本地部署Deepseek有几种经典的做法,有借助ollama实现也有直接下载各种对应模型到本地用vllm调用等。我为了使用和部署方便,决定使用docker部署实现。
使用多种方案部署前,需要先做好准备工作。
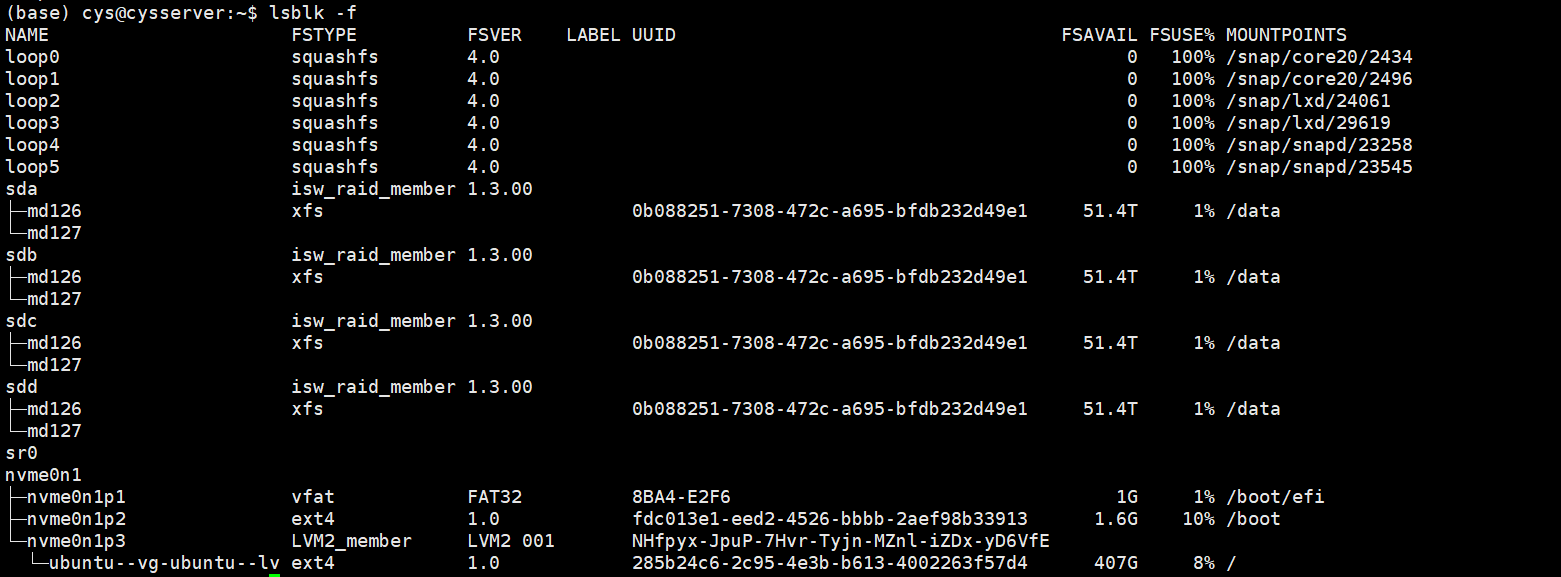
一、前期准备 1、系统、存储及驱动情况 我之前是ubuntu20.04的系统,Linux核心也是老版本的,但是Nvidia驱动和conda等环境不想变动还有很多数据不方便挪,所以选择了使用命令后台升级成了下面的版本(大约3小时),为了方便直接使用docker。以下是升级完成后我的机器情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 (base) cys@cysserver:~$ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 24.04.2 LTS Release: 24.04 Codename: noble (base) cys@cysserver:~$ uname -r 6.8.0-53-generic (base) cys@cysserver:~$ free -h total used free shared buff/cache available Mem: 503Gi 5.9Gi 456Gi 7.3Mi 44Gi 497Gi Swap: 8.0Gi 0B 8.0Gi (base) cys@cysserver:~$ nvidia-smi Fri Feb 28 06:36:49 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 550.144.03 Driver Version: 550.144.03 CUDA Version: 12.4 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 3090 Off | 00000000:47:00.0 Off | N/A | | 41% 27C P8 22W / 350W | 4MiB / 24576MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ | 1 NVIDIA GeForce RTX 3090 Off | 00000000:5E:00.0 Off | N/A | | 41% 25C P8 25W / 350W | 4MiB / 24576MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
2、国内安装docker 2.1、安装docker 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 sudo apt-get purge docker-ce docker-ce-cli containerd.io docker-buildx-plugin sudo rm -rf /var/lib/docker sudo rm -rf /var/lib/containerd sudo rm -rf /etc/docker curl -fsSL https://get.docker.com | sudo sh sudo apt-get update sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin sudo sed -i 's/noble/jammy/g' /etc/apt/sources.list.d/docker.list sudo apt update sudo apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin sudo usermod -aG docker $USER newgrp docker vim /etc/docker/daemon.json --------------------------------------------------- { "registry-mirrors" : [ "https://docker.m.daocloud.io" ] } --------------------------------------------------- 或 --------------------------------------------------- { "registry-mirrors" : [ "https://docker.m.daocloud.io" , "https://mirror.ccs.tencentyun.com" , "https://func.ink" , "https://proxy.1panel.live" , "https://docker.zhai.cm" ] } --------------------------------------------------- sudo systemctl daemon-reload sudo systemctl enable docker sudo systemctl restart docker docker pull busybox
2.2、安装docker-compose 官方文档: https://docs.docker.com/compose/install/
1 2 3 4 5 6 sudo apt-get install docker-compose-plugin docker compose version docker compose -v
3、Docker 调用宿主机Nvidia卡 参考 :https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html https://blog.csdn.net/dw14132124/article/details/140534628
1 2 3 4 5 6 curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt-get update sudo apt-get install -y nvidia-container-toolkit
结合上面解决Docker CE的步骤,可能会导致 docker 在国内拉取不到镜像的情况,需要按照下面再搞一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 sudo vim /etc/docker/daemon.json { "registry-mirrors" : [ "https://docker.m.daocloud.io" , "https://mirror.ccs.tencentyun.com" , "https://func.ink" , "https://proxy.1panel.live" , "https://docker.zhai.cm" ] } sudo systemctl daemon-reload sudo systemctl enable docker sudo systemctl restart docker cat /etc/docker/daemon.jsonjson { "runtimes" : { "nvidia" : { "path" : "nvidia-container-runtime" , "runtimeArgs" : [] } } } docker pull busybox docker pull nvidia/cuda:12.0.1-base-ubuntu22.04
检查 docker 能不能正常使用 Nvidia的GPU
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 dpkg -l | grep nvidia-container-toolkit docker pull nvidia/cuda:12.0.1-devel-ubuntu22.04 docker run --rm --gpus all nvidia/cuda:12.0.1-devel-ubuntu22.04 nvidia-smi docker run --rm --gpus all nvidia/cuda:12.0.1-devel-ubuntu22.04 nvcc --version "apt update && apt install -y cuda-samples-12-0 && \ cd /usr/local/cuda/samples/0_Simple/vectorAdd && make && ./vectorAdd"
nvidia-docker 与 NVIDIA Container Toolkit 的关系:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 vim hello.cu __global__ void hello printf ("Hello from GPU!\n" ); } int main hello<<<1,1 >>>(); cudaDeviceSynchronize(); return 0; } nvcc --version nvcc -o hello hello.cu -arch =sm_86 && ./hello
二、自建搜索引擎 无论是 DuckDuckGo 还是 Google Search Engine,都需要科学上网才能正常使用。
所以我们就要自己搭建本地的搜索引擎。
1、SearXNG 搜索引擎本地部署(二选一) 1.1、Docker compose版本(可浏览器使用,不可被AnythingLLM/open webUI调用) 我们还是用docker版本的,方便:
https://github.com/searxng/searxng-docker https://docs.searxng.org/ https://github.com/searxng/searxng/blob/master/searx/settings.yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 git clone https://github.com/searxng/searxng-docker.git cd searxng-dockersed -i "s|ultrasecretkey|$(openssl rand -hex 32) |g" searxng/settings.yml docker compose down docker compose up -d
