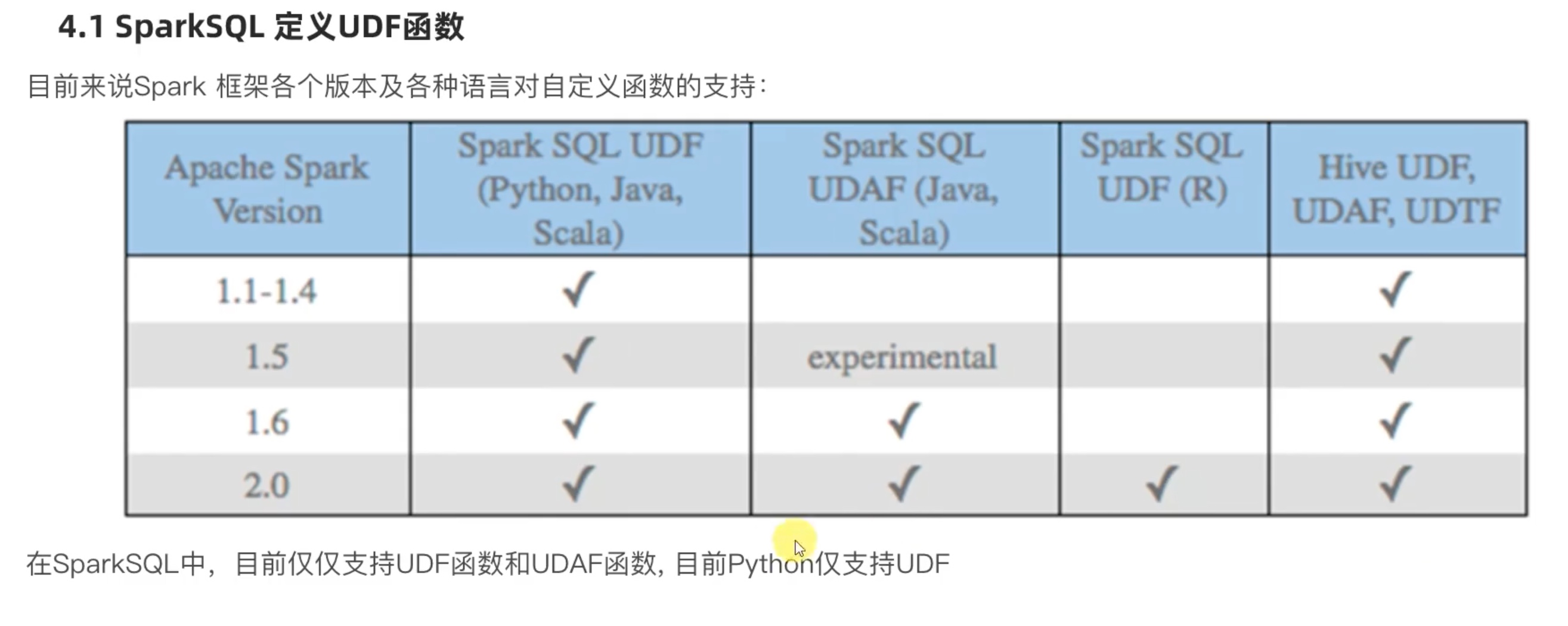
SparkSQL 自定义函数
所以,要定义udaf 、udtf 还是要用到hive帮助,或者用rdd等等模拟出udaf、udtf的效果,或者 干脆用Scala 来写。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringTypefrom pyspark.sql import functions as Fif __name__=='__main__' : spark = SparkSession.builder.appName('test' ). \ config('spark.sql.shuffle.partitions' ,'2' ). \ master('local[*]' ).getOrCreate() sc = spark.sparkContext rdd = sc.parallelize([1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ]).map (lambda x: [x]) df = rdd.toDF(['num' ]) def num_ride_10 (num ): return num*10 udf2 = spark.udf.register('udf1' ,num_ride_10,IntegerType()) df.selectExpr('udf1(num)' ).show() df.select(udf2(df['num' ])).show() udf3 = F.udf(num_ride_10,IntegerType()) df.select(udf3(df['num' ])).show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 +---------+ |udf1(num)| +---------+ | 10 | | 20 | | 30 | | 40 | | 50 | | 60 | | 70 | | 80 | | 90 | +---------+ +---------+ |udf1(num)| +---------+ | 10 | | 20 | | 30 | | 40 | | 50 | | 60 | | 70 | | 80 | | 90 | +---------+ +----------------+ |num_ride_10(num)| +----------------+ | 10 | | 20 | | 30 | | 40 | | 50 | | 60 | | 70 | | 80 | | 90 | +----------------+
注册一个返回值为array类型的udf 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringType,ArrayTypefrom pyspark.sql import functions as Fif __name__=='__main__' : spark = SparkSession.builder.appName('test' ). \ config('spark.sql.shuffle.partitions' ,'2' ). \ master('local[*]' ).getOrCreate() sc = spark.sparkContext rdd = sc.parallelize([['hadoop flink spark' ],['java python c++' ]]) df = rdd.toDF(['line' ]) def split_line (data ): return data.split(' ' ) udf2 = spark.udf.register('udf1' ,split_line,ArrayType(StringType())) df.select(udf2(df['line' ])).show() df.createTempView('lines' ) spark.sql('select udf1(line) from lines' ).show(truncate=False ) udf3 = F.udf(split_line,ArrayType(StringType())) df.select(udf3(df['line' ])).show(truncate=False )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 +--------------------+ | udf1(line)| +--------------------+ |[hadoop, flink, s...| | [java, python, c++]| +--------------------+ +----------------------+ |udf1(line) | +----------------------+ |[hadoop, flink, spark]| |[java, python, c++] | +----------------------+ +----------------------+ | split_line(line) | +----------------------+ |[hadoop, flink, spark | | [java, python, c++] | +----------------------+
