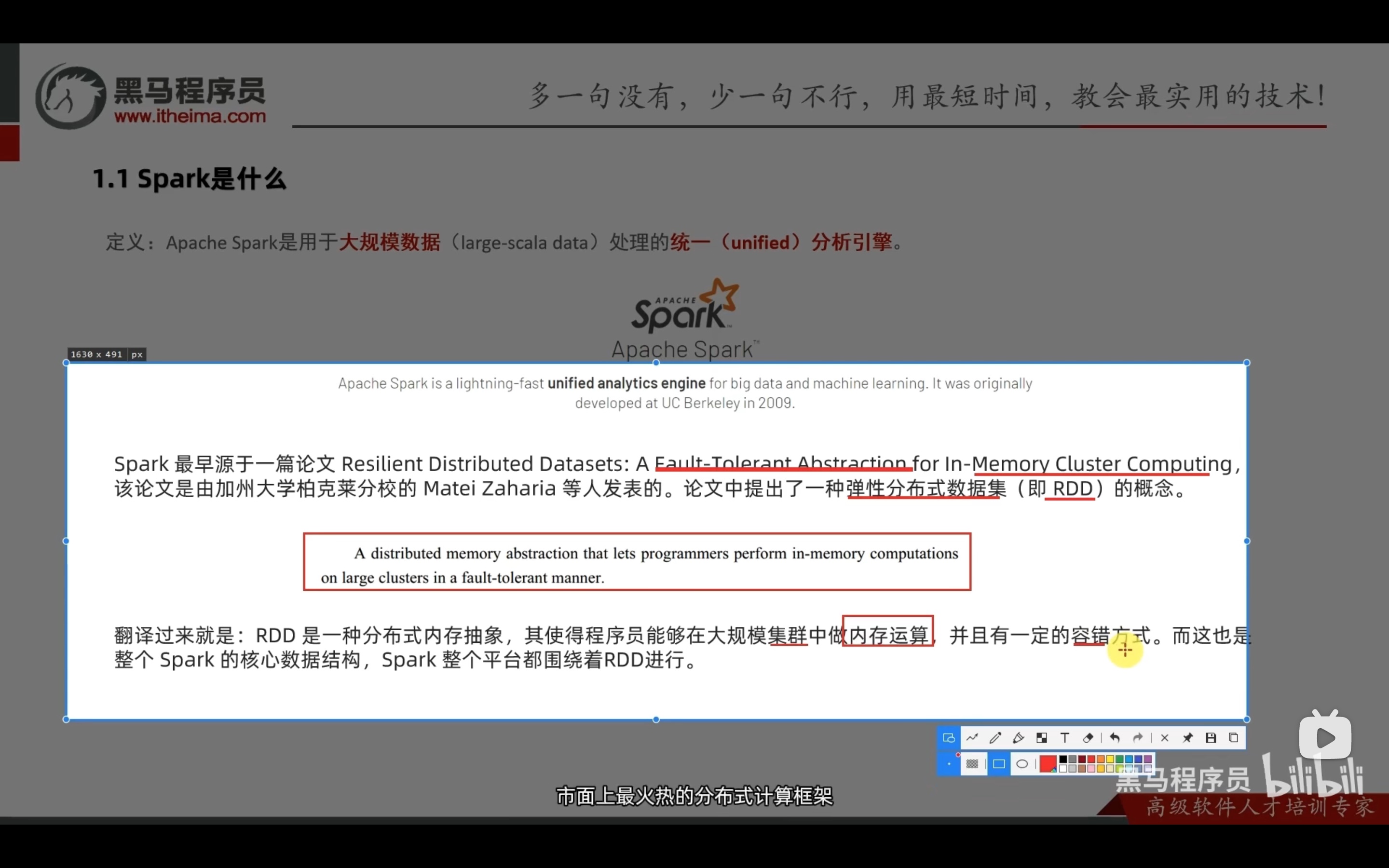
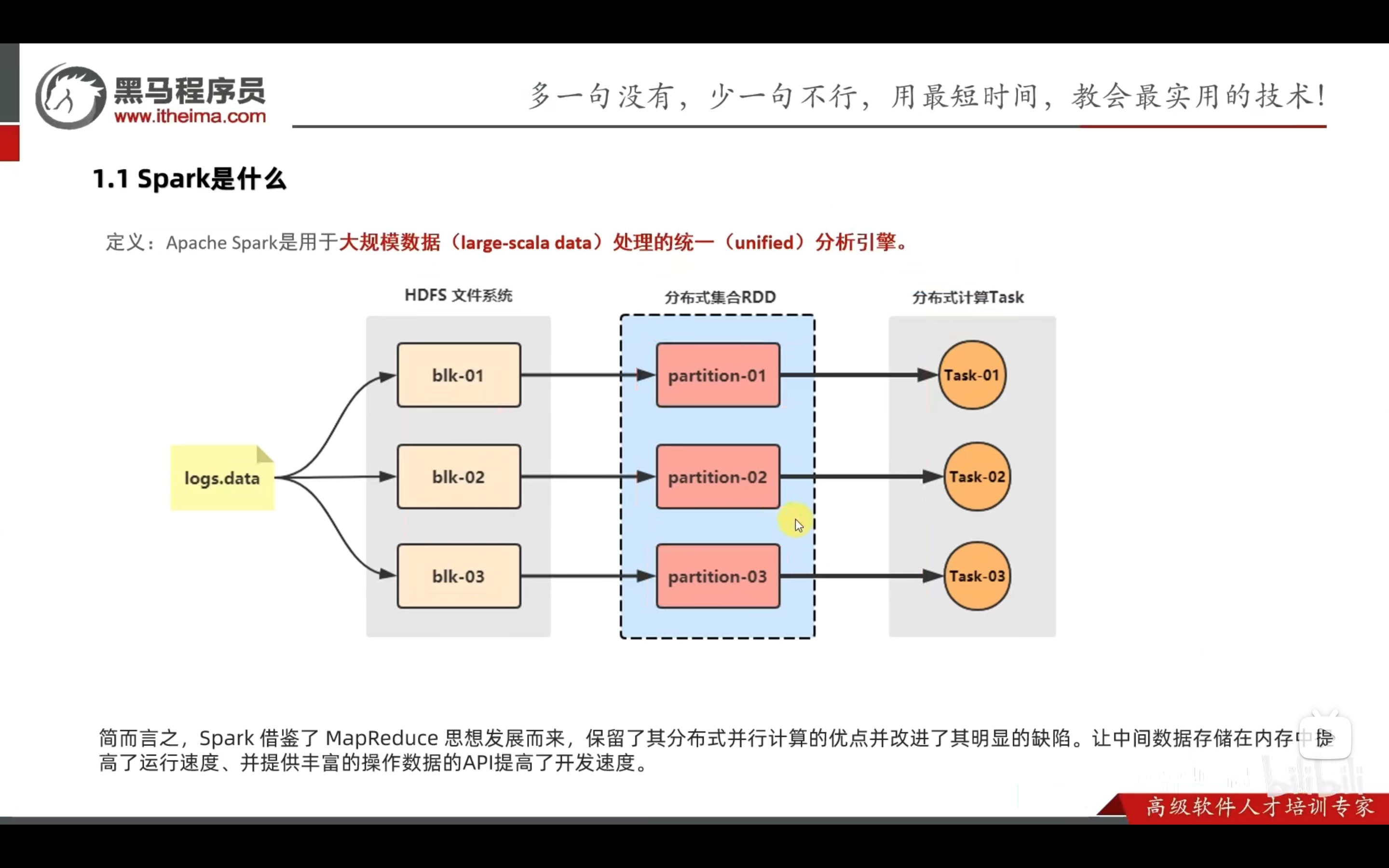
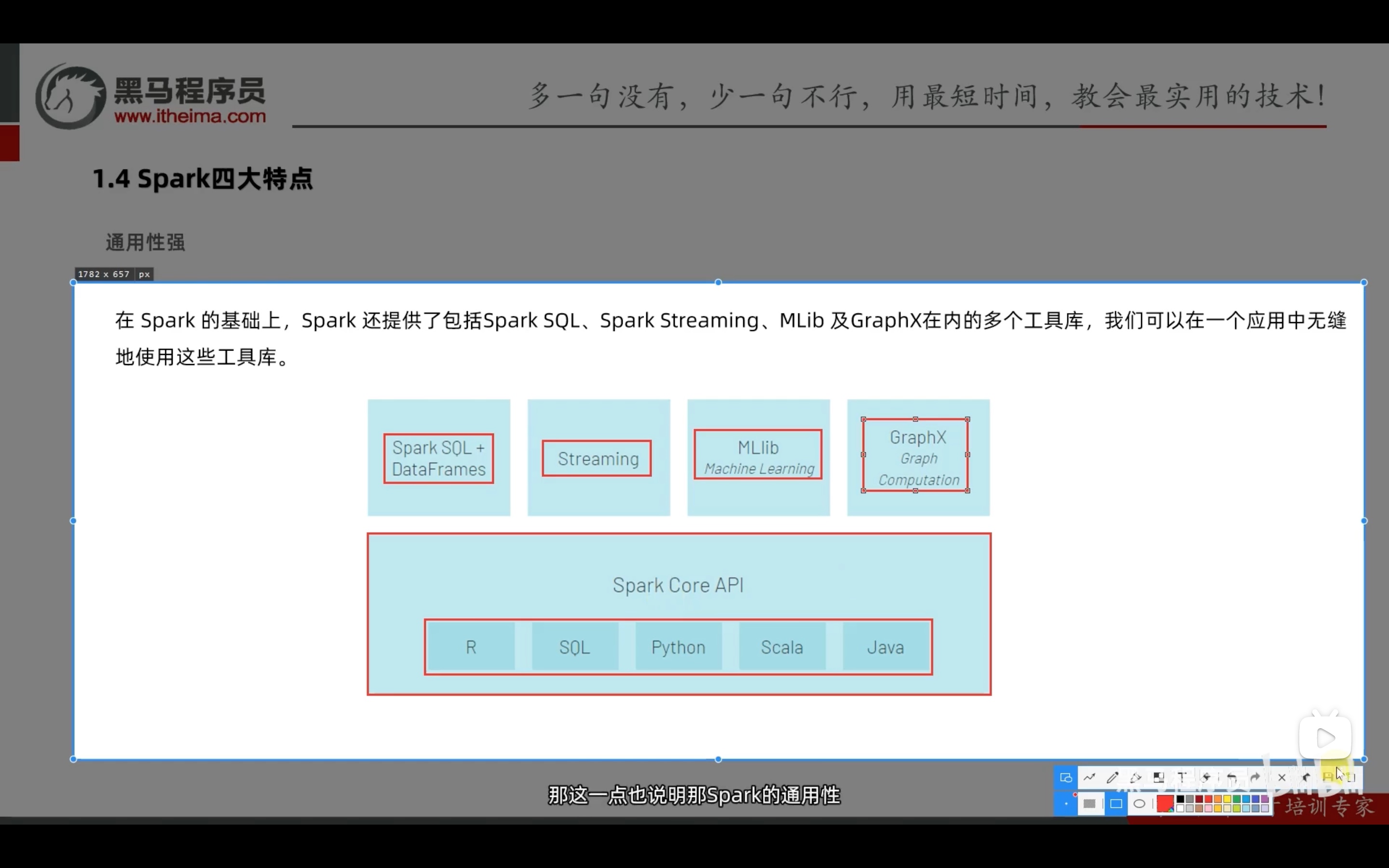
简介
说人话就是 ,spark 仅仅替代了 mapreduce 计算框架。
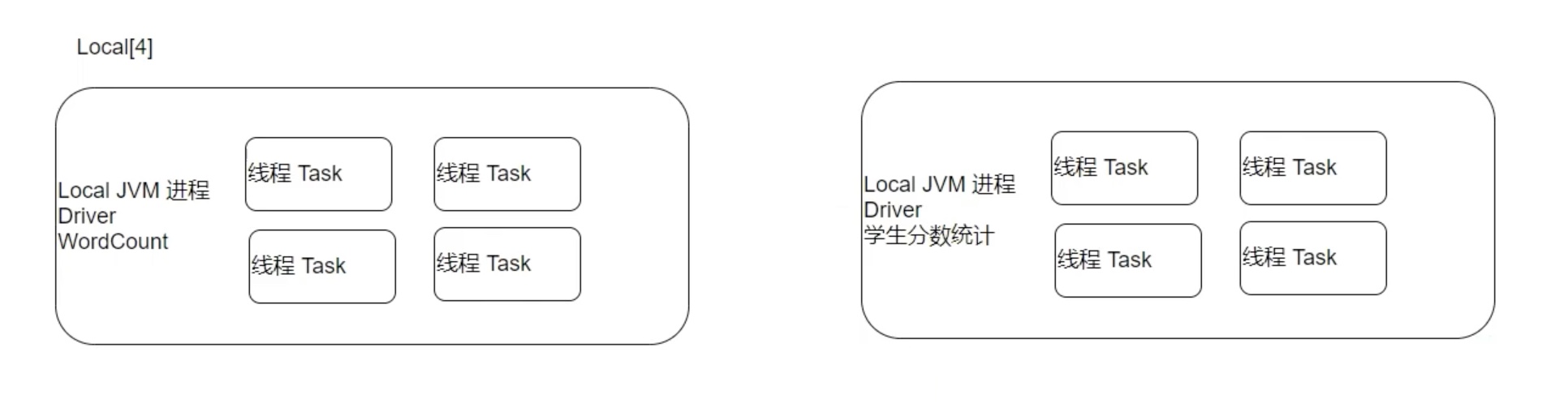
local模式下,一个local进程只负责一个任务,用进程中的多个线程来模拟集群干活。local[4] 就是在开4个线程。上图中单词计数和学生分数统计 两个任务其实是开启了两个local模式下的进程,一共8个线程。
安装部署 在已经安装部署好了Hadoop和hive、mysql的基础上,我们来安装spark,但是这里我先安装一个anaconda来让后续工作更方便的开展。
1 2 3 sh Anaconda3-2021.05-Linux-x86_64.sh
修改anaconda的源为国内源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 vim ~/.condarc channels: - defaults show_channel_urls: true default_channels: - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2 custom_channels: conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
创建一个python3.8的环境,名字叫pyspark。我的anaconda下python是3.8.8
1 2 3 conda create -n pyspark python=3.8 conda activate pyspark conda deactivate
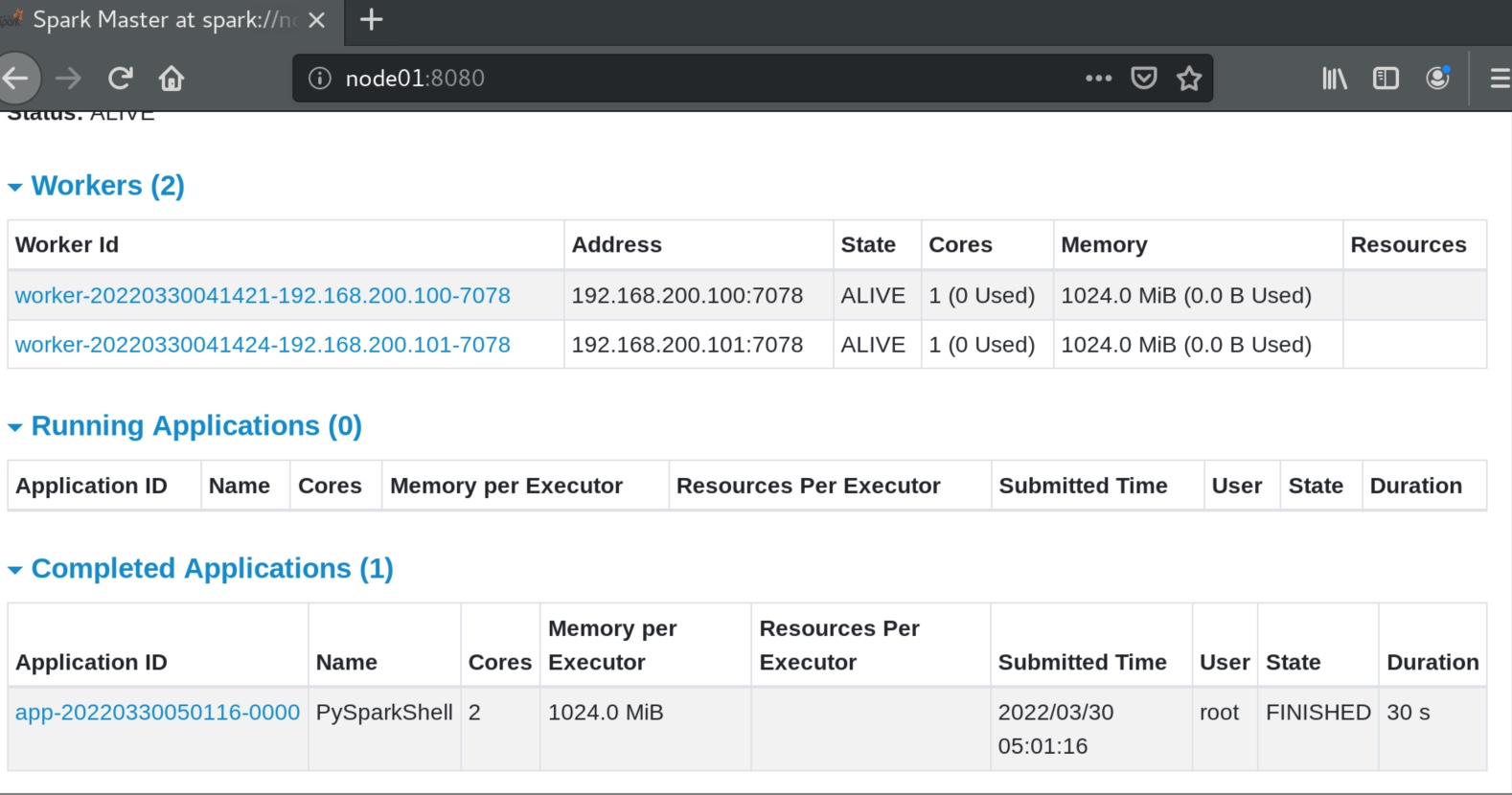
local模式部署 local模式部署就在node01这一台机器上就行。
配置环境变量(python 用conda虚拟环境的)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 vim /etc/profile export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64export HADOOP_HOME=/opt/hadoop/hadoopexport HADOOP_CONF_DIR=$HADOOP_HOME /etc/hadoopexport SPARk_HOME=/opt/spark/sparkexport PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python3.8vim /root/.bashrc export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64export PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python3.8source /etc/profilesource /root/.bashrc
/opt/spark/spark/bin/pyspark 就是一个python解释器一样的东西,可以交互式运行python代码。
同理也可以用sparkr和sparkshell 用上r语言或者shell来运行spark。都用4040端口来监测,但是彼此独立。
1 ./spark-submit --master local [*] /opt/spark/spark/examples/src/main/python/pi.py 10
driver就是master,4040端口占用就会申请4041以此类推。
StandAlone模式部署
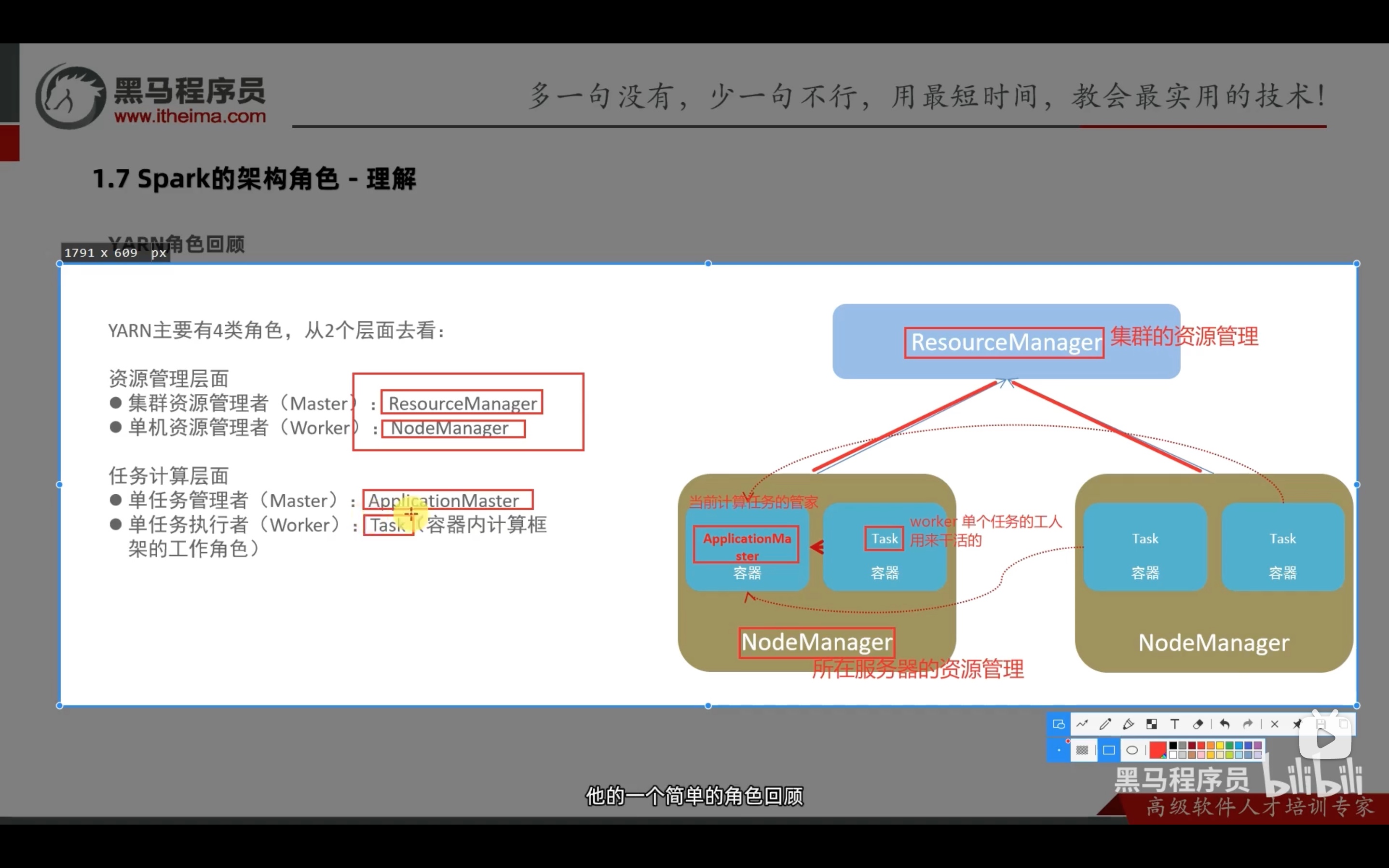
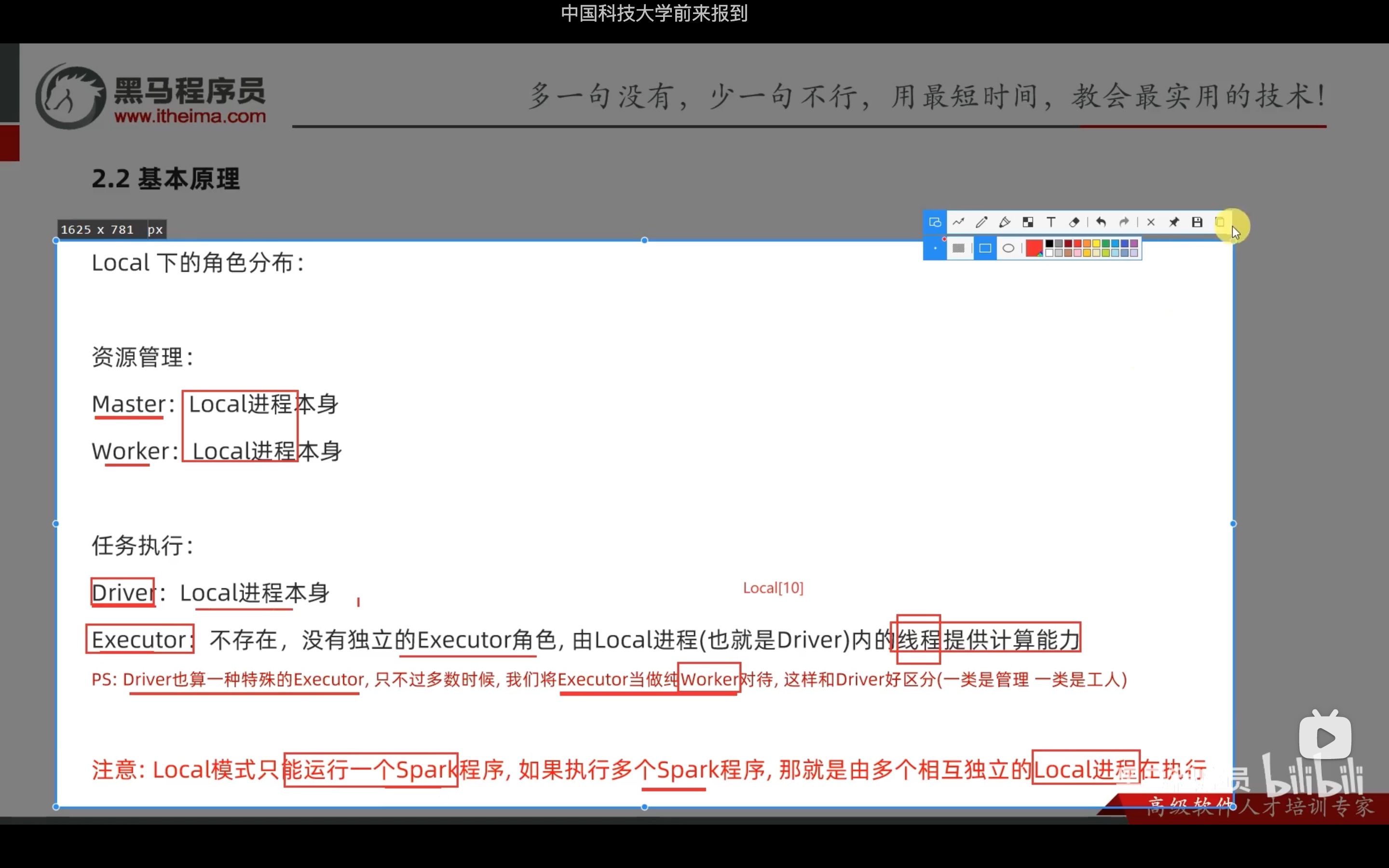
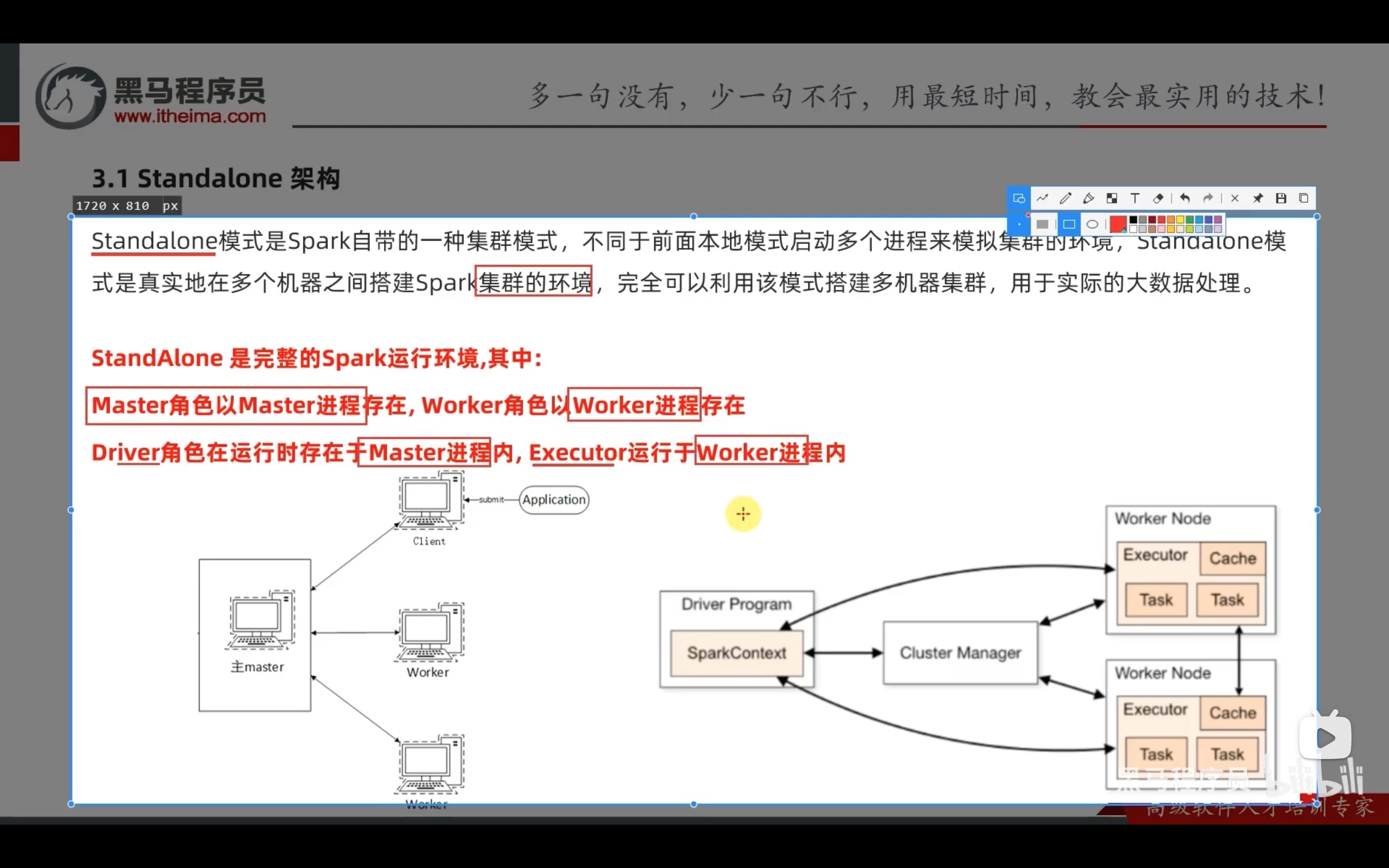
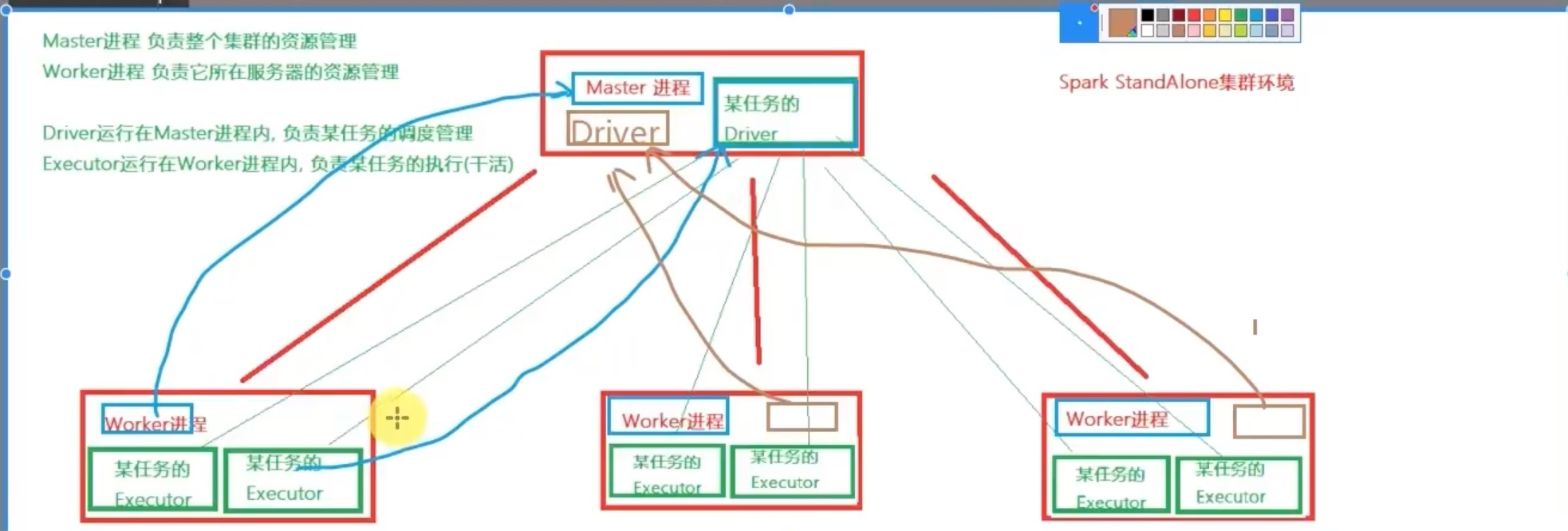
standalone模式下,有三种进程:master、worker、historyserver。
值得注意的是,standalone模式下,不像local模式开启两个个spark任务,就有两个local进程; standalone模式下,一个master和多个worded的框架是固定的,开启两个spark任务,只会在master进程中新增一个driver,同时在每一个worker中增加对应的executor,同一个spark任务的多个executor和与之对应的driver相通信。
注意:运行master的机器,也有一个worker在运行,也就是说,master机器也能执行任务。
