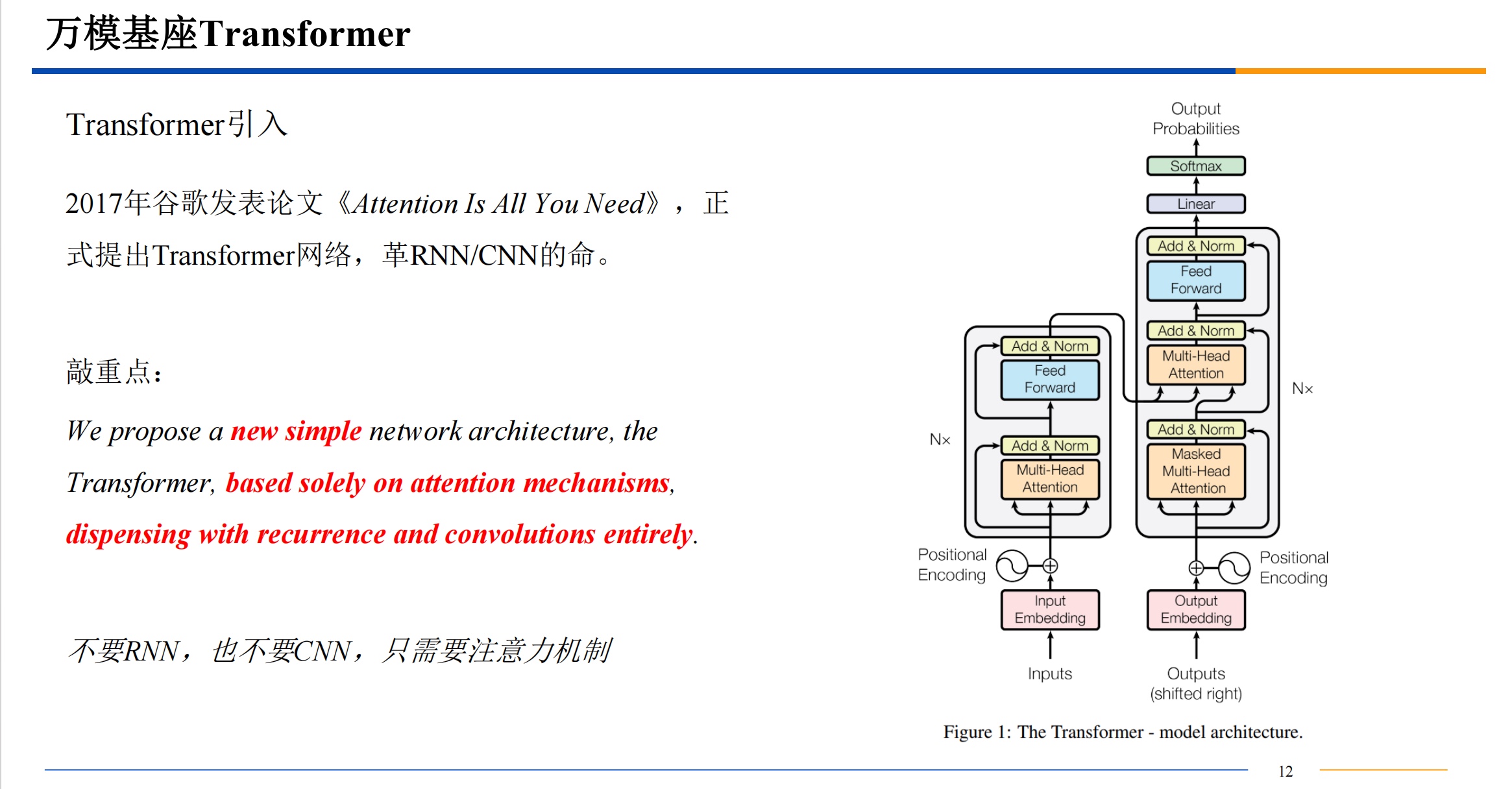
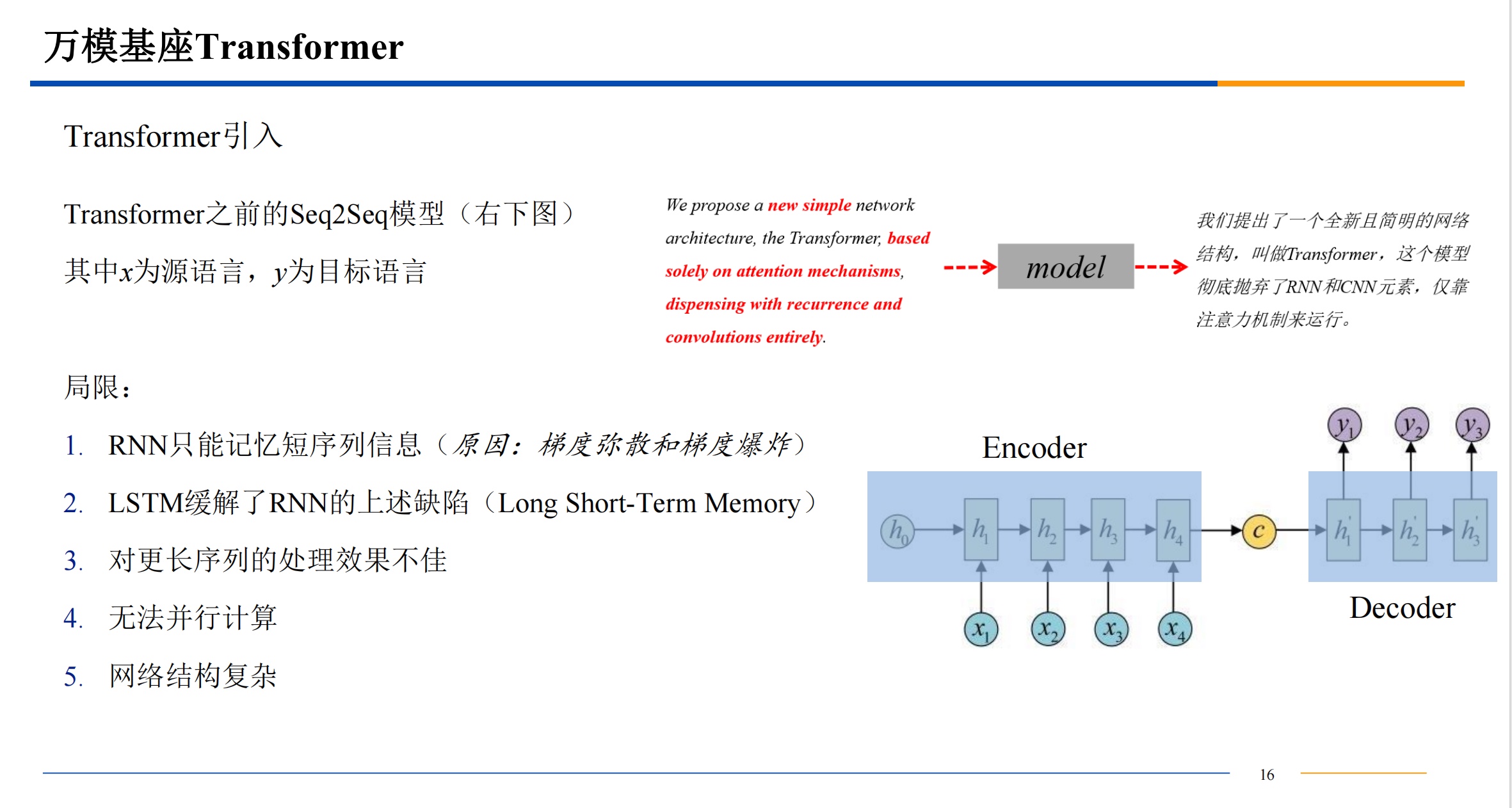
transform模型
简介
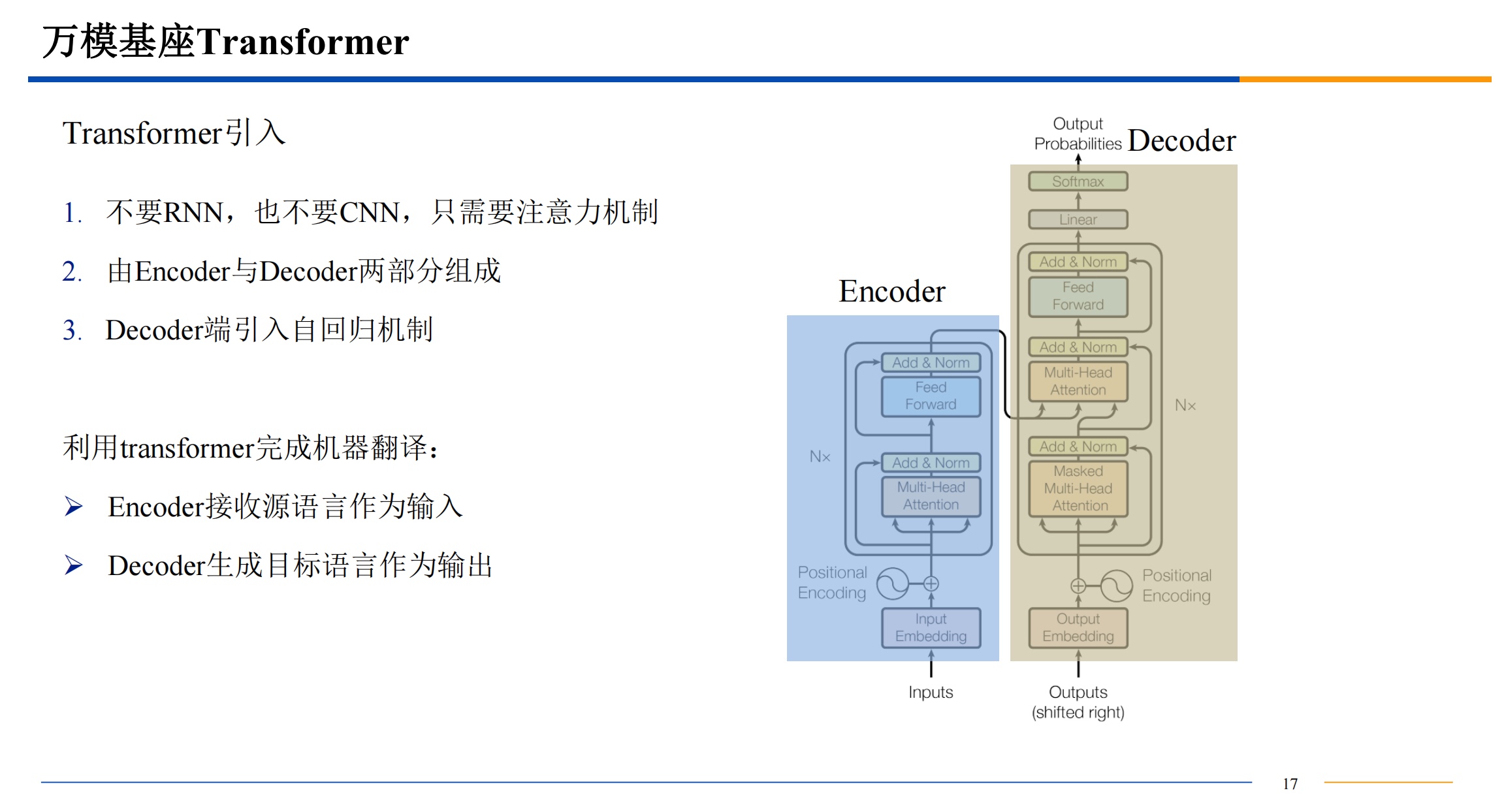
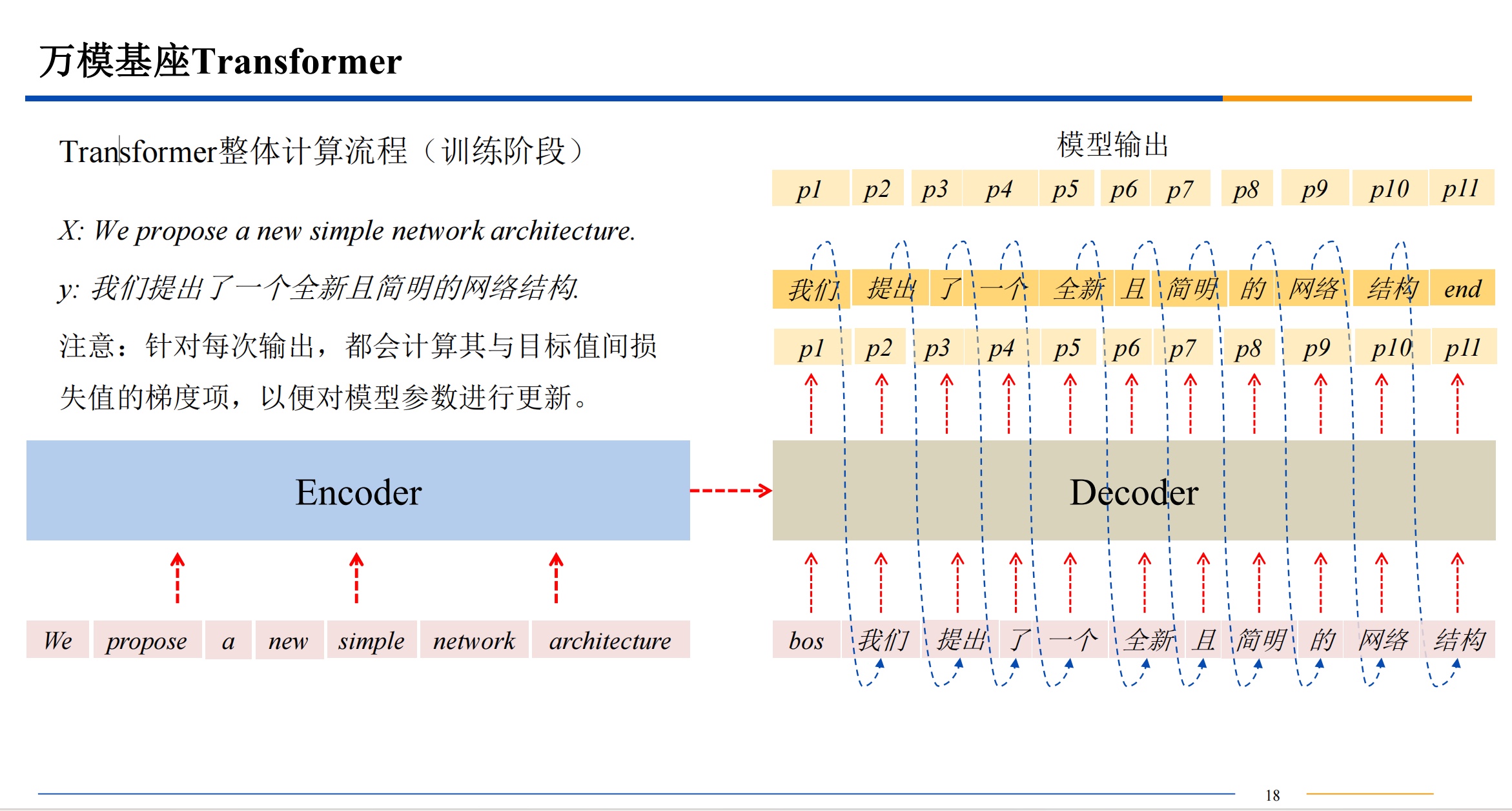
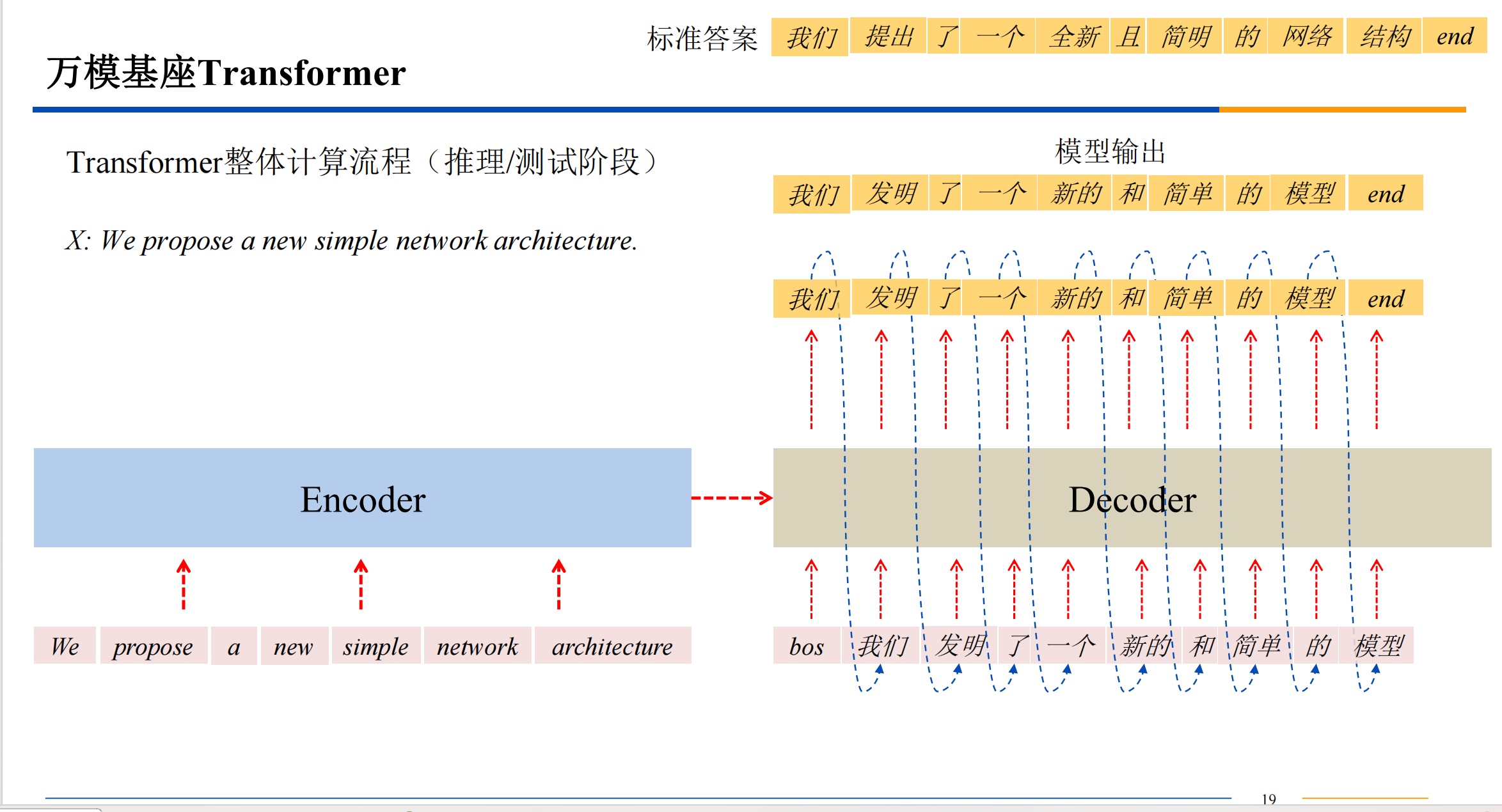