注册一个返回值为dict类型的udf 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import stringfrom pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringType,ArrayTypefrom pyspark.sql import functions as Fif __name__=='__main__' : spark = SparkSession.builder.appName('test' ). \ config('spark.sql.shuffle.partitions' ,'2' ). \ master('local[*]' ).getOrCreate() sc = spark.sparkContext rdd = sc.parallelize([[1 ],[2 ],[3 ]]) df = rdd.toDF(['num' ]) def process (data ): return {'num' :data,'letter' :string.ascii_letters[data]} udf1 = spark.udf.\ register('udf1' ,process,StructType().\ add('num' ,IntegerType(),nullable=True ).\ add('letter' ,StringType(),nullable=True )) df.select(udf1(df['num' ])).show(truncate=False ) df.selectExpr('udf1(num)' ).show(truncate=False )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 +---------+ |udf1(num)| +---------+ |{1 , b} | |{2 , c} | |{3 , d} | +---------+ +---------+ |udf1(num)| +---------+ |{1 , b} | |{2 , c} | |{3 , d} | +---------+
python绕路实现UDAF 之前说过python不像java可以直接编写udaf方法,hive集成了相应方法都是又从spark找hive解决问题有点麻烦。
所以头铁一定要用python的前提下,选择用rdd间接实现udaf方法。
和map一次处理一个元素不同的是,mapPartion算子是整个迭代器传递。走网络的时候,一次性传输一个迭代器对象 效率一定高于一次传一个元素。mappartion 的输入和输出都是list对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import stringfrom pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringType,ArrayTypefrom pyspark.sql import functions as Fif __name__=='__main__' : spark = SparkSession.builder.appName('test' ). \ config('spark.sql.shuffle.partitions' ,'2' ). \ master('local[*]' ).getOrCreate() sc = spark.sparkContext rdd = sc.parallelize([1 ,2 ,3 ,4 ,5 ,6 ],3 ) df = rdd.map (lambda x: [x]).toDF(['num' ]) single_partition_rdd = df.rdd.repartition(1 ) print (single_partition_rdd.collect()) def process (iter sum = 0 for row in iter : sum += row['num' ] return [sum ] print (single_partition_rdd.mapPartitions(process).collect())
1 2 3 [Row(num=1 ), Row(num=2 ), Row(num=3 ), Row(num=4 ), Row(num=5 ), Row(num=6 )] [21 ]
如果好奇不把分区数改为1的话会怎么样,我们试一试,把上述代码改动。
single_partition_rdd = df.rdd
结果变为
[Row(num=1), Row(num=2), Row(num=3), Row(num=4), Row(num=5), Row(num=6)]
[3, 7, 11]
可见,mappartition算子对每一个分区都计算了一次,返回了一个list,最后collect只是把他们收集了起来,形成一个新的list。实际上影响了 udaf聚合的作用域。
sparkSQL 使用窗口函数
这里可以回顾一下,hive学习中的内容《hive参数配置与函数、运算符的使用》-《高阶函数介绍》《窗口函数》。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import stringfrom pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringType,ArrayTypefrom pyspark.sql import functions as Fif __name__=='__main__' : spark = SparkSession.builder.appName('test' ). \ config('spark.sql.shuffle.partitions' ,'2' ). \ master('local[*]' ).getOrCreate() sc = spark.sparkContext rdd = sc.parallelize([ ('zhansan' ,'calss_1' ,23 ), ('lisi' ,'calss_1' ,20 ), ('wanwu' ,'calss_2' ,25 ), ('miaoyang' ,'calss_3' ,3 ), ('zhoujielun' ,'calss_2' ,45 ), ('zhoujie' ,'calss_2' ,50 ), ('liudehua' ,'calss_3' ,65 ) ]) schema = StructType().add('name' ,StringType()).