前提准备 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 sh Anaconda3-2021.05-Linux-x86_64.sh vim ~/.condarc channels: - defaults show_channel_urls: true default_channels: - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2 custom_channels: conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud conda create -n pyspark python=3.8 scp -r spark node02:/opt/ vim /etc/profile export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64export HADOOP_HOME=/opt/hadoop/hadoopexport HADOOP_CONF_DIR=$HADOOP_HOME /etc/hadoopexport SPARk_HOME=/opt/spark/sparkexport PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python3.8vim /root/.bashrc export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64export PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python3.8source /etc/profilesource /root/.bashrc
修改配置文件 回到node01主机器
1 2 3 4 5 6 7 cd /opt/spark/spark/confmv workers.template workersvim workers node01 node02
配置spark-env.sh文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 mv spark-env.sh.template spark-env.shJAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64 HADOOP_CONF_DIR=/opt/hadoop/hadoop/etc/hadoop YARN_CONF_DIR=/opt/hadoop/hadoop/etc/hadoop export SPARK_MASTER_HOST=node01export SPARK_MASTER_PORT=7077SPARK_MASTER_WEBUI_PORT=8080 SPARK_WORKER_CORES=1 SPARK_WORKER_MEMORY=1g SPARK_WORKER_PORT=7078 SPARK_WORKER_WEBUI_PORT=8081 export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node01:9000/sparklog -Dspark.history.fs.cleaner.enabled=true"
指定了spark的日志文件位置后,需要新建这个文件。
1 2 3 4 hadoop fs -ls / hadoop fs -mkdir /sparklog hadoop fs -chmod 777 /sparklog
配置spark-defaults.conf文件
1 2 3 4 5 6 7 8 9 10 # 1. 改名 mv spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf # 2. 修改内容, 追加如下内容 # 开启spark的日期记录功能 spark.eventLog.enabled true # 设置spark日志记录的路径(先在自己的Hadoop配置文件etc/core-site.xml中查看自己的hdfs文件默认位置千万别写错了。) spark.eventLog.dir hdfs://node01:9000/sparklog # 设置spark日志是否启动压缩 spark.eventLog.compress true
配置log4j.properties 文件
1 2 3 4 5 # 1. 改名 mv log4j.properties.template log4j.properties # 将log4j.rootCategory=info 改为 log4j.rootCategory=warn # 这个文件的修改不是必须的, 为什么修改为WARN. 因为Spark是个话痨会疯狂输出日志, 设置级别为WARN 只输出警告和错误日志, 不要输出一堆废话.