1.1.1、yaml: searxng/searxng-docker# cat docker-compose.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 version: "3.7" services: redis: container_name: redis image: docker.io/valkey/valkey:8-alpine command: valkey-server --save 30 1 --loglevel warning restart: unless-stopped networks: - searxng volumes: - valkey-data2:/data cap_drop: - ALL cap_add: - SETGID - SETUID - DAC_OVERRIDE logging: driver: "json-file" options: max-size: "1m" max-file: "1" searxng: container_name: searxng image: docker.io/searxng/searxng:latest restart: unless-stopped networks: - searxng ports: - "0.0.0.0:8080:8080" volumes: - ./searxng:/etc/searxng:rw environment: - SEARXNG_BASE_URL=http://${SEARXNG_HOSTNAME:-localhost}/ - UWSGI_WORKERS=${SEARXNG_UWSGI_WORKERS:-4} - UWSGI_THREADS=${SEARXNG_UWSGI_THREADS:-4} cap_add: - CHOWN - SETGID - SETUID logging: driver: "json-file" options: max-size: "1m" max-file: "1" networks: searxng: volumes: valkey-data2:
1.1.2、yaml解释: 1 2 ports: - "127.0.0.1:8080:8080"
这表示将容器内部的 8080 端口映射到宿主机的 127.0.0.1 地址(即 localhost)的 8080 端口。含义 :只有在服务器本机上访问 127.0.0.1:8080 才能看到服务。如果你在与服务器同一局域网的个人电脑上使用服务器 IP(例如 192.168.1.100:8080)访问,由于映射只绑定在 127.0.0.1 上,外部设备无法通过服务器外网 IP 访问到这个端口。
1 2 ports: - "0.0.0.0:8080:8080"
环境变量
1 2 environment: - SEARXNG_BASE_URL=https://${SEARXNG_HOSTNAME:-localhost}/
这表示默认使用 HTTPS 协议,并且如果环境变量 SEARXNG_HOSTNAME 没有设置,则使用 localhost 作为域名。
如果你的情况和我一样:
你在局域网内做了 DNS 解析,但没有在公网做 DNS。
你设置了反向代理,但没有 TLS(即只提供 HTTP 访问)。
因此,你在局域网内通过 http://局域网的域名 来访问。
1 2 environment: - SEARXNG_BASE_URL=http://${SEARXNG_HOSTNAME:-localhost}/
如果你不想使用域名,也可以直接使用服务器的 IP 地址,比如:
1 2 environment: - SEARXNG_BASE_URL=http://10.199.1.233/
这里的 10.199.1.233 就是你服务器在局域网内的 IP 地址。
1.1.3、修改setting.yml配置 找自己要添加的内容复制下来,黏贴进默认的setting.yml中就行了,这样好像不行。
以下是我的 setting.yml 情况,加了一个 json 格式 和 bing engine。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 (base) cys@cysserver:~/docker_data/searxng/searxng-docker$ cat ./searxng/settings.yml use_default_settings: true server: secret_key: "我的密钥" limiter: false image_proxy: true ui: static_use_hash: true redis: url: redis://redis:6379/0 engines: - name: 360search engine: 360search shortcut: 360so disabled: false - name: bing engine: bing shortcut: bi disabled: false - name: sogou engine: sogou shortcut: sogou disabled: false search: formats: - html - json
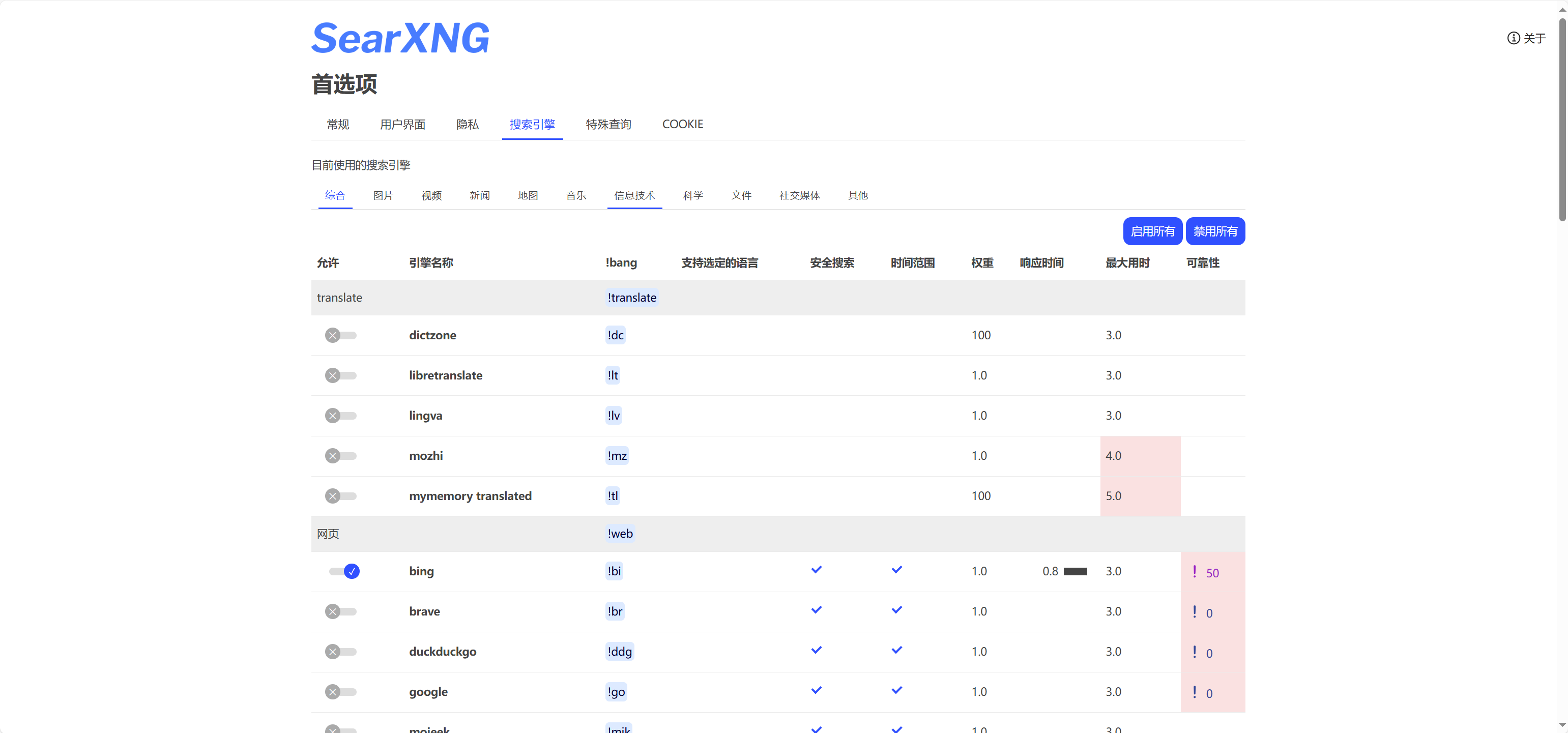
1.1.4、登录searxng页面改搜索引擎: 因为大陆不方便用很多引擎,你懂的。所以我们用 中国大陆可以用的 bing 这些。
先登录 http://IP:8080 在右上角配置。
1.2、Docker 版本(不可被AnythingLLM/open webUI调用) 参考:https://docs.searxng.org/admin/installation-docker.html#installation-docker
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 sudo usermod -a -G docker $USER $ mkdir my-instance $ cd my-instance $ export PORT=8080 $ docker pull searxng/searxng $ docker run --rm \ -d -p ${PORT} :8080 \ -v "${PWD} /searxng:/etc/searxng" \ -e "BASE_URL=http://localhost:$PORT /" \ -e "INSTANCE_NAME=my-instance" \ searxng/searxng 2f998.... $ docker container ls CONTAINER ID IMAGE COMMAND CREATED ... 2f998d725993 searxng/searxng "/sbin/tini -- /usr/…" 7 minutes ago ... $ docker container restart 2f998 xdg-open "http://localhost:$PORT " $ docker container stop 2f998 $ docker container rm 2f998
三、反向代理 1、安装Nginx Proxy Manager 官方文档: https://nginxproxymanager.com/guide/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 vim docker-compose.yml version: '3.8' services: app: image: 'jc21/nginx-proxy-manager:latest' restart: unless-stopped ports: - '80:80' - '81:81' - '443:443' volumes: - ./data:/data - ./letsencrypt:/etc/letsencrypt
version: ‘3.8’
services:
app:
image: ‘jc21/nginx-proxy-manager:latest’
jc21/nginx-proxy-manager 是镜像名称,:latest 表示使用最新版本的镜像。Docker 会自动从仓库中拉取该镜像(如果本地不存在的话)。
当容器异常退出时会自动重启,除非用户主动停止容器。
‘80:80’ 表示将主机的 80 端口映射到容器的 80 端口。
./data:/data 将当前目录下的 data 文件夹挂载到容器内的 /data 目录。
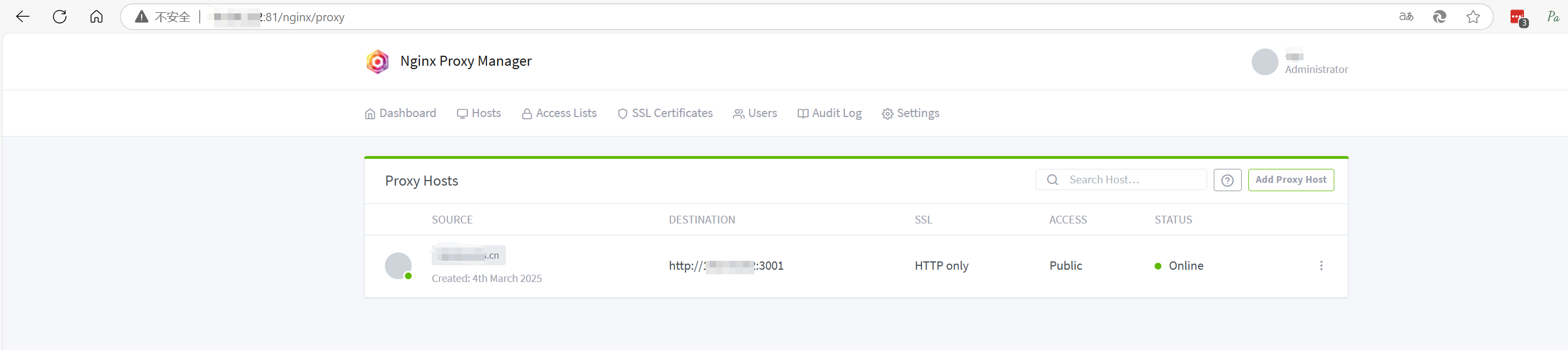
2、npm的Web管理控制台 一旦容器启动,你可以通过浏览器访问Nginx Proxy Manager的Web界面。默认地址是http://<your-server-ip>:81。
1 2 3 4 5 6 7 8 9 Email: admin@example.com Password: changeme
可以测试一下 ,在局域网或者公网中能不能用 域名访问了。
可能需要等待一下才能生效。
补充:免费域名注册 和 Cloudflare 域名解析
参考: https://blog.csdn.net/u010522887/article/details/140786338 https://www.freedidi.com/17434.html
四、思路一:Ollama部署Deepseek 1、安装ollama 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 curl -fsSL https://ollama.com/install.sh | sh sudo chown -R ollama:ollama /home/cys/data/models sudo vim /etc/systemd/system/ollama.service -------------------------------------------------------------------------- [Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/local/bin/ollama serve User=ollama Group=ollama Restart=always RestartSec=3 Environment="PATH=/home/cys/.local/bin:/home/cys/.local/bin:/home/cys/miniconda3/bin:/home/cys/miniconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin" Environment="OLLAMA_MODELS=/home/cys/data/models" Environment="OLLAMA_HOST=0.0.0.0:11434" Environment="OLLAMA_ORIGINS=*" [Install] WantedBy=default.target -------------------------------------------------------------------------- sudo systemctl daemon-reload sudo systemctl enable ollama sudo systemctl start ollama sudo systemctl status ollama ollama pull deepseek-r1:1.5b ollama list ll /home/cys/data/models/blobs/ ollama run deepseek-r1:70b
