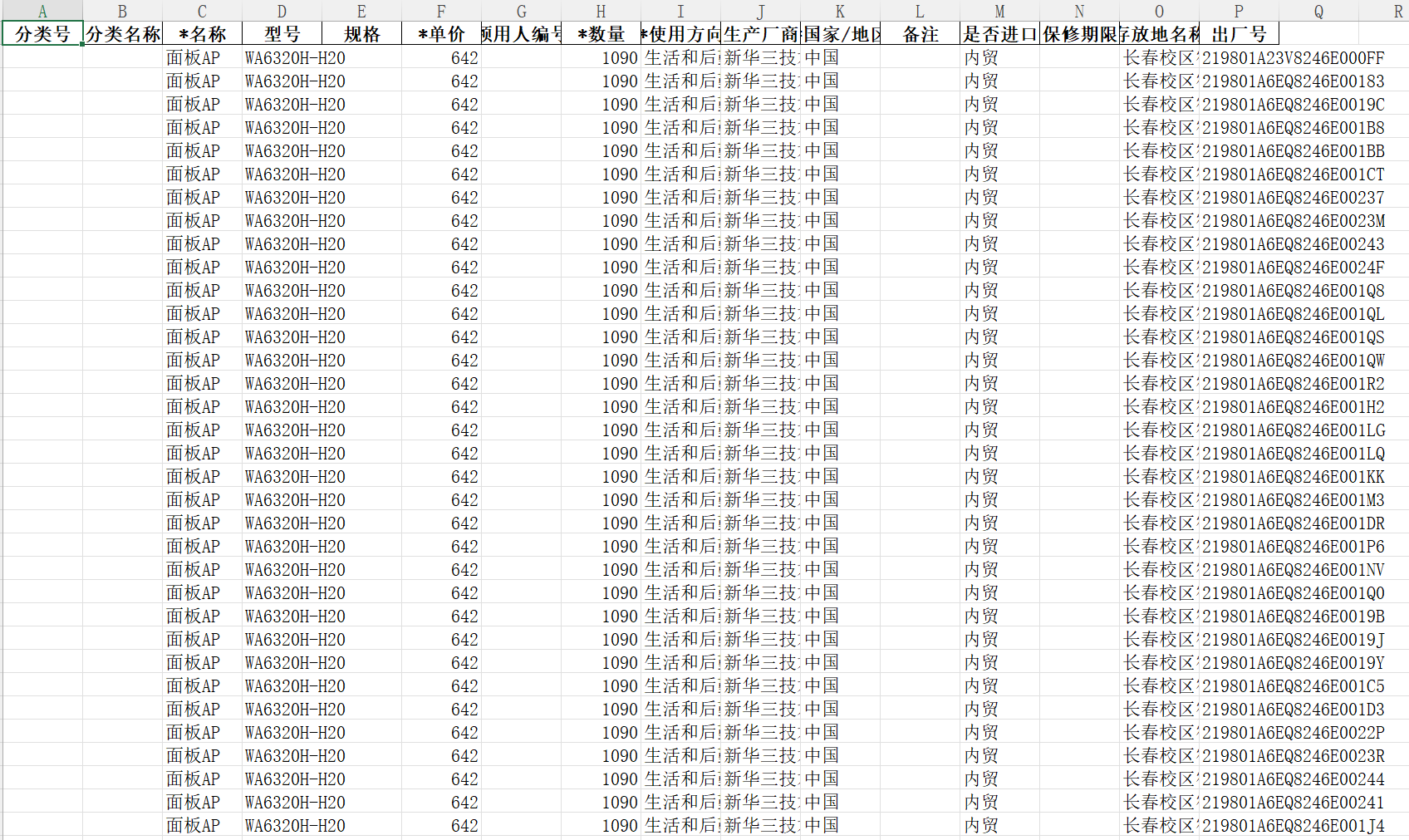
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
|
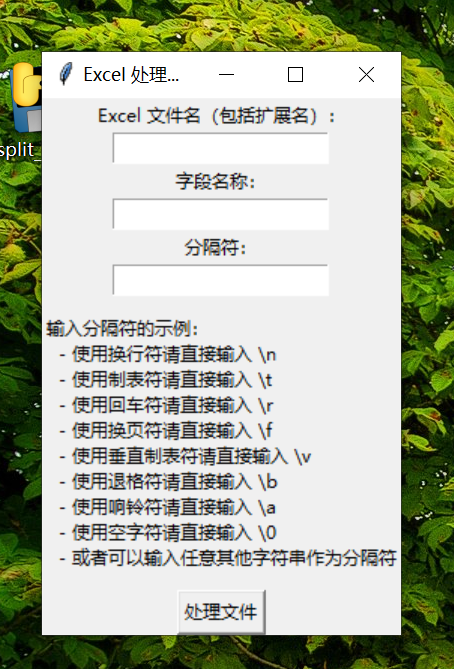
import openpyxl
import pandas as pd
import os
import tkinter as tk
from tkinter import messagebox
def process_excel_to_csv(file_name, column_name, delimiter):
try:
current_dir = os.getcwd()
file_path = os.path.join(current_dir, file_name)
escape_mapping = {
'\\n': '\n',
'\\t': '\t',
'\\r': '\r',
'\\f': '\f',
'\\v': '\v',
'\\b': '\b',
'\\a': '\a',
'\\0': '\0'
}
for escape_seq, actual_char in escape_mapping.items():
delimiter = delimiter.replace(escape_seq, actual_char)
df = pd.read_excel(file_path)
if column_name in df.columns:
expanded_rows = []
for index in range(len(df)):
value = df.at[index, column_name]
if pd.notna(value):
split_values = [elem.strip() for elem in value.split(delimiter) if elem.strip()]
for item in split_values:
new_row = df.iloc[index].copy()
new_row[column_name] = item
expanded_rows.append(new_row)
expanded_df = pd.DataFrame(expanded_rows)
expanded_df = expanded_df[expanded_df[column_name].str.strip().astype(bool)]
else:
messagebox.showerror("错误", f"字段 '{column_name}' 不存在于文件中。")
return
base, ext = os.path.splitext(file_path)
new_file_name = f"{base}(脚本处理生成).csv"
expanded_df.to_csv(new_file_name, index=False, encoding='utf-8')