在node01 和node02 分别设置好环境变量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # node01 和 node02 都重复一遍。 vim /etc/profile # 添加 export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64 export HADOOP_HOME=/opt/hadoop/hadoop export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export SPARk_HOME=/opt/spark/spark export PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python3.8 vim /root/.bashrc # 添加 export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64 export PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python3.8 source /etc/profile source /root/.bashrc
把node01配置好的spark文件发送一份到node02 中。
1 scp -r /opt/spark node02:/opt/
检验 验证历史日志进程是否打开。
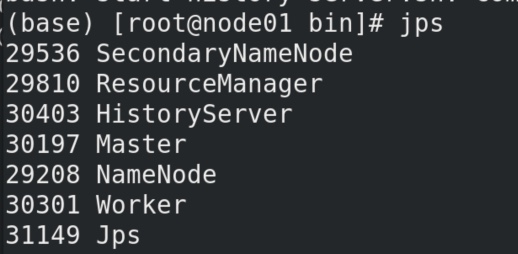
1 2 3 4 5 6 7 8 9 10 11 # 先开启Hadoop /opt/hadoop/hadoop/sbin/start-all.sh # 再 开启spark /opt/spark/spark/sbin/start-all.sh # 开启日志 /opt/spark/spark/sbin/start-history-server.sh # jps 监测java进程。 jps
验证能不能在standalone模式下,用pyspark工具连接到spark集群去工作。
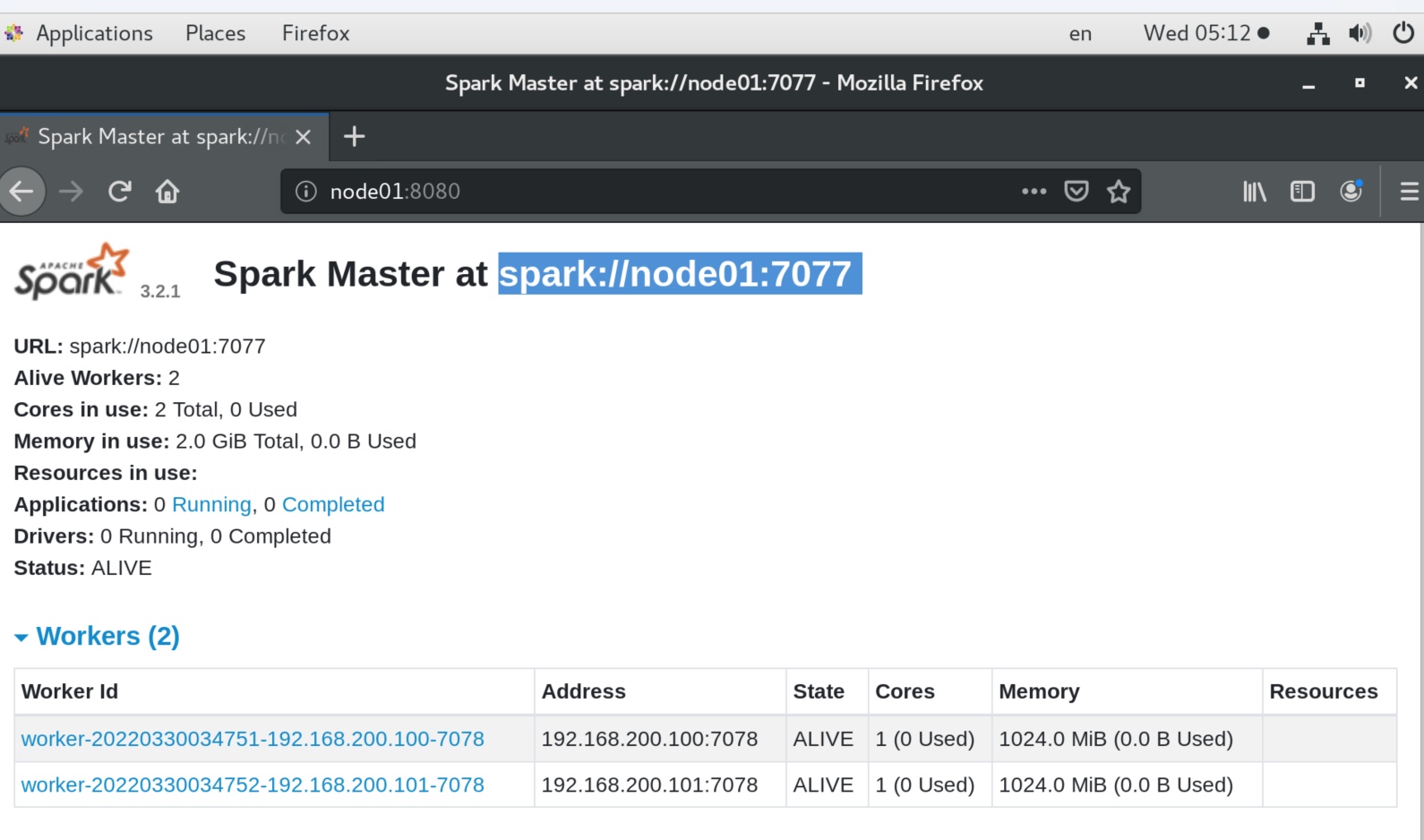
先看看spark集群的连接地址(spark://node01:7077)。
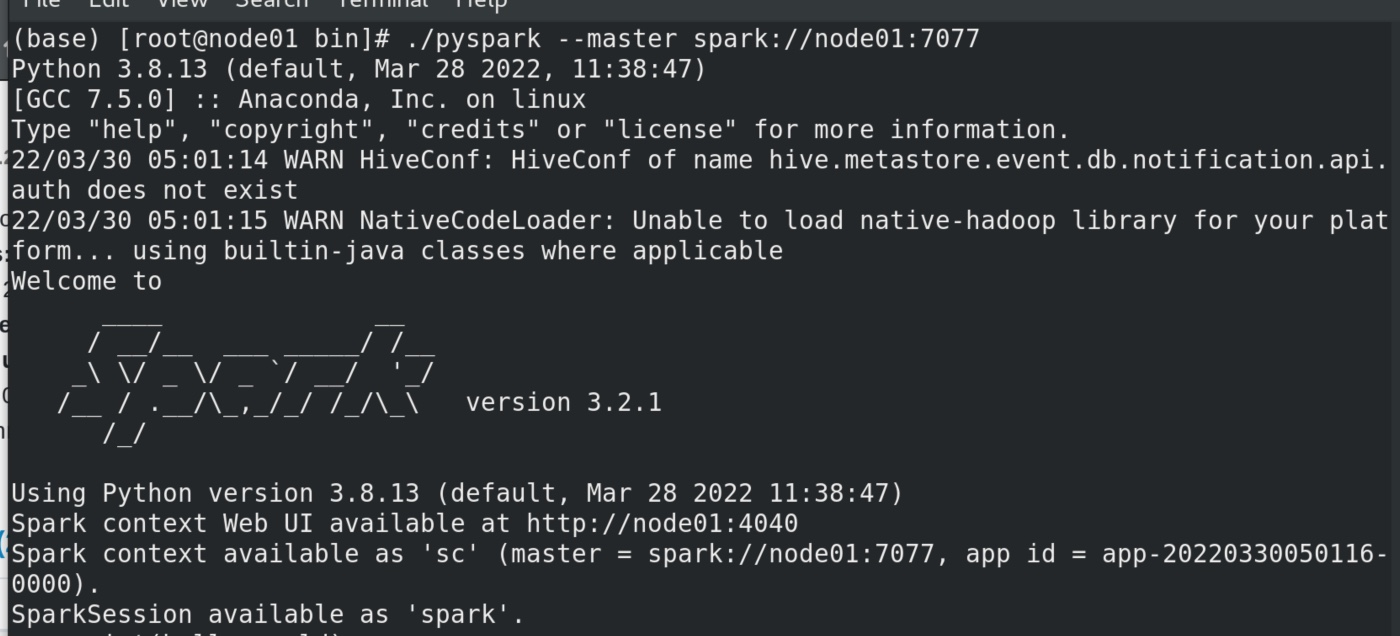
1 /opt/spark/spark/bin/pyspark --master spark://node01:7077
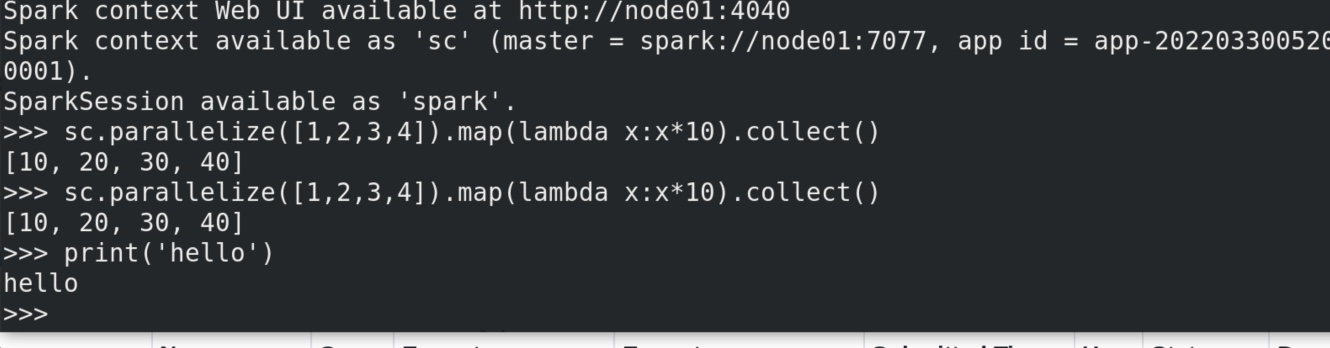
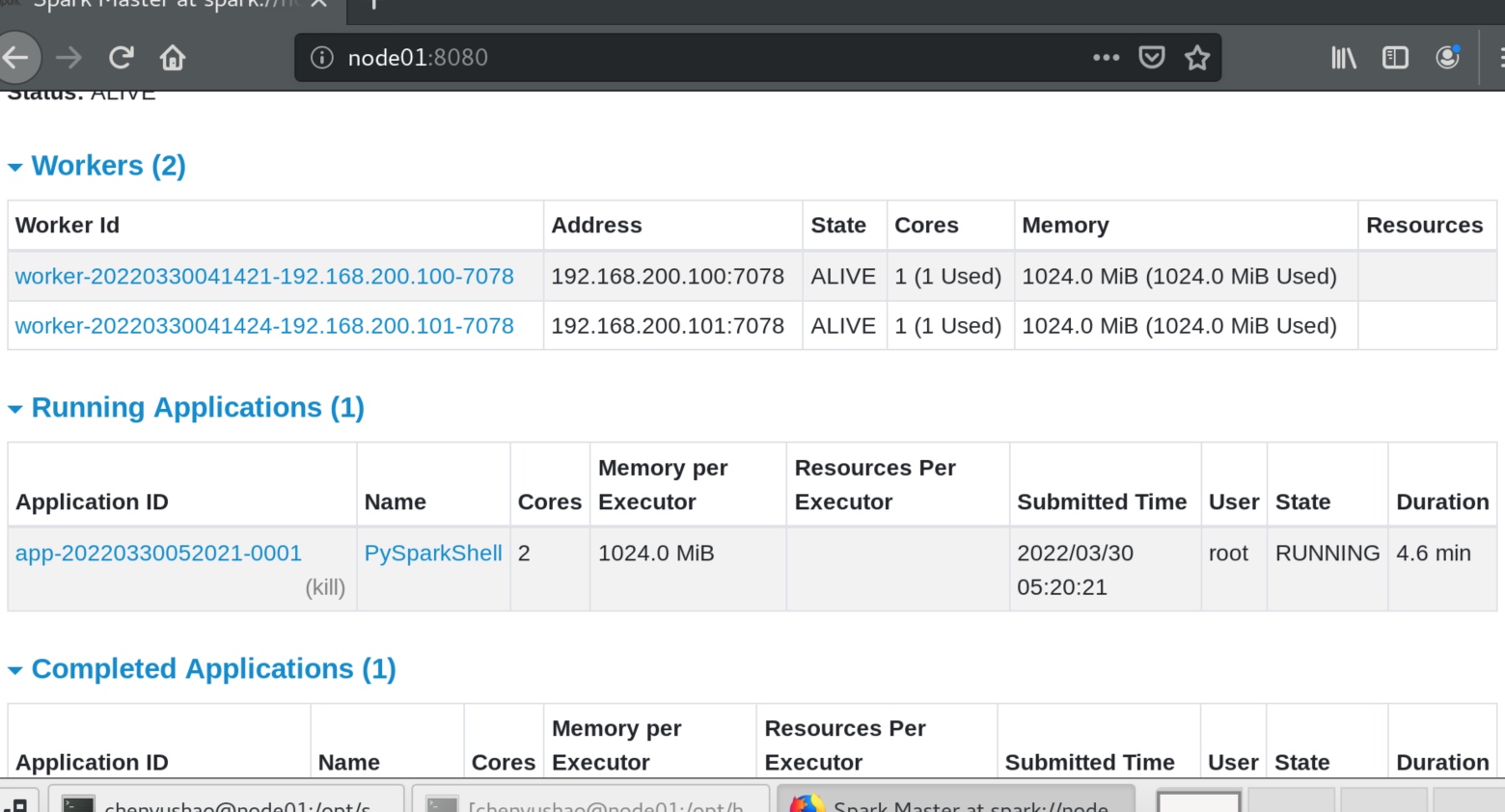
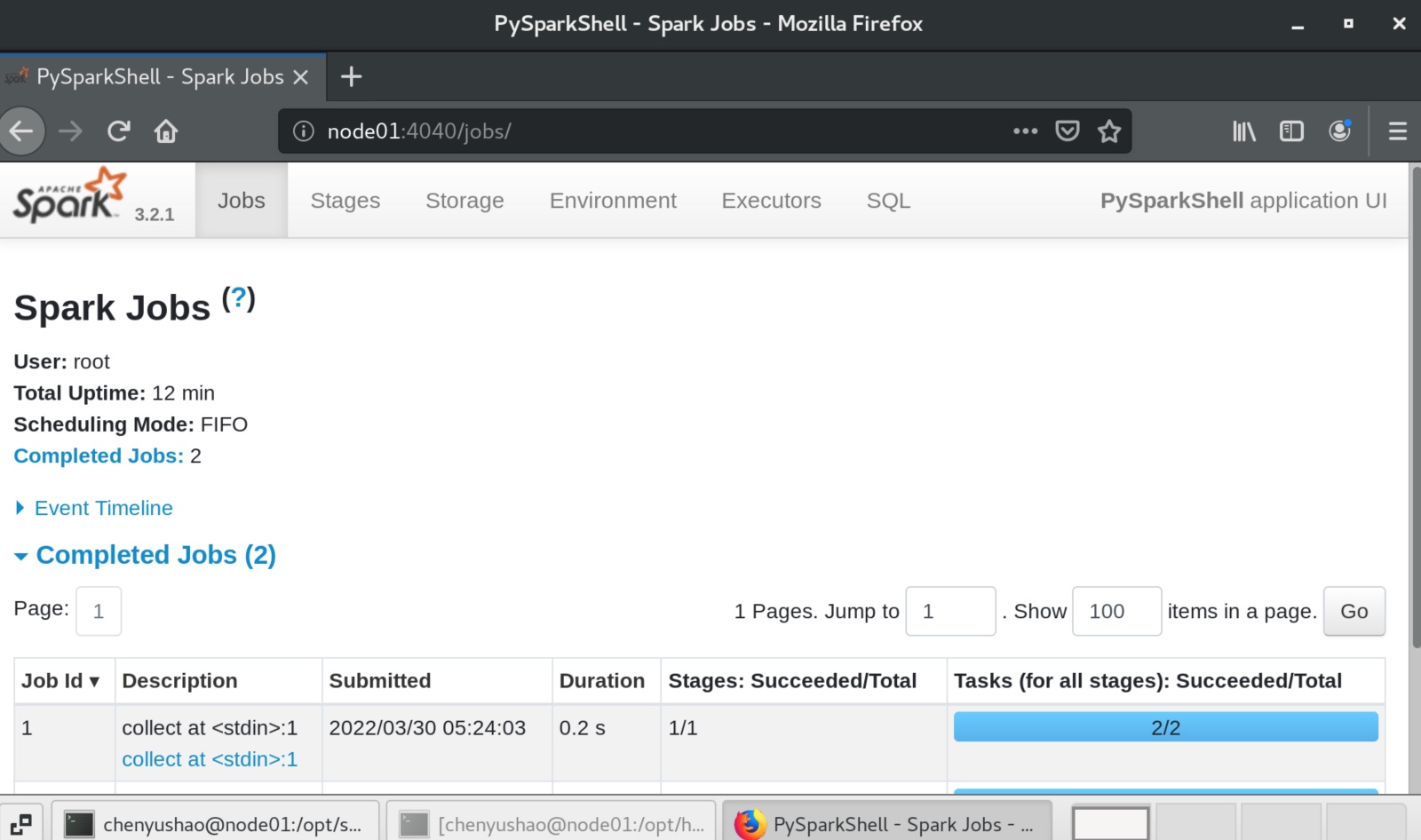
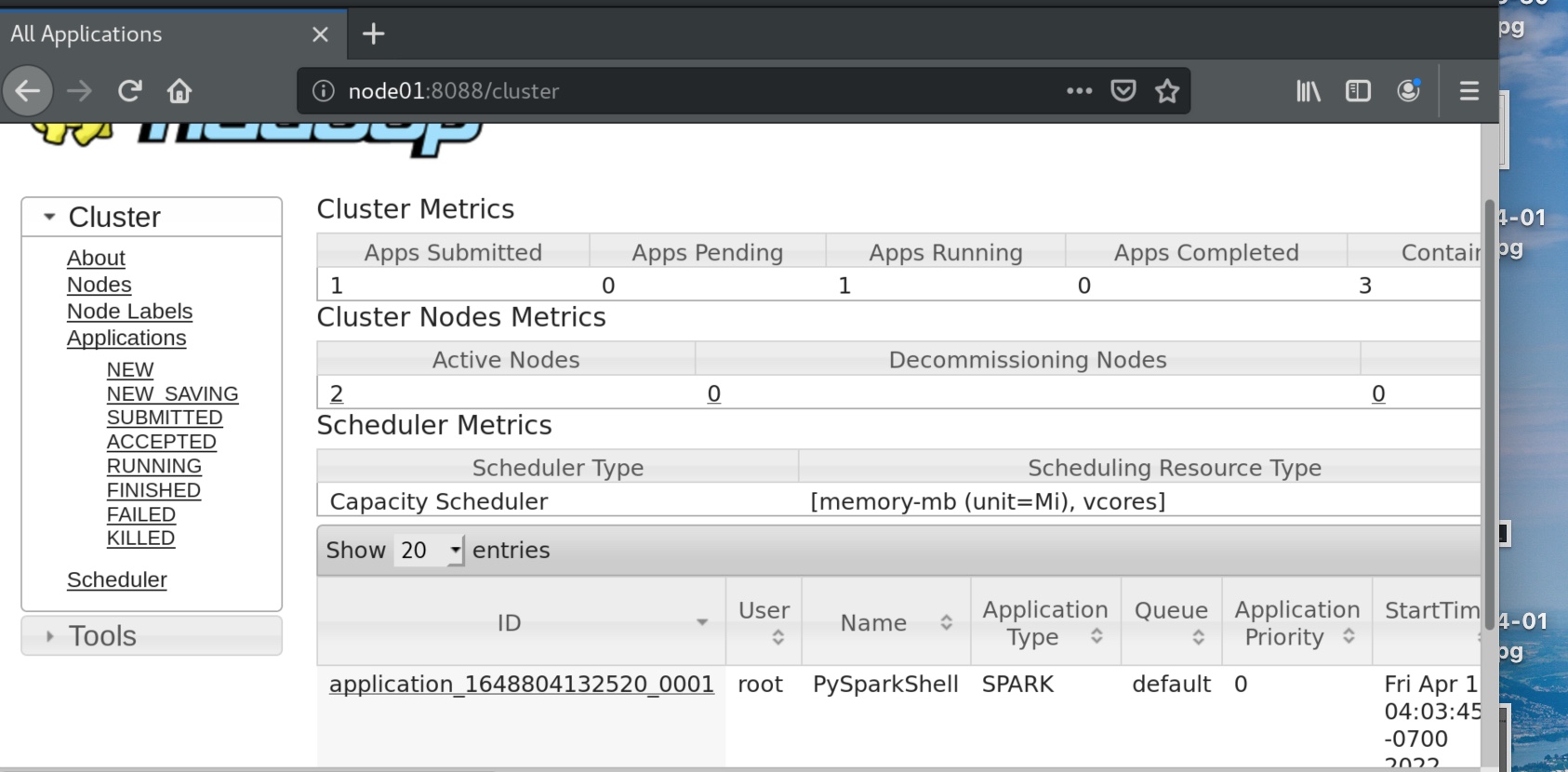
可见其master不再指向local ,而是指向spark集群地址spark://node01:7077,同时有了一个任务id,在8080端口也能看见。
1 sc.parallelize([1,2,3,4]).map(lambda x:x*10).collect()
注意这里的任务id 是被开启的pyspark程序的id,不是pyspark内运行的某个计算的id,8080端口可见。
点击0001 id 可见
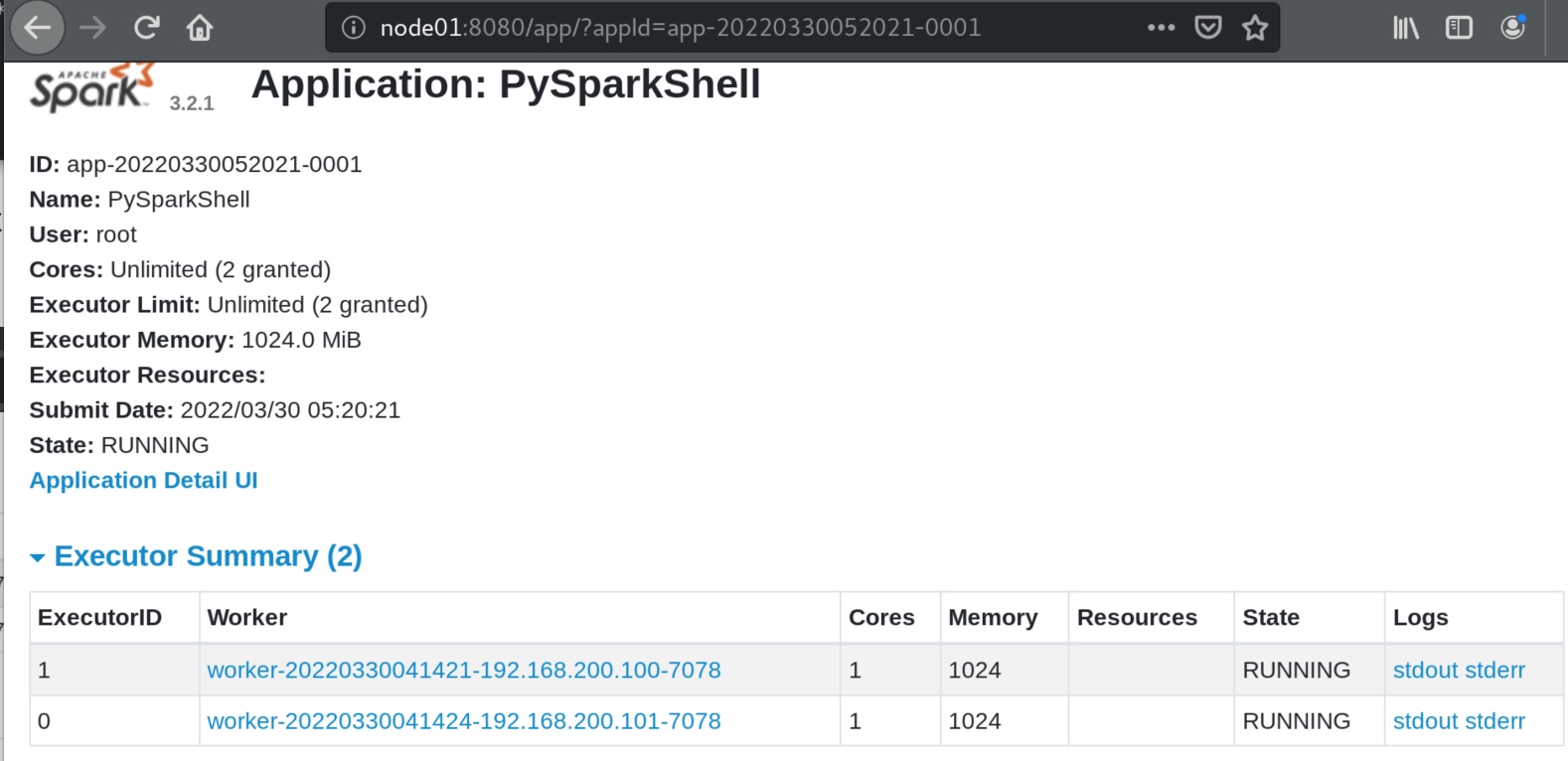
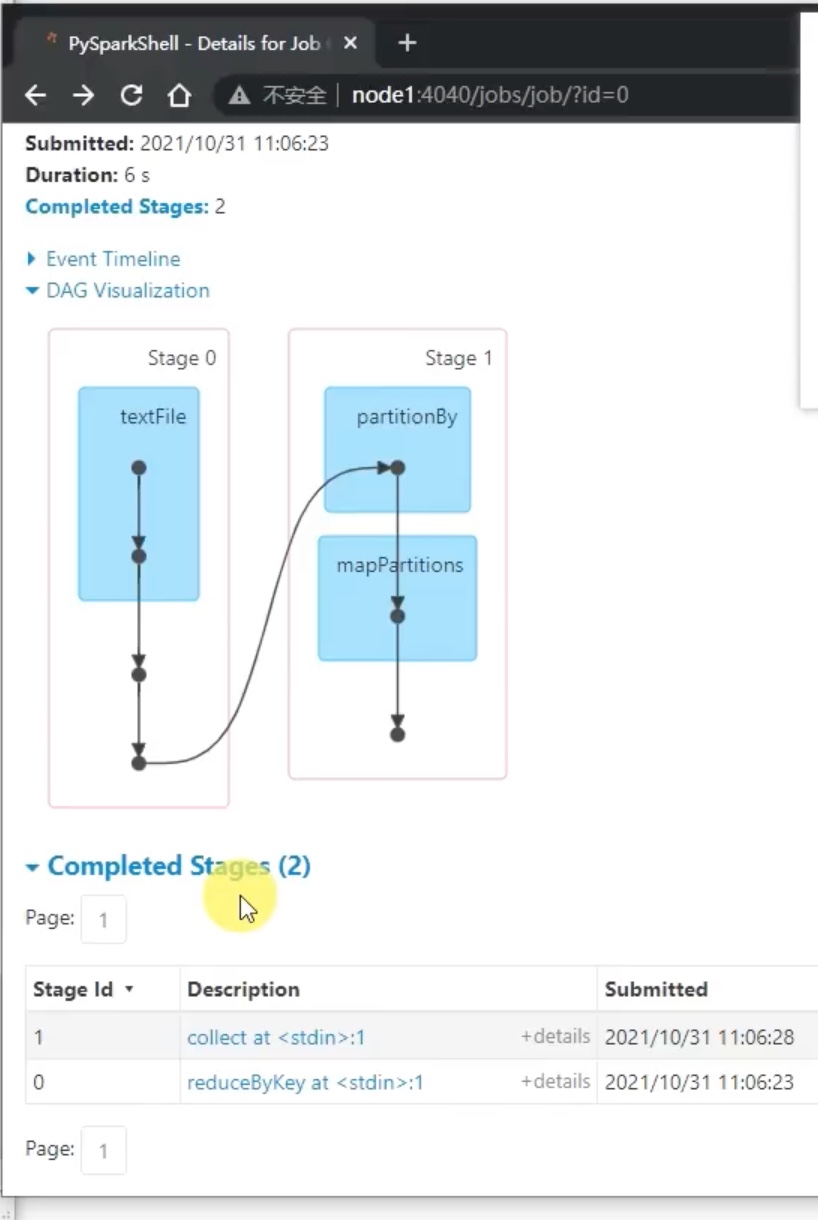
也可以在 “Application Detail UI” 内查看pyspark完成计算的历史。实际是跳转到了node01:4040页面。
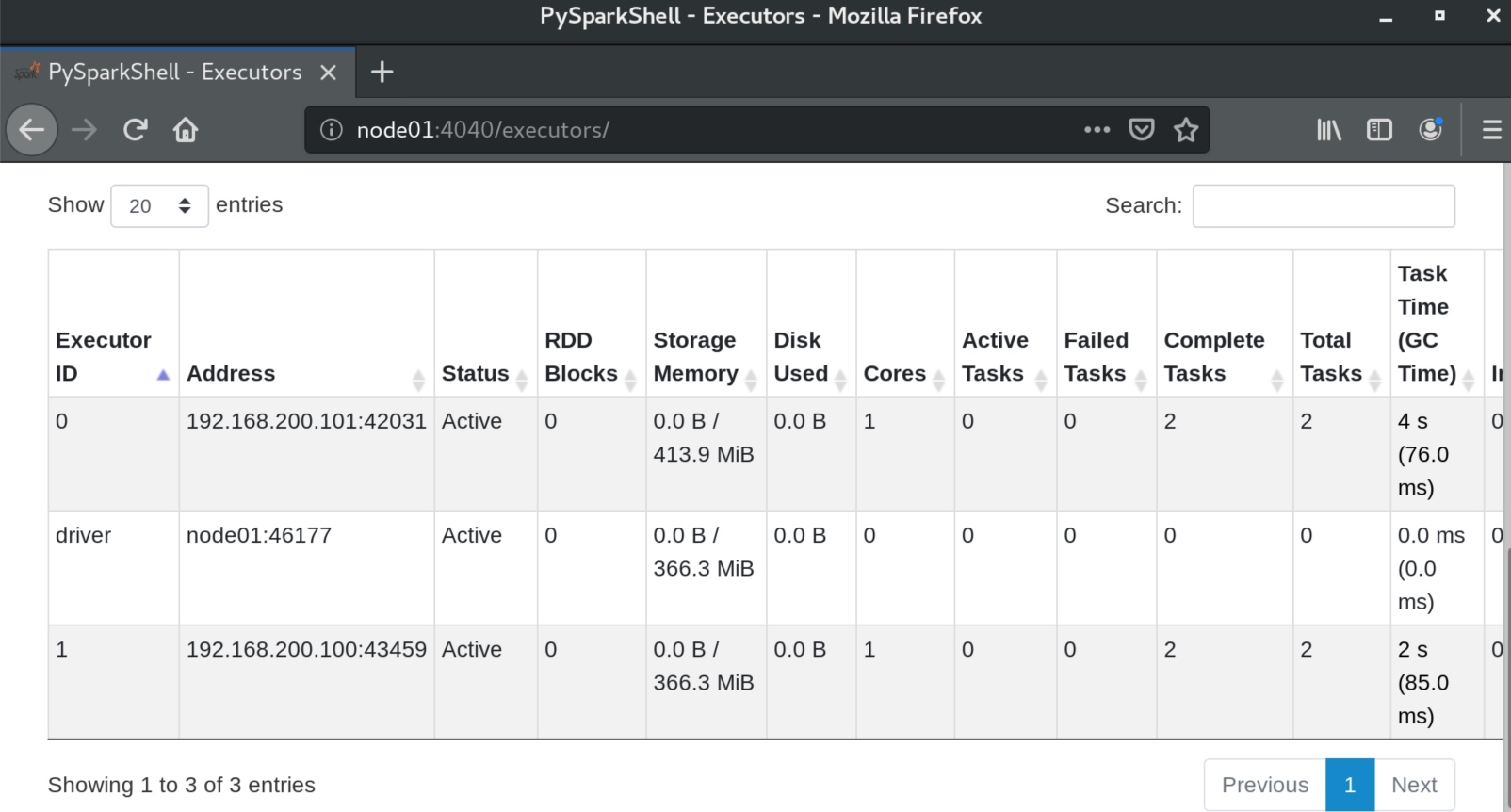