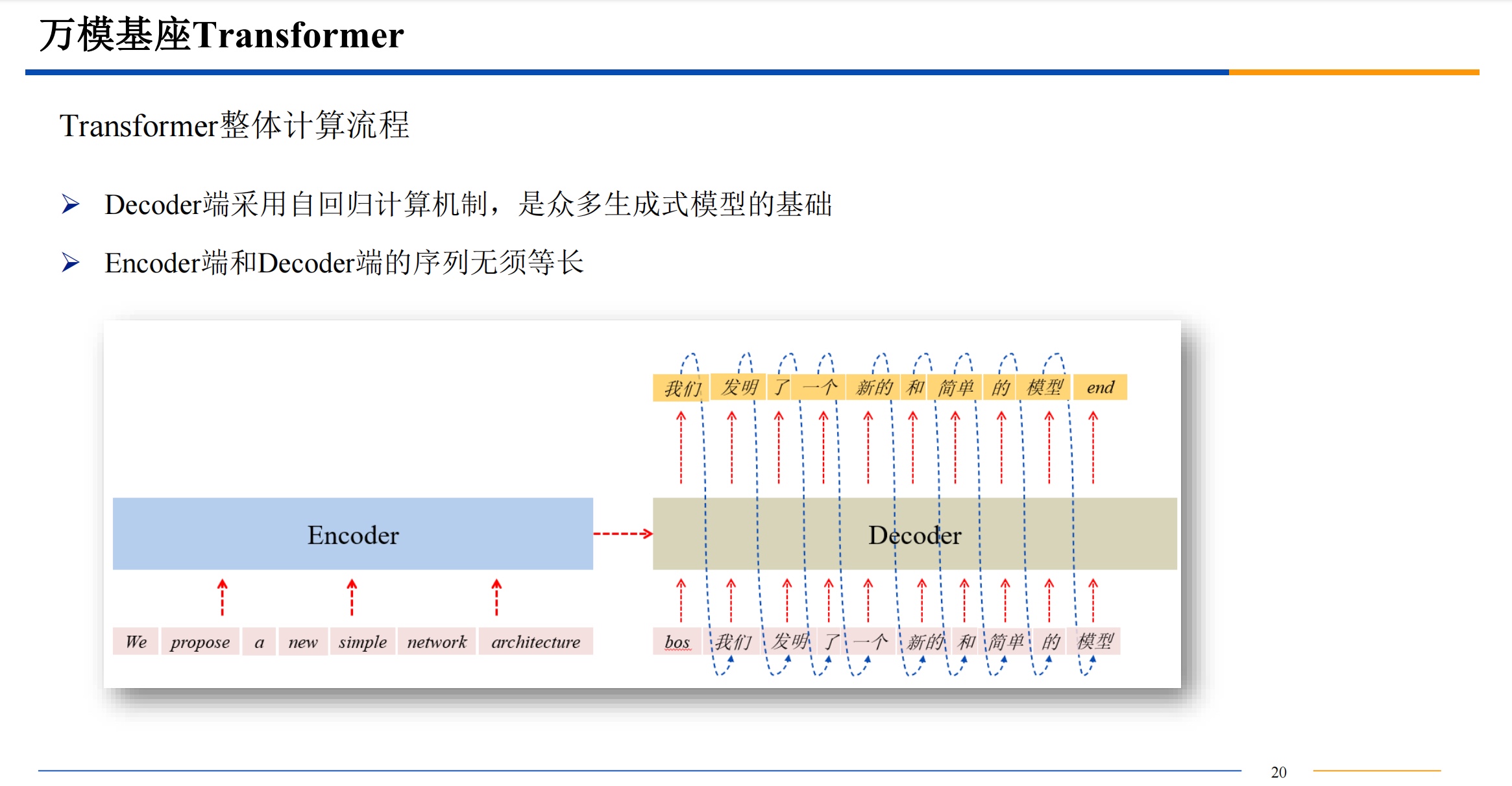
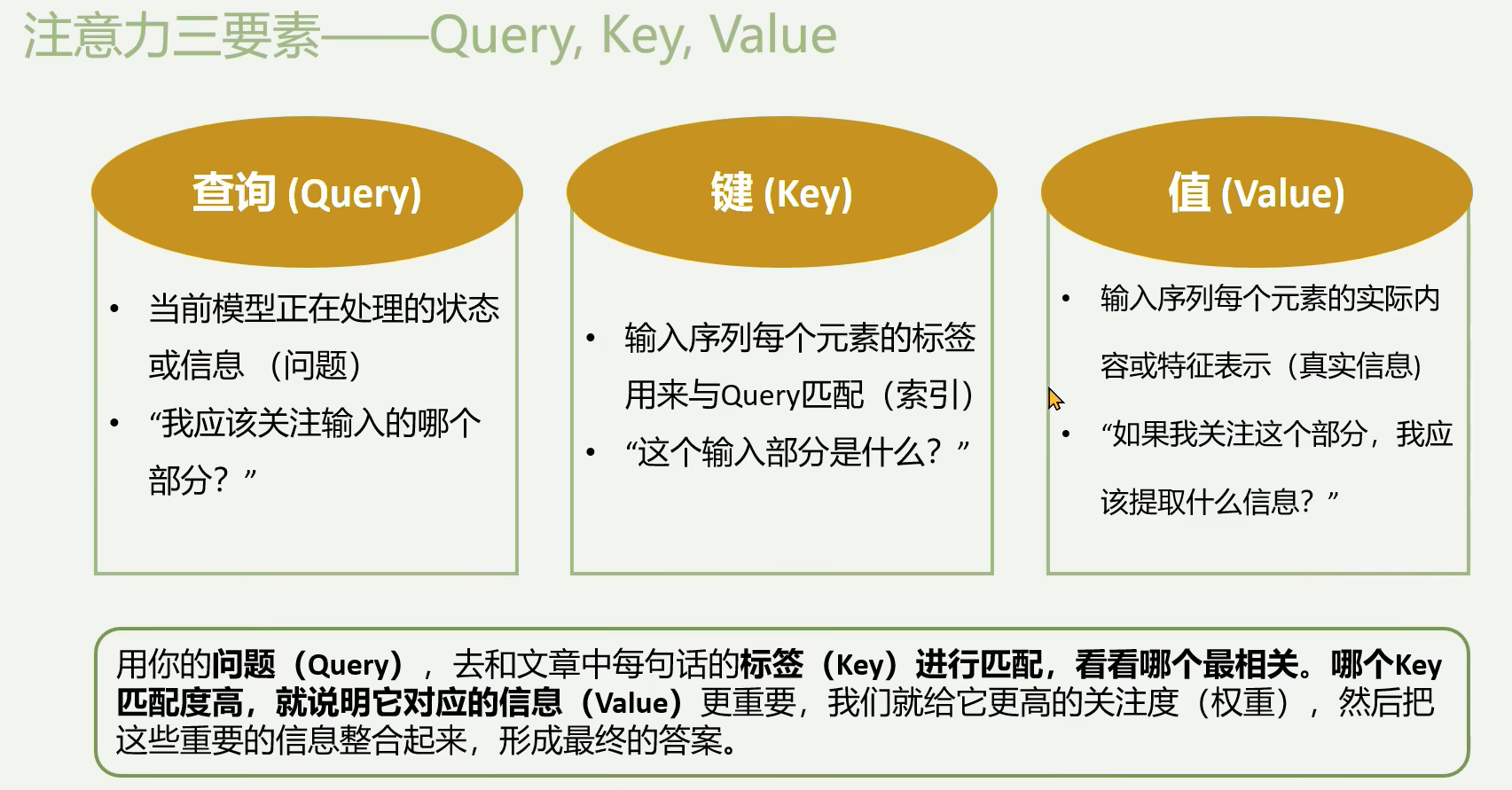
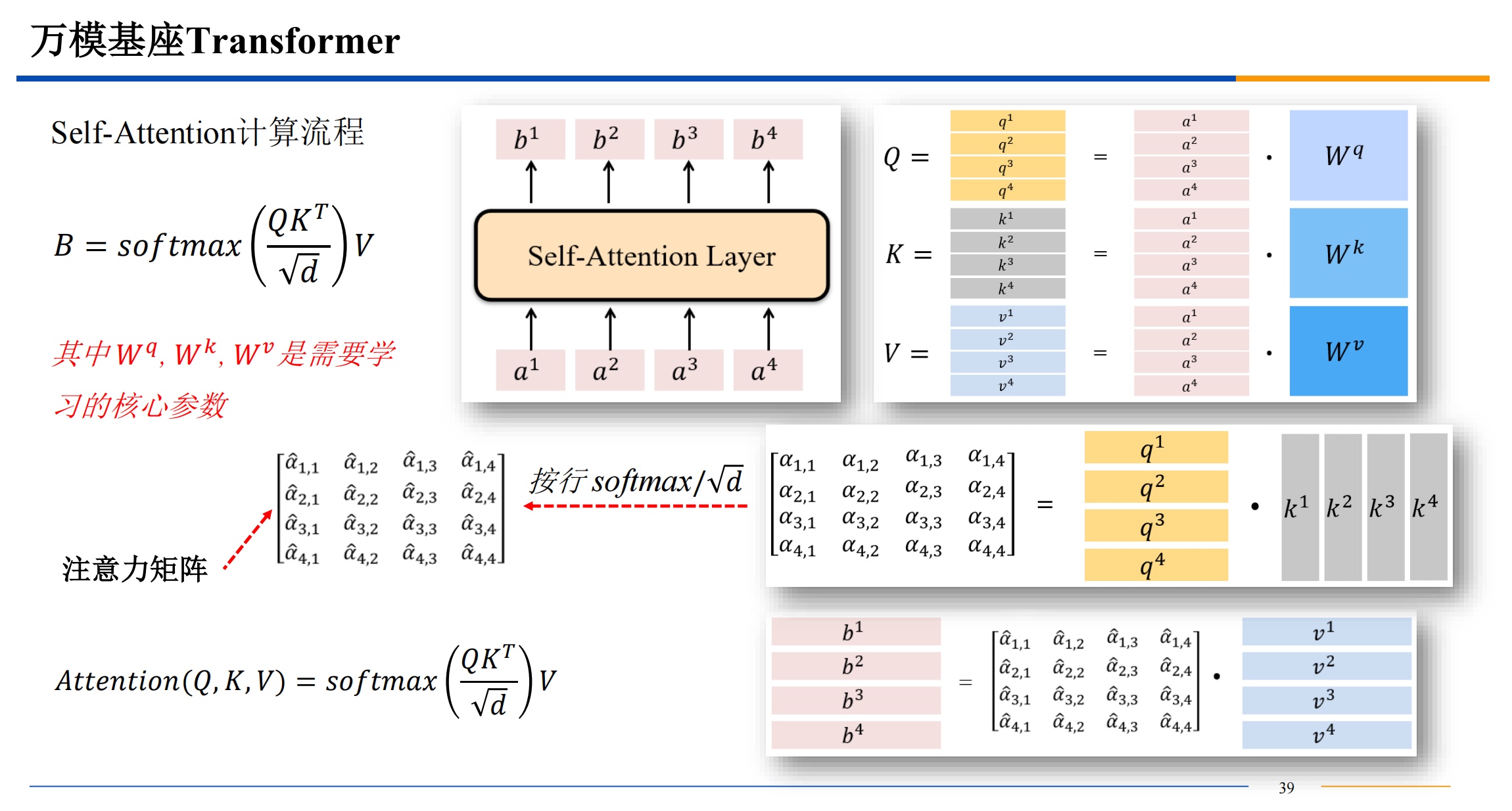
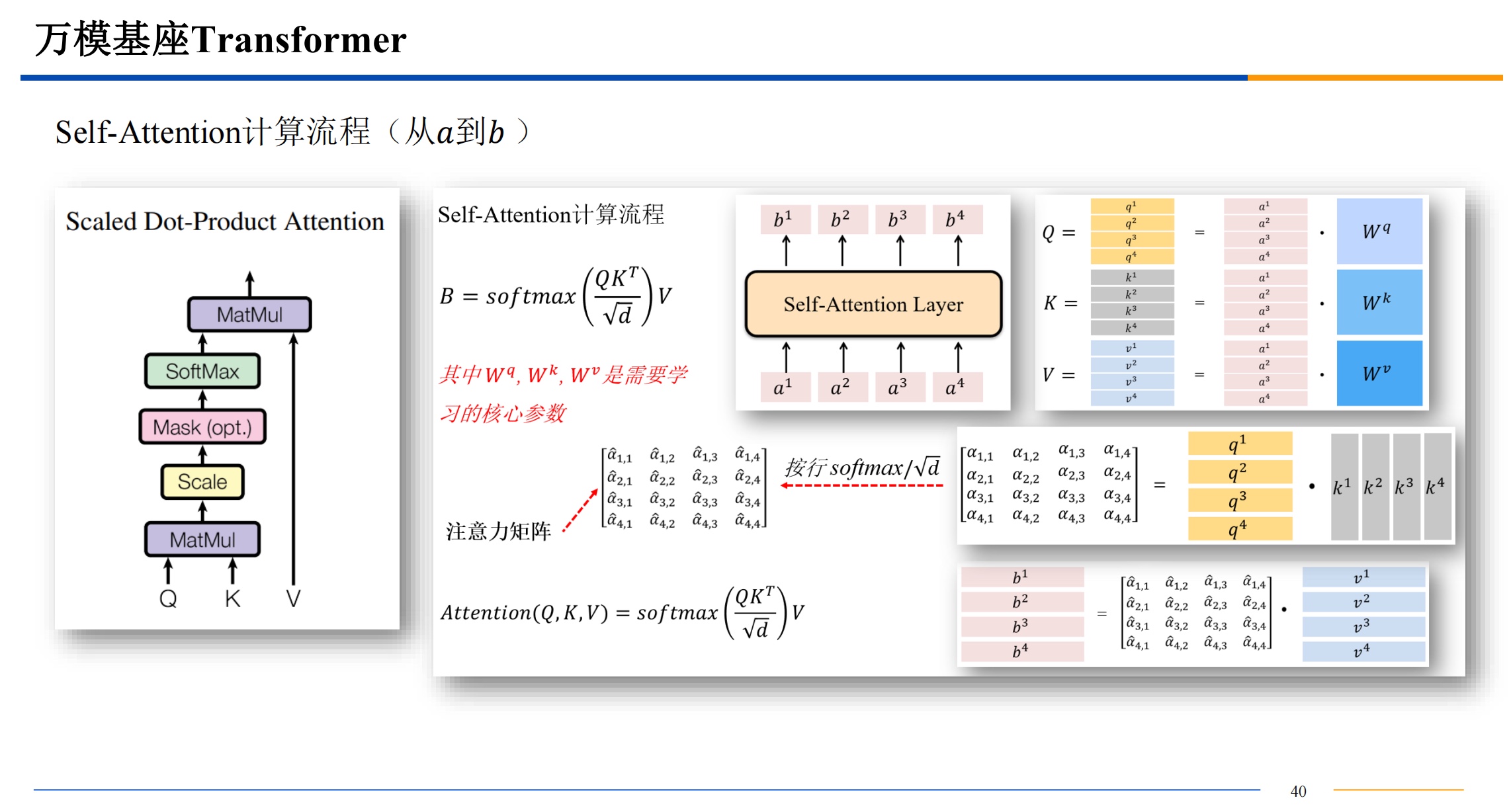
自注意力机制
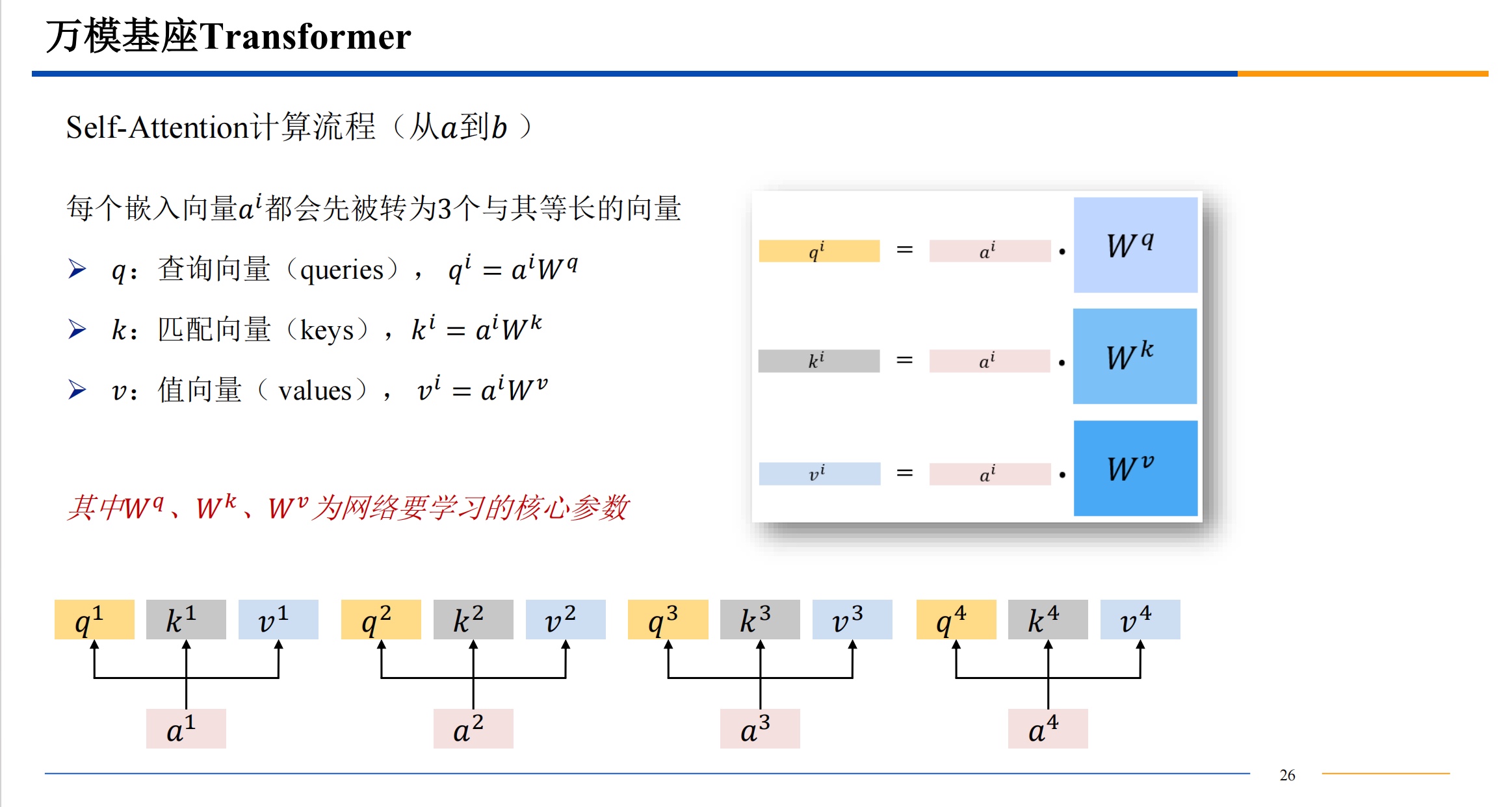

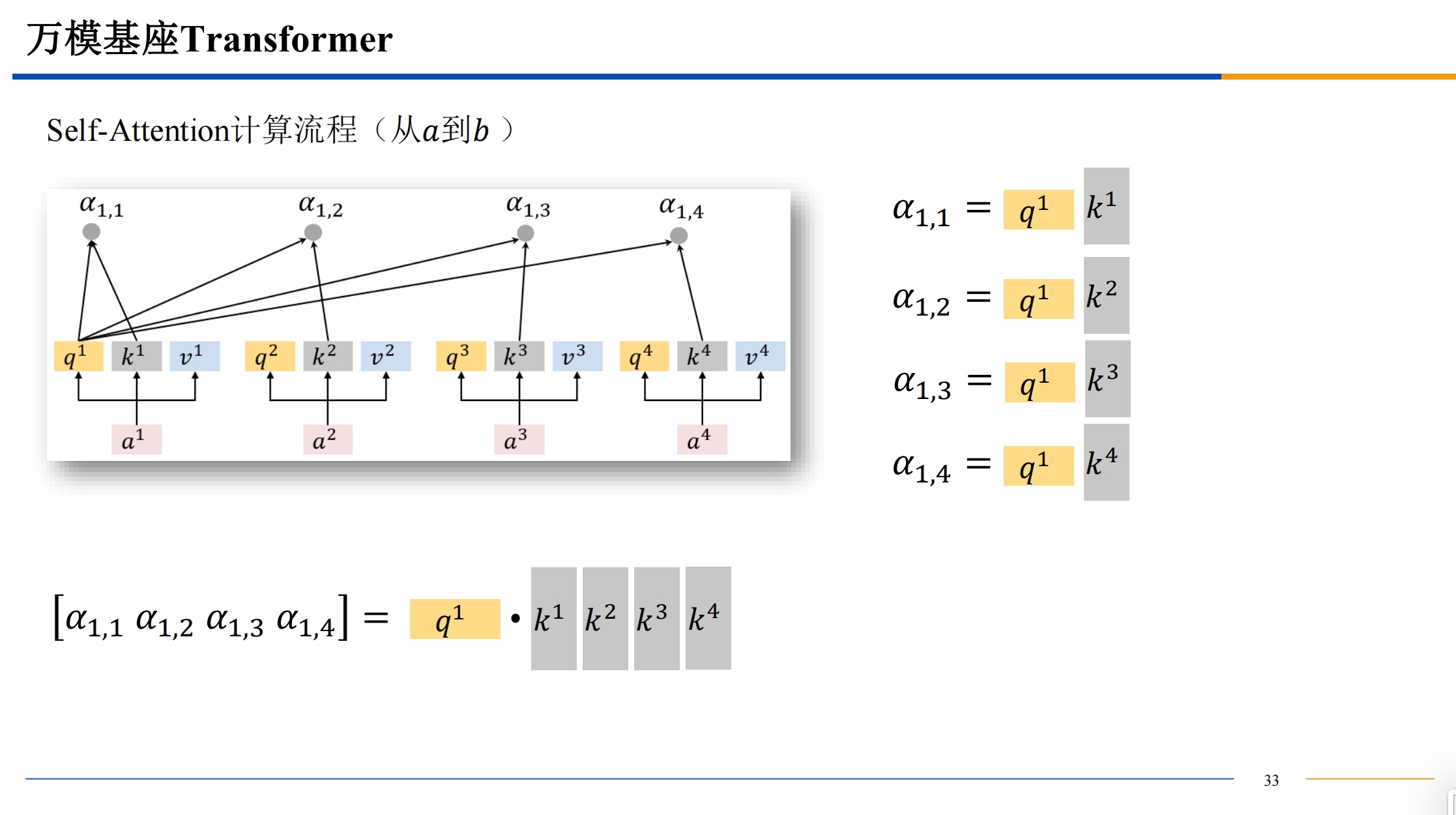
