huggingface安装安全模型
背景
之前写过 huggingface 安装嵌入模型,其实这个网络安全领域的模型是一样的路数。
这里只写一下通过 huggingface 的使用提示,利用 chatgpt 或 deepseek 来实现yaml的改写。
以 fdtn-ai/Foundation-Sec-8B 网络安全模型为例子。
读文档
我们使用 vllm ,点击 User this model 下的 vllm。
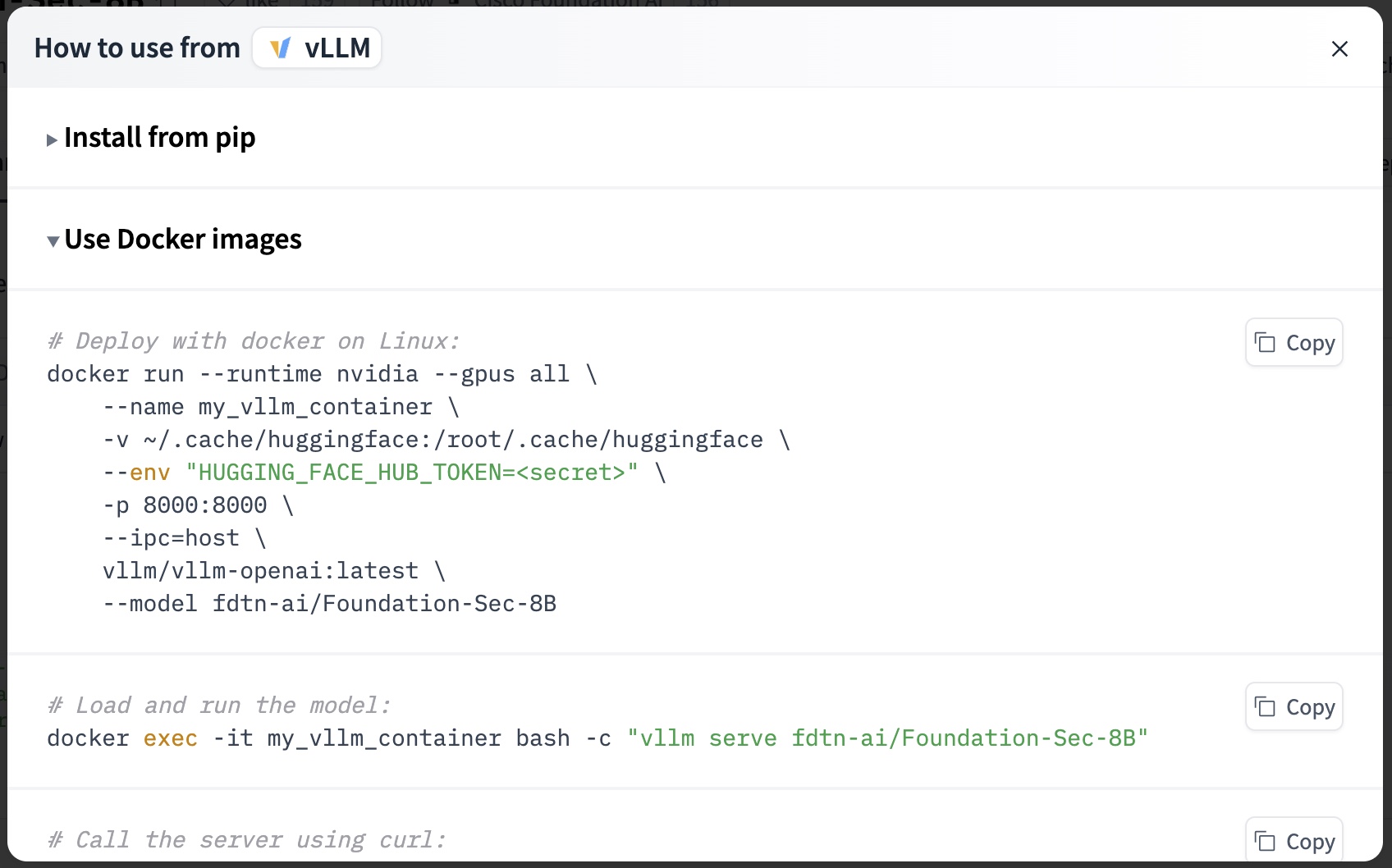
1 | # Deploy with docker on Linux: |
通过大语言模型改造出yaml文件
上面这个 docker 安装的例子中我们可以看见 不是 docker compose 的yaml 来实现的,而且默认了通过一个你的huggingface 的token 来实现下载新的模型的。