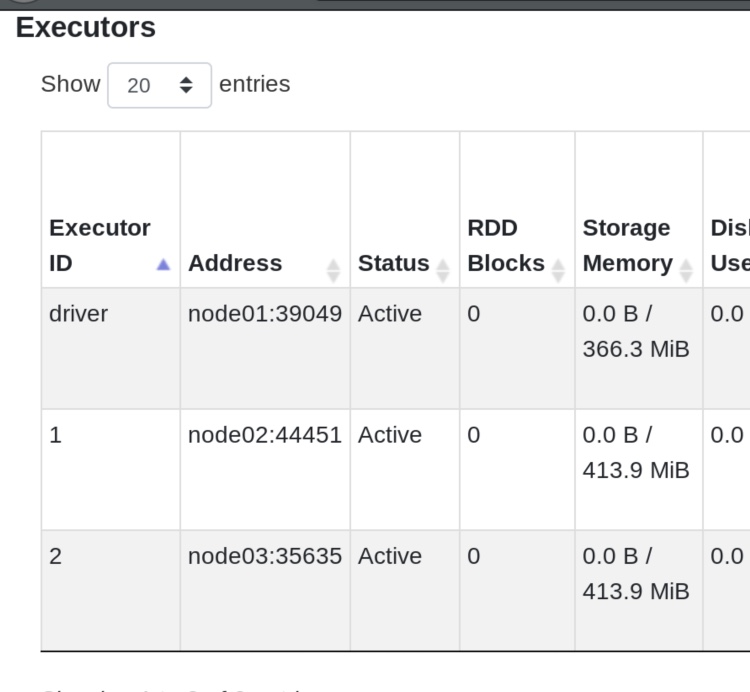
点击executors,可见有一个driver,但是有两个executor在干活。
和local不一样的地方是,standalone模式下,把一个pyspark工具退出了,其实是把一个driver退出了(driver只有在任务运行时才存在,默认4040端口监督) ,但是master和worker还在,所以4040端口打不开了,8080端口依然可见,原理可以看 “ StandAlone模式部署” 的图示。
提交程序到spark集群中去运行
1 /opt/spark/spark/bin/spark-submit --master spark://node01:7077 /opt/spark/spark/examples/src/main/python/pi.py 100
运行完毕后,可见4040端口打不开,因为任务已经结束,driver没了。8080端口可见其任务运行记录。
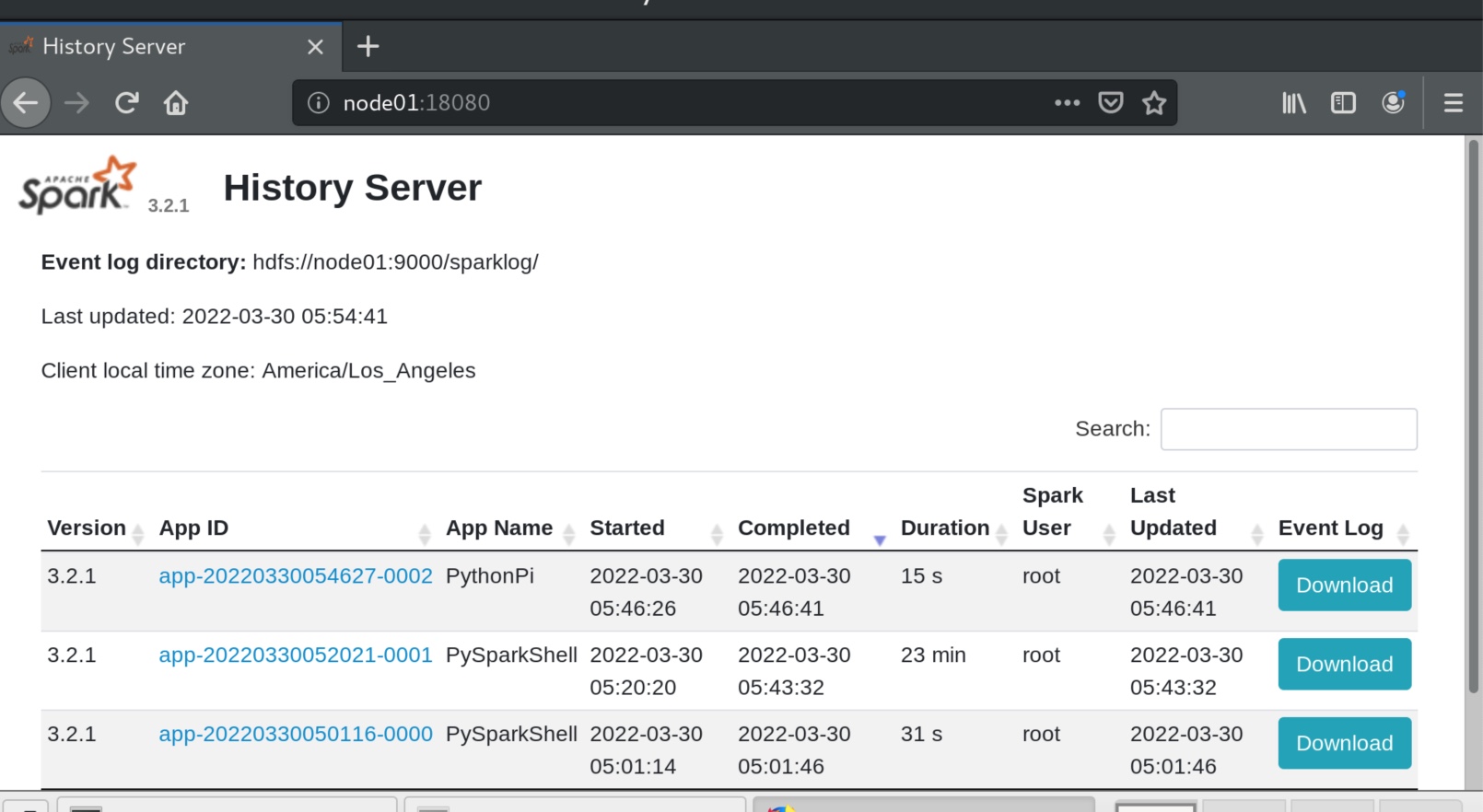
在18080端口查看history,实际上显示的和4040一样,4040端口随着driver的关闭而失效了,我们可以用18080端口看历史。
一直点击,可以看见底层的task是交给多个worker来执行的。
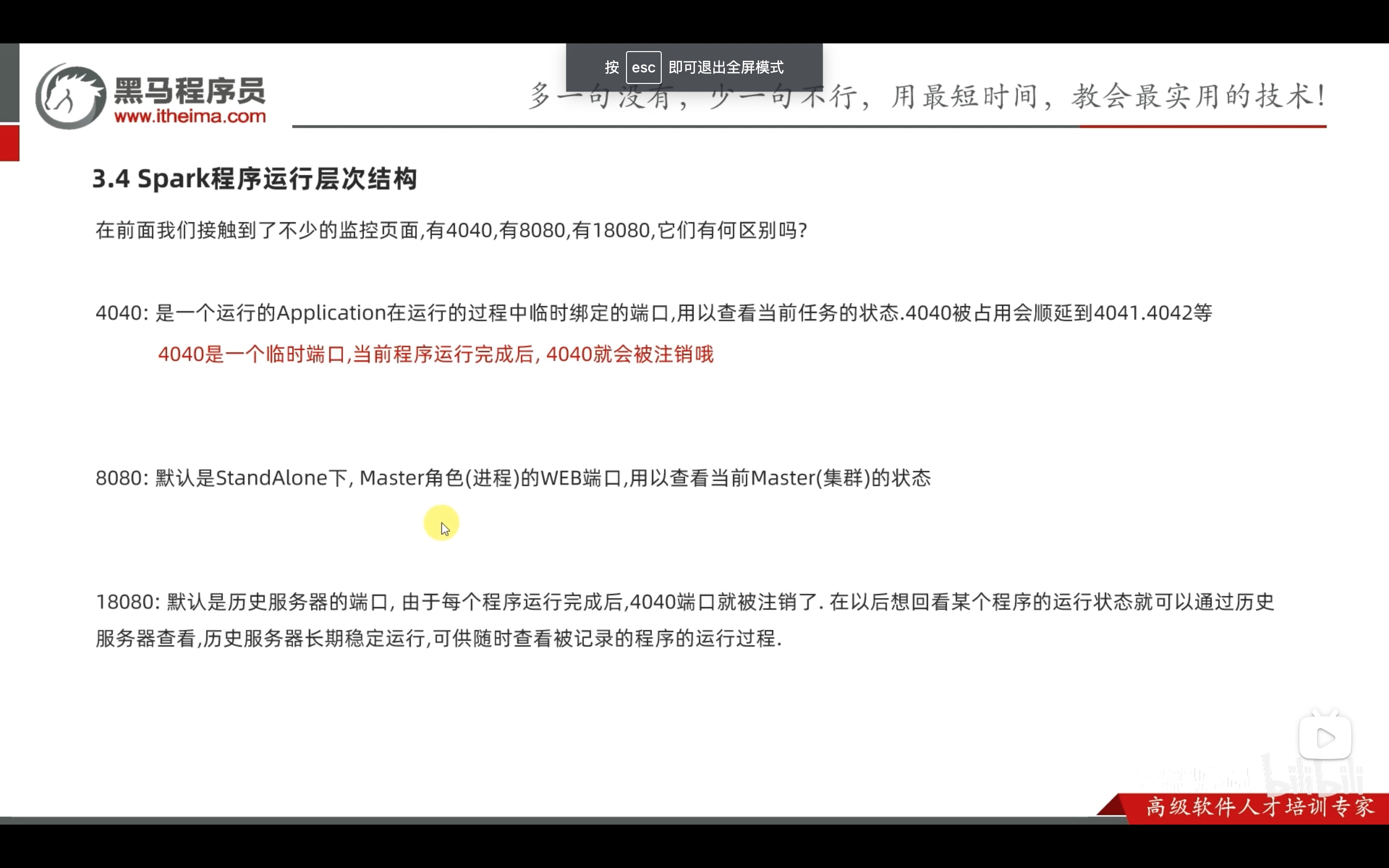
spark运行的层次结构
driver是某个任务程序的管理者,master是集群的管理者。
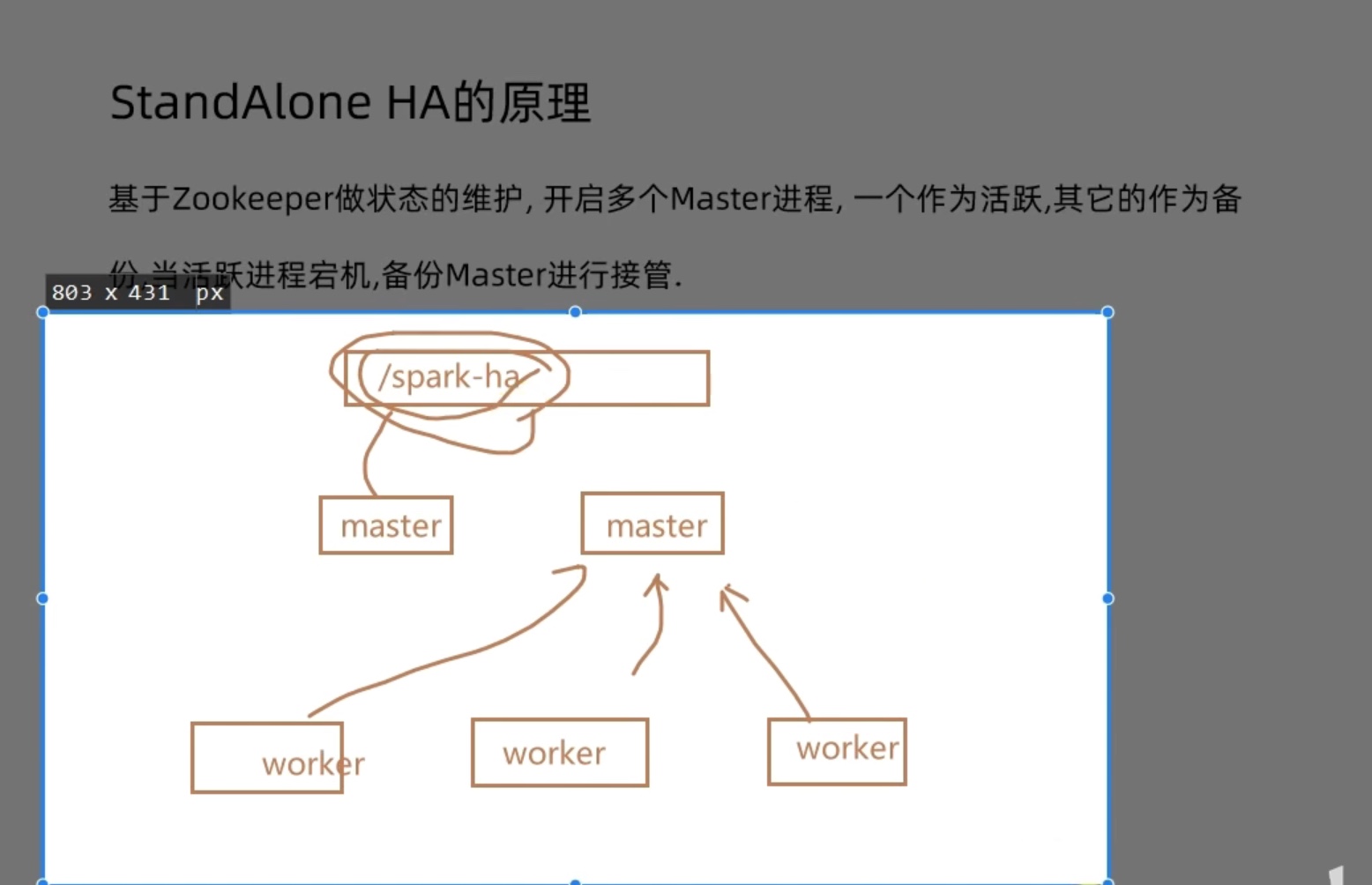
StandAlone HA环境搭建 主从结构天然有单点故障的风险。master一旦出问题集群就完蛋。
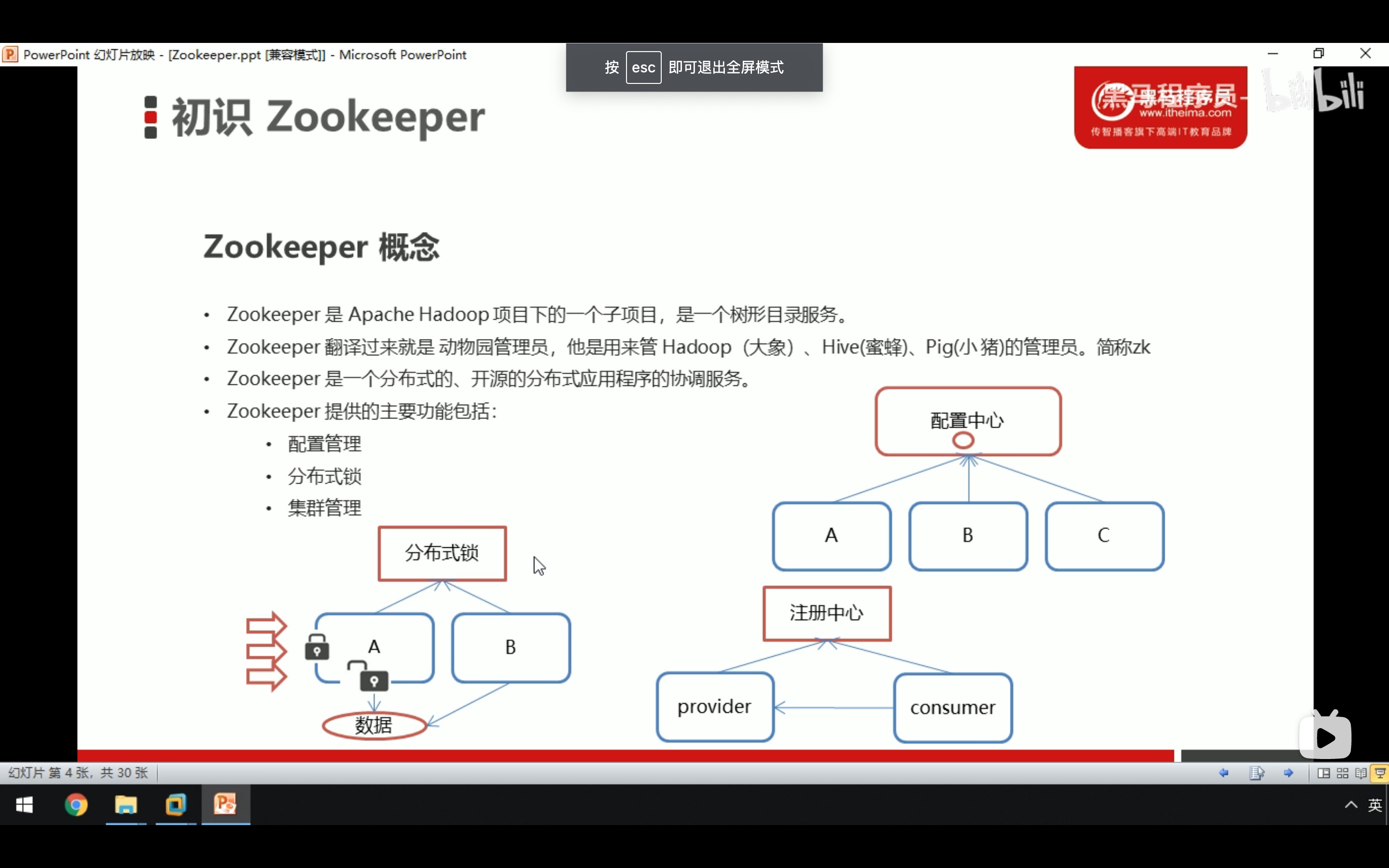
安装zookeeper集群
我们这里直接用zookeeper的集群配置,zookeeper这么个玩样儿是让节点死的时候,其它节点通过3888选举端口实现选举机制,选一个节点顶上死掉的节点,让集群正常工作。
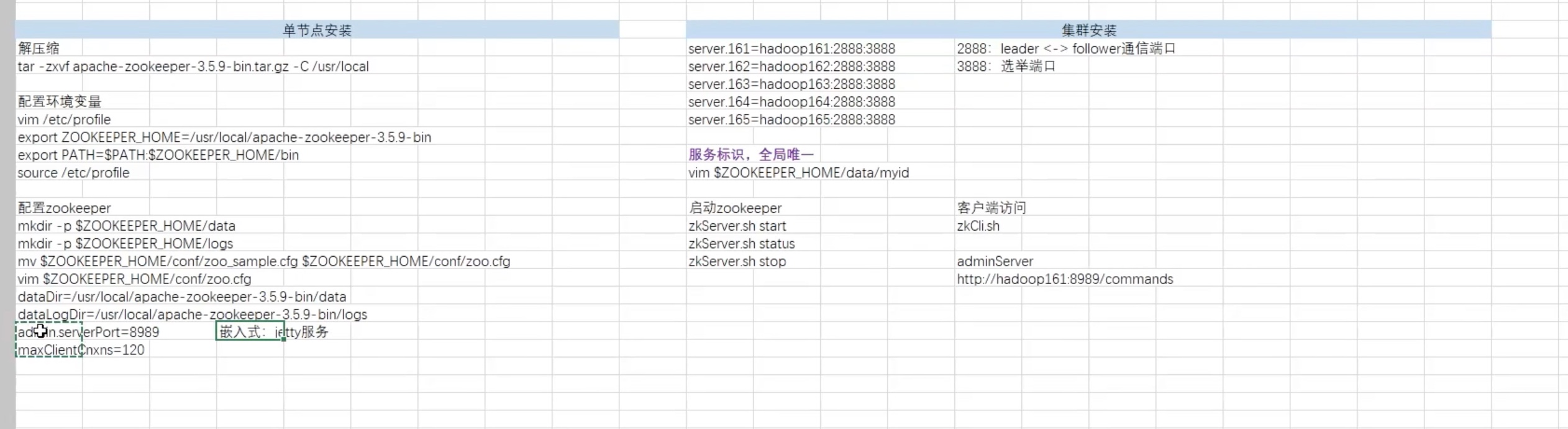
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 # 下载zookeeper,解压、改文件夹名为zookeeper放在/opt下。 http://zookeeper.apache.org/ # 关闭防火墙,保持所有端口开放,其实如果开了防火墙,保证2888 3888 等等几个端口开放就行。 # <改环境变量> vim /etc/profile export ZOOKEEPER_HOME=/opt/zookeeper export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${HADOOP_HOME}/bin:${ZK_HOME}/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin:$PATH:$ZOOKEEPER_HOME/bin # node01机器上配置zookeeper cd /opt/zookeeper mkdir data cd /opt/zookeeper/conf cp zoo_sample.cfg zoo.cfg vim zoo.cfg admin.serverPort=8989 # 我没使用默认的 8080 端口,而是用了8989端口。怕冲突。 maxClientCnxns=120 # 最大客户端数设定为120 dataDir=/opt/zookeeper/data server.1=node01:2888:3888 # 因为之前设置了/etc/hosts,用node01代替IP,1号机<唯一标识1>。 server.2=node02:2888:3888 server.3=node03:2888:3888 # 分发给其他节点。 