\ add('class' ,StringType()).add('score' ,IntegerType()) df = rdd.toDF(schema) df.createTempView('stu' ) spark.sql('''select * ,row_number() over(order by score) as row_number_rank, dense_rank() over(partition by class order by score DESC) as dense_rank, rank() over(order by score) as rank from stu ''' ).show() spark.sql(''' select * ,ntile(6) over(order by score desc) as ntile from stu''' ).show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 +----------+-------+-----+---------------+----------+----+ | name| class |score|row_number_rank|dense_rank|rank| +----------+-------+-----+---------------+----------+----+ | zhansan|calss_1| 23 | 3 | 1 | 3 | | lisi|calss_1| 20 | 2 | 2 | 2 | | zhoujie|calss_2| 50 | 6 | 1 | 6 | |zhoujielun|calss_2| 45 | 5 | 2 | 5 | | wanwu|calss_2| 25 | 4 | 3 | 4 | | liudehua|calss_3| 65 | 7 | 1 | 7 | | miaoyang|calss_3| 3 | 1 | 2 | 1 | +----------+-------+-----+---------------+----------+----+ +----------+-------+-----+-----+ | name| class |score|ntile| +----------+-------+-----+-----+ | liudehua|calss_3| 65 | 1 | | zhoujie|calss_2| 50 | 1 | |zhoujielun|calss_2| 45 | 2 | | wanwu|calss_2| 25 | 3 | | zhansan|calss_1| 23 | 4 | | lisi|calss_1| 20 | 5 | | miaoyang|calss_3| 3 | 6 | +----------+-------+-----+-----+
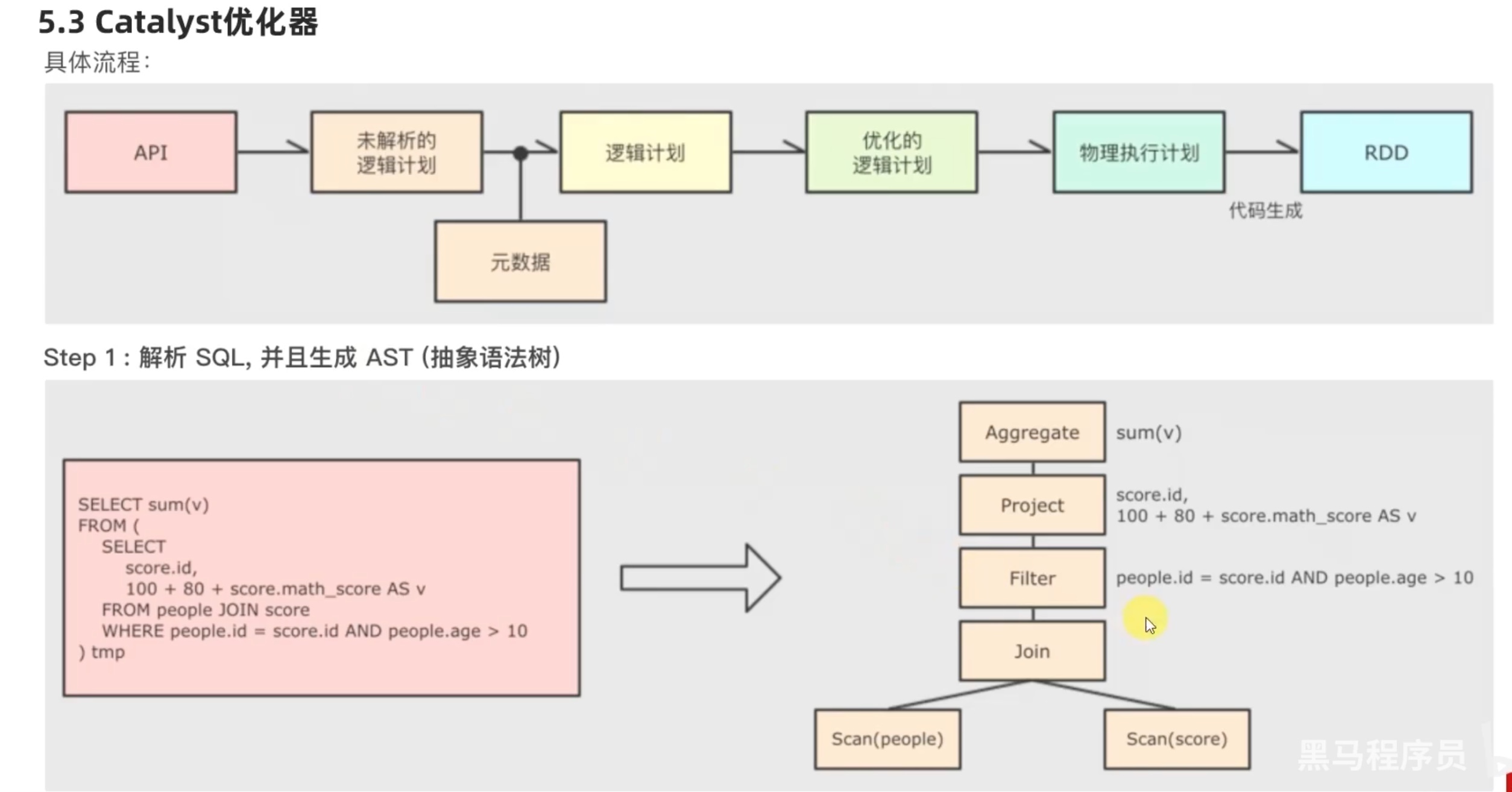
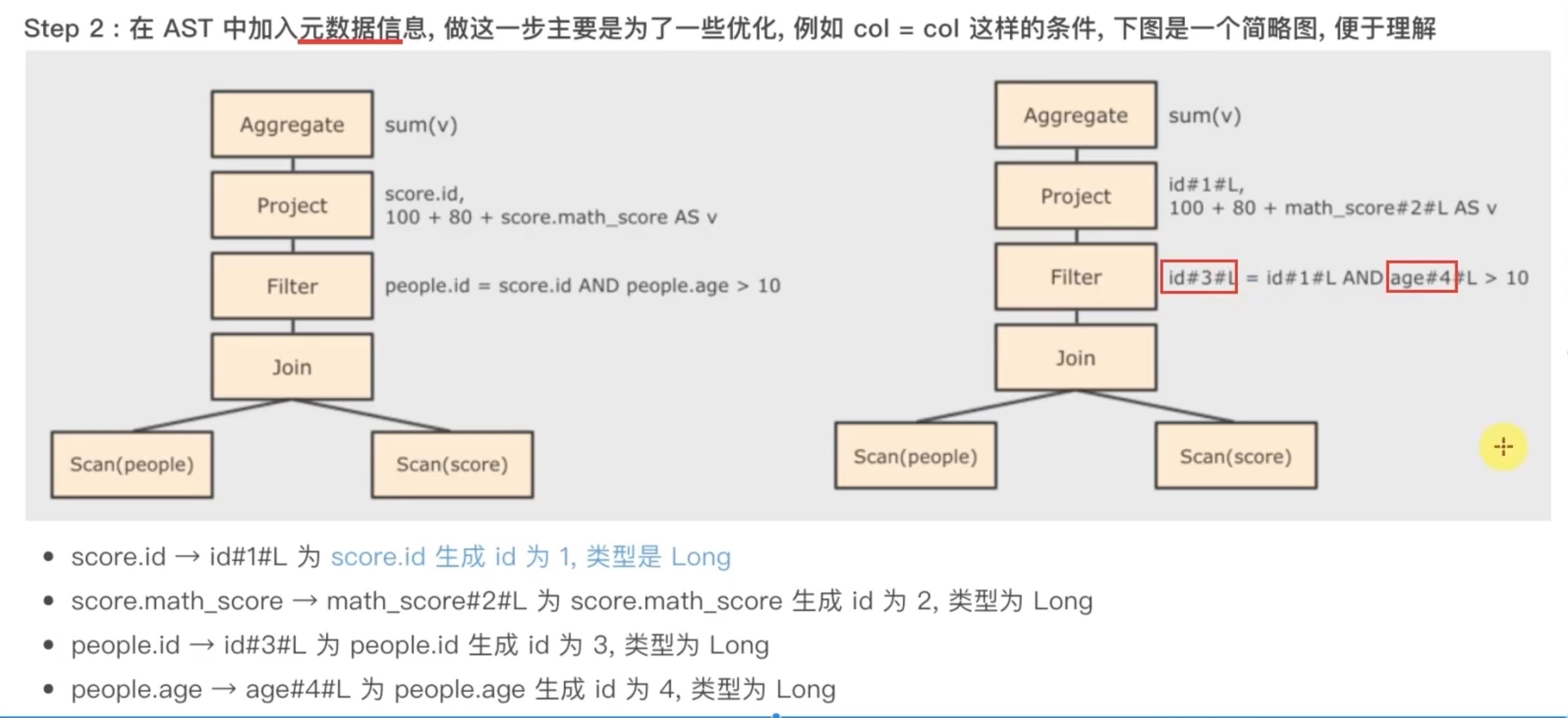
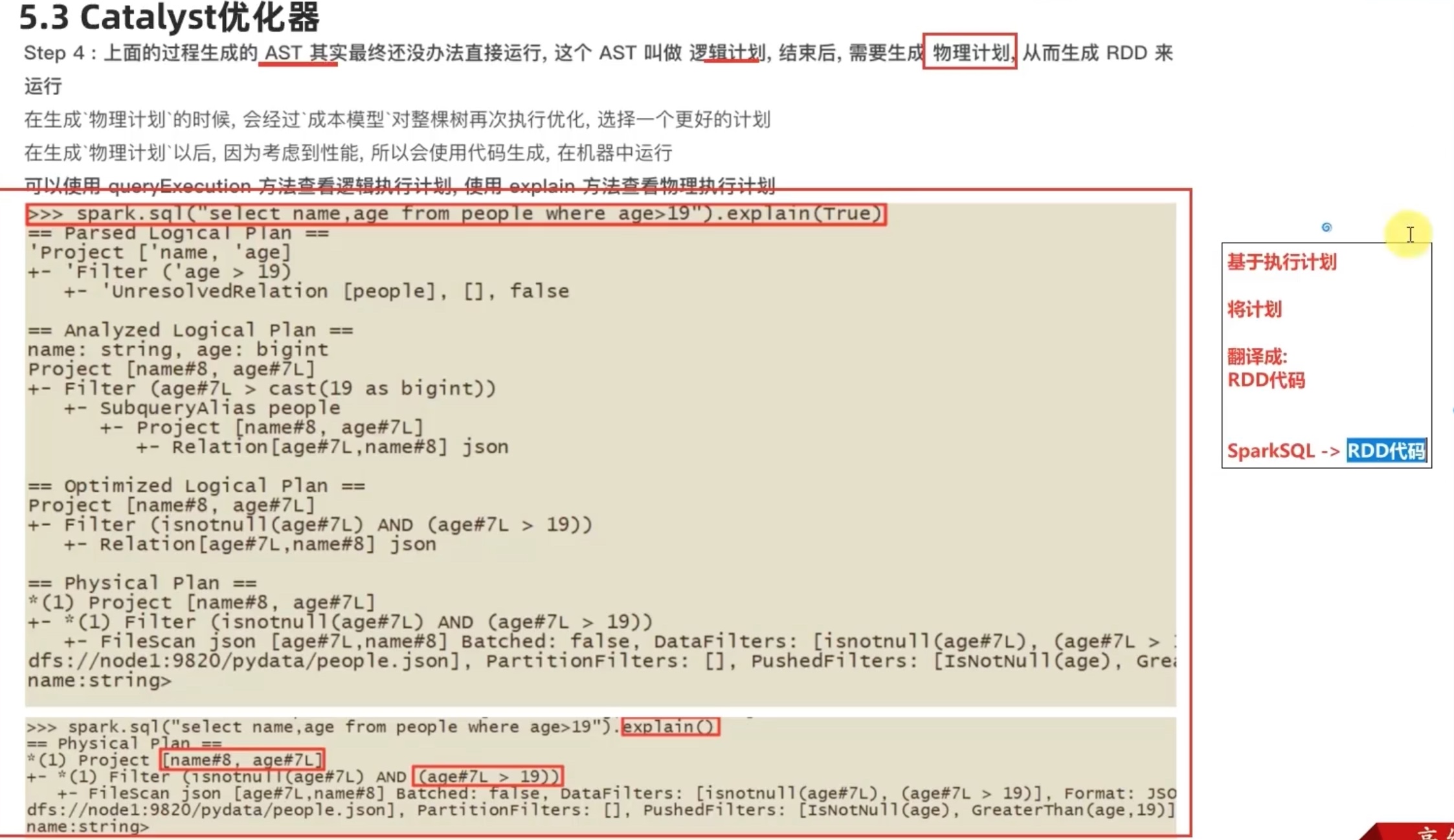
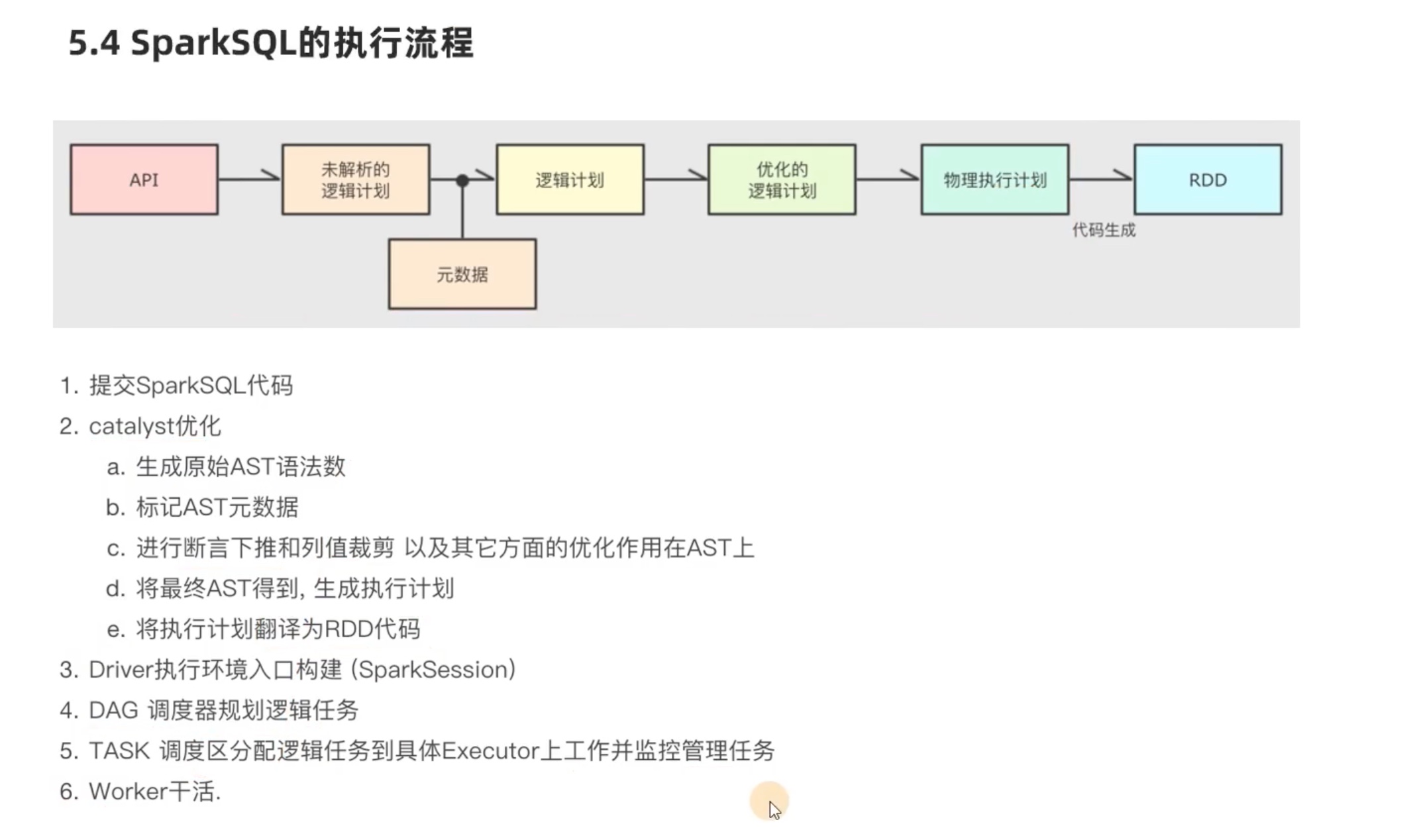
SparkSQL 执行流程
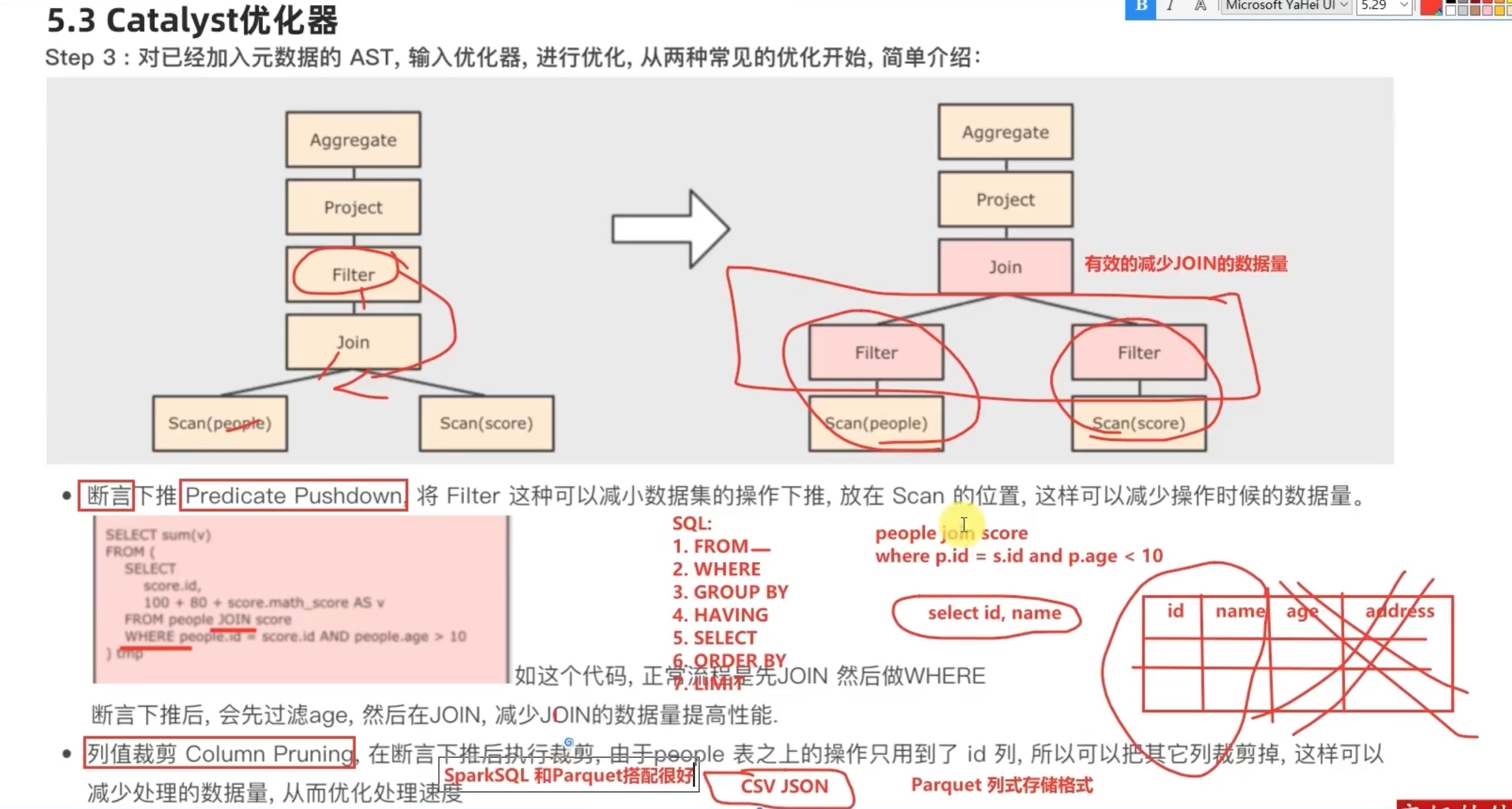
其实 predicate pushdown 断言下推(过滤前置)和 column pruning 列值裁剪 的核心思想都是 在join 之前 ,尽可能缩小数据规模,减少笛卡尔积。
其中列值裁剪 配合 parquet列式存储格式,会有很好的效果,因为以列为单位,直接可以不读取select 之外的column,仅仅保留select 会用到的column。
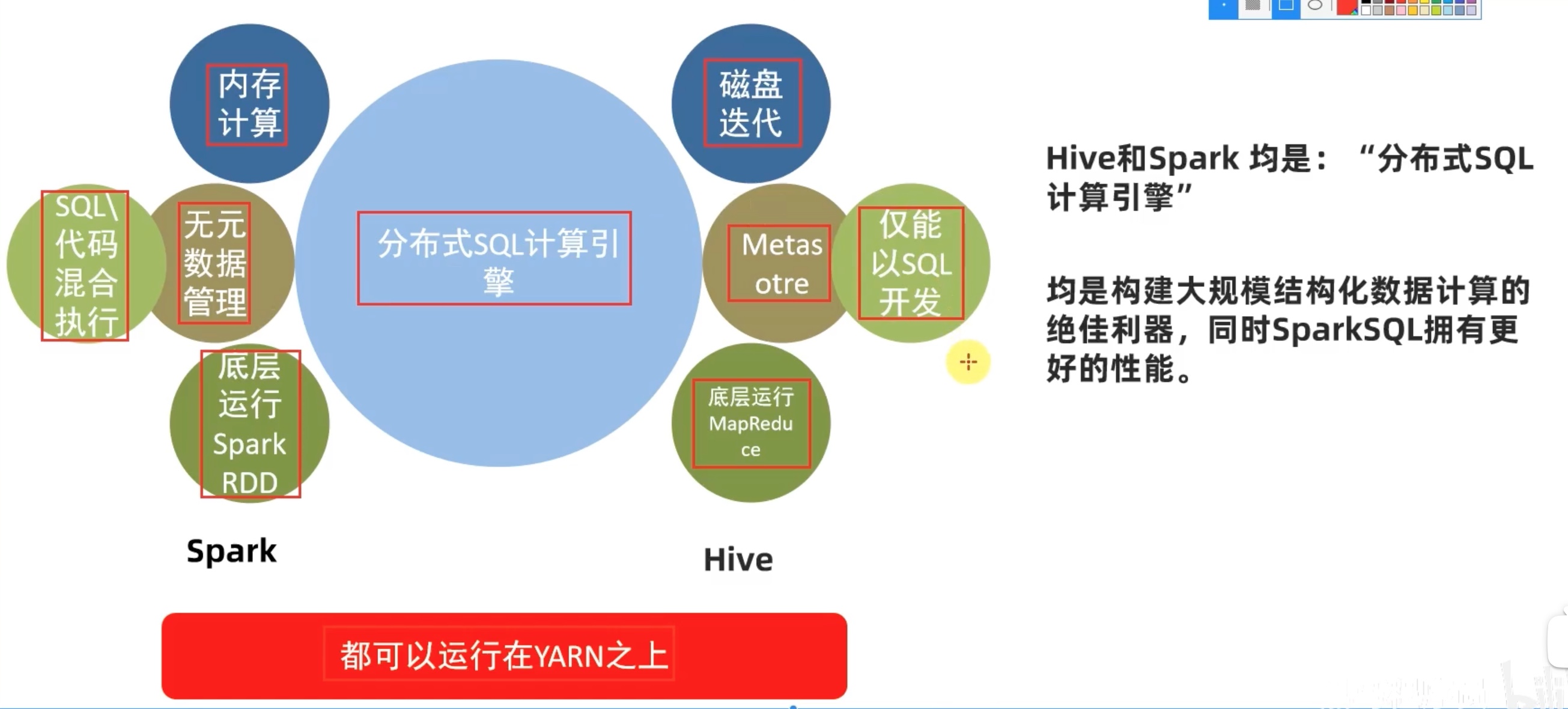
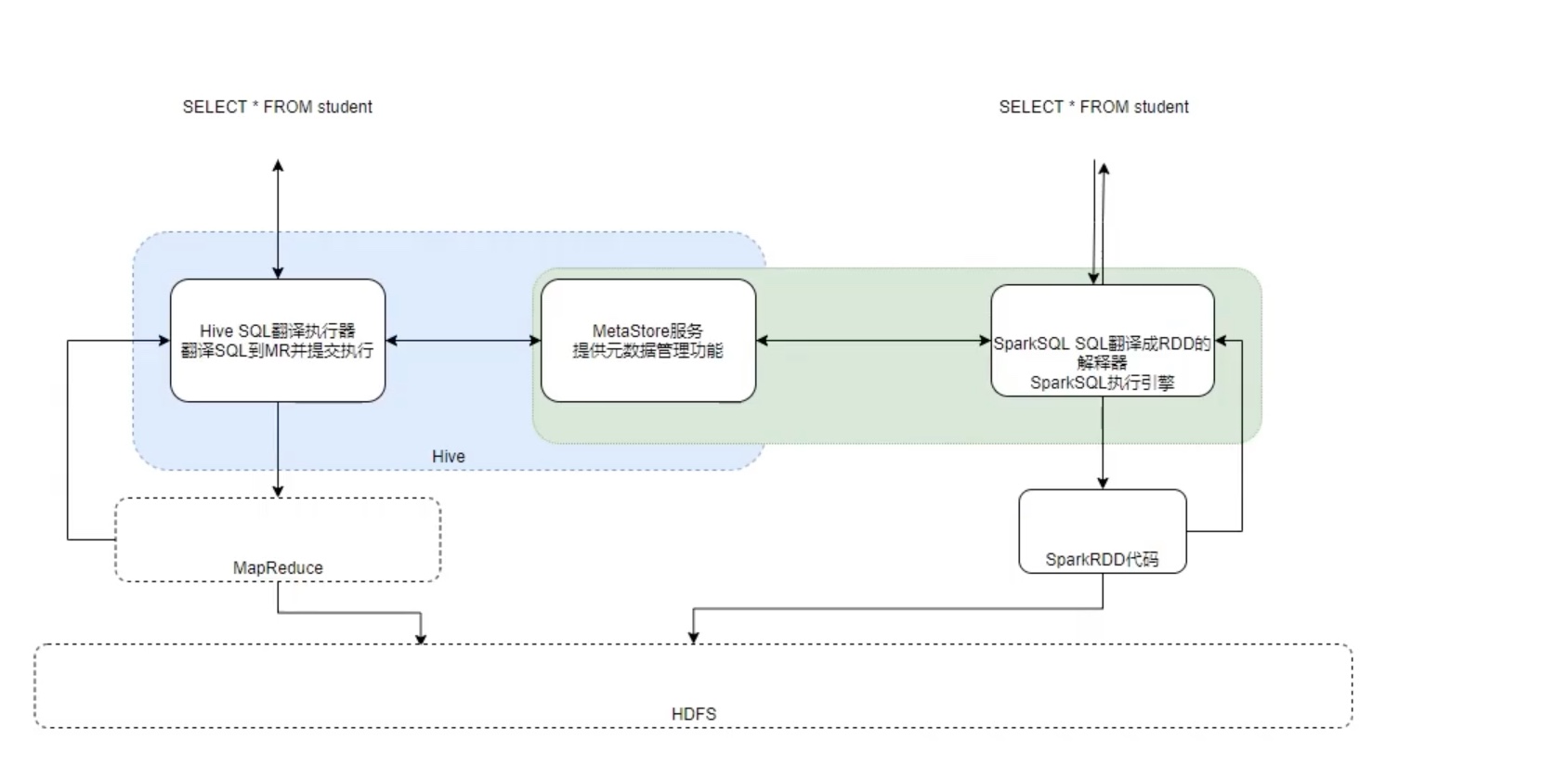
Spark on Hive
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 步骤一: 来到spark的conf 文件夹内。新建一个 hive-site.xml cd /opt/spark/spark/conf vim hive-site.xml <configuration> <property> <!--# 配置metastore的默认hdfs文件夹位置 --> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <!-- # 配置 metastore 的连接协议和端口,我的hive在node01机器上 --> <name>hive.metastore.uris</name> <value>thrift://node01:9083</value> </property> </configuration>
