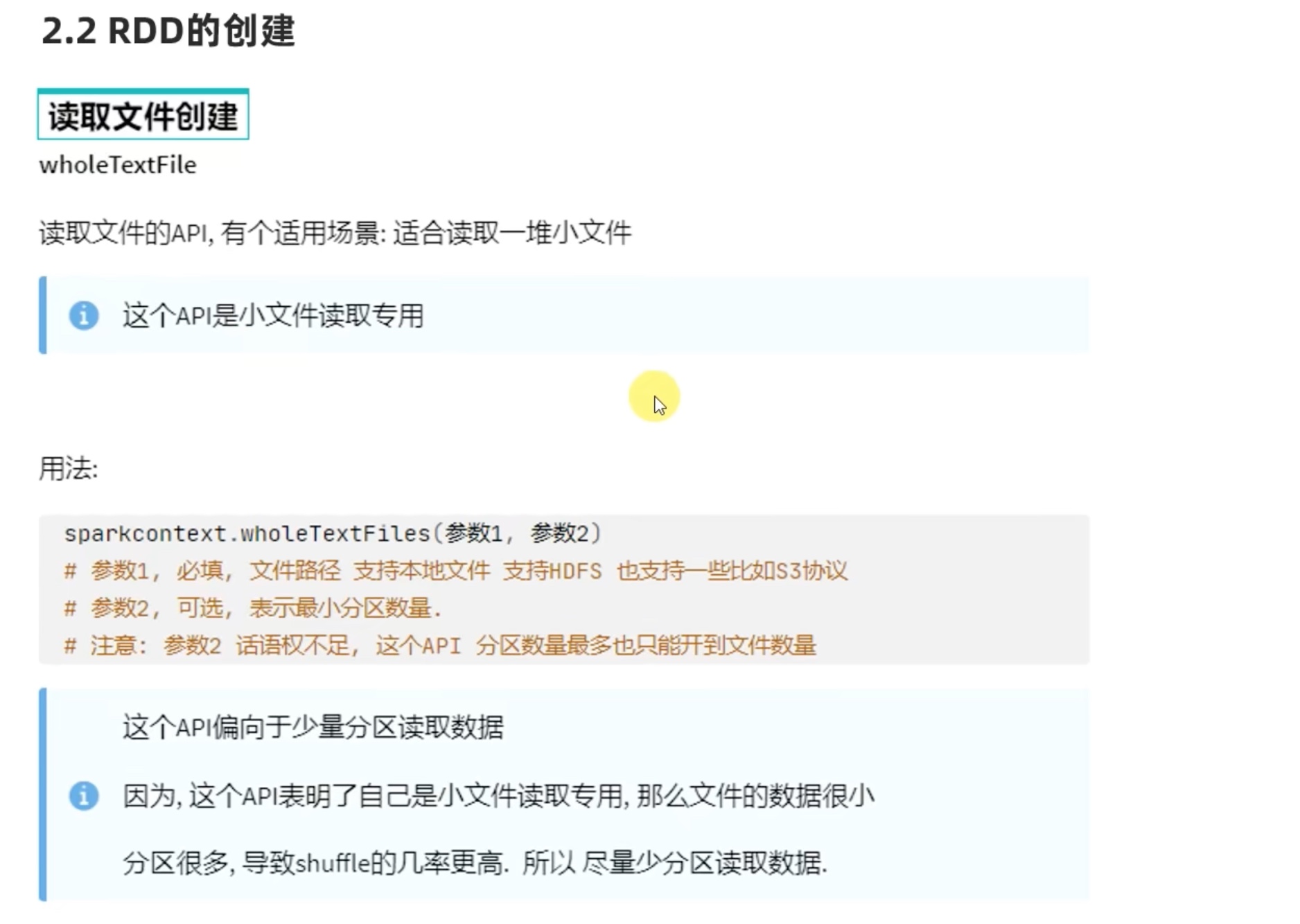
简介
简介RDD
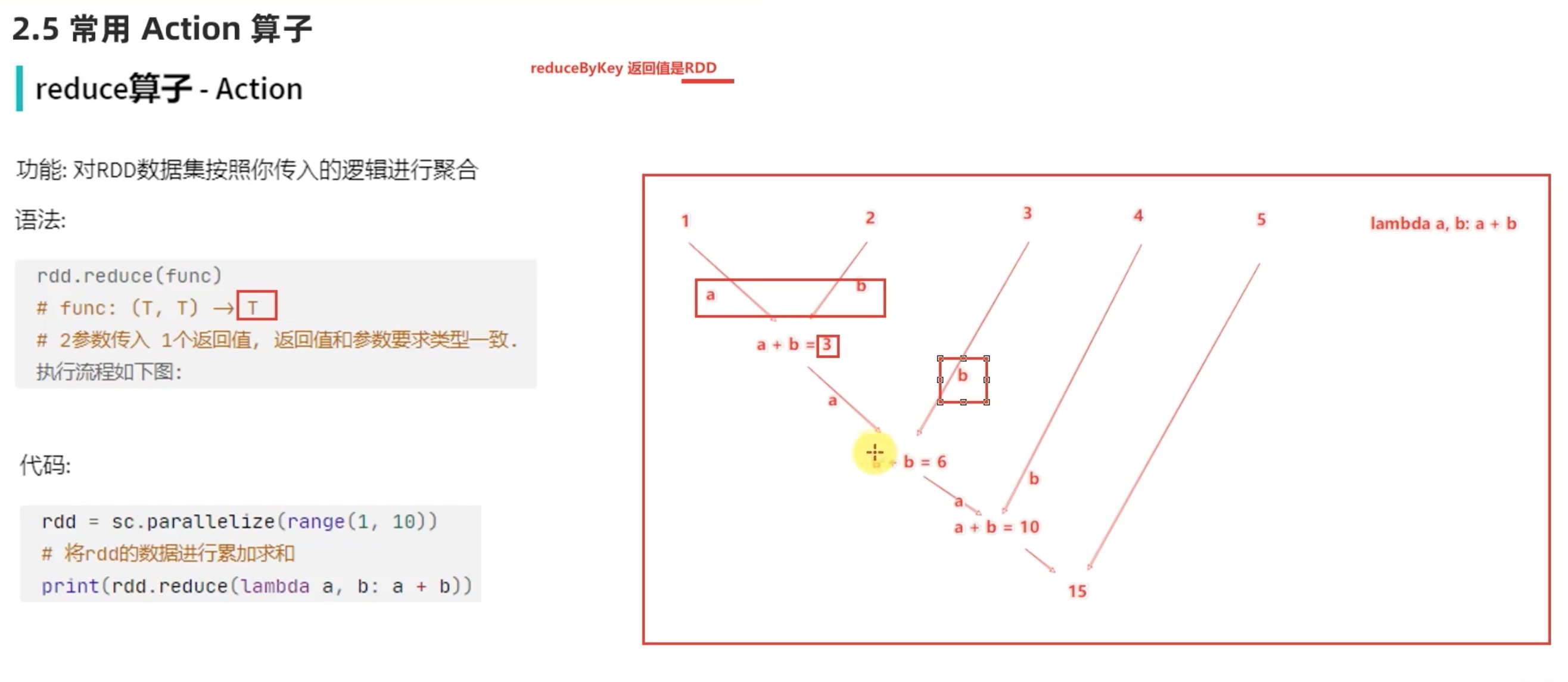
1 2 3 4 5 6 7 8 9 10 11 12 13 from pyspark import SparkConf ,SparkContextif __name__=='__main__' : conf = SparkConf().setAppName("wordcounthelloworld" ) sc = SparkContext(conf=conf) file_rdd = sc.textFile("hdfs://node01:9000/tmp/words" ) words_rdd = file_rdd.flatMap(lambda line:line.split(" " )) words_with_one_rdd = words_rdd.map (lambda x: (x, 1 )) result_rdd = words_with_one_rdd.reduceByKey(lambda a, b: a + b) print (result_rdd.collect())
以上代码分析如下。
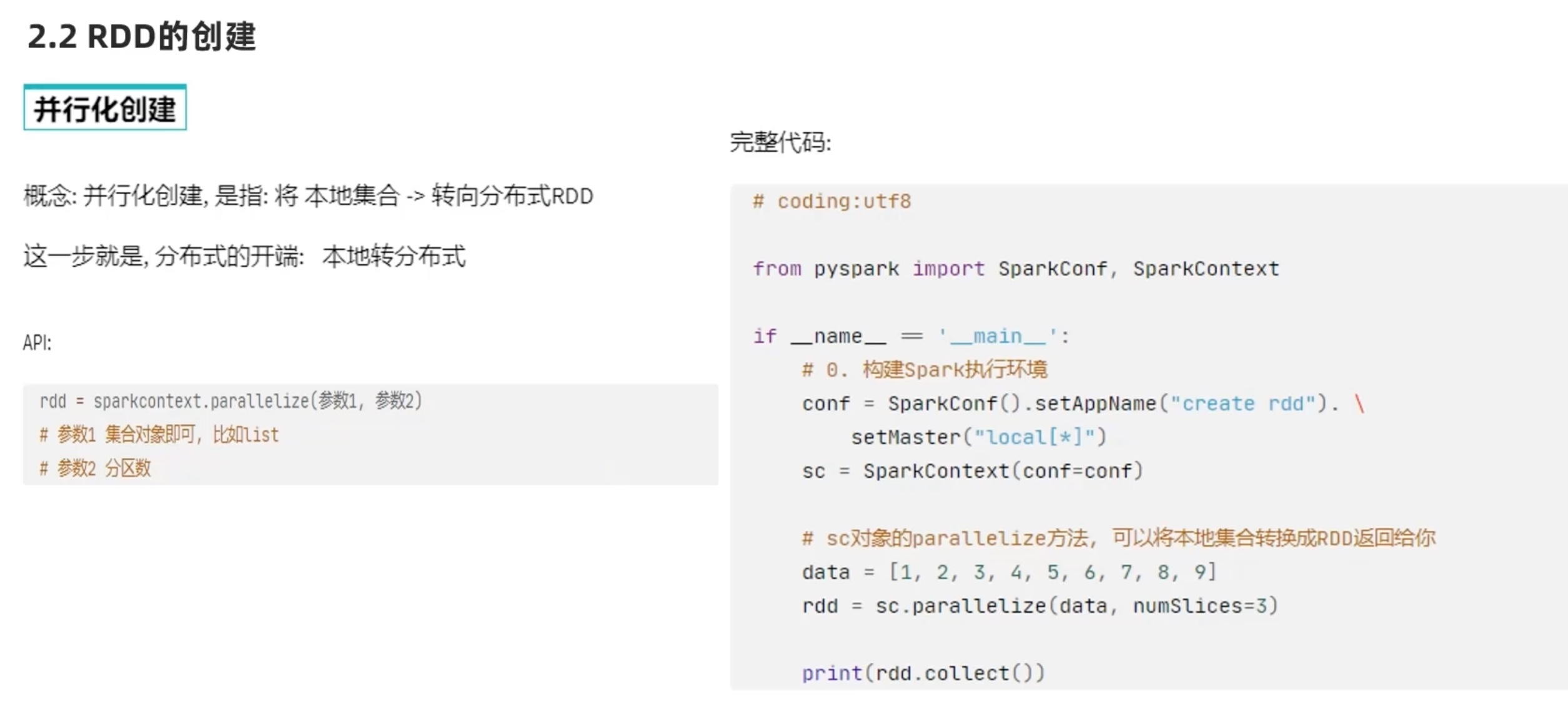
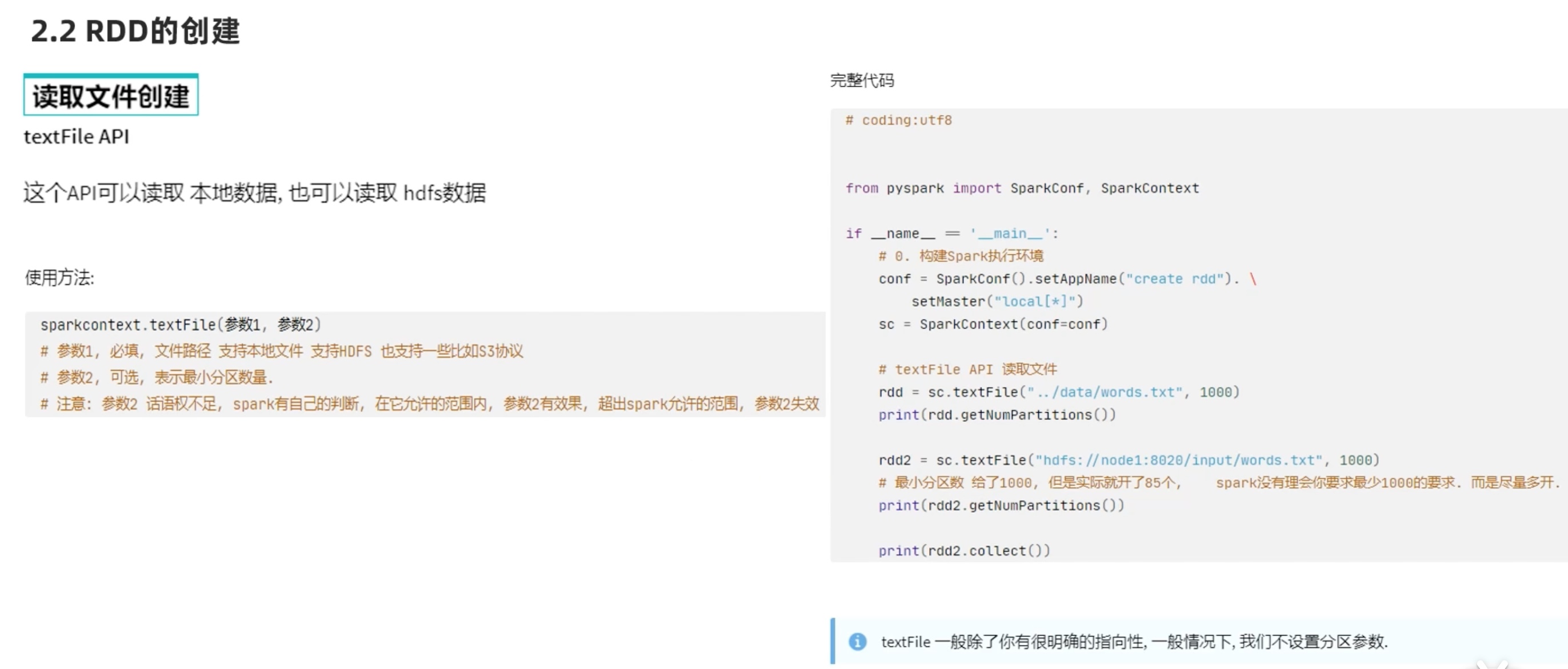
RDD编程入门 RDD的创建
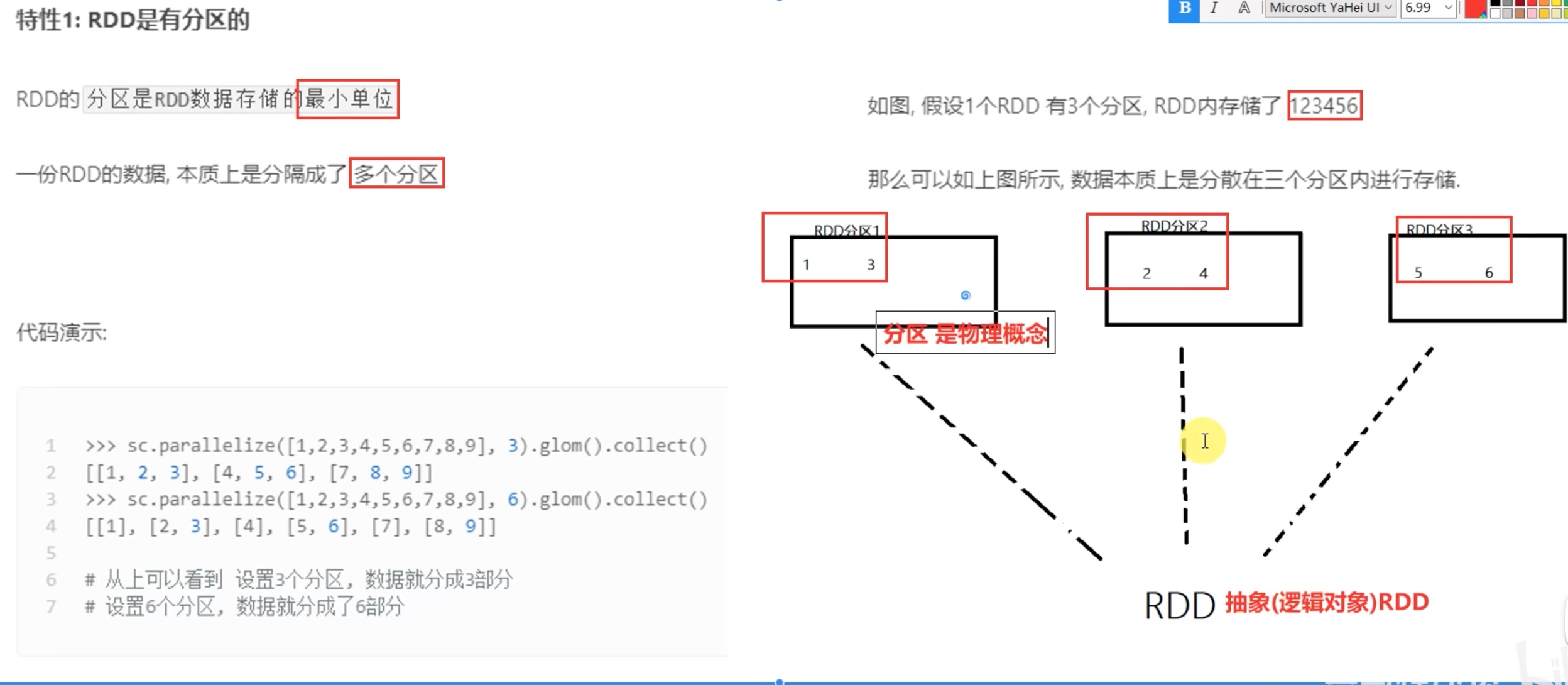
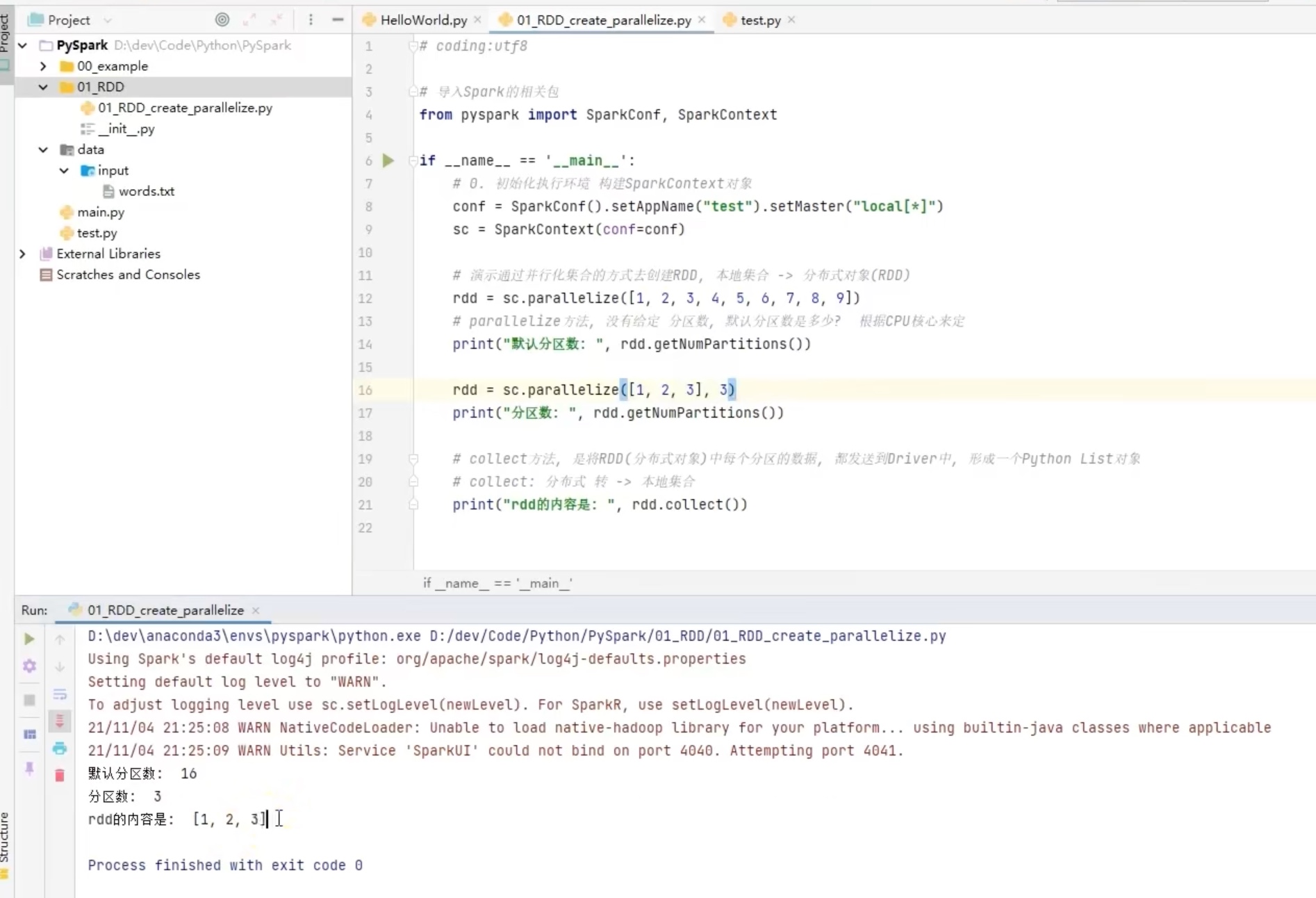
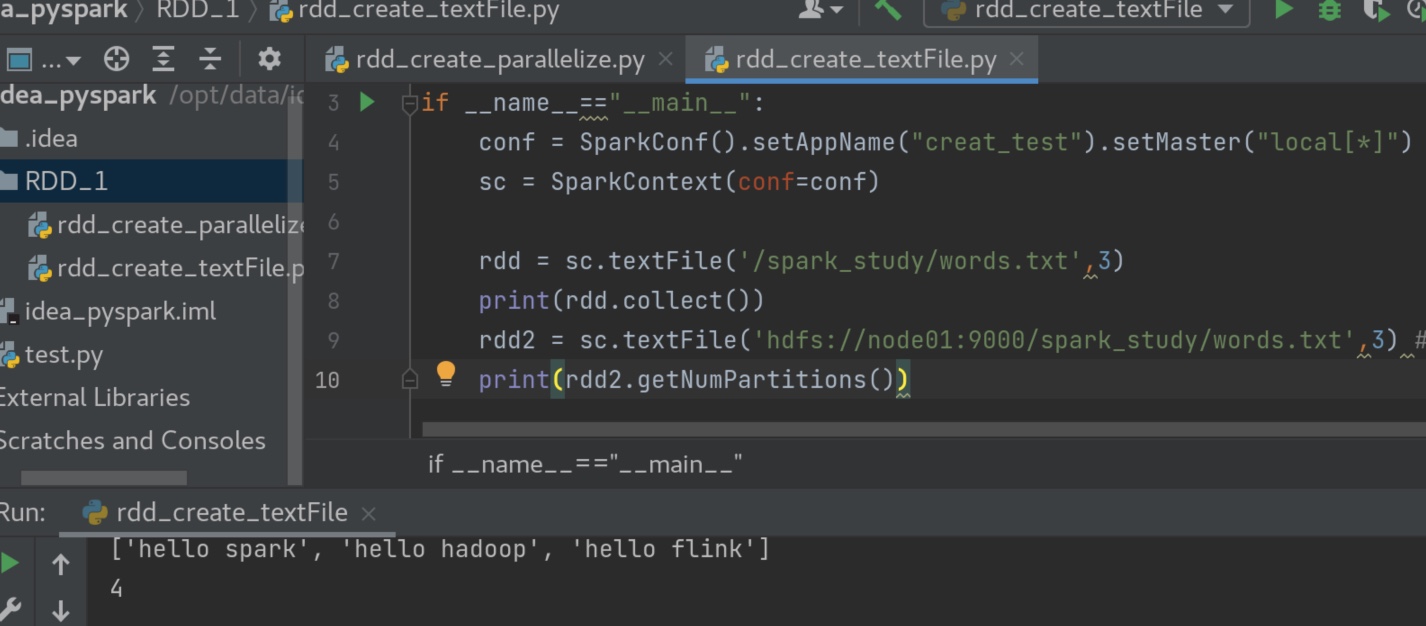
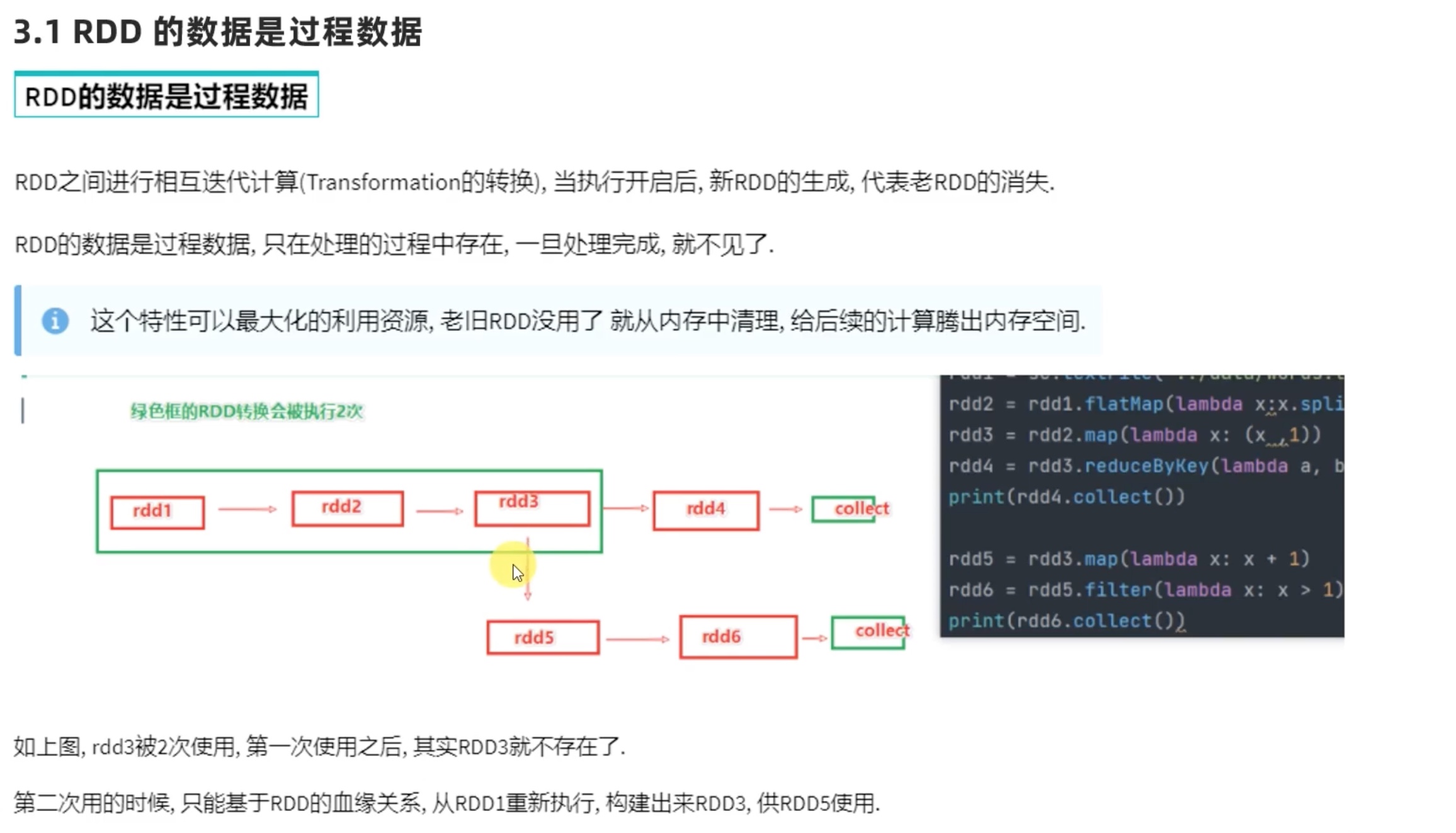
我这里的地址默认就是从hdfs 的位置去找了,即便是不写hdfs://node01:9000 也是从这里去找而不是本地,代码写了想最少分3组,但是实际上还是科学的分了4组,可见参数2不是强制的。
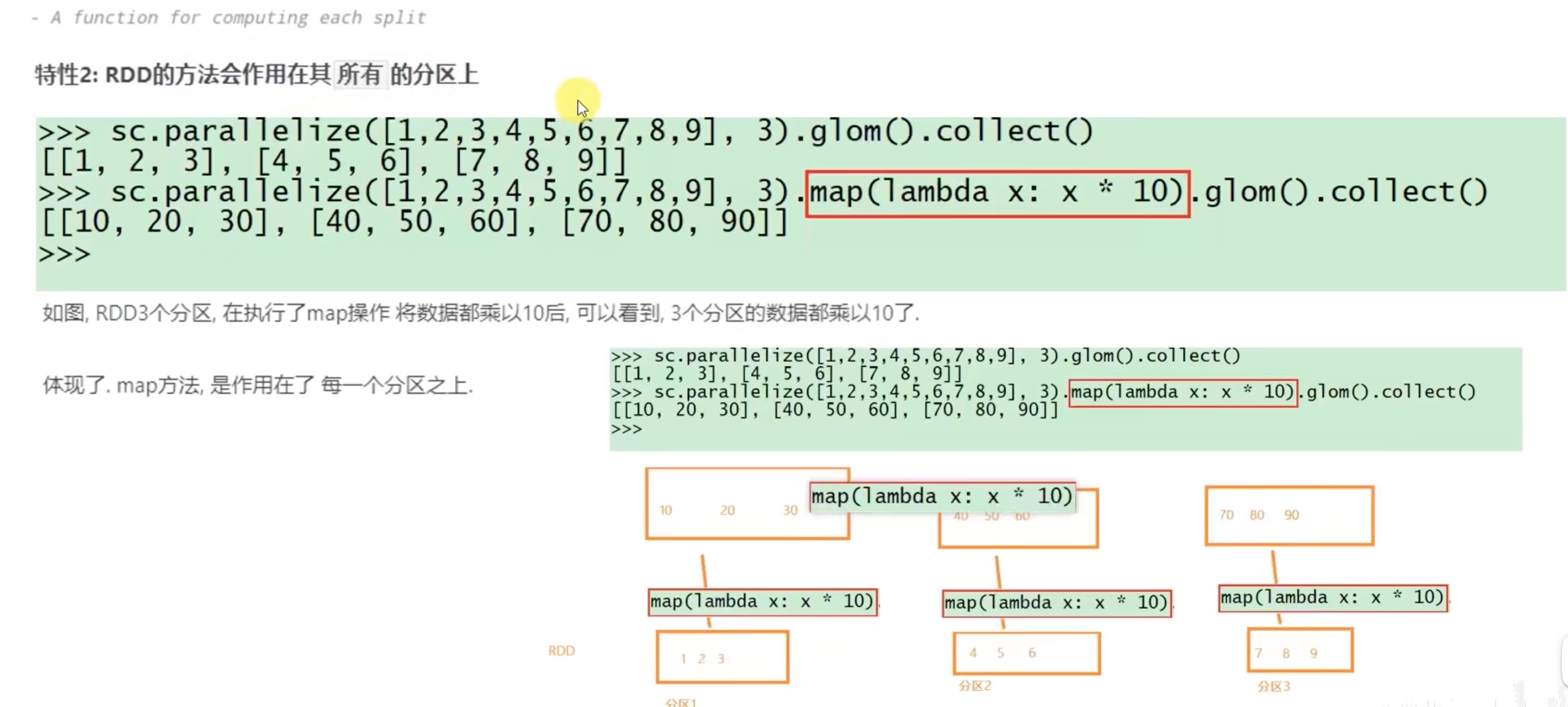
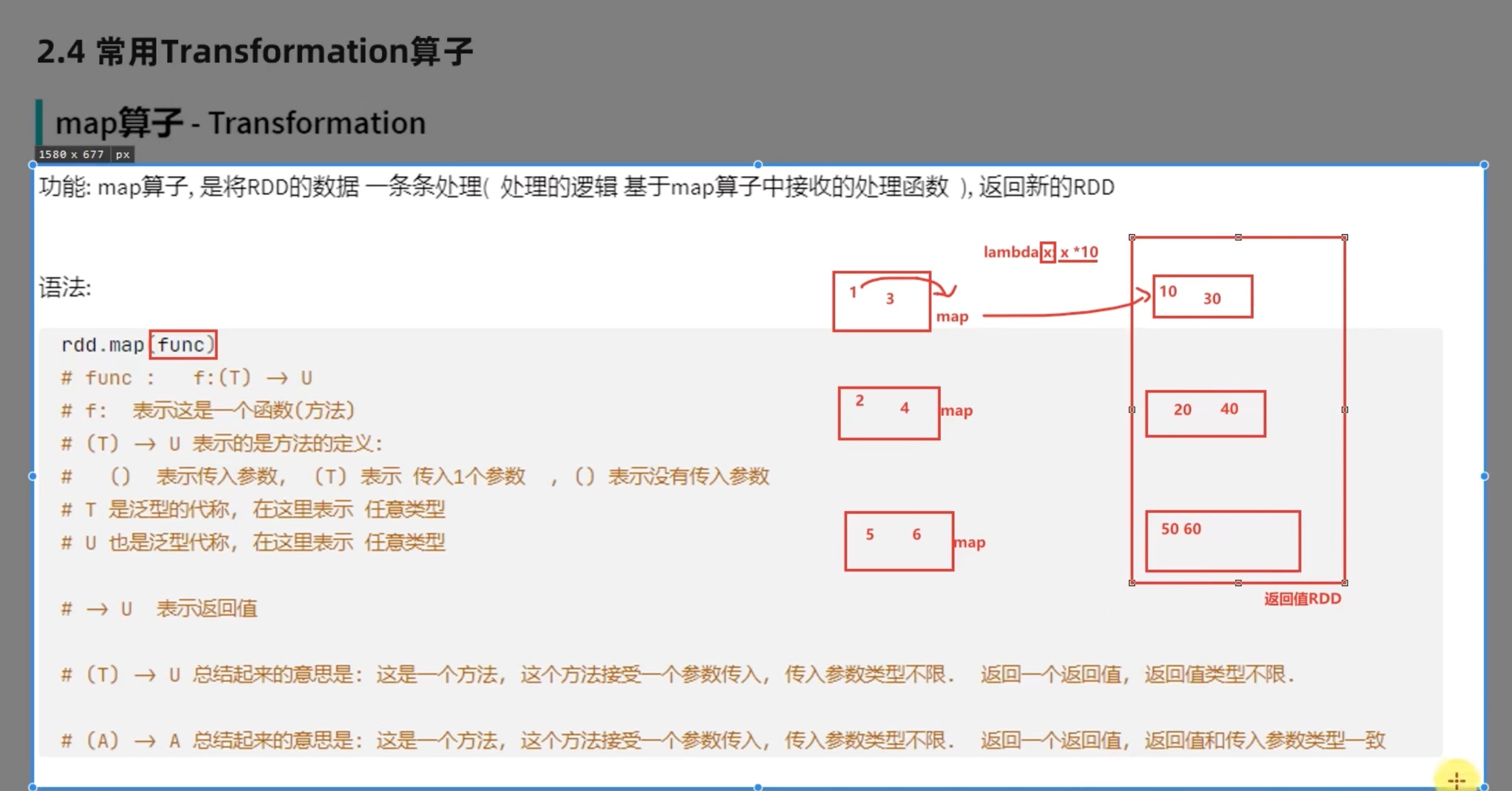
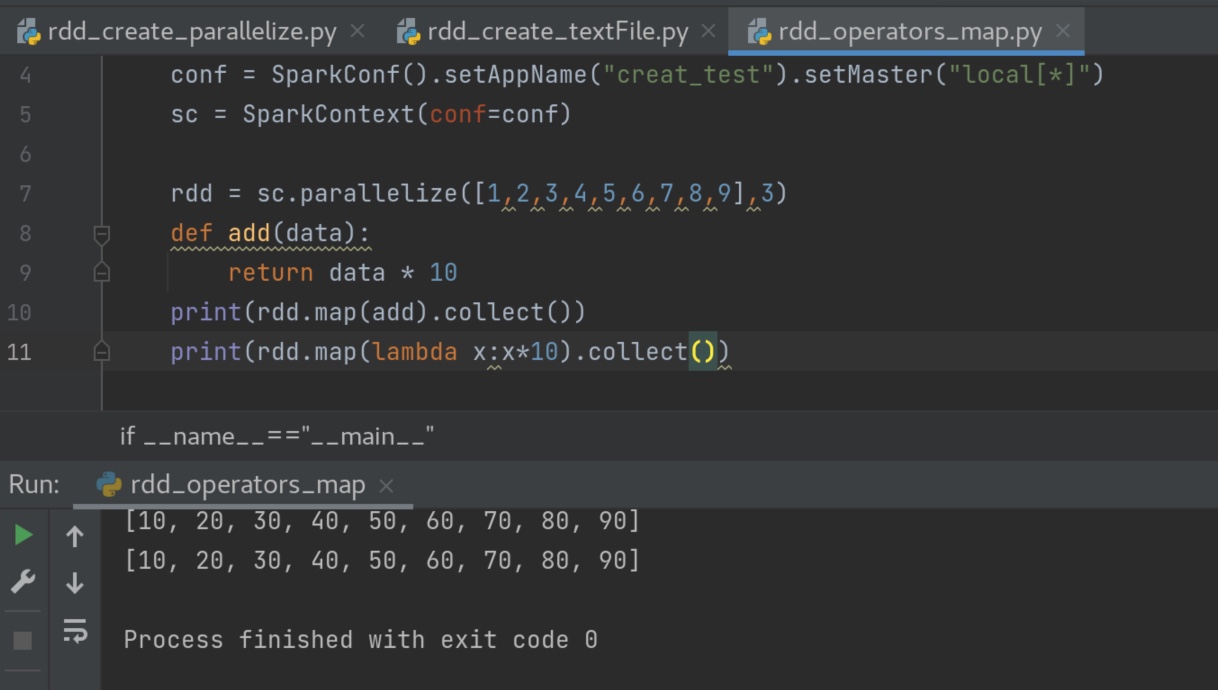
顺带提一下,python中的map(lambda x: x[1],迭代器) x 是迭代器中的每一个元素,此元素作为lambda函数的参数进入lambda函数,一个一个输出,在python中用list()函数收集成list ,rdd 中,每个分组都会计算一次map()函数,用collect()函数在每个组中收集并最终汇总到一个list中。
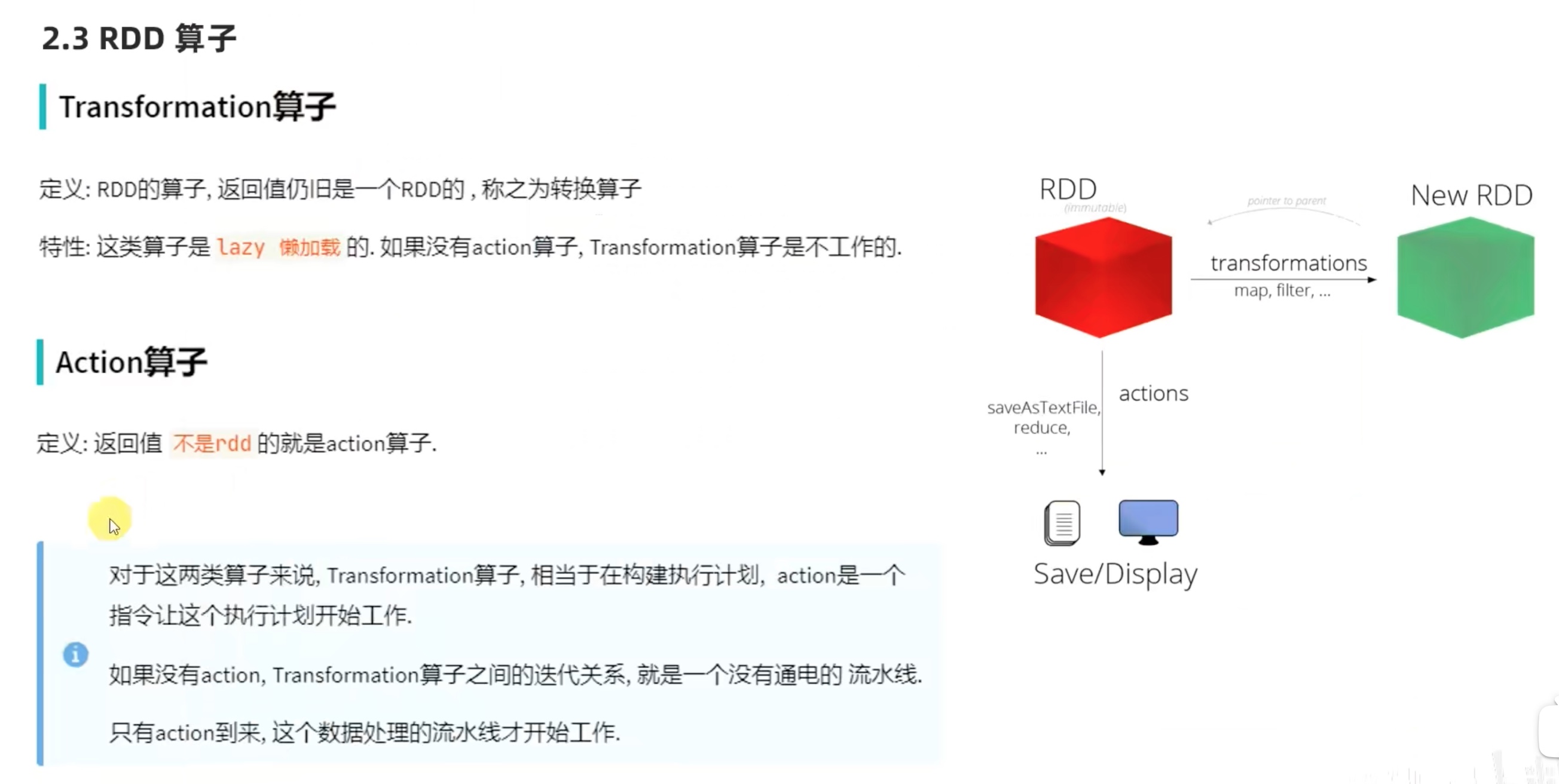
RDD算子
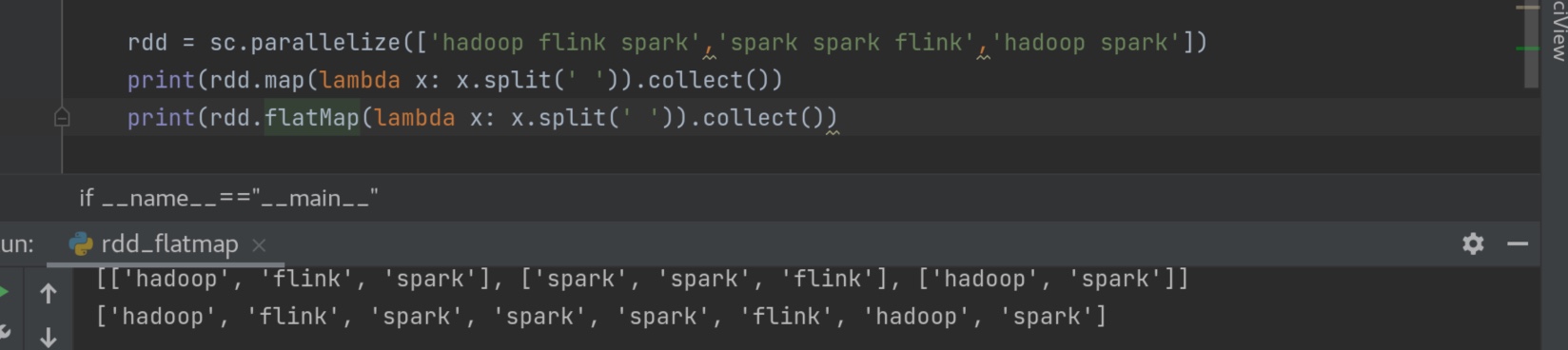
flatMap 就是内部fun函数处理完毕之后再解除嵌套,如果仅仅是想解除嵌套不处理可以 把内部的fun 写成 lambda x:x 不做处理只解除嵌套。
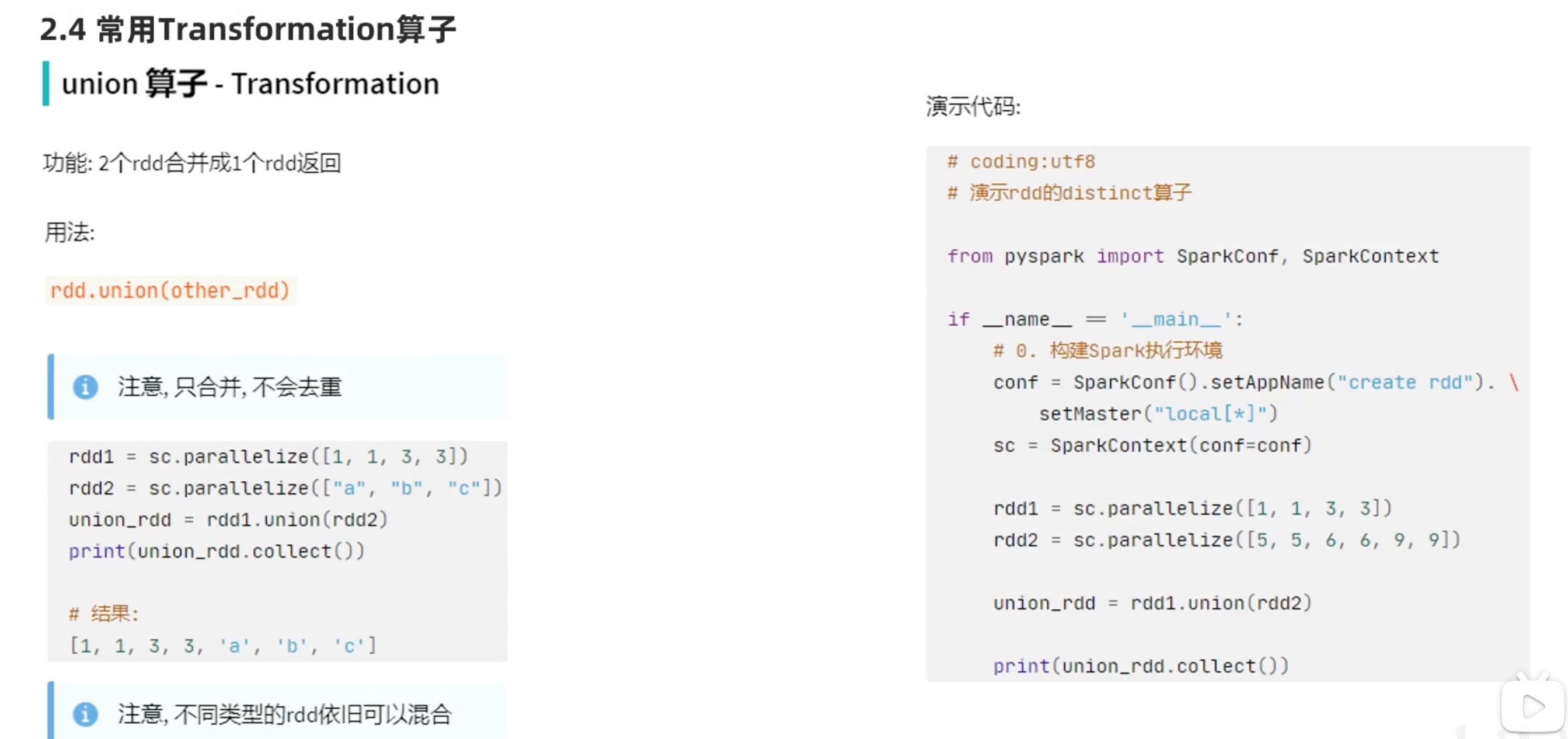
union算子不会去重,而且元素是不同类型的rdd一样可以被union到一起。
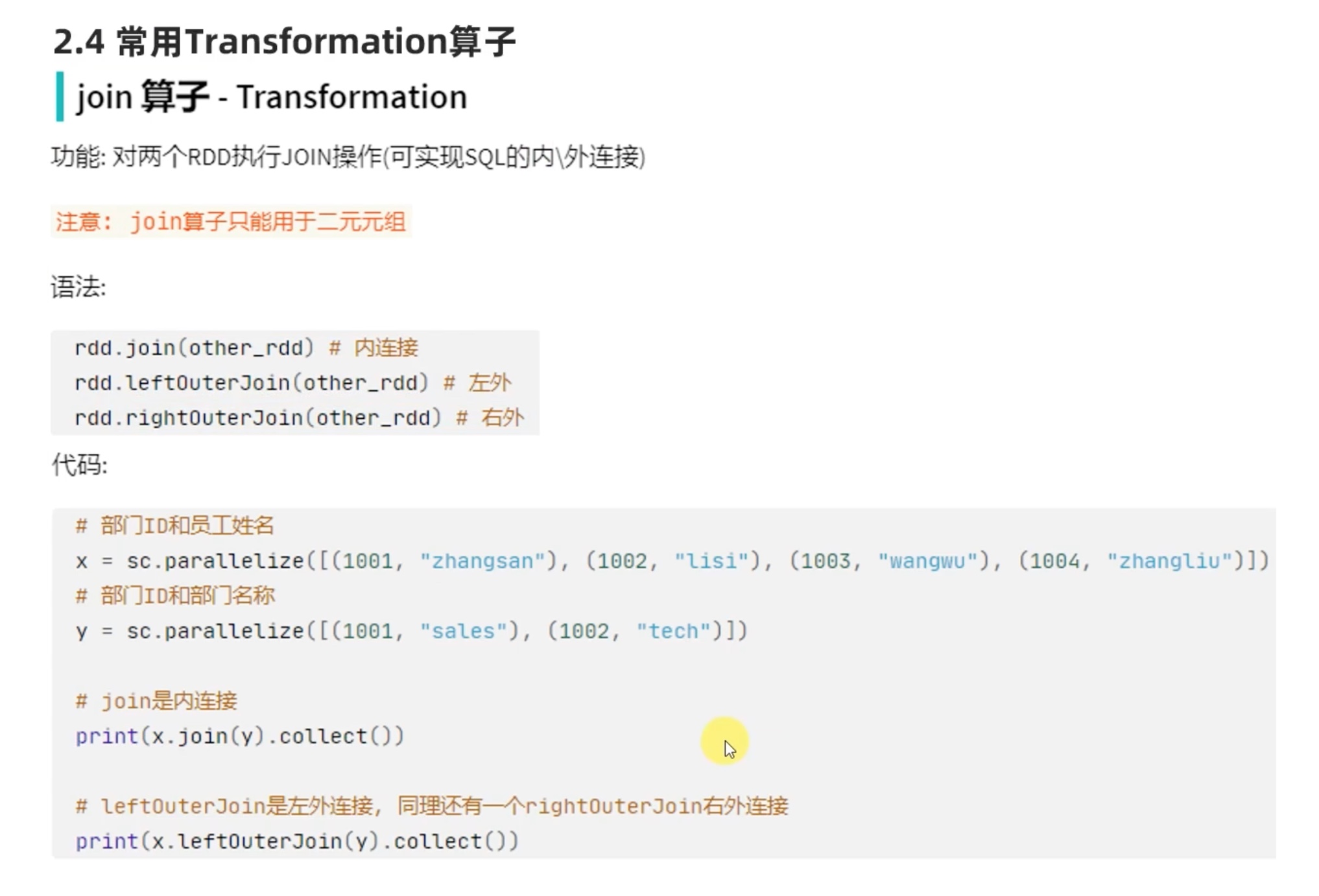
join的条件是 按照二元元组的 key 值来连接。

注意intersection相交和join内连接的不同,join 是根据key,intersection完全一样才保留。
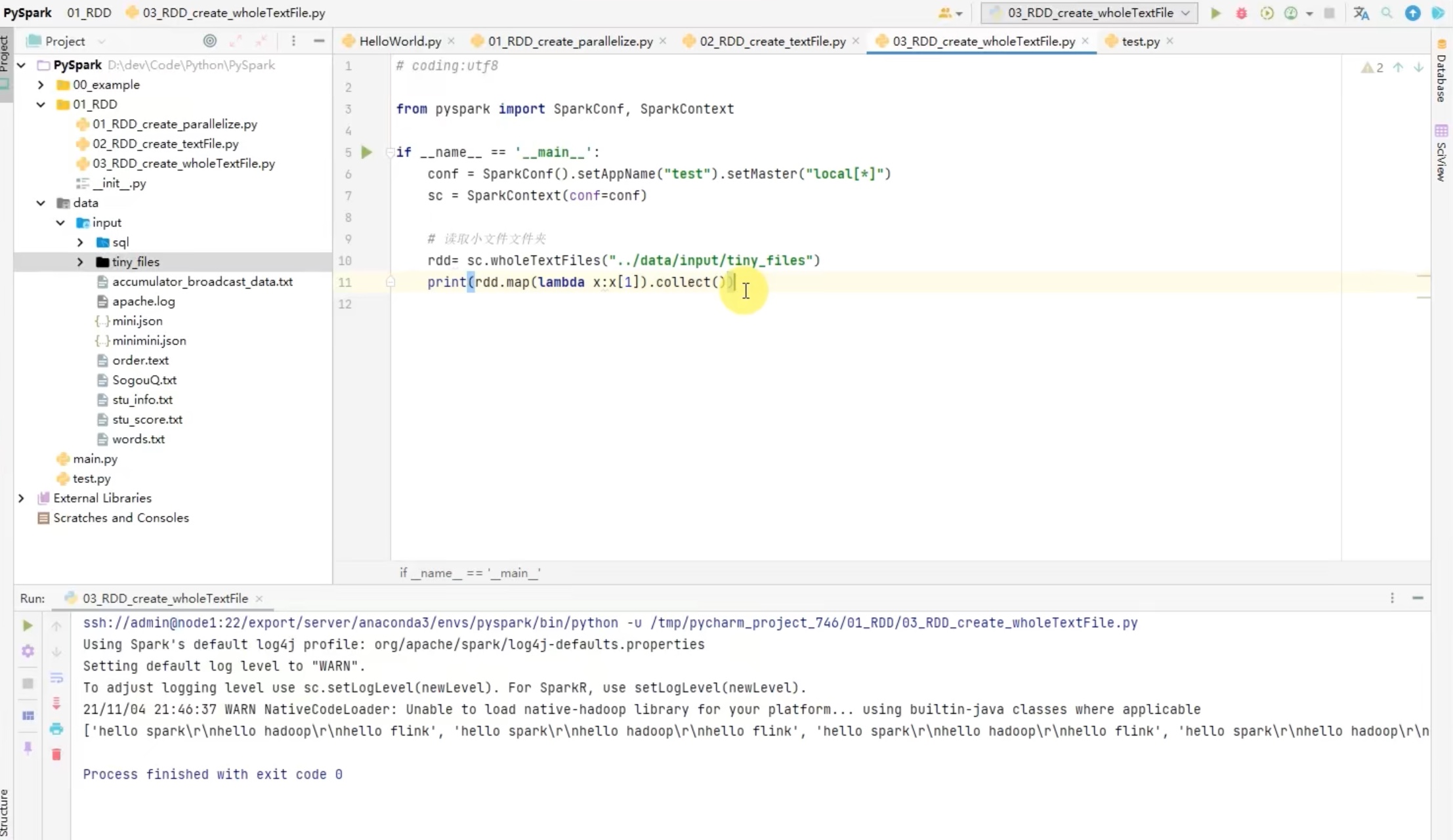
方便查看数据分区情况,可以用flatmap(lambda x:x)来解除嵌套。
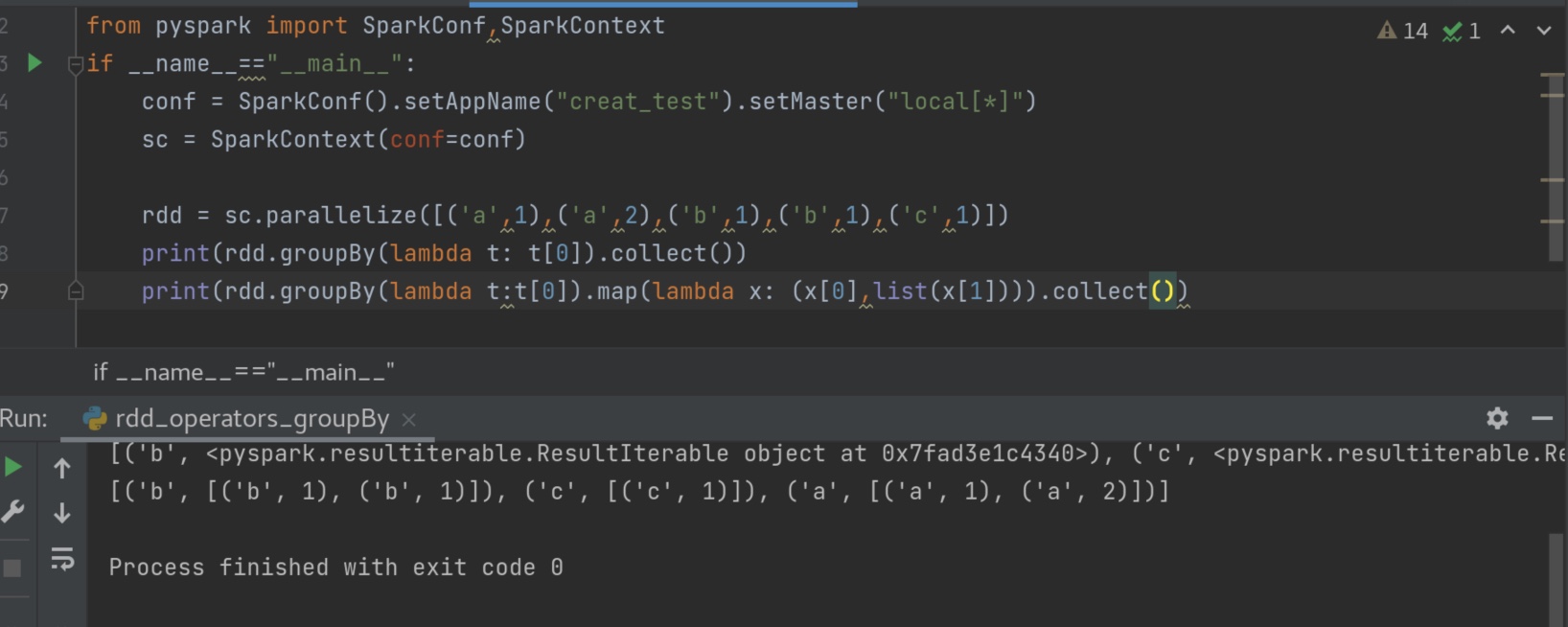
groupbykey 和groupby 的区别就是 前者仅仅保留 value,后者保留了元素的全部。
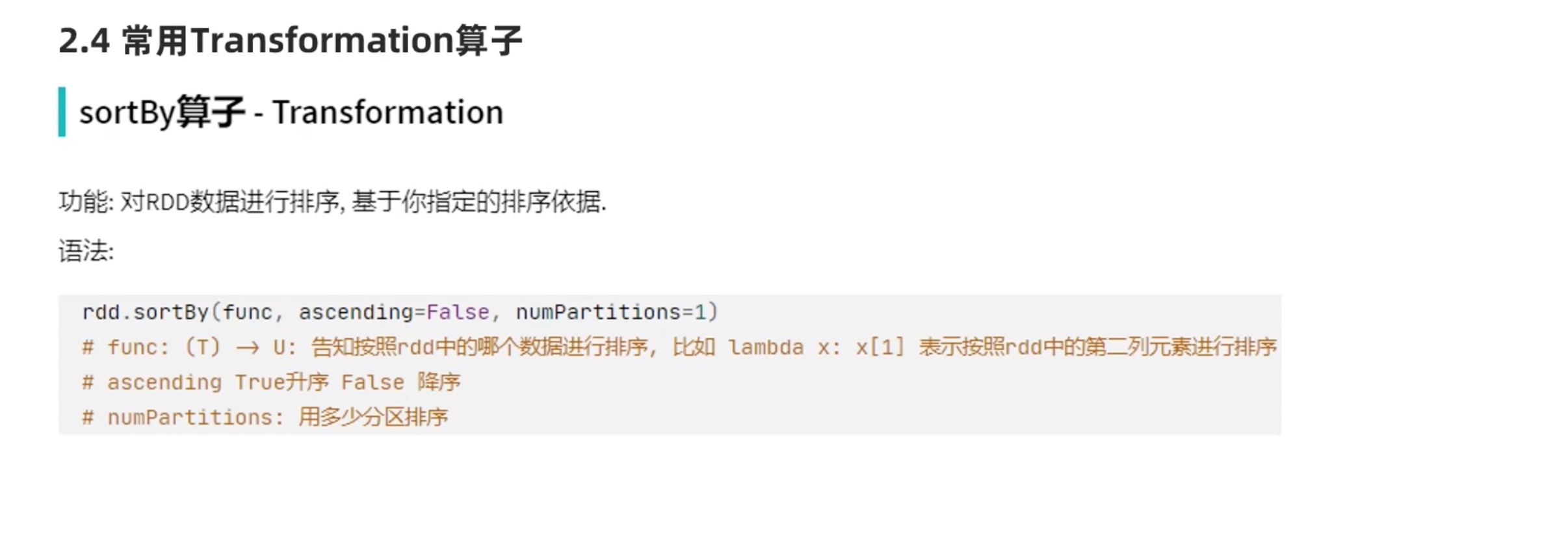
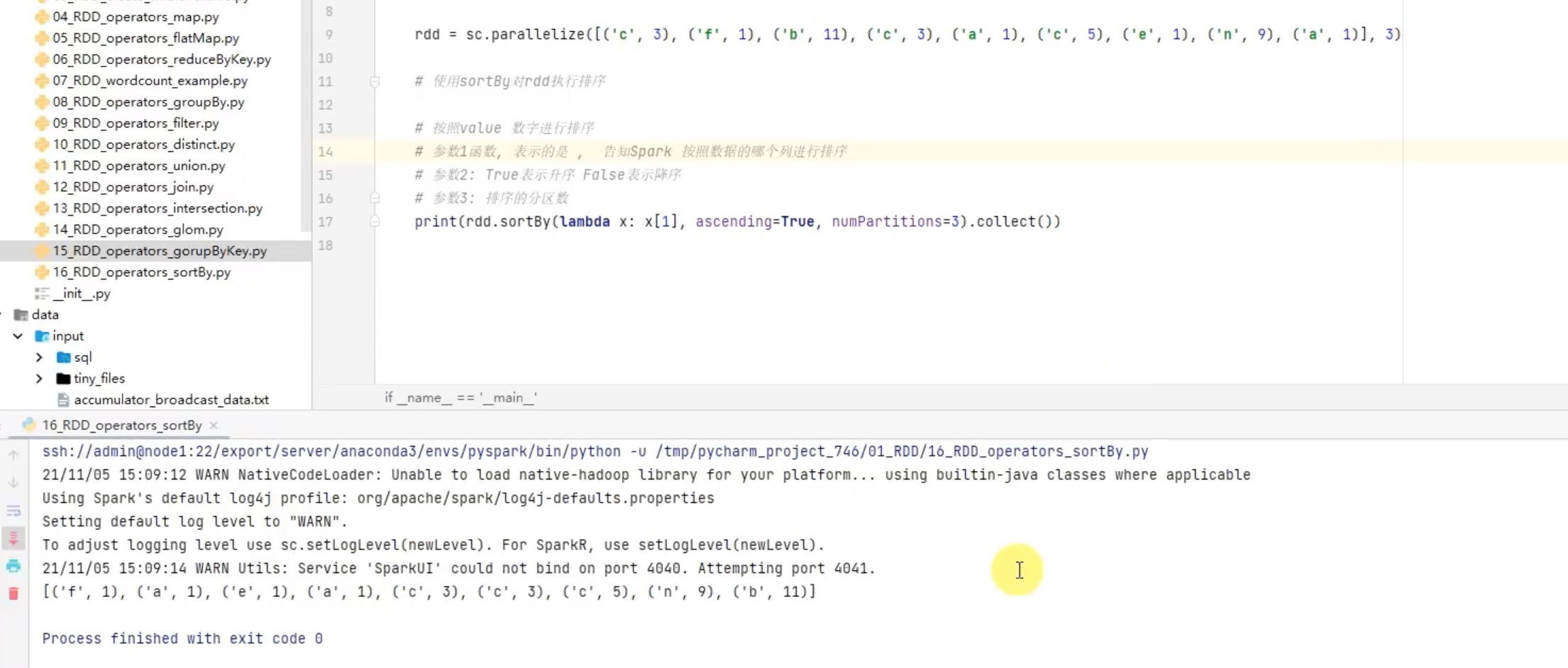
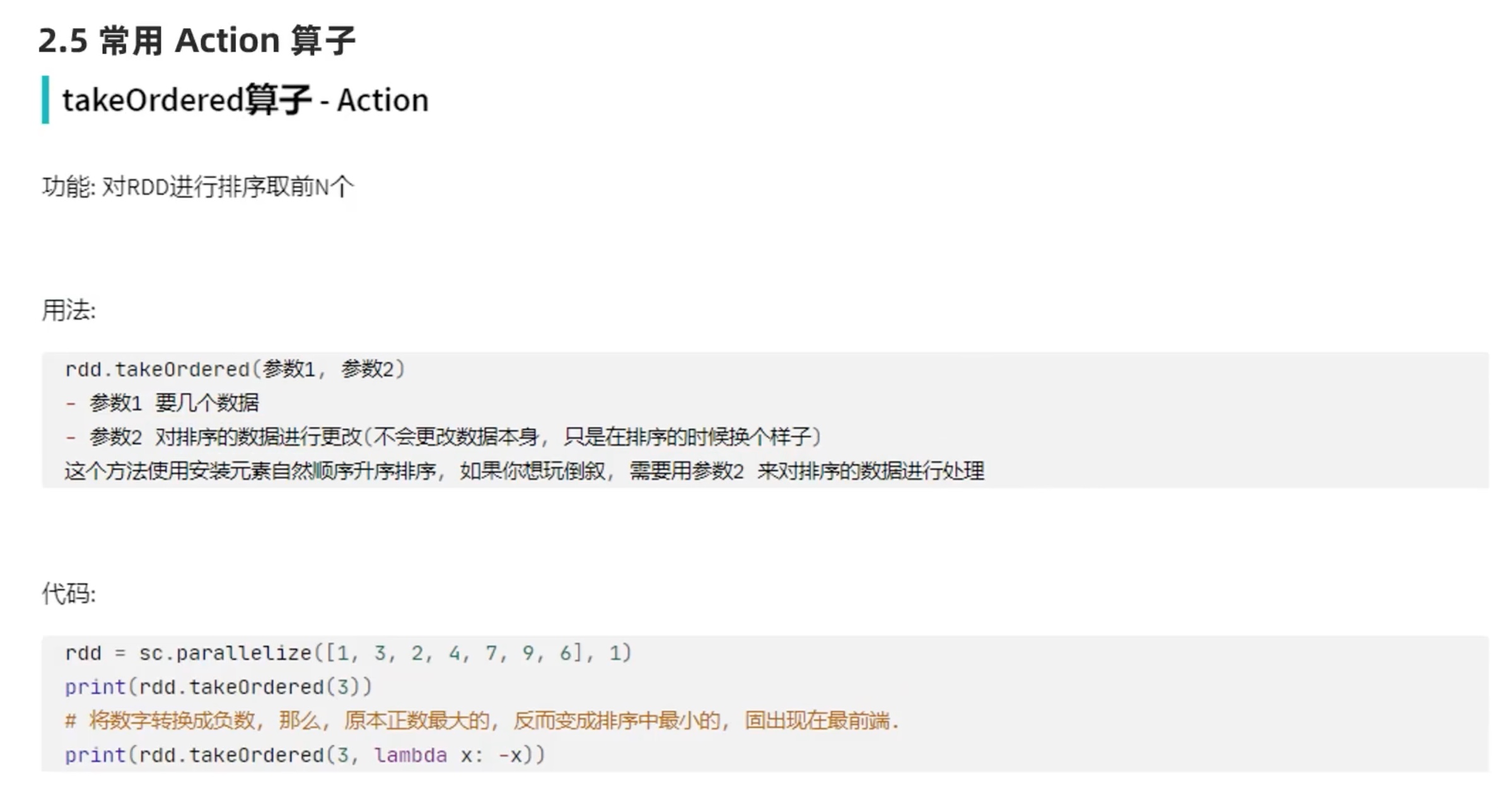
注意:排序是在executor内完成的,sortby仅仅能保证在一个executor内有序。如果想要结果全局有序,需要定义numpartitions=1,上面这种numpartitions不等于1也全局有序了,是因为用的是local模式在一个executor上运行的。
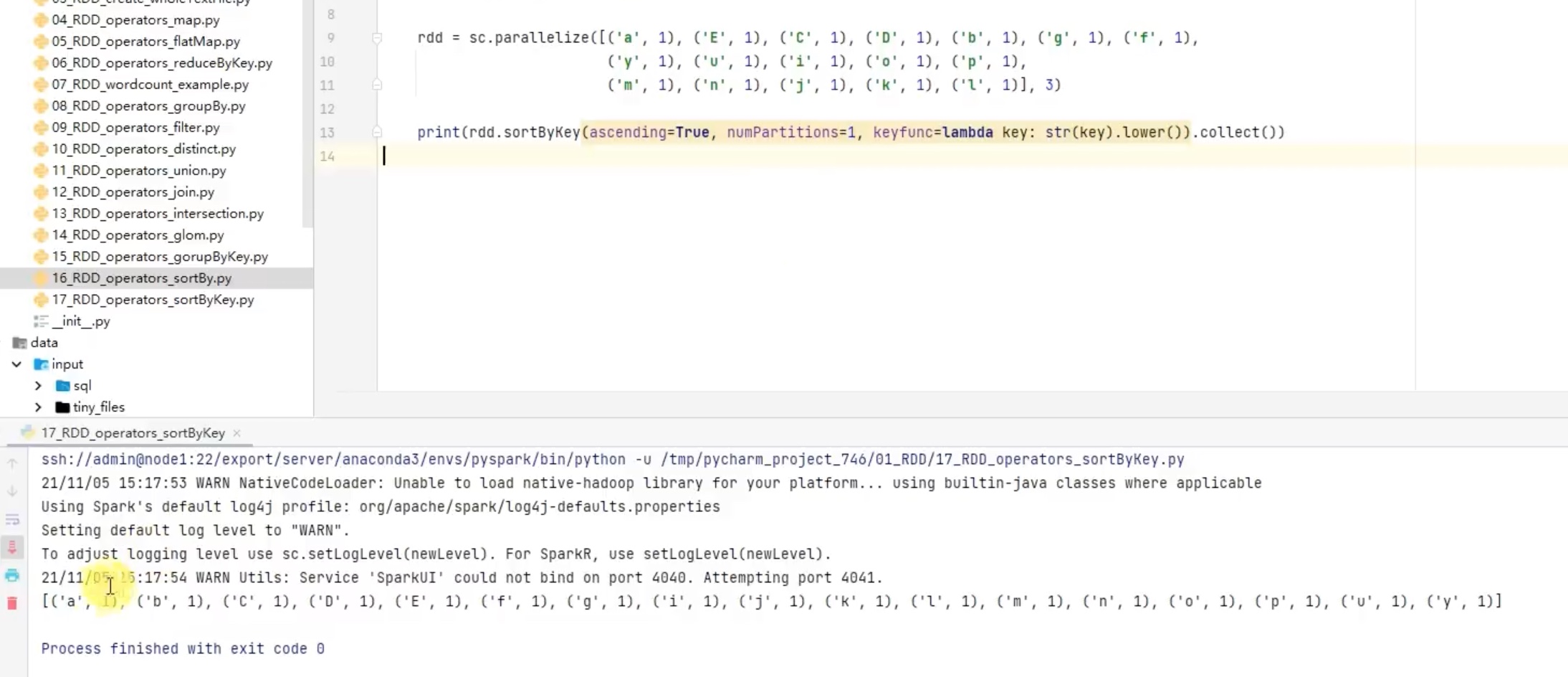
注意:其中对小写的lower()转换,只是改变了排序过程中的值,最终结果还是按照原数据排序。
案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # conding:utf8 from pyspark import SparkConf,SparkContext import json # 字符串里面是字典,就是json格式。 if __name__=="__main__": conf = SparkConf().setAppName("creat_test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.textFile('/spark_study/order.text') # 这里是hdfs 中的路径,之前已经 Hadoop fs -put 上了文件。 # print(rdd.collect()) json_rdd = rdd.flatMap(lambda jsons: jsons.split('|')) print('json_rdd_is: %s'%json_rdd.collect()) dict_rdd = json_rdd.map(lambda x: json.loads(x)) print('dict_rdd_is: %s'%dict_rdd.collect()) bejing_rdd = dict_rdd.filter(lambda x: x['areaName']=='北京') print('bejing_rdd is %s'%bejing_rdd.collect()) bejing_distinct_category_rdd = bejing_rdd.map(lambda x: x['areaName']+'-'+x['category']).distinct() print('bejing_distinct_category is \n%s'%bejing_distinct_category_rdd.collect())
1 2 3 # 结果 bejing_distinct_category is ['北京-平板电脑', '北京-家电', '北京-电脑', '北京-书籍', '北京-服饰', '北京-手机', '北京-家具', '北京-食品']
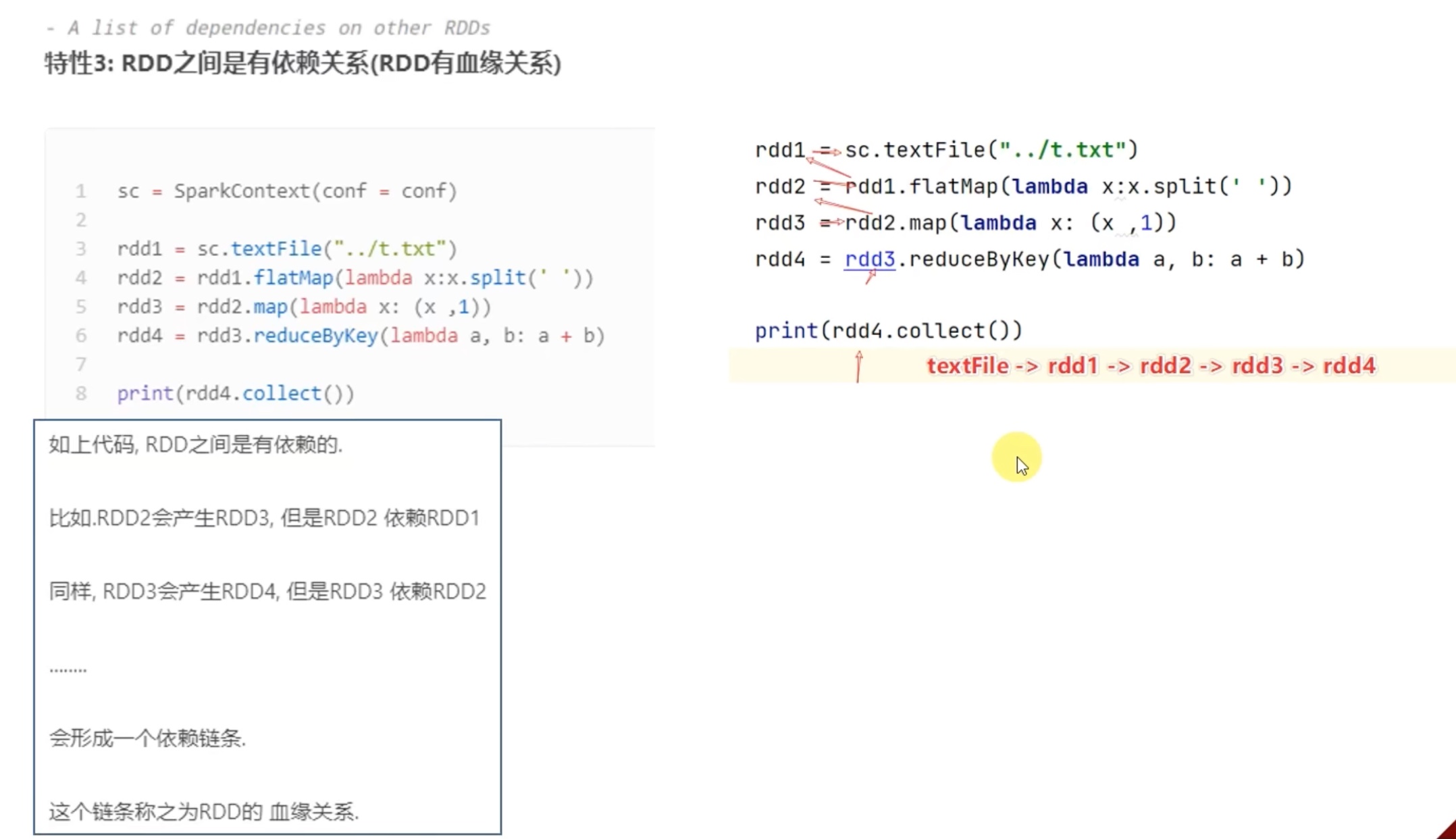
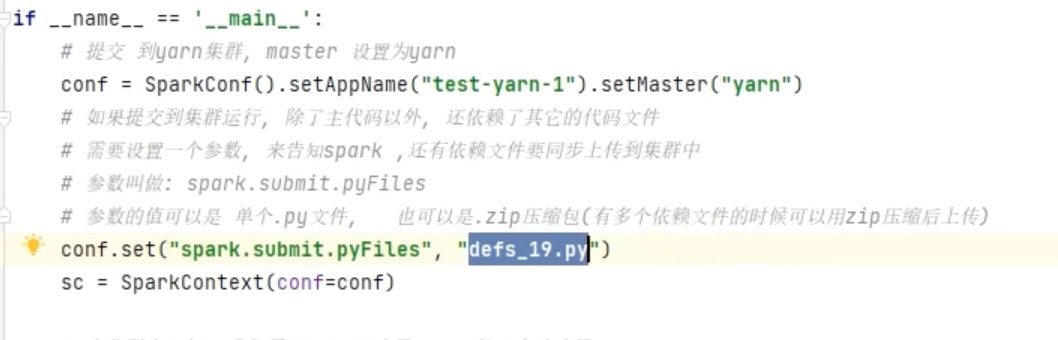