messagebox.showinfo("成功", f"CSV 文件已保存为: {new_file_name}")
new_excel_name = f"{base}(脚本处理生成).xlsx"
expanded_df.to_excel(new_excel_name, index=False)
messagebox.showinfo("成功", f"Excel 文件已保存为: {new_excel_name}")
except Exception as e:
messagebox.showerror("错误", f"处理文件时出错: {e}")
def on_submit():
file_name = entry_file.get()
column_name = entry_column.get()
delimiter = entry_delimiter.get()
if not file_name or not column_name:
messagebox.showerror("错误", "文件名和字段名称不能为空!")
return
process_excel_to_csv(file_name, column_name, delimiter)
root = tk.Tk()
root.title("Excel 处理工具")
tk.Label(root, text="Excel 文件名(包括扩展名):").pack()
entry_file = tk.Entry(root)
entry_file.pack()
tk.Label(root, text="字段名称:").pack()
entry_column = tk.Entry(root)
entry_column.pack()
tk.Label(root, text="分隔符:").pack()
entry_delimiter = tk.Entry(root)
entry_delimiter.pack()
delimiter_info = (
"输入分隔符的示例:\n"
" - 使用换行符请直接输入 \\n\n"
" - 使用制表符请直接输入 \\t\n"
" - 使用回车符请直接输入 \\r\n"
" - 使用换页符请直接输入 \\f\n"
" - 使用垂直制表符请直接输入 \\v\n"
" - 使用退格符请直接输入 \\b\n"
" - 使用响铃符请直接输入 \\a\n"
" - 使用空字符请直接输入 \\0\n"
" - 或者可以输入任意其他字符串作为分隔符"
)
tk.Label(root, text=delimiter_info, justify='left').pack(pady=10)
btn_submit = tk.Button(root, text="处理文件", command=on_submit)
btn_submit.pack()
root.mainloop()
|