1 2 3 4 5 # 步骤二: 给spark 导入 驱动mysql 的jar包。 # (之前hive配置和sparksql 读写jdbc数据都导入过mysql的java驱动包,都是位置一个是在hive中一个是在conda的pyspark虚拟环境中,这次我们直接给spark内导入mysql的java驱动包) cd /opt/spark/spark/jars ll | grep mysql # 可见现在还没有mysql的java驱动包。 cp mysql-connector-java-8.0.25.jar /opt/spark/spark/jars/
1 2 3 4 5 6 7 8 9 10 11 12 # 步骤三:在hive中 配置metastore的 属性,配置metasore服务(以thrift协议打开9083端口)。 cd /opt/hive/apache-hive-3.1.2-bin/conf vim hive-site.xml <configuration> <!--远程模式部署metastore服务地址,hive就安装在node01上,用thrift协议对外,端口 9083 --> <property> <name>hive.metastore.uris</name> <value>thrift://node01:9083</value> </property> </configuration>
1 2 3 4 # 步骤四:打开 metastore 服务。 cd /opt/hive/apache-hive-3.1.2-bin/bin nohup hive --service metastore & netstat -anp | grep 9083 # 可见 listen 此端口已经被监听了。
经过了上面的配置,且开启了hive 的 metastore 服务之后。我们可以试一试直接在spark的pyspark内 调用元数据写代码了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # (一)在pyspark内 实验 spark on hive # 先在Hadoop开启hdfs服务。(hdfs所有机器都打开) cd /opt/hadoop/hadoop/sbin start-all.sh # 进入虚拟环境 ,打开pyspark。 conda activate pyspark cd /opt/spark/spark/bin pyspark # 在pyspark 内直接用sql语句。新建一个表。 spark.sql('create table sparkinhive(id int)') spark.sql('create table students(id int,name string)') # 若不用 pyspark ,直接用 spark-sql ,可以直接用sql语句去操作。 spark-sql insert into students values(1,'zhangsan'),(2,'wanwu'); # 我们回到hive 中,检查是否出现了 一个叫 sparkinhive的表。 hive show tables; # 可见刚刚用sparksql 新建的 sparkinhive 表,也在hive 默认的库中。这说明 sparksql和hive 公用了一套元数据metastore。但是 sparksql 底层是用 spark 的rdd来计算的,而hive 底层是 mapreduce 来计算的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import stringfrom pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType,IntegerType,StringType,ArrayTypefrom pyspark.sql import functions as Fif __name__=='__main__' : spark = SparkSession.builder.appName('test' ). \ config('spark.sql.warehouse.dir' ,'hdfs://node01:9000/user/hive/warehouse' ).\ config('hive.metastore.uris' ,'thrift://node01:9083' ).\ enableHiveSupport().\ master('local[*]' ).getOrCreate() sc = spark.sparkContext spark.sql('select * from students' ).show()
1 2 3 4 5 6 7 +---+--------+ | id | name| +---+--------+ | 1 |zhangsan| | 2 | wanwu| +---+--------+
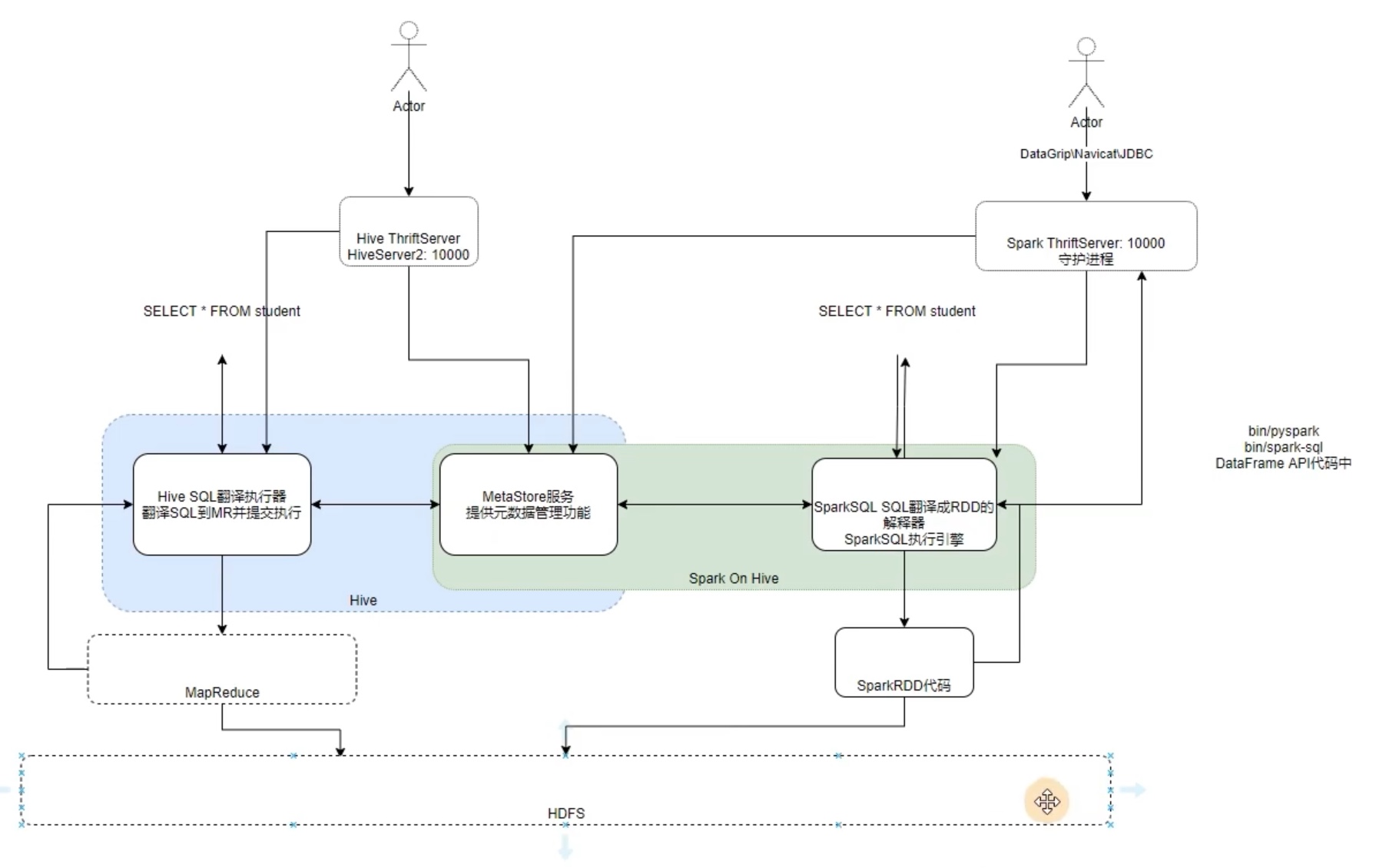
分布式SQL 执行引擎 (简述就是降低门槛,仅用sql操作sparkSQL)
其实类似于 hive的 hiveserver2 。就是让纯sql 代码调用 metastore 更加方便直观。
在已经配置好 spark on hive 之后,只需要启动 ThriftServer 即可 实现 hiveserver2一样的效果。
1 2 3 4 cd /opt/spark/spark/sbin start-thriftserver.sh --hiveconf hive.server2.thrift.port=10000 --hiveconf hive.server2.thrift.bind.host=node01 --master local[*] netstat -anp | grep 10000 # 可以看见10000端口正在被监听。