2.1、方案一:(ollama+anythingllm+searxng+Nignx proxy manager) 用ollama在本地部署 deepseek-r1-70b模型,然后安装docker,在docker 中方便的下载镜像 AnythingLLM,容器化AnythingLLM实现RAG。
2.1.1、Docker下安装AnythingLLM 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 docker pull mintplexlabs/anythingllm:latest docker stop AnythingLLM && docker rm AnythingLLM export STORAGE_LOCATION=/home/cys/docker_data/anythingllm mkdir -p $STORAGE_LOCATION cd ${STORAGE_LOCATION} touch .env docker run -d -p 3001:3001 \ --name AnythingLLM \ --network host \ --cap-add SYS_ADMIN \ -v ${STORAGE_LOCATION} :/app/server/storage \ -v ${STORAGE_LOCATION} /.env:/app/server/.env \ -e STORAGE_DIR="/app/server/storage" \ mintplexlabs/anythingllm docker ps | grep AnythingLLM docker start AnythingLLM docker stop AnythingLLM
2.1.2、AnythingLLM控制界面配置 在外部机器,比如一台Windows机器,浏览器访问 Ubuntu机器的 IP:3001。
进入一步一步设置,推荐 选团队使用,可以添加使用成员。
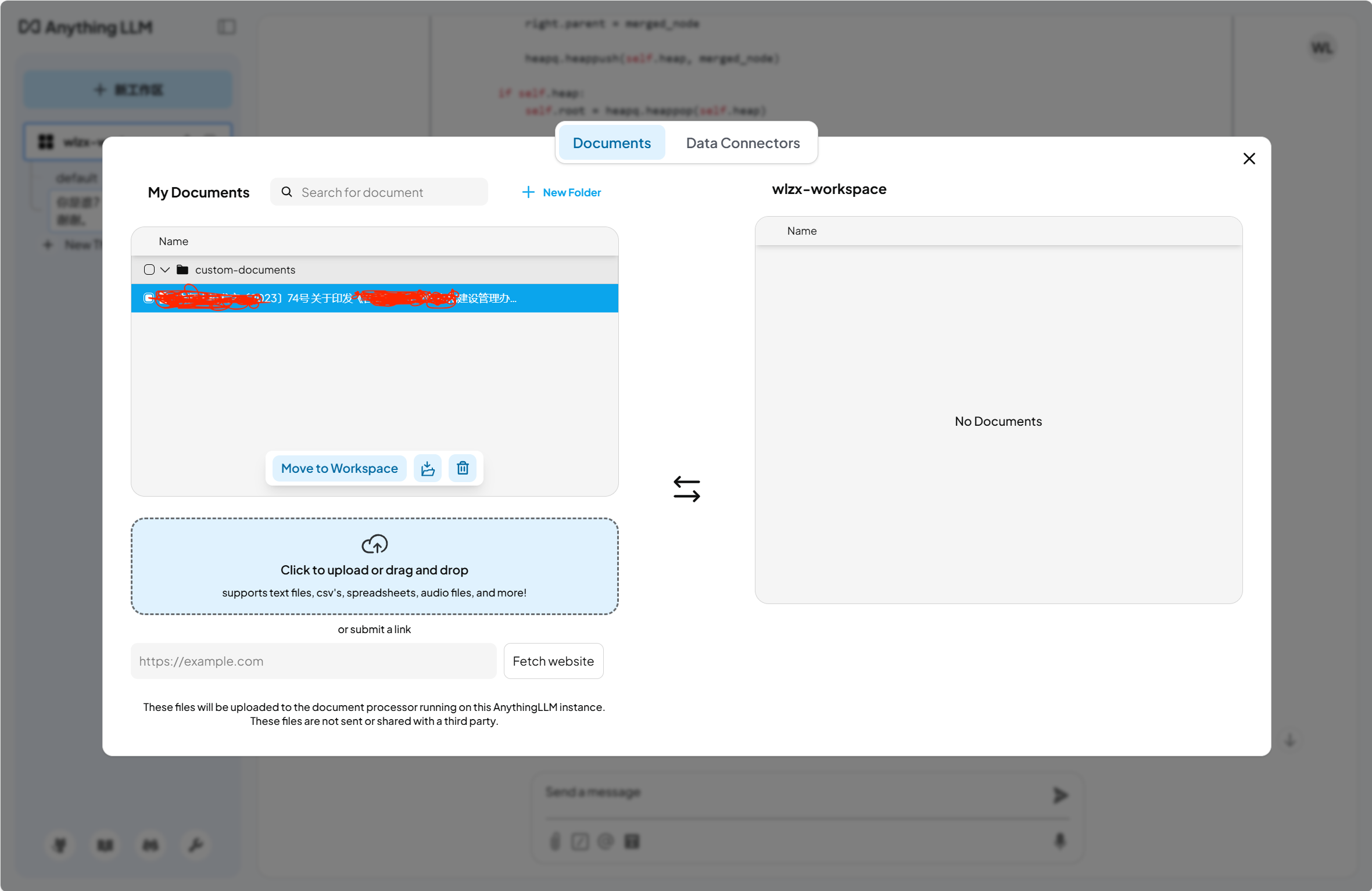
点击这一个workspace中的 上传 文件可以实现 RAG。
点击这一个workspace中的设置按钮,在聊天设置可以把 这个workspace选择 chat模式或者查询模式,查询模式优先从知识库中找内容回答,chat 则优先使用 自己训练的模型为主,但是也会参考知识库。
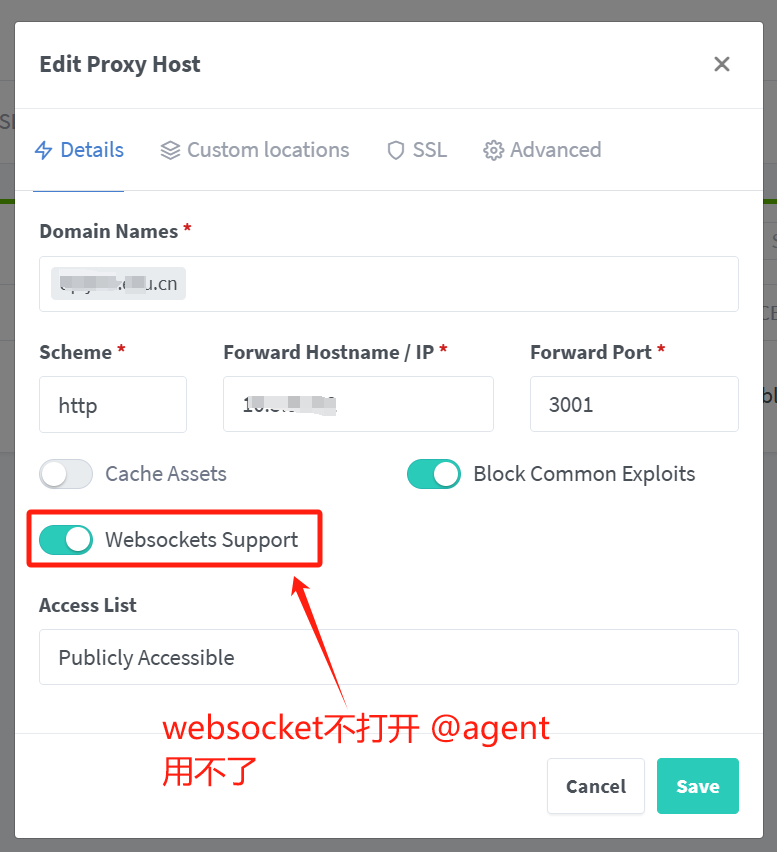
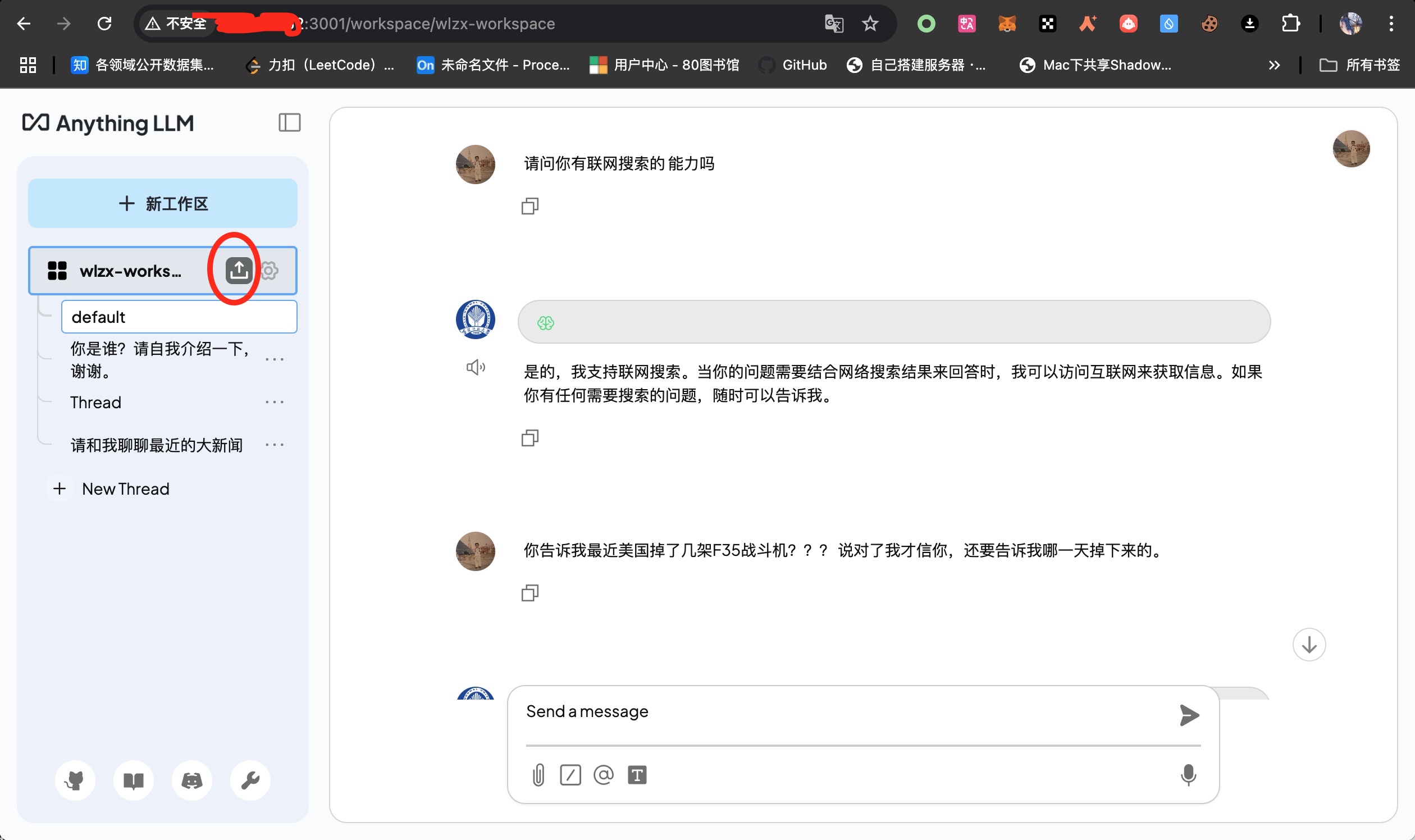
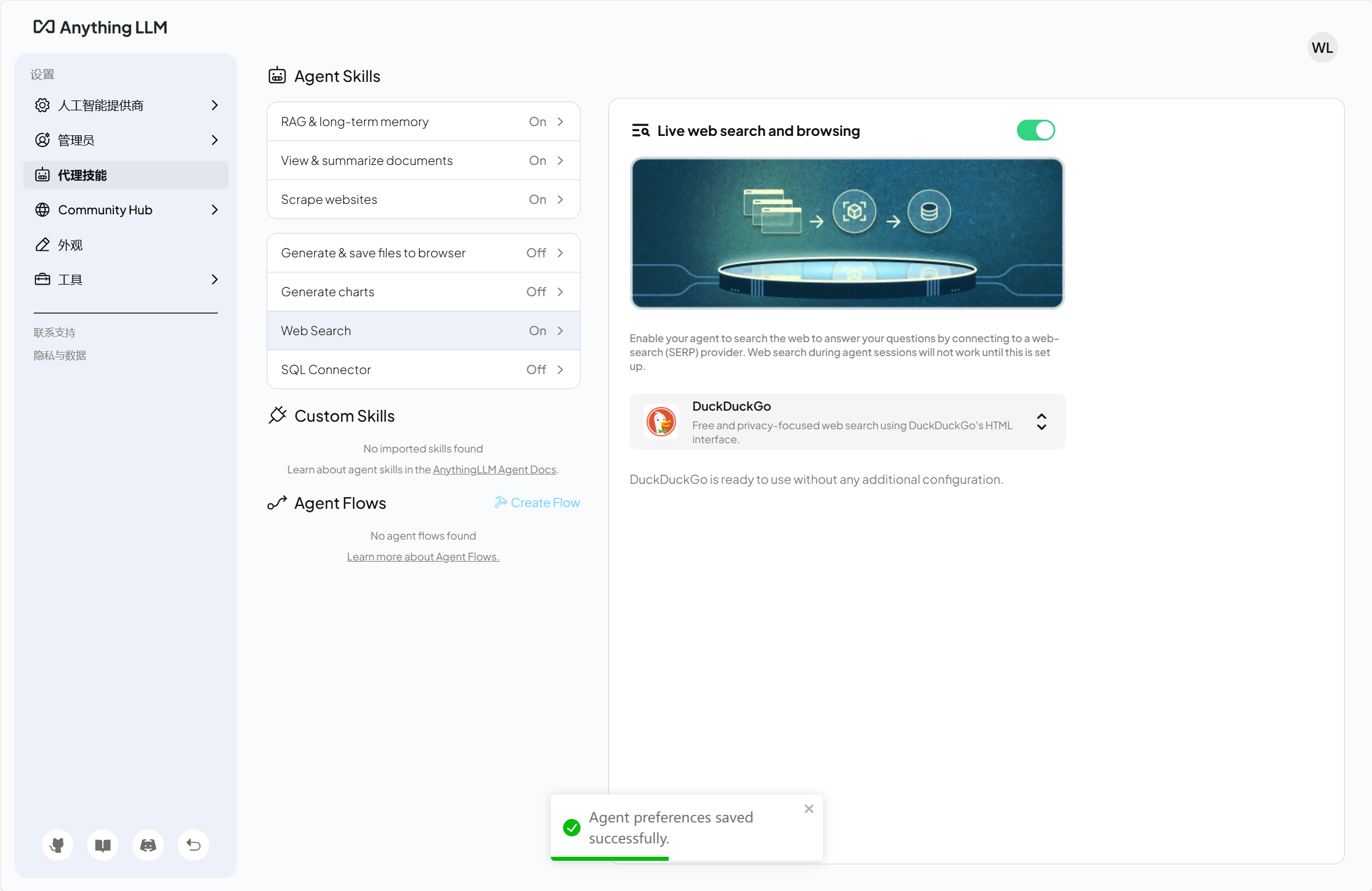
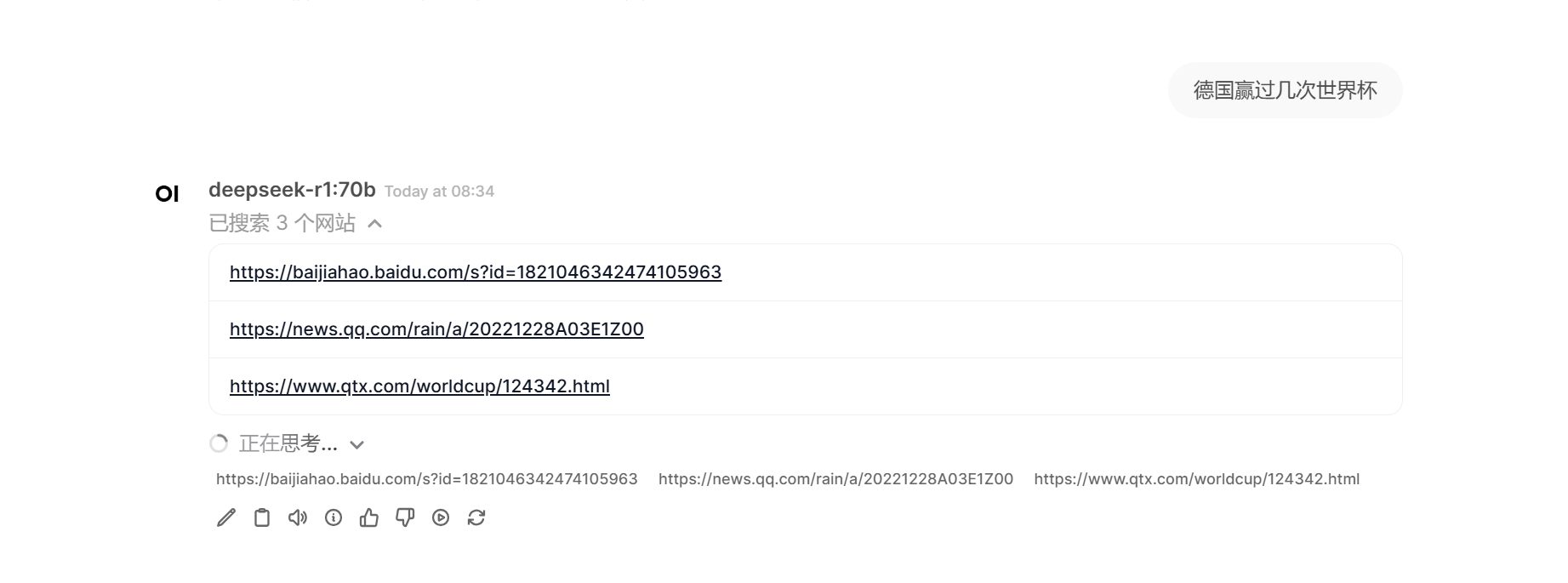
点击下方 扳手🔧,可以进入agent代理打开联网搜索功能,但是注意有的是国内用不了的,有的要收费,推荐使用开源的本地部署的搜索引擎。
tor浏览器的DuckDuckGo 浏览器在国内就不方便用。
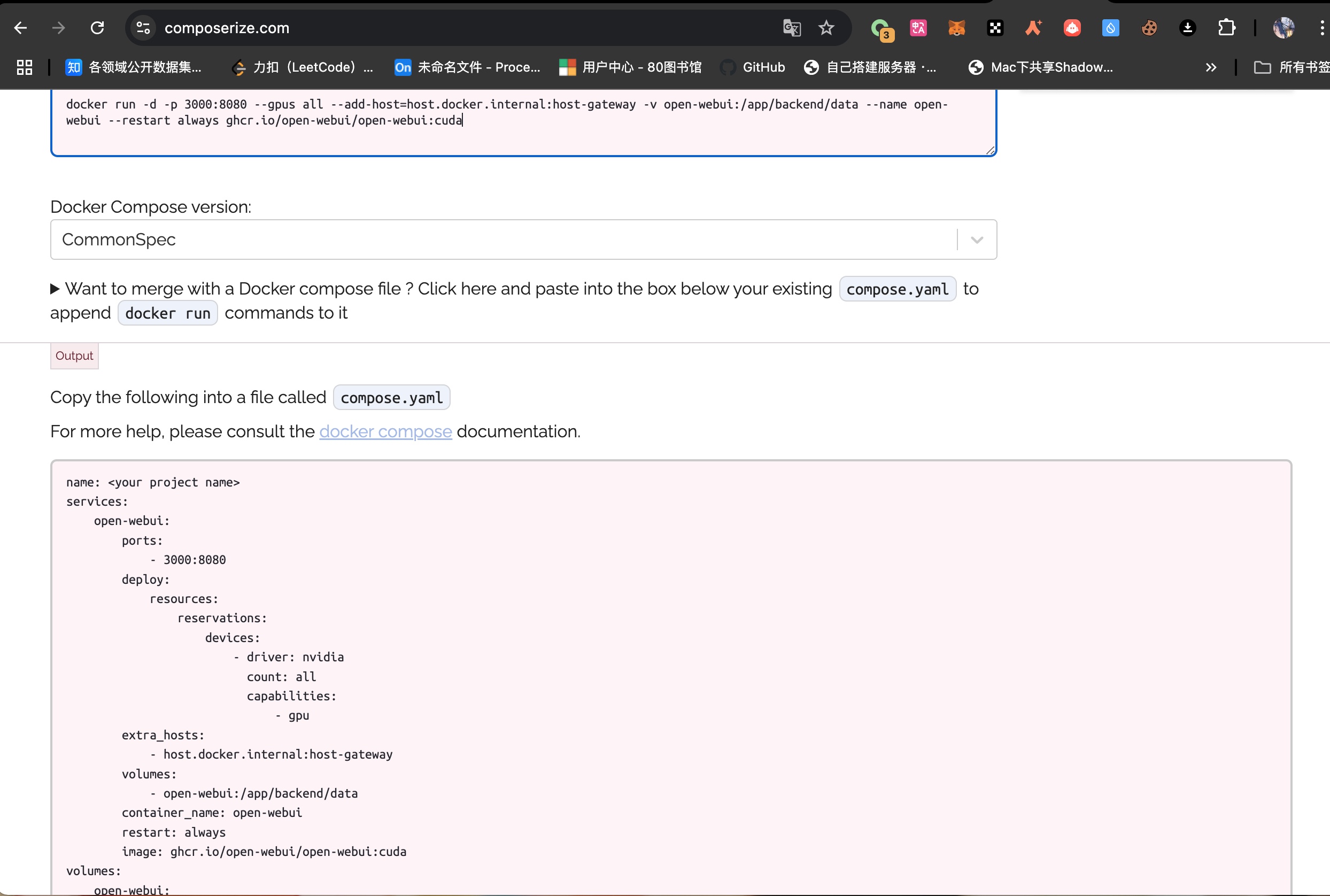
2.1、方案二:(ollama+open web UI+searxng+Nignx proxy manager) 前提也是在安装好ollama 的基础上进行的。https://github.com/open-webui/open-webui https://www.composerize.com/ https://www.bilibili.com/video/BV1MS9BYaEa5/?spm_id_from=333.337.search-card.all.click&vd_source=a07523372ea1438247b770c295f20822
先安装 【NVIDIA Container Toolkit NVIDIA容器工具包】https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
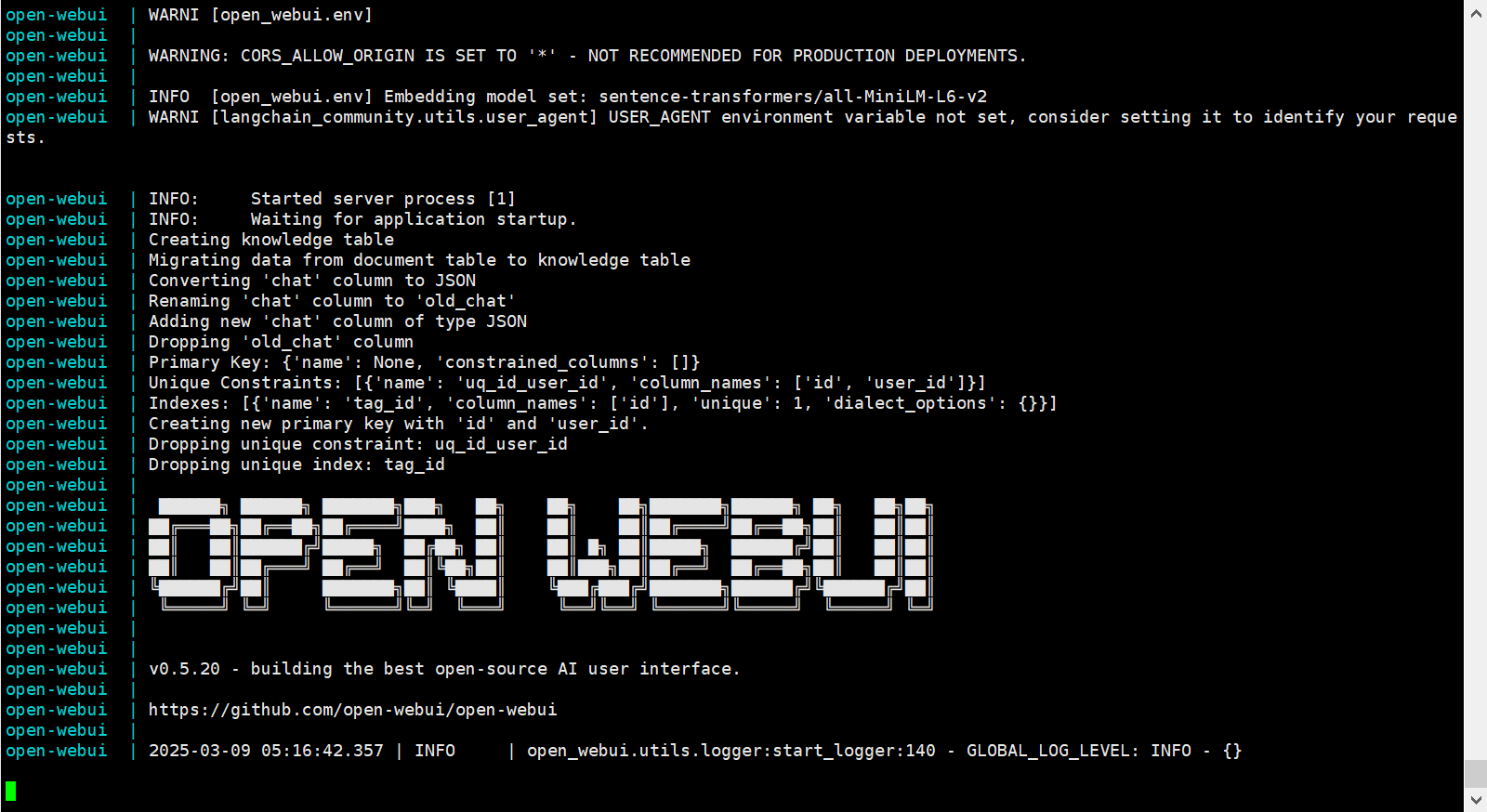
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 mkdir -p openwebuicd openwebui vim docker-compose.yml docker compose pull docker compose up -d docker compose logs -f --tail =100
docker-compose.yml截图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 name: <your project name> services: open-webui: ports: - 3000 :8080 deploy: resources: reservations: devices: - driver: nvidia count: all capabilities: - gpu extra_hosts: - host.docker.internal:host-gateway volumes: - open-webui:/app/backend/data container_name: open-webui restart: always image: ghcr.io/open-webui/open-webui:cuda volumes: open-webui: external: true name: open-webui
2.1.1、联网搜索部署成功案例 参考:
https://mp.weixin.qq.com/s/Fgwn9DYit65sw7ql1S3Pfw
2.1.1.1、配置searxng 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 mkdir -p /home/cys/docker_data/searxng/searxngcd /home/cys/docker_data/searxng/searxngvim settings.yml use_default_settings: true general: debug: true engines: - name: bing engine: bing shortcut: bi disabled: false - name: bilibili engine: bilibili shortcut: bil disabled: false - name: archlinuxwiki engine: archlinux disabled: true - name: duckduckgo engine: duckduckgo distabled: true - name: github engine: github shortcut: gh disabled: true - name: wikipedia engine: wikipedia disabled: true server: secret_key: "ultrasecretkkkkey" limiter: false image_proxy: true search: formats: - html - json ui: static_use_hash: true redis: url: redis://redis:6379/0 vim limiter.toml [botdetection.ip_limit] link_token = false cd /home/cys/docker_data/searxng/vim docker-compose.yml services: redis: container_name: redis image: hub.mirrorify.net/valkey/valkey:8-alpine command : valkey-server --save 301 --loglevel warning restart: unless-stopped networks: - searxng volumes: - valkey-data2:/data cap_drop: - ALL cap_add: - SETGID - SETUID - DAC_OVERRIDE logging: driver: "json-file" options: max-size: "1m" max-file: "1" searxng: container_name: searxng image: searxng/searxng:latest restart: unless-stopped networks: - searxng ports: - 8081:8080 volumes: - ./searxng:/etc/searxng:rw environment: - SEARXNG_BASE_URL=http://10.5.9.252:8081 - UWSGI_WORKERS=${SEARXNG_UWSGI_WORKERS:-4} - UWSGI_THREADS=${SEARXNG_UWSGI_THREADS:-4} cap_drop: - ALL cap_add: - CHOWN - SETGID - SETUID logging: driver: "json-file" options: max-size: "1m" max-file: "1" networks: searxng: volumes: valkey-data2: docker compose down sudo docker compose up -d sudo docker compose up
redis 服务中的 volumes,searxng 服务中的 volumes,以searxng为例。作用: 将宿主机当前目录下的 ./searxng 文件夹挂载到 searxng 容器内部的 /etc/searxng 目录,并以读写模式(rw)挂载。意义: 这样可以直接在宿主机上编辑 searxng 的配置文件(比如 settings.yml 等),容器内会自动同步更新,从而方便管理和调试。
最底部的 volumes 部分
作用: 在 Compose 文件的顶层声明一个名为 valkey-data2 的命名卷。意义: 这告诉 Docker Compose,这个卷由 Docker 管理,用于持久化存储。服务(比如 redis)在使用挂载时会自动关联到这个已声明的卷。valkey-data2 的卷,Docker 会自动为它分配一个默认的存储位置(在 Linux 上通常是 /var/lib/docker/volumes/valkey-data2/_data 也可能有服务作为前缀)。