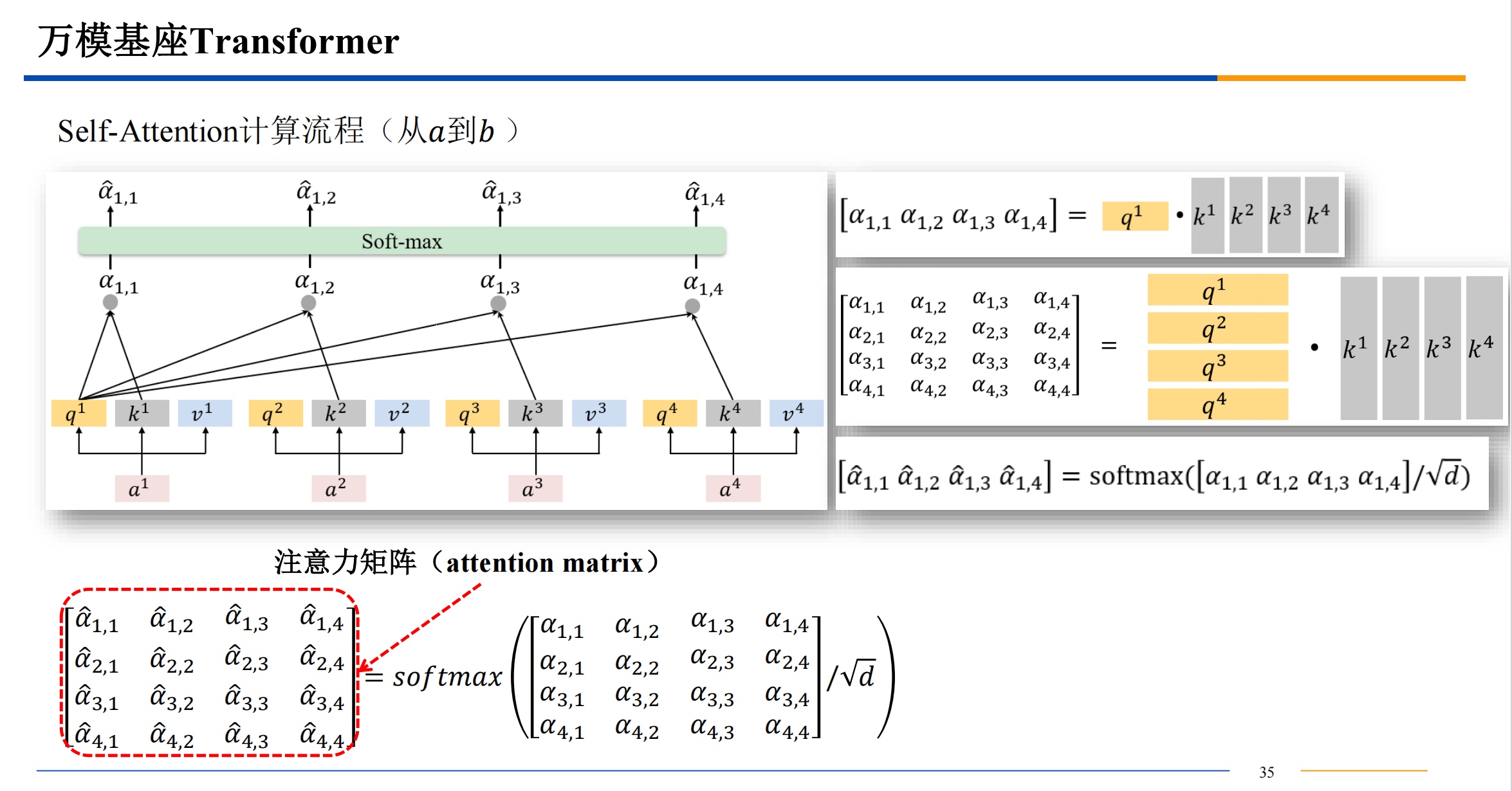
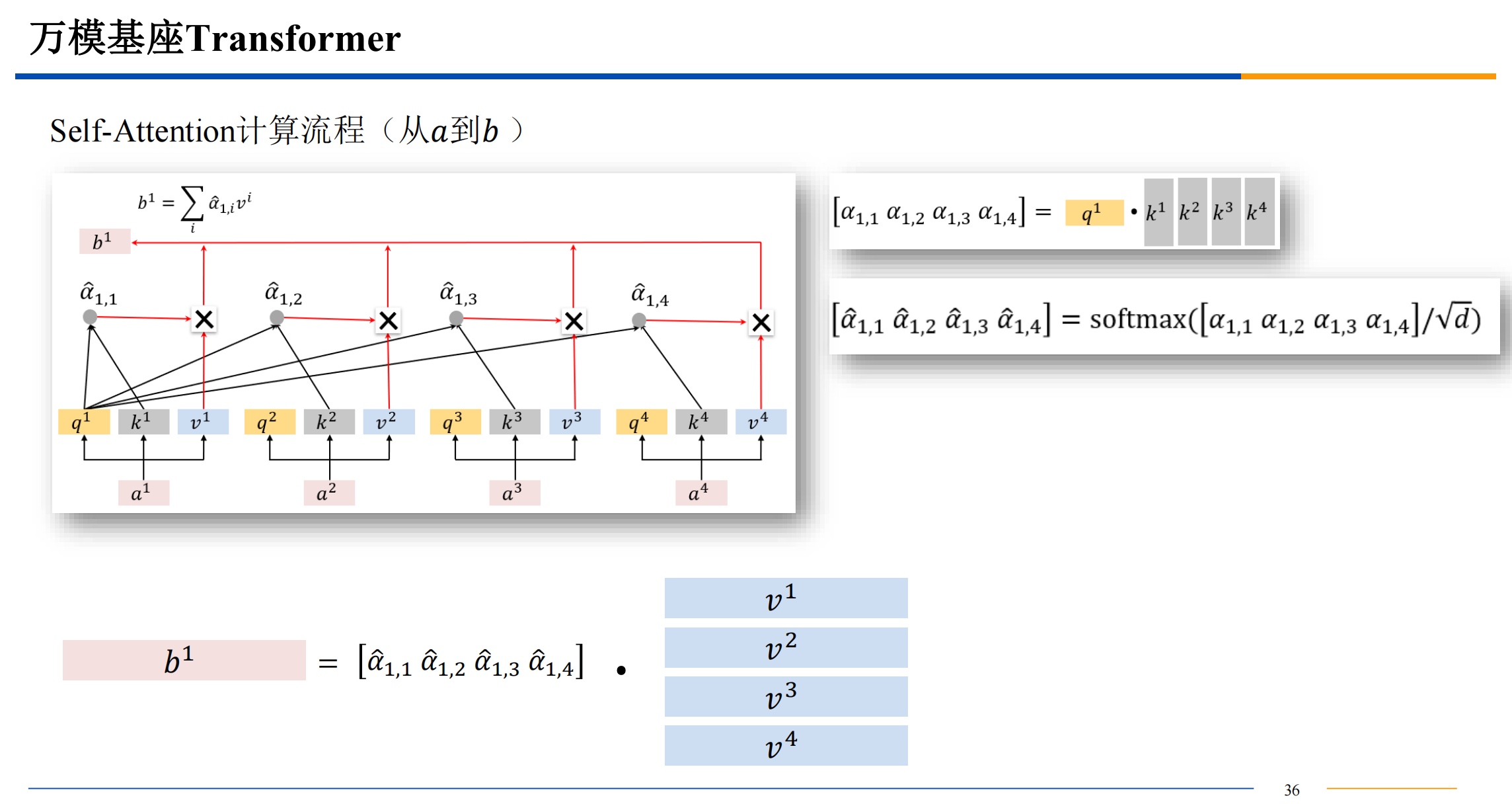
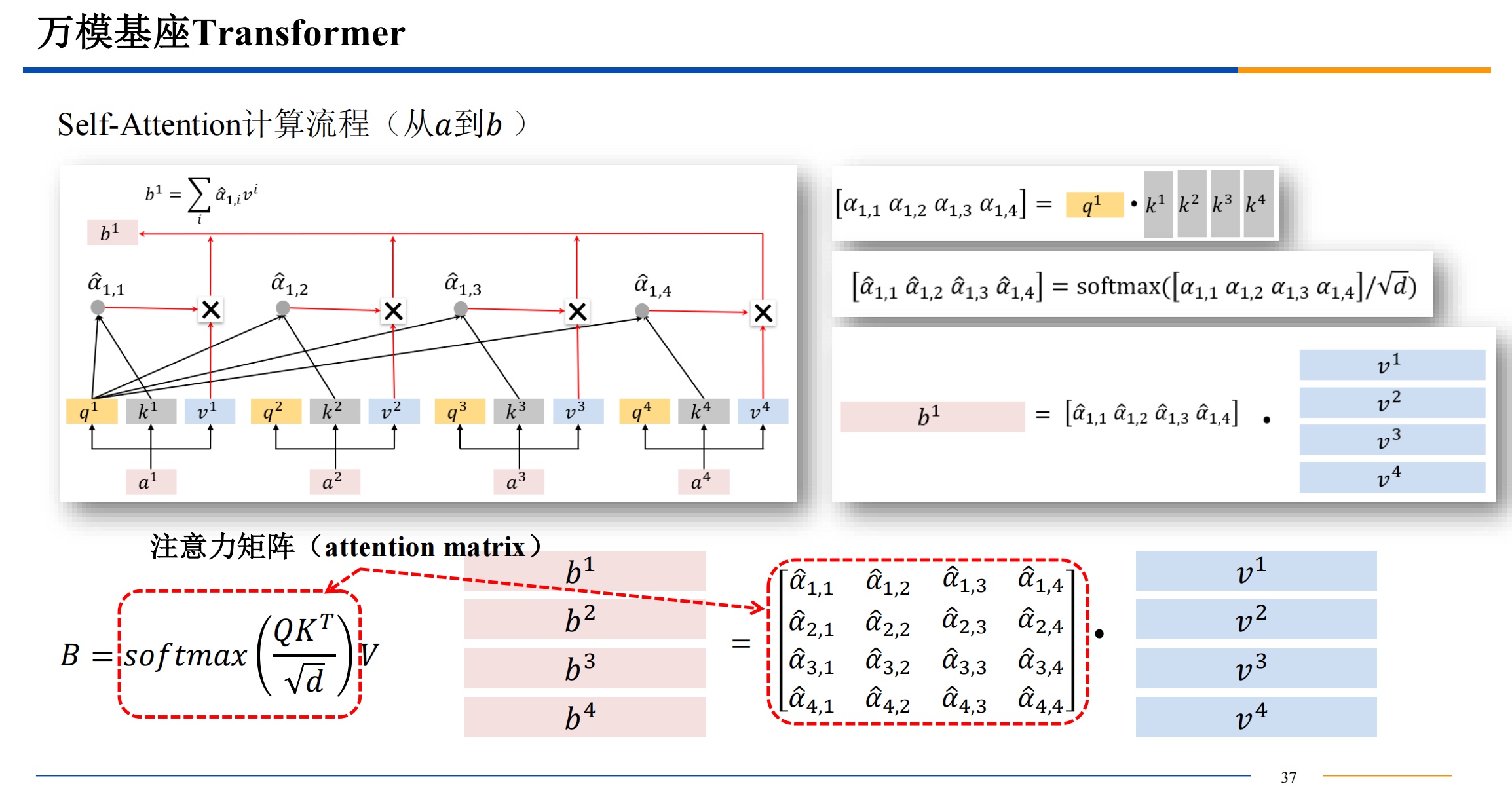
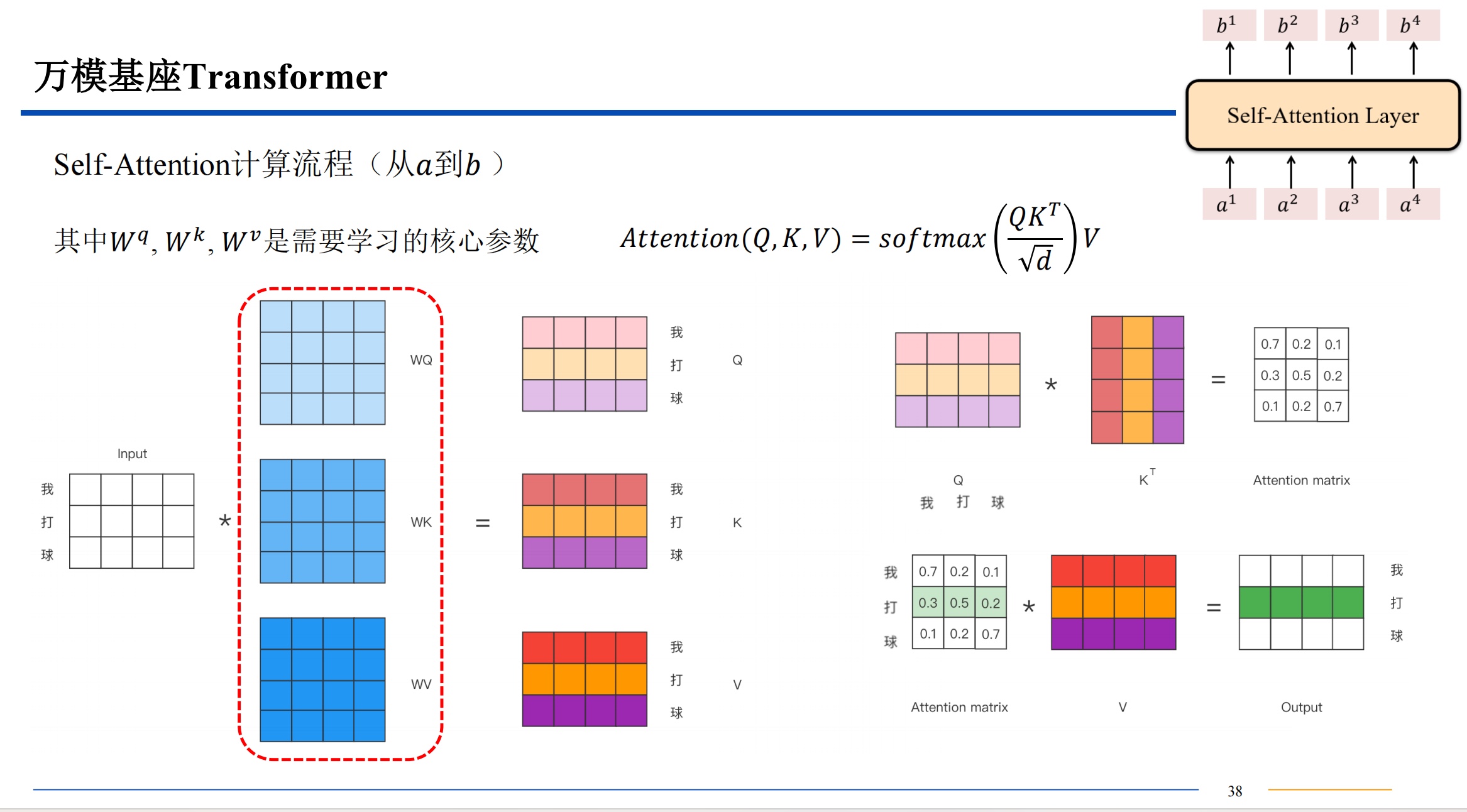
需要提一下,QKV三者的维度是一样的。dk 是key 的维度也是其他三者的维度,比如512维。