thriftserver 服务打开之后, 就像之前hive 学习时,用idea利用hiveserver2 登录元数据库一样,thriftserver 用法一样,一些软件可利用它连接到 元数据库,比如 datagrip、heidisql等等软件,目的是实现 纯 sql 编程,但是底层是spark的 rdd在跑,保证了 性能 与 编程的简单。
下载一个pyhive ,就可以用 jdbc 协议 连接 thriftserver。
1 2 3 4 5 yum -y install cyrus-sasl cyrus-sasl-devel cyrus-sasl-lib pip install sasl -i https://pypi.tuna.tsinghua.edu.cn/simple pip install thrift -i https://pypi.tuna.tsinghua.edu.cn/simple pip install thrift-sasl -i https://pypi.tuna.tsinghua.edu.cn/simple pip install pyhive -i https://pypi.tuna.tsinghua.edu.cn/simple
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pyhive import hiveif __name__=='__main__' : conn = hive.Connection(host='node01' ,port=10000 ,username='root' ) cursor = conn.cursor() cursor.execute('select * from students' ) result = cursor.fetchall() print (result) [(1 , 'zhangsan' ), (2 , 'wanwu' )]
实际上就是 让仅仅懂sql 的人也能 用上 spark 的计算 和 hive 的元数据。降低使用门槛。
综合练习
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 from pyspark.sql import SparkSessionfrom pyspark.sql import functions as Ffrom pyspark.storagelevel import StorageLevelfrom pyspark.sql.types import StringType''' demand 1: 每个省份销售额统计 demand 2: top3 销售额的省份中,有多少家店铺 存在日销售额>1000的情形? demand 3: top3 销售额的省份中,平均单价。 demand 4: top3 销售额的省份中,各个省份支付类型比例。 receivalbe: 销售额 storeProvince: dateTS: 时间 payType: 支付类型 storeID: 操作: 写出结果到mysql; 写出结果到 hive库。 ''' if __name__=='__main__' : spark = SparkSession.builder.appName('sparksql_example' ). \ master('local[*]' ). \ config('spark.sql.shuffle.partitions' ,'2' ). \ config('spark.sql.warehouse.dir' ,'hdfs://node01:9000/user/hive/warehouse' ). \ config('hive.metastore.uris' ,'thrift://node01:9083' ). \ enableHiveSupport(). \ getOrCreate() df = spark.read.format ('json' ). \ load('file:///home/chenyushao/Documents/spark测试数据/minimini.json' ). \ dropna(thresh=1 ,subset=['storeProvince' ]). \ filter ("storeProvince != 'null'" ). \ select('storeProvince' ,'storeID' ,'receivable' ,'dateTS' ,'payType' ) province_sale_df = df.groupBy('storeProvince' ).sum ('receivable' ). \ withColumnRenamed('sum(receivable)' ,'money' ). \ withColumn('money' ,F.round ('money' ,2 )). \ orderBy('money' ,ascending=False ) province_sale_df.show() province_sale_df.write.mode('overwrite' ).\ format ('jdbc' ).\ option('url' ,'jdbc:mysql://node01:3306/spark_databases?useSSL=false&useUnicode=true' ).\ option('dbtable' ,'province_sale_table' ).\ option('user' ,'root' ).\ option('password' ,'密码' ).\ option('encoding' ,'utf-8' ).