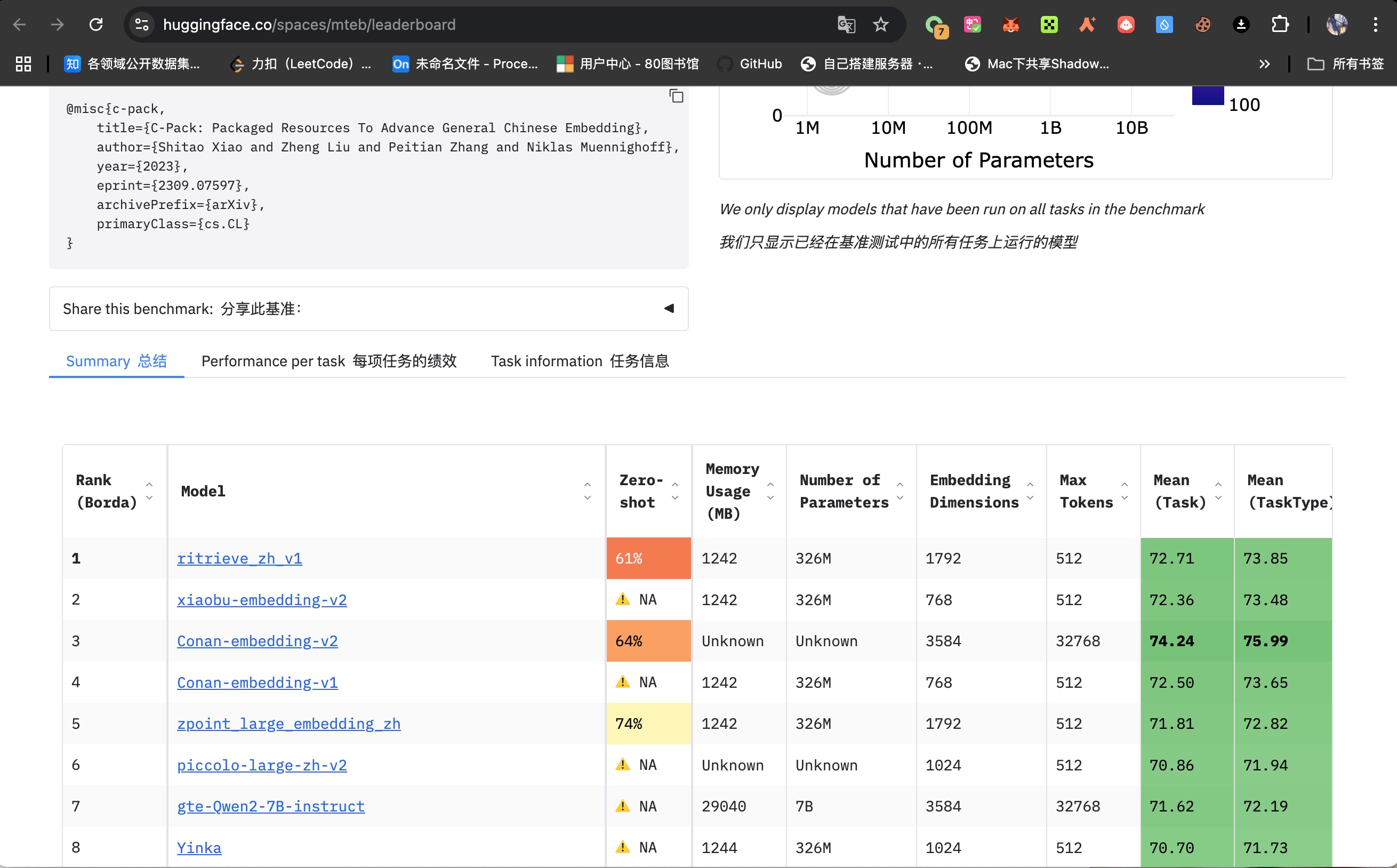
查看嵌入模型排名 访问网址:
https://huggingface.co/spaces/mteb/leaderboard
选择中文
注意,英文的嵌入模型好,不代表 中文的向量化的效果好。
huggingface下载模型 参考:
https://zhuanlan.zhihu.com/p/663712983
推荐这样用huggingface推荐工具优雅的下载。
1 2 3 4 5 6 7 8 pip install -U huggingface_hub huggingface-cli download richinfoai/ritrieve_zh_v1 --local-dir ./ritrieve_zh_v1 ls ./ritrieve_zh_v1/
传输,这一步可能是因为服务器不能科学上网,我们把下载好的模型传到服务器中。
我这里是从MacBook 传到Linux中。
1 2 3 4 5 6 7 8 tar -czvf ritrieve_zh_v1.tar.gz ritrieve_zh_v1/ md5 ritrieve_zh_v1.tar.gz > ritrieve_zh_v1.tar.gz.md5 awk '{print $4" "$2}' ritrieve_zh_v1.tar.gz.md5 > temp.md5 && mv temp.md5 ritrieve_zh_v1.tar.gz.md5 scp ritrieve_zh_v1.tar.gz* cys@10.5.9.252:/home/cys/data/models/embeddingModel/.