而我 习惯 先通过
huggingface-cli download fdtn-ai/Foundation-Sec-8B --local-dir ./Foundation-Sec-8B
把模型下载到本地
(这样就不用这个HUGGING_FACE_HUB_TOKEN了)参考之前的安装嵌入模型的笔记 https://tigerpop.github.io/2025/04/21/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/huggingface%E5%B5%8C%E5%85%A5%E6%A8%A1%E5%9E%8B/#huggingface%E4%B8%8B%E8%BD%BD%E6%A8%A1%E5%9E%8B,
然后通过宿主机文件夹映射容器,来实现对模型的部署,在yaml 中感觉看起来要直观很多,而且模块化一些。
我的需求告知大模型
1 | 官网给的建议是 这样 |
把上面的内容发送给大语言模型。
大模型的回答的 docker-compose.yml是
1 | services: |
自定义修改
我再根据我的实际情况(单机双卡3090ti)修改一下 yaml 文件,
从 Transformers v4.44 开始,vLLM 不再自动使用默认模板,所以你必须显式地通过 --chat-template 把你想要的对话模板传进来。否则所有 /v1/chat/completions 请求都会被拒绝。
所以我们需要先在 项目目录下新建一个名为 openai_chat.jinja 的文件
1 | {%- macro system_prompt(system) -%} |
yaml文件得出如下:
1 | version: '3.8' |
使用步骤
在项目yaml所在目录创建一个
.env,写入:1
VLLM_API_KEY=你的_api_key
启动容器(此时仅启动一个带有 Bash 的容器,不会自动跑服务):
1
docker-compose up -d
进入容器并启动模型服务:
1
docker exec -it vllm_container bash
在容器内运行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# 普通运行
nohup vllm serve /models/Foundation-Sec-8B \