容器内的映射位置不是在这里指定的,而是在各个服务的 volumes 挂载时确定的。
浏览器中访问 http://10.5.9.252 的8081端口即可访问网页版本的searxng。
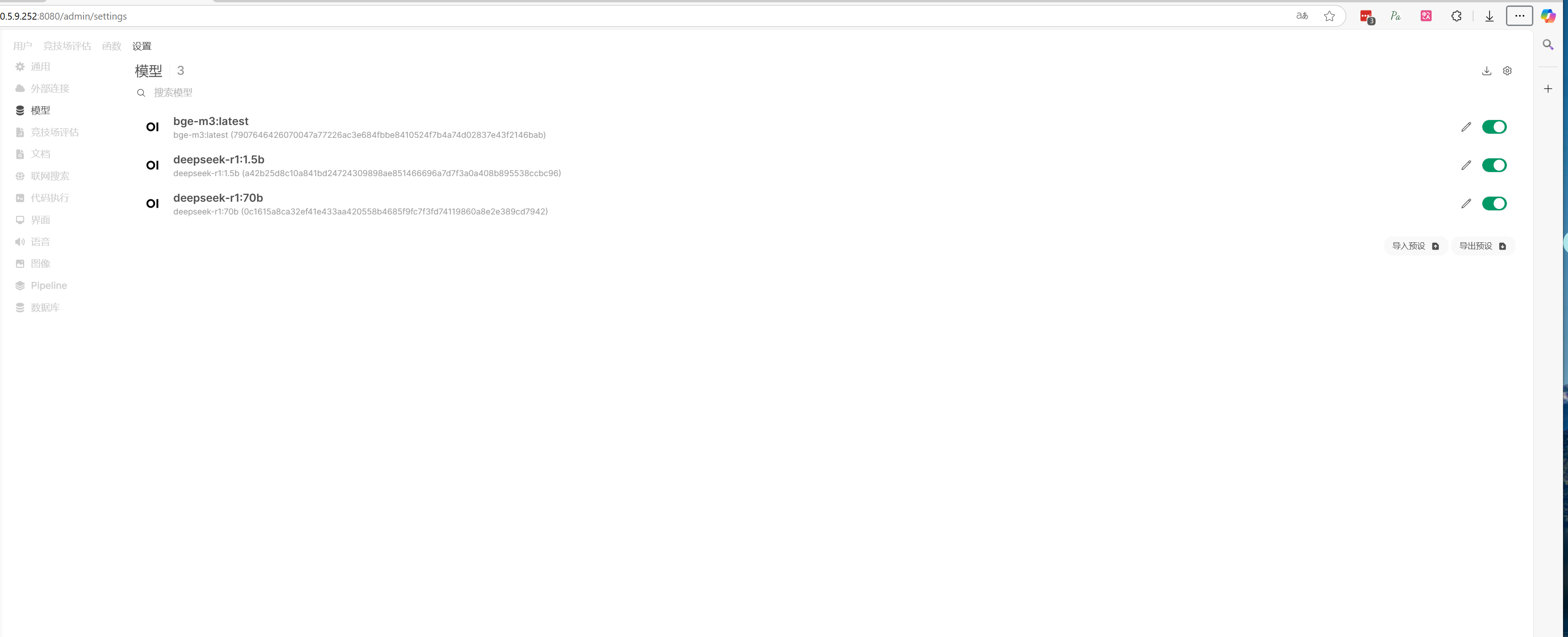
2.1.1.2、安装配置 open webUI 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 ollama pull bge-m3 mkdir -p /home/cys/docker_data/openwebui2cd /home/cys/docker_data/openwebui2vim docker-compose.yml services: open-webui: image: ghcr.io/open-webui/open-webui:cuda environment: - GLOBAL_LOG_LEVEL=DEBUG - OLLAMA_API_BASE_URL=http://10.5.9.252:11434 - HF_ENDPOINT=https://hf-mirror.com - ENABLE_OPENAI_API=false - OPENAI_API_BASE_URL=https://api.openai.com/v1 - CORS_ALLOW_ORIGIN=* - RAG_EMBEDDING_MODEL=bge-m3 - DEFAULT_MODELS=deepseek-r1:70b - ENABLE_OAUTH_SIGNUP=true ports: - 8080:8080 volumes: - ./open_webui_data:/app/backend/data docker compose down sudo docker compose up -d sudo docker compose up
2.1.1.3、网页中配置
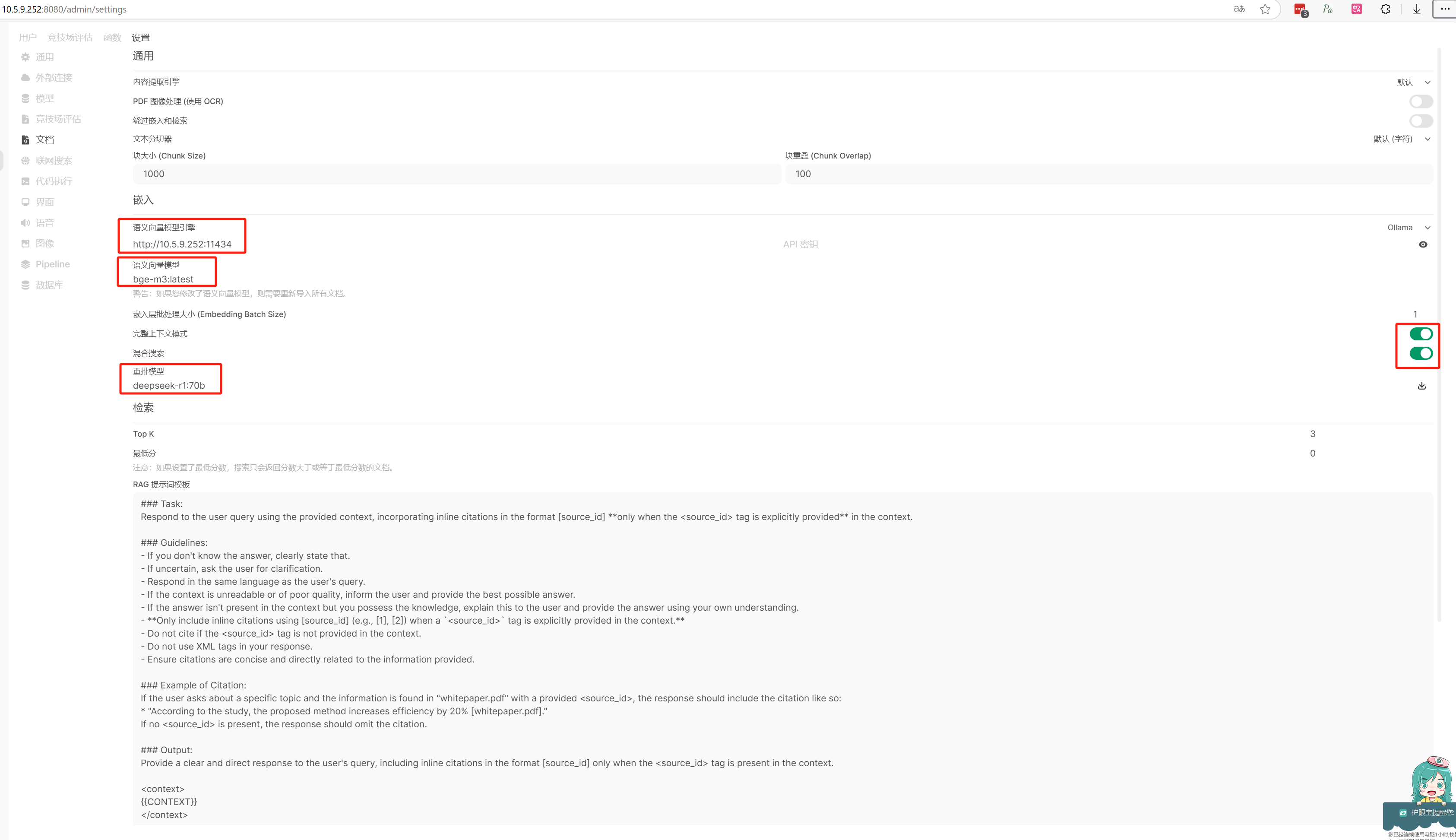
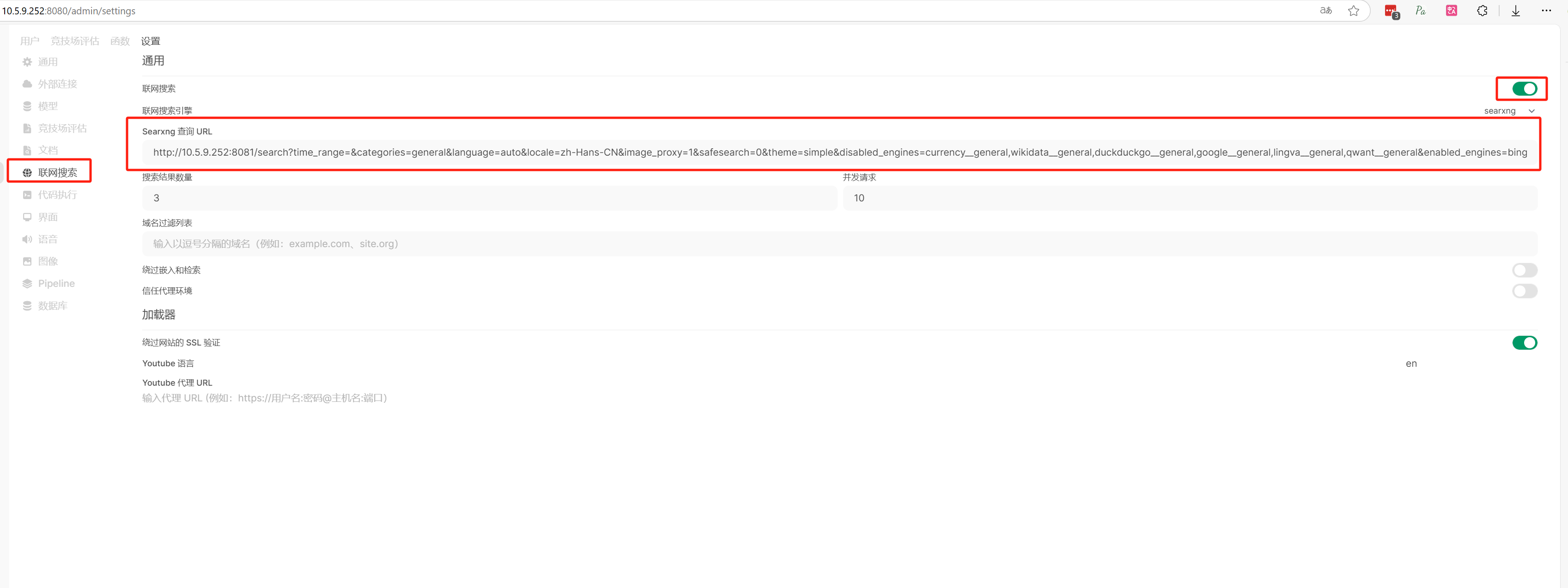
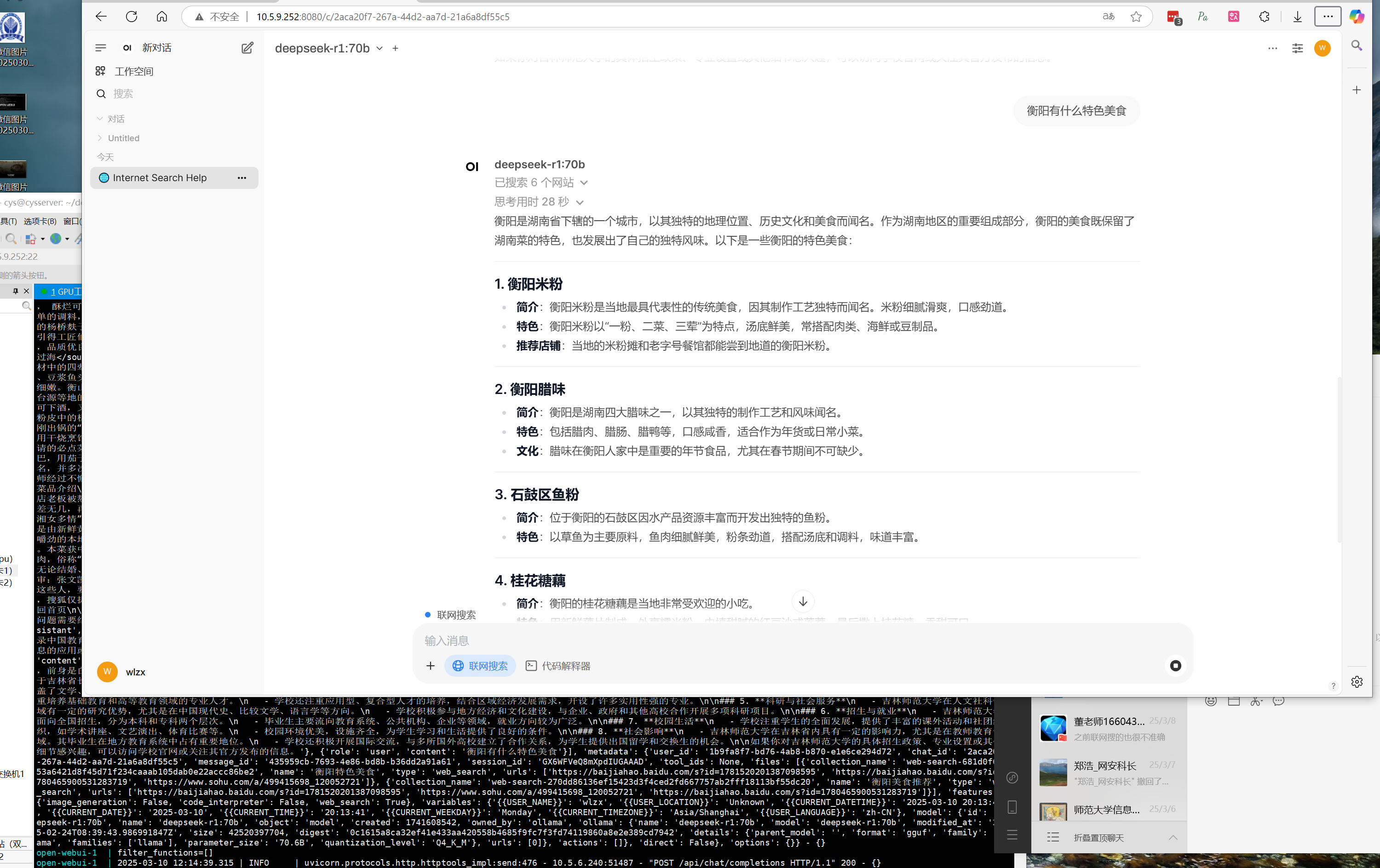
在配置【Searxng 查询 URL】
1 http://10.5.9.252:8081/search?time_range=&categories=general&language=auto&locale=zh-Hans-CN&image_proxy=1&safesearch=0&theme=simple&disabled_engines=currency__general,wikidata__general,duckduckgo__general,google__general,lingva__general,qwant__general&enabled_engines=bing__general,brave__general
可查看如下地址中 Open-WebUI 接入 SearXNG 的实现源码了解其具体逻辑:
https://github.com/open-webui/open-webui/blob/main/backend/open_webui/retrieval/web/searxng.py
效果图如下:
效果并不好,经常会出现搜不到的情况。
2.1.2、补充说明部分 2.1.2.1、本地数据映射、迁移 1 2 3 4 5 6 7 8 9 10 11 12 13 services: redis: volumes: - valkey-data2:/data searxng: volumes: - ./searxng:/etc/searxng:rw networks: searxng: volumes: valkey-data2:
以前面配置 searxng 为例作用: 将宿主机当前目录下的 ./searxng 文件夹挂载到 searxng 容器内部的 /etc/searxng 目录,并以读写模式(rw)挂载。意义: 这样可以直接在宿主机上编辑 searxng 的配置文件(比如 settings.yml 等),容器内会自动同步更新,从而方便管理和调试。
最底部的 volumes 部分
作用: 在 Compose 文件的顶层声明一个名为 valkey-data2 的命名卷(没有指定映射到容器中的某个位置)。意义: 这告诉 Docker Compose,这个卷由 Docker 管理,用于持久化存储。服务(比如 redis)在使用挂载时会自动关联到这个已声明的卷。valkey-data2 的卷,Docker 会自动为它分配一个默认的存储位置(在 Linux 上通常是 /var/lib/docker/volumes/valkey-data2/_data 也可能有服务作为前缀)。
容器内的映射位置不是在这里指定的,而是在各个服务的 volumes 挂载时确定的。
命名卷 valkey-data2 挂载到 redis 容器内的 /data 目录。也就是说,redis 在 /data 下写入的数据都会存储到这个命名卷中。
如果服务运行很久产生大量数据,这些数据会写入到容器中被映射的目录(比如 redis 的 /data),而最终存放在宿主机上对应命名卷的默认位置(如 /var/lib/docker/volumes/valkey-data2/_data)。
如果你想自定义宿主机上的存储位置(例如改为 /data/docker-data/sear),你不能在顶层的 volumes 声明里直接指定宿主机目录,而是需要在服务的 volumes 映射中使用绑定挂载的方式。例如,对于 searxng 服务,如果原来是这样写:
1 2 3 4 5 volumes: - ./searxng:/etc/searxng:rw volumes: - valkey-data2:/data
你可以修改为:
1 2 3 4 5 volumes: - /data/docker-data/sear:/etc/searxng:rw volumes: - /data/docker-data/redis:/data
这样,容器中 /etc/searxng 的所有数据就会直接存储在宿主机的 /data/docker-data/sear 目录中,而不再使用默认的 ./searxng 目录。(需要提前有这个文件夹且权限打开)注意:radis要频繁 IO 操作,不建议修改位置到别的磁盘。
把原来的 文件夹 cp 过去,然后 在改yaml 文件,重新 docker compose up -d ,可以迁移了,如果还是不成功,可以在docker logs 【容器名/id】 看看日志提示。
2.1.2.2、日志 日志文件默认存储在宿主机的 /var/lib/docker/containers/<container-id>/ 目录中。与容器共存亡 。当容器被删除(如执行 docker compose down)后,其日志文件也会被清理。
如果希望将日志文件存储在特定的宿主机目录中,您可以使用 Docker 的 local 日志驱动程序,并指定 log-path。
请注意,直接将 Redis 的日志输出到文件可能会影响性能,不建议。
1 2 3 4 5 6 7 8 9 10 services: open-webui: logging: driver: "json-file" options: max-size: "10m" max-file: "3" volumes: - ./open_webui_data:/app/backend/data
2.1.2.3、改换嵌入模型 见 目录《思路二:vllm部署Deepseek》
2.1.2.4、RAG 点击工作空间;点击“知识库”选项;传好文件;再点击模型;在编辑中选择关联上哪些知识库即可。
2.1.2.5、自建searxng搜索引擎插件实现微信搜索 要读源码自己仿写,暂时没写,难度不大。
2.1.2.6、让用户能够自己注册
四、思路二:vllm部署Deepseek 1、方案:(vllm+open web UI+searxng+Nignx proxy manager) 1.1、modelscope本地下载大模型 国内用modelscope本地下载大模型,为vllm调用作铺垫。
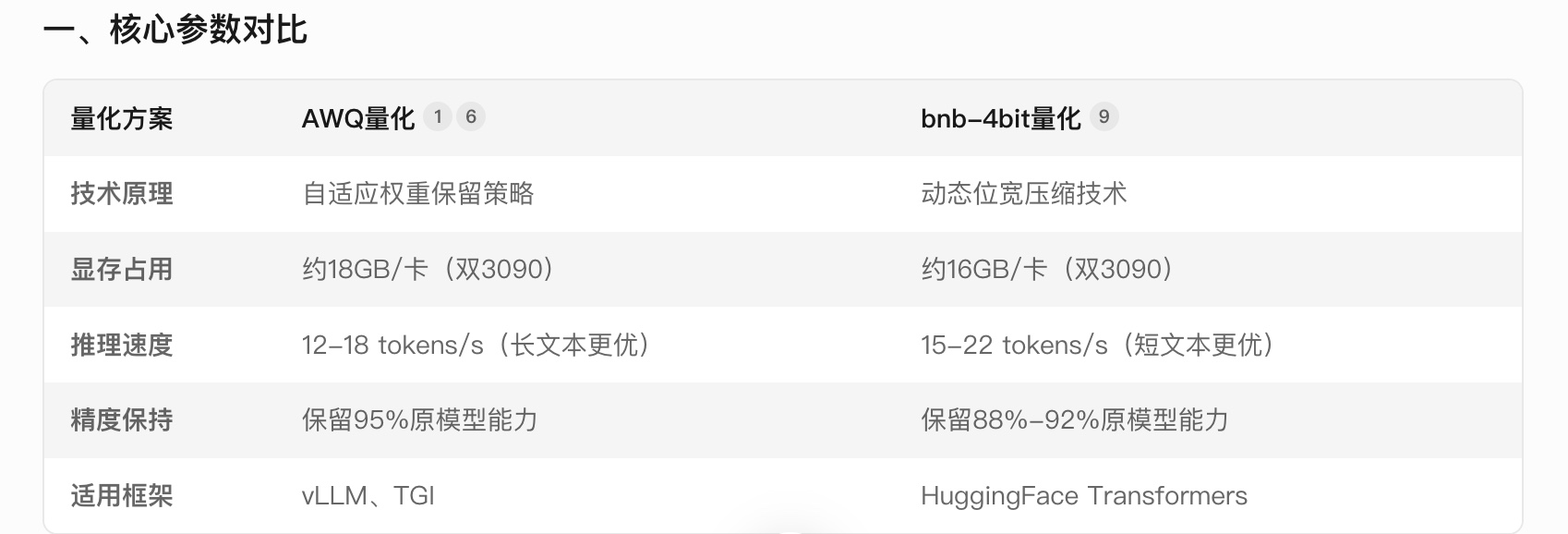
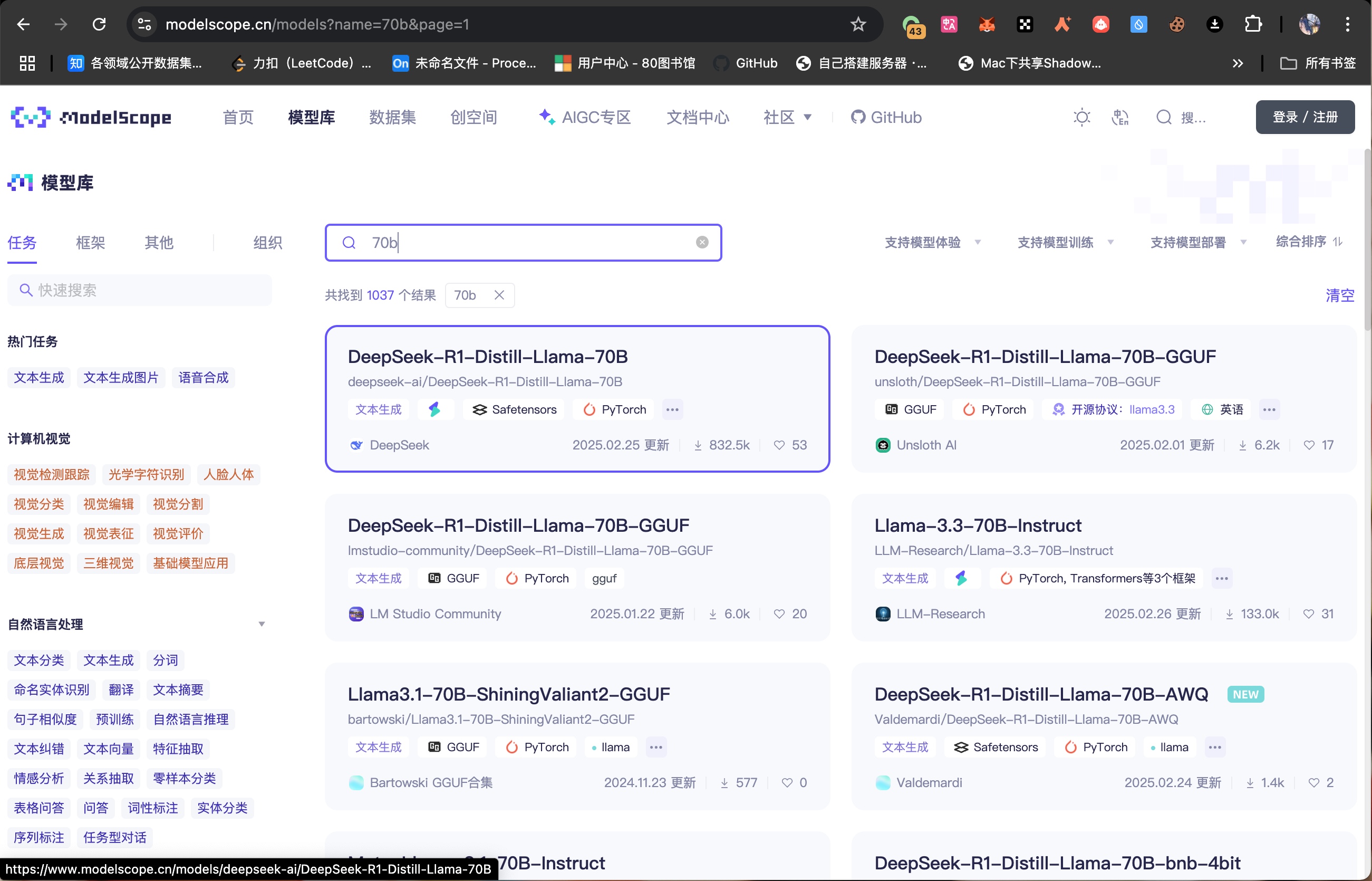
https://www.modelscope.cn/models/ 注意 :如果多GPU需下载 DeepSeek-R1-70B-AWQ 分片版模型(支持张量并行),以下只是演示没有选AWQ版本。
推荐使用modelscope 下载到指定位置。
1.2、vllm部署 1.2.1、vllm单机多卡部署 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 mkdir -p /home/cys/docker_data/vLLMcd /home/cys/docker_data/vLLMvim hello.cu __global__ void hello printf ("Hello from GPU!\n" ); } int main hello<<<1,1 >>>(); cudaDeviceSynchronize(); return 0; } nvcc --version nvcc -o hello hello.cu -arch =sm_86 && ./hello docker network create vllm-network vim docker-compose.yml services: vllm-openai: runtime: nvidia restart: unless-stopped container_name: deepseek-container ipc: host image: vllm/vllm-openai:latest volumes: - /home/cys/data/models/deepseek-r1-70b-AWQ:/models/deepseek-r1-70b:ro command : - "--model=/models/deepseek-r1-70b" - "--tensor_parallel_size=2" - "--pipeline_parallel_size=1" - "--gpu_memory_utilization=0.95" - "--max_model_len=8192" - "--served-model-name=deepseek-r1-70b-AWQ" - "--dtype=half" - "--api-key=jisudf*&QW123" - "--swap_space=8" environment: - CUDA_VISIBLE_DEVICES=0,1 - PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True - NCCL_DEBUG=INFO ports: - "8000:8000" deploy: resources: reservations: devices: - driver: nvidia count: 2 capabilities: [gpu] networks: - my-network logging: driver: json-file options: max-size: "100m" max-file: "3" networks: my-network: external: true name: vllm-network docker compose up -d docker logs deepseek-container