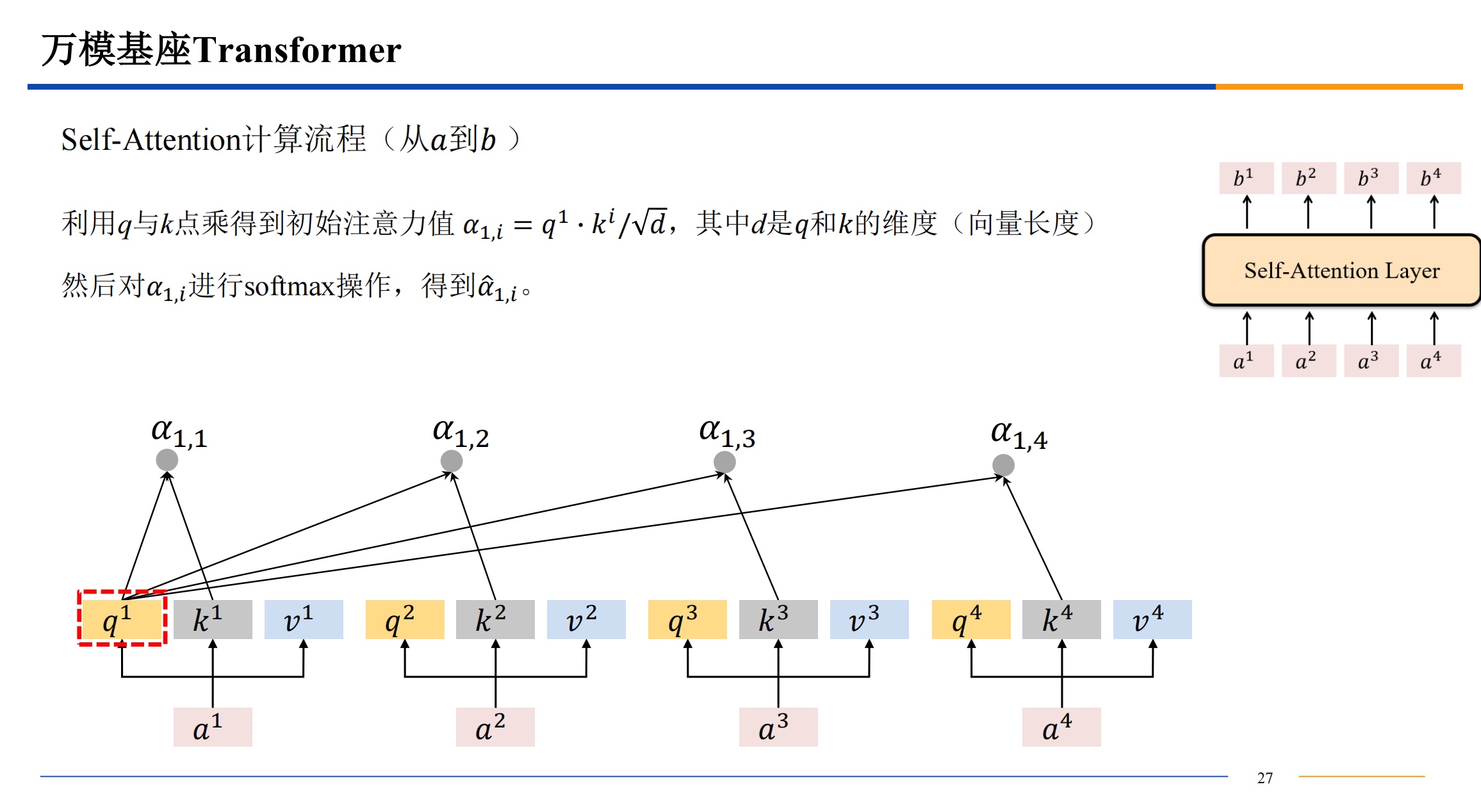
计算相似度的方法有很多,不一定都是用点积,有高斯距离等等其他的计算相似度的方法都是可以选择的。点积的话结果越大,相似度越高。
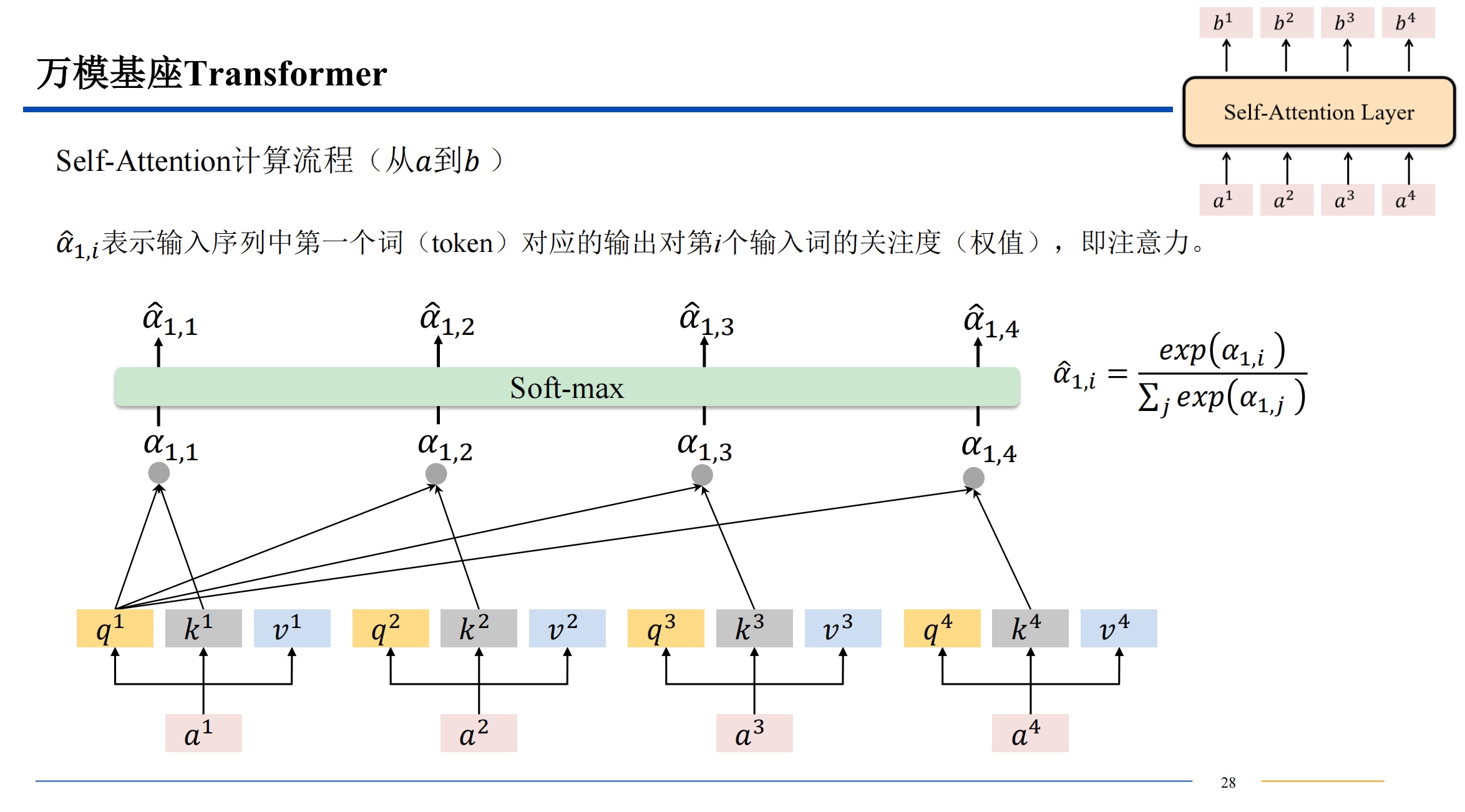
softmax 算出来的 都是 0-1 之间的值,来把前面的结果变成概率。
如果直接用点积结果进入softmax 可能导致概率极大和概率极小,导致梯度爆炸或者消失,所以点积结果除一下根号的维度,来让最后softmax输出的数据变柔和一些。