在Linux服务器中校验
1 2 3 4 5 6 7 8 9 10 11 12 13 cd /home/cys/data/models/embeddingModelvim ritrieve_zh_v1.tar.gz.md5 md5sum -c ritrieve_zh_v1.tar.gz.md5tar -xzvf ritrieve_zh_v1.tar.gz ls
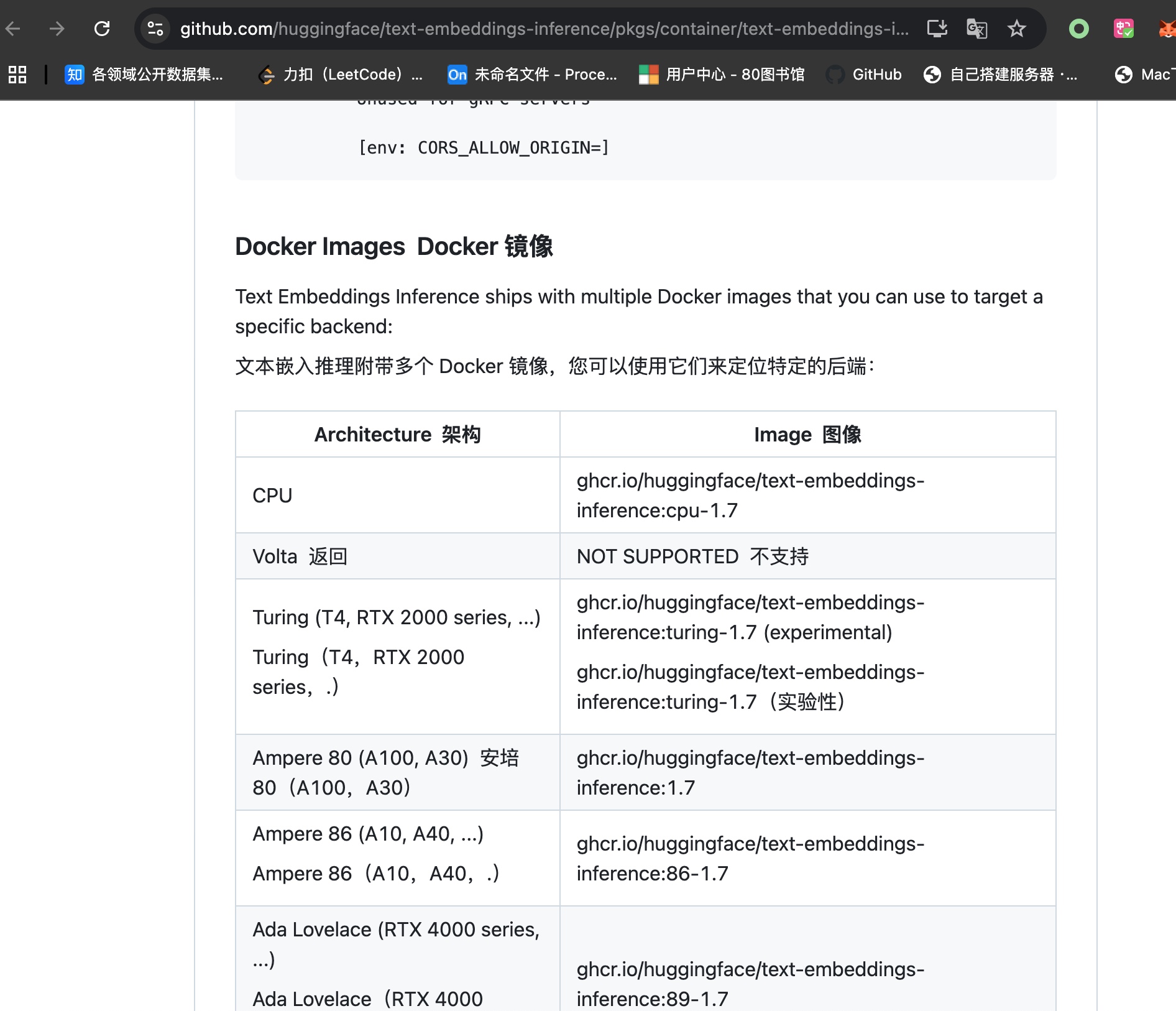
模型中介(huggingface/text-embeddings-inference) 在这里可以查看使用嵌入模型的通用中介工具的相关内容:
https://github.com/huggingface/text-embeddings-inference/pkgs/container/text-embeddings-inference
配置 yml 文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 cd /home/cys/docker_data/embeddingModel/ritrieve_zh_v1 vim docker-compose.yml --------------------------------- docker-compose.yml ------------------------------------ services: text-embeddings-inference: user: "0:0" image: ghcr.io/huggingface/text-embeddings-inference:cpu-1.7 ports: - "8002:80" volumes: - "/home/cys/data/models/embeddingModel:/data" environment: - EMBEDDING_API_KEY="wiekdoid@JIDj124123" - TOKENIZATION_WORKERS=18 - MAX_BATCH_TOKENS=32768 - MAX_CLIENT_BATCH_SIZE=64 command: ["--model-id" , "/data/ritrieve_zh_v1" , "--auto-truncate" ] networks: - my-network networks: my-network: external: true name: vllm-network --------------------------------- docker-compose.yml ----------------------------------- docker compose up -d
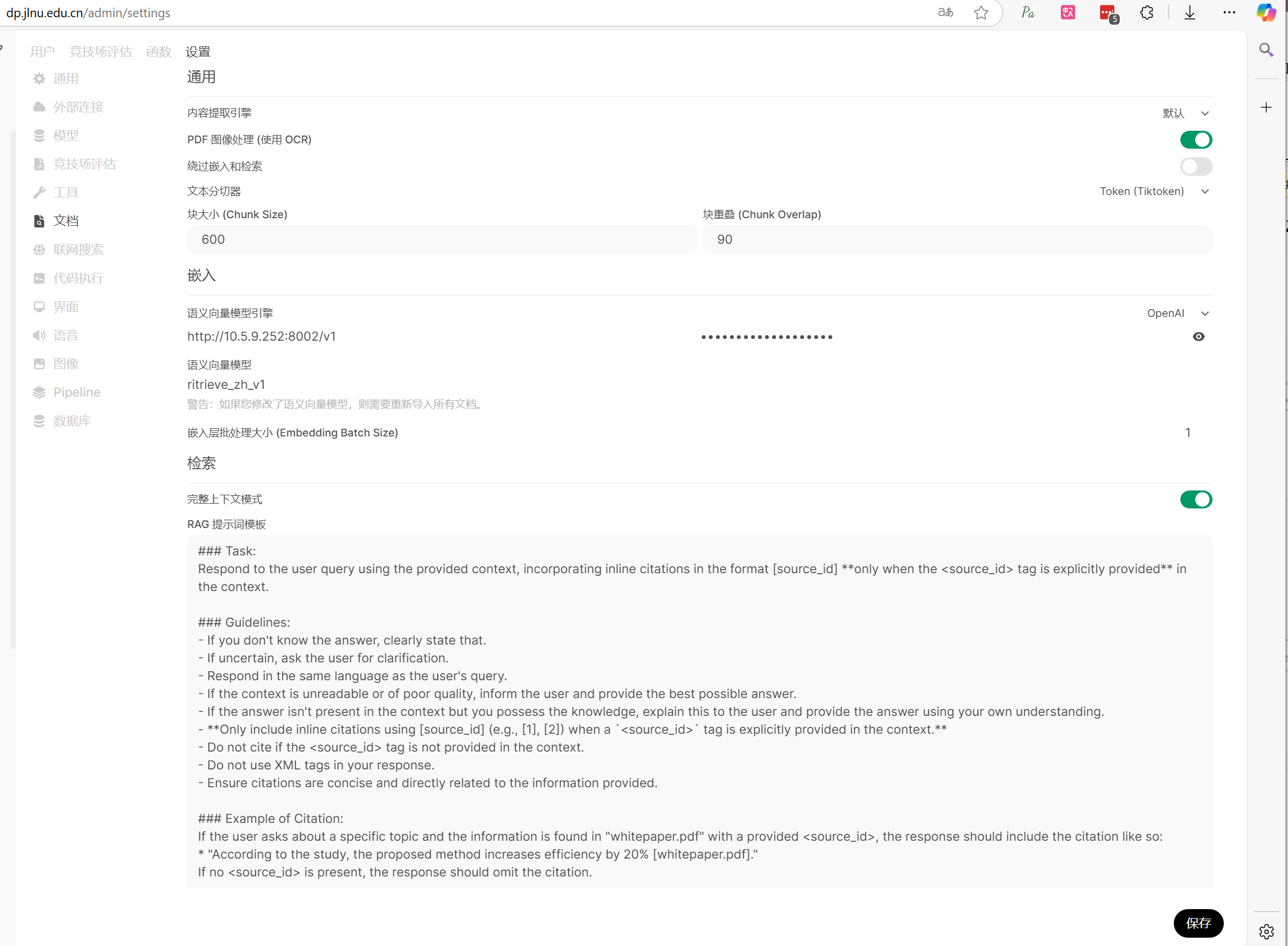
open webUI控制页面修改 在设置、文档、中选择 “语意向量模型” ,重排模型等等修改成 ritrieve_zh_v1
检查模型是否可用 1 2 3 4 5 curl -X POST "http://localhost:8002/embed" -H "Content-Type: application/json" -d '{ "inputs": ["你好,世界"], "truncate": false }'
可能遇到的问题 报错:onnx/model.onnx does not exist onnx/model.onnx does not exist
错误根因:ORT 后端找不到 ONNX 文件
TEI 支持 Safetensors,但生产级部署推荐 ONNX
将 Safetensors 模型导出为 ONNX
1 2 3 4 5 6 7 8 9 10 11 12 13 14 pip install --upgrade optimum[onnxruntime] pip install --upgrade sentence-transformers optimum[exporters] optimum-cli export onnx \ --model /home/cys/data/models/embeddingModel/ritrieve_zh_v1 \ --task feature-extraction \ /data/onnx mv /data/onnx /home/cys/data/models/embeddingModel/ritrieve_zh_v1/onnx