spark集群运算时,别的机器找不到本地的依赖方法,
1、要记得用conf.set()来让hdfs 能够找到依赖。
2、若用spark-submit 工具直接提交,要用--py-file 依赖文件路径 让hdfs找到依赖哦。
用spark集群跑刚才的代码(先把其中的一个方法独立到这个脚本外面,做成一个依赖)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 vim defs_areaName_add_category.py def areaName_add_category(x): return x['areaName']+'-'+x['category'] vim rdd_operator_demo_runYarn.py # conding:utf8 from pyspark import SparkConf,SparkContext import json from defs_areaName_add_category import areaName_add_category if __name__=="__main__": conf = SparkConf().setAppName("creat_test") # 命令窗口指定master,这里就不写setMster了。 # 指出依赖。 conf.set('spark.submit.pyFiles','defs_areaName_add_category.py') sc = SparkContext(conf=conf) rdd = sc.textFile('/spark_study/order.text') json_rdd = rdd.flatMap(lambda jsons: jsons.split('|')) dict_rdd = json_rdd.map(lambda x: json.loads(x)) bejing_rdd = dict_rdd.filter(lambda x: x['areaName']=='北京') # 用依赖的方法 代替 原来的方法。考察集群内其他机器能不能找到依赖。 bejing_distinct_category_rdd = bejing_rdd.map(areaName_add_category).distinct() print('bejing_distinct_category is \n%s'%bejing_distinct_category_rdd.collect())
在编辑py文件的位置打开命令窗口运行
/opt/spark/spark/bin/spark-submit --master yarn --py-files ./defs_areaName_add_category.py ./rdd_operator_demo_runYarn.py
结果如下(有交互式反馈,是客户端模式运行):
1 2 bejing_distinct_category is ['北京-平板电脑', '北京-家电', '北京-电脑', '北京-书籍', '北京-服饰', '北京-食品', '北京-手机', '北京-家具']
常用Action算子
统计key的出现次数,和value没关系,这里value设置成2也是一样的。
种子参数如果不变,随机出来的数据会是一样的,所以我们尽量不要写种子参数。
注意:排序完了以后,输出还是原来这个位置的元素,那个lambda 匿名函数只是改变排序规则而已。
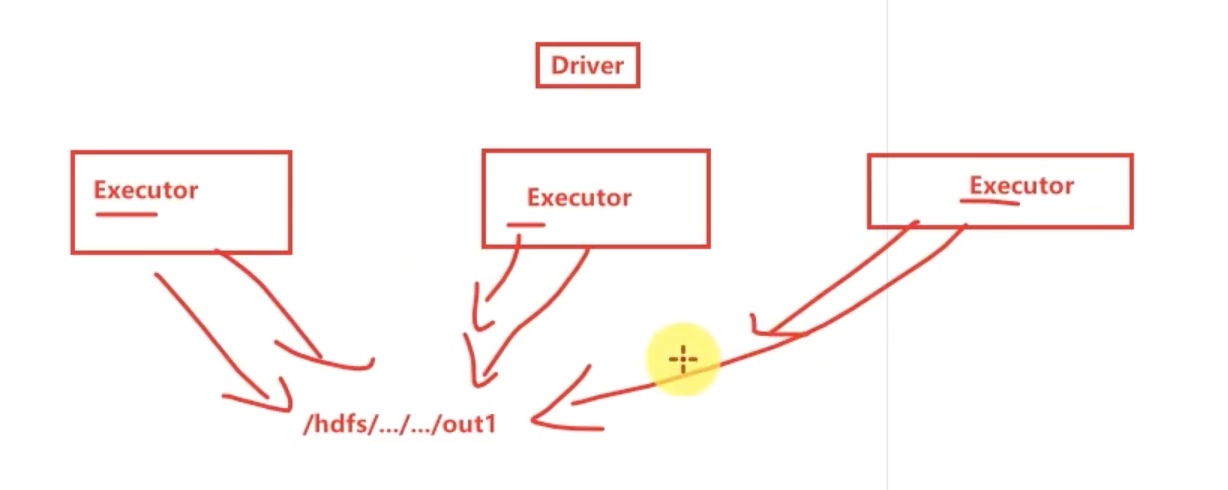
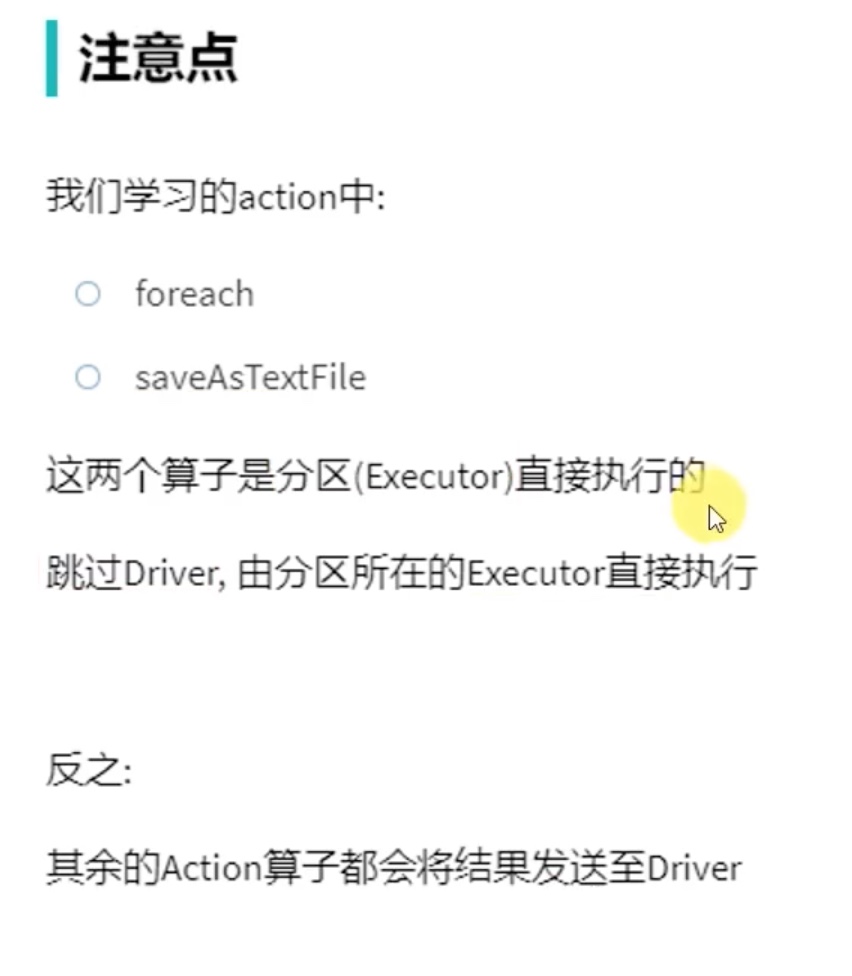
注意 foreach是没有返回值的,而且foreach 是executor里直接输出的,不像collect那些action算子 一样汇总到driver中输出。
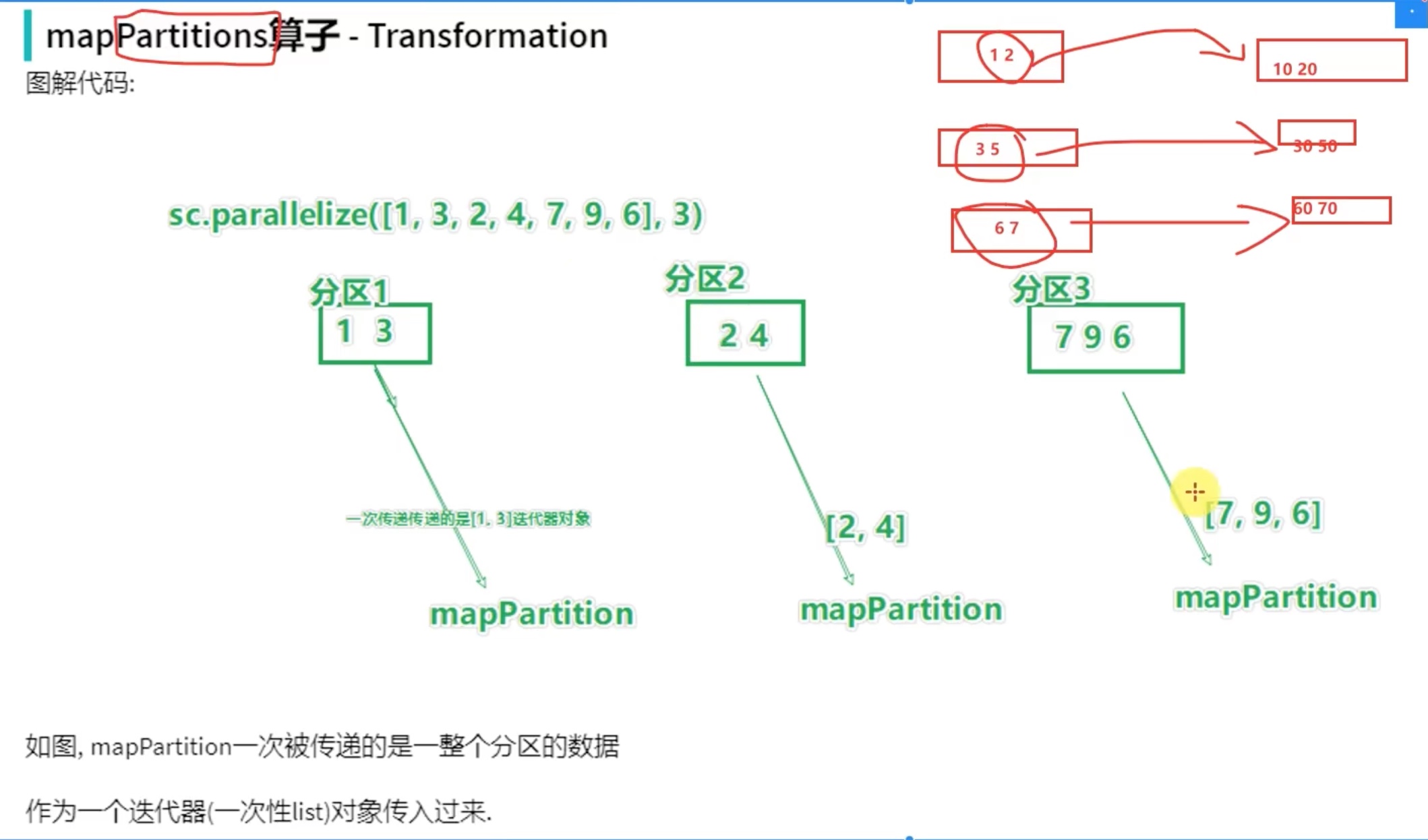
分区操作算子
和map一次处理一个元素不同的是,mapPartion算子是整个迭代器传递。走网络的时候,一次性传输一个迭代器对象 效率一定高于一次传一个元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # conding:utf8 from pyspark import SparkConf,SparkContext if __name__=="__main__": conf = SparkConf().setAppName("creat_test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([1,3,2,5,4,3],3) def process(iter): result = [] for it in iter: result.append(it*10) return result result = rdd.mapPartitions(process).collect() print(result) # output [10, 30, 20, 50, 40, 30]
foreachPartion 除了是一个没有返回值的mapPartitions 以外,还是一个action算子,所以不用收集。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # conding:utf8 from pyspark import SparkConf,SparkContext if __name__=="__main__": conf = SparkConf().setAppName("creat_test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([('hadoop',1),('hadoop',2),('spark',1),('hello',1),('flink',1)],4) print(rdd.glom().collect()) # 用默认分区来对比一下。 def process(k): if k == 'hadoop' or k == 'spark': return 0 if k == 'flink': return 1 return 2 result = rdd.partitionBy(3,process).glom().collect() print(result) # output [[('hadoop', 1)], [('hadoop', 2)], [('spark', 1)], [('hello', 1), ('flink', 1)]] [[('hadoop', 1), ('hadoop', 2), ('spark', 1)], [('flink', 1)], [('hello', 1)]]