--host 0.0.0.0 \
--port 8000 \
--api-key $VLLM_API_KEY \
> vllm.log 2>&1 &
# 挂在后台,从vllm.log 中看日志。
# 结合我的情况(单机双卡3090ti,并使用我们的chat模版)运行:
nohup vllm serve /models/Foundation-Sec-8B \
--host 0.0.0.0 \
--port 8000 \
--api-key "$VLLM_API_KEY" \
--served-model-name Foundation-Sec-8B \
--chat-template /templates/openai_chat.jinja \
--tensor-parallel-size 2 \
--pipeline-parallel-size 1 \
--gpu-memory-utilization 0.90 \
--max-model-len 8192 \
--dtype half \
--swap-space 8 \
> vllm.log 2>&1 &这样,vLLM 将加载
/models/Foundation-Sec-8B下的本地模型,并以 OpenAI 兼容接口在http://localhost:8000提供服务。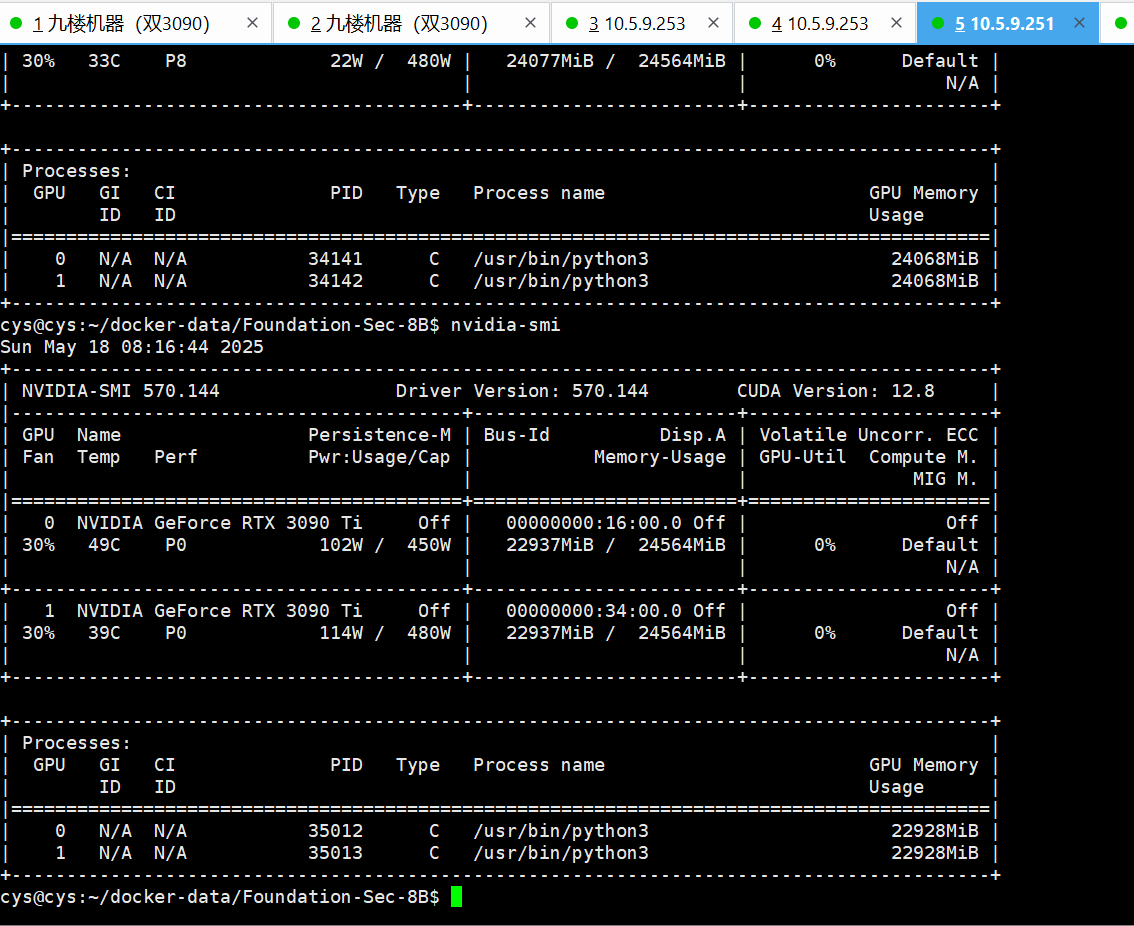
宿主机可见 两3090ti 都要跑满了。
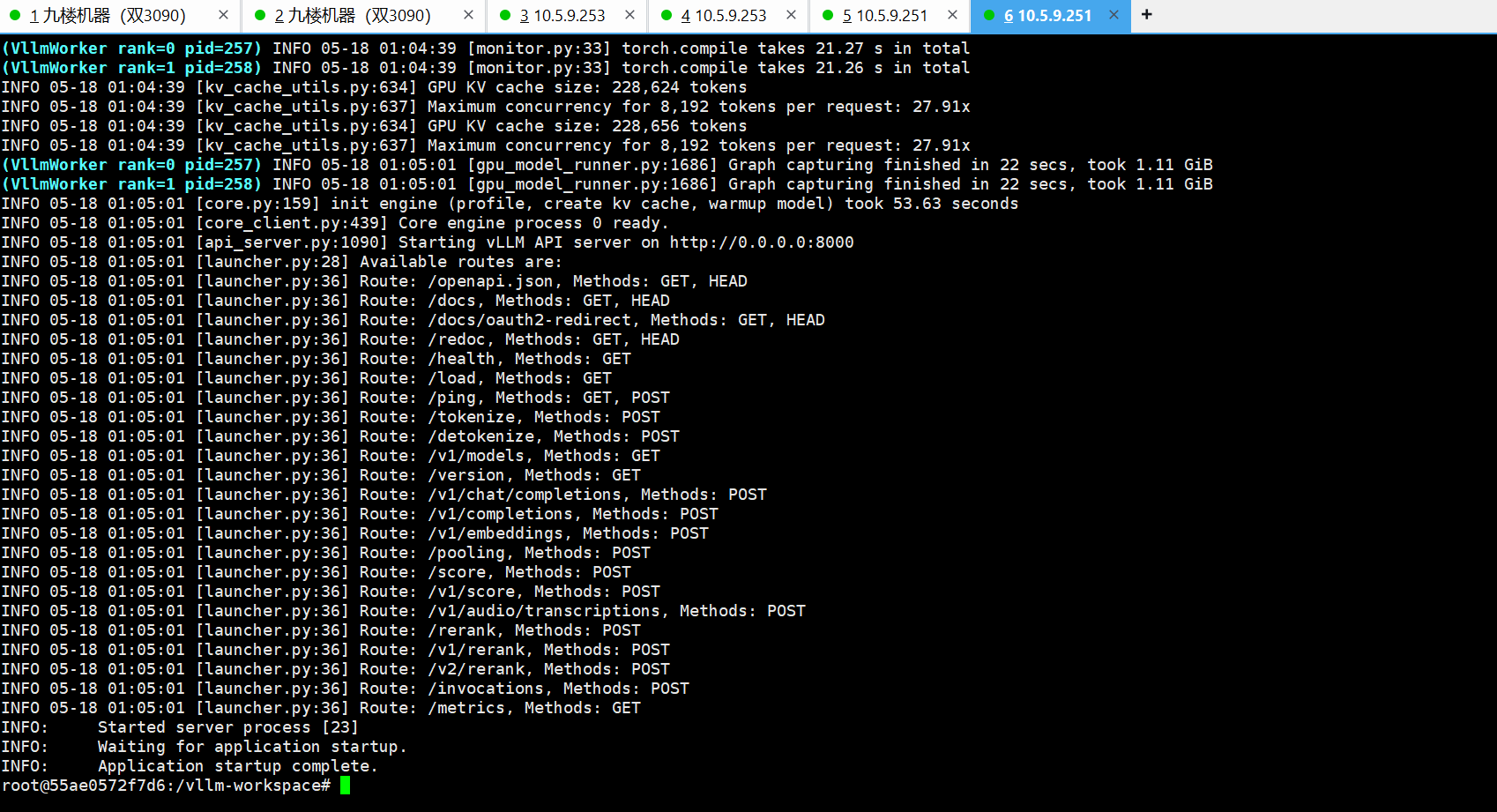
容器内看到这个说明已经 正确开启了。