yml中网络问题 前文中的使用的是 一个 docker 的网络,在一台机器内部 部署了多个服务,如open webUI、 seargxn等等都是
1 2 3 4 5 6 networks: - my-network networks: my-network: external: true name: vllm-network
但是事实上,在实际项目中 可以把嵌入模型部署到其他机器中,然后通过 IP:port 这样的地址加端口的方式调用,都是 容器映射到宿主机的某个端口,通过宿主机的IP 加上暴露的端口,最好配上一个 APIkey 来实现相互链接,而不是在一个 机器中使用上面的 docker network 网络。
测试能否正常使用
1 2 3 4 5 curl -X POST http://10.5.9.254:8002/embed \ -H "Content-Type: application/json" \ -H "Authorization: Bearer wiekdoid@JIDj124123" \ -d '{"inputs":"样例文本"}'
在open webUI中上传大文件问题 上传一个 5M docx 文件到知识库中, 居然花了我6个小时,我都惊了。
解决方法是docker compose 的yaml文件中改 嵌入模型 cpu 处理 为 GPU 版本来处理。
这也是我为什么推荐使用 另一台机器 部署 嵌入模型容器的原因,因为这两台机器的GPU资源 快要满了。
同时注意: ValueError: This model's maximum context length is 53520 tokens. However, you requested 3305318 tokens in the messages, Please reduce the length of the messages. 这样的报错。