1 2 3 4 5 6 7 8 9 10 11 12 # conding:utf8 from pyspark import SparkConf,SparkContext if __name__=="__main__": conf = SparkConf().setAppName("creat_test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([1,2,3,4,5],3) print(rdd.repartition(1).getNumPartitions()) print(rdd.repartition(4).getNumPartitions()) print(rdd.coalesce(1).getNumPartitions()) print(rdd.coalesce(10,shuffle=True).getNumPartitions()) # coalesce 和repartition 功能一样,但是coalesce有一个shuffle 开关,在分区增加时 要手动打开。
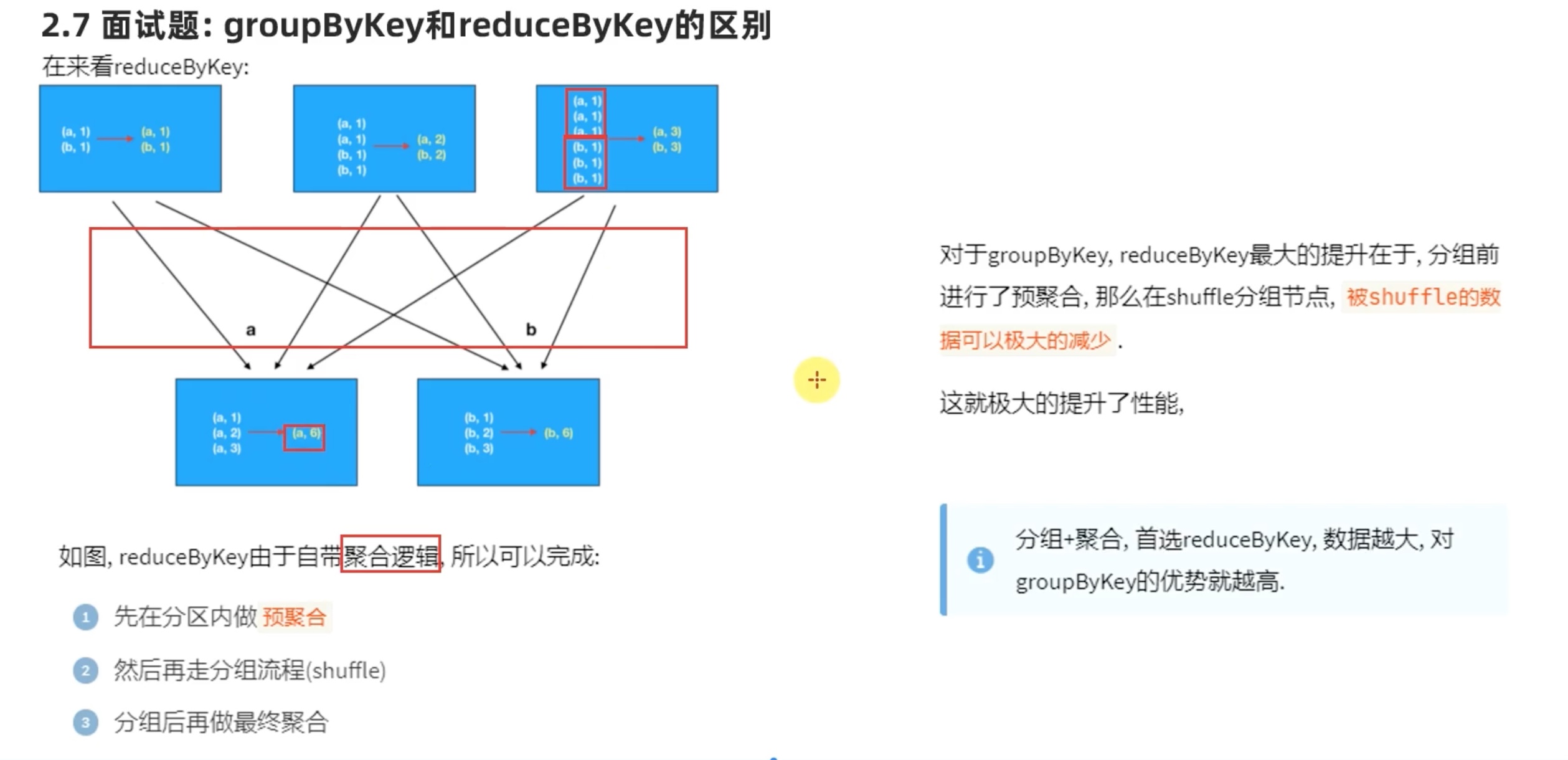
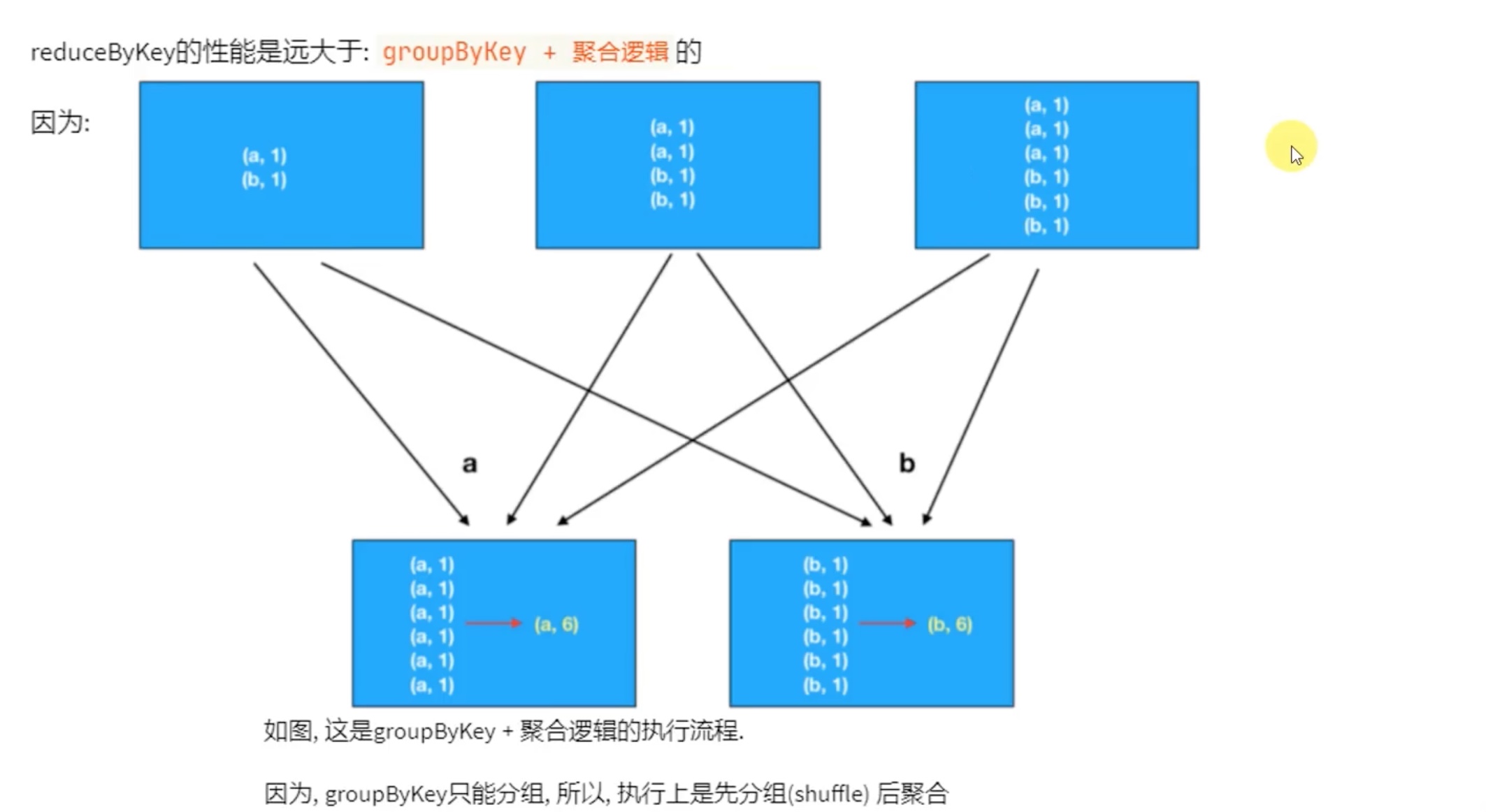
网络io 来看,groupbykey 开销太大了,而reducebykey rdd内先聚合过了,所以开销小很多。
答题:从 功能方面看;从 性能方面看。
RDD的持久化
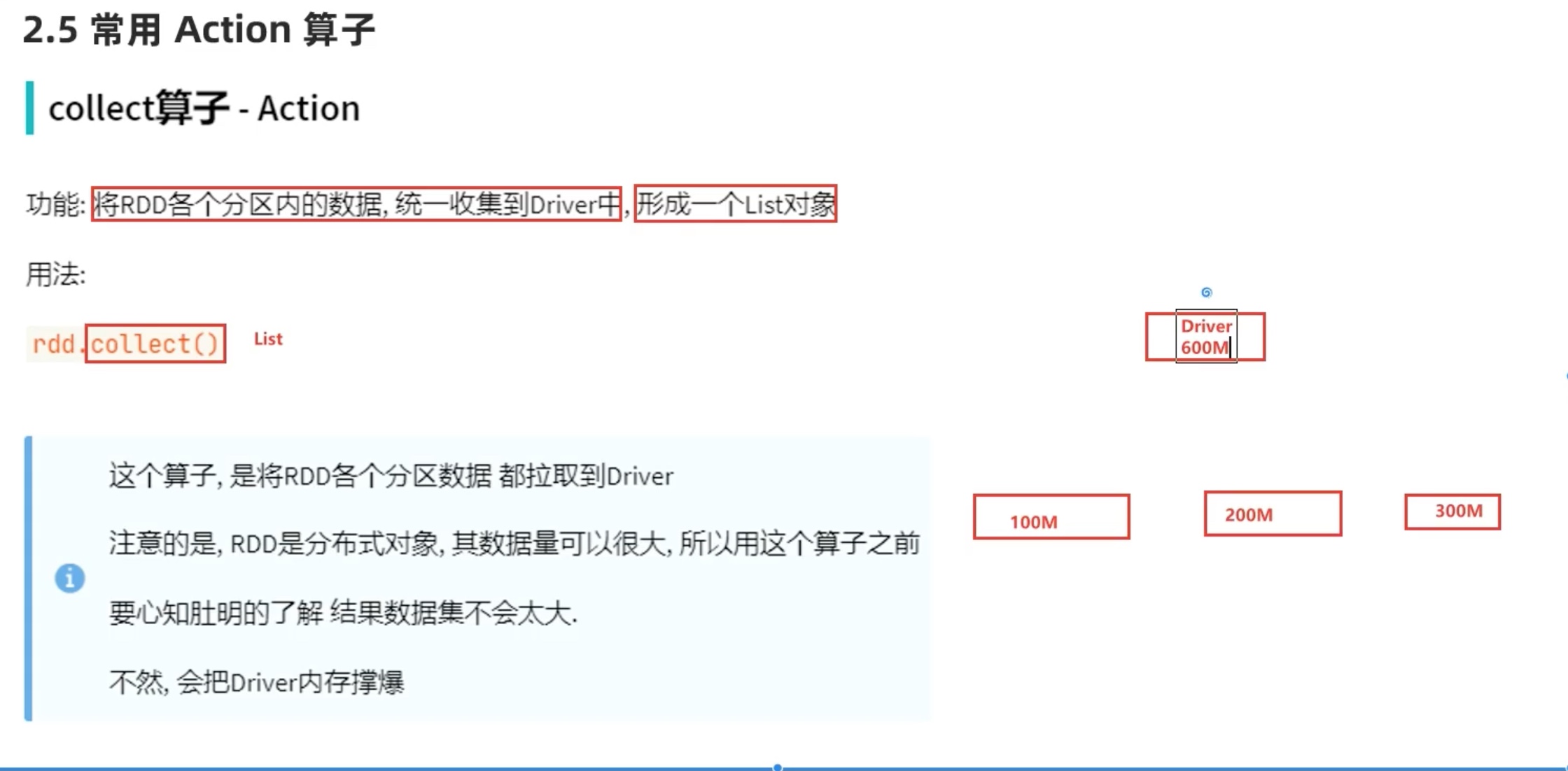
一次到collect(),只会有一个rdd,找不到想要的rdd就又要重新运行一遍,花销很大。
”持久化“ 就是解决这个问题。
补充:查看源码小技巧: 在idea中快速查看源码,比如一个要引入的方法我们不知道它需要哪个包,怎么用等等,可以先 ctrl+单击鼠标左键点方法名 快速查看方法的源码,Mac上需要 ctrl+command+单击方法名 快速查看方法源码。
打开源码后,看看方法需要的参数,在源码文件夹搜索参数名,往上找 import 可以看到这个方法想用此参数需要导入什么包。回到我们的代码中,import 需要导入的包名就行了,此时方法内可以正常使用该参数了。
RDD缓存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 # conding:utf8 from pyspark import SparkConf,SparkContext import time from pyspark.storagelevel import StorageLevel # 通过上面查看源码小技巧从 persis里找要导入什么包。 if __name__=="__main__": conf = SparkConf().setAppName("creat_test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd1 = sc.textFile('/spark_study/words.txt') rdd2 = rdd1.flatMap(lambda x: x.split(' ')) rdd3 = rdd2.map(lambda x: (x,1)) rdd3.cache() # 用cache方法缓存 rdd3.persist(StorageLevel.MEMORY_ONLY) # 用persist持久化缓存。 rdd4 = rdd3.reduceByKey(lambda a,b: a+b) print(rdd4.collect()) rdd5 = rdd3.groupByKey() rdd6 = rdd5.mapValues(lambda x:sum(x)) print(rdd6.collect()) rdd3.unpersist() # 记得释放缓存 time.sleep(10000) # 故意让进程睡眠,方便4040端口实时查看
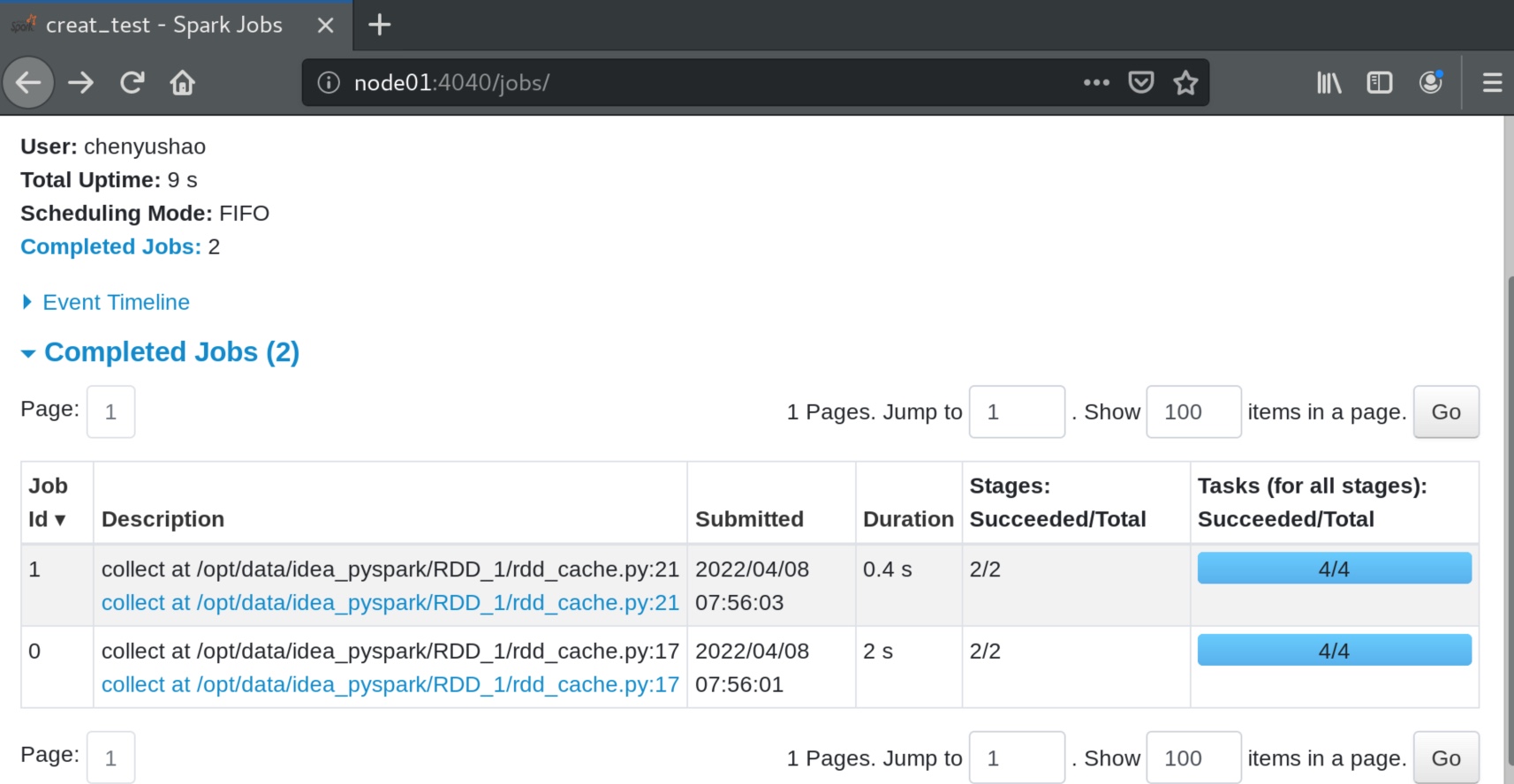
程序运行中,可以从 node01:4040 端口查看spark的运行情况。可见有两个任务在运行,一个是 rdd1->rdd2->rdd3->rdd4; 另一个是 rdd1->rdd2->rdd3->rdd5->rdd6。
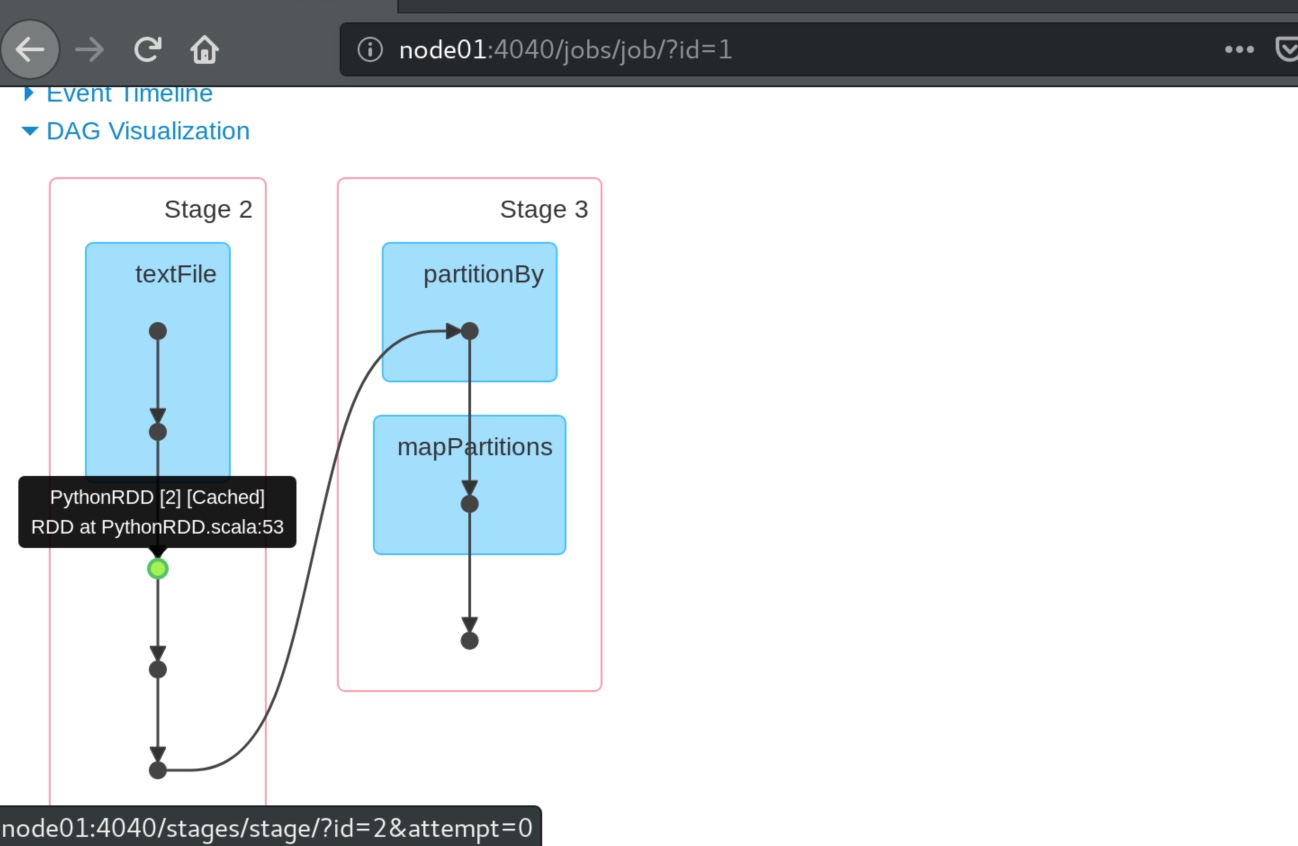
点击进任意一个任务,再点击 DAG Visualization 可视化,可见一个绿色的小点,说明任务在运行时,并非每次都从头运行一遍,而是从这个绿点缓存位置再向下运行的。
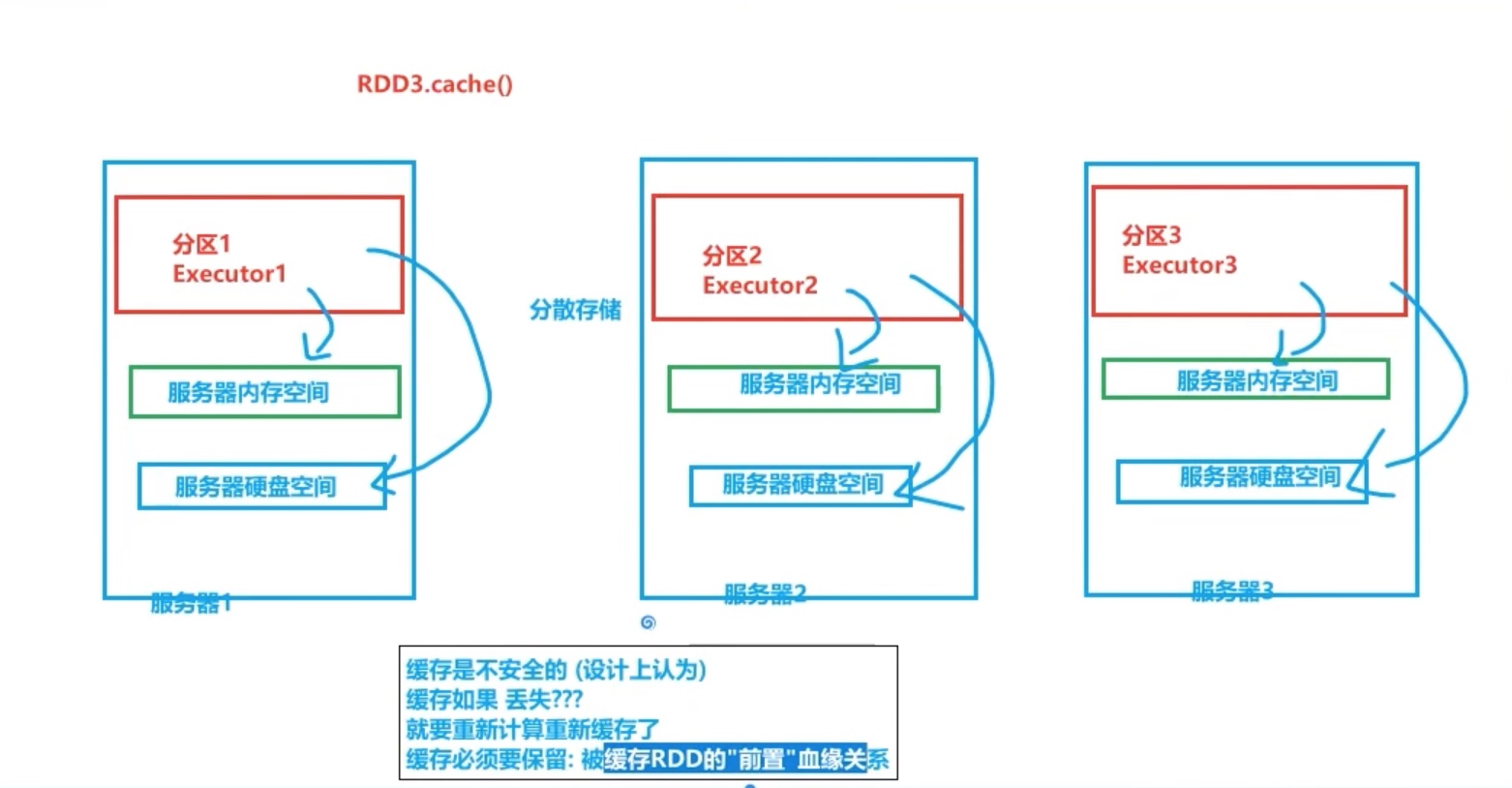
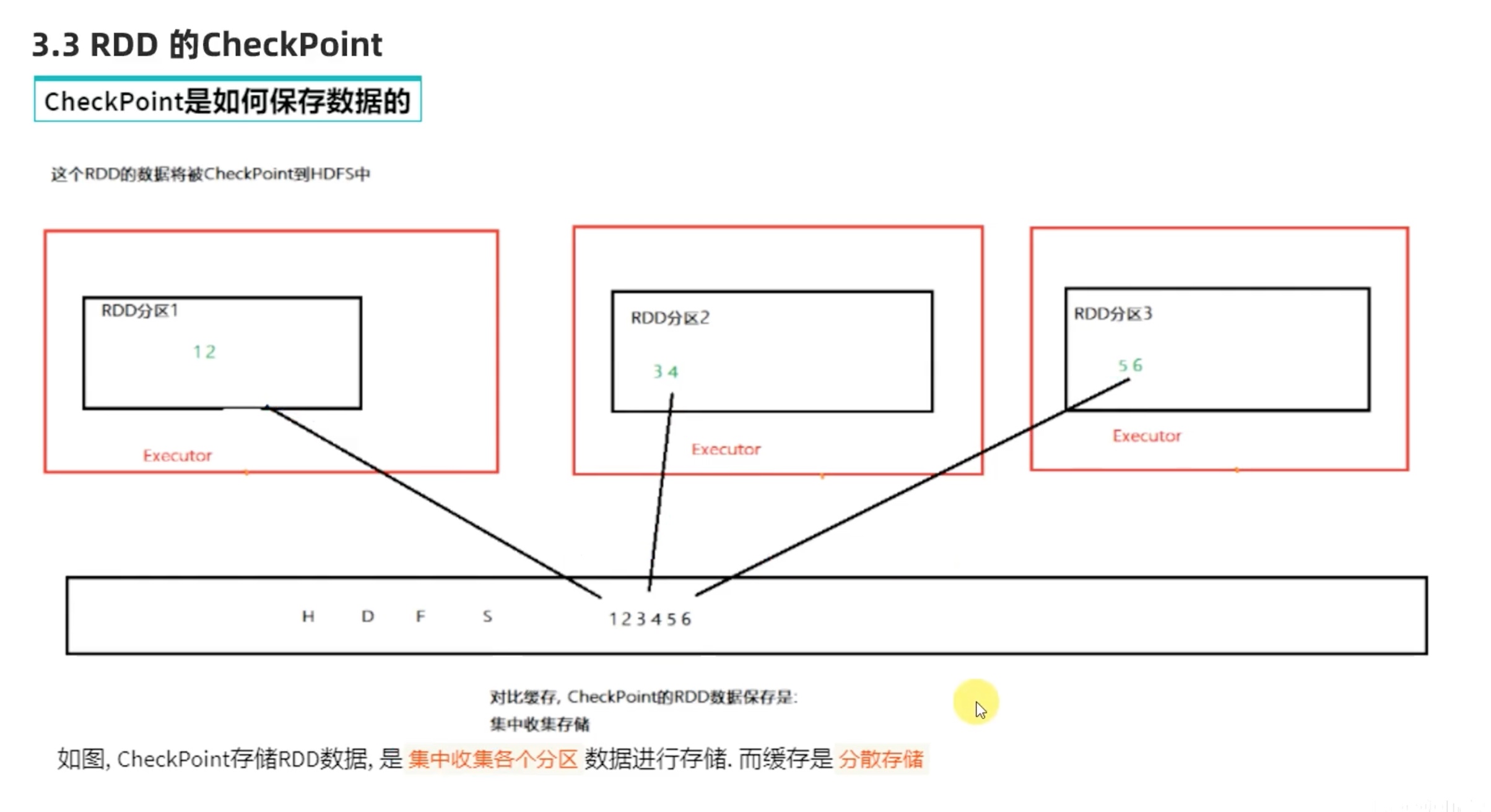
缓存仅仅在逻辑上是一个整体,具体物理存储实际上是分散存储的。
RDD_checkpoint
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 # conding:utf8 from pyspark import SparkConf,SparkContext import time from pyspark.storagelevel import StorageLevel if __name__=="__main__": conf = SparkConf().setAppName("creat_test").setMaster("local[*]") sc = SparkContext(conf=conf) sc.setCheckpointDir('/spark_study/checkpoint_log') #指定checkpoint存储位置 rdd1 = sc.textFile('/spark_study/words.txt') rdd2 = rdd1.flatMap(lambda x: x.split(' ')) rdd3 = rdd2.map(lambda x: (x,1)) # rdd3.cache() # rdd3.persist(StorageLevel.MEMORY_ONLY) rdd3.checkpoint() # 从这里 checkpoint。 rdd4 = rdd3.reduceByKey(lambda a,b: a+b) print(rdd4.collect()) rdd5 = rdd3.groupByKey() rdd6 = rdd5.mapValues(lambda x:sum(x)) print(rdd6.collect()) rdd3.unpersist() time.sleep(10000)
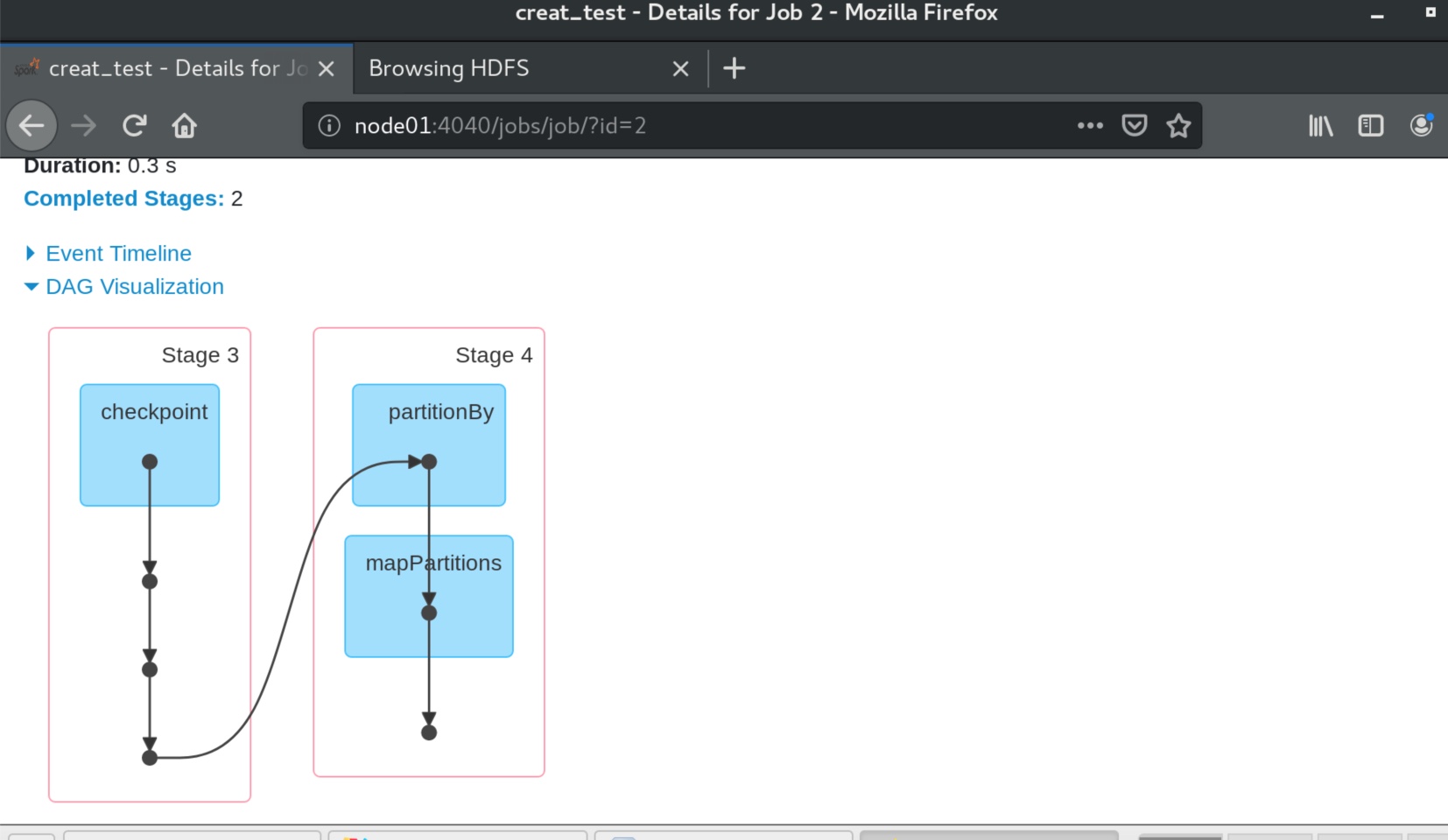
我们可以从4040端口的可视化试图看见,没有绿色的cache点了,而且程序开头直接从checkpoint 开始运行。
总结
案例练习
先在 conda 的 pyspark虚拟环境 pip install jieba。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import jiebaif __name__ == '__main__' : content = '小明硕士毕业于中国科学院计算所,后在深造。' result = jieba.cut(content,True ) print (list (result)) print (type (result)) result2 = jieba.cut(content,False ) print (list (result2)) result3 = jieba.cut_for_search(content) print (',' .join(result3)) print (list (result3),type (result3))