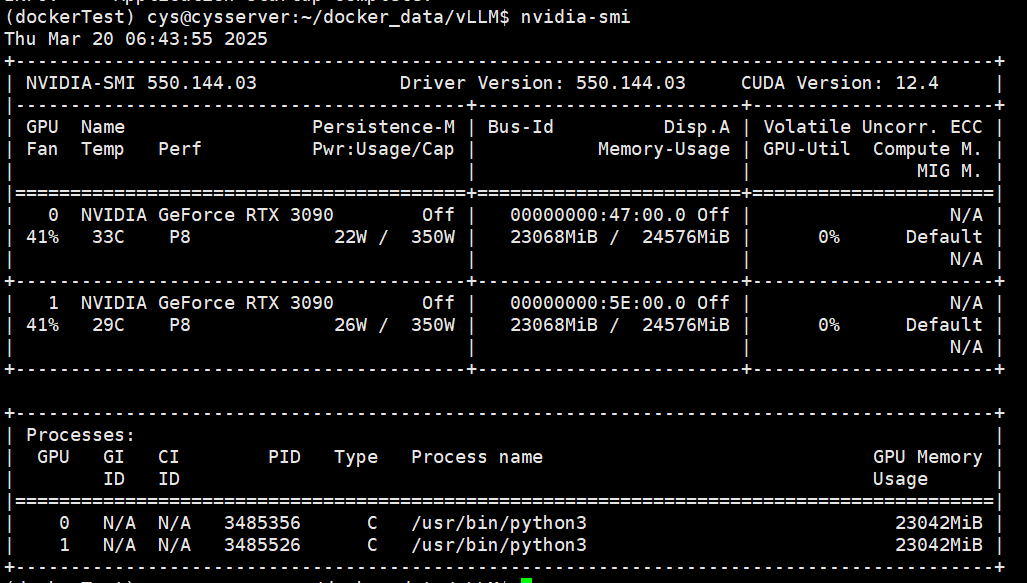
显卡跑起来了,看见 显存被搞起来了,说明调用成功。
1.2.2、vllm多机多卡部署 参考:
https://docs.vllm.ai/en/latest/serving/distributed_serving.html
https://mp.weixin.qq.com/s/tdubYmXNt98ZN6SB7iMIrw
先在另一台机器中安装好和第一台机器一样的 环境(推荐docker 搞),当从节点。
从第一台机器(主节点)中把模型复制过来。
下载一个vllm 官方的脚本(cluster启动脚本)。
1 wget https://github.com/vllm-project/vllm/blob/main/examples/online_serving/run_cluster.sh
1.2.2.1、选项一:通过swarm部署 Docker Swarm 集群基础 参考:https://www.bilibili.com/video/BV1ZM4m1Z75k/?spm_id_from=333.337.search-card.all.click&vd_source=a07523372ea1438247b770c295f20822
docker swarm 和 docker compose一样都是为了简化 容器化程序的部署、管理和扩展的工具。
docker compose 单机上用而已。
docker swarm 集群用。
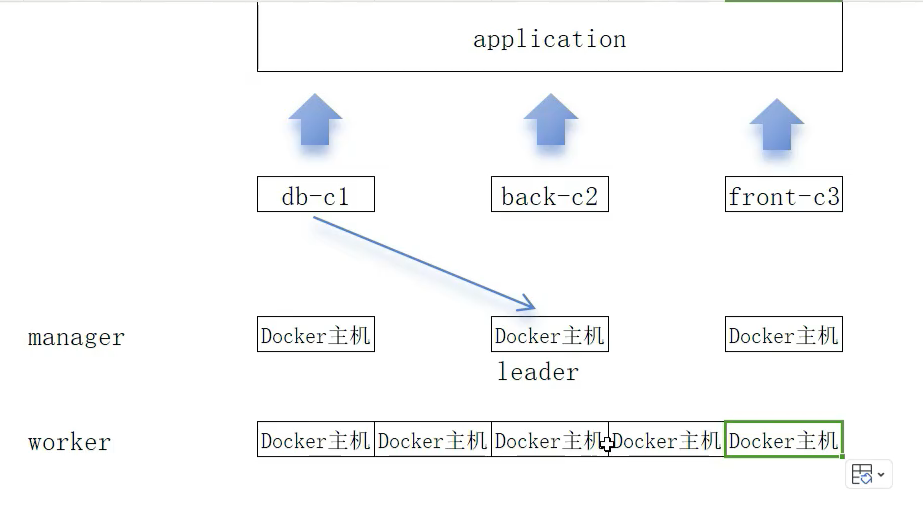
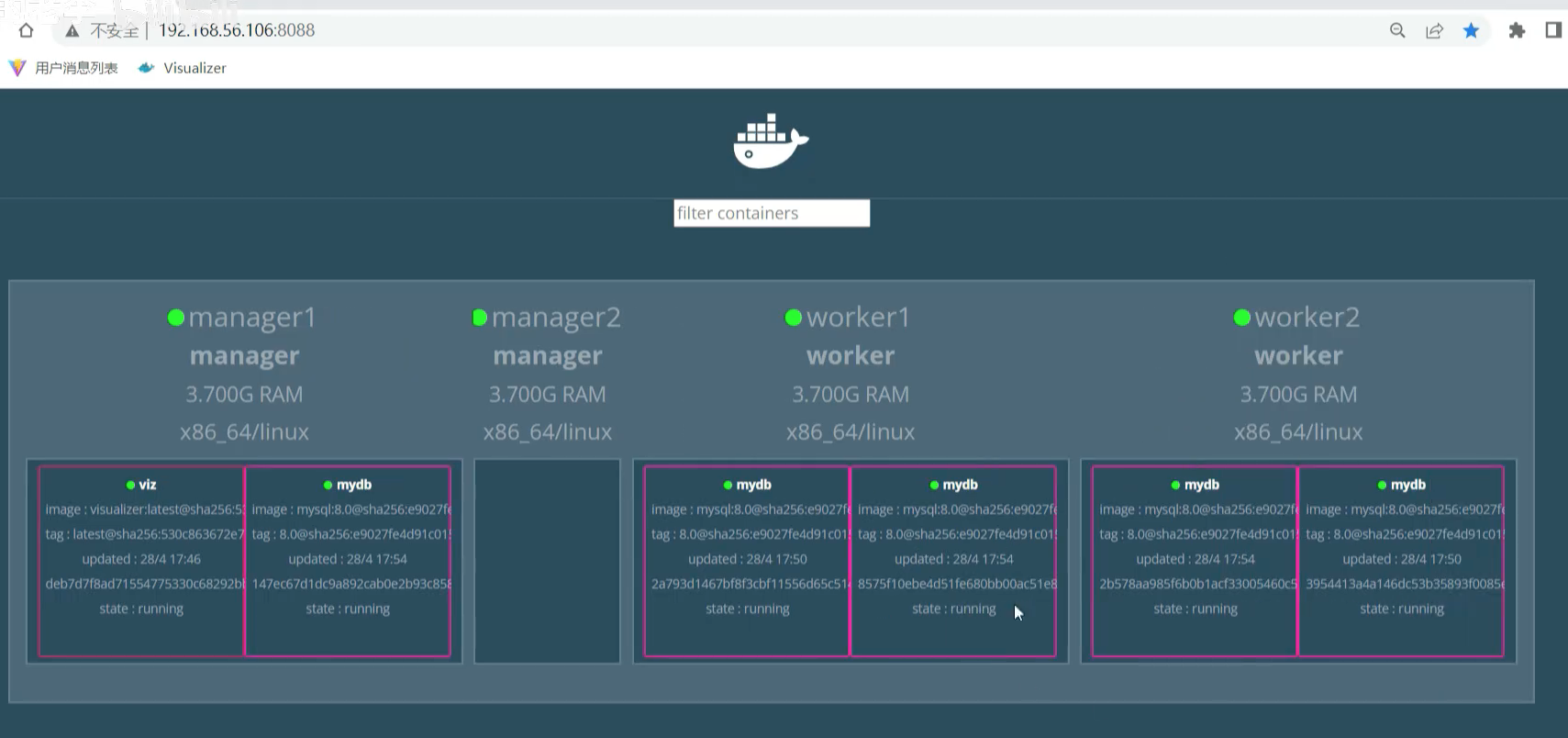
下面的例子 是 两个 manager 节点 两个 worker 节点 组成的4个 node 的 swarm集群例子。
· 初始化集群: · 加入节点:
docker node ls 查看 有哪些节点。
· 集群解散:
· 节点管理:
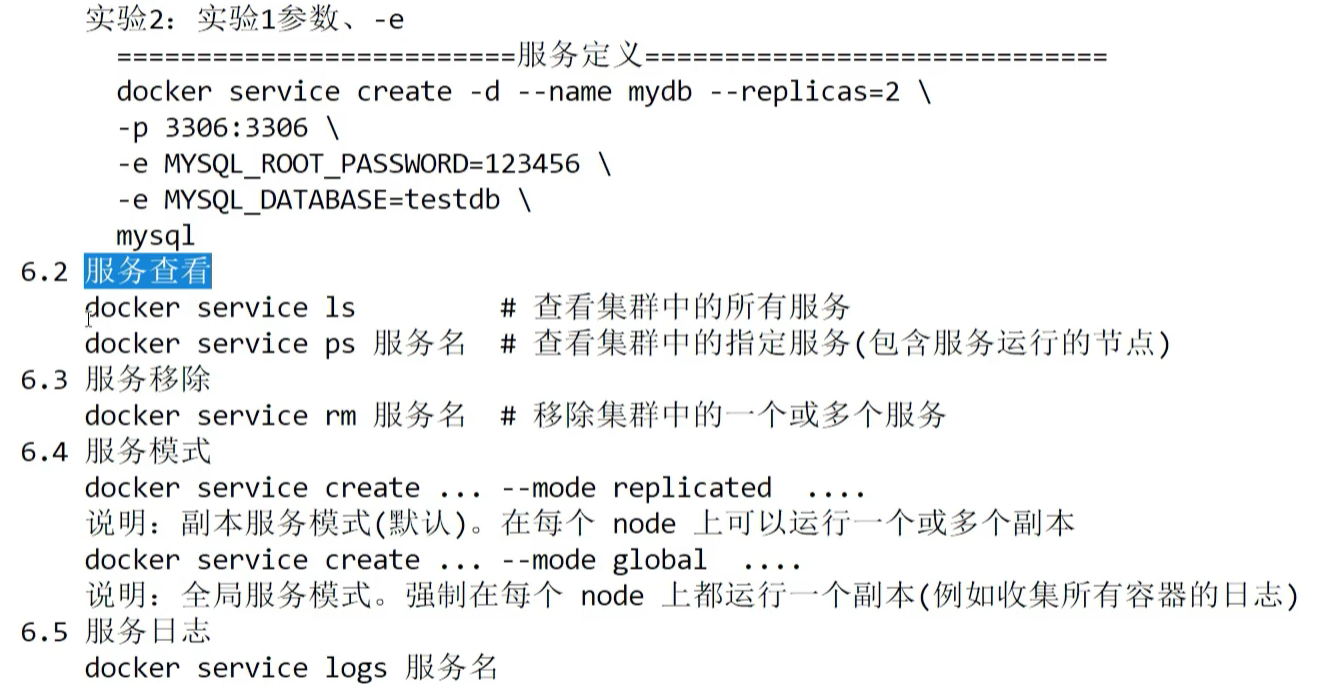
· 服务管理:
replicas 是 2 说明 搞了两个副本容器在集群中,但是具体分配给了哪两个节点 由调度策略来决定,注意一共就是 两个容器 ,副本的意思不是 说再复制出2个一共3个,别误会了。
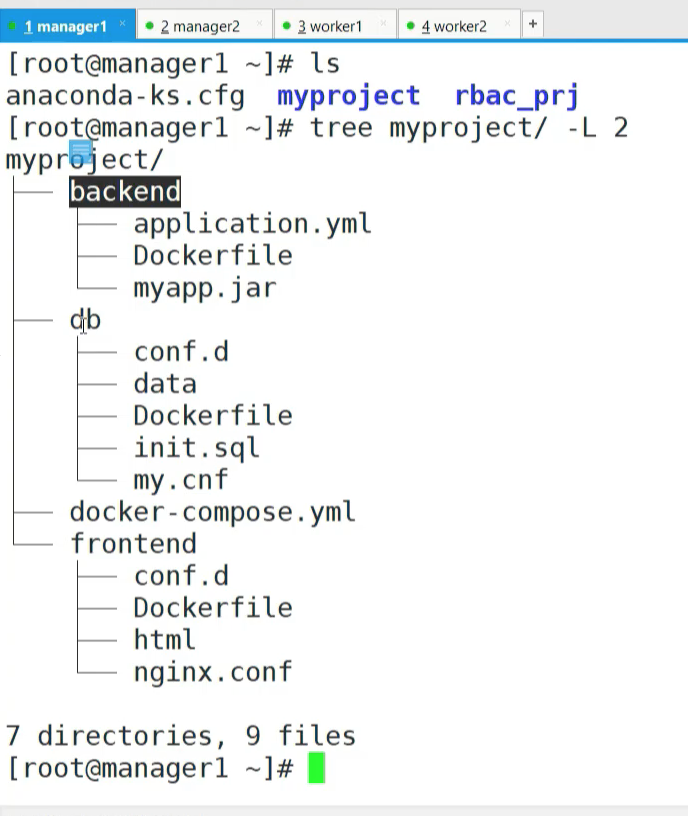
source 是 宿主机的映射目录,target是 容器内部的 目录,用bing直接映射挂载。
docker service ls 看见 属性中的 replicas 2/2 3/3 1/1 5/5 前后数字一致 说明有2个replicas副本,有2个成功运行,以此类推。前后不一致说明没有正常运行。
服务定义好以后,是在集群中的全部 node 都能访问的,但是容器并不是在每一个节点中运行,仅仅是在调度分配的节点中运行。
· swarm集群弹性伸缩:
· swarm集群服务滚动更新:
1 2 3 4 5 docker service update --replicas=5 --image mysql:8.0 --update-delay 60s --update-parallelism 5 mydb
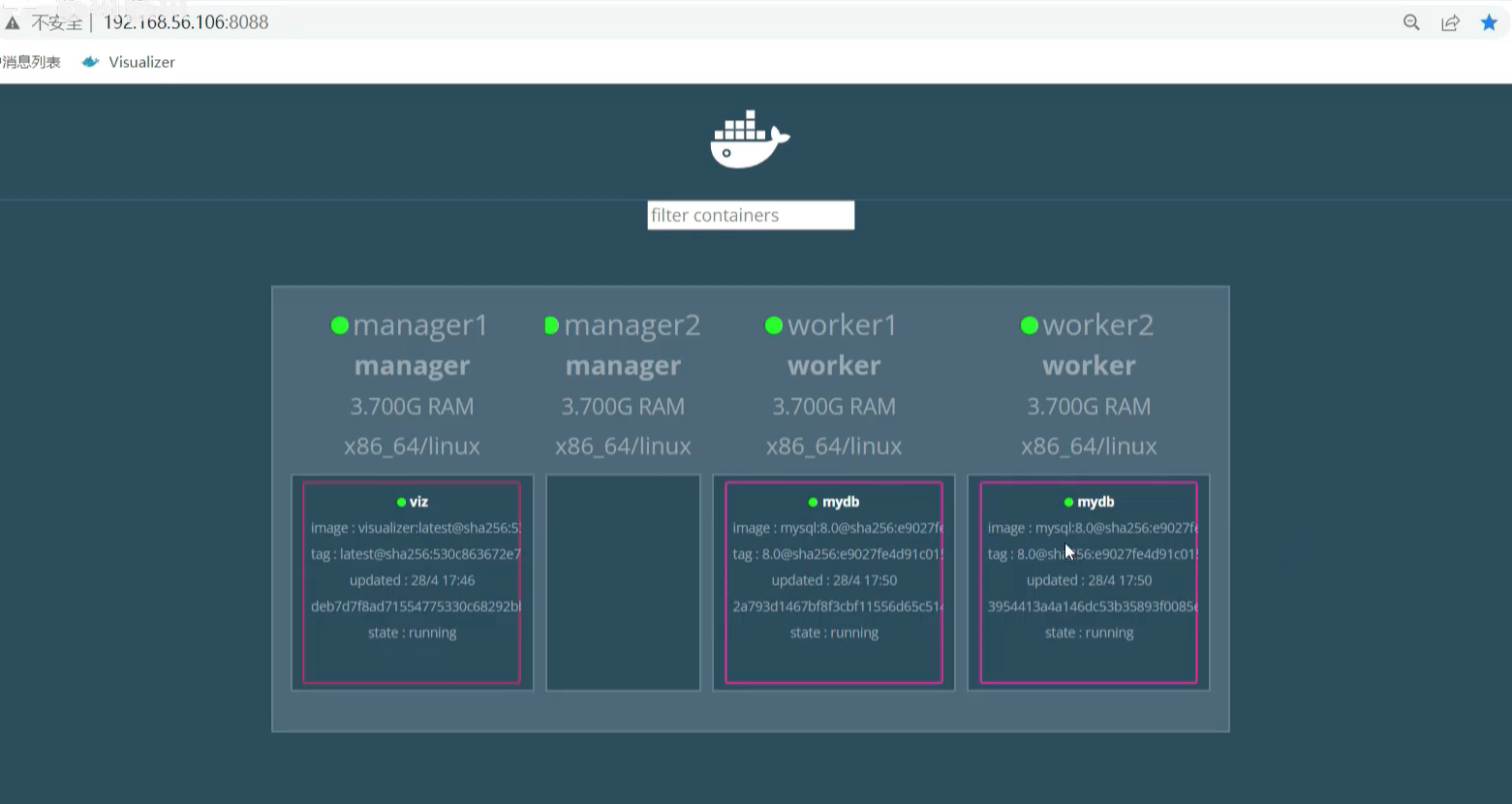
60秒后 4个node 中出现了5个更新到 mysql8.0的服务容器。
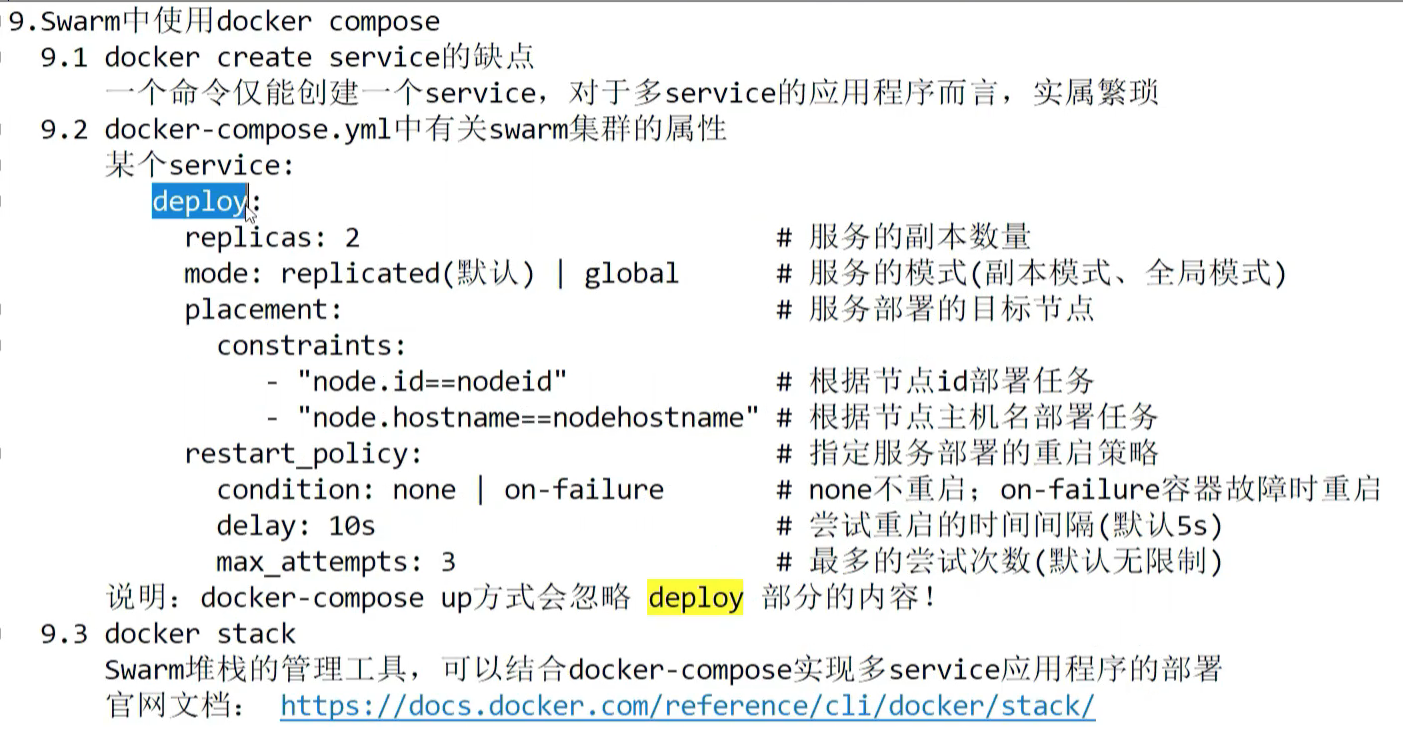
· swarm集群中使用docker compose:
可以把 这么多个副本全部落到指定的node 节点中。
docker compose up 是单机启动方式,会忽略 deploy 内容。
1 docker stack deploy -c yml文件名 自定义stack名
docker swarm 中不支持 name 属性的定义
docker swarm 和 k8s 是竞争关系,但是 docker swarm 没有竞争过k8s,但是docker swarm依然有它的意义。
具体操作 在 Docker Swarm 的集群架构中,所有 YAML 文件都需要在主节点上运行 。
· docker swarm GPU支持 参考 https://gist.github.com/coltonbh/374c415517dbeb4a6aa92f462b9eb287
对主从节点每一台机器作如下操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 nvidia-smi -a sudo vim /etc/docker/daemon.json ------------------------------------ daemon.json ------------------------------------ { "registry-mirrors" : [ "https://docker.m.daocloud.io" , "https://mirror.ccs.tencentyun.com" , "https://func.ink" , "https://proxy.1panel.live" , "https://docker.zhai.cm" ], "default-runtime" : "nvidia" , "runtimes" : { "nvidia" : { "path" : "nvidia-container-runtime" , "runtimeArgs" : [] } }, "node-generic-resources" : [ "NVIDIA-GPU=GPU-c8fcc40e-7aef-0401-1519-2e8b2ef1521b" , "NVIDIA-GPU=GPU-a27b8ea5-b0bf-3a21-90ff-e9417f58ff11" ] } ------------------------------------ daemon.json ------------------------------------
在主节点机器中 编辑 vllm-head.yml vllm-worker1.yml vllm-worker1.yml 等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 vim vllm-head.yml services: vllm-head: image: vllm/vllm-openai:latest restart: unless-stopped command : - "--head" - "--model=/models/deepseek-r1-70b" - "--tensor_parallel_size=2" - "--pipeline_parallel_size=2" - "--served-model-name=deepseek-r1-70b-AWQ" - "--max-model-len=8192" - volumes: - /home/cys/data/models/deepseek-r1-70b-AWQ:/models/deepseek-r1-70b-AWQ:ro environment: - CUDA_VISIBLE_DEVICES=0,1 - VLLM_HOST_IP=10.5.9.252 - RAY_HEAD_IP=10.5.9.252 - RAY_HEAD_PORT=6379 - NCCL_SOCKET_IFNAME=enp1s0 ports: - "8000:8000" - "6379:6379" networks: vllm-cluster: ipv4_address: 10.10.0.100 deploy: placement: constraints: - node.hostname == cysserver resources: reservations: generic_resources: - discrete_resource_spec: kind: "nvidia-gpu" value: 2 networks: vllm-cluster: driver: overlay ipam: config: - subnet: 10.10.0.0/24
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 vim vllm-worker.yml services: vllm-worker: runtime: nvidia image: vllm/vllm-openai:latest restart: unless-stopped command : - "--worker" - "--model=/models/deepseek-r1-70b" volumes: - /home/cys/models/deepseek-r1-70b-AWQ:/models/deepseek-r1-70b:ro environment: - CUDA_VISIBLE_DEVICES=1 - RAY_HEAD_IP=10.5.9.252:6379 - NCCL_SOCKET_IFNAME=eno1 networks: vllm-cluster: ipv4_address: 10.10.0.101 deploy: placement: constraints: - node.hostname == cys networks: vllm-cluster: external: true name: vllm-cluster
加标签,yml 文件中有通过标签 指定服务具体落在的哪个节点。
1 2 docker node update --label-add node.hostname=cys cys docker node update --label-add node.hostname=cysserver cysserver
在主节点机器上 作 swarm 初始化,然后在各个从节点 以worker身份加入 warm 集群。
具体操作 参考 什么的Docker Swarm基础。