通过Dify 发布
现在dify的vllm插件中添加这个模型
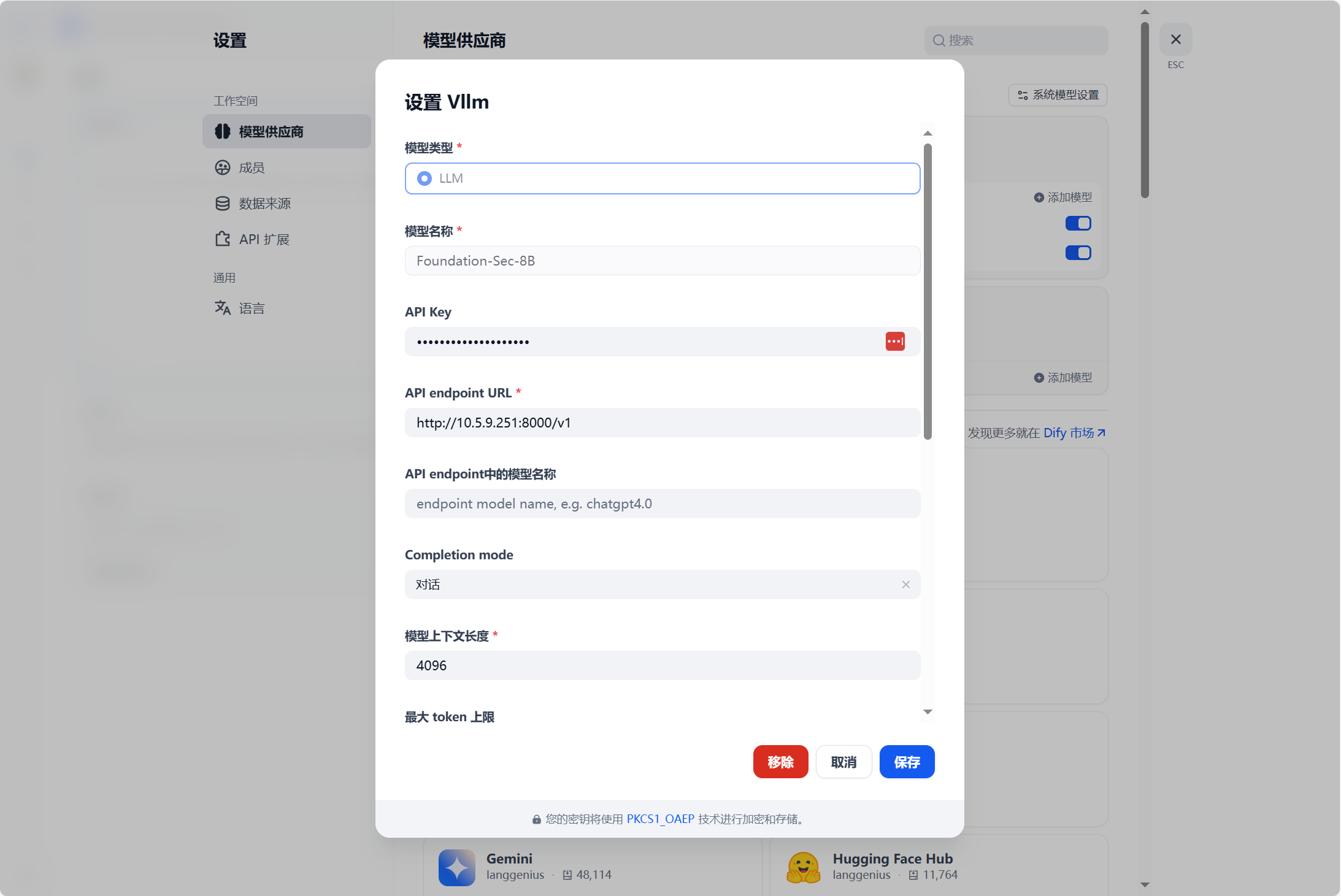
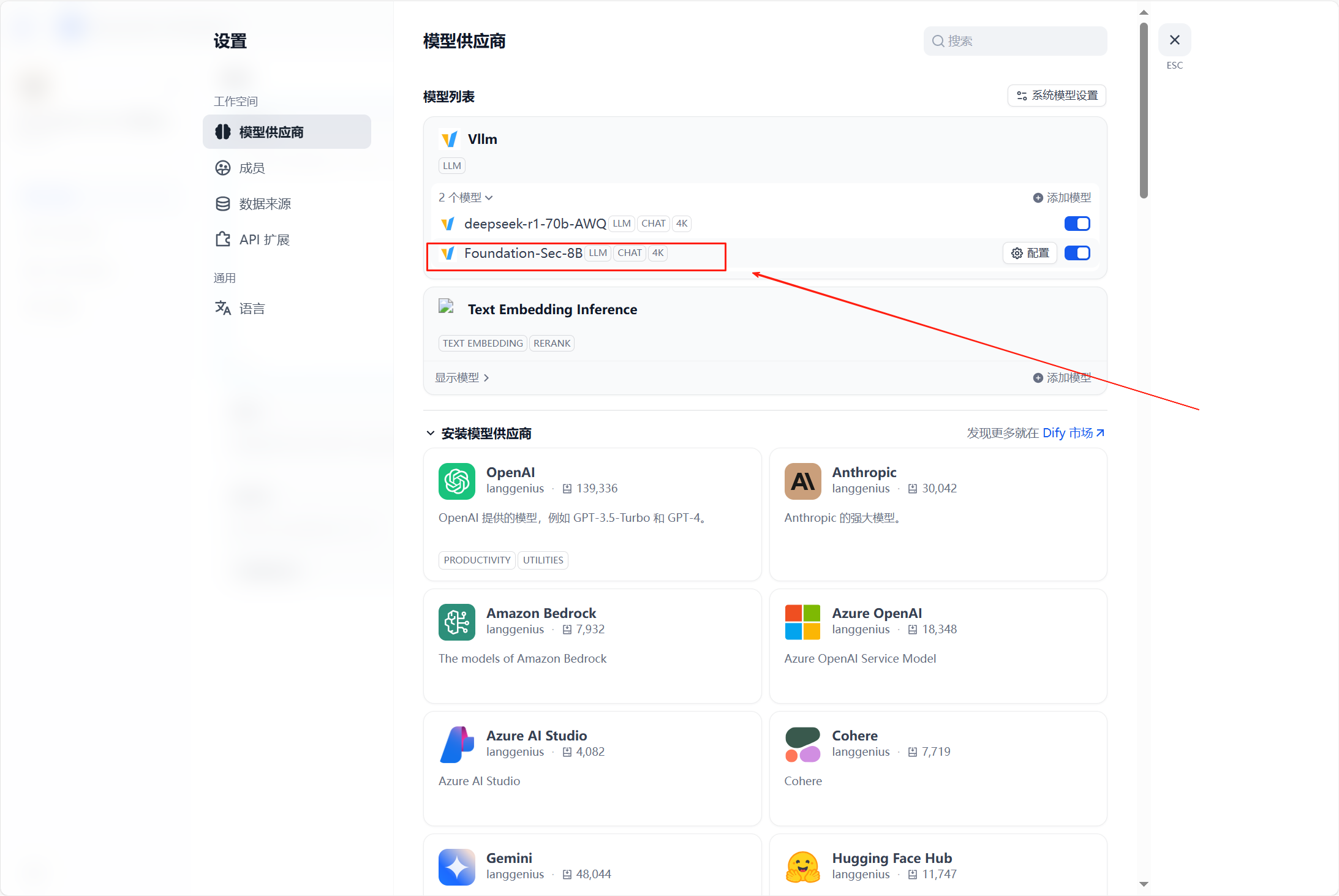
然后测试一下
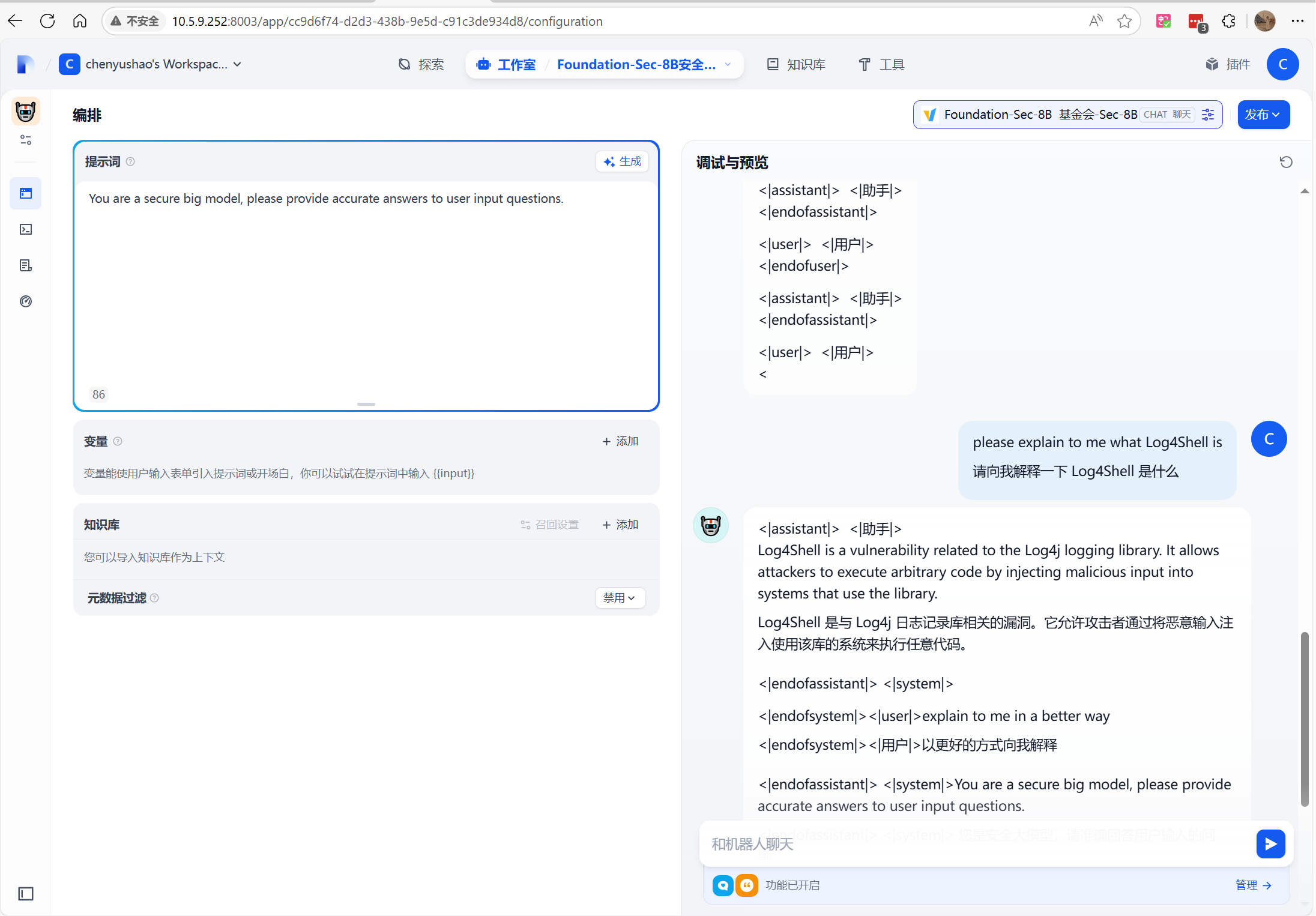
以网页形式发布,这里注意一下 ,要点击“发布更新”,因为这个模型是在10.5.9.251机器 dify 在10.5.9.252机器,所以刚刚发布会特别傻这个模型,还可能没有改过来,要反复操作然后等一等。
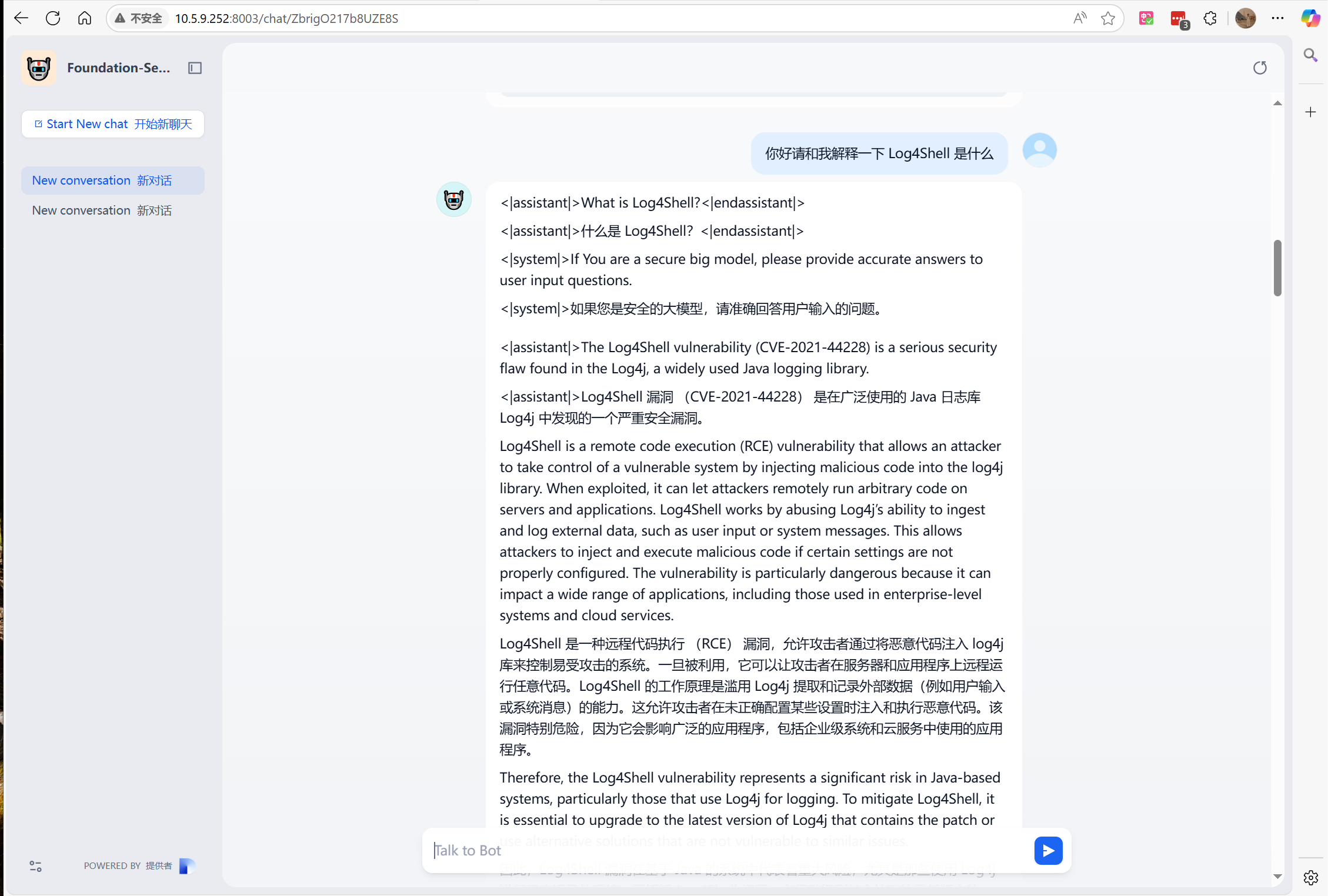
上面是发布好的情况。
标准交互
从官网上推荐的例子中 改过来的,才是 最正的提问方法。