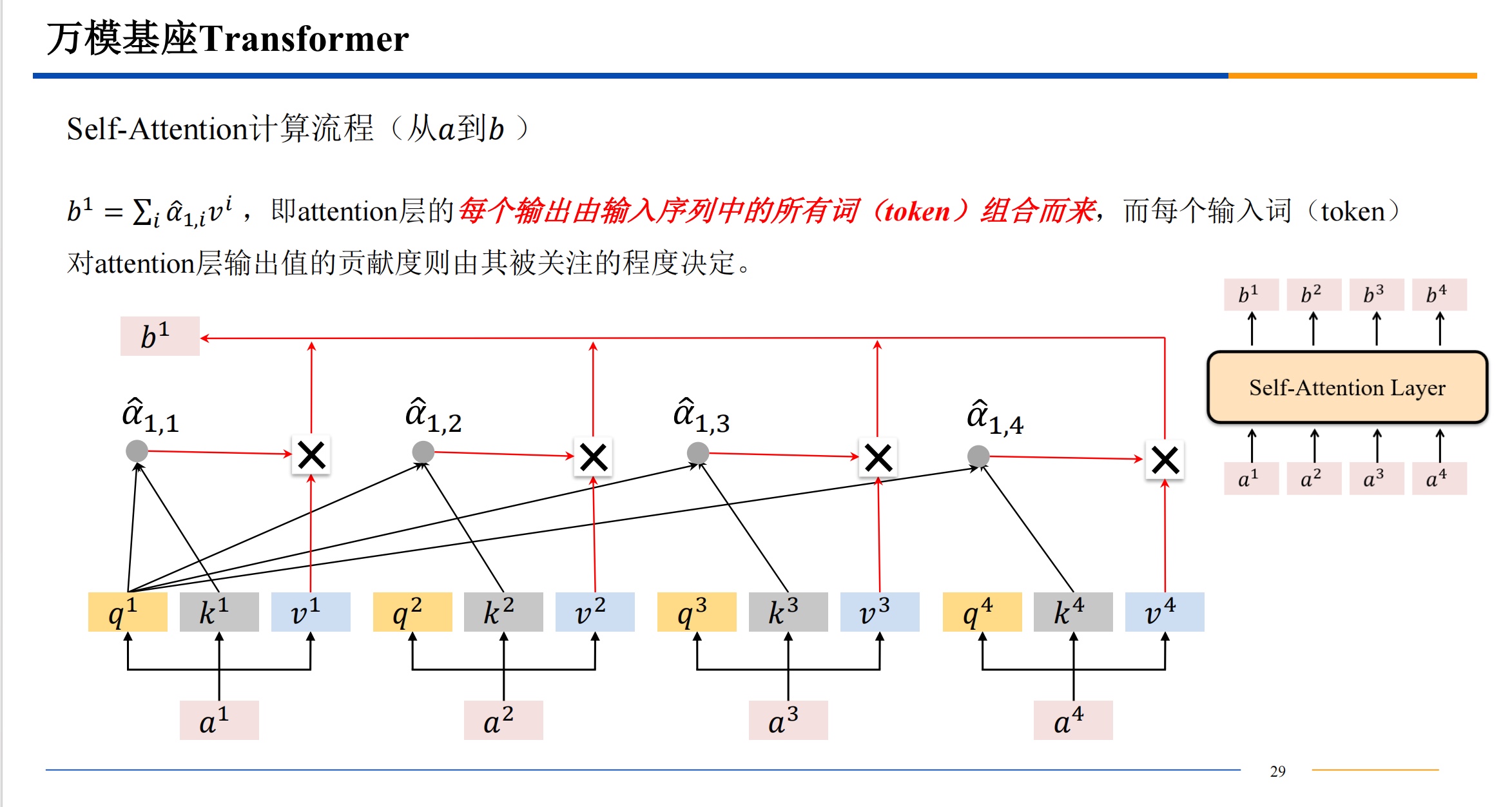
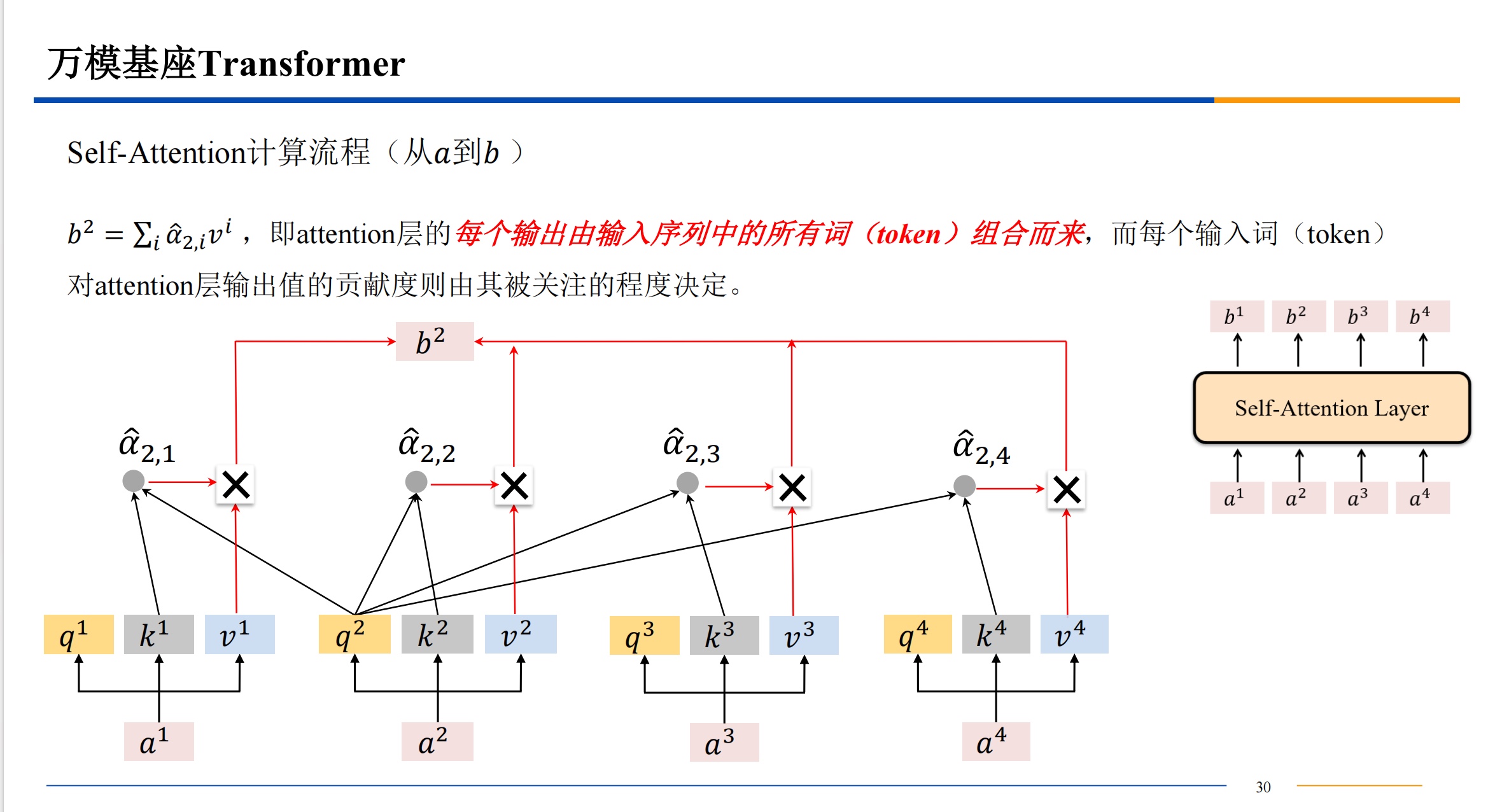


总结
Q、K、V 来自同一组输入的时候,就是自注意力。它相当于注意力机制中的一个特例。
小明看小红长相就是注意力机制,小红自己看自己就是自注意力机制。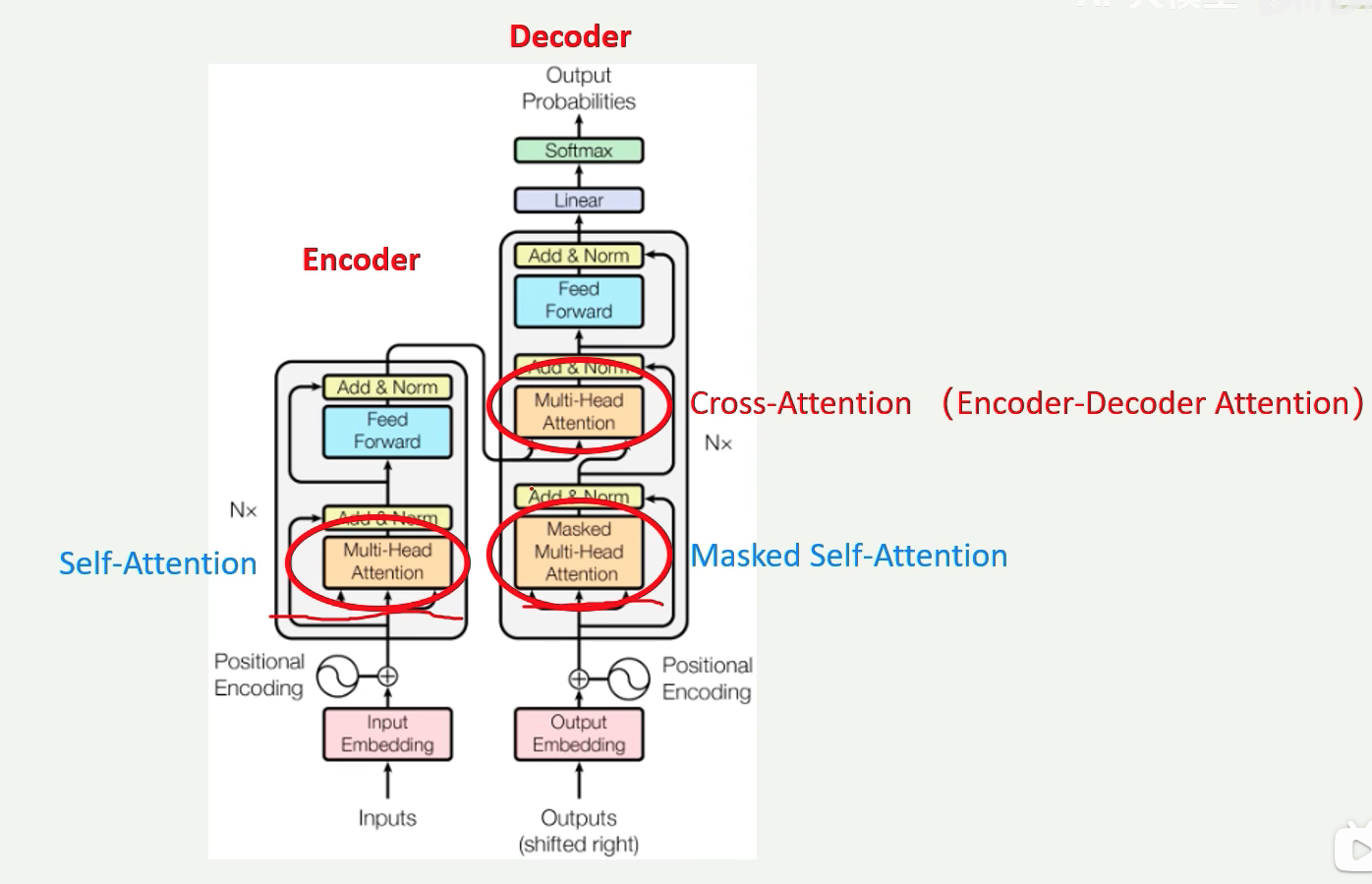
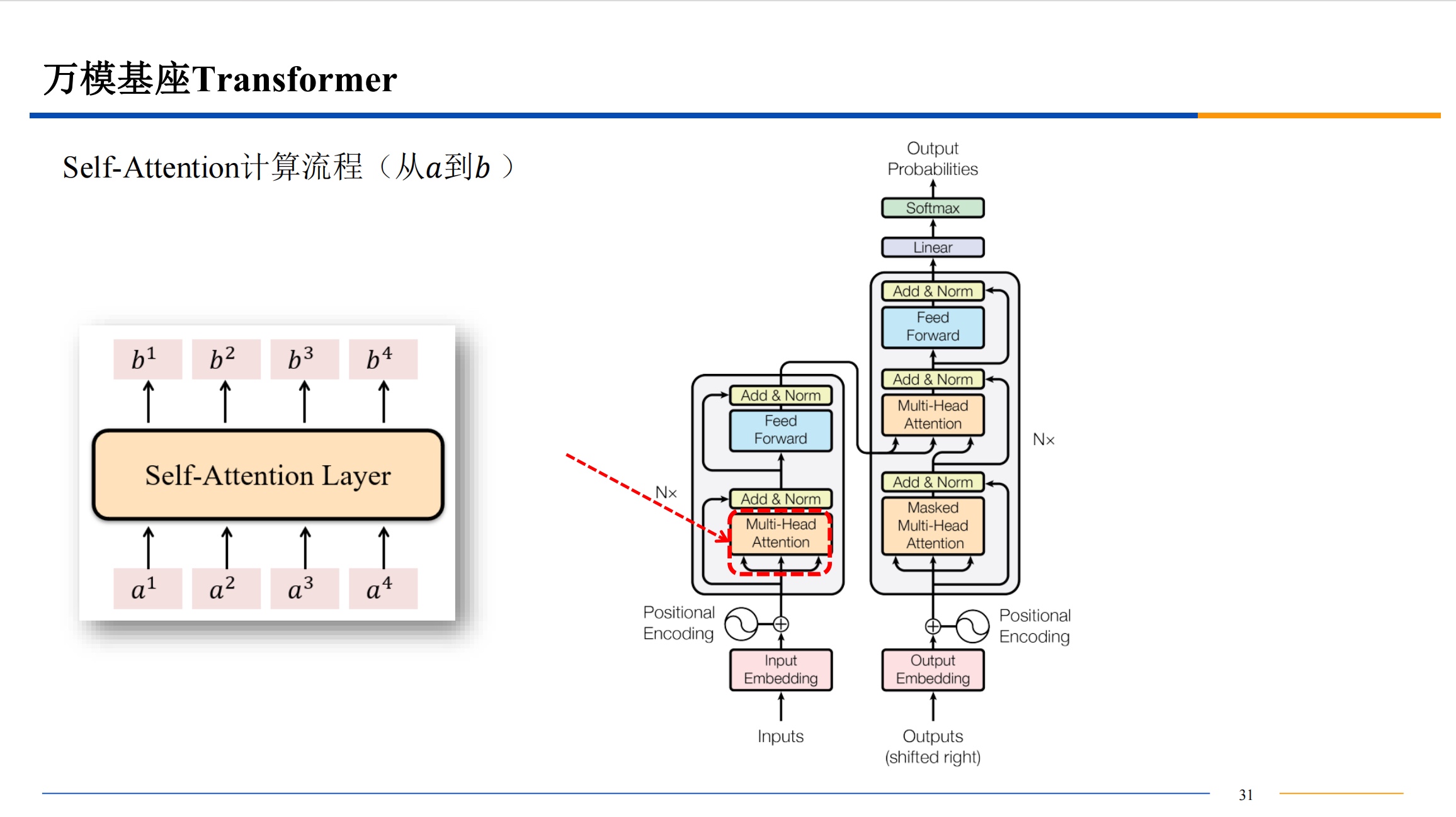