问题: 通过 docker swarm 集群部署的 大模型,并没有实现 对算力资源的 汇总,而仅仅是像一个普通的分布式应用一样选择把服务部署在哪一个节点中运行,顶多只是 这个节点坏了,有一个 新节点 补充 类似这样。
如果每一个节点的GPU 资源都不足以部署此大模型, 那这样的 docker swarm 集群部署 大模型无法成功,所以这种 集群分布式部署不是我们要的 方式。
那我们应该用哪一种 分布式的部署方式呢?
答案就在vllm 的官网中,其实 下载 vllm github 中的 分布式部署脚本,可以用它自带的ray 集群实现对资源的整合调度。
1.2.2.2、选项二:通过 ray 集群部署 参考:https://docs.vllm.ai/en/latest/serving/distributed_serving.html https://mp.weixin.qq.com/s/fflQZOcNCAcltpzm6hB7AA
https://mp.weixin.qq.com/s/tdubYmXNt98ZN6SB7iMIrw
上面的swarm集群部署解决不了资源整合的 问题导致了单个节点资源不足就无法在这个节点部署服务。
为了解决此问题,我们用vllm 推荐的 分布式部署方式。(我在swarm 集群部署上面绕了一个好大的弯,以后都优先使用官网推荐的最佳实践,不要自己折腾,费劲不讨好。)
下载官方多节点脚本到本地
1 2 3 4 5 cd /home/cys/docker_data/vLLMwget https://github.com/vllm-project/vllm/raw/main/examples/online_serving/run_cluster.sh
部署ray集群
主节点10.5.9.252
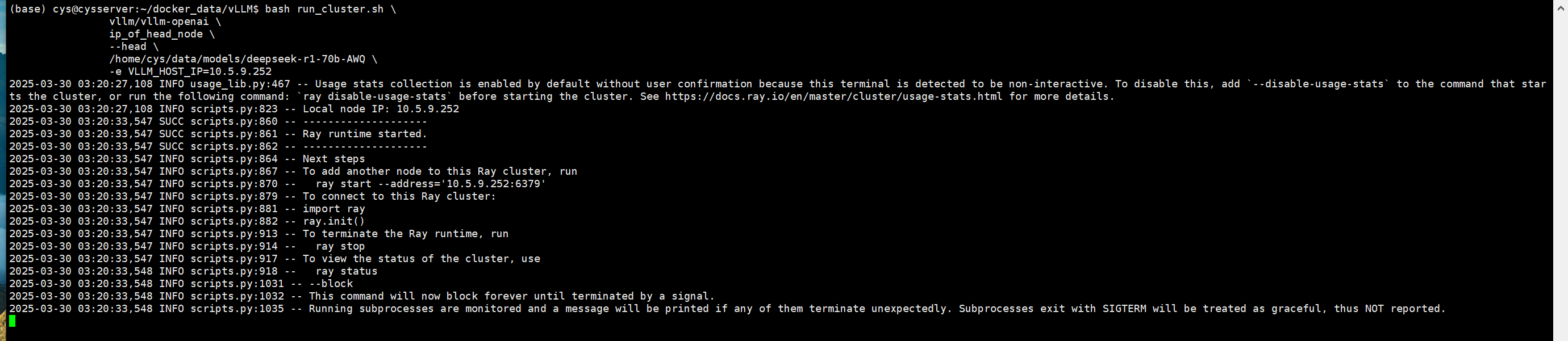
1 2 3 4 5 6 7 8 9 bash run_cluster.sh \ vllm/vllm-openai \ 10.5.9.252 \ --head \ /home/cys/data/models/deepseek-r1-70b-AWQ \ -v /home/cys/data/models/deepseek-r1-70b-AWQ/:/model/deepseek-r1-70b-AWQ/ \ -e VLLM_HOST_IP=10.5.9.252 \ -e GLOO_SOCKET_IFNAME=enp1s0 \ -e NCCL_SOCKET_IFNAME=enp1s0
enp1s0 是 看ip 走那个网口 得出的
此时再开一个窗口,进入主节点的容器中查看ray 集群。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 docker exec -it f474c557b8a6 /bin/bash root@cysserver:/vllm-workspace ======== Autoscaler status: 2025-03-30 03:27:55.102175 ======== Node status --------------------------------------------------------------- Active: 1 node_8e51bfc57e87e7c4c7c44817444eabd64c1b2fd109e67d065110c5a1 Pending: (no pending nodes) Recent failures: (no failures) Resources --------------------------------------------------------------- Usage: 0.0/24.0 CPU 0.0/2.0 GPU 0B/484.01GiB memory 0B/9.73GiB object_store_memory Demands: (no resource demands)
从节点10.5.9.253
1 2 3 4 5 6 7 8 9 bash run_cluster.sh \ vllm/vllm-openai \ 10.5.9.252 \ --worker \ /home/cys/models/deepseek-r1-70b-AWQ \ -v /home/cys/models/deepseek-r1-70b-AWQ/:/model/deepseek-r1-70b-AWQ/ \ -e VLLM_HOST_IP=10.5.9.253 \ -e GLOO_SOCKET_IFNAME=eno1 \ -e NCCL_SOCKET_IFNAME=eno1
eno1 是 看ip 走那个网口 得出的
此时再开一个窗口,进入主节点的容器中查看ray 集群。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 docker exec -it f474c557b8a6 /bin/bash root@cysserver:/vllm-workspace ======== Autoscaler status: 2025-03-30 11:21:02.211262 ======== Node status --------------------------------------------------------------- Active: 1 node_921f86c035112492b0daccabd0f373361ea3a721370c3cbcc1dc32ea 1 node_4260699a5c1bfdf24d9a886b7aec5e38b7f5e42ab38a2427c13e8366 Pending: (no pending nodes) Recent failures: (no failures) Resources --------------------------------------------------------------- Usage: 0.0/48.0 CPU 0.0/4.0 GPU 0B/725.54GiB memory 0B/19.46GiB object_store_memory Demands: (no resource demands)
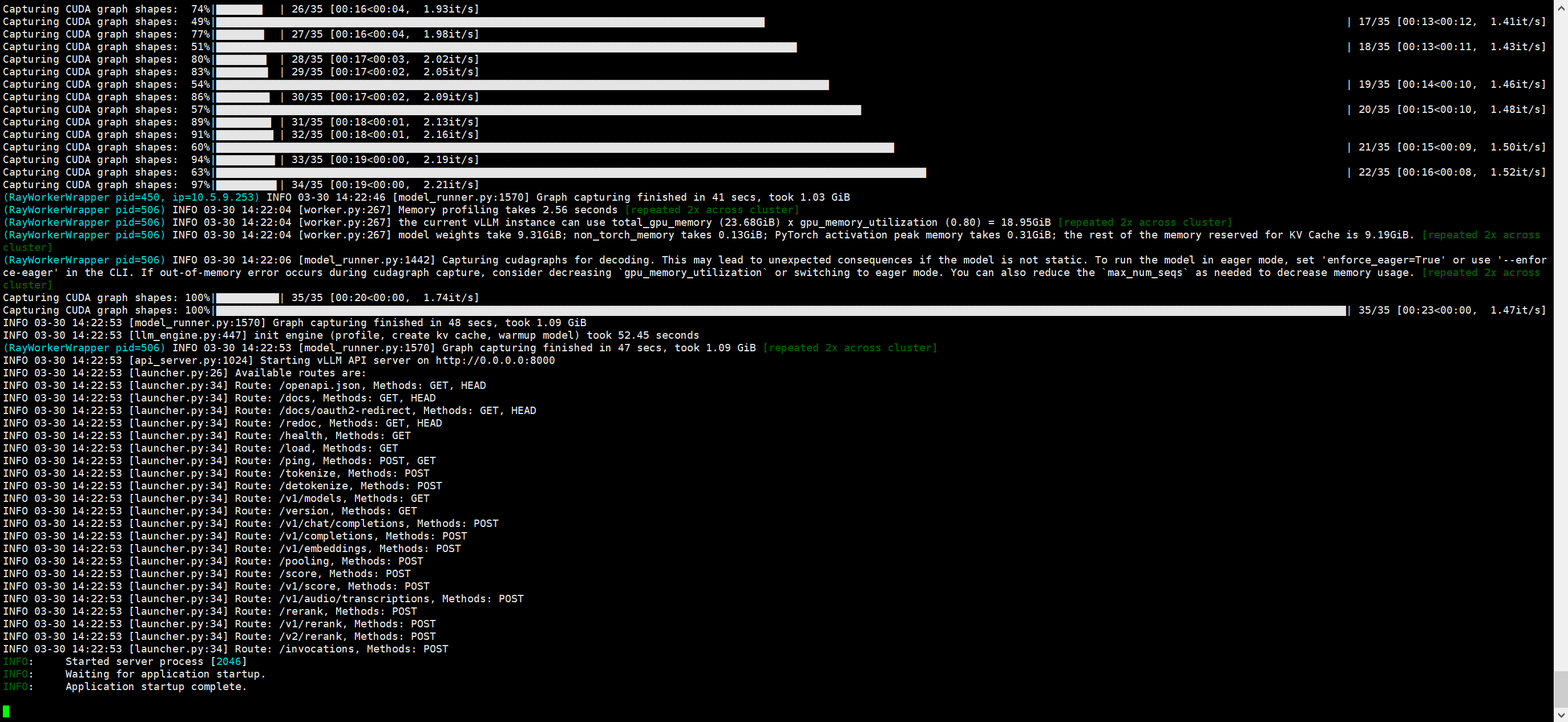
在ray集群部署好之后可以看见,在一台机器上可以调用整个集群的资源了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 docker exec -it f474c557b8a6 /bin/bash vllm serve /model/deepseek-r1-70b-AWQ \ --tensor-parallel-size 2 \ --pipeline-parallel-size 2 \ --max-model-len 53520 \ --gpu-memory-utilization 0.8 \ --served-model-name deepseek-r1-70b-AWQ \ --api-key 'jisudf*&QW123' nohup vllm serve /model/deepseek-r1-70b-AWQ \ --tensor-parallel-size 2 \ --pipeline-parallel-size 2 \ --max-model-len 53520 \ --gpu-memory-utilization 0.8 \ --served-model-name deepseek-r1-70b-AWQ \ --api-key 'jisudf*&QW123' \ > ./logs/vllm.log 2>&1 &
如果换模型为千问,上面一步一步改成这样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 bash run_cluster.sh vllm/vllm-openai 10.5.9.252 --head /home/cys/data/models/Qwen2.5-72B-Instruct-AWQ -v /home/cys/data/models/Qwen2.5-72B-Instruct-AWQ:/model/Qwen2.5-72B-Instruct-AWQ -e VLLM_HOST_IP=10.5.9.252 -e GLOO_SOCKET_IFNAME=enp1s0 -e NCCL_SOCKET_IFNAME=enp1s0 bash run_cluster.sh vllm/vllm-openai 10.5.9.252 --worker /home/cys/data/models/Qwen2.5-72B-Instruct-AWQ -v /home/cys/data/models/Qwen2.5-72B-Instruct-AWQ:/model/Qwen2.5-72B-Instruct-AWQ -e VLLM_HOST_IP=10.5.9.251 -e GLOO_SOCKET_IFNAME=eno3np0 -e NCCL_SOCKET_IFNAME=eno3np0 nohup vllm serve /model/Qwen2.5-72B-Instruct-AWQ \ --tensor-parallel-size 2 \ --pipeline-parallel-size 2 \ --max-model-len 21104 \ --gpu-memory-utilization 0.8 \ --served-model-name Qwen2.5-72B-Instruct-AWQ \ --api-key 'jisudf*&QW123' \ > ./logs/vllm.log 2>&1 &
1.3、嵌入模型部署 参考: https://blog.csdn.net/make_progress/article/details/146051006
https://github.com/huggingface/text-embeddings-inference
文本嵌入推理(TEI,Text Embeddings Inference )是HuggingFace研发的一个用于部署和服务开源文本嵌入和序列分类模型 的工具包。TEI兼容OpenAI的嵌入模型的规范。 我们用到的就是它。
先在国内的ModelScope上下载BAAI/bge-reranker-large模型;
1 modelscope download --model BAAI/bge-large-zh-v1.5 --local_dir /home/cys/data/models/embeddingModel/.