1 2 3 4 5 6 7 ['小' , '明' , '硕士' , '毕业' , '于' , '中国' , '中国科学院' , '科学' , '科学院' , '学院' , '计算' , '计算所' , ',' , '后' , '在' , '深造' , '。' ] <class 'generator' > ['小明' , '硕士' , '毕业' , '于' , '中国科学院' , '计算所' , ',' , '后' , '在' , '深造' , '。' ] 小明,硕士,毕业,于,中国,科学,学院,科学院,中国科学院,计算,计算所,,,后,在,深造,。 [] <class 'generator' >
文件内容如下:
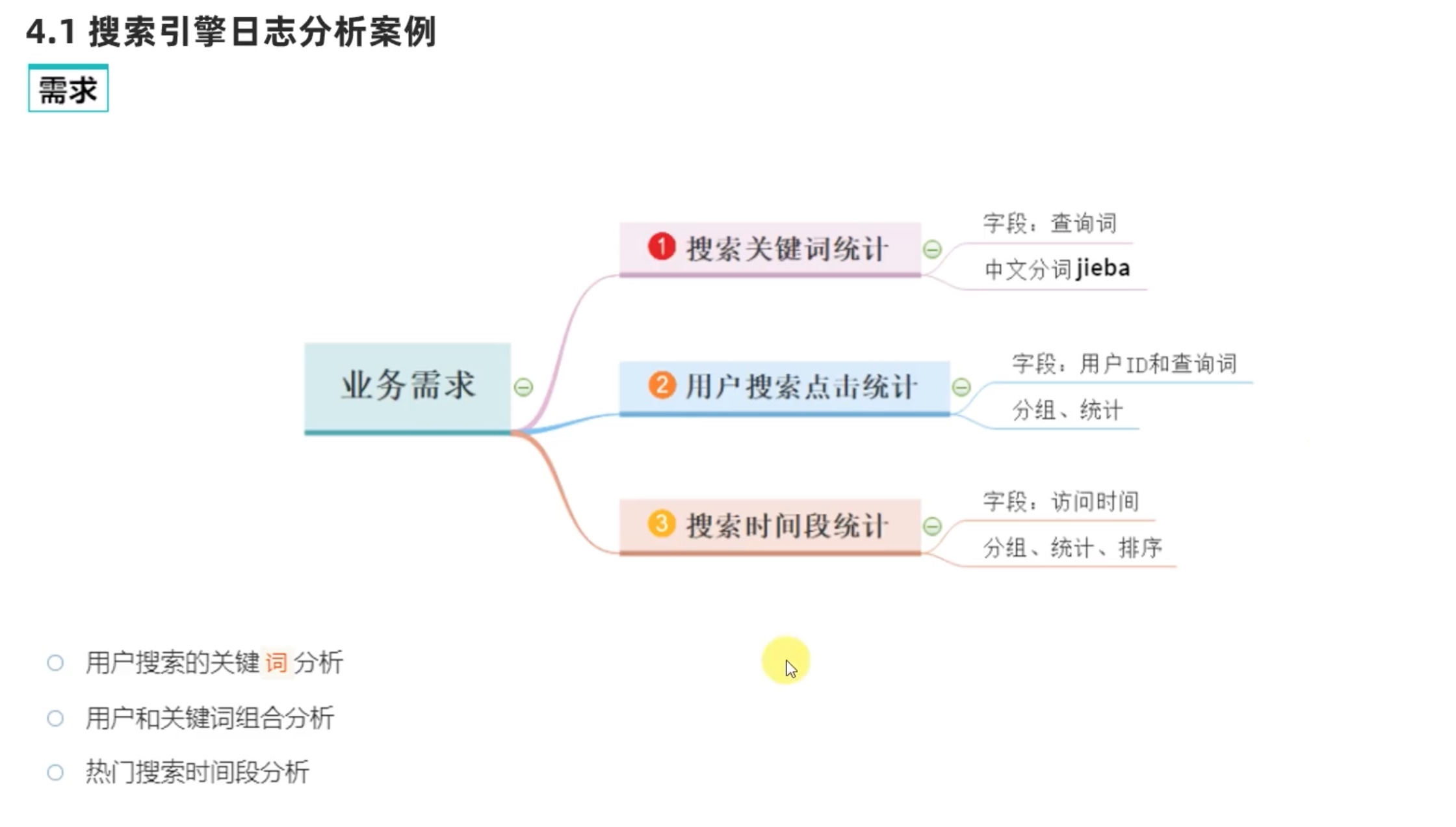
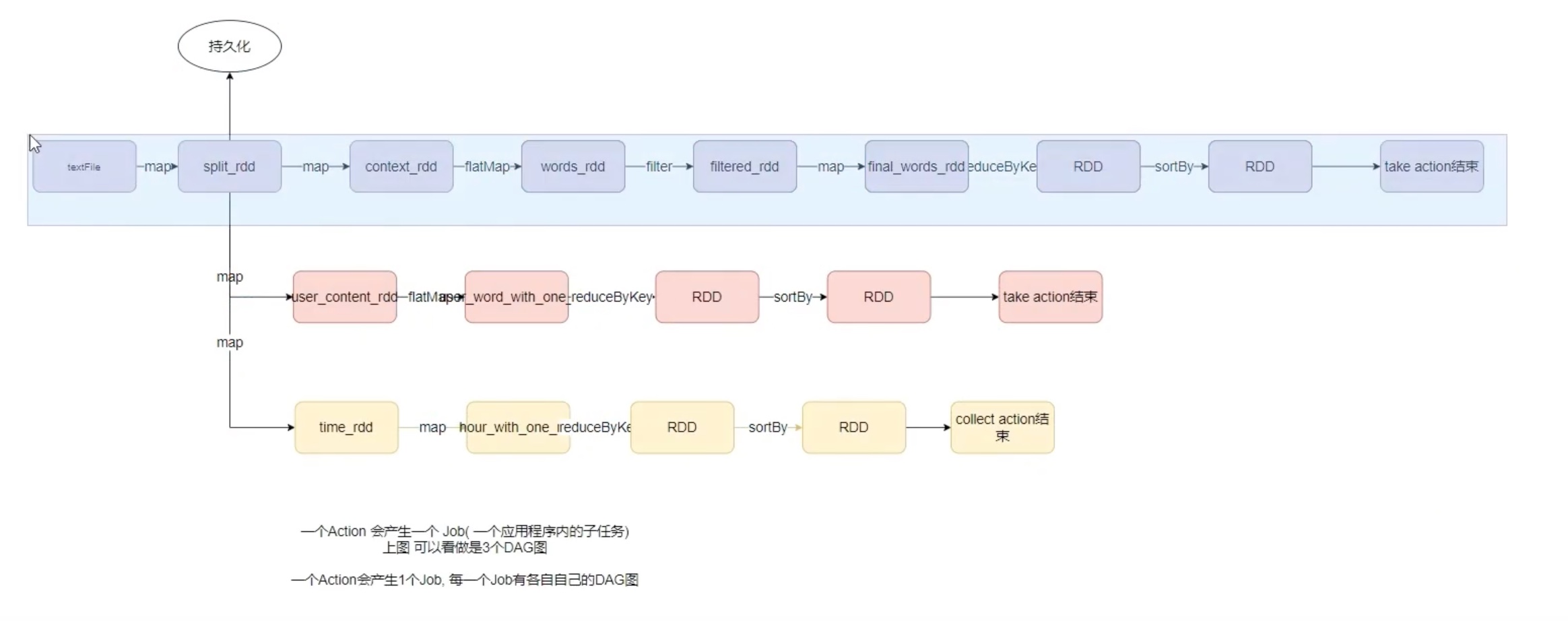
需求1:统计搜索词排名前五的关键词。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 vim log_analize.py from pyspark import SparkConf,SparkContextfrom pyspark.storagelevel import StorageLevelfrom defs import context_jieba,filter_words,append_wordsif __name__=="__main__" : conf = SparkConf().setAppName("creat_test" ).setMaster("local[*]" ) sc = SparkContext(conf=conf) file_rdd = sc.textFile('/spark_study/SogouQ.txt' ) split_rdd = file_rdd.map (lambda x: x.split('\t' )) split_rdd.persist(StorageLevel.DISK_ONLY) context_rdd = split_rdd.map (lambda x: x[2 ]) words_rdd = context_rdd.flatMap( context_jieba) filtered_rdd = words_rdd.filter ( filter_words) final_words_rdd = filtered_rdd.map ( append_words) result = final_words_rdd.reduceByKey(lambda a,b : a+b).\ sortBy(lambda x: x[1 ],ascending=False ,numPartitions=1 ).take(5 ) print (result)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 vim defs.py import jiebadef context_jieba (data ): seg = jieba.cut_for_search(data) l = [] for word in seg: l.append(word) return l def filter_words (data ): return data not in ['谷' ,'帮' ,'客' ] def append_words (data ): if data == '传智播' : data = '传智播客' if data == '院校' : data = '院校帮' if data == '博学' : data = '博学谷' return (data,1 )
1 2 [('scala' , 2310 ), ('hadoop' , 2268 ), ('博学谷' , 2002 ), ('传智汇' , 1918 ), ('itheima' , 1680 )]
需求2: 用户和关键词组合分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 vim log_analize.py from pyspark import SparkConf,SparkContextfrom pyspark.storagelevel import StorageLevelfrom defs import context_jieba,filter_words,append_wordsif __name__=="__main__" : conf = SparkConf().setAppName("creat_test" ).setMaster("local[*]" ) sc = SparkContext(conf=conf) file_rdd = sc.textFile('/spark_study/SogouQ.txt' ) split_rdd = file_rdd.map (lambda x: x.split('\t' )) split_rdd.persist(StorageLevel.DISK_ONLY) user_content_rdd = split_rdd.map (lambda x: (x[1 ],x[2 ])) user_word_with_one_rdd = user_content_rdd.flatMap( extract_user_and_word) result2 = user_word_with_one_rdd.reduceByKey(lambda a,b:a+b).\ sortBy(lambda x:x[1 ],ascending=False ,numPartitions=1 ).take(5 ) print (result2)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 vim defs.py import jiebadef context_jieba (data ): seg = jieba.cut_for_search(data) l = [] for word in seg: l.append(word) return l def filter_words (data ): return data not in ['谷' ,'帮' ,'客' ] def append_words (data ): if data == '传智播' : data = '传智播客' if data == '院校' : data = '院校帮' if data == '博学' : data = '博学谷' return (data,1 ) def extract_user_and_word (data ): userid = str (data[0 ]) word_all = str (data[1 ]) words = context_jieba(word_all) list_ = [] for word in words: whether_word_is_null = filter_words(word) if whether_word_is_null: word = append_words(word)[0 ] list_.append((userid+' ' +word,1 )) return (list_)