注意上面的Attention部分,只有左边的是自注意力机制,右边上面是交叉注意力机制,右边下面是掩码注意力机制,
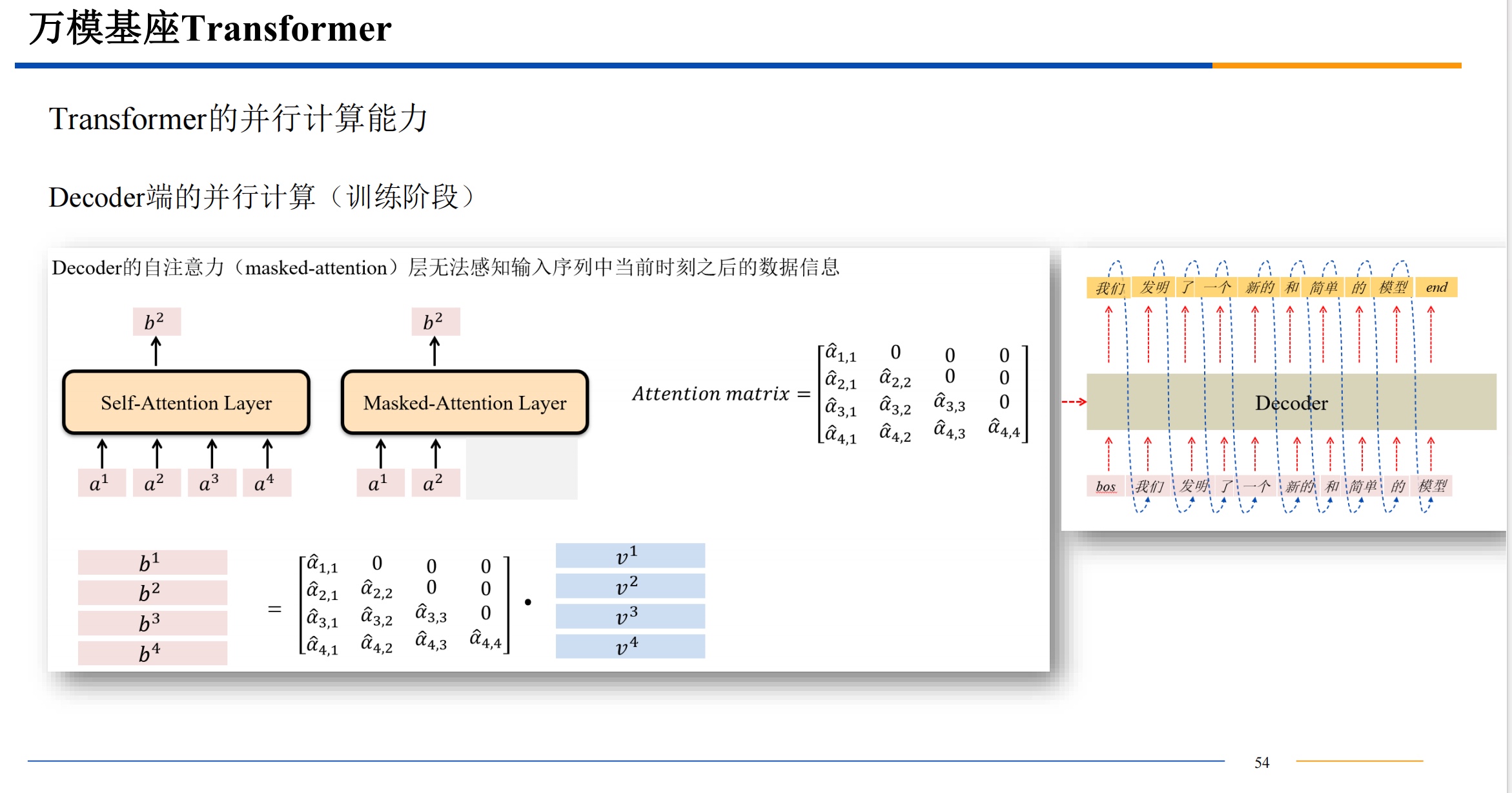
- 所谓 “掩码注意力机制” 用一个例子说明:【我吃零食】是预测目标,在预测时不能把目标全部公开,相当于需要闭卷答题,【我 X X X】掩住后面要预测的部分。
- “交叉注意力机制”中,Q 来自于 Decoder 的输入,K、V 来自 Encoder 的输出。