scp -r /opt/zookeeper node02:/opt/ scp -r /opt/zookeeper node03:/opt/ # 其他节点<改环境变量>,同上。 # node01、node02、node03 各自创建myid文件,并写入唯一标识。 cd /opt/zookeeper/data touch myid echo "1">>myid # 1号机<唯一标识1> 2号机<唯一标识2> echo "2">>myid依次类推。 # 在每一台机器上都开启zookeeper服务。 /opt/zookeeper/bin/zkServer.sh start # 在每台机器上检查状态 /opt/zookeeper/bin/zkServer.sh status # 在每台机器关闭zookeeper服务。 /opt/zookeeper/bin/zkServer.sh stop
可见,Hadoop和spark中 设定为master的node01机器,在zookeeper中并不是leader,只是follower,而leader是node02机器。
StandAlone HA 在开启了zookeeper服务和hdfs服务前提下。
先在spark-env.sh中, 注释掉: SPARK_MASTER_HOST=node1
原因: 配置文件中固定master是谁, 那么就无法用到zk的动态切换master功能了.
在spark-env.sh中, 增加:
1 2 3 4 SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark-ha" # spark.deploy.recoveryMode 指定HA模式 基于Zookeeper实现 # 指定Zookeeper的连接地址 # 指定在Zookeeper中注册临时节点的路径
将spark-env.sh 分发到每一台服务器上
1 2 scp spark-env.sh node02:/opt/spark/spark/conf/ scp spark-env.sh node03:/opt/spark/spark/conf/
停止当前StandAlone集群停止当前spark的StandAlone集群
启动集群:
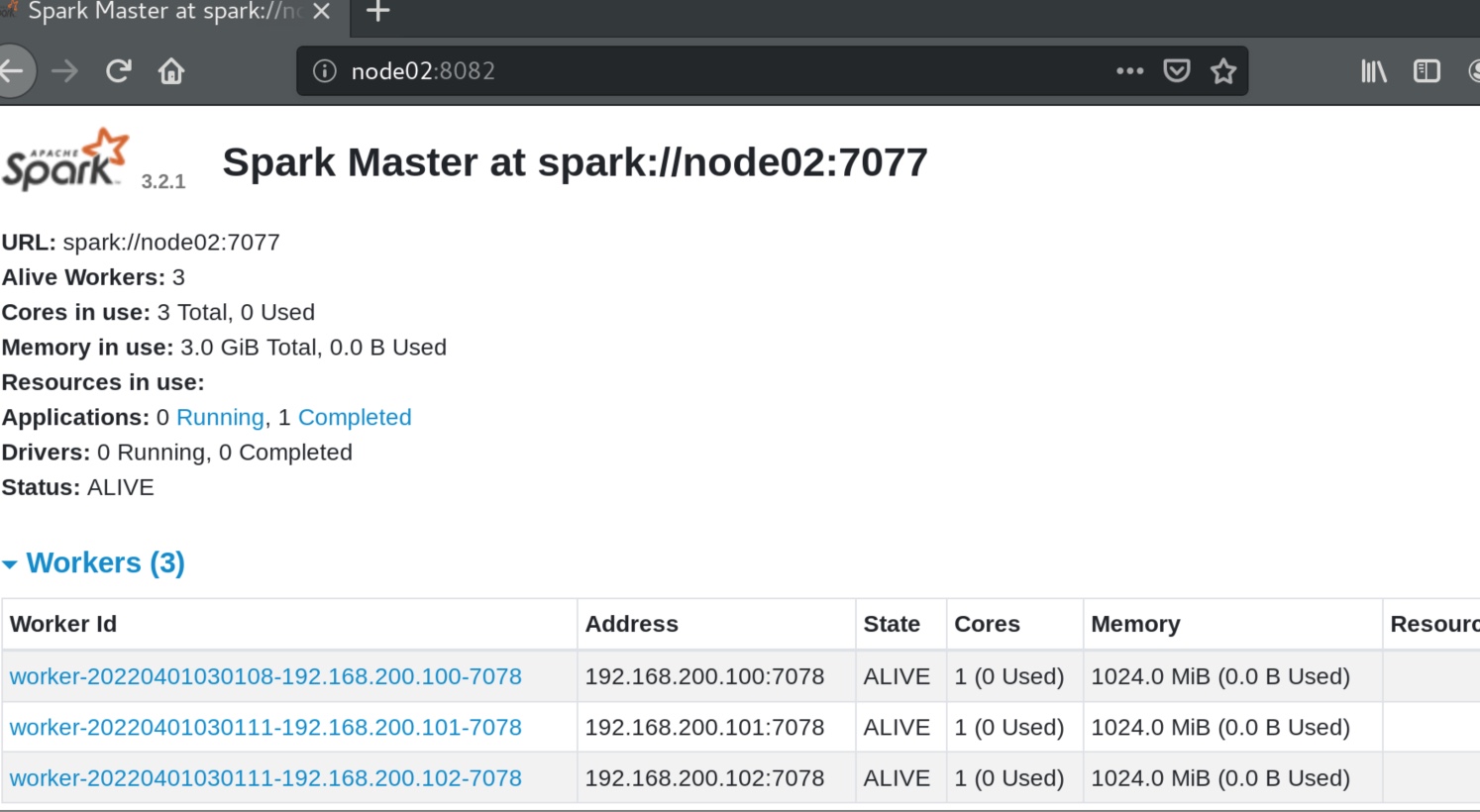
1 2 3 4 5 6 # 在node1上 启动一个master 和全部worker,node01机器抢到了master(alive状态)的8080端口。 sbin/start-all.sh # 注意, 下面命令在node2上执行 sbin/start-master.sh # 在node2上启动一个备用的master进程。 但是这个node02上的master(standby状态),在node01的master抢占了8080端口,而配套的三个worker抢占了8081端口,他就只能抢占8082端口了。
可见node02上的master其实占用的是8082端口,我们在node02:8082 查看,可见其状态在standby等待中。
master主备切换 在node01、node02、node03任意机器提交一个spark任务到当前alivemaster上,让node01领导的worker集群去处理(spark-subimit –master 集群地址为*** 文件 参数):
1 bin/spark-submit --master spark://node01:7077 /opt/spark/spark/examples/src/main/python/pi.py 1000
在提交成功后, 程序还在运行的过程中,突然将alivemaster kill掉
kill -9 node01中jps看见的master进程号
不会影响程序运行:
当新的master接收集群后, 程序继续运行, 正常得到结果.