1 2 [('6185822016522959 scala' , 2016 ), ('41641664258866384 博学谷' , 1372 ), ('44801909258572364 hadoop' , 1260 ), ('7044693659960919 数据' , 1120 ), ('7044693659960919 数据仓库' , 1120 )]
这样是方便针对性营销。
需求3: 热门搜索时间段分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 vim log_analize.py from pyspark import SparkConf,SparkContextfrom pyspark.storagelevel import StorageLevelfrom defs import context_jieba,filter_words,append_wordsif __name__=="__main__" : conf = SparkConf().setAppName("creat_test" ).setMaster("local[*]" ) sc = SparkContext(conf=conf) file_rdd = sc.textFile('/spark_study/SogouQ.txt' ) split_rdd = file_rdd.map (lambda x: x.split('\t' )) split_rdd.persist(StorageLevel.DISK_ONLY) time_rdd = split_rdd.map (lambda x: x[0 ]) hourse_with_one_rdd = time_rdd.map (lambda x: (x.split(':' )[0 ],1 )) result3 = hourse_with_one_rdd.reduceByKey(lambda a,b:a+b).\ sortBy(lambda x:x[1 ],ascending=False ,numPartitions=1 ).collect() print (result3)
1 2 [('20' , 3479 ), ('23' , 3087 ), ('21' , 2989 ), ('22' , 2499 ), ('01' , 1365 ), ('10' , 973 ), ('11' , 875 ), ('05' , 798 ), ('02' , 756 ), ('19' , 735 ), ('12' , 644 ), ('14' , 637 ), ('00' , 504 ), ('16' , 497 ), ('08' , 476 ), ('04' , 476 ), ('03' , 385 ), ('09' , 371 ), ('15' , 350 ), ('06' , 294 ), ('13' , 217 ), ('18' , 112 ), ('17' , 77 ), ('07' , 70 )]
可见晚上的20点是搜索高峰期。
集群中运行上述三个需求 先在每台机器上 安装好jieba,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 vim log_analize_on_yarn.py from pyspark import SparkConf,SparkContextfrom pyspark.storagelevel import StorageLevelfrom defs_on_yarn import context_jieba,filter_words,append_words,extract_user_and_wordif __name__=="__main__" : conf = SparkConf().setAppName("analize_log" ) sc = SparkContext(conf=conf) file_rdd = sc.textFile('/spark_study/SogouQ.txt' ) split_rdd = file_rdd.map (lambda x: x.split('\t' )) split_rdd.persist(StorageLevel.DISK_ONLY) context_rdd = split_rdd.map (lambda x: x[2 ]) words_rdd = context_rdd.flatMap( context_jieba) filtered_rdd = words_rdd.filter ( filter_words) final_words_rdd = filtered_rdd.map ( append_words) result = final_words_rdd.reduceByKey(lambda a,b : a+b).\ sortBy(lambda x: x[1 ],ascending=False ,numPartitions=1 ).take(5 ) print ('需求1: \n' ,result) user_content_rdd = split_rdd.map (lambda x: (x[1 ],x[2 ])) user_word_with_one_rdd = user_content_rdd.flatMap( extract_user_and_word) result2 = user_word_with_one_rdd.reduceByKey(lambda a,b:a+b).\ sortBy(lambda x:x[1 ],ascending=False ,numPartitions=1 ).take(5 ) print ('需求2: \n' ,result2) time_rdd = split_rdd.map (lambda x: x[0 ]) hourse_with_one_rdd = time_rdd.map (lambda x: (x.split(':' )[0 ],1 )) result3 = hourse_with_one_rdd.reduceByKey(lambda a,b:a+b).