【它就不是自注意力机制,因为它有别的地方的输入。】
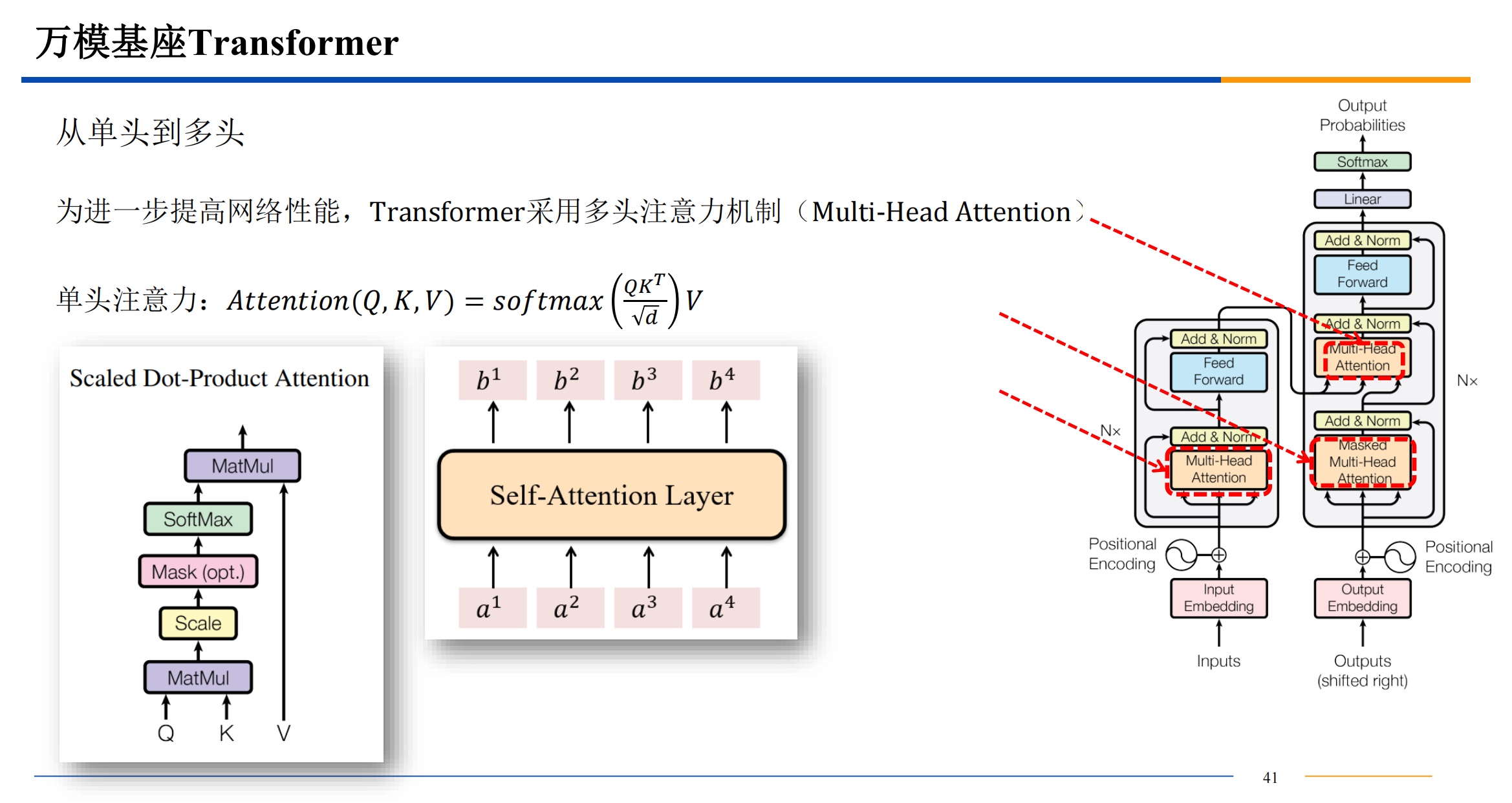
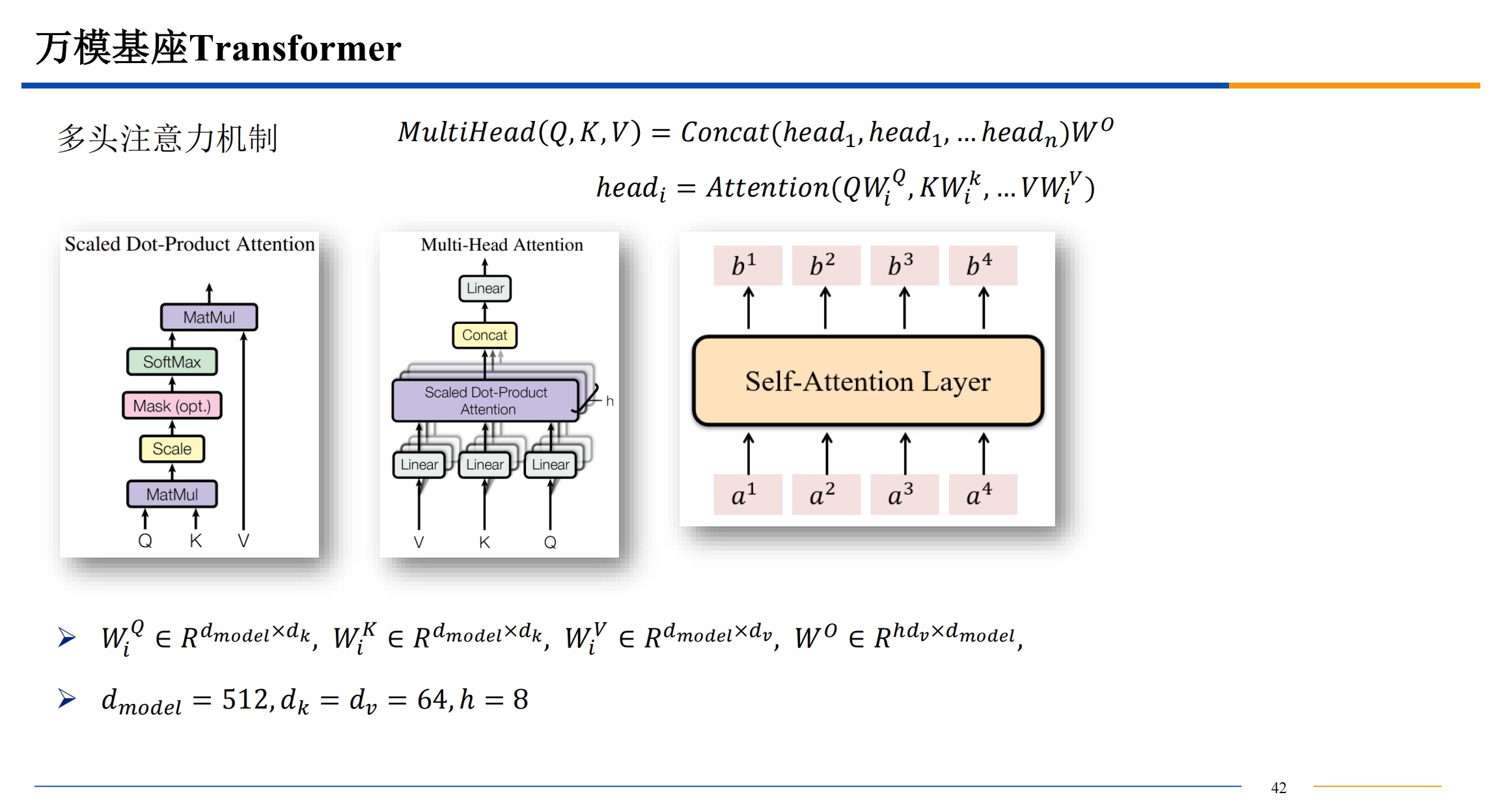
多头注意力机制




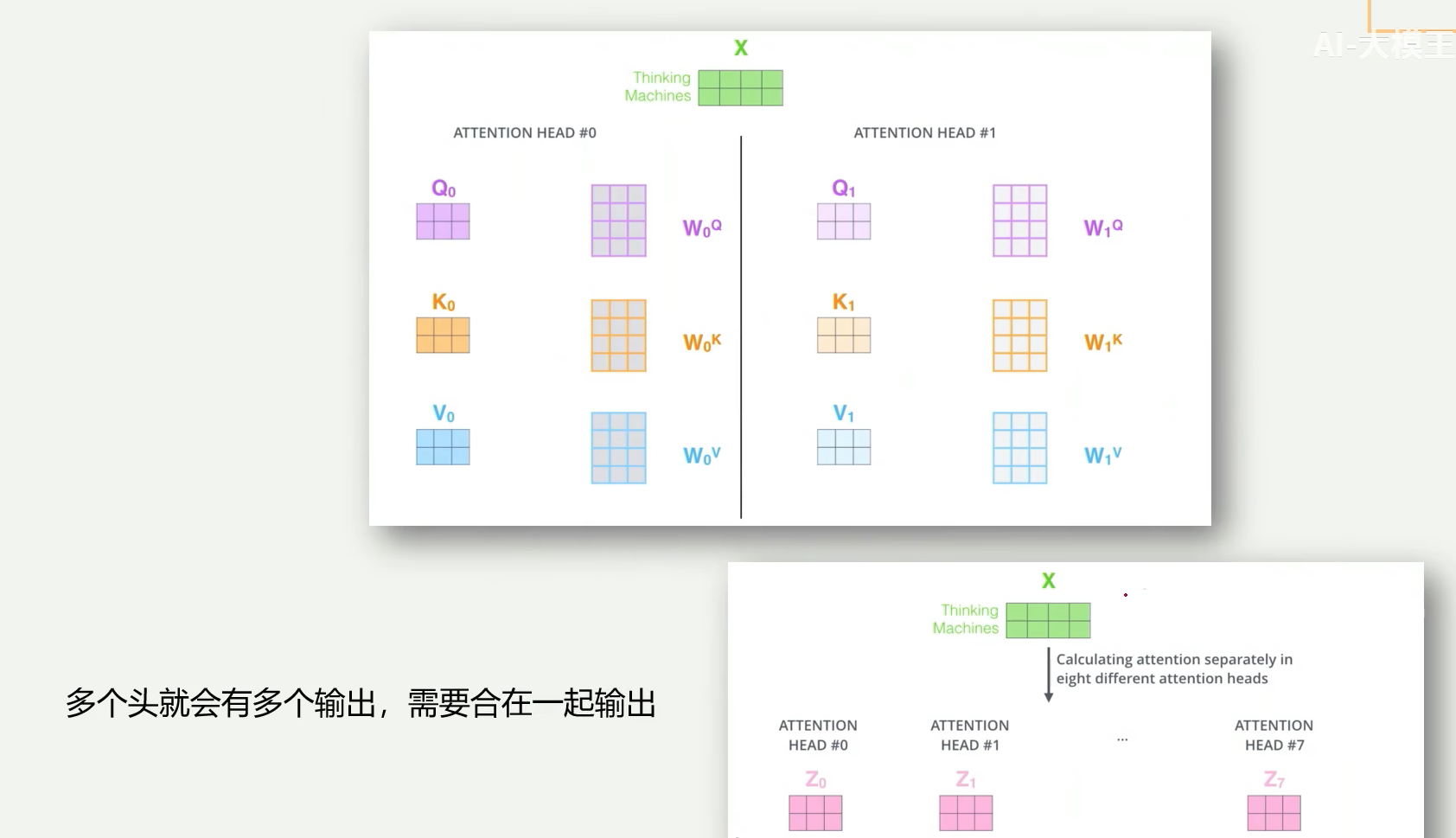
基础演示

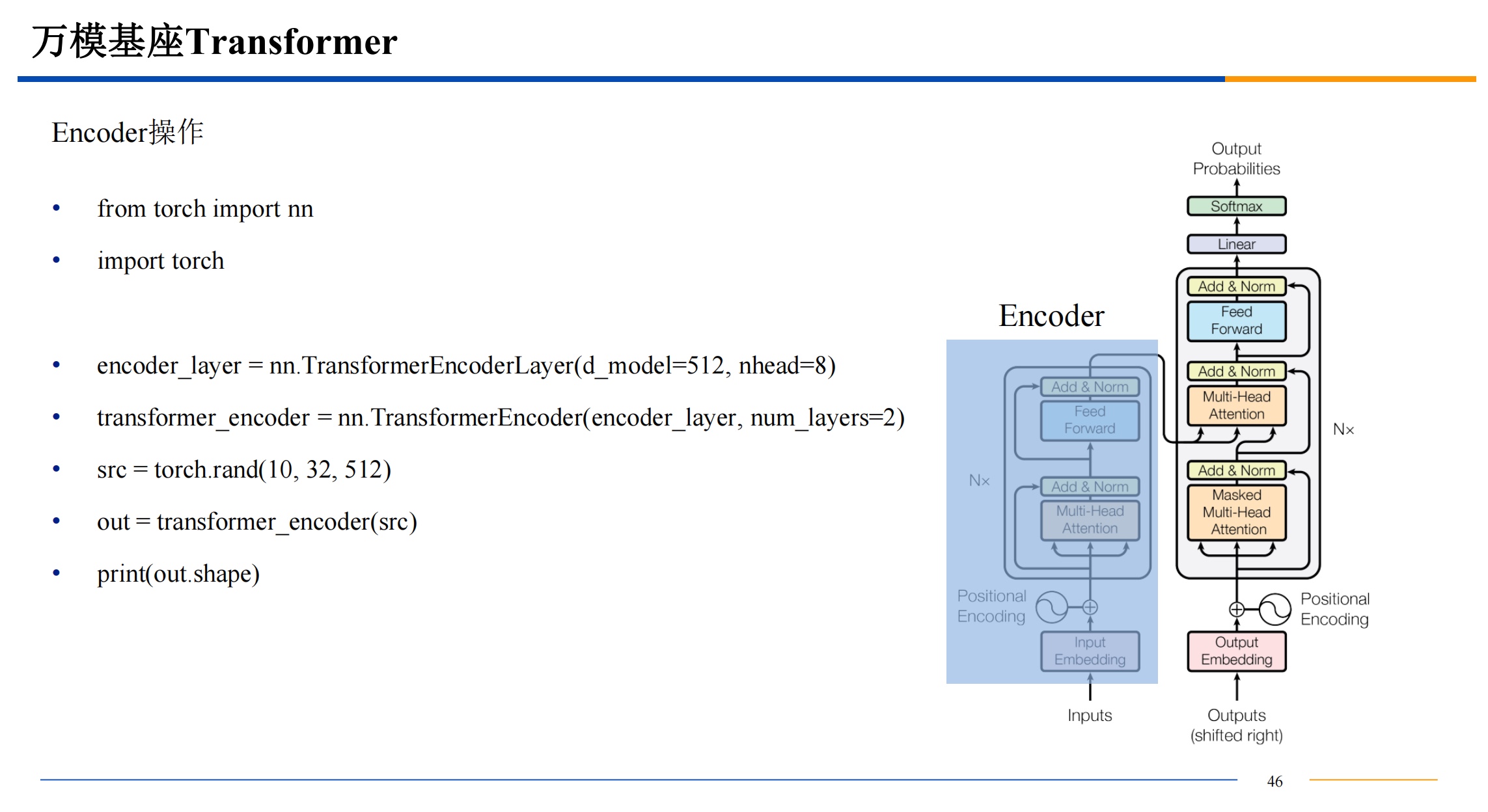