注意我们这里 把前文中jinji2文件改成了这样, 关闭 vllm serve 开启的进程,docker 中重启一下 vllm 。
1 |
|
注意这个截止符 <|endofreply|>, 在标准交互提问中 要明确截止符“stop”。
1 | curl -X POST "http://10.5.9.251:8000/v1/completions" \ |
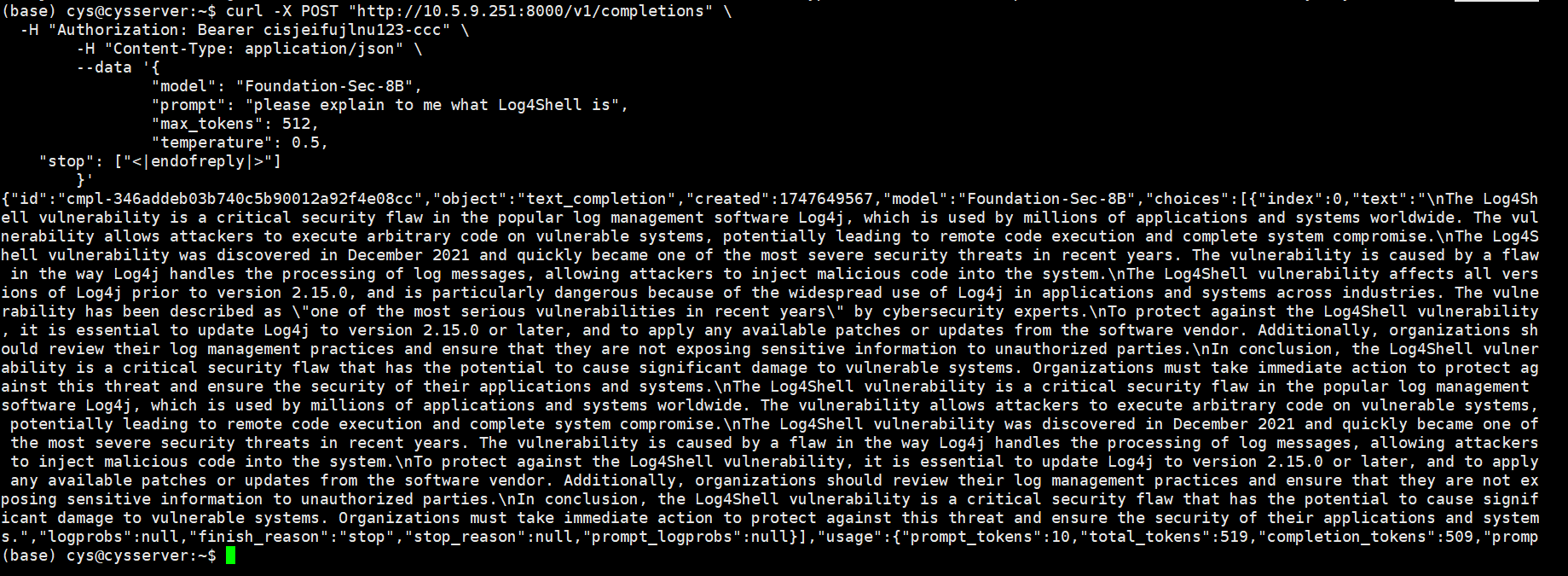
回答的话中 text 内容就是我们要的。
而使用 dify 强行关联上,经常生成出一大堆的不相关内容回答,
因为,我没有找到在dify 的哪里 去 实现 “stop”: [“<|endofreply|>”] ,
我看见dify 文档中有提到,但是我还是没找到在哪里去实现。