建立一个 docker 容器专门提供嵌入服务;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 cd /home/cys/docker_data/embeddingModelmkdir -p bge-large-zh-v1.5cd /home/cys/docker_data/embeddingModel/bge-large-zh-v1.5vim docker-compose.yml ------------------------------ docker-compose.yml ------------------------------ services: text-embeddings-inference: user: "0:0" image: ghcr.io/huggingface/text-embeddings-inference:1.6 ports: - "8002:80" volumes: - "/home/cys/data/models/embeddingModel:/data" environment: - EMBEDDING_API_KEY=wiekdoid@JIDj124123 command : ["--model-id" , "/data/bge-large-zh-v1.5" , "--auto-truncate" ] networks: - my-network networks: my-network: external: true name: vllm-network ------------------------------ docker-compose.yml ------------------------------ docker compose up -d
检查是否可用
1 2 3 4 5 curl -X POST "http://localhost:8002/embed" -H "Content-Type: application/json" -d '{ "inputs": ["你好,世界"], "truncate": false }'
注意:TEI当前不会自动截断输入。您可以通过在请求中设置truncate: true来启用此功能。
在官网github中可见
1 2 3 4 5 6 --auto-truncate Automatically truncate inputs that are longer than the maximum supported size Unused for gRPC servers [env : AUTO_TRUNCATE=]
1.4、open webUI调用vllm 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 mkdir -p /home/cys/docker_data/openwebui2cd /home/cys/docker_data/openwebui2vim docker-compose.yml services: open-webui: image: ghcr.io/open-webui/open-webui:cuda environment: - ENABLE_OPENAI_API=true - OPENAI_API_BASE_URL=http://vllm-openai:8000/v1 - OPENAI_API_KEYS=jisudf*&QW123 - GLOBAL_LOG_LEVEL=DEBUG - HF_ENDPOINT=https://hf-mirror.com - CORS_ALLOW_ORIGIN=* - RAG_EMBEDDING_MODEL=bge-m3 - DEFAULT_MODELS=deepseek-r1-70b-AWQ - ENABLE_OAUTH_SIGNUP=true ports: - 8080:8080 volumes: - /home/cys/data/docker-data/open_webui_data:/app/backend/data networks: - my-network networks: my-network: external: true name: vllm-network docker compose up -d
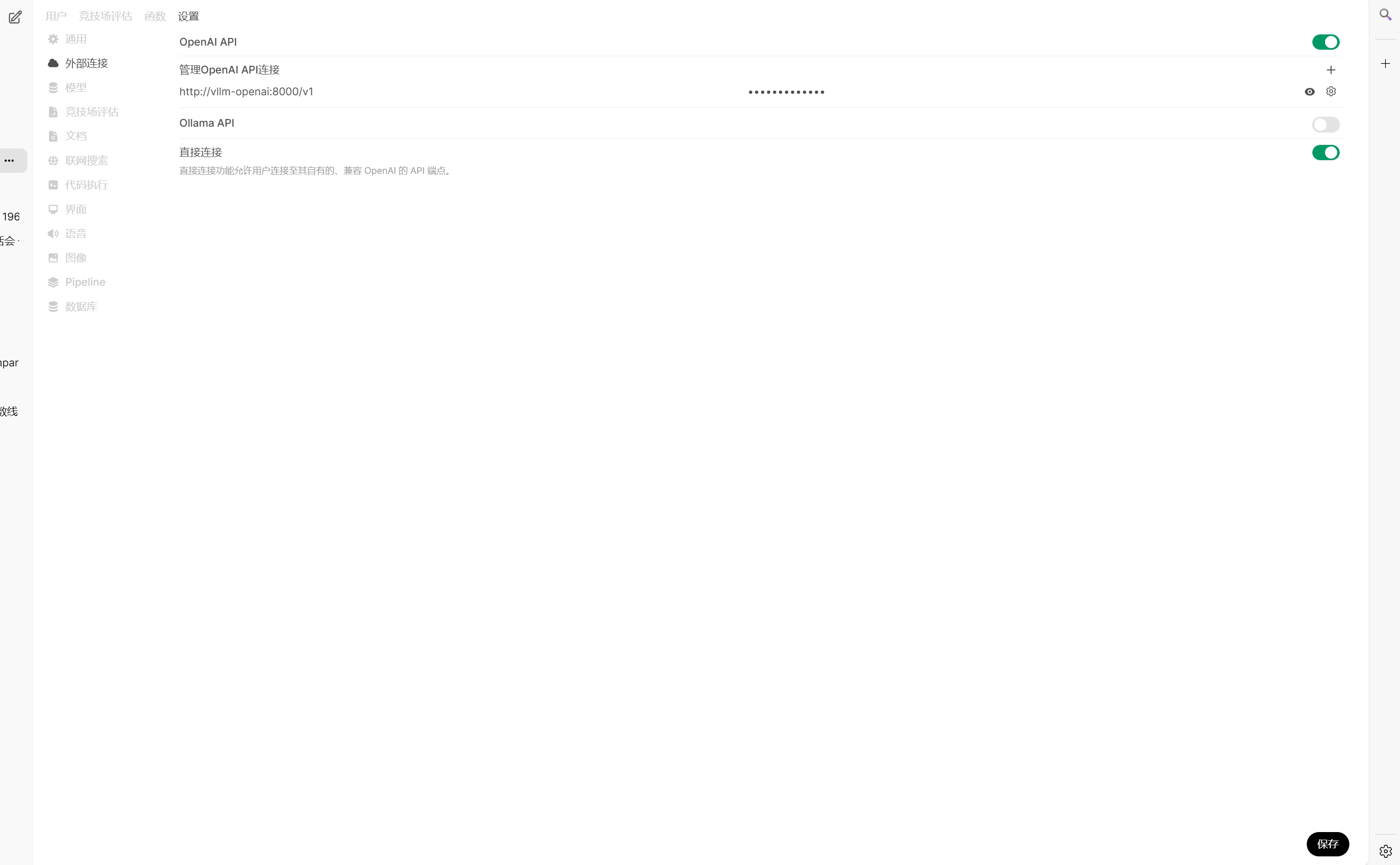
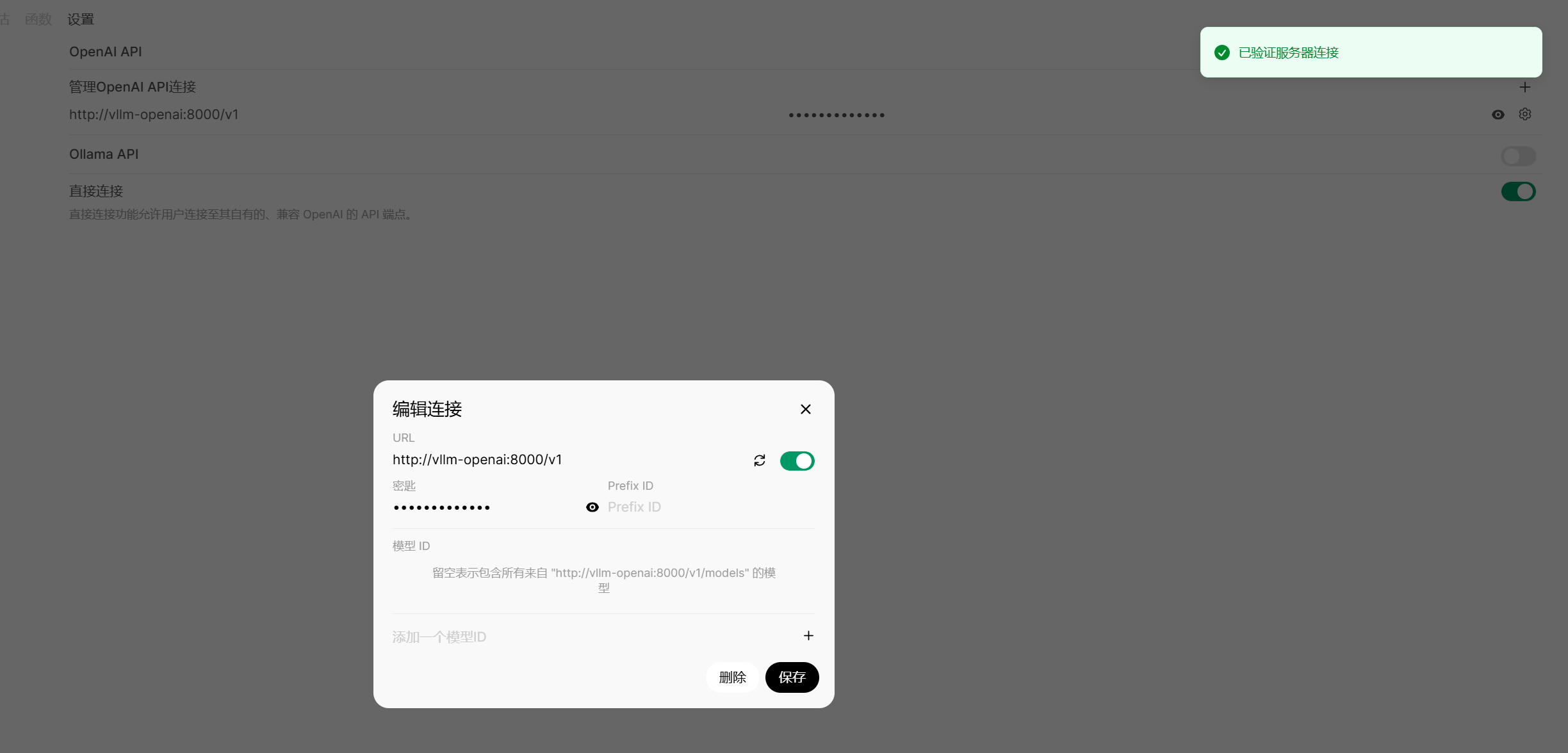
再在web页面配置一下连接上 vllm 。
分布式vllm ,open webUI如下:
docker-compose.yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 services: open-webui: image: ghcr.io/open-webui/open-webui:cuda environment: - ENABLE_OPENAI_API=true - OPENAI_API_BASE_URL=http://vllm-openai:8000/v1 - OPENAI_API_KEYS=jisudf*&QW123 - GLOBAL_LOG_LEVEL=DEBUG - HF_ENDPOINT=https://hf-mirror.com - CORS_ALLOW_ORIGIN=* - RAG_EMBEDDING_MODEL=bge-m3 - DEFAULT_MODELS=deepseek-r1-70b-AWQ - ENABLE_OAUTH_SIGNUP=true - RAG_EMBEDDING_MODEL=bge-large-zh-v1.5 - EMBEDDING_API_BASE_URL=http://10.5.9.252:8002/v1 - EMBEDDING_API_KEYS=wiekdoid@JIDj124123 ports: - 8080 :8080 volumes: - /home/cys/data/docker-data/open_webui_data:/app/backend/data networks: - my-network networks: my-network: external: true name: vllm-network
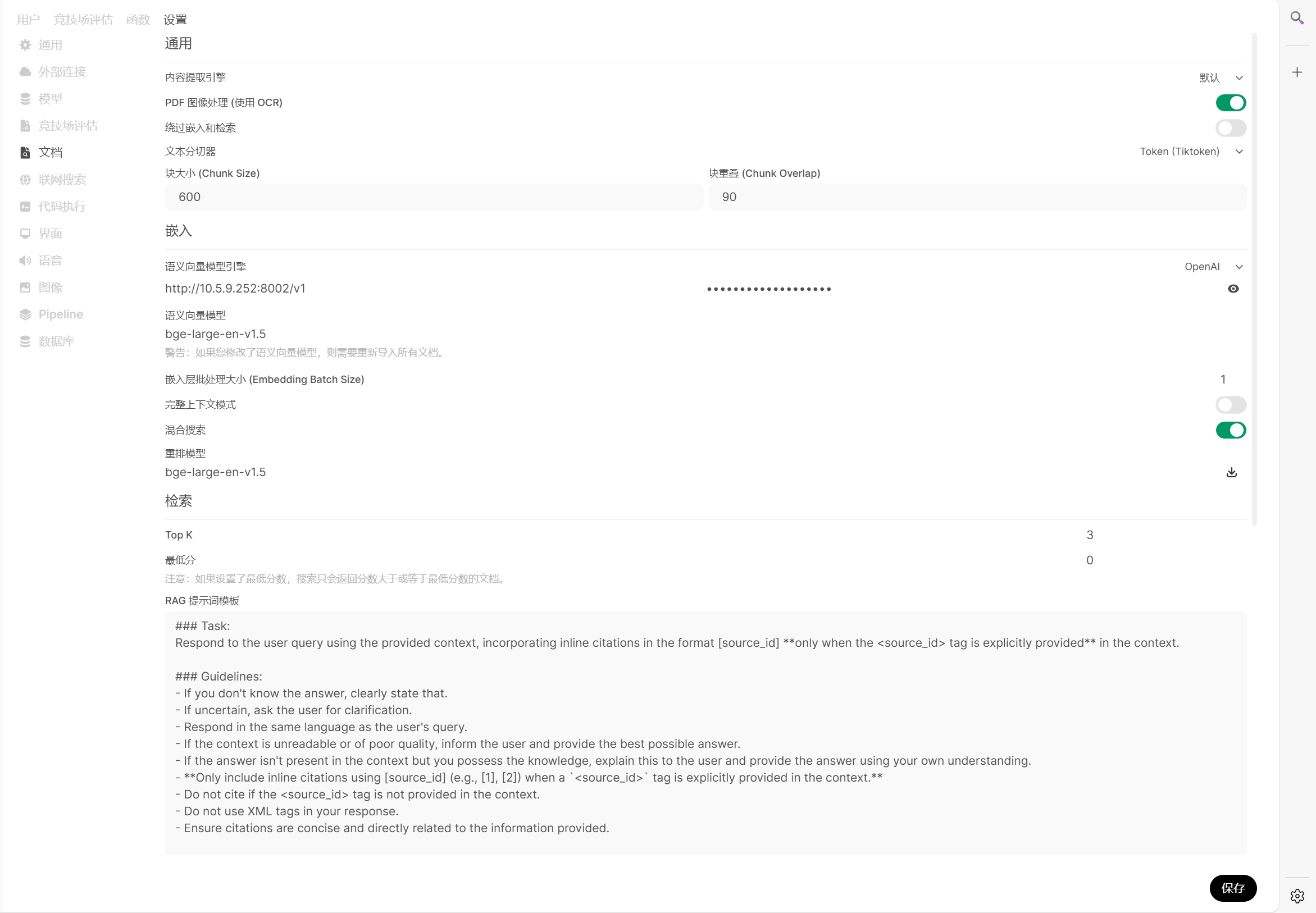
以上加入了 嵌入模型的调用,别的没有太大变化。
记得在open webUI web管理界面添加 嵌入模型。
附加:可能遇到的若干问题: 1 2 3 4 docker compose down docker compose up -d
1 2 3 4 docker compose stop docker compose up -d
1 2 docker compose up -d --no-deps <服务名>
· AnythingLLM数据迁移 如果是 之前 拉取anythingllm 没有做本地的映射,在更新anythingllm 的时候,一定要做好 数据的转移。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 docker start AnythingLLM mkdir ~/anythingllm_backupdocker cp AnythingLLM:/app/server/storage XXXXXXXXX/anythingllm cp XXXXX/XXXX/.env XXXXXXXXX/anythingllm export STORAGE_LOCATION=XXXXXXXXX/anythingllm mkdir -p $STORAGE_LOCATION && chmod -R 777 $STORAGE_LOCATION cp -r ~/anythingllm_backup/* $STORAGE_LOCATION /cp -r ~/anythingllm_backup/storage/* $STORAGE_LOCATION /docker ps -a docker stop AnythingLLM docker rm AnythingLLM docker images docker rmi <旧镜像ID> docker stop AnythingLLM && docker rm AnythingLLM docker pull mintplexlabs/anythingllm:latest export STORAGE_LOCATION=/home/cys/docker_data/anythingllm mkdir -p $STORAGE_LOCATION cd ${STORAGE_LOCATION} touch .env docker run -d -p 3001:3001 \ --name AnythingLLM \ --network host \ --cap-add SYS_ADMIN \ -v ${STORAGE_LOCATION} :/app/server/storage \ -v ${STORAGE_LOCATION} /.env:/app/server/.env \ -e STORAGE_DIR="/app/server/storage" \ mintplexlabs/anythingllm
· 测试容器之间是否相通 1 2 3 4 5 6 docker exec -it AnythingLLM /bin/bash curl "http://宿主机IP:端口/search?q=测试&format=json"
· 遇到 阿里云 Docker CE 镜像源 和 GPG 密钥过时 1 2 3 4 5 6 7 sudo apt-get update W: An error occurred during the signature verification. The repository is not updated and the previous index files will be used. GPG error: https://mirrors.aliyun.com/docker-ce/linux/ubuntu noble InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 7EA0A9C3F273FCD8 W: https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu/dists/noble/InRelease: Key is stored in legacy trusted.gpg keyring (/etc/apt/trusted.gpg), see the DEPRECATION section in apt-key(8) for details. W: Failed to fetch https://mirrors.aliyun.com/docker-ce/linux/ubuntu/dists/noble/InRelease The following signatures couldn' t be verified because the public key is not available: NO_PUBKEY 7EA0A9C3F273FCD8W: Some index files failed to download. They have been ignored, or old ones used instead.