\ sortBy(lambda x:x[1 ],ascending=False ,numPartitions=1 ).collect() print ('需求3: \n' ,result3)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 vim defs_on_yarn.py import jiebadef context_jieba (data ): seg = jieba.cut_for_search(data) l = [] for word in seg: l.append(word) return l def filter_words (data ): return data not in ['谷' ,'帮' ,'客' ] def append_words (data ): if data == '传智播' : data = '传智播客' if data == '院校' : data = '院校帮' if data == '博学' : data = '博学谷' return (data,1 ) def extract_user_and_word (data ): userid = str (data[0 ]) word_all = str (data[1 ]) words = context_jieba(word_all) list_ = [] for word in words: whether_word_is_null = filter_words(word) if whether_word_is_null: word = append_words(word)[0 ] list_.append((userid+' ' +word,1 )) return (list_)
yarn集群中运行:
1 /opt/spark/spark/bin/spark-submit --master yarn --py-files /opt/data/idea_pyspark/RDD_1/example/defs_on_yarn.py /opt/data/idea_pyspark/RDD_1/example/log_analize_on_yarn.py
结果
1 2 3 4 5 6 需求1 : [('scala' , 2310 ), ('hadoop' , 2268 ), ('博学谷' , 2002 ), ('传智汇' , 1918 ), ('itheima' , 1680 )] 需求2 : [('6185822016522959 scala' , 2016 ), ('41641664258866384 博学谷' , 1372 ), ('44801909258572364 hadoop' , 1260 ), ('7044693659960919 仓库' , 1120 ), ('7044693659960919 数据' , 1120 )] 需求3 : [('20' , 3479 ), ('23' , 3087 ), ('21' , 2989 ), ('22' , 2499 ), ('01' , 1365 ), ('10' , 973 ), ('11' , 875 ), ('05' , 798 ), ('02' , 756 ), ('19' , 735 ), ('12' , 644 ), ('14' , 637 ), ('00' , 504 ), ('16' , 497 ), ('08' , 476 ), ('04' , 476 ), ('03' , 385 ), ('09' , 371 ), ('15' , 350 ), ('06' , 294 ), ('13' , 217 ), ('18' , 112 ), ('17' , 77 ), ('07' , 70 )]
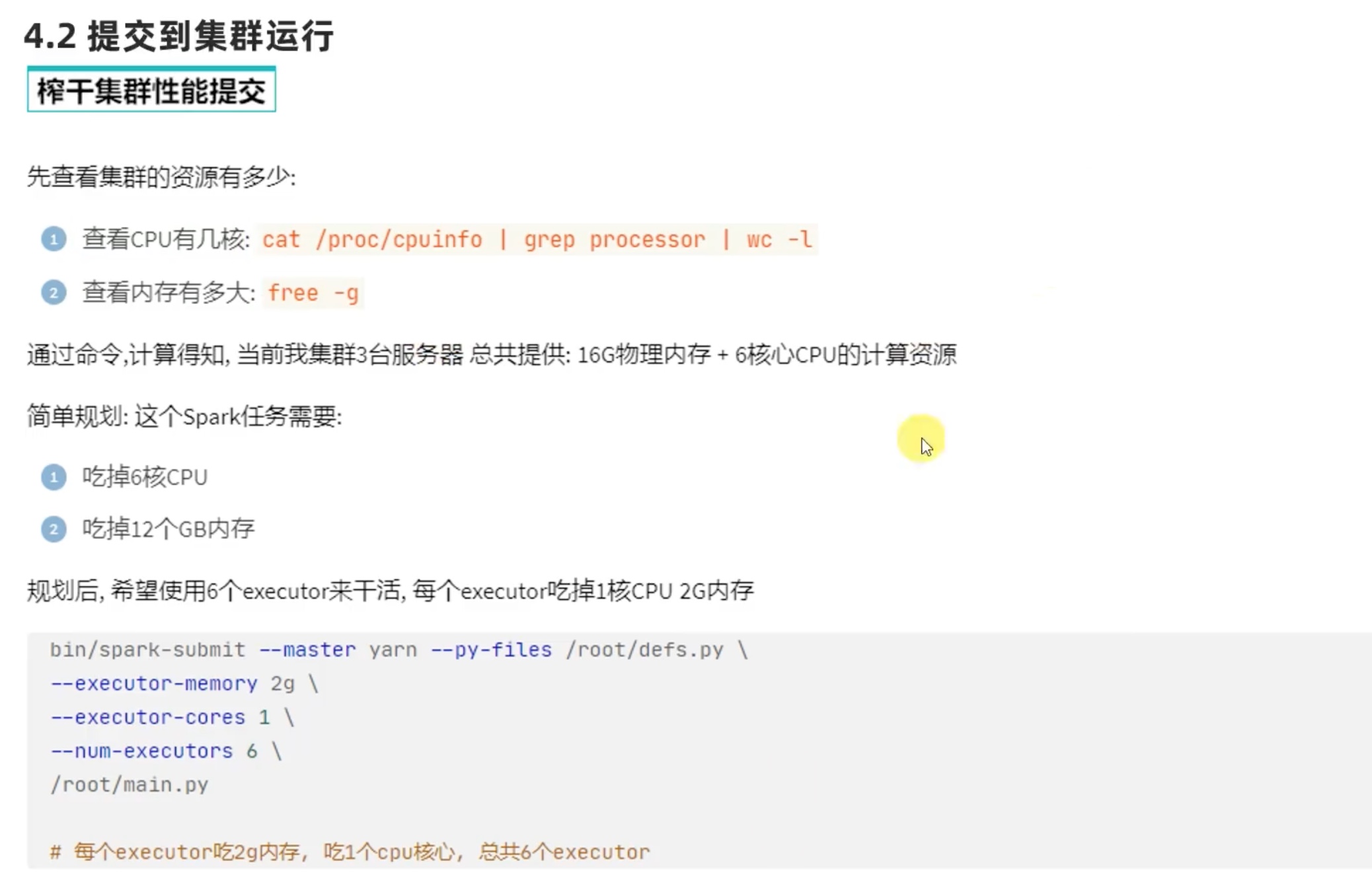
压榨集群的性能 提交
一般是每个虚拟机有多少个cpu, 就开多少个executors --num-executor 6。
每个executor 的core可以完全压榨,但是 每个 executor 内存需要留出一些空间给别的进程用,不能完全压榨!
由于我的几台虚拟机配置惨不忍睹,如下:
1 2 3 /opt/spark/spark/bin/spark-submit --master yarn --py-files /opt/data/idea_pyspark/RDD_1/example/defs_on_yarn.py --executor-memory 1g --executor-cores 1 --num-executors 3 /opt/data/idea_pyspark/RDD_1/example/log_analize_on_yarn.py
老实说上面压榨方法我都怕斯基,捂脸。总之压榨性能就是这么干。工作中用得到。
共享变量
广播变量
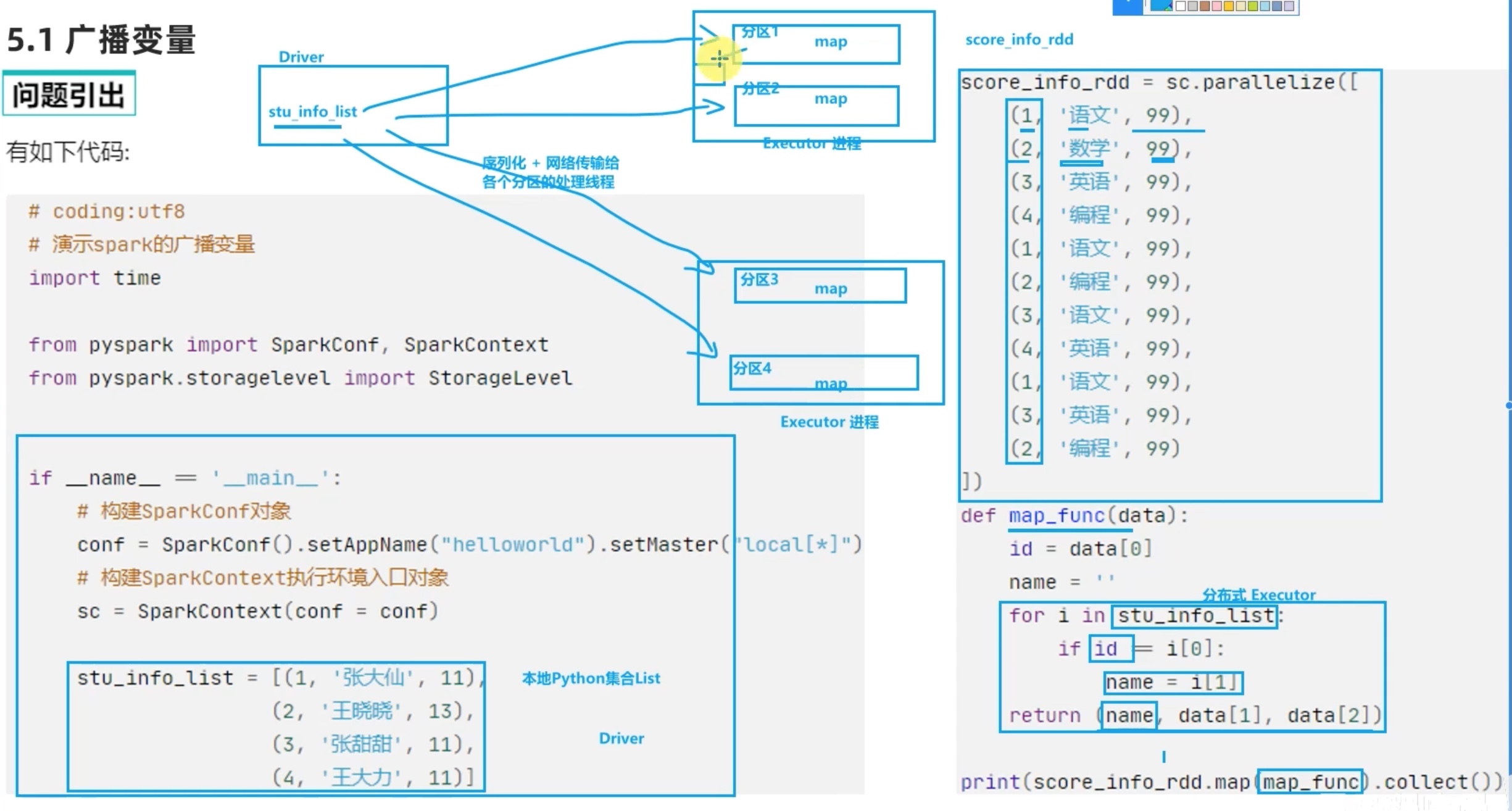
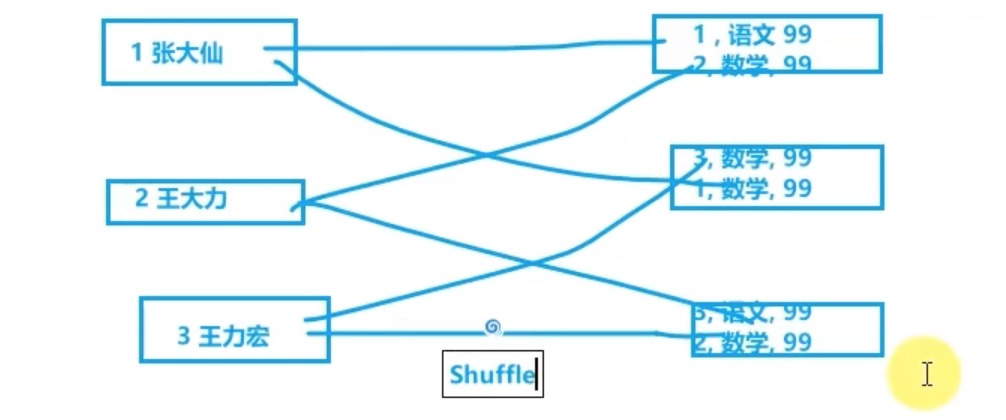
rdd 才运行在executor 内,之前的部分都在driver 内,以上代码中 stu_info_list 就是driver中的文件。
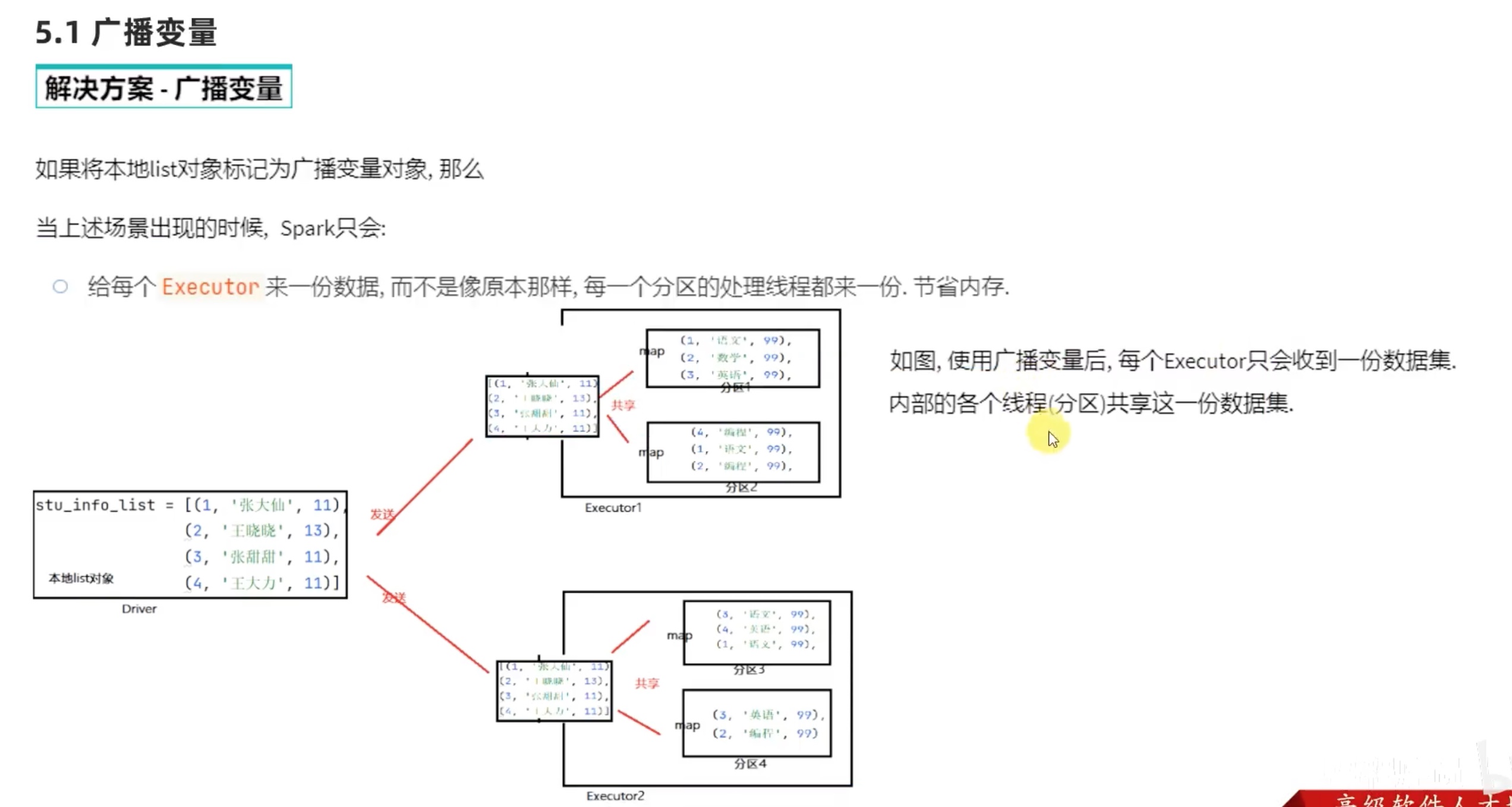
如果 executor 需要 driver 发送一些文件过来用,是一个分区发送一份吗?如果是这样会造成io资源和内存资源的浪费,因为executor 是进程,里面的分区可以视为线程,能共享进程的资源,理论上一个executor 发送一份文件就行了,executor 内部的分区共享driver 发送来的文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from pyspark import SparkConf,SparkContextif __name__=="__main__" : conf = SparkConf().setAppName("creat_test" ).setMaster("local[*]" ) sc = SparkContext(conf=conf) stu_info_list = [(1 ,'张大仙' ,11 ), (2 ,'王小小' ,13 ), (3 ,'张甜甜' ,11 ), (4 ,'王大力' ,11 )] broadcast = sc.broadcast(stu_info_list) score_info_rdd = sc.parallelize([(1 ,'语文' ,99 ), (2 ,'数学' ,99 ), (3 ,'英语' ,99 ), (4 ,'编程' ,99 ), (1 ,'语文' ,99 ), (2 ,'数学' ,99 ), (3 ,'英语' ,99 ), (4 ,'编程' ,99 )]) def map_func (data ): id = data[0 ] for stu_info in broadcast.value: stu_id = stu_info[0 ] if id == stu_id: name = stu_info[1 ] return (name,data[1 ],data[2 ]) print (score_info_rdd.map (map_func).collect()) [('张大仙' , '语文' , 99 ), ('王小小' , '数学' , 99 ), ('张甜甜' , '英语' , 99 ), ('王大力' , '编程' , 99 ), ('张大仙' , '语文' , 99 ), ('王小小' , '数学' , 99 ), ('张甜甜' , '英语' , 99 ), ('王大力' , '编程' , 99 )]
有人有疑问,既然放在本地容易造成io资源浪费,那直接把大量的文件以rdd形式直接存放在executor 中,以此避免资源浪费行吗?
不行!