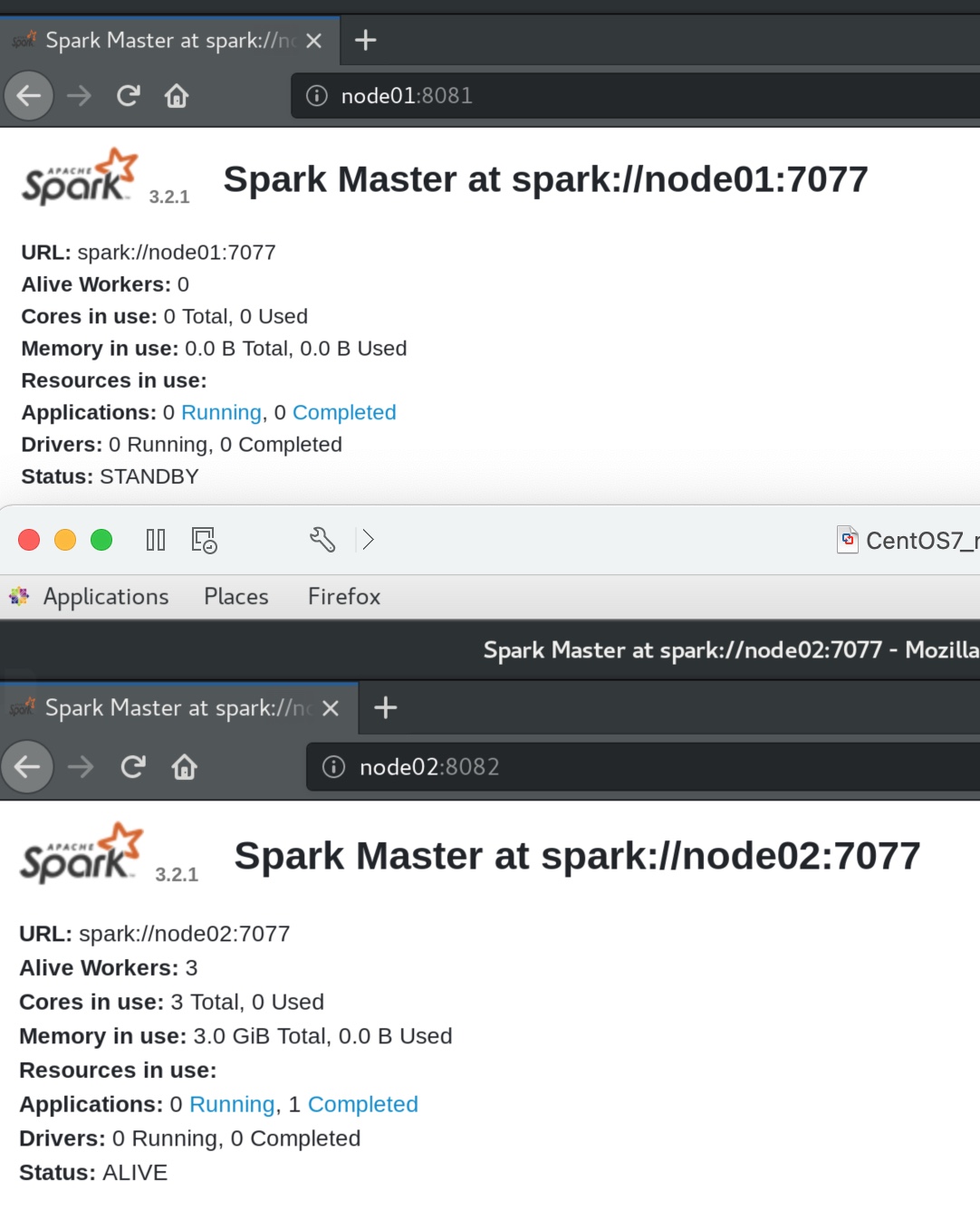
我们在node02:8082端口 可见,node02的master已经从standby转为了alive状态(我猜测worker们现在占用的变成了8083端口,8081端口被空出来了)。
此时,node01的master没有了,三个worker又只有了一个master,有单点故障的风险,所以我们应该重新在node01机器上 开启一个master服务。
node01 执行 sbin/start-master.sh
不过node01重新开启master后,换成了8081的端口,而且变成了standby等待状态,此时node02的master占用8082端口,是alive状态。
结论 HA模式下, 主备切换 不会影响到正在运行的程序.
最大的影响是 会让它中断大约30秒左右.
Spark on Yarn 环境搭建
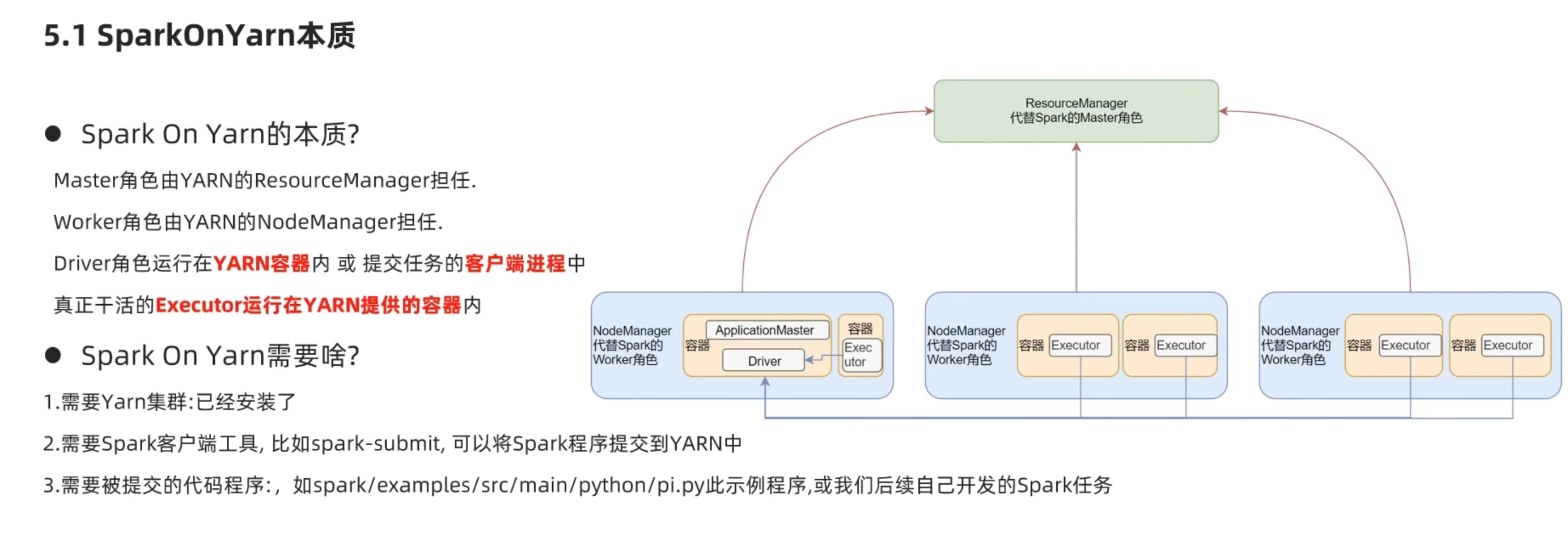
spark 仅仅保留driver和executor运行的能力,资源管理交给Hadoop自带的 yarn即可。避免了master、worker结构和yarn已有的结构重叠浪费资源和冲突的问题。
其实仅仅在spark-env.sh中配置有Hadoop的conf和yarn的conf环境变量,就能用spark on yarn了,炒鸡简单。
1 2 3 # HADOOP_CONF_DIR=/opt/hadoop/hadoop/etc/hadoop YARN_CONF_DIR=/opt/hadoop/hadoop/etc/hadoop
1 2 3 4 # 提交运行 例子 bin/spark-submit --master yarn /opt/spark/spark/examples/src/main/python/pi.py 1000 # 交互式运行 bin/pyspark --master yarn
可以在yarn的node01:8088端口看到pyspark的脚本运行。
spark on yarn 的两种运行模式
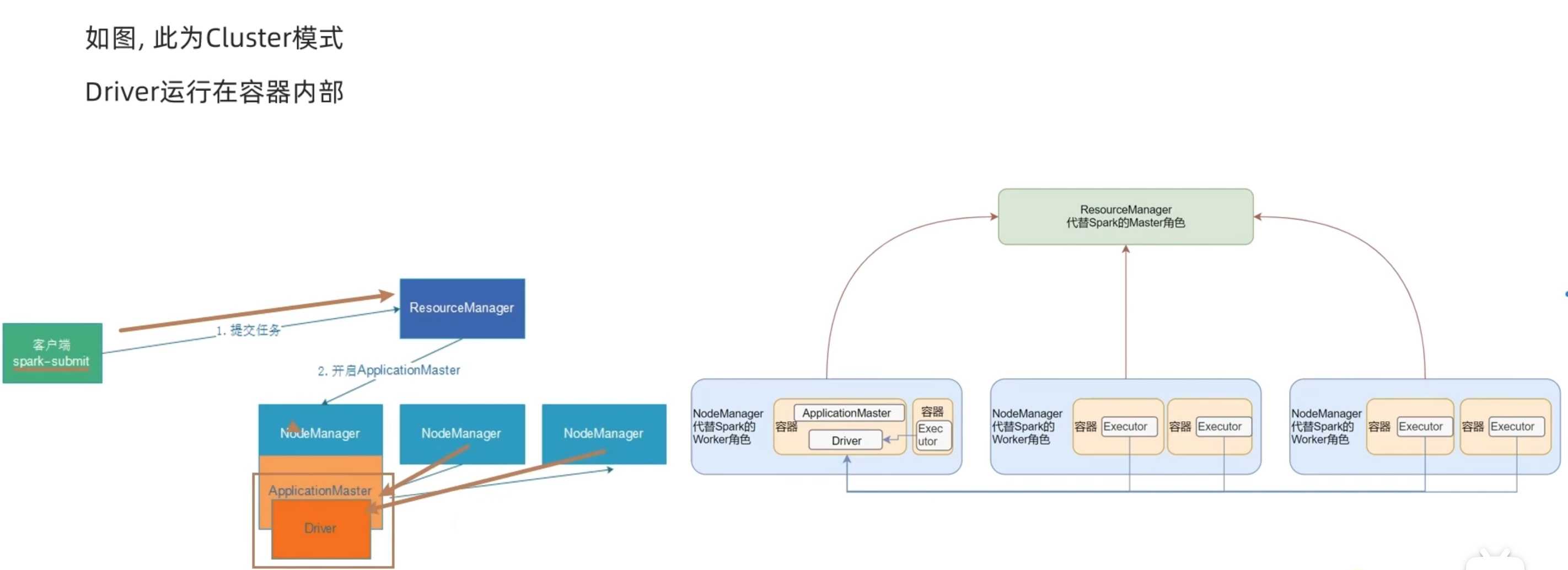
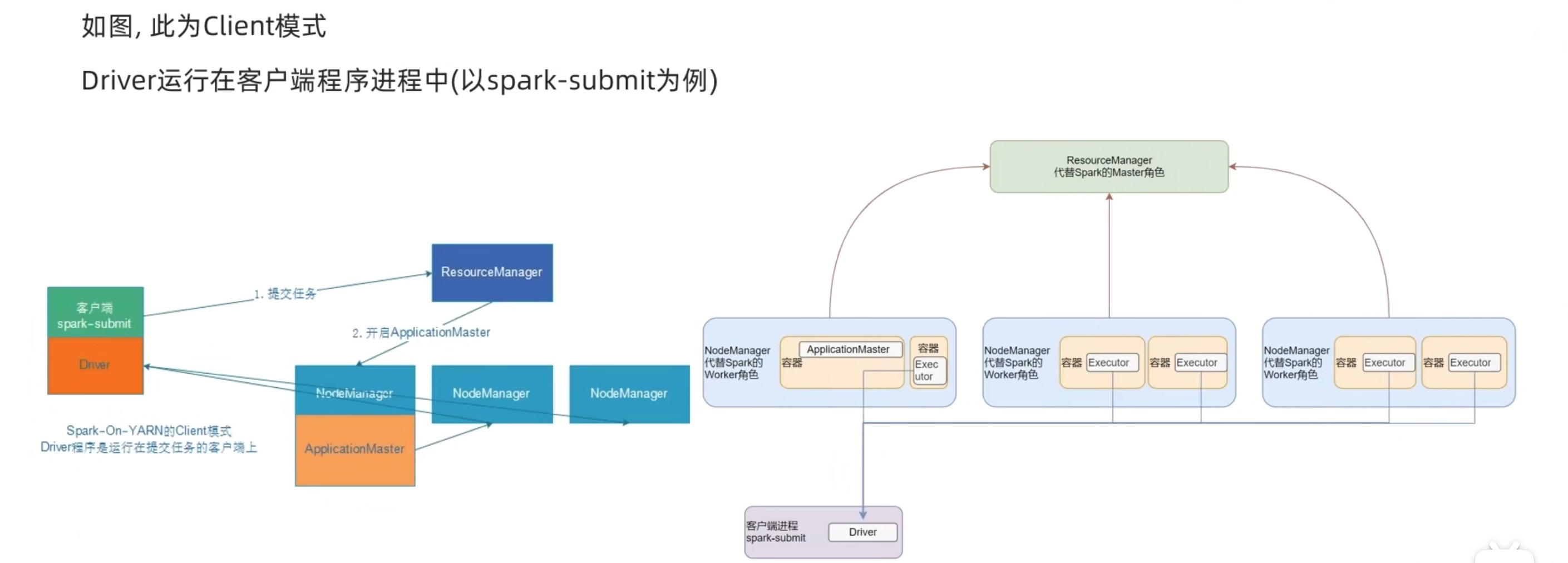
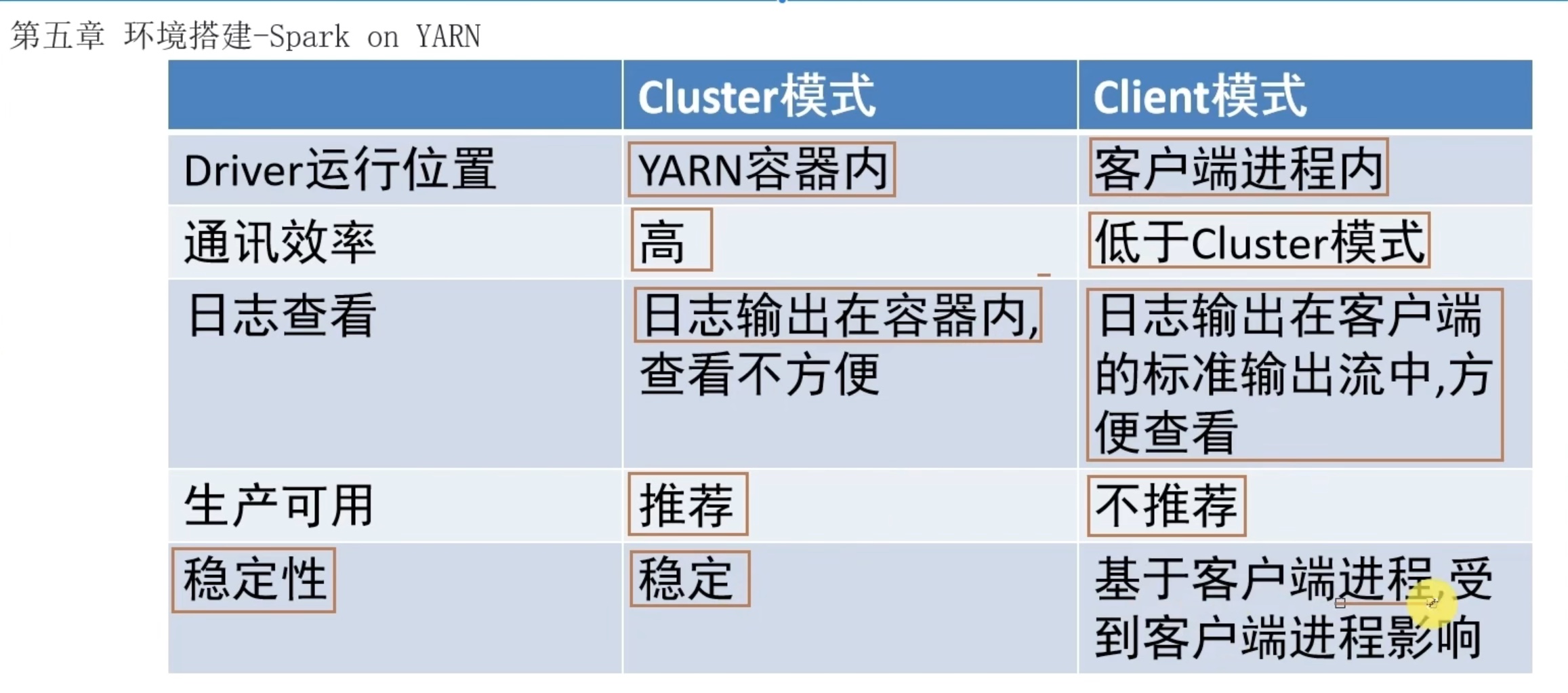
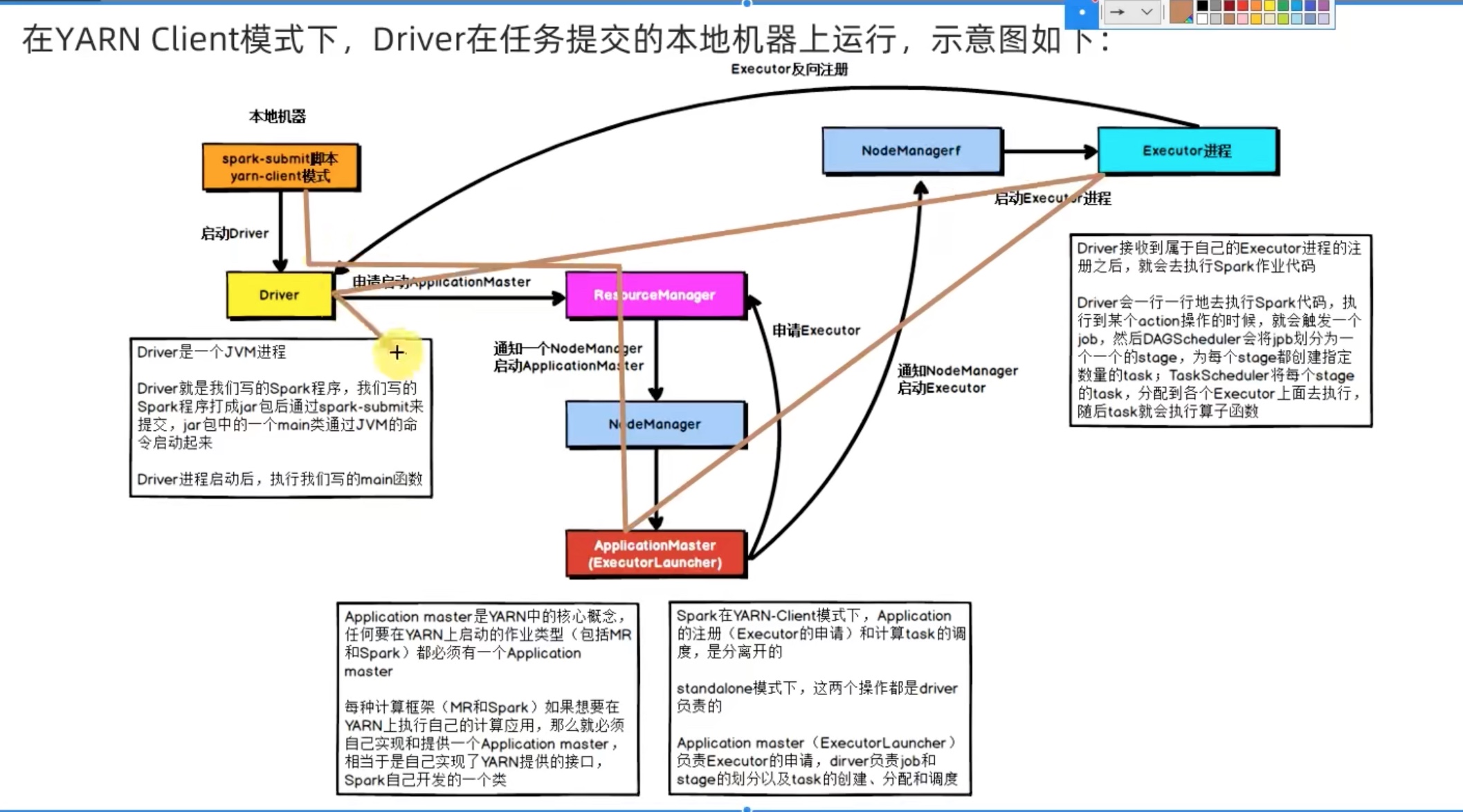
cluster模式是yarn内部通信(driver和executor),client模式是yarn内部的executor和yarn外部的driver通信。性能当然cluster好,但是交互式体验明显client更好。
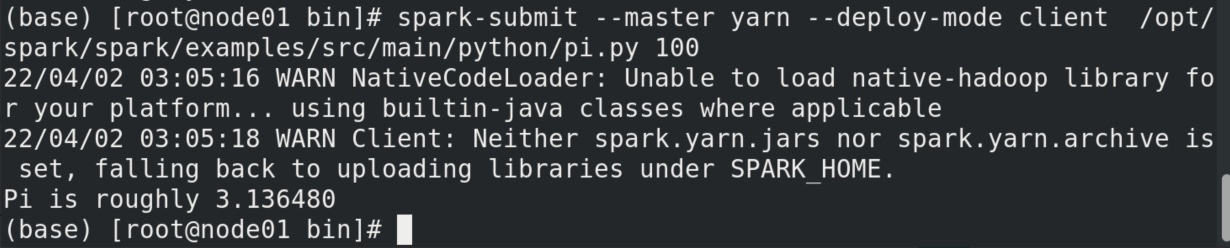