\ save() province_sale_df.write.mode('overwrite' ).saveAsTable('province_sale_table' ,'parquet' ) top3_province_df = province_sale_df.limit(3 ).select('storeProvince' ).\ withColumnRenamed('storeProvince' ,'top3_storeProvince' ) top3_province_joined_df = df.join(top3_province_df,on = df['storeProvince' ] ==top3_province_df['top3_storeProvince' ]) top3_province_joined_df.show() top3_province_joined_df.persist( StorageLevel.MEMORY_AND_DISK) province_over1000_storenum = top3_province_joined_df.groupBy('storeProvince' ,'storeID' , F.from_unixtime(df['dateTS' ].substr(0 ,10 ),'yyyy-MM-dd' ).alias('day' )).\ sum ('receivable' ).withColumnRenamed('sum(receivable)' ,'money' ).\ filter ('money > 1000' ).\ dropDuplicates(subset=['storeProvince' ,'storeID' ]).\ groupBy('storeProvince' ).count() province_over1000_storenum.write.mode('overwrite' ).\ format ('jdbc' ).\ option('url' ,'jdbc:mysql://node01:3306/spark_databases?useSSL=false&useUnicode=true' ).\ option('dbtable' ,'province_over1000_storenum_table' ).\ option('user' ,'root' ).\ option('password' ,'密码' ).\ option('encoding' ,'utf-8' ).\ save() province_over1000_storenum.write.mode('overwrite' ).saveAsTable('province_over1000_storenum_table' ,'parquet' ) province_over1000_storenum.show() top3_province_order_avg_df = top3_province_joined_df.groupBy('storeProvince' ).\ avg('receivable' ).withColumnRenamed('avg(receivable)' ,'money' ).\ withColumn('money' ,F.round ('money' ,2 )).\ orderBy('money' ,ascending=False ) top3_province_order_avg_df.show() top3_province_order_avg_df.write.mode('overwrite' ). \ format ('jdbc' ). \ option('url' ,'jdbc:mysql://node01:3306/spark_databases?useSSL=false&useUnicode=true' ). \ option('dbtable' ,'top3_province_order_avg_table' ). \ option('user' ,'root' ). \ option('password' ,'密码' ). \ option('encoding' ,'utf-8' ). \ save() top3_province_order_avg_df.write.mode('overwrite' ).saveAsTable('top3_province_order_avg_table' ,'parquet' ) top3_province_joined_df.createTempView('province_pay' ) def udf_func (percent ): return str (round (percent*100 ,2 ))+'%' percent_udf = F.udf(udf_func,StringType()) pay_type_df = spark.sql(''' select storeProvince,payType,(count(payType)/total) as percent_paytype from (select storeProvince,payType,count(1) over(partition by storeProvince) as total from province_pay) group by storeProvince, payType, total ''' ).withColumn('percent_paytype' ,percent_udf('percent_paytype' )) pay_type_df.show() pay_type_df.write.mode('overwrite' ). \ format ('jdbc' ). \ option('url' ,'jdbc:mysql://node01:3306/spark_databases?useSSL=false&useUnicode=true' ). \ option('dbtable' ,'pay_type_df_table' ). \ option('user' ,'root' ). \ option('password' ,'密码' ). \ option('encoding' ,'utf-8' ). \ save() pay_type_df.write.mode('overwrite' ).saveAsTable('pay_type_df_table' ,'parquet' ) top3_province_joined_df.unpersist()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 demand 1 : +--------------+--------+ | storeProvince| money| +--------------+--------+ | 湖南省|24088.95 | | 广东省| 13235.0 | |广西壮族自治区| 515.5 | | 江苏省| 308.0 | | 北京市| 53.0 | +--------------+--------+ -------------------------------------------------------------------------------- demand 2 : 2022 -04-20 02:50 :55 ,428 WARN util.package: Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.sql.debug.maxToStringFields' .2022 -04-20 02:50 :57 ,157 WARN conf.HiveConf: HiveConf of name hive.metastore.event.db.notification.api.auth does not exist2022 -04-20 02:50 :59 ,851 WARN session.SessionState: METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory.+--------------+-------+----------+-------------+-------+------------------+ | storeProvince|storeID|receivable| dateTS|payType|top3_storeProvince| +--------------+-------+----------+-------------+-------+------------------+ | 湖南省| 4064 | 22.5 |1563758583000 | alipay| 湖南省| | 湖南省| 718 | 7.0 |1546737450000 | alipay| 湖南省| | 湖南省| 1786 | 10.0 |1546478081000 | cash| 湖南省| | 广东省| 3702 | 10.5 |1559133703000 | wechat| 广东省| |广西壮族自治区| 1156 | 10.0 |1548594458000 | cash| 广西壮族自治区| | 广东省| 318 | 3.0 |1548292824000 | wechat| 广东省| | 湖南省| 1699 | 6.5 |1545356344000 | cash| 湖南省| | 湖南省| 1167 | 17.0 |1547284514000 | alipay| 湖南省| | 湖南省| 3466 | 19.0 |1563845059000 | cash| 湖南省| | 广东省| 333 | 4.0 |1557231358000 | wechat| 广东省| | 湖南省| 3354 | 22.0 |1560692925000 | cash| 湖南省| | 广东省| 3367 | 19.0 |1552019799000 | cash| 广东省| | 湖南省| 832 | 45.0 |1563413959000 | wechat| 湖南省| | 湖南省| 949 | 6.0 |1565683992000 | cash| 湖南省| | 广东省| 4213 | 22.5 |1561301033000 | cash| 广东省| | 广东省| 3487 | 6.0 |1563104184000 | cash| 广东省| | 湖南省| 2583 | 900.0 |1557558714000 | cash| 湖南省| | 广东省| 3561 | 215.0 |1552703028000 | cash| 广东省| | 湖南省| 1975 | 15.0 |1560845929000 | cash| 湖南省| | 广东省| 389 | 72.0 |1542464496000 | cash| 广东省| +--------------+-------+----------+-------------+-------+------------------+ only showing top 20 rows +-------------+-----+ |storeProvince|count| +-------------+-----+ | 湖南省| 3 | +-------------+-----+ -------------------------------------------------------------------------------- demand 3 : +--------------+-----+ | storeProvince|money| +--------------+-----+ |广西壮族自治区|51.55 | | 湖南省|49.98 | | 广东省|26.36 | +--------------+-----+ demand 4 : +--------------+--------+---------------+ | storeProvince| payType|percent_paytype| +--------------+--------+---------------+ | 广东省| wechat| 39.04 %| | 广东省| cash| 52.19 %| | 广东省|bankcard| 0.6 %| | 广东省| alipay| 8.17 %| |广西壮族自治区| cash| 80.0 %| |广西壮族自治区| wechat| 10.0 %| |广西壮族自治区| alipay| 10.0 %| | 湖南省| alipay| 4.77 %| | 湖南省| cash| 68.05 %| | 湖南省| wechat| 26.97 %| | 湖南省|bankcard| 0.21 %| +--------------+--------+---------------+
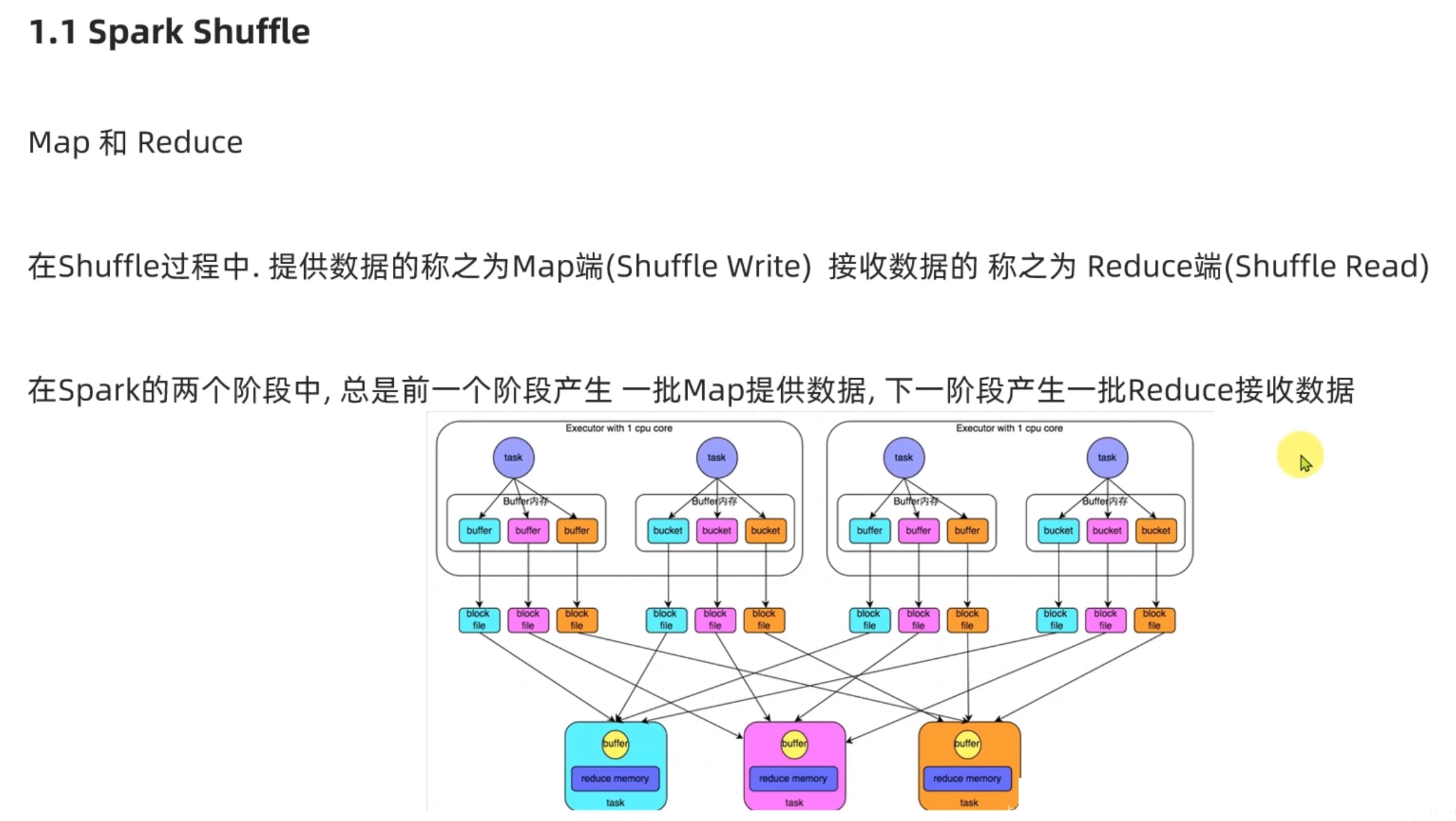
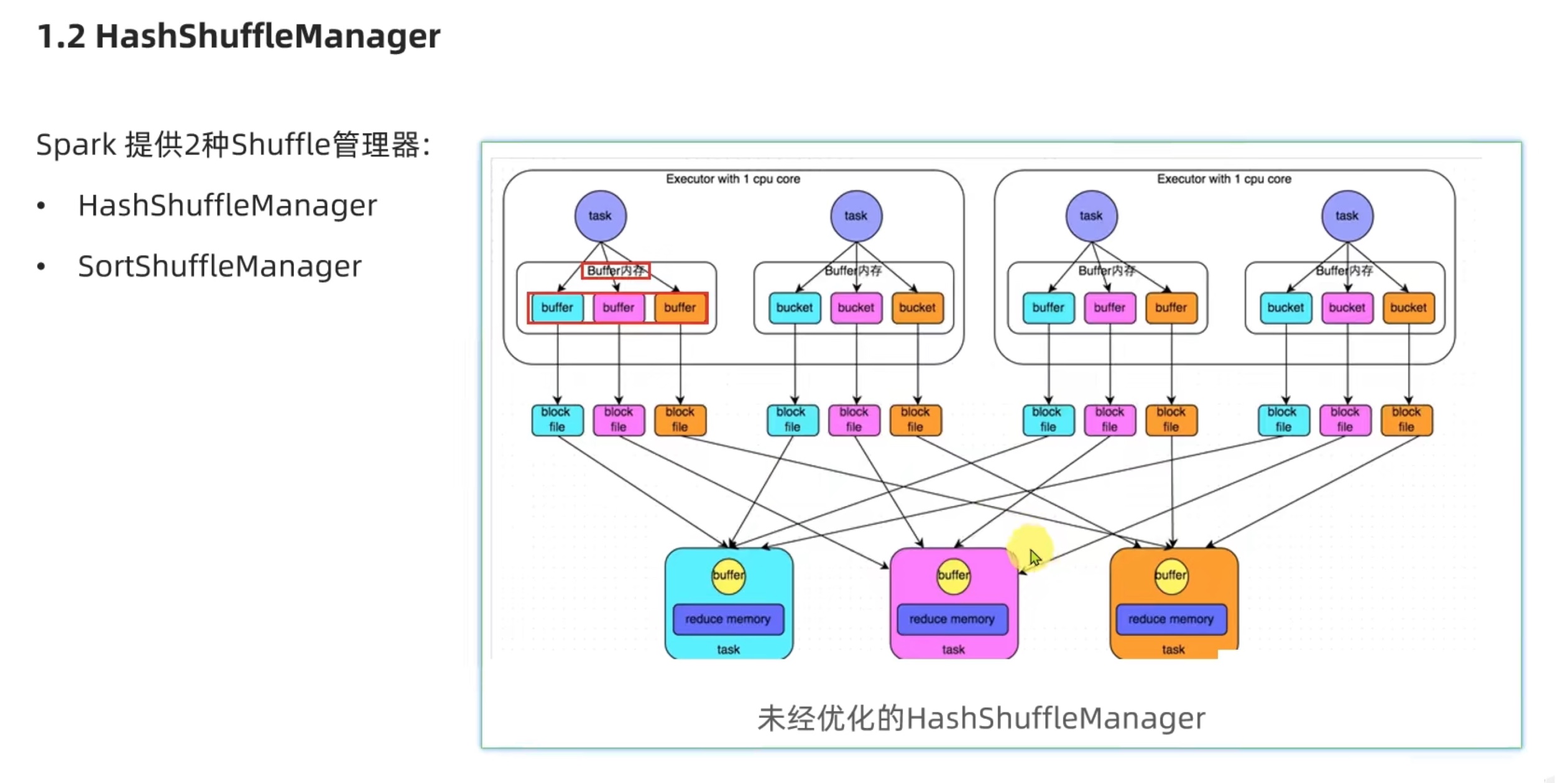
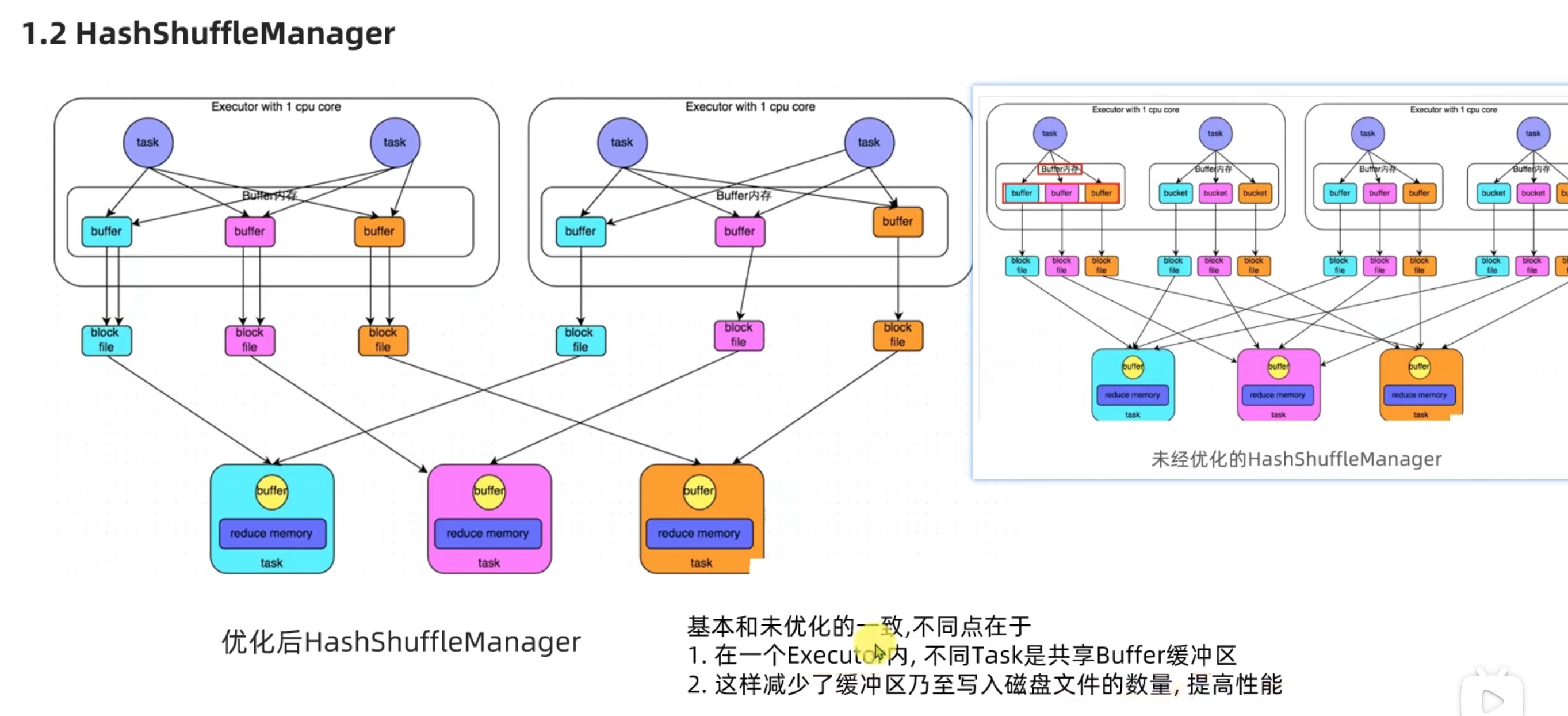
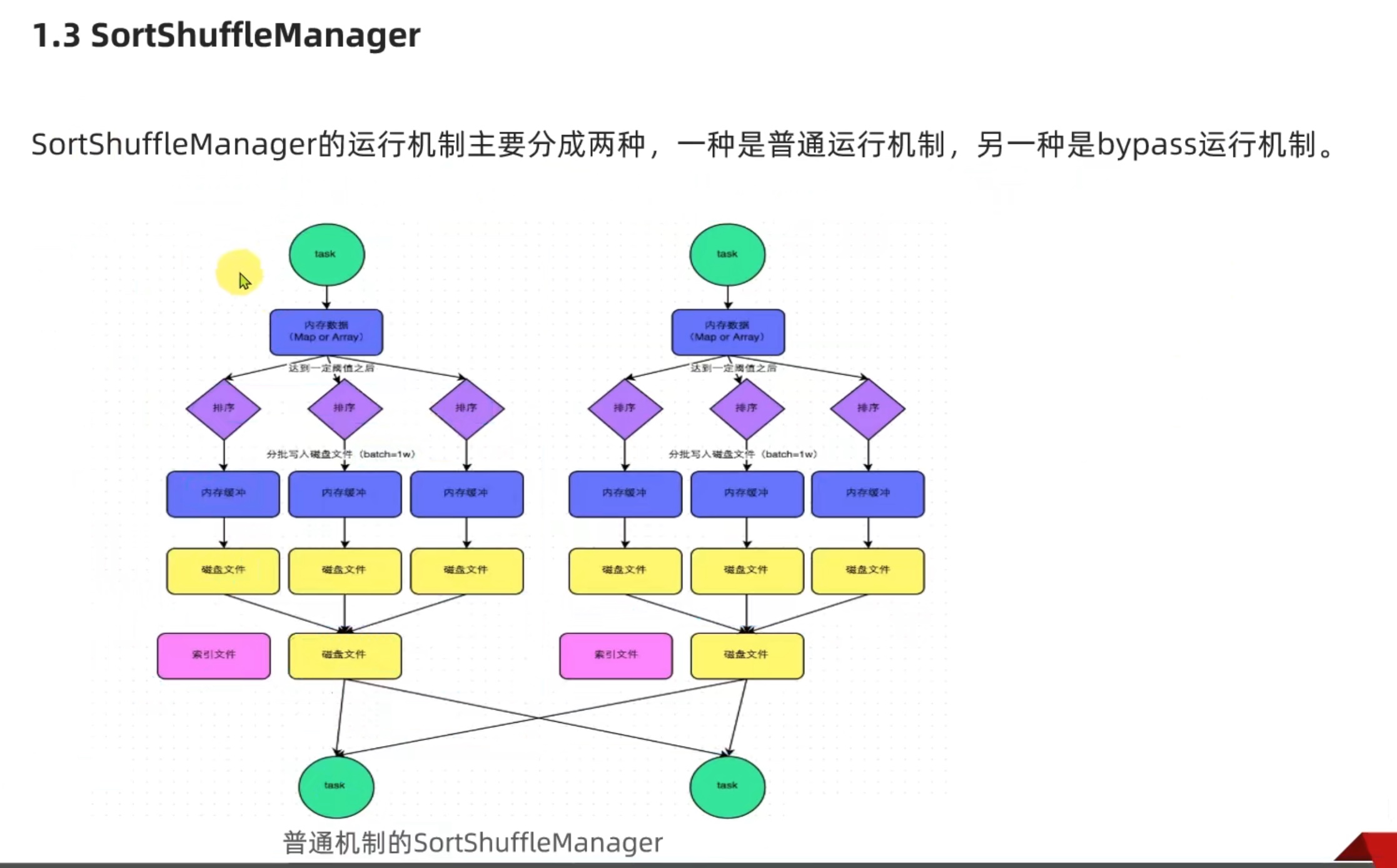
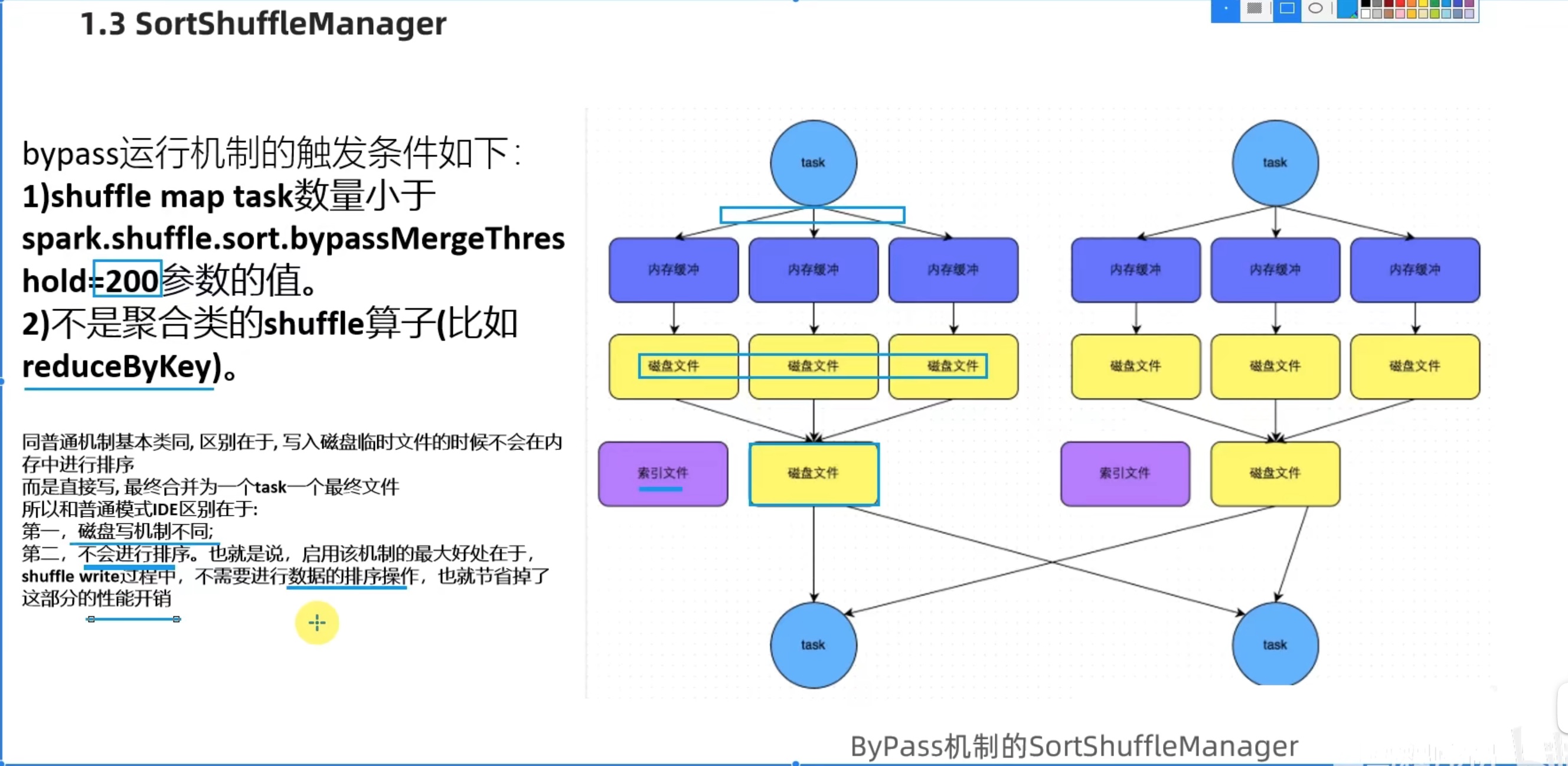
Spark新特性 及 核心回顾 shuffle
可以看出sort shufflemanager 优于 hash shufflemanager。io更少。也是spark后续改良的产物。
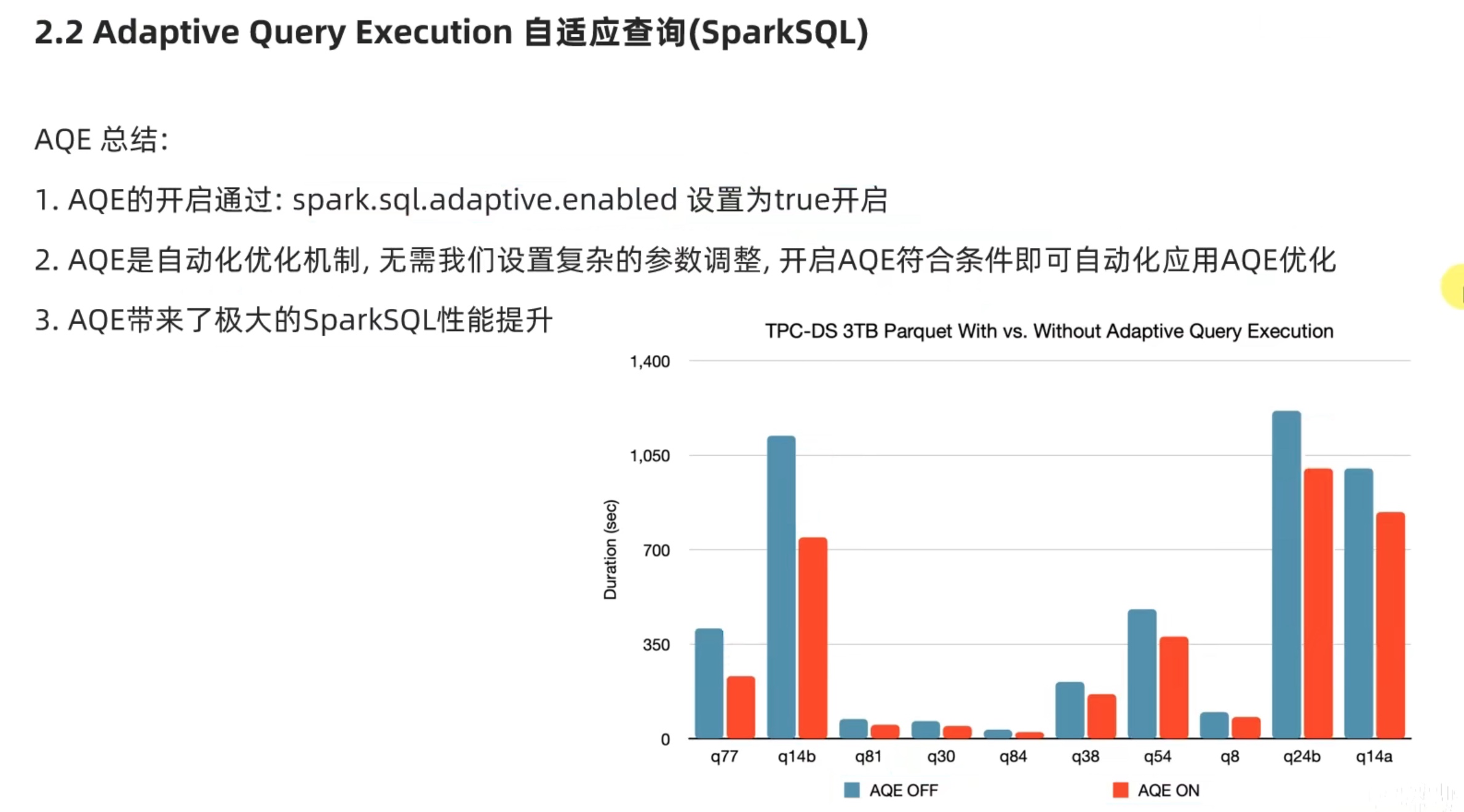
新特性 自适应查询
这个自适应查询 有点像 之前hive 学习中 各种自动优化的设置,打开开关或者再conf配置文件中配置就行。
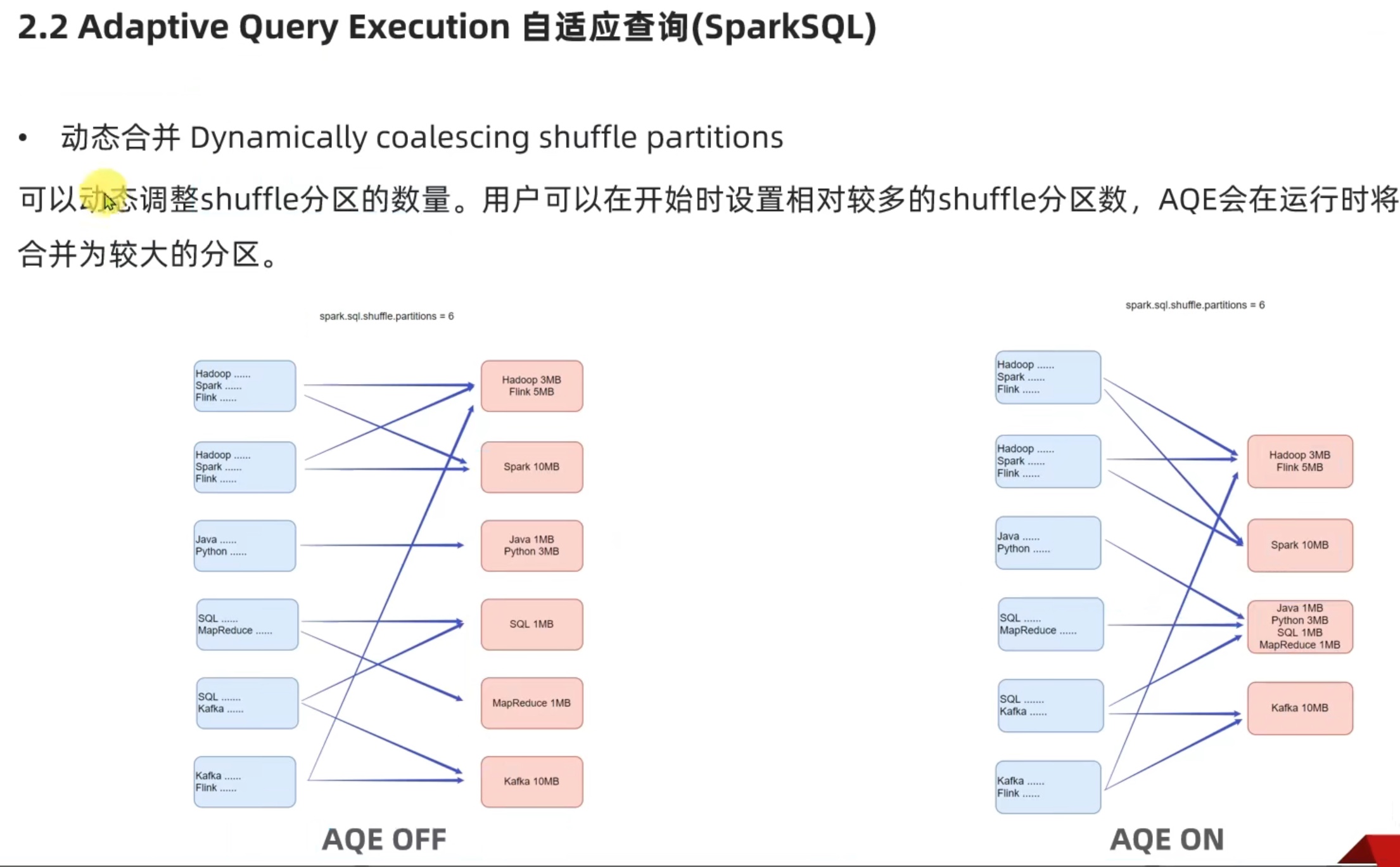
1、动态合并
动态合并,把几个小分区合并,让每个分区大小差不多,让数据量均衡。
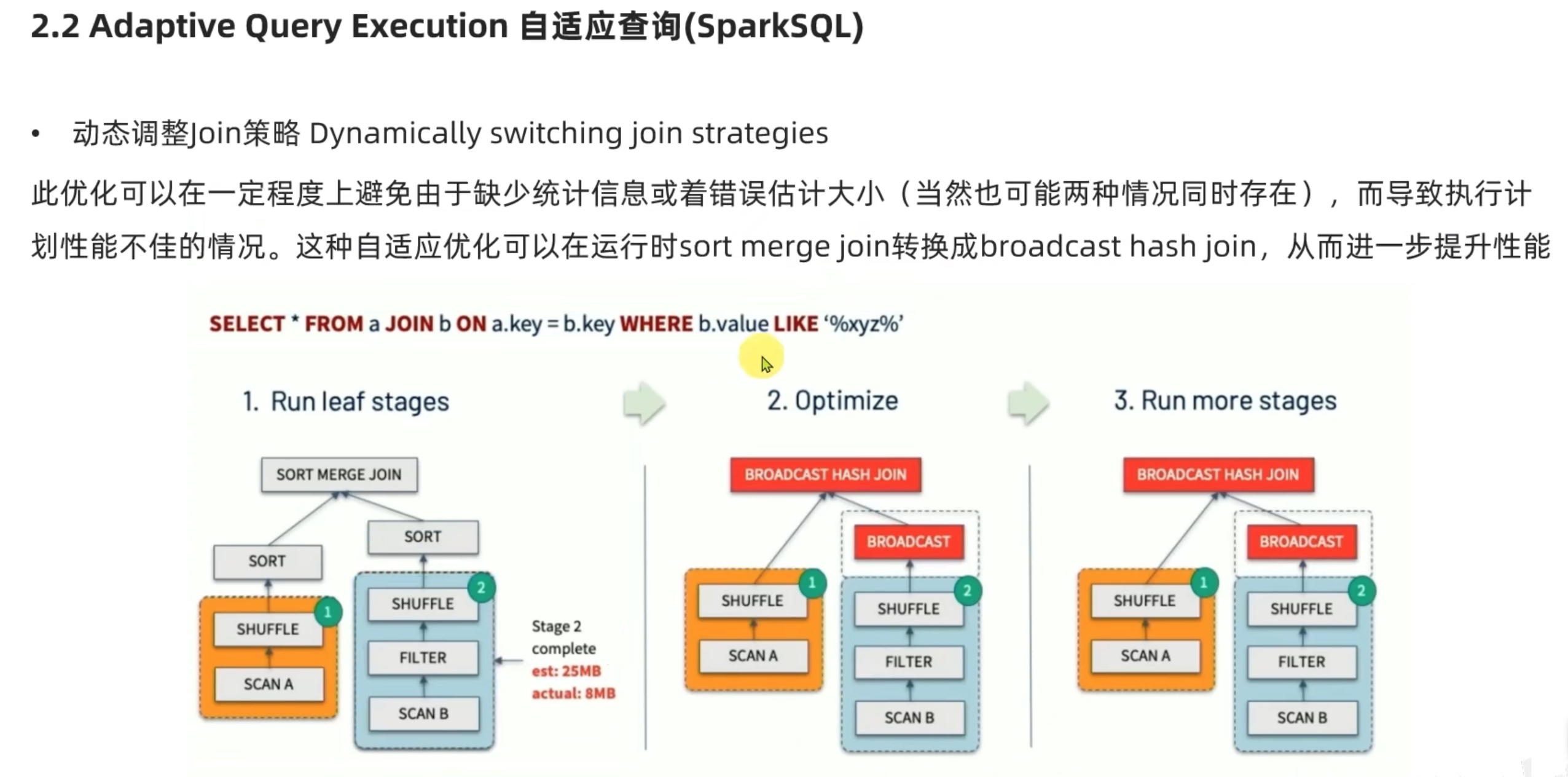
2、动态 join 策略
上图意思是:
语法树本来要做的是 将 两个分区内 sort ,再 将两个数据集的内容作 join 操作。
但是预想 数据集2 大小是25m,实际上 数据集2 大小是8m,太小了。
所以动态将策略调整 –>>( 取消数据集2内的sort操作,直接把数据集2这么一点点数据以广播方式,广播到数据集1相关的executor内,数据集1相关的executor得到一份完整的数据集2数据,再在数据集1所在的executor内部作join操作;之所以能这样搞,因为数据集2内东西非常少,相当于集中到一个executor内把活都干了,避免io资源浪费。)。
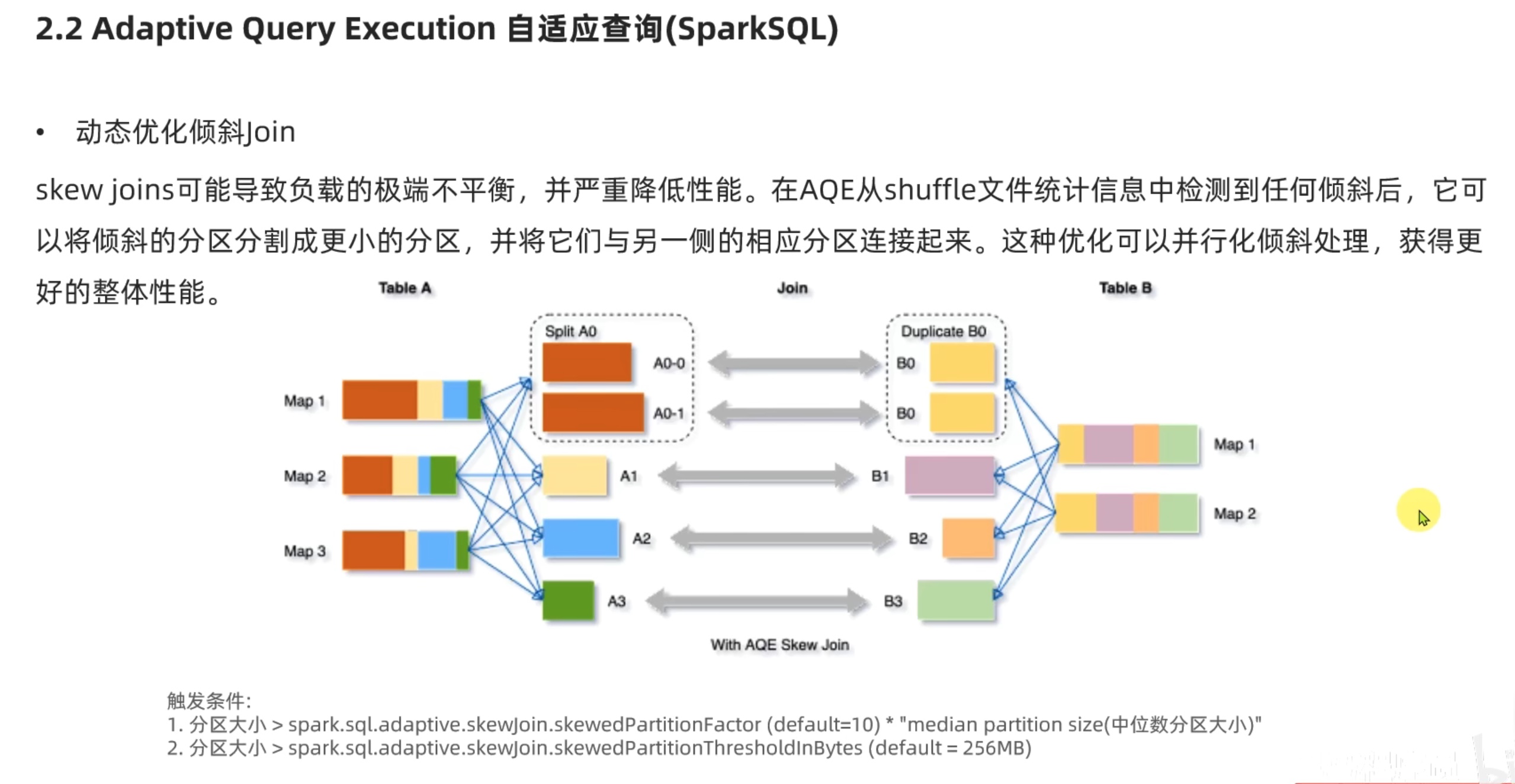
3、动态优化倾斜join
上图解释:
按道理说,红、黄、蓝、绿 四种数据 在经过了shuffle 后会分成 红、黄、蓝、绿 四个分区,但是由于红 数据量太大了,如果把红 只放一个分区,会造成严重的数据倾斜,所以我们把红数据 拆分成 两个 分区,这样 红1、红2、黄、蓝、绿 这5个分区大小都差不多,缓解了数据倾斜;
红1、红2 两个分区 在 pipline内存计算管道 内一样享受 高性能的 并行计算,在下一次的shuffle中 还是按照原来的 (红、黄、蓝、绿)衍生色(黄、紫、橙、绿)来进入一个分区,这样就会出现两个分区(红1、黄、蓝、绿)衍生色(黄1、紫、橙、绿)、(红2、黄、蓝、绿)衍生色(黄2、紫、橙、绿)。
这样一来,pipline 内从左到右的 计算时间 会大致相同,从而提高了计算效率。
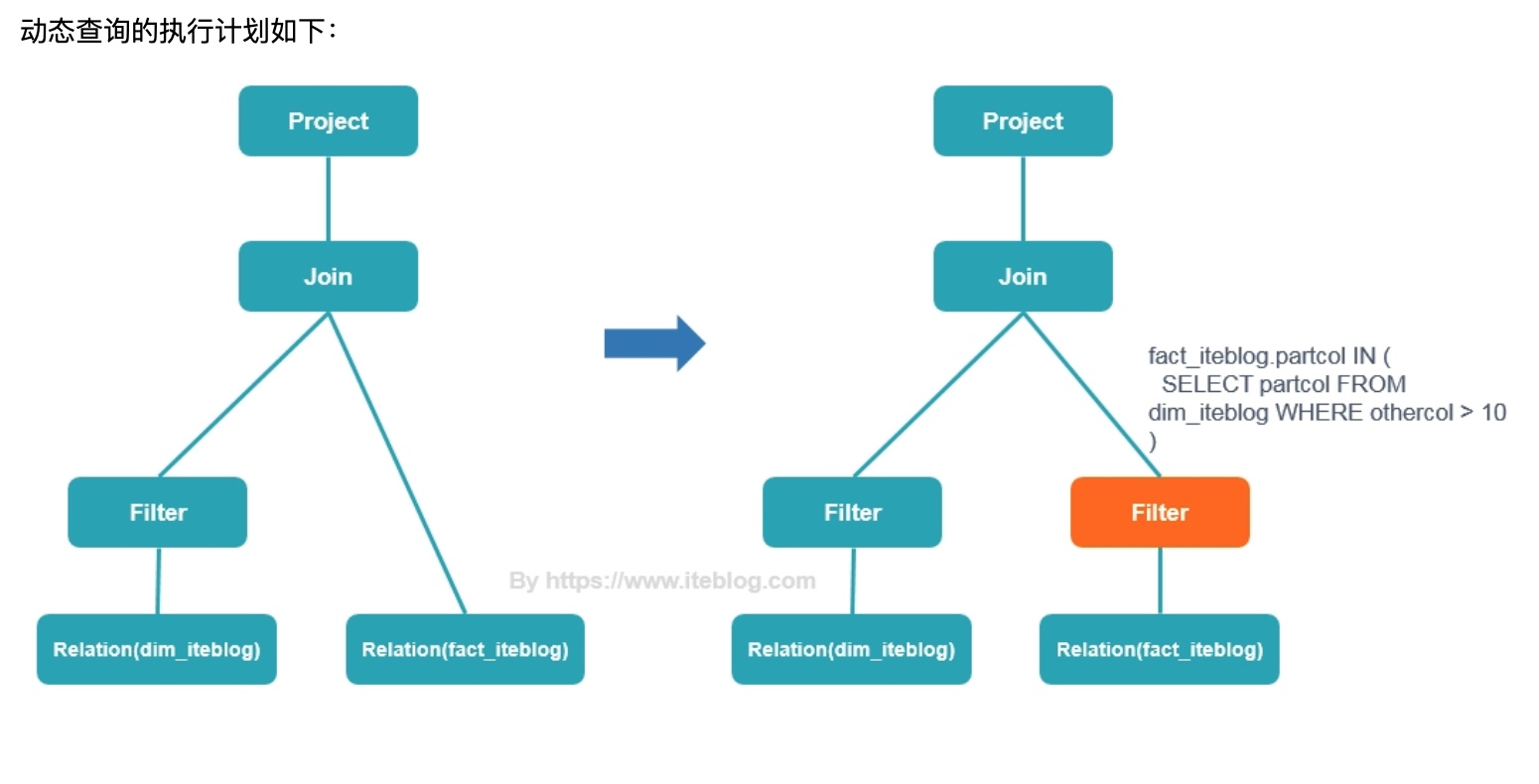
动态分区裁剪 dynamic partition pruning,部分条件下性能提升巨大!!!这是spark3.0的重大改进(自动优化无需配置)。
我们回顾一下 static pruning静态裁剪,就是将过滤条件前置、或者提前列值裁剪,那动态裁剪 动态在哪呢?我们看一个案例。
1 2 3 4 SELECT * FROM dim_iteblog JOIN fact_iteblog ON (dim_iteblog.partcol = fact_iteblog.partcol) WHERE dim_iteblog.othercol > 10
左图为 静态裁剪 优化的执行计划,右图为动态裁剪优化的执行计划。
通俗来解释就是:
有a、b两个表 join,但是where 过滤条件 仅仅针对 其中a表!!!
如果按静态裁剪 就是先对有过滤要求的a表过滤,再join b表。
动态裁剪 聪明之处在于,考虑到 join on 后的条件,b表势必会受到a表过滤后数据的影响,所以b表针对a表的过滤结果,也提前过滤b表的数据,实际让join之前 a、b两张表都精简了很多。
例如:join on 的条件是 a.id=b.id ,a.id in(1,2),b.id in(1,2,5,6,7,9),a经过where过滤后 仅剩 a.id in(1),b 针对 a 的过滤结果 也提前过滤一遍,得到 b.id in(1),过滤掉了2,5,6,7,9,实际就是 a.id=1 和 b.id=1 join。笛卡尔积被大量精简,性能得到巨大提升!!!
koalas koalas 就是 让pandas 借用spark 实现 分布式计算的一个包,方便只会pandas的人用spark。
这里不多介绍了,比较简单就能完成,下载包再按pandas写代码就行。