因为大量的文件rdd 存储在 分区的话,其实是分布式存储,等于各个分区均匀存储一部分数据,如果要运算这样的数据,就需要各个 分区之间 传输数据,也就是shuffle,非常浪费资源!如下还仅仅是小的数据就已经有了这么多传输线。
但是,当数据集有 10g 或者比较大的情况下,不要再放在本地 用driver存储了,最好还是分布式存储。相当于小的数据时,把数据存放在本地driver,然后广播变量性能更好一些,大的数据时情况就变了。
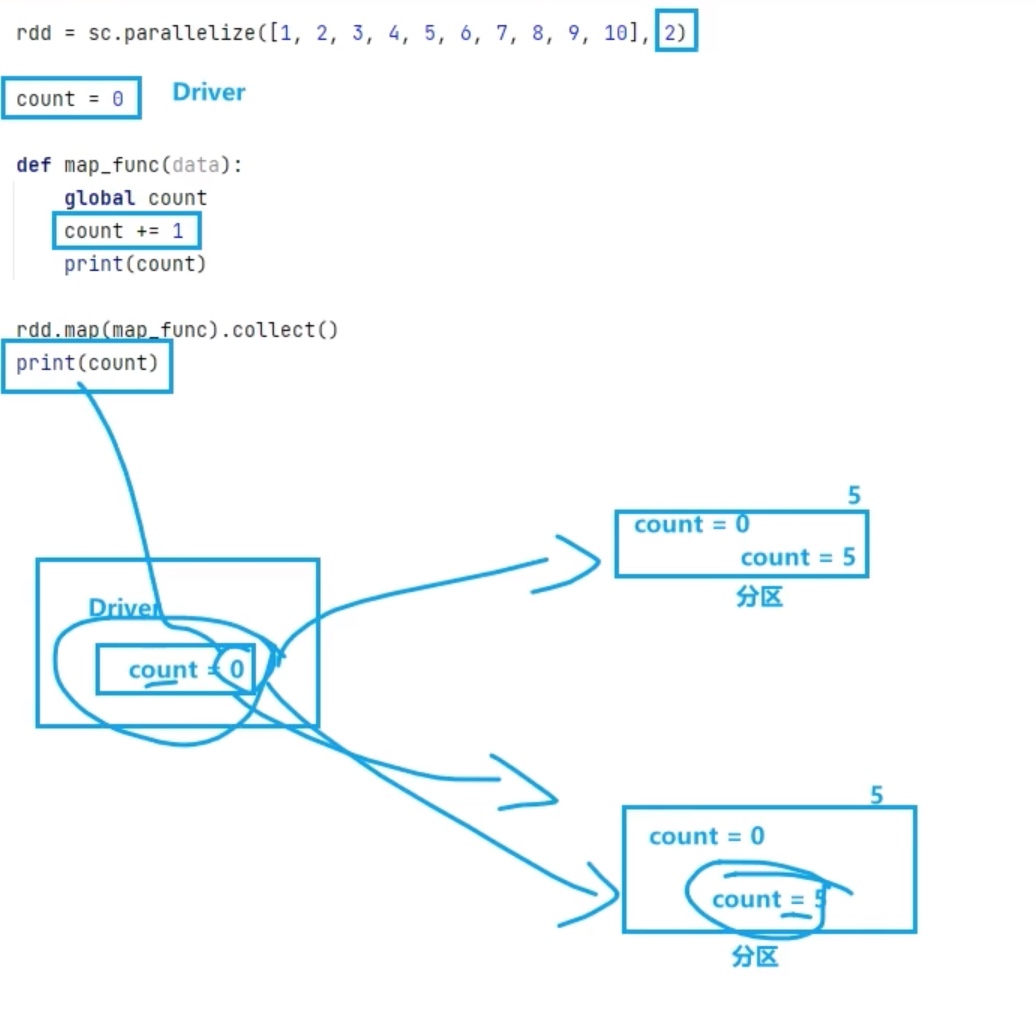
累加器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pyspark import SparkConf,SparkContextif __name__=="__main__" : conf = SparkConf().setAppName("creat_test" ).setMaster("local[*]" ) sc = SparkContext(conf=conf) rdd = sc.parallelize([1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ],2 ) count = 0 def map_fun (data ): global count count += 1 rdd.map (map_fun).collect() print (count)
首先我们要明确,map这样的rdd算子是在executor 中计算的,实际发生在分区内,而不在driver内,第一个count 在driver中,而map_fun() 方法是在两个分区内被调用的,最后的print(count) 输出的还是driver内的初始count。
分布式计算想要解决这个问题,就用到了累加器。
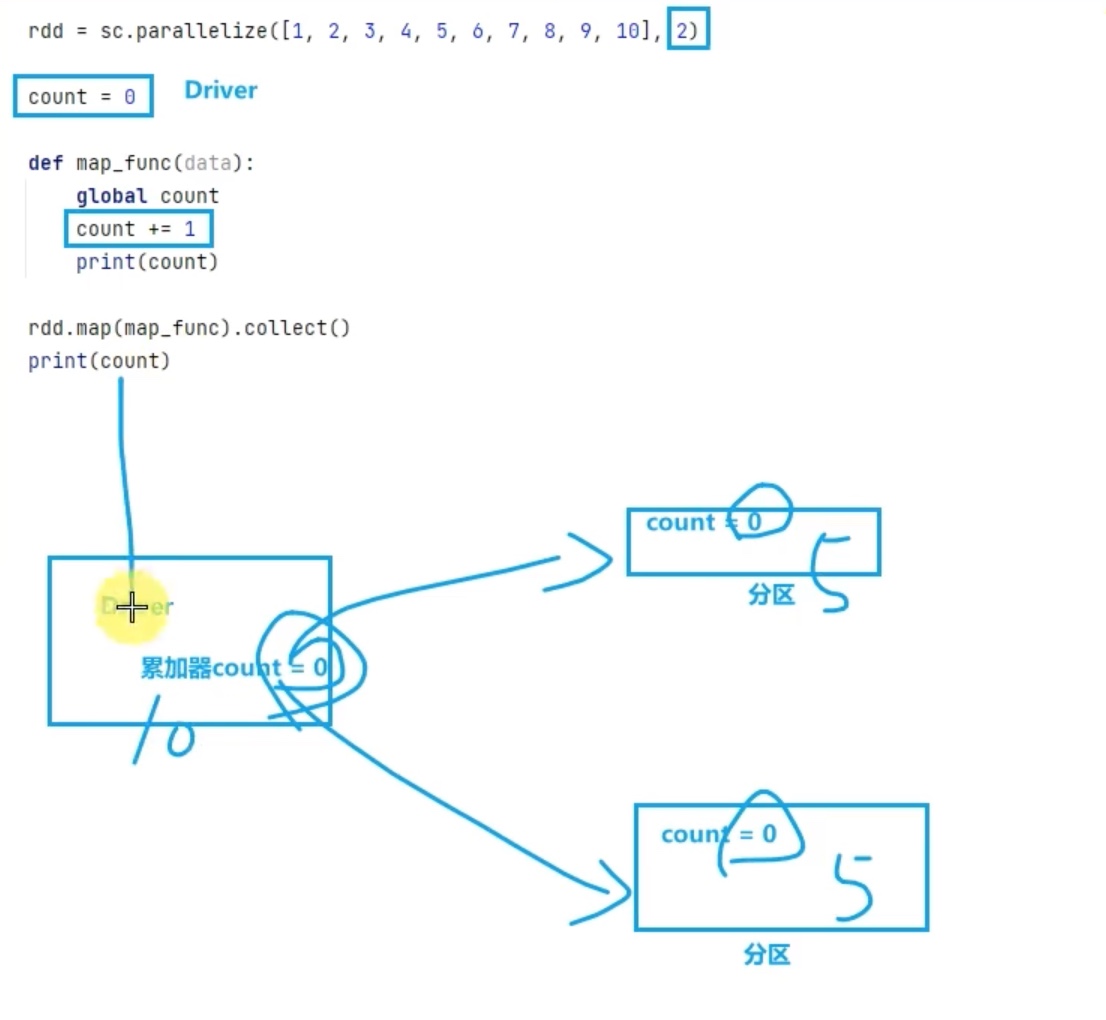
累加器,就是让分区内此对象的操作(相加) 能够同步到 driver中,让driver内的相应对象也操作(相加)一遍。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from pyspark import SparkConf,SparkContextif __name__=="__main__" : conf = SparkConf().setAppName("creat_test" ).setMaster("local[*]" ) sc = SparkContext(conf=conf) rdd = sc.parallelize([1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ],2 ) count = sc.accumulator(0 ) def map_fun (data ): global count count += 1 print (count) rdd.map (map_fun).collect() print (count) 1 2 3 4 5 1 2 3 4 9
老版本spark累加器 需要注意的问题(新版本好像已经解决了): 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from pyspark import SparkConf,SparkContextif __name__=="__main__" : conf = SparkConf().setAppName("creat_test" ).setMaster("local[*]" ) sc = SparkContext(conf=conf) rdd = sc.parallelize([1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ],2 ) count = sc.accumulator(0 ) def map_fun (data ): global count count += 1 rdd2 = rdd.map (map_fun) rdd2.collect() rdd3 = rdd2.map (lambda x: x) print (count) 18
综合案例
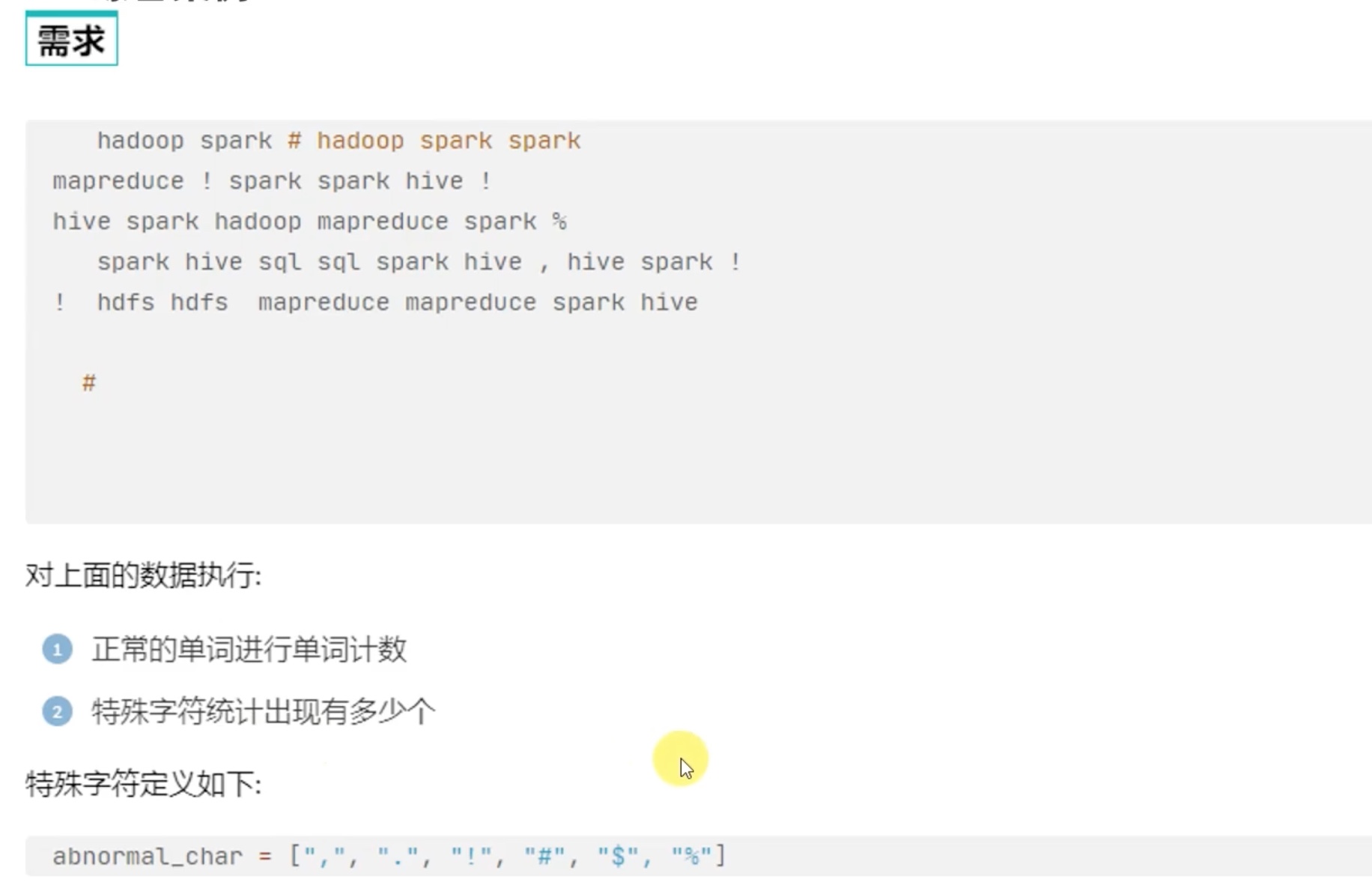
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from pyspark import SparkConf,SparkContextimport reif __name__=="__main__" : conf = SparkConf().setAppName("creat_test" ).setMaster("local[*]" ) sc = SparkContext(conf=conf) file_rdd = sc.textFile('file:///opt/data/idea_pyspark/RDD_1/data/accumulator_broadcast_data.txt' ) abnormal_char = [',' ,'.' ,'!' ,'#' ,'$' ,'%' ] broadcast = sc.broadcast(abnormal_char) acmlt = sc.accumulator(0 ) lines_rdd = file_rdd.filter (lambda line: line.strip()) data_rdd = lines_rdd.map (lambda line: line.strip()) word_rdd = data_rdd.flatMap(lambda line: re.split('\s+' ,line )) def filter_func (data ): global acmlt abnormal_char_list = broadcast.value if data in abnormal_char_list: acmlt += 1 return False else : return True normal_words_rdd = word_rdd.filter (filter_func) result_rdd = normal_words_rdd.map (lambda x: (x,1 )).reduceByKey(lambda a,b: a+b).\ sortBy(lambda x: x[1 ],ascending=False ,numPartitions=1 ) print (result_rdd.collect()) print (acmlt)