1 2 # 指定为spark-yarn客户端模式,其实默认也就是客户端模式。 bin/spark-submit --master yarn --deploy-mode client /opt/spark/spark/examples/src/main/python/pi.py 100
在开启spark的history服务后,选中18080端口此任务的executor,可见driver没有生成logs文件。
这是由于driver在客户端内,logs信息都生成在命令窗口了,如下。
1 2 # 指定为spark-yarn集群模式cluster,driver在datanode的容器内,集成进了yarn。 bin/spark-submit --master yarn --deploy-mode cluster /opt/spark/spark/examples/src/main/python/pi.py 100
在开启spark的history服务后,选中18080端口此任务的executor,可见driver生成了logs文件,并且命令窗口没有输出。
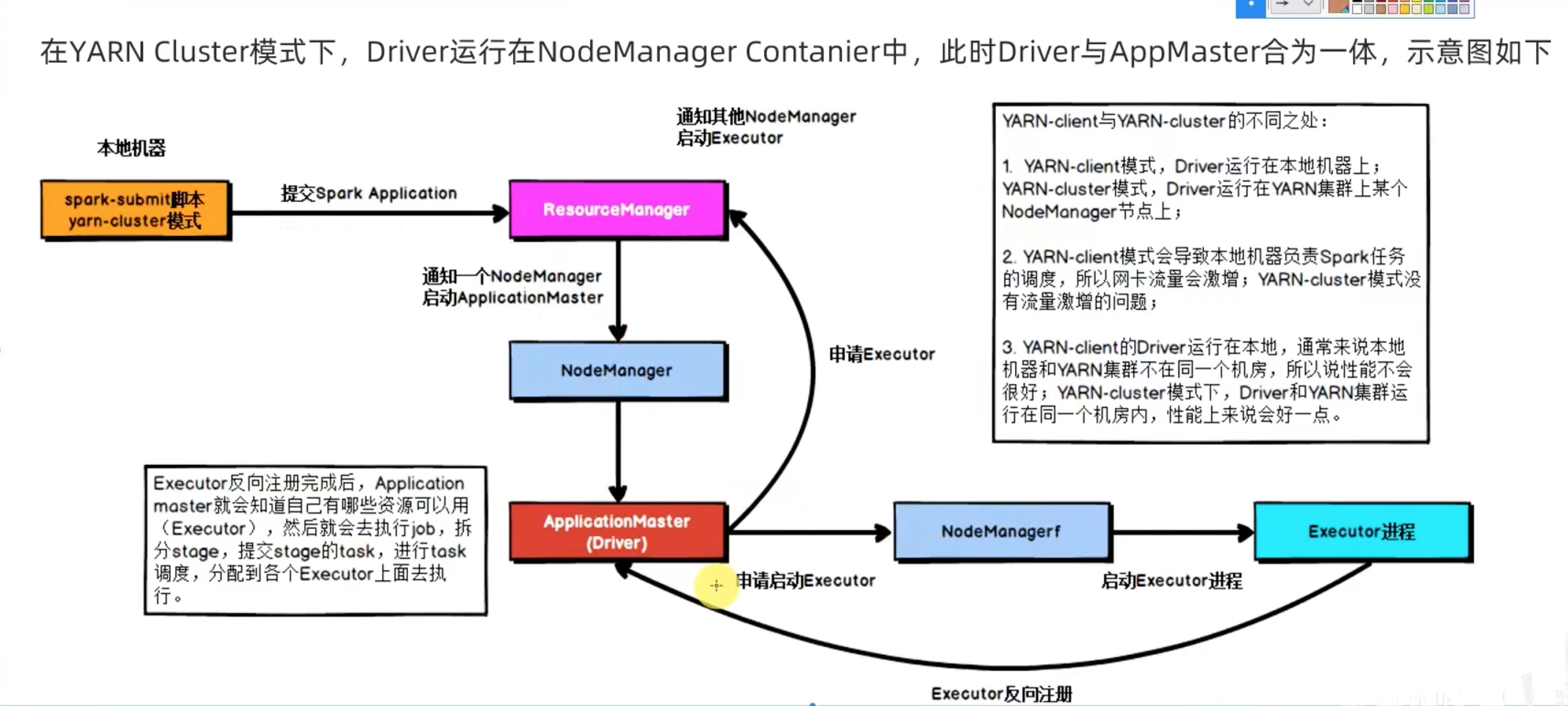
两种模式都是先生成application master,(但是一个driver在外一个driver在内)然后applicationmaster和driver通信问问要啥,application master回头再去和resourcemanager要资源,告诉nodemanager兄弟们启动executor,executor再去找driver 反向注册,形成一套driver和executors的计算框架。
框架和类库
1 2 3 # 每一台机器都执行一遍 conda activate pyspark pip install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple
基础实战
Windows要打Hadoop补丁,macOS和Linux不用这么麻烦,直接跳过。
因为我在centos的虚拟机内之前已经安装好了idea,所以就不按照pycharm了,直接在idea添加python插件再添加conda虚拟环境中python的编译器就好。
添加idea的python插件。
这里顺带提一句题外话,idea的永久激活工具在cache 缓存中有文件,自己为了centos精简空间清理了cache缓存可能让idea的激活失败,所以还是少清理cache。
添加之前conda虚拟环境建好的python解释器。
当然,我其实没有按照最优的方法去配置,最优的方法是在mac上运行pycharm或者idea,然后在python解释器配置中,配置一个ssh远程连接到虚拟机的centos的conda虚拟环境的python解释器,这样运行是最好的,我猜工作中用的也最多。就点conda environment 下面的ssh interpreter配置就行了。配置好远程解释器之后,project的文件夹会和虚拟机的相应文件夹同步。