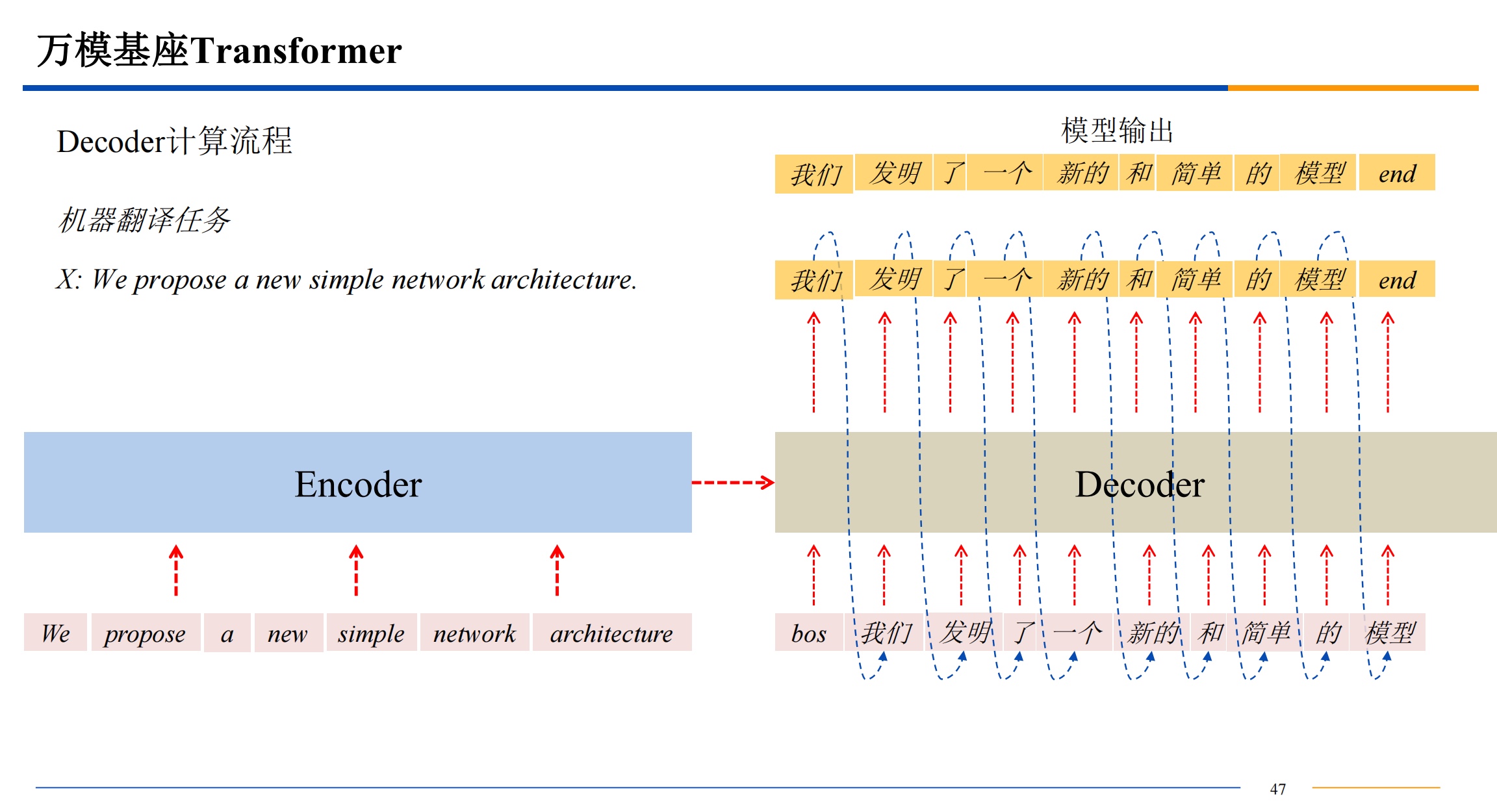
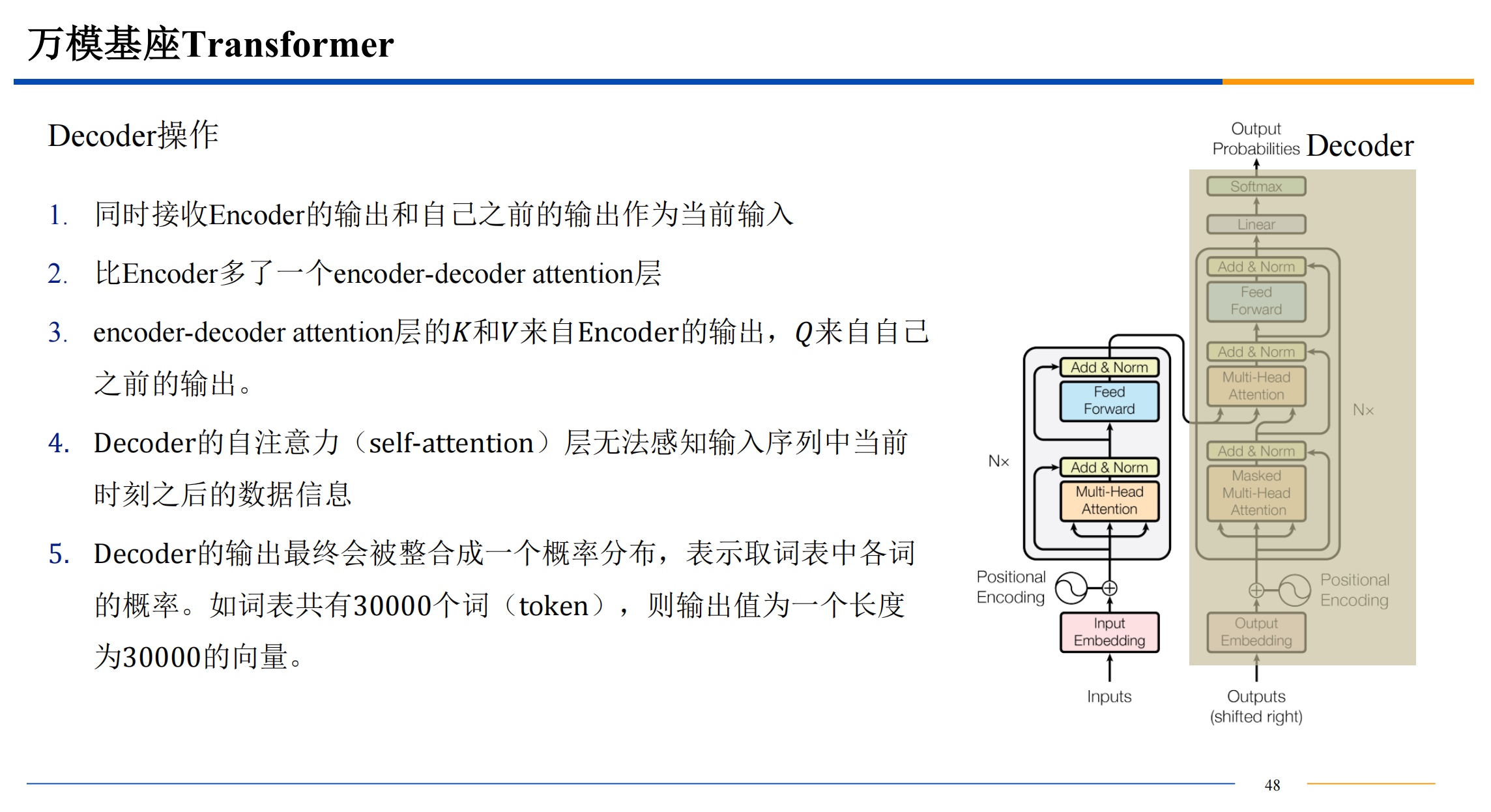
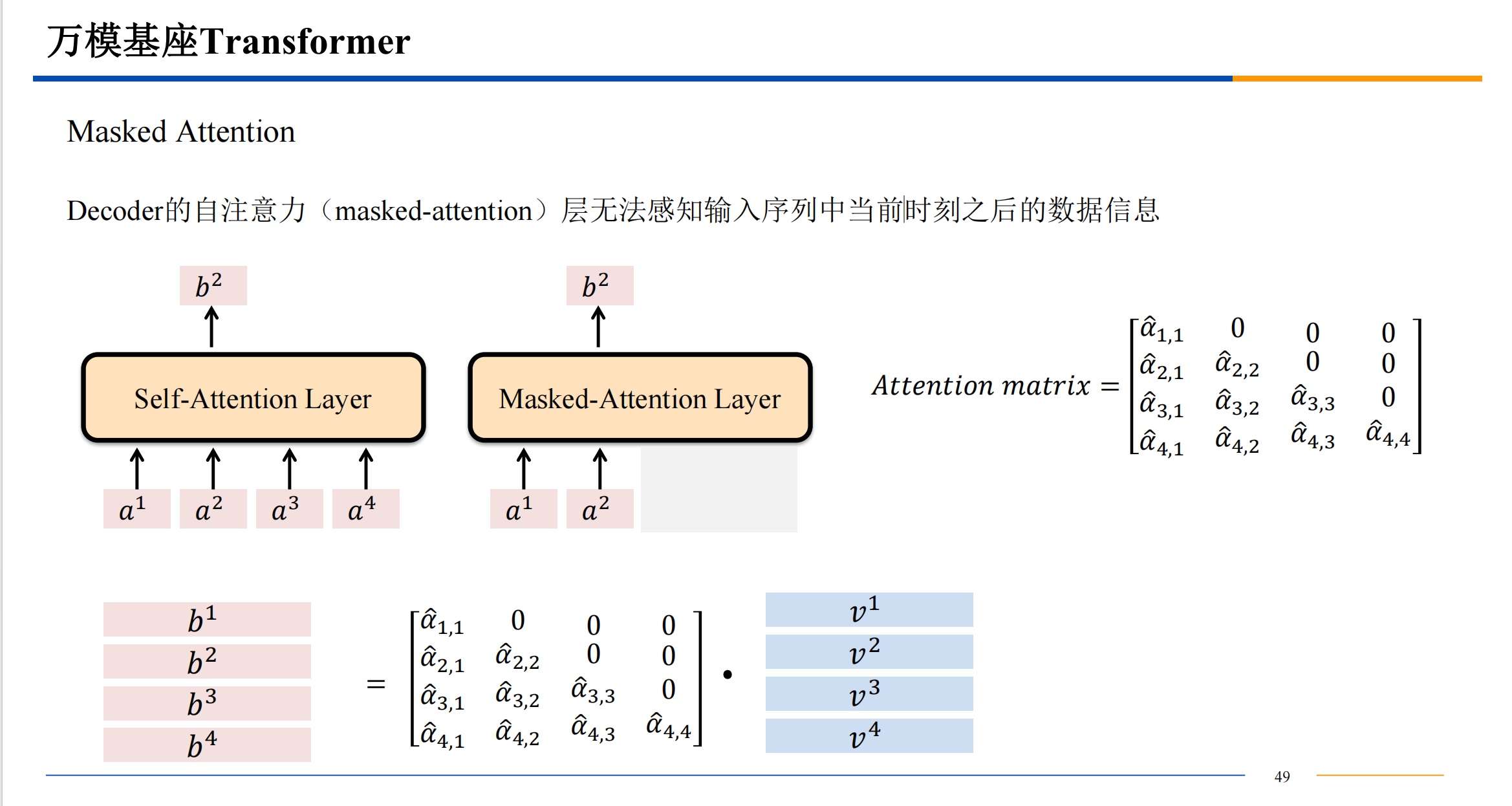

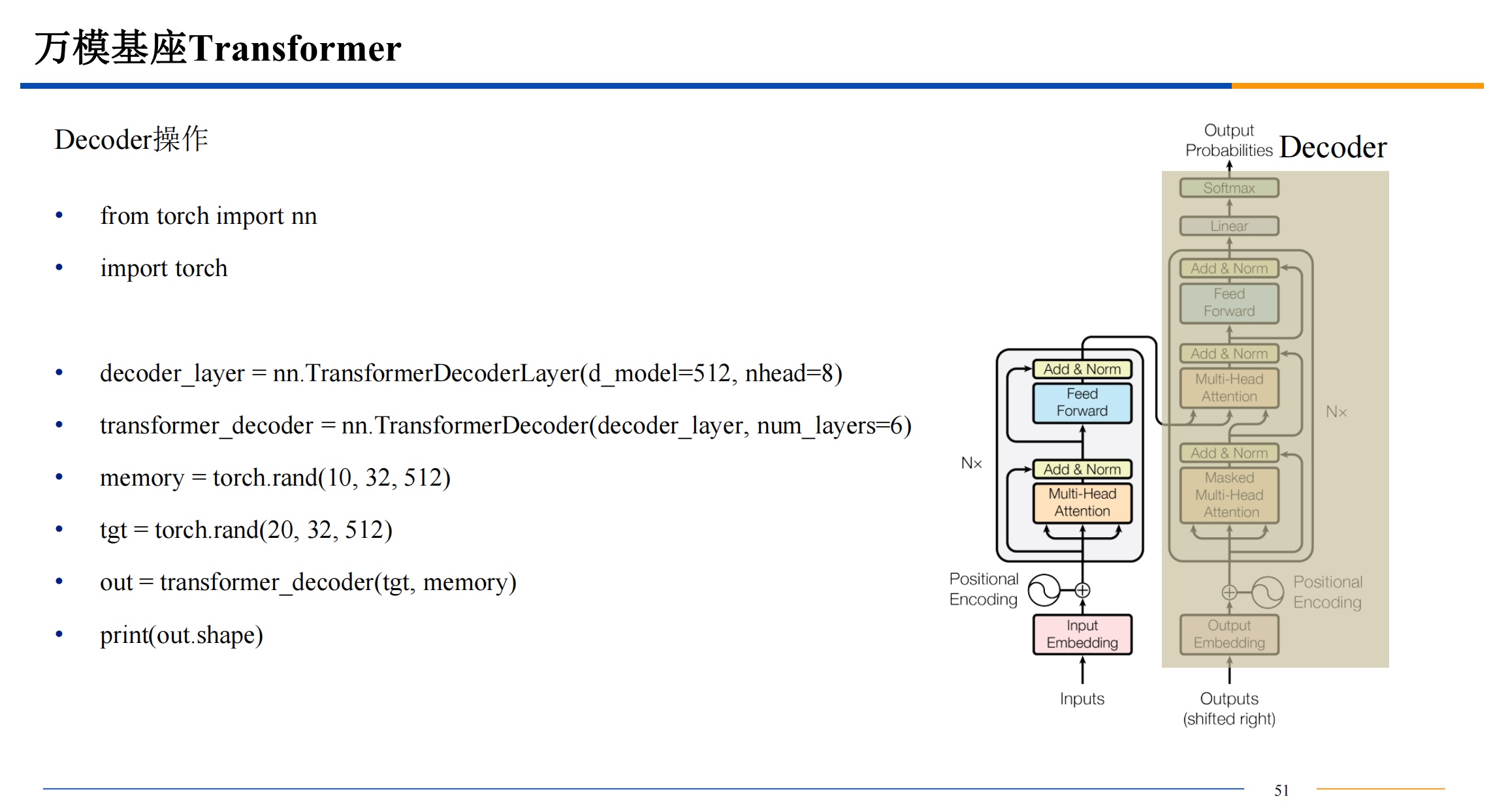
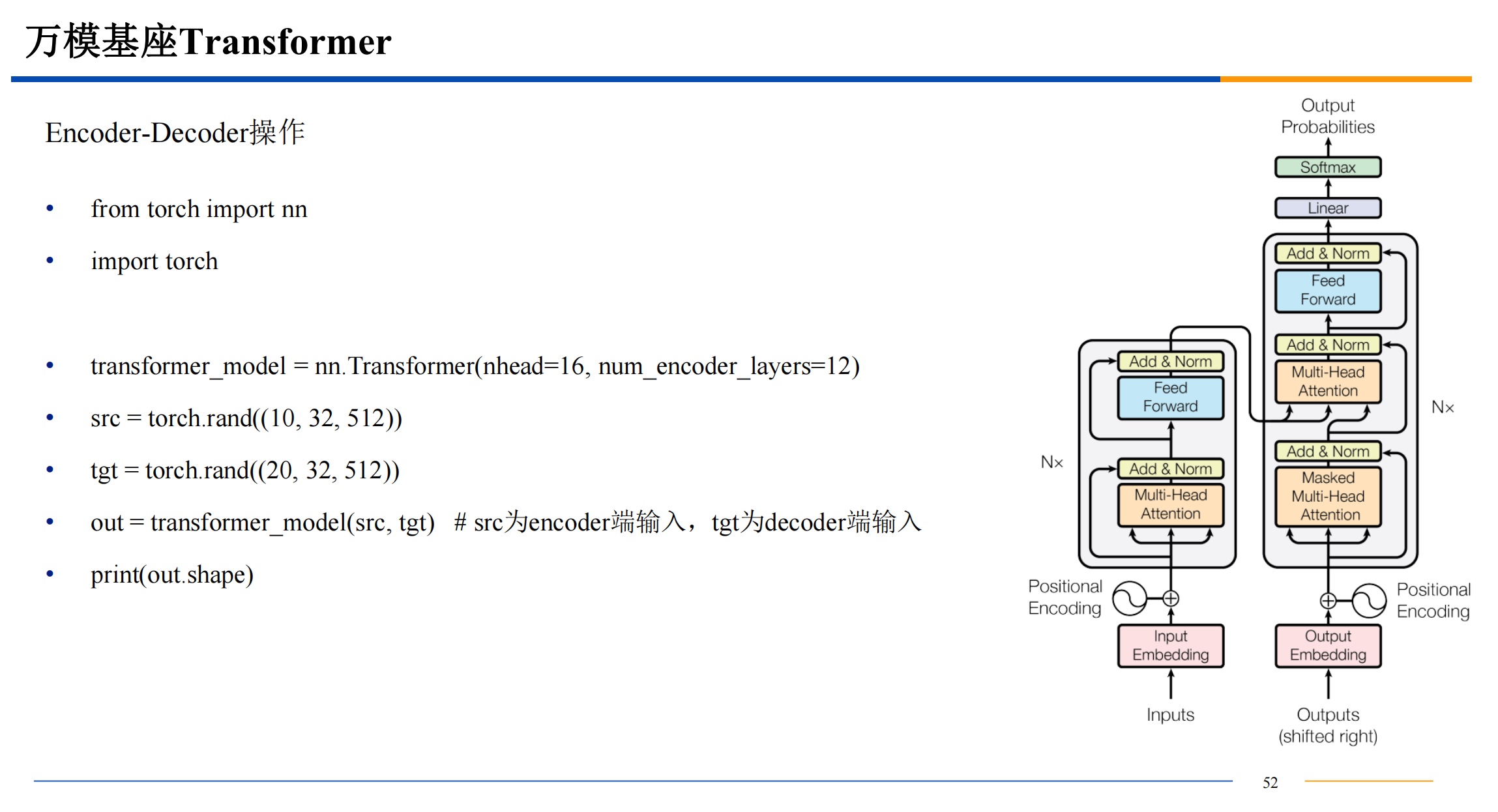
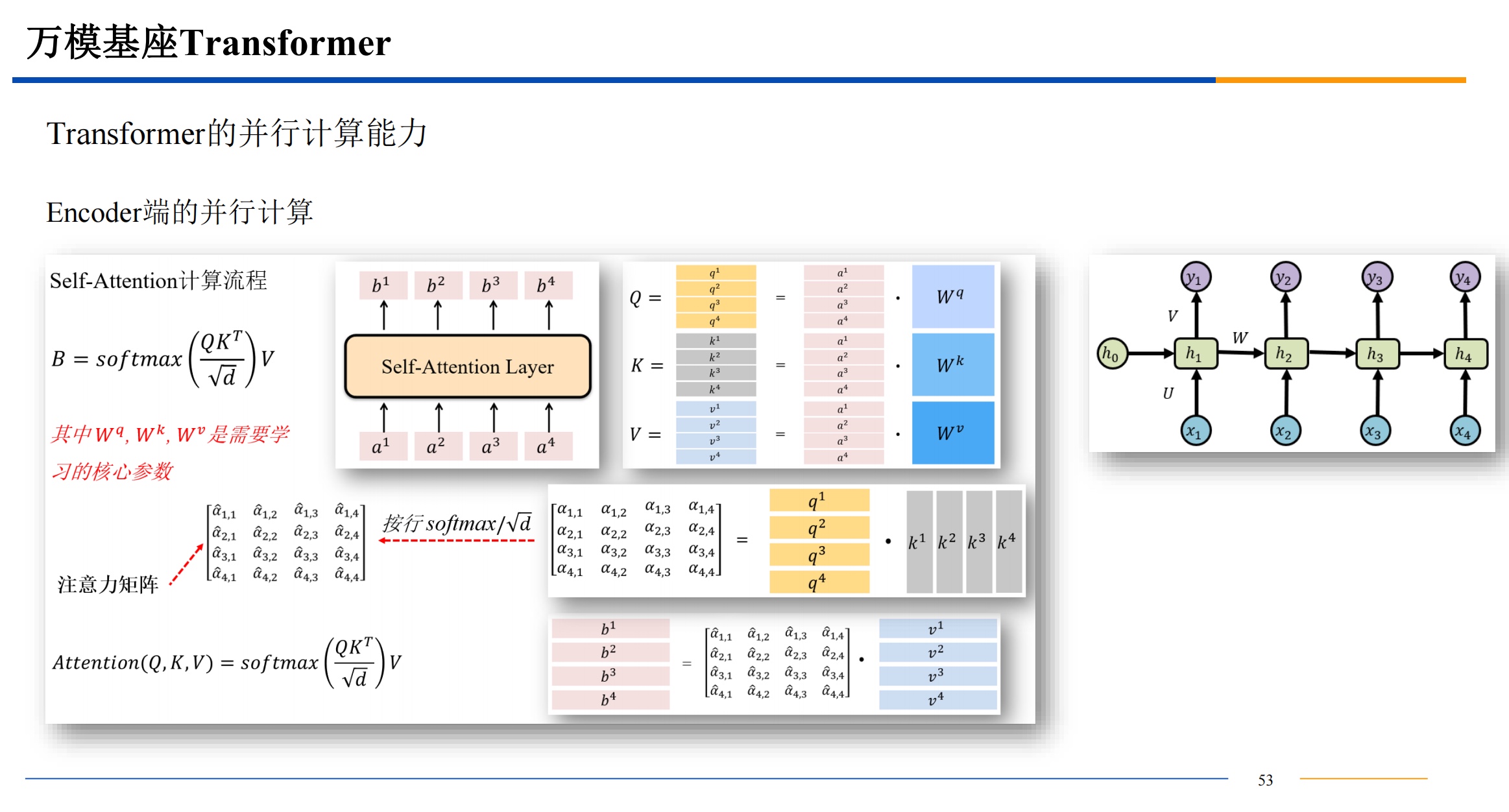
并行计算