1 2 3 [('spark' , 11 ), ('hive' , 6 ), ('mapreduce' , 4 ), ('hadoop' , 3 ), ('hdfs' , 2 ), ('sql' , 2 )] 8
内核调度(重要)
DAG 有向无环图 有向无环图,可以参考我之前的《数据结构_浙江大学》-《41拓扑排序.py》。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def TopSort (): for 图中每个顶点 v: if Indegree[v] == 0 : Enqueue(v,Q) while !IsEmpty(Q): v = Dequeue(Q) 输出,或者记录v的输出序号 count ++ for v 的每个邻接点 w: if --Indegree[w] == 0 : Enqueue(w,Q) if count != v_num: Error 图中有回路(有环)
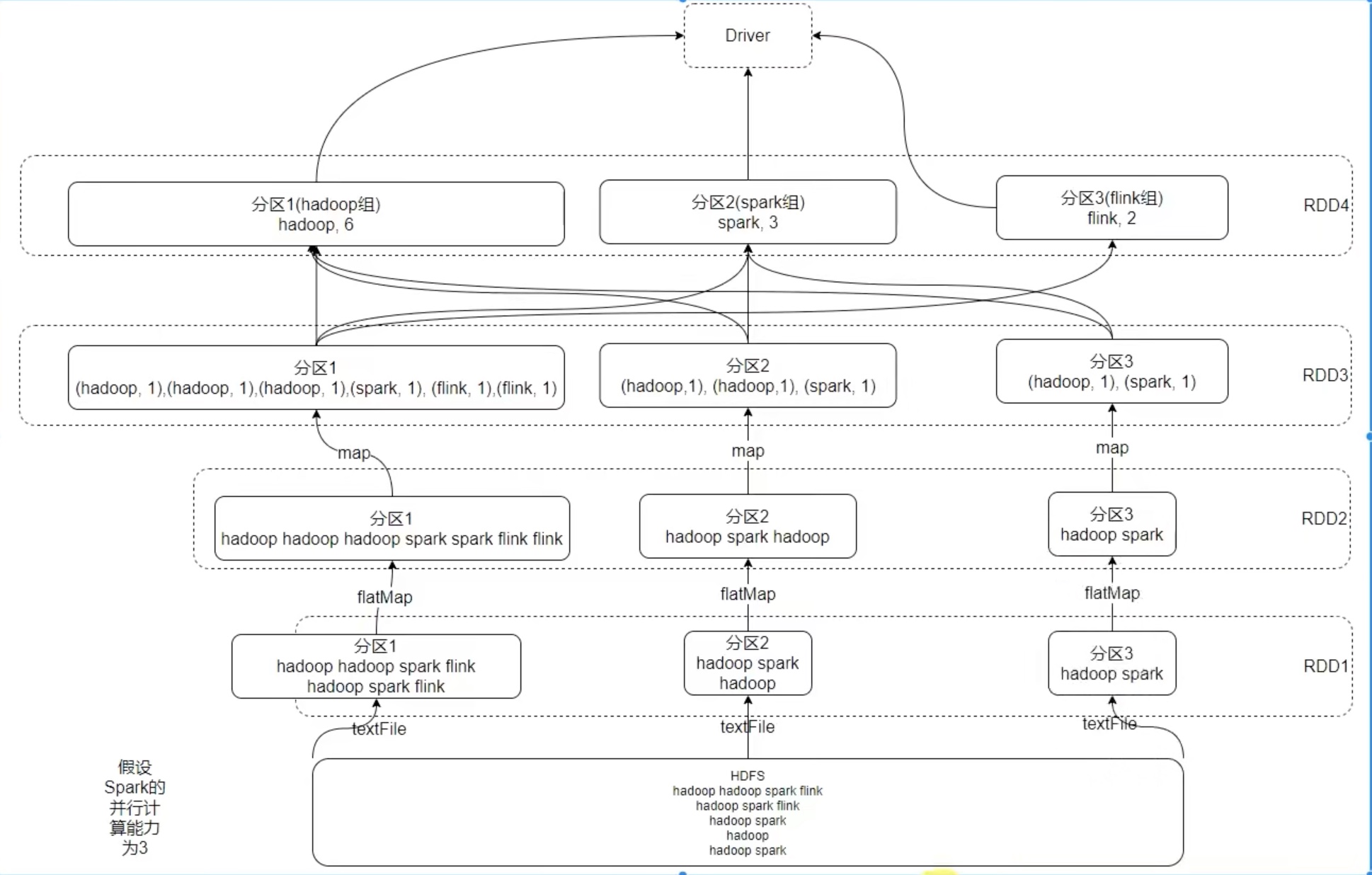
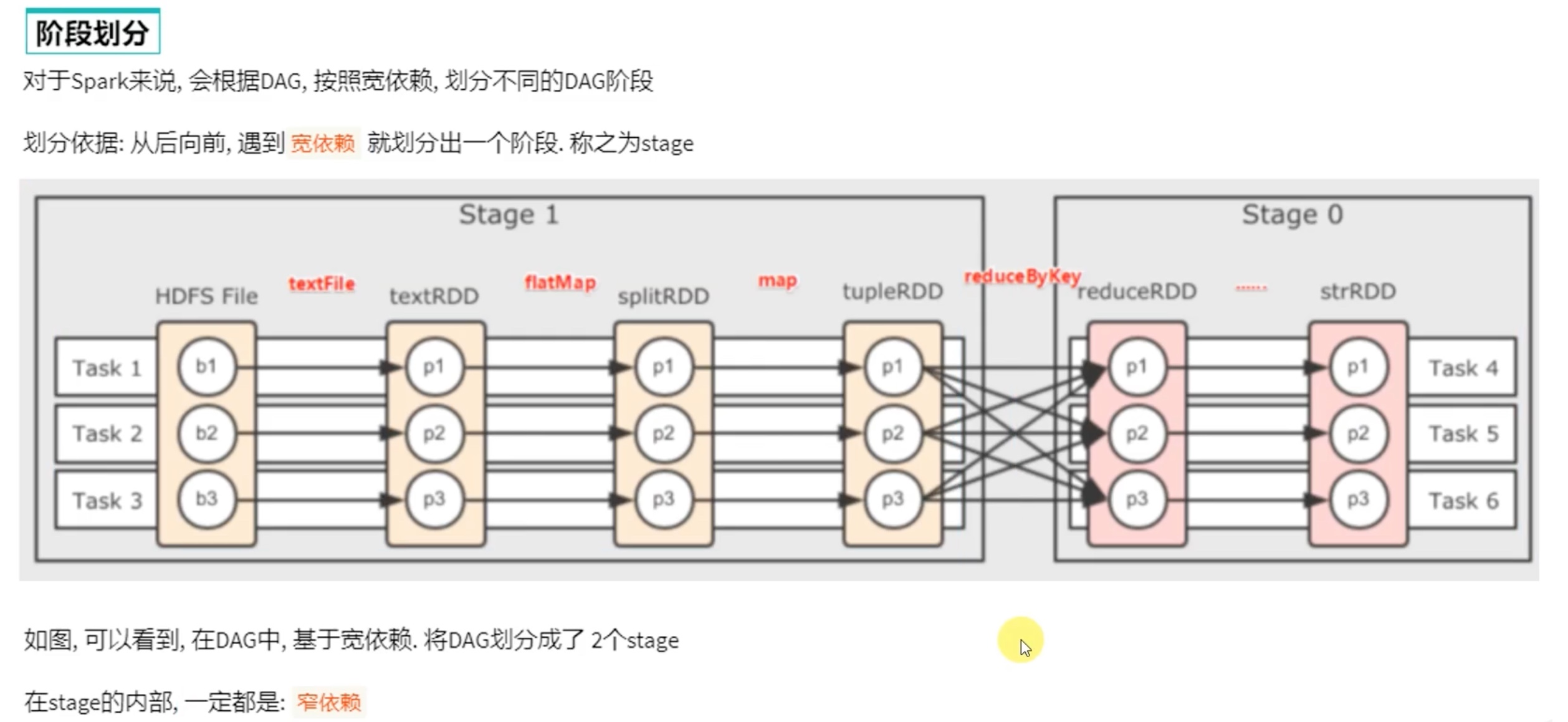
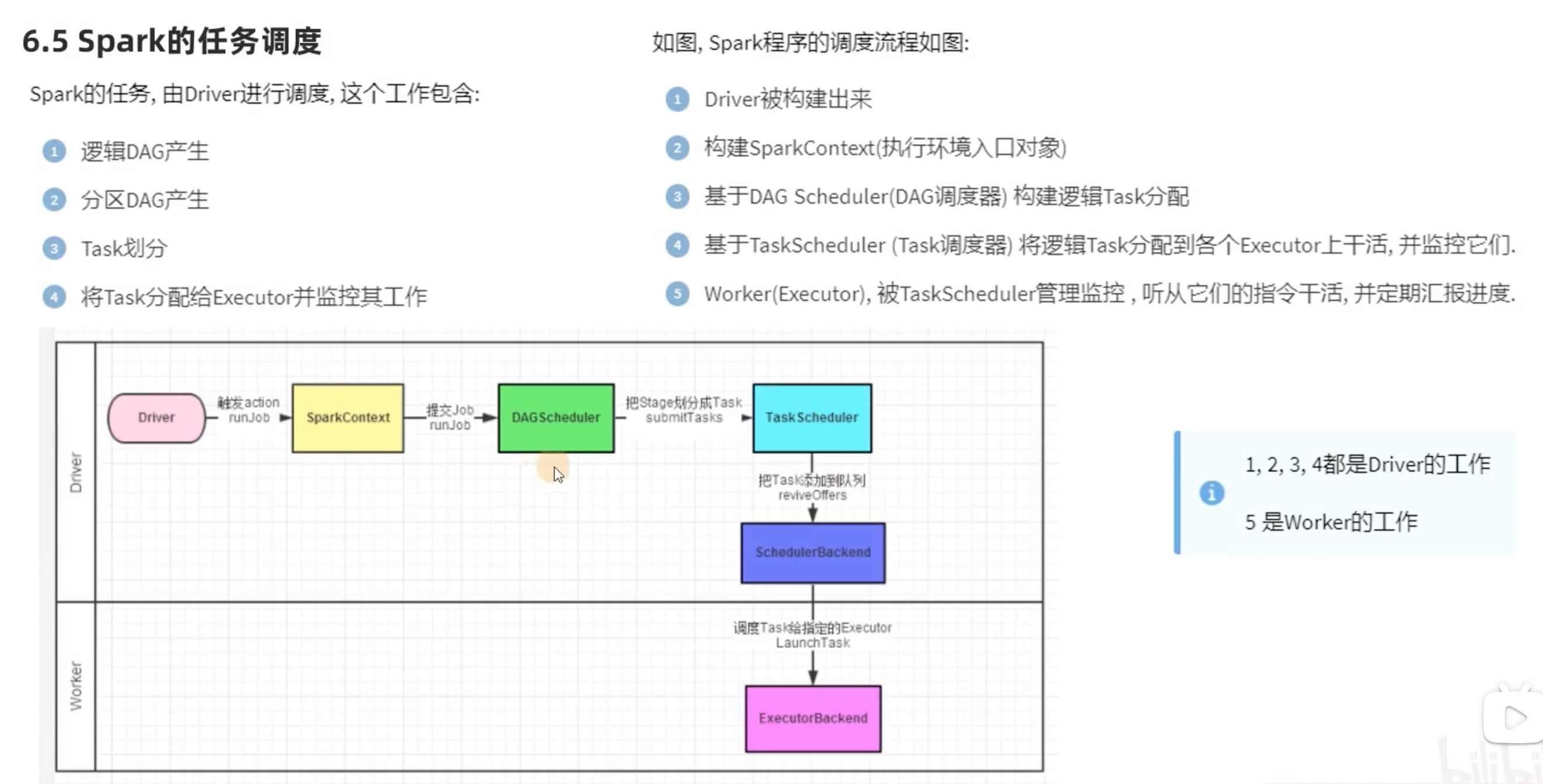
上图是之前 案例练习 三个需求的DAG ,实际上三个 action算子 就是三个 job任务(action算子才能把rdd链条运行起来),在4040端口或者历史端口的DAG可视化 也能看见。
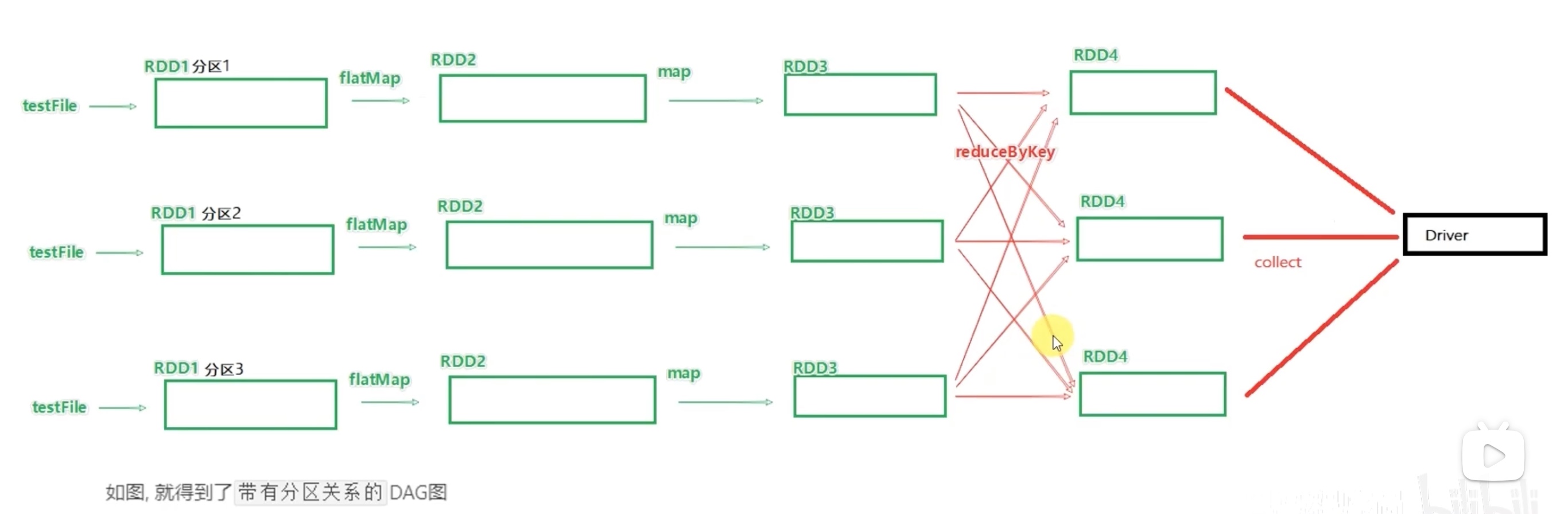
代码运行起来以后,把其中一个 job任务链条 多分区拆开来看,如下:
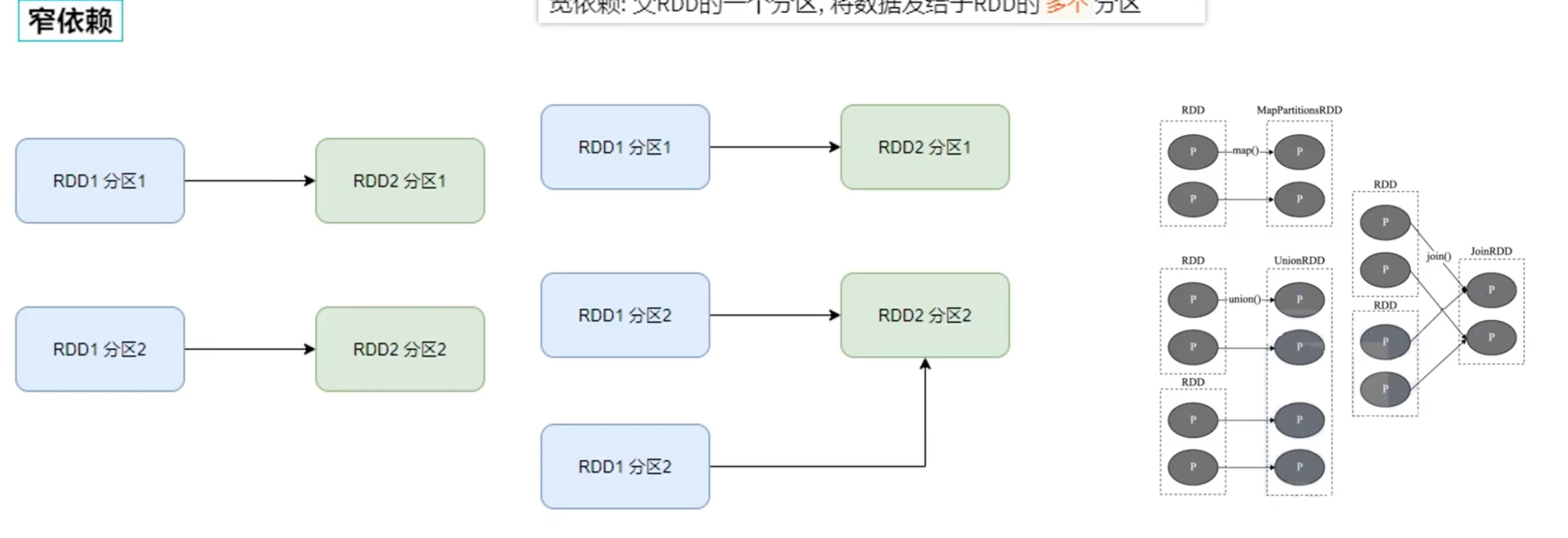
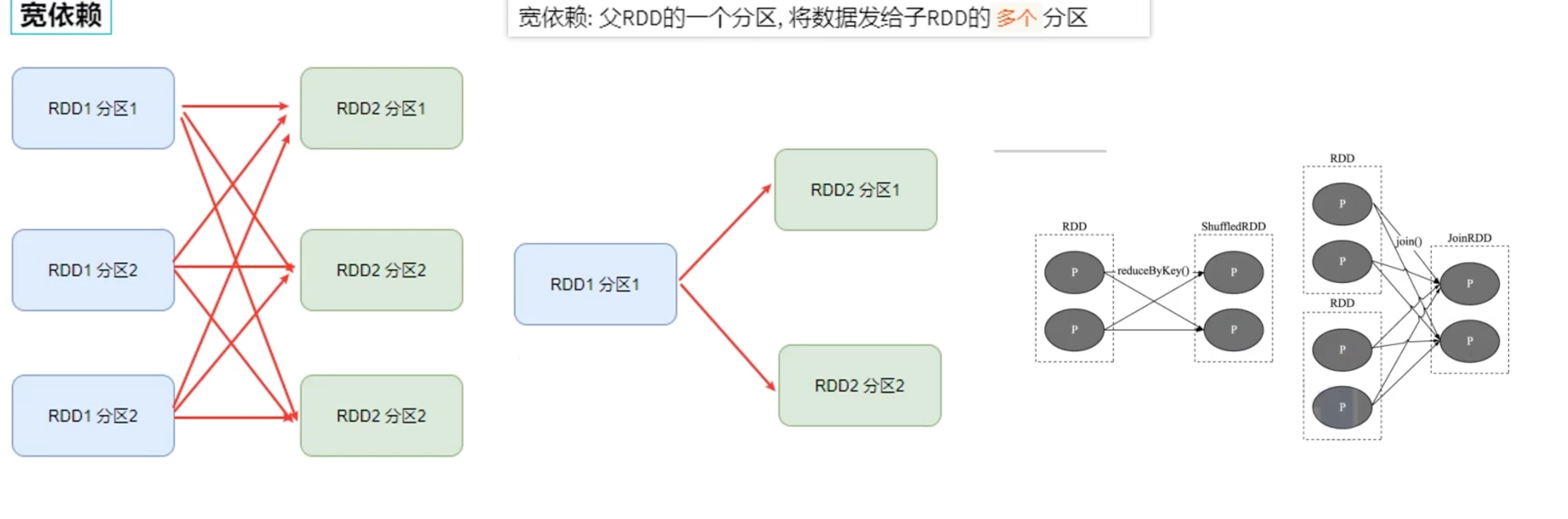
宽窄依赖和阶段划分
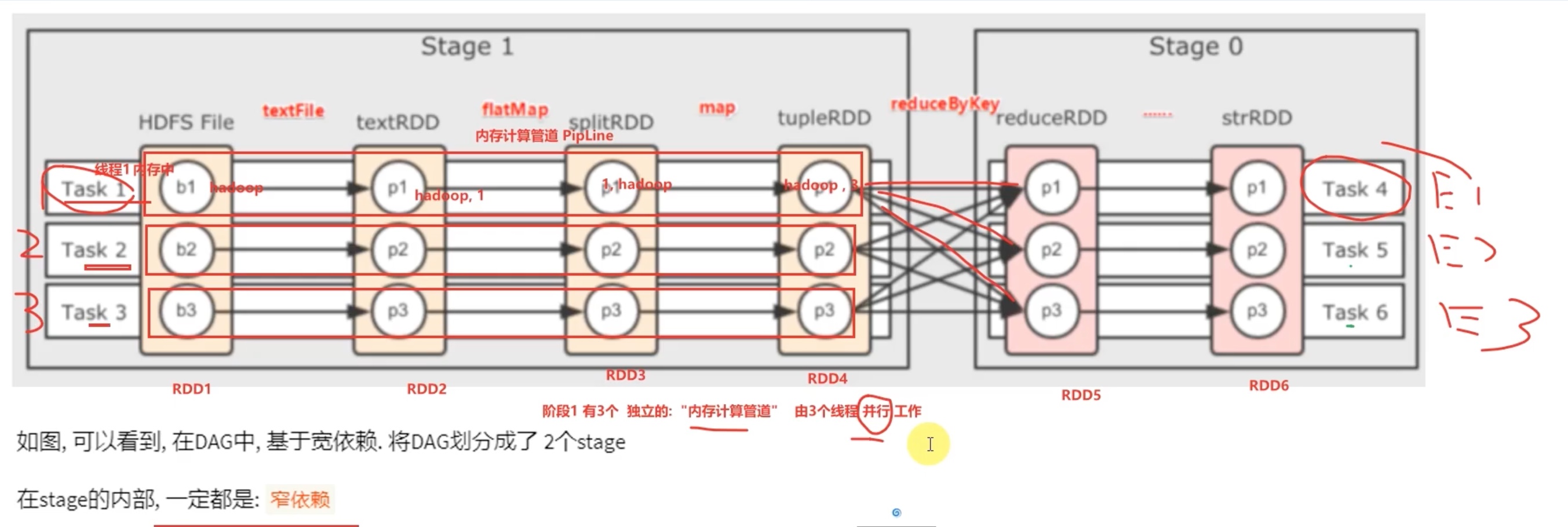
内存迭代计算
上图是三个executor 并行计算的DAG,一个task 是一个executor内的线程,这样可以避免 stage 内走网络。
task 之间是不需要交互的,所以task 之间可以并行计算,要保证spark的性能,首先要“并行”,其次要减少网络io传输。 000
两个stage 之间的宽依赖 连接时,比如reducebykey() ,不可避免走网络 在executor之间交互内容。
像local模式,直接走内存,不走任何网络,因为只有一个executor 实际是用内部的多个线程来模拟 并行计算,实现不了spark集群多个executor 的并行计算性能优势。
像上图一样,在rdd3 的位置,如果分成5个分区,破坏了之前 3 个分区的 结构,就会出现“分叉”也就是 “宽依赖”,缩短了 pipeline 内存计算管道(红色框内容)长度,增加了stage 的个数,同时大幅增加了 shuffle 的的复杂度。
spark 就是将尽可能多的计算步骤在 pipeline 内存计算管道(红色框内容)内完成,以实现spark 内存并行计算的 “高性能”。
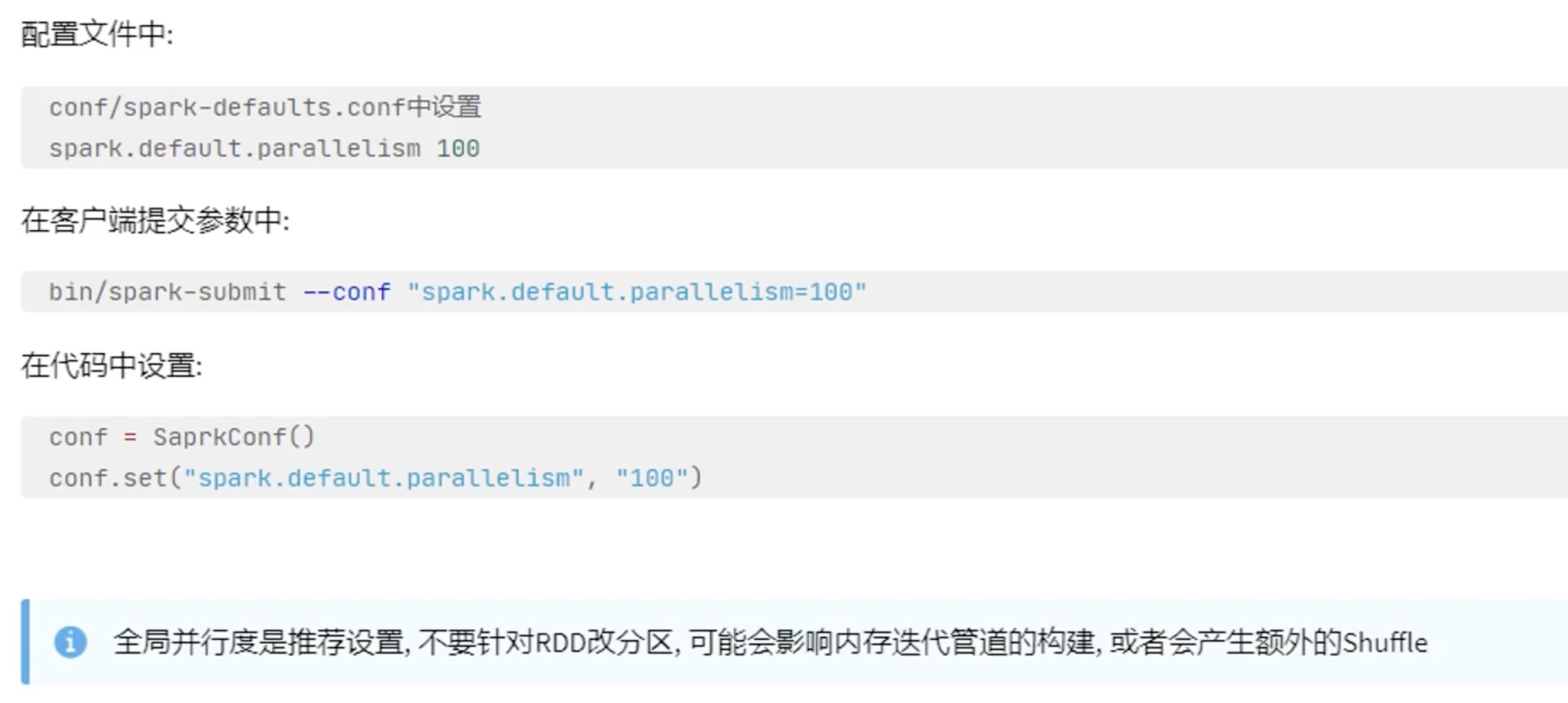
因此 ,spark 加了 “全局并行度限制”。
spark并行度 逻辑上是先确定了并行度,再根据并行度确定分区数。
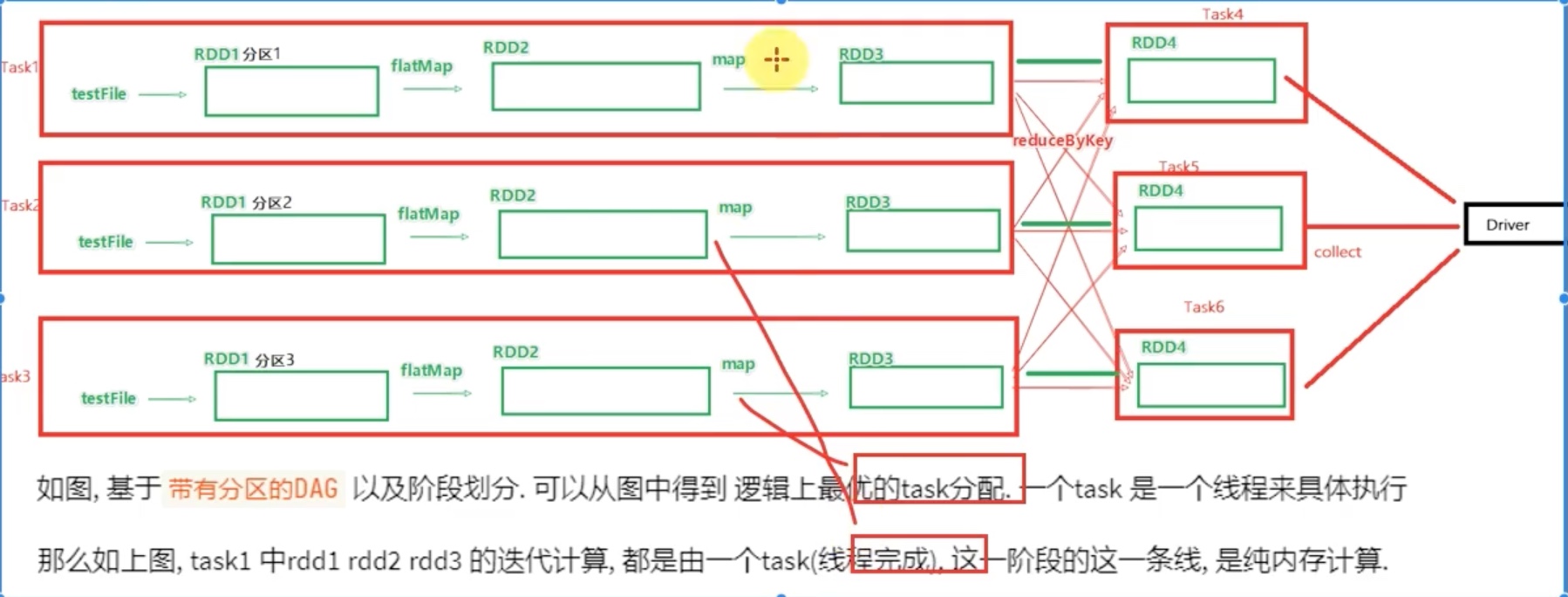
一个分区在一个stage内 只会被一个 task 处理,一个task 处理多个rdd 的某一个分区 的内容。
理论上,并行的task越多,每个的task大小就都会变小,相当于摊薄了task,最后的一批task任务结束时间就会相对接近,从这个角度看,也可以降低 cpu 空闲。
spark任务调度
executor 的数量 由 --num-executors 决定,和并行度 没有关系。
DAGscheduler 先 分解task 任务,再根据executor 数量分配下去。(关键)
Taskscheduler 仅仅是把 DAGscheduler 安排好的策略 发到executor,自己扮演一个“监工”。
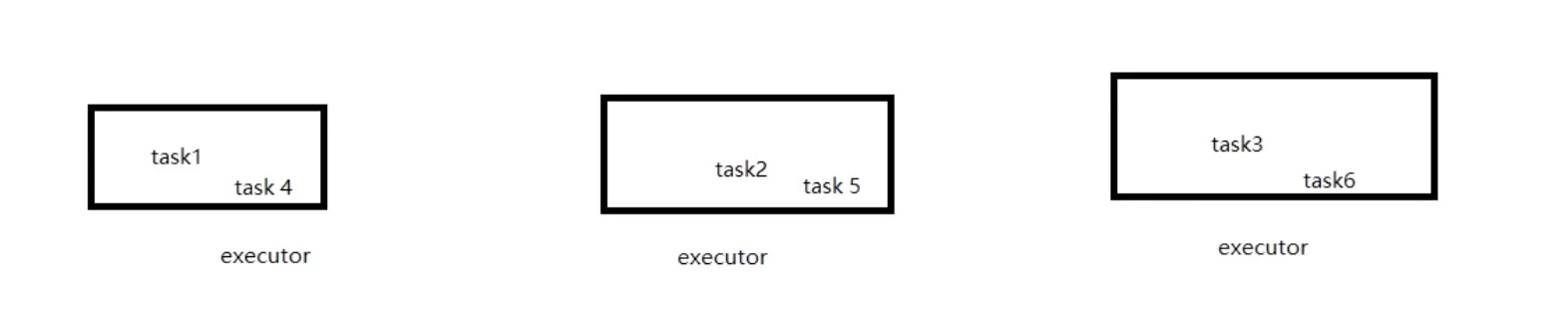
如果是 3 个executor ,DAGscheduler 就会把上面6个task 按如下方法分配给executor。
有多少个 机器,设置多少个 executor ,保证都用上就行。
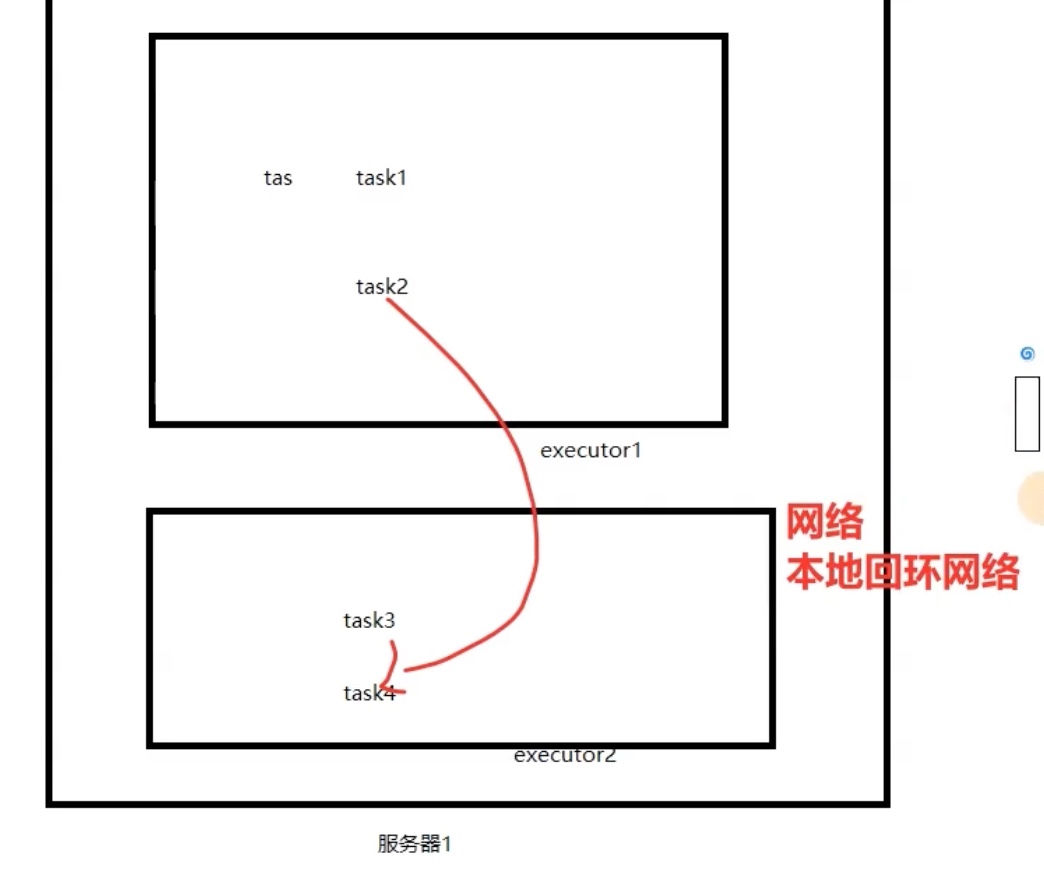
如果只有2个机器,却强制开启了4个 executor 进程,反而会降低性能,因为进程之间的通信要走网络,无法像进程内部的不同task线程通信一样走内存,如下图:
理论上,一个服务器内,cpu的核心数量(严格来说是线程数量) == task分配进此服务器的数量,也就是把cpu性能吃满,效率会最高。
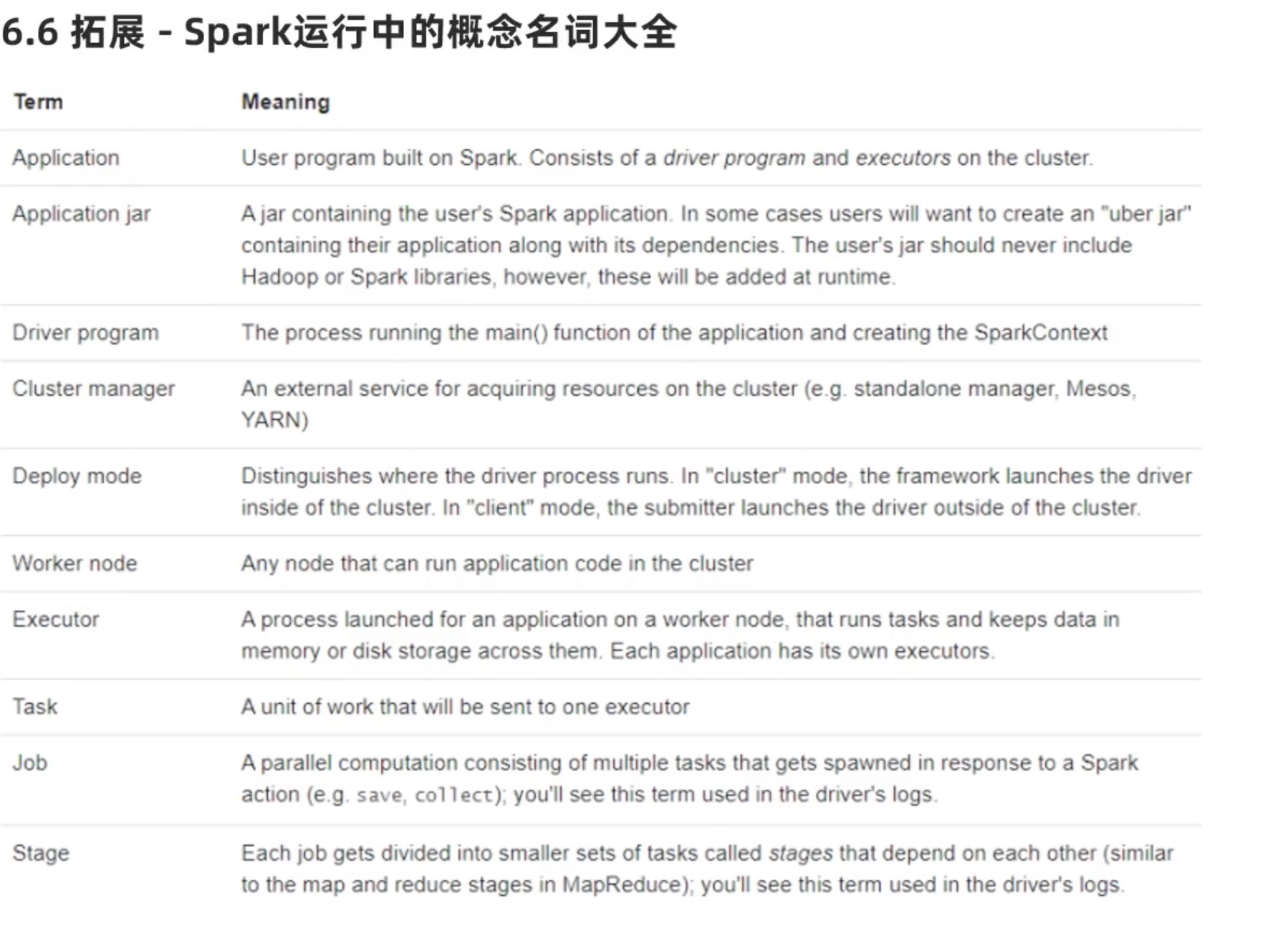
spark常用词汇