以上代码要注意两个点:
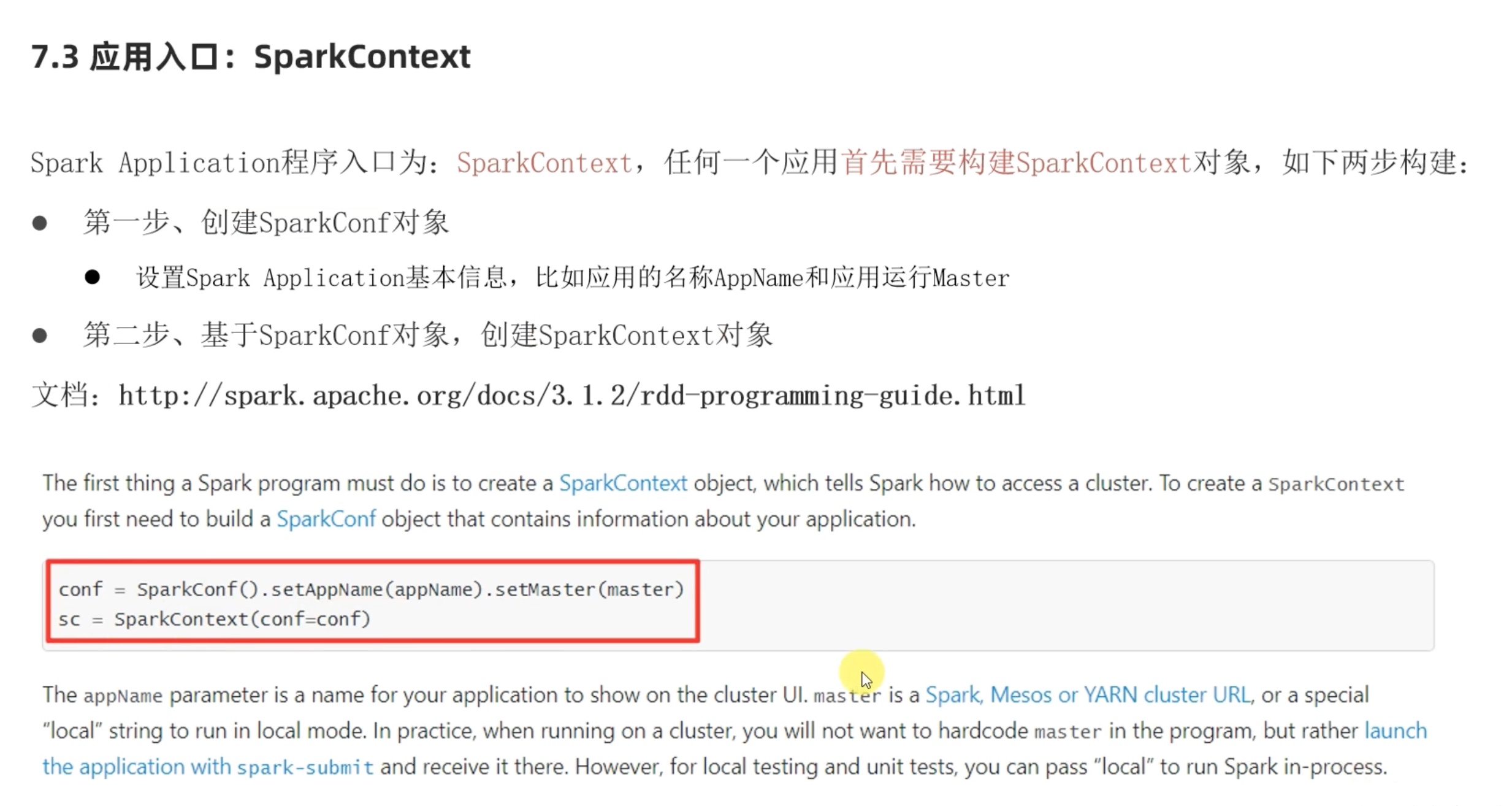
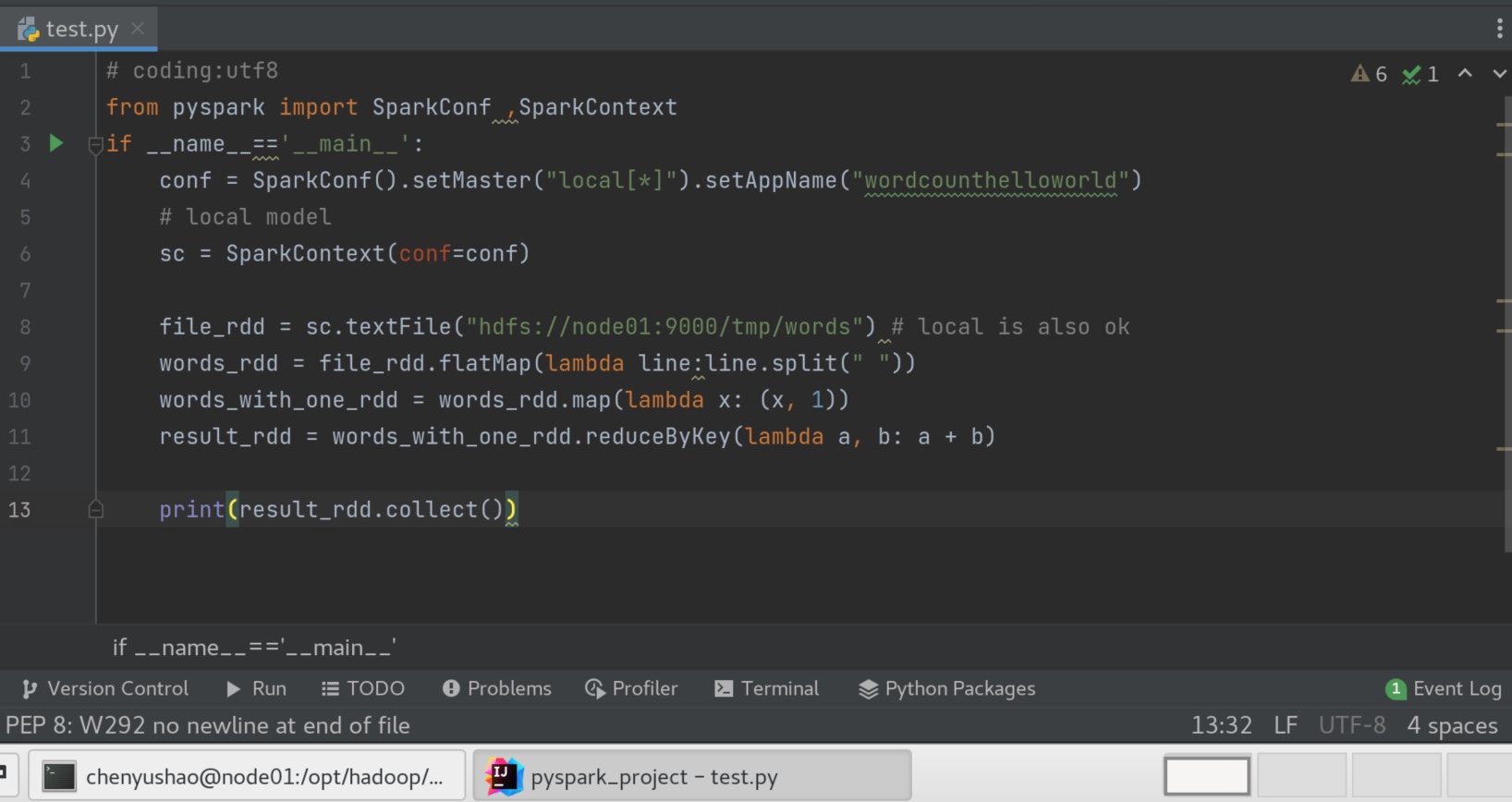
1、最好不要指定setMaster(), 如果要在spark-submit 提交给spark on yarn运行,代码setMaster("local[*]")设置了本地模式,本地模式会和集群模式冲突;
2、最好用hdfs的文件,而不是本地文件,因为要用到集群计算,别的机器可能找不到文件位置,hdfs大家都能访问的到。
1 vim /opt/data/idea_pyspark/test.py
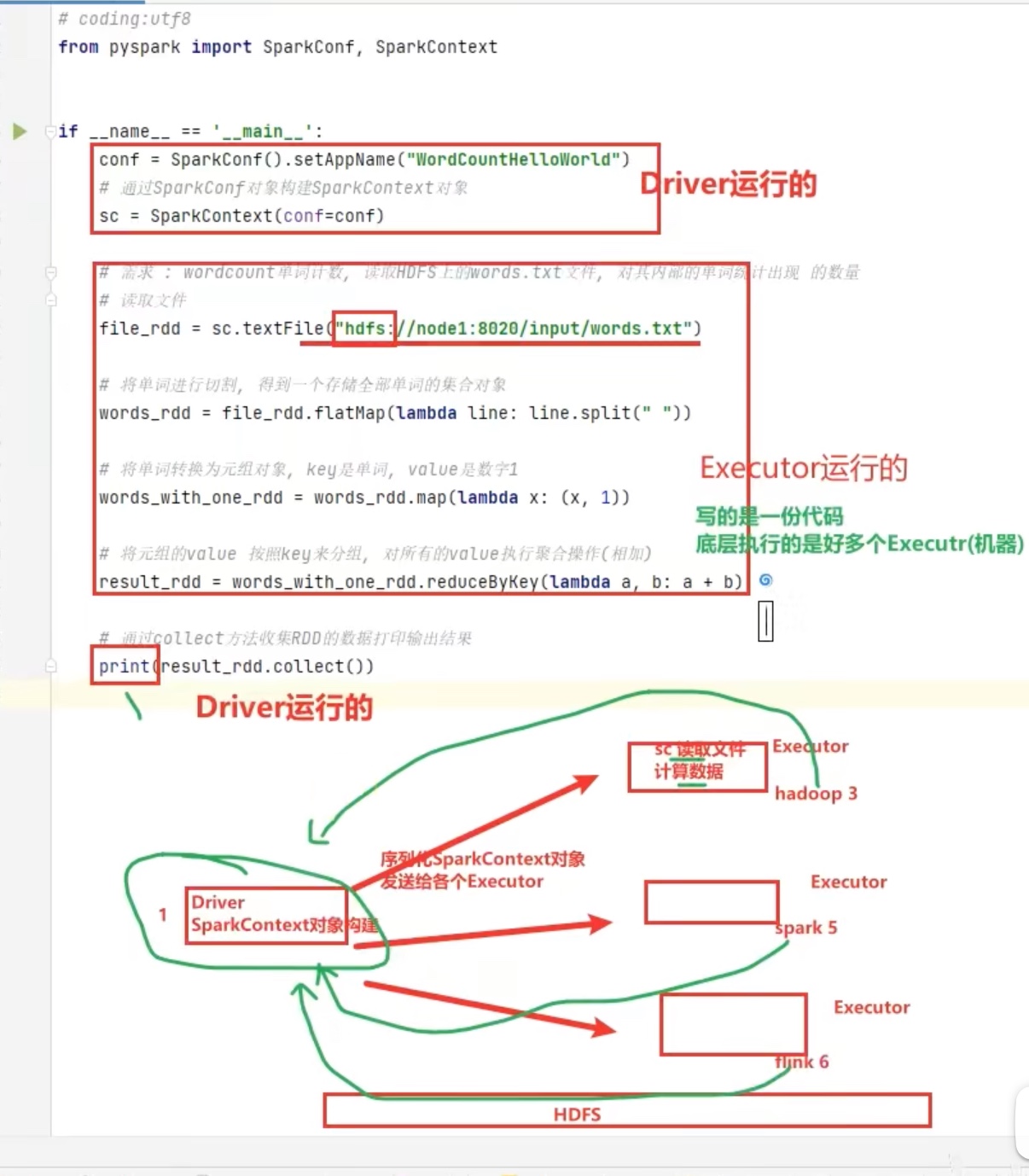
1 2 3 4 5 6 7 8 9 10 11 12 13 from pyspark import SparkConf ,SparkContextif __name__=='__main__' : conf = SparkConf().setAppName("wordcounthelloworld" ) sc = SparkContext(conf=conf) file_rdd = sc.textFile("hdfs://node01:9000/tmp/words" ) words_rdd = file_rdd.flatMap(lambda line:line.split(" " )) words_with_one_rdd = words_rdd.map (lambda x: (x, 1 )) result_rdd = words_with_one_rdd.reduceByKey(lambda a, b: a + b) print (result_rdd.collect())
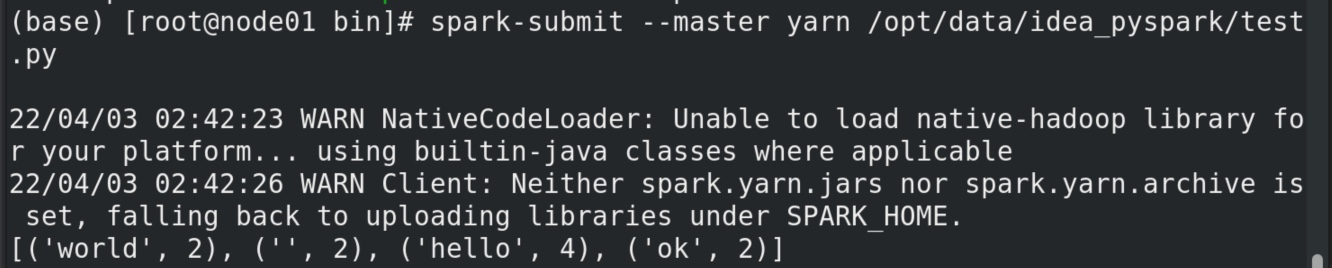
1 2 # 在spark on yarn 的客户端模式,运行自己写的脚本。需要一点时间来构建容器等等前面说过的步骤。 spark-submit --master yarn /opt/data/idea_pyspark/test.py
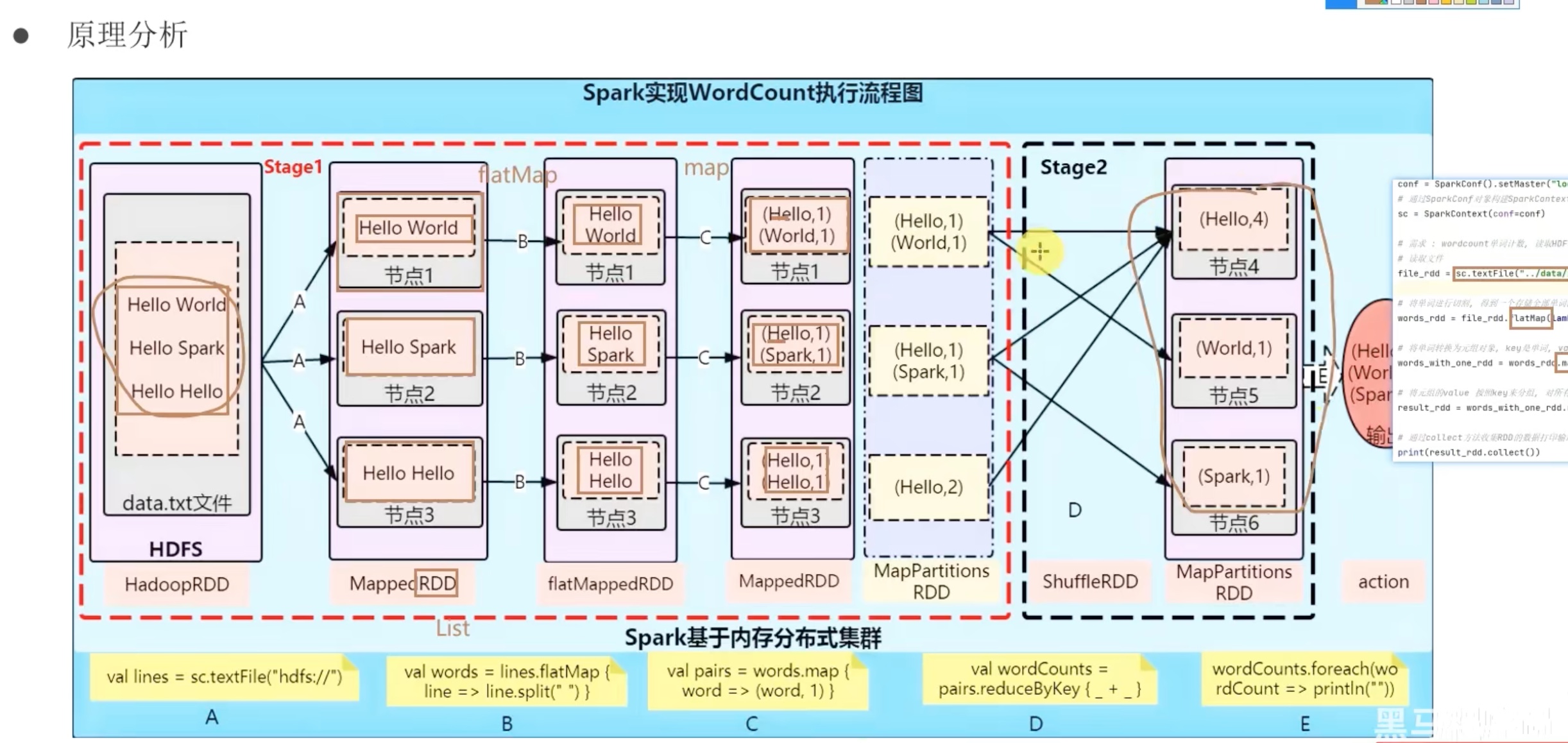
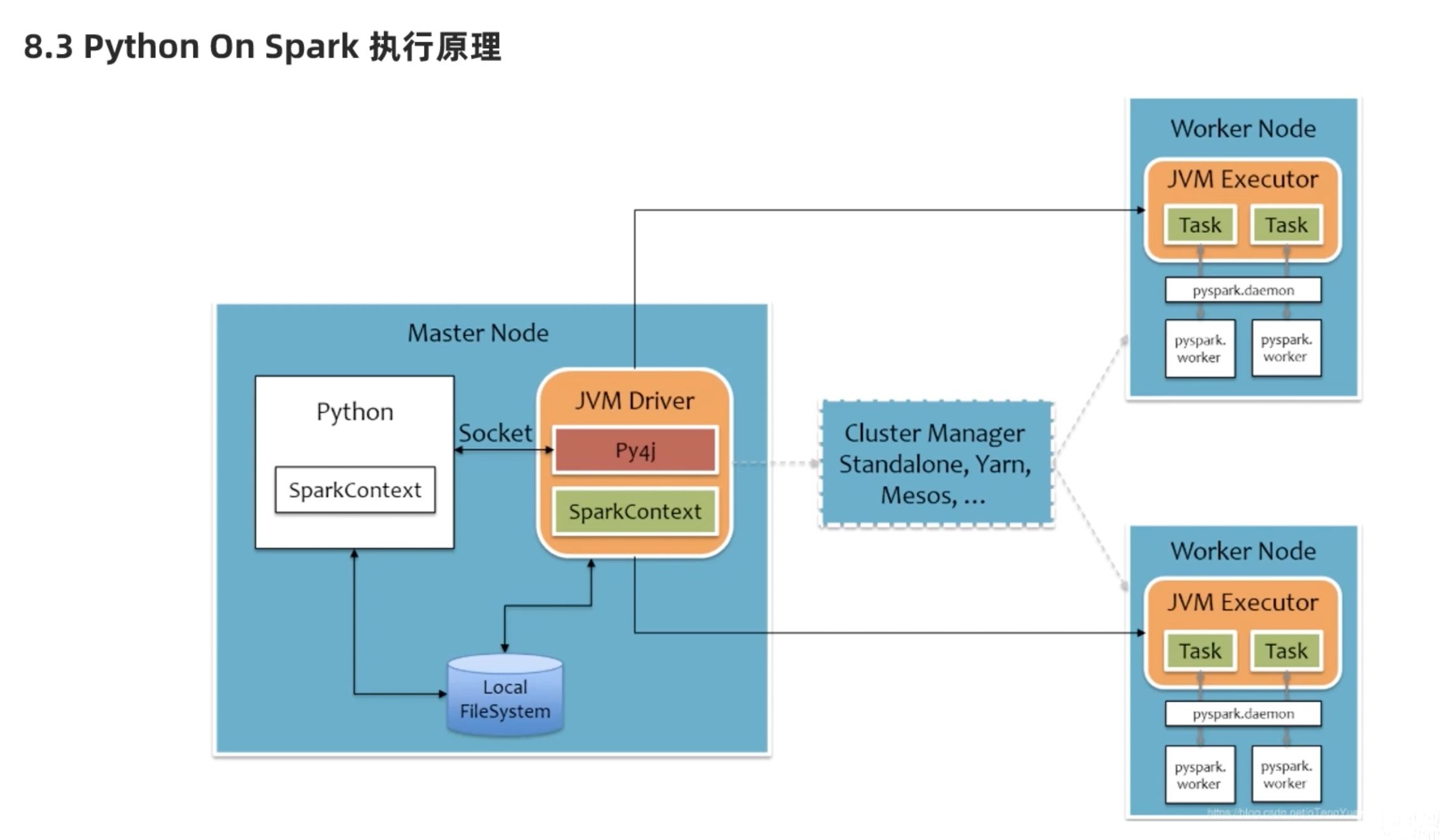
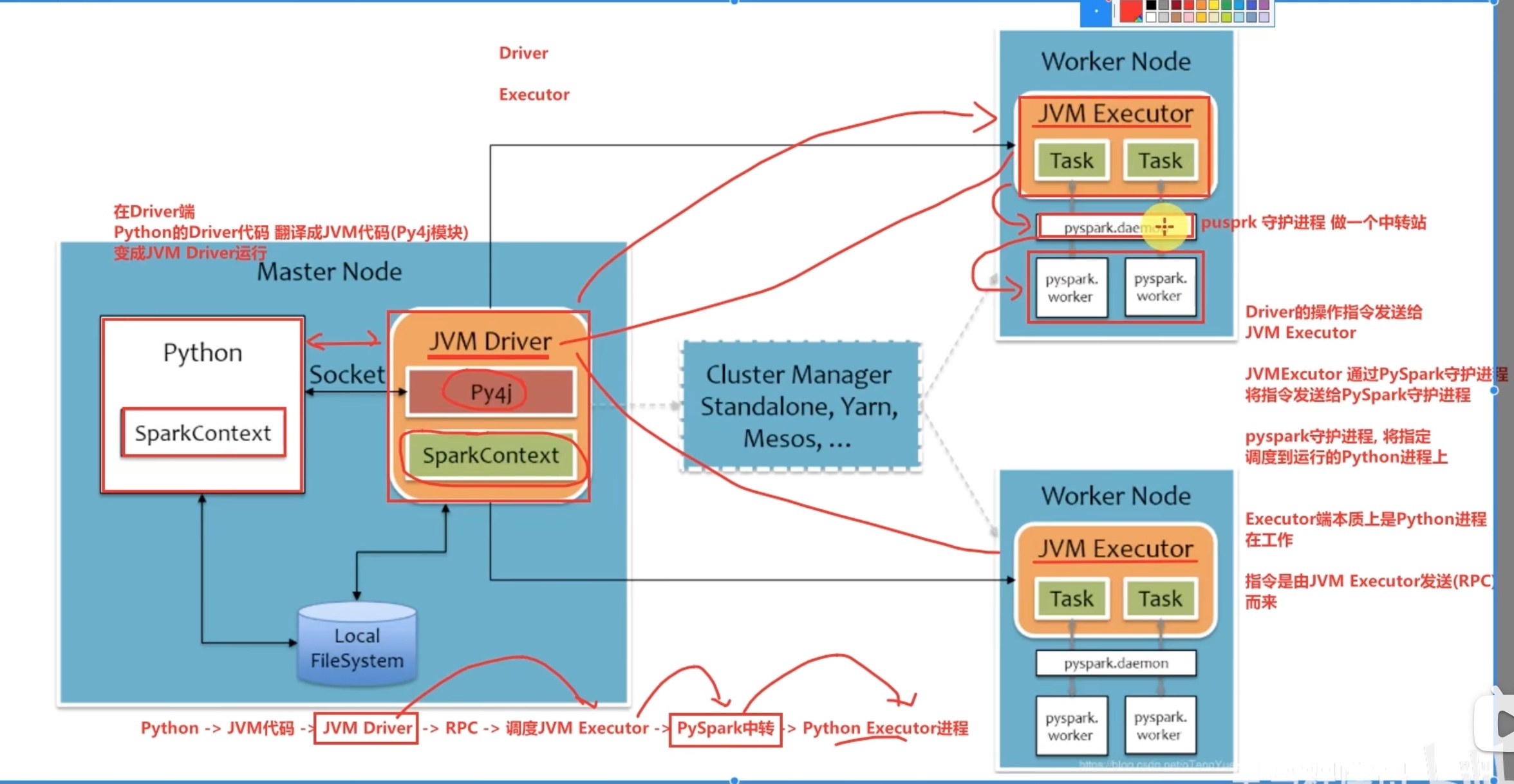
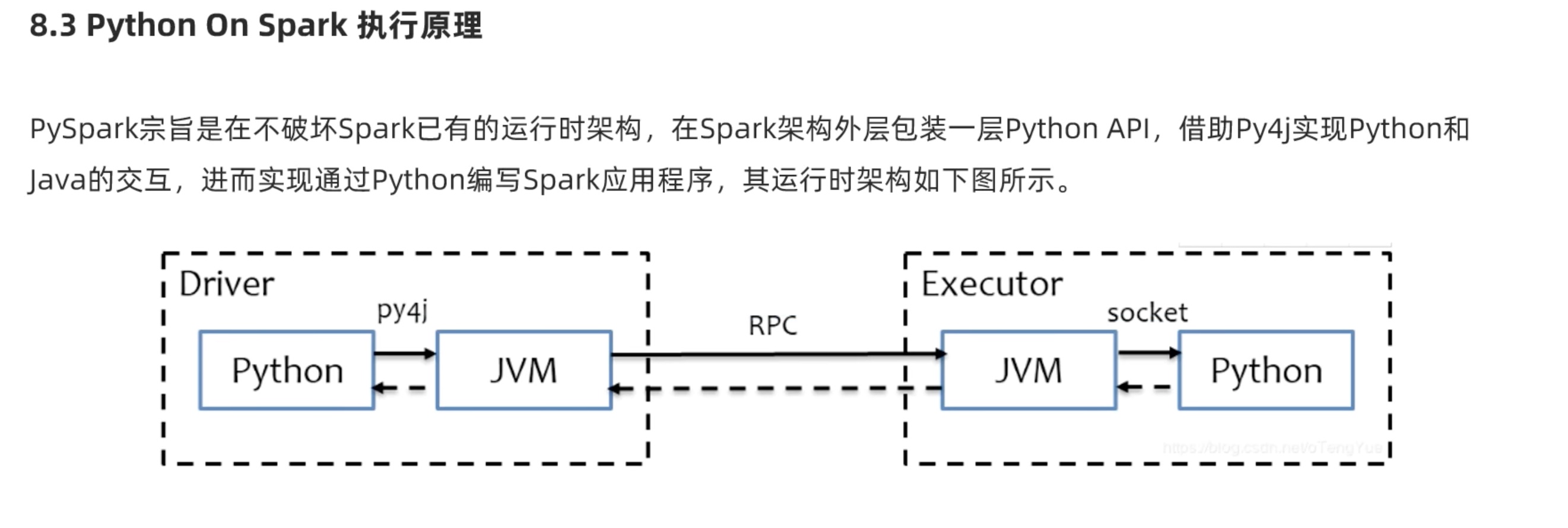
spark架构原理回顾(基于python)
上图简单来说,driver是python翻译成java给jvm driver,但是executor中jvm executor仅仅是传达指令,工作用python executor来做。