处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 grep -ri "mirrors.aliyun.com" /etc/apt/sources.list.d/ sudo sed -i.bak '/mirrors.aliyun.com/docker-ce/d' /etc/apt/sources.list sudo apt-key export 7EA0A9C3F273FCD8 | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg sudo sed -i 's#deb [arch=amd64]#deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg]#g' /etc/apt/sources.list.d/docker-ce.list sudo rm -rf /var/lib/apt/lists/* sudo apt-get update sudo rm -f /etc/apt/sources.list.d/third-party.sources /etc/apt/sources.list.d/docker.list sudo sed -i '/mirrors.aliyun.com/docker-ce/d' /etc/apt/sources.list sudo apt-key export 7EA0A9C3F273FCD8 | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg sudo apt-key del 7EA0A9C3F273FCD8 sudo sed -i 's#signed-by=/etc/apt/keyrings/docker.gpg#signed-by=/usr/share/keyrings/docker-archive-keyring.gpg#g' /etc/apt/sources.list.d/docker-ce.list sudo rm -rf /var/lib/apt/lists/* sudo apt-get update sudo apt-key export 7EA0A9C3F273FCD8 | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg sudo apt-key del 7EA0A9C3F273FCD8 sudo sed -i 's#deb \[arch=amd64#deb \[arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg#g' /etc/apt/sources.list.d/docker-ce.list sudo apt-get update sudo apt update apt-cache policy docker-ce
· open webui 白屏问题解决 参考:https://blog.csdn.net/xianciSele/article/details/145340554
https://blog.kazoottt.top/posts/openwebui-long-loading-white-screen-solution/
https://github.com/open-webui/open-webui/discussions/7769
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 extra_hosts: - "api.openai.com:127.0.0.1" -e ENABLE_OPENAI_API=0 \ environment: - ENABLE_OPENAI_API=0 ------------------------------------------------------------- name: openwebui services: open-webui: ports: - 3000:8080 deploy: resources: reservations: devices: - driver: nvidia count: all capabilities: - gpu extra_hosts: - host.docker.internal:host-gateway volumes: - open-webui:/app/backend/data container_name: open-webui restart: always image: ghcr.io/open-webui/open-webui:cuda environment: - ENABLE_OPENAI_API=0 volumes: open-webui: external: true name: open-webui
以上的例子都是在ollama下载的deepseek的处理办法,在vllm 直接下载 deepseek模型到本地的方法中一定要打开openaai 的支持,只不过在具体的url 要指定要本地就好了。可以看看前面vllm的部署例子。
· searxng中长句子不能搜索的问题 开启 多个国内能用的搜索引擎,而不是只开一个bing。可以解决。bing 搜索引擎好像不支持长句的搜索。
· 容器间通信问题的最佳实践 1 2 docker network create vllm-network
在每个 docker-compose 文件中引用这个网络。例如,在 vllm 的 docker-compose.yml 文件中添加:
external: true 表示使用已存在的外部网络,而不是由当前的 Compose 文件创建新的网络。
1 2 3 4 networks: my-network: external: true name: my-shared-network
然后在对应的服务配置中加入:
1 2 3 4 5 services: open-webui: networks: - my-network
修改 open-webui 的 API 地址 :OPENAI_API_BASE_URL 设置为 http://vllm-openai:8000/v1。这样 open-webui 容器会通过 DNS 查找同一网络中的 vllm-openai 服务。
这种方法比较稳定,服务间互访不依赖宿主机 IP。vllm-openai ,所以其他同网络的容器可以通过 “vllm-openai” 来访问它。
将多个容器加入同一个自定义网络后:
容器与宿主机之间的端口映射: 自定义网络不会影响容器与宿主机之间的端口映射。端口映射是在容器启动时通过 -p 参数或在 Compose 文件中通过 ports 指定的,用于将宿主机的特定端口转发到容器的端口。这些映射在自定义网络中仍然有效。容器连接互联网: 默认情况下,Docker 使用 bridge 网络驱动程序创建的自定义网络允许容器访问外部互联网。因此,容器加入自定义网络后,通常仍能连接互联网。但如果使用其他网络驱动程序(如 macvlan),可能需要额外配置以确保互联网连接。
· 无法科学上网使用docker技巧 在能科学上网的机器 下载下来镜像,打包成 .tar 文件,复制到不能科学上网的机器中;
按照下面例子操作
1 2 3 4 5 docker save -o vllm.tar vllm/vllm-openai:dddddddddddd docker load -i vllm.tar
· vllm集群遇到 GLOO、NCCL 报错
先看看ip 用的哪个网口;
然后在 run_cluster.sh 脚本中加入 -e GLOO_SOCKET_IFNAME=对应网口 -e NCCL_SOCKET_IFNAME=对应网口 环境变量。
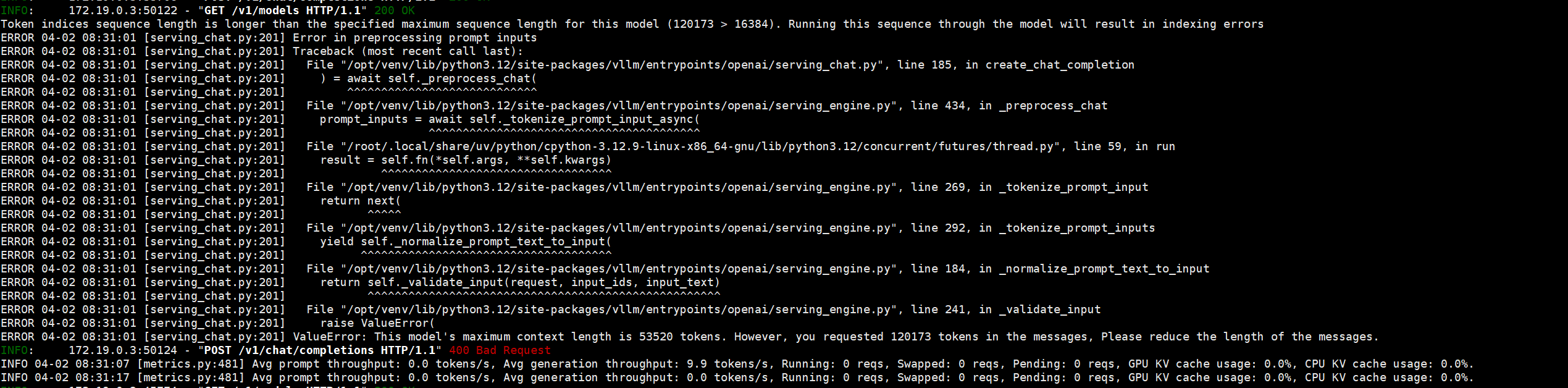
· vllm集群遇到 The model’s max seq 报错
给我们提示了 Try increasing gpu_memory_utilization or decreasing max_model_len when initializing the engine. [repeated 2x across cluster]
可以从运行 vllm serve 后的 提示中看到全部的 args 参数表中
找 gpu_memory_utilization、max_model_len。
如上图显示,硬件只能支持到 KV cache (69040) 于是我们把 参数加上
1 2 3 4 vllm serve /model/deepseek-r1-70b-AWQ \ --tensor-parallel-size 2 \ --pipeline-parallel-size 2 \ --max_model_len 69040
· vllm集群遇到 CUDA out of memory 报错
杀死占用显存多的进程,然后
1 2 3 4 5 vllm serve /model/deepseek-r1-70b-AWQ \ --tensor-parallel-size 2 \ --pipeline-parallel-size 2 \ --max_model_len 69040 \ --gpu-memory-utilization 0.8
· open webUI知识库上传文件遇到 上传 报错 Extracted content is not available for this file. Please ensure that the file is processed before proceeding.
进入 嵌入式模型容器中,查看日志,有可能是 truncate 没有切,导致的 超过了 最大承受token。
在 嵌入模型容器的 yml 文件中 配置 自动切分功能参数,参考 HuggingFace Text Embeddings Inference 官网GitHub 即可。
· RAG 时遇到了 Please reduce the length of the messages 报错
我们即使在vLLM中设置了max-model-len 53520,也可能在rag时报这样的错误;
因为:
RAG的上下文叠加特性
用户输入:50 tokens
检索到3篇文档,每篇2000 tokens
总输入量:50 + 3×2000 = 6050 tokens
解决办法:
滑动窗口分块 :将长文档按500-800 tokens为单位分割,重叠率建议15%,如每块保留前一块的75 tokens。
限制召回内容规模 :设置Top-K阈值,仅保留相关性最高的3-5个知识块。
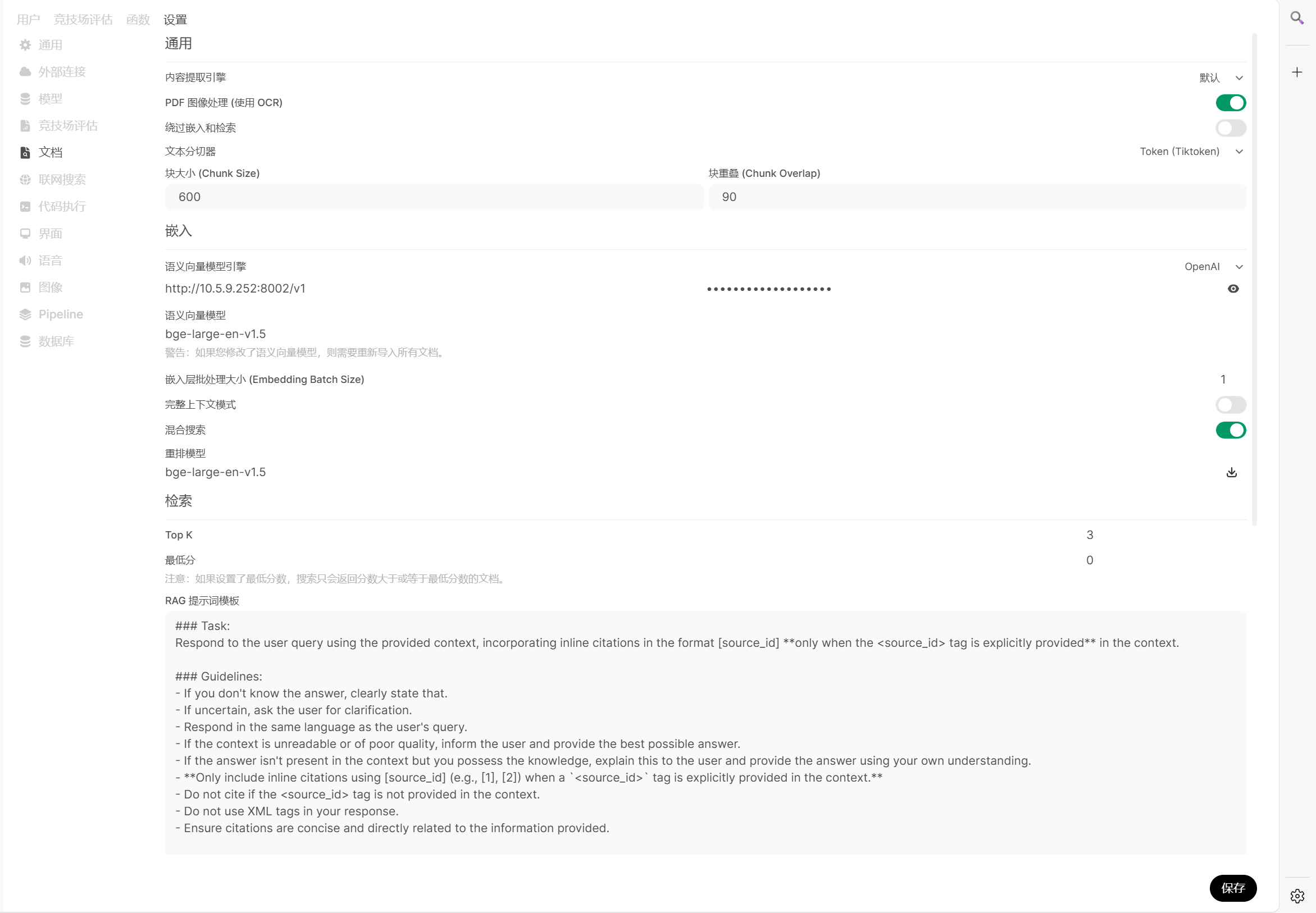
在open webUI 中设置。
然后重新传一下 知识库中的文档。
· 更新容器的服务 以open webUI的yaml文件为例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 services: open-webui: image: ghcr.io/open-webui/open-webui:cuda environment: - ENABLE_OPENAI_API=true - OPENAI_API_BASE_URL=http://vllm-openai:8000/v1 - OPENAI_API_KEYS=jisudf*&QW123 - GLOBAL_LOG_LEVEL=DEBUG - HF_ENDPOINT=https://hf-mirror.com - CORS_ALLOW_ORIGIN=* - RAG_EMBEDDING_MODEL=bge-m3 - DEFAULT_MODELS=deepseek-r1-70b-AWQ - ENABLE_OAUTH_SIGNUP=true ports: - 8080 :8080 volumes: - /home/cys/data/docker-data/open_webui_data:/app/backend/data networks: - my-network networks: my-network: external: true name: vllm-network
open webUI在昨天进行了版本更新,我们也更新一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 tar -czvf openwebui-bak-$(date +%Y%m%d).tar.gz \ /home/cys/data/docker-data/open_webui_data cd ~/docker_data/openwebui2docker compose down docker pull ghcr.io/open-webui/open-webui:cuda docker compose up -d